مرحباً هابر. أود أن أتحدث عن أحد أساليب حل مشكلة تعدد المتحدثين وأظهر كيف يمكن تنفيذ هذه الطريقة في الثعبان. حتى لا نخيف القارئ ، لن أقدم صيغًا رياضية معقدة (جزئياً لأنني أنا "لست لحامًا حقيقيًا") ، لكنني سأحاول أن أذكر كل شيء بلغة بسيطة وأخبر كل شيء حتى يتمكن مطور لم يواجه التعلم الآلي من قبل من فهمه.
في الاستعداد لكتابة هذا المقال ، اخترت بين خيارين: لأولئك الذين هم على دراية بعلوم البيانات وأولئك الذين يبرمجون جيدًا في النهاية ، اخترت الخيار الثاني ، وقررت أن هذا سيكون عرضًا جيدًا لقدرات DS.
بيان المشكلة
كما
تخبرنا ويكيبيديا ، فإن التنويع هو عملية تقسيم دفق صوتي وارد إلى مقاطع متجانسة وفقًا لما إذا كان الدفق الصوتي ينتمي إلى مكبر صوت واحد أو آخر. بمعنى آخر ، يجب تقسيم السجل إلى أجزاء وترقيم: شخص يتحدث في هذه الأماكن وآخر في هذه الأماكن. من وجهة نظر التعلم الآلي ، تنتمي المهام من هذا النوع إلى فئة التعلم بدون معلم وتسمى المجموعات. على سبيل المثال ، ما هي طرق العنقود الموجودة التي يمكن قراءتها
هنا أو
هنا ، سأناقش فقط تلك التي تفيدنا - هذه هي نموذج الخليط الغوسي والتجمع الطيفي. ولكن عنهم بعد ذلك بقليل.
لنبدأ من البداية.
إعداد البيئة
المفسدلم أكن متأكدًا من ترك هذا القسم - لم أرغب في تحويل المقالة إلى برنامج تعليمي للغاية. لكن في النهاية تركتها. كل من لا يحتاج إليها سوف يتخطى ، وبالنسبة لأولئك الذين سيفعلون كل شيء من الصفر ، فإن هذه الخطوة ستسهل البداية.
بشكل عام ، بالإضافة إلى R ، python هي اللغة الرئيسية لحل مشاكل علوم البيانات ، وإذا لم تكن قد حاولت البرمجة عليها بعد ، فأنا أوصي بشدة بالقيام بذلك لأن python يتيح لك القيام بالعديد من الأشياء بشكل أنيق ، حرفيا في بضعة أسطر (بالمناسبة ، هناك حتى مثل هذا ميمي).
هناك فرعين متطورين بشكل منفصل من الثعبان - الإصداران 2 و 3. في أمثلتي ، استخدمت الإصدار 3.6 ، ولكن إذا رغبت في ذلك ، يمكن بسهولة نقلهما إلى الإصدار 2.7. من الملائم نشر أي من هذه الفروع جنبًا إلى جنب مع مثبت
Anaconda ، من خلال التثبيت الذي ستتلقى على الفور غلافًا تفاعليًا للتطوير - IPython.
بالإضافة إلى بيئة التطوير نفسها ، ستكون هناك حاجة إلى مكتبات إضافية: librosa (للعمل مع سمات الصوت والاستخراج) ، webrtcvad (للتجزئة) والمخلل (لكتابة نماذج مدربة إلى ملف). يتم تثبيت كل منهم بواسطة أمر بسيط في Anaconda Prompt.
pip install [library]
استخراج الميزة
لنبدأ باستخراج الميزات - البيانات التي ستعمل بها نماذج تعلُم الآلة. من حيث المبدأ ، فإن الإشارة الصوتية نفسها هي بالفعل بيانات ، وهي مجموعة مرتبة من قيم اتساع الصوت ، والتي تتم إضافة رأس يحتوي على عدد القنوات وتردد أخذ العينات ومعلومات أخرى. لكننا لن نتمكن من تحليل هذه البيانات مباشرة ، لأنها لا تحتوي على مثل هذه الأشياء ، بالنظر إلى ما يمكن لنموذجنا أن يقوله - نعم ، هذه القطع تخص نفس الشخص.
في مهام معالجة الكلام ، هناك العديد من الأساليب لاستخراج الميزات. واحد منهم هو الحصول على معاملات Cepstral تردد ميل. لقد
كتبوا هنا
بالفعل ، لذلك سأذكركم قليلاً.
يتم قطع الإشارة الأصلية إلى إطارات بطول 16-40 مللي ثانية. ثم ، بتطبيق نافذة
هامينج على الإطار ، يقومون بتحويل فورييه السريع ويحصلون على الكثافة الطيفية للقدرة. ثم ، مع "مشط" خاص من المرشحات مرتبة بشكل موحد على مقياس الطباشير ، يتم عمل مخطط طيفي للطباشير ، يتم تطبيق تحويل جيب التمام المنفصل (DCT) - خوارزمية ضغط البيانات المستخدمة على نطاق واسع. المعاملات التي تم الحصول عليها بهذه الطريقة هي نوع من الخصائص المضغوطة للإطار ، وبما أن المرشحات التي استخدمناها كانت موجودة في مقياس
الطباشير ، فإن المعاملات تحمل المزيد من المعلومات في نطاق إدراك الأذن البشرية. عادة ، يتم استخدام 13 إلى 25 MFCC لكل إطار. نظرًا لأنه بالإضافة إلى الطيف نفسه ، يتم تشكيل شخصية الصوت بالسرعة والتسارع ، يتم دمج MFCC مع المشتقات الأولى والثانية.
بشكل عام ، يعد MFCC هو الخيار الأكثر شيوعًا للعمل مع الكلام ، ولكن بالإضافة إلى ذلك ، هناك علامات أخرى - LPC (الترميز التنبؤي الخطي) و PLP (التنبؤ الخطي الإدراكي) ، وأحيانًا يمكنك أيضًا العثور على LFCC ، حيث يتم استخدام الخط الخطي بدلاً من مقياس الطباشير.
دعونا نرى كيفية استخراج MFCC في بيثون.
import numpy as np import librosa mfcc=librosa.feature.mfcc(y=y, sr=sr, hop_length=int(hop_seconds*sr), n_fft=int(window_seconds*sr), n_mfcc=n_mfcc) mfcc_delta=librosa.feature.delta(mfcc) mfcc_delta2=librosa.feature.delta(mfcc, order=2) stacked=np.vstack((mfcc, mfcc_delta, mfcc_delta2)) features=stacked.T
كما ترى ، يتم ذلك حقًا في بضعة أسطر. الآن دعنا ننتقل إلى خوارزمية التجميع الأولى.
نموذج الخليط الغوسي
يشير نموذج مزيج من توزيعات غوسية إلى أن بياناتنا هي مزيج من توزيعات غوسية متعددة الأبعاد مع معلمات معينة.
إذا كنت ترغب في ذلك ، يمكنك بسهولة العثور على وصف تفصيلي للنموذج وكيف تعمل
خوارزمية EM التي تدرب هذا النموذج ، لكنني وعدت بعدم الإزعاج من الصيغ المعقدة وبالتالي سأعرض أمثلة جميلة من
هذه المقالة.
سننشئ أربع مجموعات ونرسمها.
from sklearn.datasets.samples_generator import make_blobs X, y_true=make_blobs(n_samples=400, centers=4, cluster_std=0.60, random_state=0) plt.scatter(X[:, 0], X[:, 1]);
سننشئ نموذجًا ، ونتدرب على بياناتنا ونرسم النقاط مرة أخرى ، ولكن مع مراعاة النموذج المتوقع لعضوية المجموعة.
from sklearn.mixture import GaussianMixture gmm = GaussianMixture(n_components=4) gmm.fit(X) labels=gmm.predict(X) plt.scatter(X[:, 0], X[:, 1], c=labels, s=40, cmap='viridis');
تعامل النموذج بشكل جيد مع البيانات الاصطناعية. من حيث المبدأ ، من خلال تنظيم عدد مكونات الخليط ونوع مصفوفة التغاير (عدد درجات حرية الغوسيين) ، يمكن وصف البيانات المعقدة إلى حد ما.

لذا ، فنحن نعرف كيفية تنفيذ معلمات البيانات وقادرون على تدريب نموذج مزيج من التوزيعات الغوسية. الآن يمكن للمرء أن يحاول التكتل على الجبهة - تدريب GMM على MFCC المستخرجة من الحوار. وربما ، في بعض الحوار الفراغي الكروي المثالي ، والذي سيتناسب فيه كل متحدث مع لغته الغوسية ، سنحصل على نتيجة جيدة. من الواضح أن هذا لن يحدث في الواقع. في الواقع ، بمساعدة GMM ، لا يشكلون نموذجًا لحوار ، ولكن كل شخص في حوار - أي أنهم يتخيلون أن صوت كل متحدث في العلامات المستخرجة موصوف من قبل مجموعته الخاصة من Gaussians.
للتلخيص ، نحن نصل ببطء إلى الموضوع الرئيسي.
تجزئة
تقليديا ، تتكون عملية التنحيف من ثلاث كتل متتالية - الكشف الصوتي (اكتشاف نشاط الصوت) ، والتجزئة والتجميع (هناك نماذج يتم فيها الجمع بين الخطوتين الأخيرتين ، انظر
LIA E-HMM ).
في الخطوة الأولى ، يتم فصل الكلام عن أنواع مختلفة من الضوضاء. تحدد خوارزمية VAD ما إذا كانت قطعة الملف الصوتي المقدمة إليها عبارة عن خطاب ، أو على سبيل المثال ، تبدو صفارة إنذار أو شخص عطس. من الواضح أنه لكي تكون هذه الخوارزمية عالية الجودة ، من الضروري التدريب مع المعلم. وهذا بدوره يعني أنك بحاجة إلى ترميز البيانات - بعبارة أخرى ، إنشاء قاعدة بيانات مع تسجيلات الكلام وجميع أنواع الضوضاء. سنفعل ذلك بتكاسل - خذ جهاز
VAD الجاهز ، والذي لا يعمل بشكل مثالي ، ولكن بالنسبة للمبتدئين لدينا ما يكفي.
تقطع الكتلة الثانية بيانات الكلام إلى مقاطع بمكبر صوت نشط واحد. النهج الكلاسيكي في هذا الصدد هو الخوارزمية لتحديد تغيير المتحدث بناءً على معيار معلومات بايزي -
BIC . جوهر هذه الطريقة هو كما يلي - تمر نافذة منزلقة من خلال التسجيلات الصوتية وفي كل نقطة من المقطع يجيبون على السؤال: "كيف يتم وصف البيانات في هذا المكان بشكل أفضل - توزيع واحد أم اثنين؟" للإجابة على هذا السؤال ، يتم حساب المعلمة
، بناءً على علامة اتخاذ قرار بتغيير المتحدث. تكمن المشكلة في أن هذه الطريقة لن تعمل بشكل جيد للغاية في حالة حدوث تغييرات متكررة في مكبر الصوت ، وحتى في وجود ضجيج (وهي خاصية مميزة جدًا لتسجيل محادثة هاتفية).
شرح صغيرفي الأصل ، عملت مع تسجيلات الهاتف لمركز اتصال بمتوسط مدة حوالي 4 دقائق. لأسباب واضحة ، لا يمكنني نشر هذه الملاحظات ، لذلك بالنسبة للمظاهرة أخذت مقابلة من محطة إذاعية واحدة. في حالة إجراء مقابلة طويلة ، من المحتمل أن تعطي هذه الطريقة نتيجة مقبولة ، لكنها لم تعمل على بياناتي.
في الظروف التي لا يقاطع فيها المذيعون بعضهم البعض ولا تتداخل أصواتهم ، فإن VAD أننا سنستخدم نسخًا أقل أو أكثر مع مهمة التقسيم ، وبالتالي ستبدو الخطوتان الأوليان على هذا النحو.
في الواقع ، سيتحدث الناس بالتأكيد في نفس الوقت. علاوة على ذلك ، فإن VAD في بعض الأماكن قد أخطأ بسبب حقيقة أن السجل غير مباشر ، ولكنه لصق يتم قطعه. يمكنك محاولة تكرار القطع إلى شرائح ، مما يزيد من عدوانية VAD من 2 إلى 3.
GMM-UBM
لدينا الآن مقاطع منفصلة ، وقررنا أن نقوم بتصميم نموذج لكل متحدث باستخدام GMM. نستخرج الإشارات من المقطع وعلى هذه البيانات ندرب النموذج. دعنا نفعل ذلك في كل مقطع ومقارنة النماذج الناتجة مع بعضها البعض. من المبرر أن نتوقع أن تكون النماذج التي تم تدريبها على قطاعات تابعة لنفس الشخص متشابهة إلى حد ما. ولكننا نواجه هنا المشكلة التالية ، وهي استخراج الإشارات من ملف صوتي مدته ثانية واحدة بتردد أخذ العينات 8000 هرتز مع نافذة بحجم 10 مللي ثانية ، نحصل على مجموعة من 800 متجه MFCC. لن يتمكن نموذجنا من التعلم من هذه البيانات ، لأنها لا تذكر. حتى لو لم تكن ثانية واحدة ، ولكن عشر ، فإن البيانات لن تكون كافية. وهنا يأتي نموذج الخلفية العالمي (UBM) إلى الإنقاذ ، ويطلق عليه أيضًا اسم اللغة المستقلة. الفكرة هي كما يلي. سنقوم بتدريب GMM على عينة بيانات كبيرة (في حالتنا ، هذا تسجيل كامل للمقابلة) وسنحصل على نموذج صوتي لمتحدث معمم (سيكون هذا UBM الخاص بنا). وبعد ذلك ، باستخدام خوارزمية تكيف خاصة (حولها أدناه) ، سوف "نلائم" هذا النموذج مع الخصائص المستخرجة من كل جزء. يستخدم هذا النهج على نطاق واسع ليس فقط في التأقلم ، ولكن أيضًا في أنظمة التعرف على الصوت. للتعرف على شخص ما عن طريق الصوت ، تحتاج أولاً إلى تدريب نموذج عليه وبدون UBM ، يجب أن يكون لديك عدة ساعات من تسجيل خطاب هذا الشخص.
من كل GMM مكيف ، نستخرج ناقل معاملات القص
(إنه أيضًا متوسط أو حصيرة. توقع ، إذا أردت) ، واستنادًا إلى البيانات على هذه المتجهات من جميع الأجزاء ، سنقوم بتجميع (أدناه سيكون واضحًا سبب كونها متجه التحول).
تعديل الخريطة
تسمى الطريقة التي سنخصص بها UBM لكل مقطع الحد الأقصى من التكيف مع A-Posteriori. بشكل عام ، الخوارزمية هي كما يلي. أولاً ، يتم حساب الاحتمال الخلفي على بيانات التكيف
والإحصاءات الكافية للوزن والوسيط والتباين لكل غوسي. ثم يتم دمج الإحصائيات التي تم الحصول عليها مع معلمات UBM ويتم الحصول على معلمات النموذج المعدل. في حالتنا ، سنكيف فقط الوسطيات ، دون التأثير على بقية المعلمات. على الرغم من حقيقة أنني وعدت بعدم التعمق في الرياضيات ، فسأذكر ثلاث صيغ بعد كل شيء ، لأن تكييف MAP هو النقطة الرئيسية في هذه المقالة.
هنا
- الاحتمال الخلفي ،
- إحصائيات كافية ل
،
- وسيط النموذج المكيّف ،
- معامل التكيف ،
- عامل الامتثال.
إذا كان كل هذا يبدو هراء ويسبب اليأس - لا تيأس. في الواقع ، لفهم تشغيل الخوارزمية ، ليس من الضروري الخوض في هذه الصيغ ؛ يمكن توضيح عملها بسهولة من خلال المثال التالي:
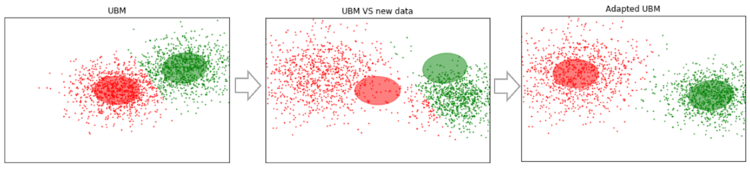
لنفترض أن لدينا بعض البيانات الكبيرة بما يكفي ، وقمنا بتدريب UBM عليها (الصورة اليسرى ، UBM عبارة عن مزيج مكون من مكونين من التوزيعات الغوسية). تظهر بيانات جديدة لا تتناسب مع نموذجنا (الشكل في المنتصف). باستخدام هذه الخوارزمية ، سنقوم بتحويل مراكز Gaussians بحيث تقع على البيانات الجديدة (الشكل على اليمين). بتطبيق هذه الخوارزمية على البيانات التجريبية ، فإننا نتوقع أنه في الأجزاء التي بها نفس المتحدث سوف يتحول الغوسيون في اتجاه واحد ، وبالتالي تشكيل مجموعات. لهذا السبب سنستخدم بيانات القص لتجميع الأجزاء
.
لذا ، فلنقم بتكييف خطة عمل البحر المتوسط لكل جزء. (كمرجع: بالإضافة إلى تكيف MAP ، يتم استخدام طريقة MLLR - الحد الأقصى من الانحدار الخطي المحتمل وبعض تعديلاته على نطاق واسع. كما يحاولون الجمع بين هاتين الطريقتين.)
SV = []
الآن لدينا كل قطعة لدينا بيانات عن
، ننتقل أخيرًا إلى الخطوة النهائية.
التكتل الطيفي
يتم وصف التكتل الطيفي بإيجاز في المقالة ، وهو ارتباط أعطيته في البداية. تبني الخوارزمية رسمًا بيانيًا كاملاً ، حيث تكون القمم بياناتنا ، وتكون الحواف بينهما مقياسًا للتشابه. في مهام التعرف على الصوت ، يتم استخدام مقياس جيب التمام على هذا النحو ، لأنه يأخذ في الاعتبار الزاوية بين المتجهات ، متجاهلاً حجمها (الذي لا يحمل معلومات حول المتحدث). من خلال إنشاء الرسم البياني ، يتم حساب المتجهات الذاتية لمصفوفة Kirchhoff (والتي هي في الأساس تمثيل للرسم البياني الناتج) ثم يتم استخدام بعض طريقة التجميع القياسية ، على سبيل المثال ، طريقة k-يعني. تناسبها كلها في سطرين من التعليمات البرمجية
N_CLUSTERS = 2 sc = SpectralClustering(n_clusters=N_CLUSTERS, affinity='cosine') labels = sc.fit_predict(SV)
الاستنتاجات والخطط المستقبلية
تم اختبار الخوارزمية الموصوفة بمعلمات مختلفة:
- رقم MFCC: 7 ، 13 ، 20
- MFCC بالاشتراك مع LPC
- نوع وعدد المخاليط في GMM: كامل [8 ، 16 ، 32] ، دياج [8 ، 16 ، 32 ، 64 ، 256]
- طرق تكييف UBM: MAP (مع covariance_type = 'full') و MLLR (مع covariance_type = 'diag')
ونتيجة لذلك ، ظلت المعلمات مثالية من الناحية الذاتية: MFCC 13 ، GMM covariance_type = 'full' n_components = 16.
لسوء الحظ ، لم يكن لدي الصبر (لقد بدأت كتابة هذه المقالة قبل أكثر من شهر) من أجل ترميز الشرائح المستلمة وحساب DER (معدل خطأ Diariztion). ذاتيًا ، أقيم تشغيل الخوارزمية على أنه "من حيث المبدأ ، ليس سيئًا ، ولكنه بعيد عن المثالية". من خلال التجميع على المتجهات التي تم الحصول عليها من أول مائة قطعة (بتمريرة واحدة من MAP) ، ثم اختيار تلك التي تقول فيها المحاورة (فتاة ، تتحدث أقل بكثير من الضيف هناك) ، يقدم التجميع قائمة
أي بنسبة 100٪. في الوقت نفسه ، تتسرب المقاطع التي يوجد فيها مكبرا الصوت (على سبيل المثال ، 14) ، ولكن يمكن إلقاء اللوم بالفعل على خطأ VAD. علاوة على ذلك ، تبدأ هذه الأجزاء في الاعتبار مع زيادة في عدد تصاريح MAP. نقطة مهمة. المقابلة التي عملنا معها كانت "نظيفة". إذا تمت إضافة إدخالات موسيقية مختلفة ، وضوضاء ، وأشياء أخرى غير لفظية ، يبدأ التكتل بالضعف. لذلك ، هناك خطط لمحاولة تدريب VAD الخاصة بنا (لأن webrtcvad ، على سبيل المثال ، لا يفصل الموسيقى عن الكلام).
نظرًا لأنني عملت في البداية مع محادثة هاتفية ، لم أكن بحاجة إلى تقدير عدد المتحدثين. لكن عدد المتحدثين ليس محددًا مسبقًا دائمًا ، حتى إذا كانت هذه مقابلة. على سبيل المثال ، في
هذه المقابلة في المنتصف ، هناك إعلان متراكب على الموسيقى وعبر عنه شخصان إضافيان. لذلك ، سيكون من المثير للاهتمام تجربة طريقة تقدير عدد المتحدثين المحددة في المقالة الأولى في قسم قائمة المراجع (بناءً على تحليل القيم الذاتية لمصفوفة لابلاس المعيارية).
المراجع
بالإضافة إلى المواد الموجودة على الروابط في النص وأجهزة الكمبيوتر المحمولة من Jupyter ، تم استخدام المصادر التالية لإعداد هذه المقالة:
- استقطاب مكبرات الصوت باستخدام GMM Supervector وخوارزميات الاختزال المتقدمة. نوريت سبينجارن
- طرق استخراج الميزات LPC و PLP و MFCC في التعرف على الكلام. نامراتا ديف
- تقييم MAP لملاحظات خليط غاوسي متعدد المتغيرات من سلاسل ماركوف. جان لوك جوفين وشين هوي لي
- في تحليل التكتل الطيفي وخوارزمية. Andrew Y. Ng، Michael I. Jordan ، Yair Weiss
- التعرف على المتحدث باستخدام نموذج الخلفية العالمي على قاعدة بيانات YOHO. ألكسندر ماجيتنياك
سأضيف أيضًا بعض مشاريع التنويع:
- ملحق الاستقطاب الجانبي و s4d. مكتبة بيثون للعمل مع الكلام. لسوء الحظ ، الوثائق ضعيفة.
- Bob وأجزائه المختلفة مثل bob.bio و bob.learn.em - مكتبة بيثون لمعالجة الإشارات والعمل مع البيانات البيومترية. Windows غير مدعوم.
- LIUM هو حل جاهز مكتوب بلغة Java.
يتم نشر جميع التعليمات البرمجية على
جيثب . من أجل الراحة ، قمت بعمل العديد من أجهزة الكمبيوتر المحمولة من Jupyter مع عرض لأشياء معينة - MFCC و GMM و MAP Adaptation و Diarization. هذا الأخير هو العملية الرئيسية. يوجد أيضًا في المستودع ملفات مخلل مع بعض النماذج المدربة مسبقًا والمقابلة نفسها.