لا يرتبط النجاح في مشاريع تعلُم الآلة عادةً بالقدرة على استخدام مكتبات مختلفة فحسب ، بل أيضًا بفهم المنطقة التي تأتي منها البيانات. كان الحل المثالي الذي اقترحه فريق أليكسي كايوتشنكو وسيرجي بيلوف وألكسندر دروبوتوف وأليكسي سميرنوف في مسابقة PIK Digital Day مثالاً ممتازًا على هذه الأطروحة. احتلوا المركز الثاني ، وبعد أسبوعين تحدثوا عن مشاركتهم والنماذج المبنية في
تدريب Yandex ML القادم.
أليكسي كايوتشنكو:
- مساء الخير! سنتحدث عن مسابقة PIK Digital Day التي شاركنا فيها. قليلا عن الفريق. كان هناك أربعة منا. كل ذلك بخلفية مختلفة تمامًا ، من مناطق مختلفة. في الواقع ، التقينا في النهائيات. تشكل الفريق قبل يوم واحد من المباراة النهائية. سوف أتحدث عن مسار المنافسة وتنظيم العمل. ثم سيخرج Seryozha ، سيخبرنا عن البيانات ، وسيخبر Sasha عن التقديم ، والمسار النهائي للعمل وكيف انتقلنا على طول المتصدرين.

باختصار حول المسابقة. تم تطبيق المهمة للغاية. نظمت PIC هذه المسابقة من خلال توفير بيانات عن مبيعات الشقق. كمجموعة بيانات تدريبية ، كانت هناك قصة ذات سمات لمدة عامين ونصف في موسكو ومنطقة موسكو. اشتملت المسابقة على مرحلتين. كانت مرحلة على الإنترنت ، حيث حاول كل مشارك على حدة صنع نموذجه الخاص ، والمرحلة غير المتصلة بالإنترنت ، لم يمض وقت طويل ، كانت يومًا واحدًا فقط من الصباح إلى المساء. ضرب قادة المرحلة على الإنترنت.
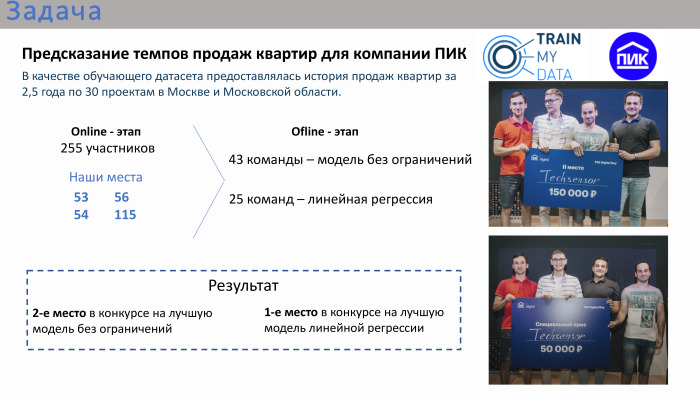
وفقًا لنتائج المسابقة عبر الإنترنت ، لم تكن أماكننا حتى في المراكز العشرة الأولى ، ولا حتى في المراكز العشرين الأولى. كنا هناك في الأماكن 50+. في النهاية ، كان هناك حاليا 43 فريقًا. كان هناك الكثير من الفرق تتكون من شخص واحد ، على الرغم من أنه كان من الممكن الاتحاد. حوالي ثلث الفرق لديها أكثر من شخص واحد. كانت هناك مسابقتان في المباراة النهائية. المسابقة الأولى هي نموذج بدون قيود. كان من الممكن استخدام أي خوارزميات: التعلم العميق ، التعلم الآلي. وبالتوازي ، عقدت مسابقة لأفضل حل للانحدار الخطي. اعتبر المنظم أن الانحدار الخطي تم تطبيقه أيضًا تمامًا ، حيث تم تطبيق المنافسة نفسها بشكل عام ككل. أي أنه تم طرح المهمة - كان من الضروري التنبؤ بحجم مبيعات الشقق ، مع وجود بيانات تاريخية للسنوات 2.5 السابقة مع السمات.
حصل فريقنا على المركز الثاني في المسابقة للحصول على أفضل نموذج بدون قيود والمركز الأول في المسابقة للحصول على أفضل انحدار. جائزة مزدوجة.

أستطيع أن أقول عن المسار العام للمنظمة أن المباراة النهائية كانت مرهقة للغاية ، مرهقة للغاية. على سبيل المثال ، تم تحميل قرار الفوز قبل دقيقتين فقط من مباراة التوقف. القرار السابق وضعنا ، في رأيي ، في المركز الرابع أو الخامس. أي أننا عملنا حتى النهاية ، دون الاسترخاء. نظمت الموافقة المسبقة عن علم كل شيء بشكل جيد للغاية. كانت هناك مثل هذه الطاولات ، بل كانت هناك شرفة أرضية حتى تتمكن من الجلوس في الشارع ، وتنفس الهواء النقي. تم توفير الطعام والقهوة ، كل شيء. تظهر الصورة أن الجميع كانوا يجلسون في مجموعاتهم ، وهم يعملون.
سيرجي سيروي المزيد عن البيانات.
سيرجي بيلوف:
- شكرا. قدمت لنا الموافقة المسبقة عن علم العديد من ملفات البيانات. النوعان الرئيسيان هما train.csv و test.csv ، حيث كان هناك حوالي 50 ميزة تم إنشاؤها بواسطة الموافقة المسبقة عن علم نفسها. يتكون القطار من حوالي 10 آلاف خط ، اختبار - من 2 ألف.
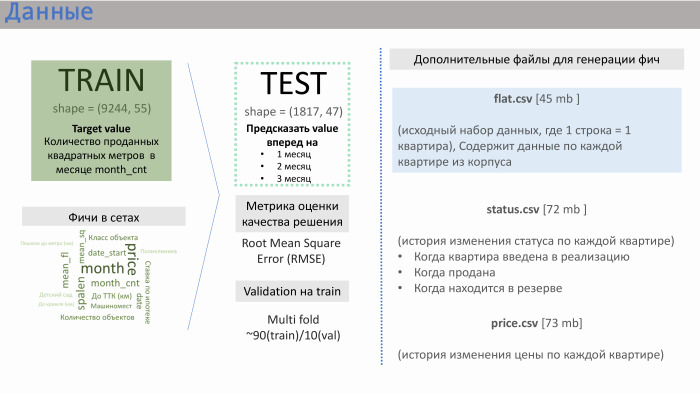
ماذا قدمت السلسلة؟ يحتوي على بيانات المبيعات. أي ، كقيمة (في هذه الحالة ، الهدف) ، كان لدينا مبيعات بالمتر المربع لشقق متوسطها فوق مبنى معين. كان هناك ما يقرب من 10 آلاف من هذه الخطوط. يتم عرض الميزات في المجموعات التي أنشأها PIK نفسه على الشريحة مع الأهمية التقريبية التي حصلنا عليها.
لقد ساعدتني هنا خبرة في شركات التطوير. ميزات مثل المسافة من الشقة إلى الكرملين أو إلى حلبة النقل ، وعدد أماكن وقوف السيارات - لا تؤثر بشكل كبير على المبيعات. يتم التأثير من خلال فئة الكائن ، الخمول ، والأهم من ذلك ، عدد الشقق في التنفيذ في الوقت الحالي. لم تنشئ PIC هذه الميزة ، لكنها زودتنا بثلاثة ملفات إضافية: flat.csv و status.csv و price.csv. وقررنا إلقاء نظرة على flat.csv ، لأنه كانت هناك بيانات فقط عن عدد الشقق وحالتها.
وإذا كان المرء يتساءل عما كان بمثابة نجاح قرارنا ، فهذا عمل جماعي محدد. منذ بداية هذه المسابقة ، عملنا بانسجام شديد. ناقشنا على الفور في مكان ما في حوالي 20 دقيقة ما سنفعله. توصلنا إلى استنتاج عام بأن أول شيء تحتاج إليه للعمل مع البيانات هو أن أي عالم بيانات يدرك أن هناك الكثير من البيانات في البيانات وغالبًا ما يكون النصر بسبب بعض الميزات التي أنشأها الفريق. بعد العمل مع البيانات ، استخدمنا بشكل أساسي نماذج مختلفة. قررنا معرفة النتيجة التي تعطيها ميزاتنا في كل من هذه النماذج ، ثم ركزنا على النموذج غير المحدود ونموذج الانحدار الخطي.
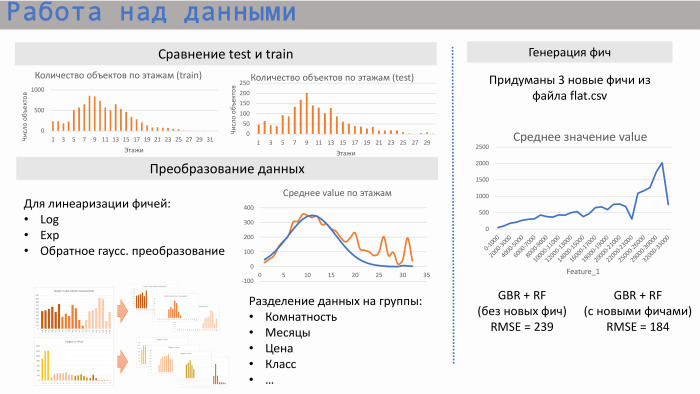
بدأنا العمل مع البيانات. بادئ ذي بدء ، نظرنا في كيفية ارتباط اختبارات مجموعة القطار مع بعضها البعض ، أي ، هل تتقاطع مجالات هذه البيانات. نعم ، إنها تتقاطع: في عدد الشقق ، وفي السكون ، وفي متوسط عدد الطوابق.
علاوة على ذلك ، بالنسبة للانحدار الخطي ، بدأنا في إجراء بعض التحولات. إنها مثل اللوغاريتمات القياسية للأسي. على سبيل المثال ، في حالة الطابق الأوسط ، كان هذا هو التحول الغوسي العكسي للتخطية. لاحظنا أيضًا أنه من الأفضل في بعض الأحيان فصل البيانات إلى مجموعات. إذا أخذنا ، على سبيل المثال ، المسافة من الشقة إلى المترو أو غرفته ، فهناك أسواق مختلفة قليلاً ، ومن الأفضل التقسيم وإنشاء نماذج مختلفة لكل مجموعة.
أنشأنا ثلاث ميزات من ملف flat.csv. واحد منهم معروض هنا. يمكن ملاحظة أن لها علاقة خطية جيدة إلى حد ما ، إلى جانب هذا الهبوط. ما هي هذه الميزة؟ وهو يتوافق مع عدد الشقق قيد التنفيذ حاليا. وهذه الميزة تعمل بشكل جيد للغاية عند قيم منخفضة. أي أنه لا يمكن أن يكون هناك شقق مبيعة أكثر من المبلغ الموجود في البيع. ولكن في هذه الملفات ، في الواقع ، تم وضع عامل بشري معين ، لأنه يتم تجميعها من قبل البشر. لقد رأينا مباشرة نقاطًا خرجت من هذه المنطقة ، لأنها كانت مسدودة قليلاً بشكل غير صحيح.
مثال من المعرفة والتعلم. أعطى نموذج من GBR و Random Forest بدون ميزات RMSE 239 ، ومع هذه الميزات الثلاث - 184.
سوف تتحدث ساشا عن النماذج التي استخدمناها.
ألكسندر دروبوتوف:
- بضع كلمات حول نهجنا. كما قال الرجال ، كلنا مختلفون ، نأتي من مناطق مختلفة ، تعليم مختلف. وكان لدينا مناهج مختلفة. في المرحلة النهائية ، استخدمت Lesha XGBoost من Yandex أكثر (على الأرجح ، أعني CatBoost - ed.) ، Seryozha - مكتبة التعلم الموسيقي ، I - LightGBM والانحدار الخطي.

نماذج XGBoost والانحدار الخطي والنبي هي الخيارات الثلاثة التي أظهرت لنا أفضل نتيجة. بالنسبة للانحدار الخطي ، كان لدينا مزيج من نموذجين ، وللمنافسة العامة ، XGBoost ، وأضفنا القليل من الانحدار الخطي.

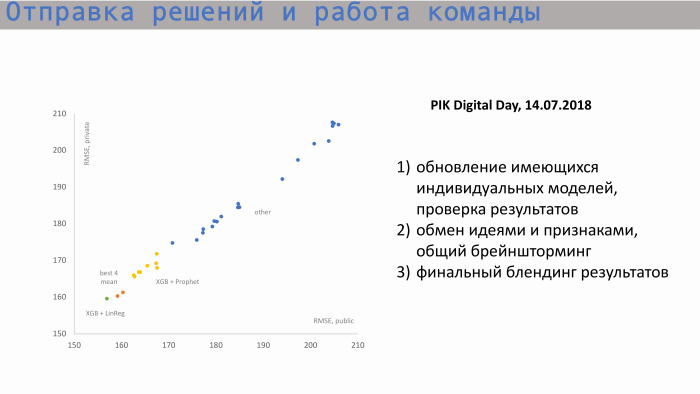
إليك عملية إرسال القرارات والعمل الجماعي. في الرسم البياني على اليسار ، المحور X هو RMSE العام ، وقيمة المقياس ، والمحور Y هو الدرجة الخاصة ، RMSE. بدأنا من هذه المواقف. هنا نماذج فردية لكل من المشاركين. ثم ، بعد تبادل الأفكار وإنشاء ميزات جديدة ، بدأنا في الاقتراب من أفضل درجاتنا. كانت قيمنا للنماذج الفردية هي نفسها تقريبًا. أفضل نموذج فردي هو XGBoost والنبي. خلق النبي توقعات للمبيعات المتراكمة. كان هناك علامة مثل مربع البداية. أي أننا عرفنا عدد الشقق التي لدينا إجماليًا ، وفهمنا القيمة التاريخية ، والقيمة الإضافية التي سعت إلى القيمة الإجمالية. توقع النبي للمستقبل ، وأصدر القيم في الفترات التالية وقدمها إلى XGBoost.
مزج أفضل درجاتنا الفردية موجود في مكان ما هنا ، هاتان النقطتان البرتقاليتان. لكن هذه النتيجة لم تكن كافية لنا للوصول إلى القمة.
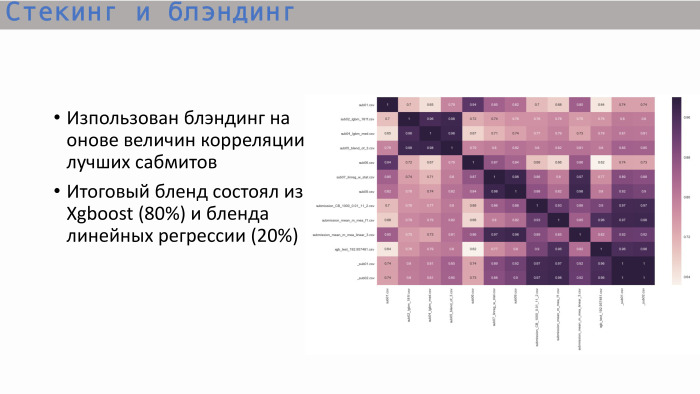
بعد دراسة مصفوفة الارتباط المعتادة لأفضل التقديمات ، رأينا ما يلي: أظهرت الأشجار - وهذا منطقي - ارتباطًا قريبًا من الوحدة ، وأعطت أفضل شجرة XGBoost. لا يظهر ارتباطًا كبيرًا مع الانحدار الخطي. قررنا مزج هذين الخيارين بنسبة 8 إلى 2. وبهذه الطريقة حصلنا على أفضل حل نهائي.
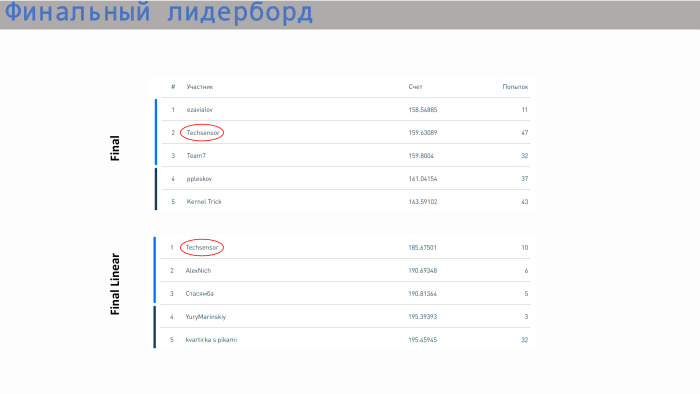
هذا هو المتصدرين مع النتائج. احتل فريقنا المركز الثاني في نماذج غير محدودة والمركز الأول في النماذج الخطية. بالنسبة للنتيجة - هنا جميع القيم قريبة جدًا. الفرق ليس كبيرا جدا. إن الانحدار الخطي يتخذ بالفعل خطوة في المجال 5. لدينا كل شيء ، شكرا!