
بدأ أحد المؤتمرات الرئيسية لعلوم البيانات لهذا العام في لندن اليوم ، وسأحاول التحدث على الفور عما كان مثيرًا للاهتمام لسماعه.
تبين أن البداية كانت متوترة: في صباح نفس اليوم ، تم تنظيم اجتماع جماعي لشهود يهوه في نفس المركز ، لذلك لم يكن من السهل العثور على مكتب التسجيل لشرطة المرور ، وعندما وجدته أخيرًا ، كان الخط بطول 150-200 متر. ومع ذلك ، بعد حوالي 20 دقيقة من الانتظار ، حصل على شارة مرغوبة وذهب إلى فصل دراسي رئيسي.
الخصوصية في تحليل البيانات
تم تخصيص ورشة العمل الأولى للحفاظ على الخصوصية في تحليل البيانات. في البداية ، تأخرت ، ولكن ، على ما يبدو ، لم أفقد أي شيء كثيرًا - لقد تحدثوا عن مدى أهمية الخصوصية وكيف يمكن للمهاجمين استخدام المعلومات الخاصة التي تم الكشف عنها. بالمناسبة ، يقول أشخاص محترمون تمامًا من Google و LinkedIn و Apple. نتيجة ترك الفصل الرئيسي انطباعًا إيجابيًا للغاية ، فإن جميع الشرائح متوفرة
هنا .
اتضح أن مفهوم
الخصوصية التفاضلية موجود منذ فترة طويلة ، وفكرته هي إضافة ضوضاء تجعل من الصعب تحديد قيم فردية حقيقية ، ولكنها تحتفظ بالقدرة على استعادة التوزيعات الشائعة. في الواقع ، هناك معلمتان:
e - مدى صعوبة الكشف عن البيانات ، و
d - مدى تشويه الإجابات.
يشير المفهوم الأصلي إلى وجود نوع من الارتباط الوسيط بين المحلل والبيانات - "أمين" ، وهو الذي يعالج جميع الطلبات ويولد ردودًا حتى تحجب الضوضاء البيانات الخاصة. في الواقع ، غالبًا ما يتم استخدام نموذج الخصوصية التفاضلية المحلية ، حيث تظل بيانات المستخدم على جهاز المستخدم (على سبيل المثال ، هاتف محمول أو كمبيوتر شخصي) ، ومع ذلك ، عند الرد على طلبات المطور ، يرسل التطبيق حزمة بيانات من الجهاز الشخصي لا تسمح بمعرفة ما هو بالضبط رد هذا المستخدم بالذات. على الرغم من أنه عند دمج الردود من عدد كبير من المستخدمين ، يمكنك استعادة الصورة العامة بدقة عالية.
مثال جيد هو استطلاع "هل أجريت عملية إجهاض"؟ إذا قمت بإجراء مسح "على الجبهة" ، فلن يقول أحد الحقيقة. ولكن إذا قمت بتنظيم المسح على النحو التالي: "ألق عملة معدنية ، إذا كان هناك نسر ، ثم رميها مرة أخرى وقول" نعم "للنسر ، ولكن" لا "إلى ذيول ، وإلا أجبت بالحقيقة" ، فمن السهل استعادة التوزيع الحقيقي مع الحفاظ على الخصوصية الفردية. كان تطوير هذه الفكرة هو آليات جمع الإحصائيات الحساسة
Google RAPPOR (تقرير Ordinal الحفاظ على الخصوصية العادي) ، والذي تم استخدامه لجمع البيانات حول استخدام Chrome وشوكه.
مباشرة بعد إصدار Chrome في المصدر المفتوح ، ظهر عدد كبير إلى حد ما من الأشخاص الذين أرادوا إنشاء متصفحهم الخاص مع صفحة رئيسية تم تجاوزها ، ومحرك بحث ، ونرد إعلاني خاص بهم ، وما إلى ذلك. بطبيعة الحال ، لم يكن المستخدمون و Google متحمسين لذلك. يمكن فهم المزيد من الإجراءات بشكل عام: لمعرفة البدائل الأكثر شيوعًا والسحق إداريًا ، ولكن ما جاء غير متوقع ... لم تسمح سياسة خصوصية Chrome لـ Google بأخذ المعلومات وجمعها حول إعداد الصفحة الرئيسية ومحرك البحث للمستخدم :(
للتغلب على هذا القيد وإنشاء RAPPOR ، والذي يعمل على النحو التالي:
- يتم تسجيل البيانات الموجودة على الصفحة الرئيسية في فلتر بلوم صغير بحجم 128 بت.
- تتم إضافة ضجيج أبيض دائم إلى مرشح الإزهار. دائم = نفس الشيء لهذا المستخدم ، بدون حفظ ضوضاء ، يمكن للطلبات المتعددة أن تكشف عن بيانات المستخدم.
- فوق الضوضاء المستمرة ، يتم فرض الضوضاء الفردية التي تم إنشاؤها لكل طلب.
- يتم إرسال متجه البت الناتج إلى Google ، حيث يبدأ فك تشفير الصورة الإجمالية.
- أولاً ، من خلال الأساليب الإحصائية ، نطرح تأثير الضوضاء من الصورة الإجمالية.
- بعد ذلك ، نبني ناقلات بت مرشحة (المواقع / محركات البحث الأكثر شعبية من حيث المبدأ).
- باستخدام المتجهات التي تم الحصول عليها كأساس ، نقوم ببناء انحدار خطي لإعادة بناء الصورة.
- دمج الانحدار الخطي مع LASSO لقمع المرشحين غير ذوي الصلة.
من الناحية التخطيطية ، يبدو إنشاء الفلتر كما يلي:

اتضح أن تجربة تنفيذ RAPPOR كانت إيجابية للغاية ، ويتزايد بسرعة عدد الإحصاءات الخاصة التي تم جمعها بمساعدتها. من بين عوامل النجاح الرئيسية ، حدد المؤلفون:
- بساطة ووضوح النموذج.
- الانفتاح وتوثيق الكود.
- التواجد على الرسوم البيانية النهائية لحدود الأخطاء.
ومع ذلك ، فإن هذا النهج له قيود كبيرة: من الضروري أن يكون لديك قوائم إجابات مرشح لفك التشفير (وهذا هو السبب في O - Ordinal). عندما بدأت Apple في جمع إحصائيات حول الكلمات والرموز التعبيرية المستخدمة في الرسائل النصية ، أصبح من الواضح أن هذا النهج لم يكن جيدًا. ونتيجة لذلك ، في مؤتمر WDC-2016 ، كانت إضافة الخصوصية التفاضلية واحدة من أهم الميزات الجديدة التي تم الإعلان عنها على iOS. تم استخدام مزيج من هيكل التخطيط مع الضوضاء المضافة كأساس ، ومع ذلك ، كان لا بد من حل العديد من المشاكل التقنية:
- يجب أن يكون العميل (الهاتف) قادرا على بناء وتخزين هذه الإجابة في وقت معقول.
- علاوة على ذلك ، يجب تعبئة هذه الاستجابة في رسالة شبكة محدودة الحجم.
- من ناحية Apple ، يجب أن يكون كل هذا متراكمًا في فترة زمنية معقولة.
ونتيجة لذلك ، توصلنا إلى مخطط يستخدم
رسم العد-min-sketch لتشفير الكلمات ، ثم اخترنا بشكل عشوائي استجابة وظيفة واحدة فقط من وظائف التجزئة (ولكن مع تحديد خيار زوج المستخدم / الكلمة) ، تم تحويل المتجه باستخدام تحويل
Hadamard وإرساله إلى الخادم فقط "بت" واحد مهم لوظيفة التجزئة المحددة.
لاستعادة النتيجة على الخادم ، كان من الضروري أيضًا مراجعة الفرضيات المرشحة. ولكن اتضح أنه مع حجم القاموس الكبير يكون معقدًا للغاية حتى بالنسبة للكتلة. كان من الضروري اختيار بطريقة ما بطريقة استكشافية بطريقة مجردة أكثر مجالات البحث الواعدة. كانت تجربة استخدام bigrams كنقاط انطلاق ، والتي يمكنك من خلالها تجميع الفسيفساء ، غير ناجحة - كانت جميع bigrams ذات شعبية متساوية. حل أسلوب تجزئة bigram + word المشكلة ، لكنه أدى إلى انتهاك الخصوصية. ونتيجة لذلك ، استقرنا على أشجار البادئة: تم جمع الإحصائيات حول الأجزاء الأولية للكلمة ثم على الكلمة بأكملها.
ومع ذلك ، أظهر تحليل خوارزمية الخصوصية التي تستخدمها Apple من قبل مجتمع البحث أنه لا يزال من
الممكن اختراق الخصوصية مع الإحصائيات طويلة المدى.
كان LinkedIn في وضع أكثر صعوبة مع دراسته لتوزيع رواتب المستخدمين. والحقيقة هي أن الخصوصية التفاضلية تعمل بشكل جيد عندما يكون لدينا عدد كبير جدًا من القياسات ، وإلا فإنه لا يمكن طرح الضوضاء بشكل موثوق. في استبيان الرواتب ، عدد التقارير محدود ، وقررت LinkedIn اتخاذ مسار مختلف: الجمع بين التشفير التقني وأدوات الأمن السيبراني مع مفهوم
عدم الكشف عن الهوية : تعتبر بيانات المستخدم مقنعة بما فيه الكفاية إذا قمت بتقديمها في حزمة حيث يوجد k إجابات بنفس سمات الإدخال (على سبيل المثال ، الموقع والمهنة) التي تختلف فقط في المتغير المستهدف (الراتب).
ونتيجة لذلك ، تم بناء ناقل معقد تقوم فيه خدمات مختلفة بإرسال أجزاء من البيانات إلى بعضها البعض ، وتشفيرها باستمرار حتى لا تتمكن آلة واحدة من فتحها بالكامل. ونتيجة لذلك ، يتم تقسيم المستخدمين حسب السمات إلى مجموعات نموذجية ، وعندما تصل المجموعة إلى الحجم الأدنى ، تنتقل إحصائياتها إلى HDFS لتحليلها.
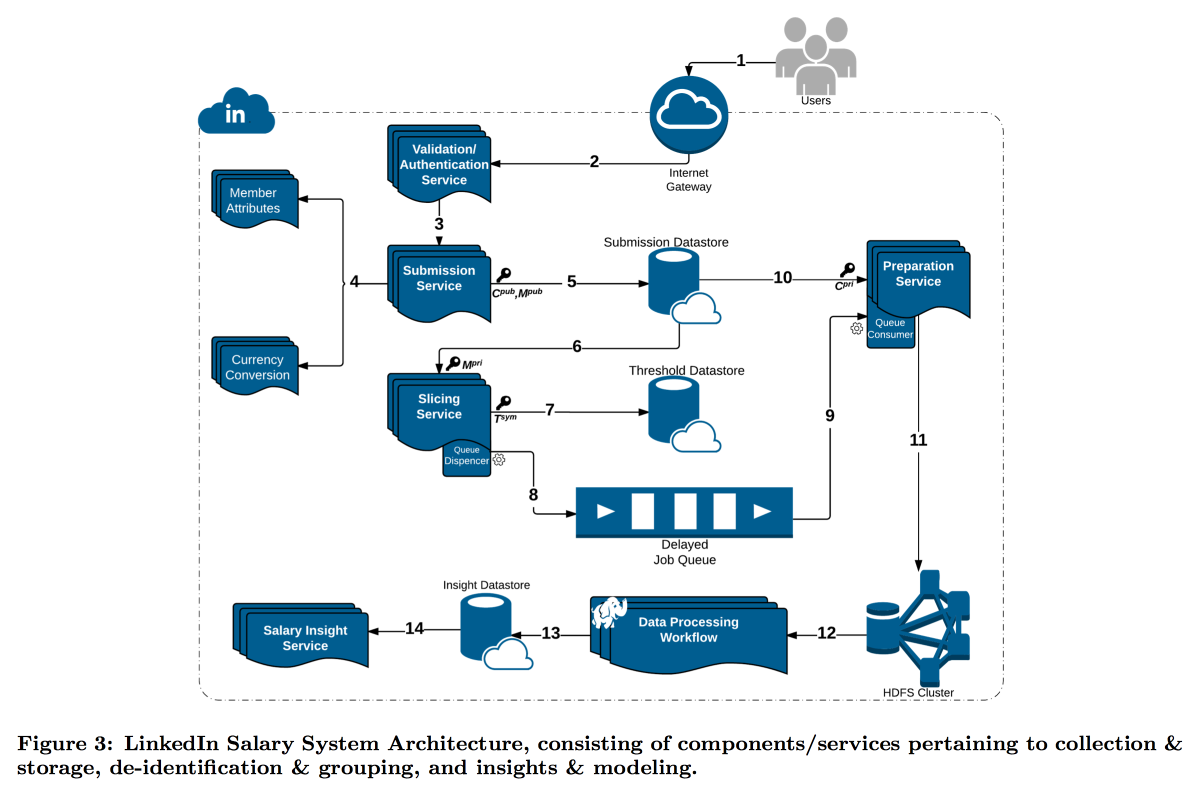
يستحق الطابع الزمني اهتمامًا خاصًا: يجب أيضًا أن يكون مجهولاً ، وإلا يمكنك معرفة من هو سجل المكالمات. لكني لا أريد قضاء بعض الوقت تمامًا ، لأنه من المثير للاهتمام متابعة الديناميكيات. ونتيجة لذلك ، قررنا إضافة طابع زمني للسمات التي يتم من خلالها بناء المجموعة النموذجية ، ومتوسط قيمتها فيها.
والنتيجة هي ميزة مميزة مثيرة للاهتمام وبعض الأسئلة المفتوحة المفتوحة المثيرة للاهتمام:
تقترح اللائحة العامة لحماية البيانات أنه ، عند الطلب ، يجب أن نتمكن من حذف جميع بيانات المستخدم ، لكننا حاولنا إخفائها حتى لا نتمكن الآن من العثور على بياناتها. بوجود بيانات على عدد كبير من الشرائح / المجموعات النموذجية المختلفة ، يمكنك عزل التطابقات وتوسيع قائمة السمات المفتوحة
يعمل هذا النهج مع البيانات الكبيرة ، ولكنه لا يعمل مع البيانات المستمرة. تُظهر الممارسة أن أخذ عينات البيانات ببساطة ليس فكرة جيدة ، لكن Microsoft في NIPS2017
اقترحت حلاً حول كيفية العمل معها. لسوء الحظ ، لم يكن لدى التفاصيل الوقت للكشف.
تحليل الرسم البياني الكبير
بدأت ورشة العمل الثانية حول تحليل الرسوم البيانية الكبيرة في فترة ما بعد الظهر. على الرغم من حقيقة أنه كان يقوده أيضًا رجال من Google ، وكان هناك المزيد من التوقعات منه ، إلا أنه لم يعجبه كثيرًا - فقد تحدثوا عن تقنياتهم المغلقة ، ثم وقعوا في المبتذلة والفلسفة العامة ، ثم غرقوا في التفاصيل الجامحة ، ولم يكن لديهم الوقت لصياغة المهمة. ومع ذلك ، تمكنت من التقاط بعض الجوانب المثيرة للاهتمام. يمكن العثور على الشرائح
هنا .
أولاً ، أعجبني المخطط المسمى
تجميع شبكة الأنا ، وأعتقد أنه من الممكن بناء حلول مثيرة للاهتمام على أساسها. الفكرة بسيطة للغاية:
- نحن نعتبر الرسم البياني المحلي من وجهة نظر مستخدم معين ، ولكن ناقص نفسه.
- نقوم بتجميع هذا الرسم البياني.
- بعد ذلك ، "نقوم بنسخ" الجزء العلوي من مستخدمنا ، بإضافة مثيل لكل عنقود وعدم ربطهم ببعضهم البعض بالحواف.
في الرسم البياني المحول المماثل ، يتم حل العديد من المشاكل بسهولة أكبر وتعمل خوارزميات الترتيب بشكل أكثر نظافة. على سبيل المثال ، من الأسهل بكثير تقسيم مثل هذا الرسم البياني بطريقة متوازنة ، وعند الترتيب في توصية الأصدقاء ، تكون عقد الجسر أقل ضوضاء. لهذه المهمة تم النظر في توصيات أصدقاء ENC / الترويج لها.
ولكن بشكل عام ، كانت ENC مجرد مثال على ذلك ، ففي Google تعمل إدارة كاملة في تطوير خوارزميات على الرسوم البيانية وتزويدها بأقسام أخرى كمكتبة. الوظائف المعلنة للمكتبة مثيرة للإعجاب: مكتبة أحلام لـ SNA ، ولكن كل شيء مغلق. في أفضل الأحوال ، يمكن تجربة الكتل الفردية لإعادة إنتاج المقالات. يُزعم أن المكتبة لديها مئات التطبيقات داخل Google ، بما في ذلك الرسوم البيانية مع أكثر من تريليون حافة.
ثم كان هناك حوالي 20 دقيقة من الترويج لنموذج MapReduce ، كما لو أننا لا نعرف مدى روعته. بعد ذلك أظهر الرجال أنه يمكن حل العديد من المشاكل المعقدة (تقريبًا) باستخدام نموذج المجموعات الأساسية المكونة العشوائية. الفكرة الرئيسية هي أن البيانات حول الحواف متناثرة بشكل عشوائي في العقد N ، وهناك يتم سحبها إلى الذاكرة ويتم حل المشكلة محليًا ، وبعد ذلك يتم نقل نتائج الحل إلى الجهاز المركزي ويتم تجميعها. يقال أنه بهذه الطريقة يمكنك الحصول على تقديرات جيدة رخيصة للعديد من المشاكل: مكونات الاتصال ، الحد الأدنى للغابة الممتدة ، الحد الأقصى للمطابقة ، التغطية القصوى ، إلخ. في بعض الحالات ، في نفس الوقت ، يحل كل من مصمم الخرائط والتصغير نفس المشكلة ، ولكن يمكن أن يكونا مختلفين قليلاً. مثال جيد على كيفية تسمية حل بسيط بذكاء حتى يؤمن به الناس.
ثم كانت هناك محادثة حول ما كنت أذهب إليه هنا: تقسيم الرسم البياني المتوازن. على سبيل المثال كيفية قطع رسم بياني إلى أجزاء N بحيث تكون الأجزاء متساوية في الحجم تقريبًا ، وعدد الروابط داخل الأجزاء أكبر بكثير من عدد الروابط الخارجية. إذا كنت قادرًا على حل هذه المشكلة جيدًا ، فإن العديد من الخوارزميات تصبح أسهل ، وحتى اختبارات A / B يمكن تشغيلها بشكل أكثر كفاءة ، مع تعويض التأثير الفيروسي. لكن القصة كانت مخيبة للآمال بعض الشيء ، كل شيء بدا وكأنه "خطة غنوم": تعيين الأرقام على أساس التجمعات الهرمية ، والتحرك ، وإضافة عدم التوازن. لا تفاصيل. حول هذا على KDD سيكون هناك تقرير منفصل عنهم لاحقًا ، سأحاول الذهاب. بالإضافة إلى وجود
مشاركة مدونة .
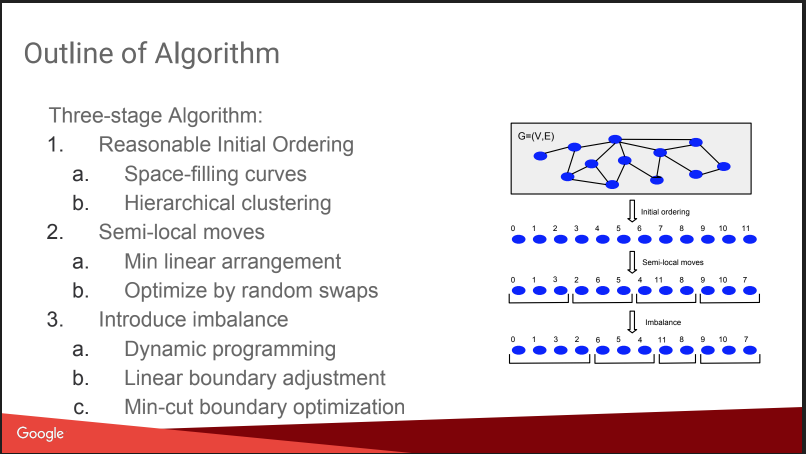
ومع ذلك ، أعطوا مقارنة مع بعض المنافسين ، بعضهم مفتوح:
Spinner ،
UB13 من FB ،
Fennel من Microsoft ،
Metis . يمكنك النظر إليهم أيضًا.
ثم تحدثنا قليلاً عن التفاصيل الفنية. يستخدمون العديد من النماذج للعمل مع الرسوم البيانية:
- MapReduce على رأس Flume. لم أكن أعلم أنه كان ممكنًا - لم يكتب Flume كثيرًا على الإنترنت لجمعه ، ولكن ليس لتحليل البيانات. أعتقد أن هذا انحراف داخل جوجل. UPD: اكتشفت أن هذا منتج داخلي من Google حقًا ، ولا علاقة له بـ Apache Flume ، فهناك بعض ersatz في السحابة تسمى dataflow
- MapReduce + جدول التجزئة الموزع. يقولون أنه يساعد على تقليل عدد جولات MP بشكل كبير ، ولكن على الإنترنت لا يوجد الكثير مكتوب حول هذه التقنية ، على سبيل المثال ، هنا
- بريجل - يقولون أنه سيموت قريبا.
- يعد تمرير الرسائل ASYnchronous أروع وأسرع وأكثر واعدة.
فكرة ASYMP مشابهة جدًا لـ Pregel:
- يتم توزيع العقد ، والحفاظ على حالتها ويمكنها إرسال رسالة إلى الجيران ؛
- قائمة الانتظار مبنية على الجهاز مع الأولويات ، ما يجب إرساله (قد يختلف الطلب عن ترتيب الإضافة) ؛
- بعد استلام رسالة ، قد تغير العقدة الحالة أو لا تغيرها ؛ عند التغيير ، نرسل رسالة إلى الجيران ؛
- تنتهي عندما تكون جميع قوائم الانتظار فارغة.
على سبيل المثال ، عند البحث عن المكونات المتصلة ، نقوم بتهيئة جميع القمم بأوزان عشوائية U [0،1] ، وبعد ذلك نبدأ في إرسال جيران على الأقل لبعضنا البعض. وبناءً على ذلك ، بعد أن حصلنا على الحد الأدنى من الجيران ، فإننا نبحث عن الحد الأدنى لهم ، وما إلى ذلك ، حتى يتم تثبيت الحد الأدنى. يلاحظون نقطة مهمة للتحسين: لطي الرسائل من عقدة واحدة (هذا هو المنعطف) ، تاركين فقط الأخيرة. يتحدثون أيضًا عن مدى سهولة التعافي من الفشل مع الحفاظ على حالة العقد.
يقولون أنهم يبنون خوارزميات سريعة جدًا بدون مشاكل ، يبدو أنها صحيحة - المفهوم بسيط وعقلاني. هناك
منشورات .
ونتيجة لذلك ، يشير الاستنتاج إلى نفسه: من المحزن أن نتابع قصصًا حول التقنيات المغلقة ، ولكن يمكن التقاط بعض الأجزاء المفيدة.