
في هذه المقالة ، سنقوم ببناء نموذج أساسي لشبكة عصبية تلافيفية قادرة على أداء
التعرف على العواطف في الصور. التعرف على العواطف في حالتنا هو مهمة تصنيف ثنائية ، الغرض منها هو تقسيم الصور إلى إيجابية وسلبية.
يمكن العثور على جميع التعليمات البرمجية ومستندات دفتر الملاحظات والمواد الأخرى ، بما في ذلك ملف Dockerfile ،
هنا .
البيانات
الخطوة الأولى في جميع مهام تعلُم الآلة تقريبًا هي فهم البيانات. فلنفعل ذلك.
هيكل مجموعة البيانات
يمكن تنزيل البيانات الأولية
هنا (في مستند
Baseline.ipynb ، يتم تنفيذ جميع الإجراءات في هذا القسم تلقائيًا). في البداية ، توجد البيانات في أرشيف بتنسيق Zip *. فكها وتعرف على بنية الملفات المستلمة.
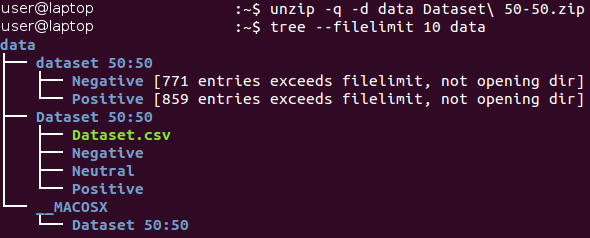
يتم تخزين جميع الصور داخل كتالوج "مجموعة البيانات 50:50" ويتم توزيعها بين دليلين فرعيين ، يتوافق اسمهما مع فئتها - السلبية والإيجابية. يرجى ملاحظة أن المهمة غير
متوازنة قليلاً - 53 في المائة من الصور إيجابية ، و 47 في المائة فقط سلبية. عادة ، تعتبر البيانات في مشاكل التصنيف غير متوازنة إذا اختلف عدد الأمثلة في الفئات المختلفة بشكل كبير. هناك
عدد من الطرق للعمل مع البيانات غير المتوازنة - على سبيل المثال ، الإفراط في أخذ العينات ، والفرط في الوزن ، وتغيير عوامل ترجيح البيانات ، وما إلى ذلك. في حالتنا ، يكون الخلل غير مهم ولا يجب أن يؤثر بشكل كبير على عملية التعلم. من الضروري فقط أن نتذكر أن المصنف الساذج ، الذي ينتج دائمًا القيمة "إيجابية" ، سيوفر قيمة دقة تبلغ حوالي 53 بالمائة لمجموعة البيانات هذه.
دعونا نلقي نظرة على بعض الصور من كل فئة.
سلبي

 إيجابية
إيجابية


للوهلة الأولى ، تختلف الصور من فصول مختلفة في الواقع عن بعضها البعض. ومع ذلك ، فلنقم بدراسة أعمق ونحاول العثور على أمثلة سيئة - صور مشابهة تنتمي إلى فئات مختلفة.
على سبيل المثال ، لدينا حوالي 90 صورة من الثعابين التي تحمل علامة سلبية وحوالي 40 صورة متشابهة جدًا من الثعابين التي تحمل علامة إيجابية.
صورة إيجابية لثعبان صورة سلبية لثعبان
صورة سلبية لثعبان
يحدث نفس الازدواجية مع العناكب (130 صورة سلبية و 20 صورة إيجابية) ، عُري (15 صورة سلبية و 45 صورة إيجابية) وبعض الفئات الأخرى. يشعر المرء أن علامات الصور تم إجراؤها من قبل أشخاص مختلفين ، وقد يختلف تصورهم للصورة نفسها. لذلك ، يحتوي التصنيف على تناقض متأصل. هاتان الصورتان من الثعابين متطابقة تقريبًا ، في حين نسبها خبراء مختلفون إلى فئات مختلفة. وبالتالي ، يمكننا أن نستنتج أنه من الصعب ضمان دقة 100٪ عند العمل مع هذه المهمة بسبب طبيعتها. نعتقد أن التقدير الأكثر واقعية للدقة سيكون بقيمة 80 في المائة - تستند هذه القيمة على نسبة الصور المماثلة الموجودة في فصول مختلفة أثناء الفحص البصري الأولي.
فصل عملية التدريب / التحقق
نحن نسعى دائمًا لإنشاء أفضل نموذج ممكن. ومع ذلك ، ما معنى هذا المفهوم؟ هناك العديد من المعايير المختلفة لذلك ، مثل: الجودة ، والمهلة الزمنية (التعلم + الحصول على المخرجات) ، واستهلاك الذاكرة. يمكن قياس بعضها بسهولة وموضوعية (على سبيل المثال ، الوقت وحجم الذاكرة) ، بينما يصعب تحديد البعض الآخر (الجودة). على سبيل المثال ، يمكن أن يثبت نموذجك دقة بنسبة 100 في المائة عند التعلم من الأمثلة التي تم استخدامها لهذه المرات العديدة ، ولكنه فشل في العمل مع الأمثلة الجديدة. تسمى هذه المشكلة
الإفراط في التجهيز وهي واحدة من أهم المشكلات في التعلم الآلي. هناك أيضًا مشكلة عدم
ملاءمة : في هذه الحالة ، لا يمكن أن يتعلم النموذج من البيانات المقدمة ويظهر توقعات ضعيفة حتى عند استخدام مجموعة بيانات تدريب ثابتة.
لحل مشكلة التجهيز الزائد ، يتم استخدام ما يسمى بتقنية
الاحتفاظ بجزء من العينات . فكرتها الرئيسية هي تقسيم بيانات المصدر إلى قسمين:
- مجموعة تدريب ، والتي عادة ما تشكل معظم مجموعة البيانات وتستخدم لتدريب النموذج.
- عادة ما تكون مجموعة الاختبار جزءًا صغيرًا من بيانات المصدر ، والتي تنقسم إلى قسمين قبل تنفيذ جميع إجراءات التدريب. لا يتم استخدام هذه المجموعة على الإطلاق في التدريب وتعتبر أمثلة جديدة لاختبار النموذج بعد الانتهاء من التدريب.
باستخدام هذه الطريقة ، يمكننا ملاحظة مدى
تعميم نموذجنا (أي أنه يعمل مع أمثلة غير معروفة سابقًا).
ستستخدم هذه المقالة نسبة 4/1 لمجموعات التدريب والاختبار. أسلوب آخر نستخدمه هو ما يسمى
التقسيم الطبقي . يشير هذا المصطلح إلى تقسيم كل فئة بشكل مستقل عن جميع الفئات الأخرى. يسمح هذا النهج بالحفاظ على نفس التوازن بين أحجام الفصول في مجموعات التدريب والاختبار. يستخدم التقسيم الطبقي ضمنيًا افتراض أن توزيع الأمثلة لا يتغير عند تغير بيانات المصدر ويظل كما هو عند استخدام أمثلة جديدة.
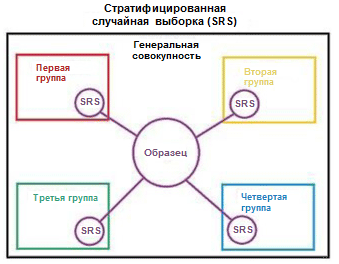
نوضح مفهوم الطبقات مع مثال بسيط. لنفترض أن لدينا أربع مجموعات / فئات بيانات تحتوي على عدد مناسب من الأشياء: الأطفال (5) والمراهقون (10) والبالغين (80) وكبار السن (5) ؛ انظر الصورة على اليمين (من
ويكيبيديا ). نحتاج الآن إلى تقسيم هذه البيانات إلى مجموعتين من العينات بنسبة 3/2. عند استخدام التقسيم الطبقي للأمثلة ، سيتم اختيار الأشياء بشكل مستقل عن كل مجموعة: شيئان من مجموعة الأطفال ، و 4 أشياء من مجموعة المراهقين ، و 32 شيئًا من مجموعة البالغين وشيئين من مجموعة كبار السن. تحتوي مجموعة البيانات الجديدة على 40 كائنًا ، وهو بالضبط 2/5 من البيانات الأصلية. في الوقت نفسه ، يتوافق التوازن بين الفئات في مجموعة البيانات الجديدة مع رصيدها في بيانات المصدر.
يتم تنفيذ جميع الإجراءات المذكورة أعلاه في وظيفة واحدة ، والتي تسمى
Prepar_data ؛ يمكن العثور على هذه الوظيفة في ملف
utils.py Python. تقوم هذه الوظيفة بتحميل البيانات وتقسيمها إلى مجموعات تدريب واختبار باستخدام رقم عشوائي ثابت (للتشغيل لاحقًا) ، ثم توزيع البيانات وفقًا لذلك بين الدلائل الموجودة على محرك الأقراص الثابتة لاستخدامها لاحقًا.
المعالجة والمعقم
في إحدى المقالات السابقة ، تم وصف إجراءات ما قبل المعالجة والأسباب المحتملة لاستخدامها في شكل زيادة البيانات. الشبكات العصبية التلافيفية نماذج معقدة للغاية ، وهناك حاجة إلى كميات كبيرة من البيانات لتدريبها. في حالتنا ، هناك 1600 مثال فقط - وهذا بالطبع لا يكفي.
لذلك ، نريد توسيع مجموعة البيانات التي تستخدمها
زيادة البيانات. وفقًا للمعلومات الواردة في المقالة الخاصة بمعالجة البيانات مسبقًا ، توفر مكتبة Keras * القدرة على زيادة البيانات أثناء التنقل عند قراءتها من محرك الأقراص الثابتة. يمكن القيام بذلك من خلال فئة
ImageDataGenerator .
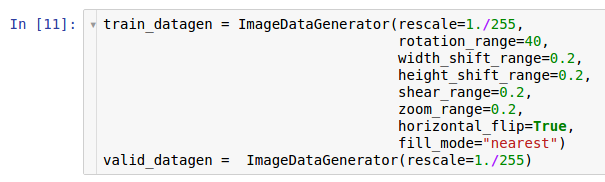
يتم إنشاء مثيلين من المولدات هنا. المثال الأول هو التدريب ويستخدم العديد من التحولات العشوائية - مثل التدوير ، والتحول ، والتواء ، والتحجيم ، والتدوير الأفقي - أثناء قراءة البيانات من القرص ونقلها إلى النموذج. ونتيجة لذلك ، يتلقى النموذج الأمثلة المحولة ، وكل مثال تم استلامه بواسطة النموذج فريد بسبب الطبيعة العشوائية لهذا التحويل. النسخة الثانية هي للتحقق ، وهي تقوم فقط بتكبير الصور. مولدات التعلم والاختبار لديها تحول واحد مشترك فقط - التكبير. لضمان الاستقرار الحسابي للنموذج ، من الضروري استخدام النطاق [0 ؛ 1] بدلاً من [0 ؛ 255].
معمارية النموذج
بعد دراسة البيانات الأولية وإعدادها ، تليها مرحلة إنشاء النموذج. نظرًا لأن كمية صغيرة من البيانات متاحة لنا ، سنقوم ببناء نموذج بسيط نسبيًا حتى نتمكن من تدريبه بشكل مناسب والقضاء على حالة الإفراط في التجهيز.
لنجرب بنية نمط
VGG ، ولكن استخدم طبقات وفلاتر أقل.
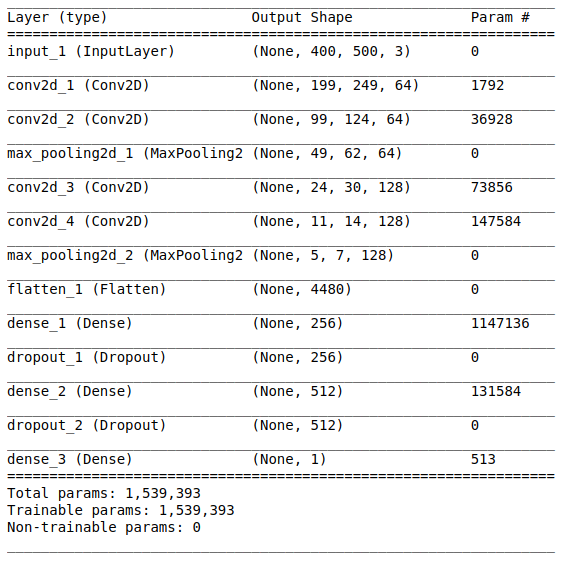

تتكون بنية الشبكة من الأجزاء التالية:
[طبقة الالتفاف + طبقة الالتفاف + اختيار القيمة القصوى] × 2يحتوي الجزء الأول على طبقتين تلافيفيتين متراكبتين مع 64 مرشحًا (بالحجم 3 والخطوة 2) وطبقة لتحديد القيمة القصوى (بالحجم 2 والخطوة 2) تقع بعدهما. يُشار إلى هذا الجزء أيضًا باسم
وحدة استخلاص الميزات ، نظرًا لأن المرشحات تستخرج بكفاءة ميزات ذات معنى من بيانات الإدخال (راجع المقالة
نظرة عامة على الشبكات العصبية التلافيفية لتصنيف الصور لمزيد من المعلومات).
المحاذاةهذا الجزء إلزامي ، حيث يتم الحصول على موترات رباعية الأبعاد عند إخراج الجزء التلافيفي (الأمثلة والارتفاع والعرض والقنوات). ومع ذلك ، بالنسبة للطبقة العادية المتصلة بالكامل ، نحتاج إلى موتر ثنائي الأبعاد (أمثلة ، ميزات) كمدخل. لذلك ، من الضروري
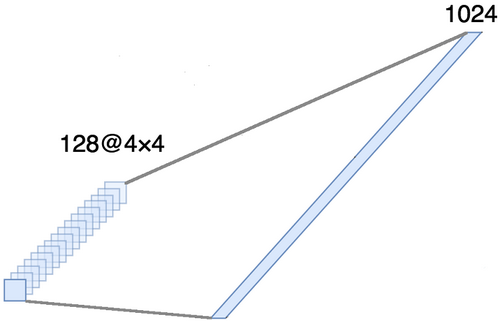
محاذاة الموتر حول المحاور الثلاثة الأخيرة من أجل دمجها في محور واحد. في الواقع ، هذا يعني أننا نعتبر كل نقطة في كل خريطة معلم خاصية منفصلة ونقوم بمحاذاةها في متجه واحد. يوضح الشكل أدناه مثالاً لصورة 4 × 4 مع 128 قناة ، والتي تتم محاذاتها في ناقل ممتد بطول 1024 عنصر.
 [طبقة كاملة + طريقة استبعاد] × 2
[طبقة كاملة + طريقة استبعاد] × 2هنا هو
جزء التصنيف من الشبكة. تأخذ نظرة متناسقة لخصائص الصور وتحاول تصنيفها بأفضل طريقة ممكنة. يتكون هذا الجزء من الشبكة من كتلتين متراكبتين تتكونان من طبقة متصلة بالكامل
وطريقة استبعاد . لقد تعرّفنا بالفعل على طبقات متصلة بالكامل - عادة ما تكون هذه طبقات ذات اتصال متصل بالكامل. ولكن ما هي "طريقة الاستبعاد"؟ طريقة الاستبعاد هي
تقنية تسوية تساعد على منع الإفراط في التجهيز. واحدة من العلامات المحتملة للتضخم الزائد هي قيم مختلفة للغاية لمعاملات الوزن (أوامر من الحجم). هناك العديد من الطرق لحل هذه المشكلة ، بما في ذلك تخفيض الوزن وطريقة التخلص. تتمثل فكرة طريقة الإزالة في فصل الخلايا العصبية العشوائية أثناء التدريب (يجب تحديث قائمة الخلايا العصبية المنفصلة بعد كل فترة حزمة / تدريب). يمنع هذا بشدة الحصول على قيم مختلفة تمامًا لمعاملات الترجيح - بهذه الطريقة يتم تنظيم الشبكة.
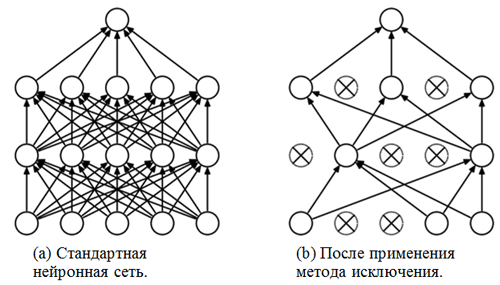
مثال على تطبيق طريقة الاستبعاد (الرقم مأخوذ من المقال
طريقة الاستبعاد: طريقة سهلة لمنع التورط في الشبكات العصبية ):
وحدة سينيةيجب أن تتوافق طبقة الإخراج مع بيان المشكلة. في هذه الحالة ، نحن نتعامل مع مشكلة التصنيف الثنائي ، لذلك ، نحتاج إلى عصبون ناتج واحد مع وظيفة تنشيط
سينية ، والتي تقدر احتمالية P للانتماء إلى الفئة برقم 1 (في حالتنا ، ستكون هذه صورًا إيجابية). ثم يمكن بسهولة حساب احتمال الانتماء إلى الفئة بالرقم 0 (الصور السلبية) على أنه من 1 إلى P.
الإعدادات وخيارات التدريب
لقد اخترنا بنية النموذج وحددناها باستخدام مكتبة Keras للغة Python. بالإضافة إلى ذلك ، قبل البدء في تدريب النموذج ، من الضروري
تجميعه .

في مرحلة التجميع ، يتم ضبط النموذج للتدريب. في هذه الحالة ، يجب تحديد ثلاث معلمات رئيسية:
- المحسن . في هذه الحالة ، نستخدم المُحسِّن الافتراضي Adam * ، وهو نوع من خوارزمية نزول التدرج العشوائي مع لحظة وسرعة تعلم تكيفية (لمزيد من المعلومات ، راجع إدخال المدونة بواسطة S. Ruder نظرة عامة حول خوارزميات تحسين نزول التدرج ).
- دالة الخسارة . مهمتنا هي مشكلة تصنيف ثنائية ، لذلك سيكون من المناسب استخدام الانتروبيا الثنائية الثنائية كدالة خسارة.
- المقاييس . هذه حجة اختيارية يمكنك من خلالها تحديد مقاييس إضافية لتتبعها أثناء عملية التدريب. في هذه الحالة ، نحتاج إلى تتبع الدقة جنبًا إلى جنب مع الوظيفة الموضوعية.
الآن نحن على استعداد لتدريب النموذج. يرجى ملاحظة أن إجراء التدريب يتم باستخدام المولدات التي تمت تهيئتها في القسم السابق.
عدد العصور هو معلمة مفرطة أخرى يمكن تخصيصها. هنا نقوم ببساطة بتعيينها بقيمة 10. ونريد أيضًا حفظ النموذج وسجل التعلم حتى نتمكن من تنزيله لاحقًا.

التقييم
الآن دعونا نرى كيف يعمل نموذجنا بشكل جيد. بادئ ذي بدء ، نحن نعتبر التغيير في المقاييس في عملية التعلم.
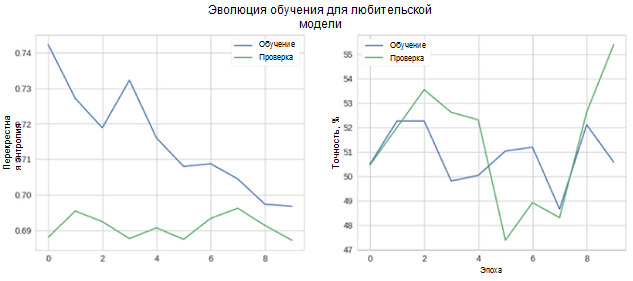
في الشكل ، يمكنك أن ترى أن إنتروبيا التحقق والدقة لا تنقص بمرور الوقت. علاوة على ذلك ، فإن مقياس الدقة لمجموعة التدريب والاختبار يتغير ببساطة حول قيمة المصنف العشوائي. تبلغ الدقة النهائية لمجموعة الاختبار 55 بالمائة ، وهي أفضل قليلاً من التقدير العشوائي.
دعونا نلقي نظرة على كيفية توزيع توقعات النموذج بين الفصول الدراسية. لهذا الغرض ، من الضروري إنشاء وتصور
مصفوفة من عدم الدقة باستخدام الوظيفة المقابلة من حزمة Sklearn * للغة Python.
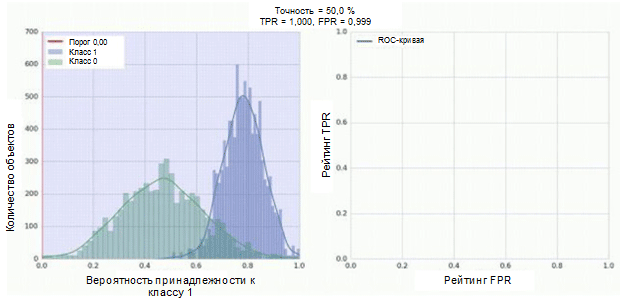
كل خلية في مصفوفة عدم الدقة لها اسمها الخاص:
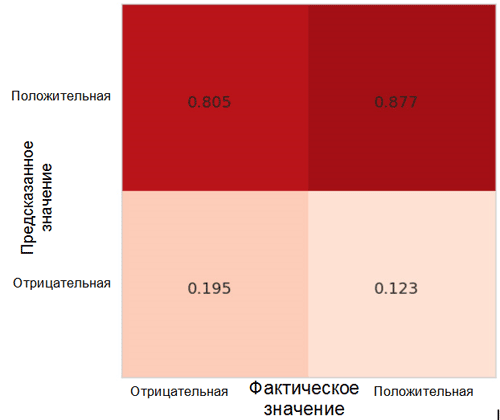
- المعدل الإيجابي الحقيقي = TPR (الخلية العلوية اليمنى) يمثل نسبة الأمثلة الإيجابية (الفئة 1 ، أي العواطف الإيجابية في حالتنا) ، مصنفة بشكل صحيح على أنها إيجابية.
- المعدل الإيجابي الكاذب = FPR (الخلية اليمنى السفلية) يمثل نسبة الأمثلة الإيجابية التي تم تصنيفها بشكل غير صحيح على أنها سلبية (الفئة 0 ، أي المشاعر السلبية).
- يمثل المعدل السلبي الحقيقي = TNR (الخلية اليسرى السفلية) نسبة الأمثلة السلبية التي تم تصنيفها بشكل صحيح على أنها سلبية.
- المعدل السلبي الكاذب = FNR (الخلية العلوية اليسرى) يمثل نسبة الأمثلة السلبية التي تم تصنيفها بشكل غير صحيح على أنها إيجابية.
في حالتنا ، كل من TPR و FPR قريبان من 1. وهذا يعني أنه تم تصنيف جميع الأشياء تقريبًا على أنها إيجابية. وبالتالي ، فإن نموذجنا ليس بعيدًا تمامًا عن النموذج الأساسي الساذج بتنبؤات مستمرة لفئة أكبر (في حالتنا ، هذه صور إيجابية).
مقياس آخر مثير للاهتمام للاهتمام بملاحظة هو منحنى أداء جهاز الاستقبال (منحنى ROC) والمنطقة تحت هذا المنحنى (ROC AUC). يمكن العثور على تعريف رسمي لهذه المفاهيم
هنا . باختصار ، يوضح منحنى ROC مدى جودة عمل المصنف الثنائي.
يحتوي المصنف في شبكتنا العصبية التلافيفية على وحدة سينية كمخرجات ، والتي تعين احتمالية المثال للفئة 1. الآن افترض أن المصنف يظهر عملًا جيدًا ويعين قيم احتمالية منخفضة لأمثلة الفئة 0 (الرسم البياني الأخضر في الشكل أدناه) قيم احتمالية عالية للأمثلة الفئة 1 (الرسم البياني الأزرق).
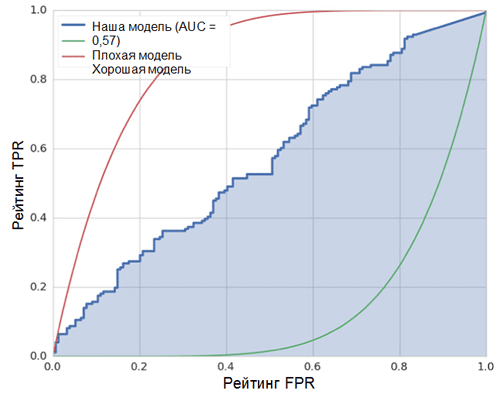
يوضح منحنى ROC كيف يعتمد مؤشر TPR على مؤشر FPR عند تحريك عتبة التصنيف من 0 إلى 1 (الشكل الأيمن ، الجزء العلوي). من أجل فهم أفضل لمفهوم العتبة ، تذكر أن لدينا احتمال الانتماء إلى الفئة 1 لكل مثال. ومع ذلك ، فإن الاحتمال ليس تسمية فئة بعد. لذلك ، يجب مقارنته مع عتبة لتحديد الفئة التي ينتمي إليها المثال. على سبيل المثال ، إذا كانت قيمة العتبة 1 ، فيجب تصنيف جميع الأمثلة على أنها تنتمي إلى الفئة 0 ، حيث لا يمكن أن تكون قيمة الاحتمال أكثر من 1 ، في حين أن قيم مؤشري FPR و TPR ستكون مساوية لـ 0 (نظرًا لعدم تصنيف أي من العينات على أنها موجبة ) يتوافق هذا الموقف مع أقصى نقطة في منحنى ROC. على الجانب الآخر من المنحنى ، هناك نقطة تكون فيها قيمة العتبة 0: وهذا يعني أن جميع العينات مصنفة على أنها تنتمي إلى الفئة 1 ، وقيم كل من TPR و FPR تساوي 1. توضح النقاط الوسيطة سلوك اعتماد TPR / FPR عندما تتغير قيمة العتبة.
الخط القطري على الرسم البياني يقابل المصنف العشوائي. كلما كان المصنف يعمل بشكل أفضل ، كلما كان منحنى أقرب إلى النقطة اليسرى العليا من الرسم البياني. وبالتالي ، فإن المؤشر الموضوعي لجودة المصنف هو المنطقة الواقعة تحت منحنى ROC (مؤشر ROC AUC). يجب أن تكون قيمة هذا المؤشر قريبة قدر الإمكان من 1. تتطابق قيمة AUC 0.5 المصنف العشوائي.
AUC في نموذجنا (انظر الشكل أعلاه) هو 0.57 ، وهو أبعد ما يكون عن أفضل نتيجة.
تشير جميع هذه المقاييس إلى أن النموذج الناتج أفضل قليلاً فقط من المصنف العشوائي. هناك عدة أسباب لذلك ، أهمها موصوف أدناه:
- كمية صغيرة جدًا من البيانات للتدريب ، غير كافية لإبراز السمات المميزة للصور. حتى زيادة البيانات لا يمكن أن تساعد في هذه الحالة.
- نموذج شبكة عصبية تلافيفية معقدة نسبيًا (مقارنة بنماذج التعلم الآلي الأخرى) مع عدد كبير من المعلمات.
الخلاصة
في هذه المقالة ، أنشأنا نموذج شبكة عصبية تلافيفية بسيطة للتعرف على العواطف في الصور. في الوقت نفسه ، في مرحلة التدريب ، تم استخدام عدد من الطرق لزيادة البيانات ، وتم تقييم النموذج أيضًا باستخدام مجموعة من المقاييس مثل الدقة ، ومنحنى ROC ، و ROC AUC ومصفوفة عدم الدقة. أظهر النموذج نتائج ، سوى عدد قليل من أفضل عشوائي. .