مرحبا زملائي.
نأمل أن نبدأ ترجمة كتاب صغير ولكنه
أساسي حقًا حول تنفيذ قدرات الذكاء الاصطناعي في بايثون قبل نهاية أغسطس.

السيد جيفت ، ربما لا يحتاج إلى إعلانات إضافية (للفضول -
ملف تعريف السيد على GitHub):

المقالة التي يتم تقديمها اليوم ستتحدث بإيجاز عن مكتبة راي ، التي تم تطويرها في جامعة كاليفورنيا (بيركلي) والمذكورة في كتاب بطرس الصغير. نأمل أن يكون ذلك بمثابة دعابة مبكرة - ما تحتاجه. مرحبا بك تحت القط
مع تطوير خوارزميات وتقنيات التعلم الآلي ، يجب تشغيل المزيد والمزيد من تطبيقات التعلم الآلي على العديد من الأجهزة في وقت واحد ، ولا يمكن الاستغناء عنها. ومع ذلك ، لا تزال البنية الأساسية لأداء التعلم الآلي على التكتلات موضعية. الآن هناك بالفعل حلول جيدة (على سبيل المثال ، خوادم المعلمات أو البحث عن معلمات مفرطة) وأنظمة موزعة عالية الجودة (على سبيل المثال ، Spark أو Hadoop) ، تم إنشاؤها في الأصل ليس للعمل مع الذكاء الاصطناعي ، ولكن غالبًا ما يقوم الممارسون بإنشاء البنية التحتية لأنظمتهم الموزعة من الصفر. يتم إنفاق الكثير من الجهد الإضافي على هذا.
كمثال ، خذ في الاعتبار خوارزمية بسيطة من الناحية النظرية ، على سبيل المثال ،
الاستراتيجيات التطورية لتعزيز التعلم . على الكود الزائف ، تتناسب هذه الخوارزمية مع حوالي 12 سطرًا ، وتنفيذها في Python أكبر قليلاً. ومع ذلك ، فإن الاستخدام الفعال لهذه الخوارزمية على آلة أو مجموعة أكبر يتطلب هندسة برمجيات أكثر تعقيدًا بشكل ملحوظ. في تنفيذ هذه الخوارزمية من مؤلفي هذه المقالة - الآلاف من أسطر التعليمات البرمجية ، من الضروري تحديد بروتوكولات الاتصال واستراتيجيات تسلسل الرسائل وإلغاء التسلسل ، بالإضافة إلى طرق مختلفة لمعالجة البيانات.
أحد أهداف
Ray هو مساعدة الممارس على تحويل خوارزمية النموذج الأولي التي تعمل على الكمبيوتر المحمول إلى تطبيق موزع عالي الأداء يعمل بكفاءة على مجموعة (أو على جهاز واحد متعدد النواة) عن طريق إضافة عدد قليل نسبيًا من أسطر التعليمات البرمجية. من حيث الأداء ، يجب أن يتمتع مثل هذا الإطار بجميع مزايا النظام المحسن يدويًا ولا يتطلب من المستخدم التفكير في الجدولة ونقل البيانات وتعطل الجهاز.
إطار AI مجانيالارتباط بأطر التعلم العميق الأخرى : يتوافق راي تمامًا مع أطر التعلم العميق مثل TensorFlow و PyTorch و MXNet ، لذلك من الطبيعي تمامًا في العديد من التطبيقات استخدام واحد أو أكثر من أطر التعلم العميق الأخرى مع Ray (على سبيل المثال ، في مكتبات التعلم المعززة لدينا بنشاط تطبيق TensorFlow و PyTorch).
التواصل مع الأنظمة الموزعة الأخرى : اليوم ، يتم استخدام العديد من الأنظمة الموزعة الشائعة ، ومع ذلك ، فقد تم تصميم معظمها دون مراعاة المهام المرتبطة بالذكاء الاصطناعي ، وبالتالي ليس لديهم الأداء المطلوب لدعم الذكاء الاصطناعي وليس لديهم واجهة برمجة تطبيقات للتعبير عن الجوانب المطبقة للذكاء الاصطناعي. في الأنظمة الموزعة الحديثة لا توجد (ضرورية ، اعتمادًا على النظام) مثل هذه الميزات الضرورية:
- دعم المهام على مستوى مللي ثانية ودعم ملايين المهام في الثانية
- التوازي المتداخل (موازاة المهام داخل المهام ، على سبيل المثال ، المحاكاة المتوازية عند البحث عن معلمات مفرطة) (انظر الشكل التالي)
- التبعيات التعسفية بين المهام ، ديناميكيًا أثناء التنفيذ (على سبيل المثال ، عدم الاضطرار إلى الانتظار ، والتكيف مع سرعة العمال البطيئين)
- المهام التي تعمل على حالة متغيرة مشتركة (على سبيل المثال ، الأوزان في الشبكات العصبية أو جهاز محاكاة)
- دعم الموارد غير المتجانسة (CPU ، GPU ، إلخ.)
 مثال بسيط على التزامن المتداخل. في تطبيقنا ، يتم إجراء تجربتين بالتوازي (كل منهما مهمة طويلة الأمد) ، وفي كل تجربة يتم محاكاة العديد من العمليات المتوازية (كل عملية هي أيضًا مهمة).
مثال بسيط على التزامن المتداخل. في تطبيقنا ، يتم إجراء تجربتين بالتوازي (كل منهما مهمة طويلة الأمد) ، وفي كل تجربة يتم محاكاة العديد من العمليات المتوازية (كل عملية هي أيضًا مهمة).هناك طريقتان رئيسيتان لاستخدام Ray: من خلال واجهات برمجة التطبيقات ذات المستوى المنخفض ومن خلال المكتبات عالية المستوى. تم بناء المكتبات عالية المستوى فوق واجهات برمجة التطبيقات منخفضة المستوى. تتضمن هذه حاليًا
Ray RLlib (مكتبة قابلة للتطوير للتعلم
التعزيزي ) و
Ray.tune ، مكتبة فعالة للبحث الموزع عن
المعلمات المفرطة.
Ray Low Level APIsالغرض من Ray API هو تقديم تعبير طبيعي عن الأنماط والتطبيقات الحسابية الأكثر شيوعًا ، دون أن يقتصر على أنماط ثابتة مثل MapReduce.
الرسوم البيانية للمهام الديناميكيةالبدائي الأساسي في تطبيق (المهمة) راي هو رسم بياني للمهام الديناميكية. إنه مختلف تمامًا عن الرسم البياني الحسابي في TensorFlow. بينما في TensorFlow ، يمثل الرسم البياني الحسابي شبكة عصبية ويتم تنفيذه عدة مرات في كل تطبيق منفصل ، في Ray يتوافق الرسم البياني للمهمة مع التطبيق بالكامل ويتم تنفيذه مرة واحدة فقط. الرسم البياني للمهمة غير معروف مسبقًا. يتم إنشاؤه ديناميكيًا أثناء تشغيل التطبيق ، ويمكن أن يؤدي تنفيذ مهمة واحدة إلى تنفيذ العديد من المهام الأخرى.
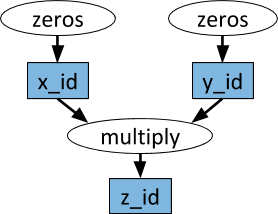 مثال على الرسم البياني الحسابي. في الأشكال البيضاوية البيضاء ، يتم عرض المهام ، وفي المستطيلات الزرقاء - الأشياء. تشير الأسهم إلى أن بعض المهام تعتمد على الكائنات ، بينما يقوم البعض الآخر بإنشاء الكائنات.
مثال على الرسم البياني الحسابي. في الأشكال البيضاوية البيضاء ، يتم عرض المهام ، وفي المستطيلات الزرقاء - الأشياء. تشير الأسهم إلى أن بعض المهام تعتمد على الكائنات ، بينما يقوم البعض الآخر بإنشاء الكائنات.يمكن تنفيذ وظائف Python التعسفية كمهام ، وبأي ترتيب قد تعتمد على إخراج المهام الأخرى. انظر المثال أدناه.
الفاعلونبمساعدة الوظائف عن بعد وحدها ومعالجة المهام أعلاه ، من المستحيل تحقيق العديد من المهام في وقت واحد على نفس الحالة المشتركة القابلة للتغيير. تنشأ مثل هذه المشكلة في التعلم الآلي في سياقات مختلفة ، حيث يمكن مشاركة حالة المحاكي أو الأوزان في الشبكة العصبية أو شيء مختلف تمامًا. يستخدم تجريد الممثل في Ray لتغليف حالة قابلة للتغيير مشتركة بين العديد من المهام. فيما يلي مثال توضيحي يوضح كيفية القيام بذلك باستخدام محاكي Atari.
import gym @ray.remote class Simulator(object): def __init__(self): self.env = gym.make("Pong-v0") self.env.reset() def step(self, action): return self.env.step(action)
على الرغم من بساطته ، فإن الممثل مرن للغاية في الاستخدام. على سبيل المثال ، يمكن تغليف جهاز محاكاة أو سياسة شبكة عصبية في ممثل ، ويمكن أيضًا استخدامه للتدريب الموزع (مثل خادم المعلمات) أو لتوفير سياسات في تطبيق "مباشر".
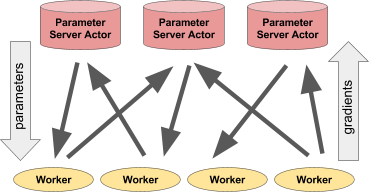 اليسار: يعطي الممثل توقعات / إجراءات لعدد من عمليات العميل. على اليمين: يقوم العديد من الممثلين لخادم المعلمات بإجراء تدريب موزع على العديد من سير العمل.مثال لخادم المعلمات
اليسار: يعطي الممثل توقعات / إجراءات لعدد من عمليات العميل. على اليمين: يقوم العديد من الممثلين لخادم المعلمات بإجراء تدريب موزع على العديد من سير العمل.مثال لخادم المعلماتيمكن تنفيذ خادم المعلمات كممثل راي على النحو التالي:
@ray.remote class ParameterServer(object): def __init__(self, keys, values): # , . values = [value.copy() for value in values] self.parameters = dict(zip(keys, values)) def get(self, keys): return [self.parameters[key] for key in keys] def update(self, keys, values): # , # for key, value in zip(keys, values): self.parameters[key] += value
هنا
مثال أكمل .
لإنشاء خادم معلمة ، نقوم بذلك.
parameter_server = ParameterServer.remote(initial_keys, initial_values)
لإنشاء أربعة عمال لفترة طويلة ، واستخراج وتحديث المعلمات باستمرار ، سنفعل ذلك.
@ray.remote def worker_task(parameter_server): while True: keys = ['key1', 'key2', 'key3'] # values = ray.get(parameter_server.get.remote(keys)) # updates = … # parameter_server.update.remote(keys, updates) # 4 for _ in range(4): worker_task.remote(parameter_server)
مكتبات راي عالية المستوىRay RLlib هي مكتبة تعلم تعزيز قابلة للتطوير مصممة للاستخدام على أجهزة متعددة. يمكن تمكينه باستخدام البرامج النصية التدريبية المقدمة كمثال ، وكذلك من خلال Pytho API. يتضمن حاليًا تطبيقات الخوارزميات:
- A3C
- دقن
- الاستراتيجيات التطورية
- PPO
العمل جار على تنفيذ خوارزميات أخرى. RLlib متوافق تمامًا مع
صالة الألعاب الرياضية OpenAI .
Ray.tune هي مكتبة فعالة للبحث الموزع
للمعلمات المفرطة. يوفر واجهة برمجة تطبيقات Python للتعلم العميق والتعلم المعزز ومهام أخرى تتطلب الكثير من قوة المعالجة. فيما يلي مثال توضيحي من هذا النوع:
from ray.tune import register_trainable, grid_search, run_experiments
يمكن تصور النتائج الحالية ديناميكيًا باستخدام أدوات خاصة ، على سبيل المثال ، Tensorboard و VisKit من rllab (أو قراءة سجلات JSON مباشرةً). يدعم Ray.tune البحث في الشبكة والبحث العشوائي وخوارزميات التوقف المبكر غير التافهة مثل HyperBand.
المزيد عن راي