 كود المشروع متاح في المستودع.
كود المشروع متاح في المستودع.مقدمة
عندما قرأت أوصاف مظهر الشخصيات في الكتب ، كنت مهتمًا دائمًا بكيفية ظهورهم في الحياة. من الممكن أن نتخيل شخصًا ككل ، لكن وصف التفاصيل الأكثر وضوحًا هو مهمة صعبة ، وتختلف النتائج من شخص لآخر. في كثير من الأحيان لم أكن أتخيل أي شيء سوى وجه ضبابي للغاية للشخصية حتى نهاية العمل. فقط عندما يتحول الكتاب إلى فيلم ، يمتلئ الوجه الباهت بالتفاصيل. على سبيل المثال ، لم أستطع أبدًا أن أتخيل كيف يبدو وجه راشيل من كتاب "
فتاة في القطار ". ولكن عندما خرج الفيلم ، تمكنت من مطابقة وجه Emily Blunt بشخصية Rachel. بالتأكيد ، يستغرق الأشخاص المشاركون في اختيار الممثلين الكثير من الوقت لتصوير الشخصيات في البرنامج النصي بشكل صحيح.
ألهمتني هذه المشكلة ودفعتني لإيجاد حل. بعد ذلك ، بدأت في دراسة الأدب عن التعلم العميق بحثًا عن شيء مماثل. لحسن الحظ ، كانت هناك عدد غير قليل من الدراسات حول تركيب الصور من النص. فيما يلي بعض تلك التي بنيت عليها:
[
تستخدم المشاريع شبكات الخصومة التوليدية ، GSS (شبكة الخصومة التوليدية ، GAN) / تقريبًا. perev. ]
بعد دراسة الأدب ، اخترت بنية مبسطة مقارنة بـ StackGAN ++ ، وتتوافق بشكل جيد مع مشكلتي. في الأقسام التالية ، سأشرح كيفية حل هذه المشكلة ومشاركة النتائج الأولية. سأذكر أيضًا بعض تفاصيل البرمجة والتدريب التي قضيت الكثير من الوقت فيها.
تحليل البيانات
مما لا شك فيه أن أهم جانب من العمل هو البيانات المستخدمة لتدريب النموذج. كما قال البروفيسور أندرو إيون في دوراته في deeplearning.ai: "في مجال التعلم الآلي ، ليس الشخص الذي يمتلك أفضل خوارزمية ، بل هو الذي يمتلك أفضل البيانات." لذلك بدأت بحثي عن مجموعة بيانات على الوجوه ذات الأوصاف النصية الجيدة والغنية والمتنوعة. لقد صادفت مجموعات بيانات مختلفة - سواء كانت مجرد وجوه ، أو وجوه بأسماء ، أو وجوه مع وصف لون العين وشكل الوجه. ولكن لم يكن هناك ما أحتاجه. كان خياري الأخير هو استخدام
مشروع مبكر - إنشاء وصف للبيانات الهيكلية بلغة طبيعية. لكن مثل هذا الخيار سيضيف ضوضاء إضافية لمجموعة بيانات صاخبة بالفعل.
مر الوقت ، وفي مرحلة ما
ظهر مشروع
Face2Text جديد. كانت عبارة عن مجموعة من قاعدة بيانات تحتوي على أوصاف نصية تفصيلية للأشخاص. أشكر مؤلفي المشروع على مجموعة البيانات المقدمة.
احتوت مجموعة البيانات على أوصاف نصية لـ 400 صورة تم اختيارها عشوائيًا من قاعدة بيانات LFW (الوجوه المميزة). تم تنظيف الأوصاف للقضاء على الخصائص الغامضة والثانوية. لا تحتوي بعض الأوصاف على معلومات حول الوجوه فحسب ، بل تتضمن أيضًا بعض الاستنتاجات التي تم التوصل إليها على أساس الصور - على سبيل المثال ، "ربما يكون الشخص الموجود في الصورة مجرمًا" كل هذه العوامل ، بالإضافة إلى صغر حجم مجموعة البيانات ، أدت إلى حقيقة أن مشروعي حتى الآن لا يظهر سوى دليل على قابلية تشغيل الهندسة المعمارية. وبالتالي ، يمكن تحجيم هذا النموذج إلى مجموعة بيانات أكبر وأكثر تنوعًا.
العمارة
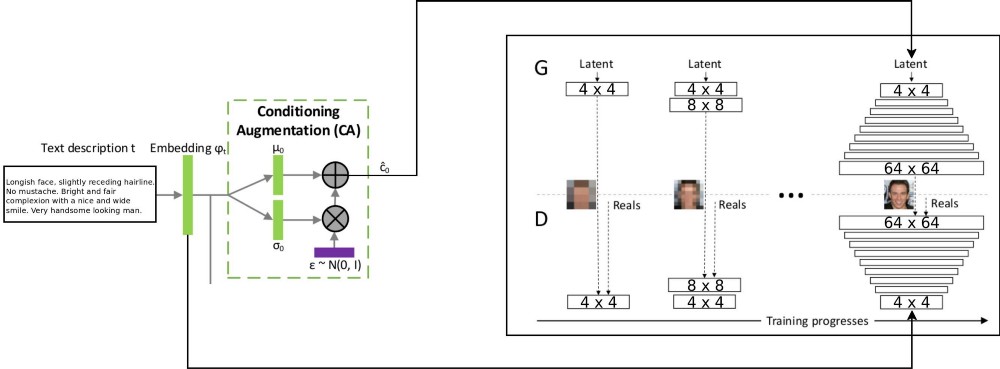
تجمع بنية مشروع T2F بين بنيتين stackGAN لترميز النص المتزايد بشروط ، و ProGAN (
النمو التدريجي لـ GSS ) لتجميع صور الوجه. استخدمت بنية stackgan ++ الأصلية العديد من أنظمة GSS ذات الدقة المكانية المختلفة ، وقررت أن هذا كان نهجًا خطيرًا جدًا لأي مهمة توزيع المراسلات. لكن ProGAN يستخدم GSS واحد فقط ، يتم تدريبه تدريجيًا على قرارات أكثر تفصيلاً. قررت الجمع بين هذين النهجين.
هناك تفسير لتدفق البيانات من خلال: يتم ترميز أوصاف النص في المتجه النهائي عن طريق التضمين في شبكة LSTM (التضمين) (psy_t) (انظر الرسم التخطيطي). بعد ذلك ، يتم إرسال التضمين من خلال كتلة التكييف المعزز (طبقة خطية واحدة) للحصول على جزء النص من المتجه الذاتي (باستخدام تقنية إعادة تأهيل VAE) لـ GSS كمدخل. الجزء الثاني من المتجه الذاتي هو الضوضاء العشوائية الغوسية. يتم تغذية المتجه الذاتي الناتج إلى مولد GSS ، ويتم تغذية التضمين إلى آخر طبقة تمييز للتوزيع المشروط للمراسلات. يذهب تدريب عمليات GSS تمامًا كما هو الحال في المقالة على ProGAN - في الطبقات ، مع زيادة الدقة المكانية. يتم تقديم طبقة جديدة باستخدام تقنية التلاشي لتجنب مسح نتائج التعلم السابقة.
التنفيذ وتفاصيل أخرى
تم كتابة التطبيق في بيثون باستخدام إطار PyTorch. كنت أعمل مع حزم tensorflow و keras ، لكني الآن أردت تجربة PyTorch. أحببت استخدام مصحح أخطاء python المدمج للعمل مع بنية الشبكة - كل ذلك بفضل استراتيجية التنفيذ المبكر. كما قام Tensorflow مؤخرًا بتشغيل وضع التنفيذ المتلهف. ومع ذلك ، لا أريد أن أحكم على أي إطار أفضل ، أريد فقط أن أؤكد أن كود هذا المشروع تمت كتابته باستخدام PyTorch.
يبدو لي أن أجزاء قليلة من المشروع قابلة لإعادة الاستخدام ، وخاصة ProGAN. لذلك ، قمت بكتابة كود منفصل لهم كملحق لوحدة PyTorch ، ويمكن استخدامه في مجموعات بيانات أخرى أيضًا. من الضروري فقط الإشارة إلى عمق وحجم ميزات GSS. يمكن تدريب GSS بشكل تدريجي على أي مجموعة بيانات.
تفاصيل التدريب
لقد دربت عددًا قليلاً من إصدارات الشبكة باستخدام معلمات هايبر مختلفة. تفاصيل العمل هي كما يلي:
- ليس لدى المميّز عمليات على مستوى الدفعة أو الطبقة المعيارية ، لذلك يمكن أن ينمو فقدان WGAN-GP بشكل متفجر. استخدمت عقوبة الانجراف مع لامدا تساوي 0.001.
- للتحكم في تنوعك ، الذي تم الحصول عليه من النص المشفر ، من الضروري استخدام مسافة Kullback - Leibler في خسائر المولد.
- لجعل الصور الناتجة تتطابق بشكل أفضل مع توزيع النص الوارد ، من الأفضل استخدام إصدار WGAN لمميز (Matching-Aware) المقابل.
- يجب أن يتجاوز وقت التلاشي في المستويات العليا وقت التلاشي في المستويات الدنيا. لقد استخدمت 85 ٪ كقيمة تتلاشى عند التدريب.
- لقد وجدت أن الأمثلة عالية الدقة (32 × 32 و 64 × 64) تنتج ضوضاء في الخلفية أكثر من الأمثلة ذات الدقة الأقل. أعتقد أن هذا يرجع إلى نقص البيانات.
- أثناء التمرين التدريجي ، من الأفضل قضاء المزيد من الوقت على درجات دقة أقل ، وتقليل الوقت المستغرق في العمل مع دقة أعلى.
يعرض الفيديو الفاصل الزمني للمولد. تم تجميع الفيديو من الصور ذات الدقة المكانية المختلفة التي تم الحصول عليها أثناء تدريب GSS.
الخلاصة
وفقًا للنتائج الأولية ، يمكن الحكم على أن مشروع T2F قابل للتطبيق ولديه تطبيقات مثيرة للاهتمام. افترض أنه يمكن استخدامه لتأليف فوتوبوتس. أو في الحالات التي يكون فيها من الضروري تعزيز الخيال. سأستمر في العمل على توسيع نطاق هذا المشروع على مجموعات البيانات مثل Flicker8K ، وتسميات Coco ، وما إلى ذلك.
إن النمو التدريجي لنظام GSS هو تقنية استثنائية لتدريب GSS بشكل أسرع وأكثر استقرارًا. يمكن دمجه مع مختلف التقنيات الحديثة المذكورة في مقالات أخرى. يمكن استخدام GSS في مناطق مختلفة من MO.