
اليوم في KDD 2018 هو يوم ندوة - جنبًا إلى جنب مع مؤتمر كبير يبدأ غدًا ، جمعت عدة مجموعات مستمعين حول بعض الموضوعات المحددة. تم إلى طرفين من هذا القبيل.
تحليل السلاسل الزمنية
في الصباح كنت أرغب في الذهاب إلى ندوة حول تحليل
الرسم البياني ، ولكن تم احتجازه لمدة 45 دقيقة ، لذلك انتقلت إلى الحلقة التالية ، حول تحليل السلاسل الزمنية. فجأة ،
افتتح أستاذ شقراء من كاليفورنيا الندوة حول موضوع "الذكاء الاصطناعي في الطب". غريب ، لأنه يوجد مسار منفصل في الغرفة المجاورة. ثم اتضح أن لديها العديد من طلاب الدراسات العليا الذين سيتحدثون عن السلاسل الزمنية هنا. ولكن ، في الواقع ، إلى هذه النقطة.
الذكاء الاصطناعي في الطب
الأخطاء الطبية هي سبب 10٪ من الوفيات في الولايات المتحدة ، وهذا أحد الأسباب الثلاثة الرئيسية للوفاة في البلاد. المشكلة هي أنه لا يوجد عدد كاف من الأطباء. تلك التي تعاني من الحمل الزائد ، والحواسيب من المحتمل أن تخلق مشاكل للأطباء أكثر مما يمكنهم حلها ، على الأقل الأطباء. ومع ذلك ، فإن معظم البيانات لا تُستخدم حقًا في اتخاذ القرار. يجب محاربة كل هذا. على سبيل المثال ، بكتيريا واحدة ،
Clostridium difficile ، شديدة الفوعة ومقاومة للأدوية. خلال العام الماضي ، ألحقت بها خسائر بقيمة 4 مليارات دولار. دعونا نحاول تقييم خطر الإصابة بالعدوى بناءً على التسلسل الزمني للسجلات الطبية. على عكس الأعمال السابقة ، نأخذ الكثير من العلامات (10 آلاف متجه لكل يوم) وسنقوم ببناء نماذج فردية لكل مستشفى (من نواح عديدة ، على ما يبدو ، إجراء ضروري ، حيث أن جميع المستشفيات لديها مجموعة بيانات خاصة بها). ونتيجة لذلك ، نحصل على دقة تبلغ حوالي 0.82 AUC مع تشخيص خطر CDI بعد 5 أيام.
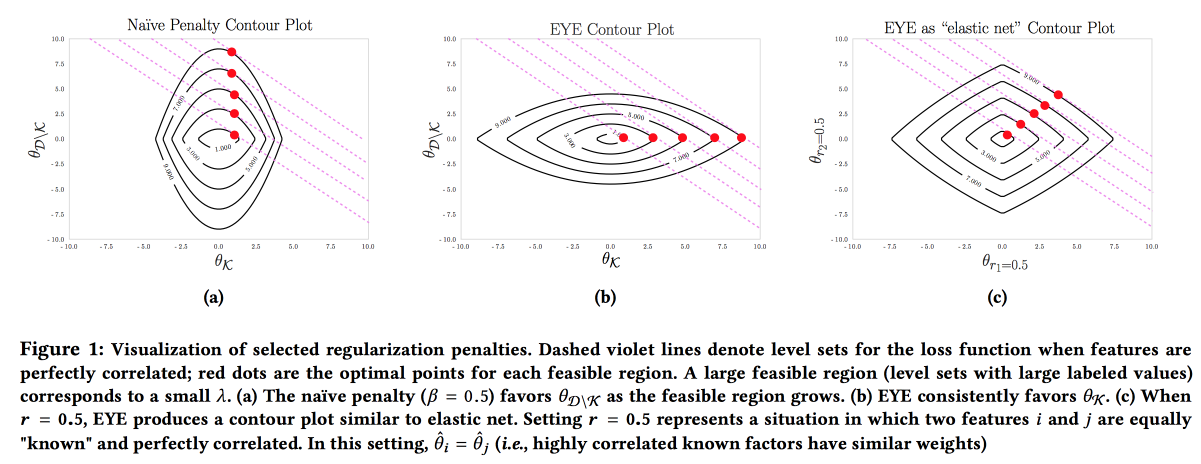
من المهم أن يكون النموذج دقيقًا وقابلًا للتفسير وقويًا ؛ نحتاج إلى إظهار ما يمكننا القيام به لمنع المرض. يمكن بناء مثل هذا النموذج من خلال استخدام المعرفة بنشاط من مجال الموضوع. إنها الرغبة في إمكانية التفسير التي غالبًا ما تقلل من عدد الميزات وتؤدي إلى إنشاء نماذج بسيطة. ولكن حتى النموذج البسيط الذي يحتوي على مساحة كبيرة من الميزات يفقد إمكانية التفسير ، وكثيرًا ما يؤدي استخدام تسوية L1 إلى حقيقة أن النموذج يختار عشوائيًا إحدى الميزات المتداخلة. ونتيجة لذلك ، لا يعتقد الأطباء أن النموذج ، على الرغم من وجود الجامعة الأمريكية بالقاهرة جيدة. يقترح المؤلفون استخدام نوع مختلف من تسوية
العين (تقدير غلة الخبراء). بالنظر إلى ما إذا كانت هناك بيانات معروفة حول التأثير على النتيجة ، فقد اتضح تركيز النموذج على الميزات الضرورية. إنه يعطي نتائج جيدة ، حتى إذا أخطأ الخبير ، علاوة على ذلك ، من خلال مقارنة الجودة مع التسويات القياسية ، يمكنك تقييم مدى صحة الخبير.
بعد ذلك ، ننتقل إلى تحليل السلاسل الزمنية. اتضح أنه من أجل تحسين الجودة فيها ، من المهم البحث عن الثوابت (في الواقع - يؤدي إلى بعض الشكل القانوني). في
مقالة حديثة ، اقترحت مجموعة من الأساتذة نهجًا قائمًا على شبكتين تلافيفيتين. الأول ، Sequence Transformer ، يجلب السلسلة إلى شكل قانوني ، والثاني ، Sequence Decoder ، يحل مشكلة التصنيف.
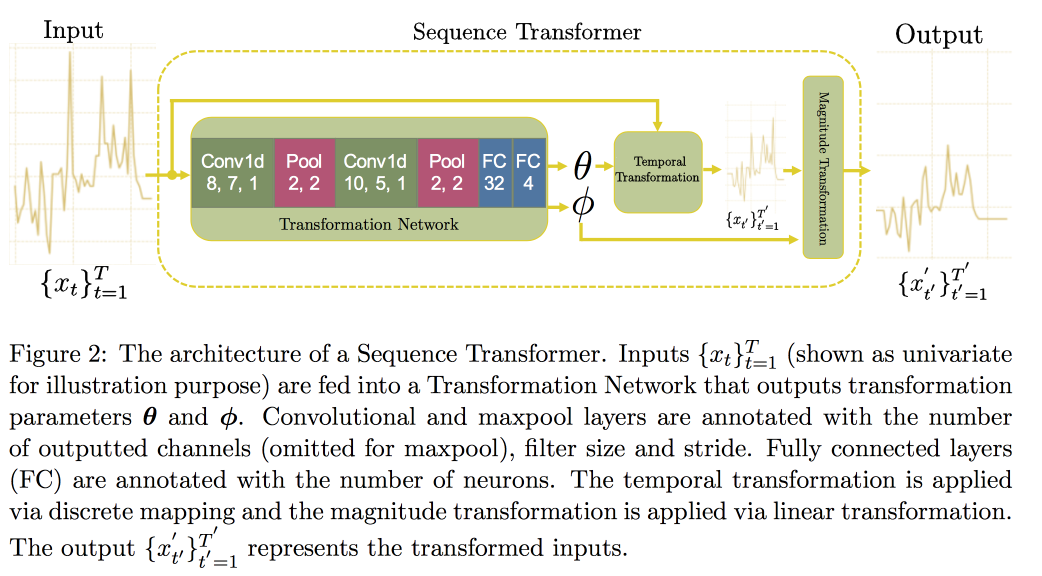
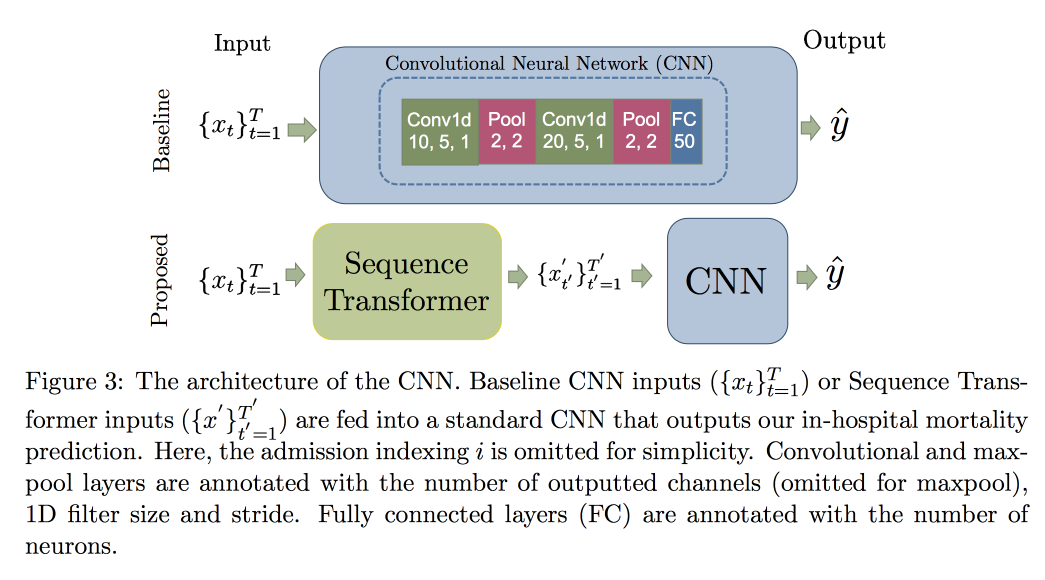
يتم تفسير استخدام CNN ، بدلاً من RNN ، بحقيقة أنها تعمل مع صفوف ذات طول ثابت. فحص في
مجموعة بيانات MIMIC ، حاول التنبؤ بالموت في المستشفى في غضون 48 ساعة. وكانت النتيجة تحسنًا بنسبة 0.02 AUC مقارنةً بـ CNN العادي مع طبقات إضافية ، ولكن فواصل الثقة تتداخل.
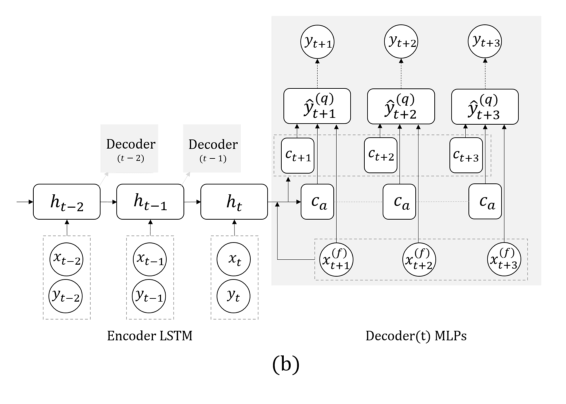
الآن مهمة أخرى: سوف نتوقع فقط على أساس السلسلة الفعلية ، بدون إشارات خارجية (التي أكلت ، وما إلى ذلك). هنا ، اقترح الفريق استبدال RNN للتنبؤ ببضع خطوات إلى الأمام بشبكة ذات مخرجات عديدة ، دون تكرارها. تفسير هذا الحل هو أن الخطأ لا يتراكم أثناء العودية. ادمج هذه التقنية مع التقنية السابقة (ابحث عن الثوابت). مباشرة بعد عرض الأستاذ ، تحدث الدكتوراه بالتفصيل حول هذا النموذج ، لذلك ننتهي هنا ، مشيرين فقط إلى أنه عند التحقق من الصحة ، من المهم النظر ليس فقط إلى الخطأ العام ، ولكن أيضًا إلى خطأ التصنيف للحالات الخطيرة ذات الجلوكوز المرتفع أو المنخفض للغاية.
طرحت سؤالا حول ردود الفعل من النموذج: في حين أن هذا سؤال مفتوح مؤلم ، يقولون أنه يجب أن نحاول أن نفهم أي تغييرات في توزيع الأعراض تحدث نتيجة لحقيقة التدخل ، وما هي التحولات الطبيعية التي تسببها العوامل الخارجية. في الواقع ، إن وجود مثل هذه التحولات يعقد الوضع بشكل كبير: من المستحيل إعادة تدريب النموذج ، حيث أن الجودة مهينة ، والاختلاط بشكل عشوائي (عدم معالجة شخص ما والتحقق من موته) ليس أخلاقيًا ، ولكن التعلم من البيانات حيث تم التعامل مع الجميع وفقًا لتوصية النموذج مضمون التحيز ...
توليد مسار العينة
مثال على كيفية عدم تقديم العروض التقديمية: يكاد يكون من المستحيل تقريبًا سريعًا جدًا ، ومن الصعب حتى سماعه ، واستيعاب الفكرة. العمل نفسه متاح
هنا .
طور الرجال نتيجة توقعاتهم السابقة عدة خطوات إلى الأمام. هناك فكرتان رئيسيتان في العمل السابق: بدلاً من RNN ، استخدم شبكة ذات مخرجات متعددة لنقاط مختلفة في الوقت المناسب ، بالإضافة إلى أرقام محددة نحاول التنبؤ بالتوزيعات وتقييم الكميات. كل هذا يسمى
MQ-RNN / CNN (الانحدار الكمي متعدد التنبؤات).
هذه المرة حاولنا تحسين التوقعات باستخدام المعالجة اللاحقة. يعتبر نهجين. كجزء من الأول ، نحن نحاول "معايرة" توزيع الشبكة العصبية باستخدام البيانات الخلفية وتعلم مصفوفة التغاير للمخرجات والملاحظات ، ما يسمى انكماش التغاير. الطريقة بسيطة وعملية ، لكني أريد المزيد. كان النهج الثاني هو استخدام النماذج التوليدية لبناء "عينة مسار": يستخدمون النهج التوليدي للتنبؤ (GAN، VAE). تم الحصول على نتائج جيدة ، ولكن غير مستقرة بمساعدة
WaveNet ، التي تم تطويرها
لتوليد الصوت.
شبكات الرسم البياني المنظمة
عمل مثير للاهتمام حول نقل "معرفة مجال الموضوع" في الشبكة العصبية. أظهروا على سبيل المثال التنبؤ بمستوى الجريمة في الفضاء (حسب مناطق المدينة) والوقت (بالأيام والساعات). الصعوبة الرئيسية: بيانات متفرقة قوية ووجود أحداث محلية نادرة. ونتيجة لذلك ، لا تعمل العديد من الطرق بشكل جيد ، في المتوسط لا يزال من الممكن تخمينها على أساس يومي ، ولكن ليس في مناطق وساعات محددة. دعونا نحاول الجمع بين بنية عالية المستوى ومتناهية الصغر في شبكة عصبية واحدة.
نحن نبني رسمًا بيانيًا للتواصل باستخدام الرموز البريدية ونحدد تأثير أحدهما على الآخر باستخدام
عملية هوكس متعددة المتغيرات . بعد ذلك ، على أساس الرسم البياني الذي تم الحصول عليه ، نقوم ببناء طبولوجيا الشبكة العصبية ، وربط كتل مناطق المدينة بجريمة أظهرت ارتباطًا.
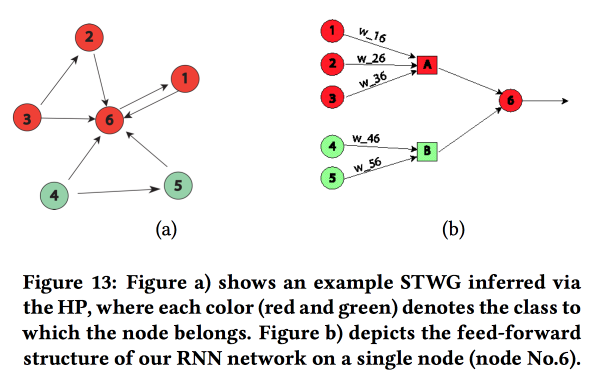
قارنا هذا النهج مع اثنين آخرين: التدريب على شبكة لمنطقة أو على شبكة لمجموعة من المناطق ذات معدل الجريمة مماثلة ، أظهر زيادة في الدقة. لكل منطقة ، يتم تقديم LSTM من طبقتين مع طبقتين متصلتين بالكامل.
بالإضافة إلى الجرائم ، أظهروا أيضًا أمثلة على العمل في التنبؤ بالمرور. هنا ، تم بالفعل رسم الرسم البياني لبناء شبكة جغرافيًا بواسطة kNN. ليس من الواضح تمامًا إلى أي مدى يمكن مقارنة نتائجهم بالنتائج الأخرى (لقد غيروا المقاييس في التحليل بحرية) ، ولكن بشكل عام ، يبدو الاستدلال لبناء شبكة مناسبًا.
النهج اللامعلمي للتنبؤ الجماعي
تعتبر المجموعات موضوعًا شائعًا جدًا ، لكن كيفية استخلاص النتيجة من التوقعات الفردية ليست دائمًا واضحة. في عملهم ، يقترح المؤلفون
نهجا جديدا .
غالبًا ما تعمل المجموعات البسيطة بشكل جيد ، بل إنها أفضل. من
متوسط نموذج بايزي الجديد والمتوسط - NN. كما أن الانحدار ليس سيئًا ، ولكنه غالبًا ما يعطي نتائج غريبة من حيث اختيار الأوزان (على سبيل المثال ، سيعطي بعض التوقعات وزنًا سلبيًا ، وما إلى ذلك). في الواقع ، غالبًا ما يكمن سبب ذلك في حقيقة أن طريقة التجميع تستخدم بعض الافتراضات حول كيفية توزيع الخطأ المتوقع (على سبيل المثال ، وفقًا لغاوس أو العادي) ، ولكن عند استخدامه ، ينسون التحقق من هذا الافتراض. حاول المؤلفون اقتراح نهج خالي من الافتراضات.
نعتبر عمليتين عشوائيتين: نماذج نماذج عملية توليد البيانات (DGP) الواقعية ويمكن أن تعتمد على الوقت ، ونماذج عملية توليد التوقعات (FGP) بناء التوقعات (هناك الكثير منها - واحد لكل عضو في المجموعة). الفرق بين هاتين العمليتين هو أيضًا عملية عشوائية ، سنحاول تحليلها.
- نجمع البيانات التاريخية وننشئ كثافة توزيع الأخطاء للمنبئات باستخدام تقدير كثافة النواة.
- بعد ذلك ، نقوم ببناء توقعات وتحويلها إلى متغير عشوائي عن طريق إضافة الخطأ الذي تم إنشاؤه.
- ثم نحل مشكلة تعظيم الاحتمالية.
تشبه الطريقة الناتجة EMOS تقريبًا (إحصائيات إخراج نموذج المجموعة) مع وجود خطأ غوسي وأفضل بكثير مع غير غوسي. غالبًا في الواقع ، على سبيل المثال ، (
مجموعة بيانات حركة مرور صفحة Wikipedia ) خطأ غير غوسي.
LSTM المتداخل: تصنيف النمذجة والديناميكيات الزمنية في الشبكة الاجتماعية القائمة على الموقع
تم تقديم العمل من قبل مؤلفين من Google. نحن نحاول التنبؤ بشيك المستخدم التالي. باستخدام تاريخه الحديث عن الصفائح الفوقية والبيانات الوصفية للأماكن ، أولاً وقبل كل شيء ، علاقتها بالعلامات / الفئات. الفئات من ثلاثة مستويات ، نستخدم المستويين العلويين: الفئة الرئيسية تصف نية المستخدم (على سبيل المثال ، الرغبة في تناول الطعام) ، وتصف الفئة الفرعية تفضيلات المستخدم (على سبيل المثال ، يحب المستخدم الطعام الإسباني). يجب إظهار الفئة الفرعية للشيك التالي للحصول على مزيد من الدخل من الإعلانات عبر الإنترنت.
نستخدم اثنين من LSTMs المتداخلة: الجزء العلوي ، كالمعتاد ، وفقًا لتسلسل الفحوصات ، والتداخل - وفقًا للتحولات في شجرة الفئة من الوالد إلى الطفل.
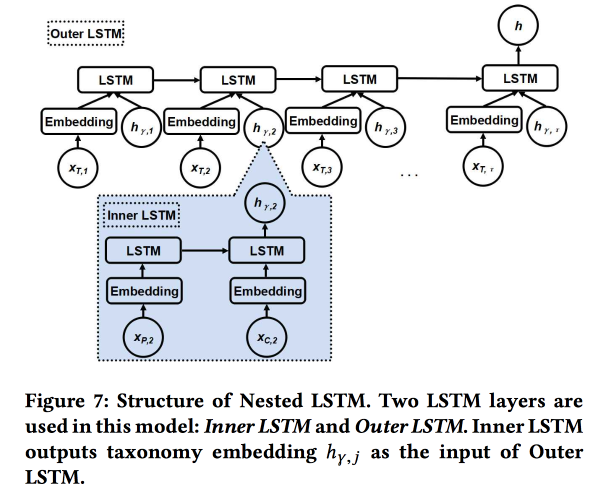
وتبين أنه أفضل بنسبة 5-7٪ مقارنة بـ LSTM البسيط مع تضمين فئة خام. بالإضافة إلى ذلك ، أظهرنا أن تقاطعات الانتقال LSTM في شجرة الفئة تبدو أكثر جمالا من تلك البسيطة ، وهي أكثر تجمعا.
تحديد التحولات في الفضاء الدلالي التطوري
خطاب مرح من
الأستاذ الصيني . خلاصة القول هي محاولة فهم كيفية تغيير الكلمات لمعانيها.
الآن الجميع يدربون بنجاح عمليات تضمين الكلمات ، فهم يعملون بشكل جيد ، ولكن التدريب في أوقات مختلفة ليس مناسبًا للمقارنة - عليك أن تفعل كل شيء.
- يمكنك أخذ القديم للتهيئة ، ولكن هذا لا يعطي ضمانات.
- يمكنك معرفة وظيفة التحويل من أجل allining ، لكنها لا تعمل دائمًا ، حيث لا يتم دائمًا مشاركة الأبعاد بالتساوي.
- ويمكنك استخدام الفضاء الطوبولوجي ، وليس الفضاء المتجه!
في النهاية ، جوهر الحل: نقوم ببناء رسم بياني knNN في جيران الكلمة في فترات مختلفة لتقييم التغيير في المعنى ، ومحاولة فهم ما إذا كان هناك تغيير كبير. لهذا نستخدم نموذج
Bayesian Surprise . في الواقع ، نحن ننظر إلى
اختلاف KL لتوزيع الفرضية (السابقة) والفرضية الخاضعة للملاحظات (الخلفية) - هذه مفاجأة. باستخدام الكلمات والرسوم البيانية cnn ، نستخدم Dirichlet استنادًا إلى ترددات الجيران في الماضي كتوزيع مسبق ونقارنه بالمتعدد الحقيقي الحقيقي في التاريخ الحديث. المجموع:
- قطعنا القصة.
- نحن نبني التضمينات (LINE مع الحفاظ على التهيئة).
- نعتبر KNN على التضمينات.
- نقدر المفاجأة.
نحن نتحقق من خلال أخذ كلمتين عشوائيتين بنفس التردد ، ونتبادل بعضنا البعض - الزيادة في الجودة كمفاجأة هي 80٪. ثم نأخذ 21 كلمة مع انحرافات المعنى المعروفة ونرى ما إذا كان بإمكاننا العثور عليها تلقائيًا. لا تحتوي المصادر المفتوحة بعد على وصف مفصل لهذا النهج ، ولكن
هناك واحد في SIGIR 2018 .
AdKDD و TargetAd
بعد الغداء ، انتقلت إلى ندوة حول الإعلان عبر الإنترنت. هناك العديد من المتحدثين من الصناعة ويفكر الجميع في كيفية كسب المزيد من المال.
تقنية الإعلان على airbnb
كونها شركة كبيرة مع فريق DS كبير ، تستثمر AirBnB كثيرًا في الترويج لنفسها وعروضها الداخلية بشكل صحيح على المواقع الخارجية. تحدث أحد المطورين قليلاً عن التحديات.
لنبدأ بالإعلان في محرك البحث: عند البحث عن الفنادق على Google ، يتم الإعلان عن أول صفحتين :(. لكن المستخدم غالبًا لا يفهم هذا ، لأن الإعلان وثيق الصلة للغاية. المخطط القياسي: نطابق طلبات الإعلان بالكلمات الرئيسية ونحصل على معنى النمط / النمط ( مدينة ، رخيصة أو فاخرة ، إلخ.)
بعد اختيار المرشحين ، نرتب مزادًا بينهم (يتم الآن استخدام
السعر الثاني المعمم في كل مكان). عند المشاركة في المزاد ، فإن الهدف هو زيادة التأثير إلى أقصى حد على ميزانية ثابتة ، باستخدام نموذج يحتوي على مزيج من احتمال النقرة والدخل: Bid = P (click | search search) * قيمة الحجز. نقطة مهمة: لا تنفق كل الأموال بسرعة كبيرة ، لذا أضف Spend pacer.
يمتلك AirBnB نظامًا قويًا لاختبارات A / B ، ولكن لا يمكن تطبيقه هنا ، حيث إنه يتحكم في معظم عمليات Google. هناك وعدوا بإضافة المزيد من الأدوات للمعلنين ، ويتطلع اللاعبون الكبار حقًا إلى الأمام.
مشكلة منفصلة: اتصال المستخدم بالإعلان في عدة أماكن. نسافر في المتوسط بضع مرات في السنة ، ودورة التحضير للرحلة والحجز طويلة جدًا (أسابيع وحتى أشهر) ، وهناك العديد من القنوات حيث يمكننا الوصول إلى المستخدم ، ونحتاج إلى تقسيم الميزانية حسب القناة. هذا الموضوع مؤلم للغاية ، هناك طرق بسيطة (خطيا ، بعناية ، من خلال النقرة الأخيرة أو نتائج
اختبار الرفع ). جربت AirBnB نهجين جديدين: بناءً على نماذج ماركوف
ونموذج شابلي .
مع نموذج ماركوف ، كل شيء أكثر أو أقل وضوحًا: نحن نبني سلسلة منفصلة ، العقد التي تتوافق مع نقاط الاتصال بالإعلان ، هناك أيضًا عقدة للتحويل. وفقًا للبيانات ، نختار أوزانًا للتحولات ، ونعطي ميزانية أكبر لتلك العقد حيث يكون احتمال الانتقال أكبر. طرحت عليهم سؤالًا: لماذا نستخدم سلسلة ماركوف البسيطة ، بينما من المنطقي استخدام MDP ؛ قالوا أنهم يعملون على هذا الموضوع.
إنه أكثر إثارة للاهتمام مع Shapley: في الواقع ، هذا مخطط معروف منذ فترة طويلة لتقييم التأثير الإضافي ، حيث يتم النظر في مجموعات مختلفة من التأثيرات ، ويتم تقييم تأثير كل منها ، ثم يتم تحديد إجمالي معين لكل تأثير فردي. تكمن الصعوبة في أنه يمكن أن يكون هناك تآزر بين الآثار (أقل تعارضًا في الغالب) ، وأن نتيجة المجموع لا تساوي مجموع النتائج. بشكل عام ، نظرية مثيرة للاهتمام وجميلة إلى حد ما ،
أنصحك بالقراءة .
في حالة AirBnB ، يبدو تطبيق نموذج Shapley مشابهًا لما يلي:
- لدينا في أمثلة البيانات المرصودة مع مجموعات مختلفة من الآثار والنتيجة الفعلية.
- املأ الفجوات في البيانات (لا يتم عرض جميع المجموعات) باستخدام ML.
- نحسب القرض لكل نوع من تأثير Shapley.
Microsoft: دفع حدود {AI}
علاوة على ذلك قليلا عن ذلك. حيث تعمل Microsoft في مجال الإعلان ، الآن من جانب الموقع ، وبشكل أساسي Bing. قليل من الذبح:
- ينمو سوق الإعلانات بسرعة كبيرة (بشكل أسي).
- الإعلان على صفحة واحدة يأكل بعضها البعض ، تحتاج إلى تحليل الصفحة بأكملها.
- يكون التحويل في بعض الصفحات أعلى ، على الرغم من حقيقة أن برنامج التحويلات النقدية أسوأ.
هناك حوالي 70 طرازًا في محرك إعلانات Bing ، 2000 تجربة دون اتصال بالإنترنت ، 400 تجربة عبر الإنترنت. تغيير واحد كبير في النظام الأساسي كل أسبوع. بشكل عام ، يعملون بلا كلل. ما هي التغييرات في النظام الأساسي:
- خرافة مقياس واحد: لا يعمل بهذه الطريقة ، تنمو المقاييس وتتنافس.
- لقد قمنا بإعادة تصميم نظام طلبات المطابقة الإعلانية من البرمجة اللغوية العصبية إلى DL ، والذي يتم حسابه على FPGA.
- يستخدمون النماذج الفيدرالية وقطاع الطرق السياقية: النماذج الداخلية تنتج الاحتمالية وعدم اليقين ، اللصوص من الأعلى يتخذ قرارًا. تحدثت كثيرًا عن قطاع الطرق ، يتم استخدامها لإطلاق النماذج والإطلاق بسرعة الإبحار ، فهم يتحايلون على حقيقة أن تحسين النموذج غالبًا ما يؤدي إلى انخفاض الدخل :(
- من المهم جدًا تقييم حالة عدم اليقين (حسنًا ، نعم ، بدونها لا يمكنك بناء قطاع طرق).
- بالنسبة للمعلنين الصغار ، لا تعمل مؤسسة الإعلان من خلال قطاع الطرق ، وهناك القليل من الإحصائيات ، فمن الضروري إنشاء نماذج منفصلة لبداية باردة.
- من المهم مراقبة الأداء على مجموعات مختلفة من المستخدمين ، فلديهم نظام أوتوماتيكي للتقطيع وفقًا لنتائج التجربة.
تحدثنا قليلاً عن تحليل التدفق. ليست دائمًا فرضيات البائعين حول أسباب التدفق الخارجي صحيحة ، فأنت بحاجة إلى التعمق أكثر. للقيام بذلك ، عليك بناء نماذج قابلة للتفسير (أو نموذج خاص لشرح التوقعات) والتفكير كثيرًا. ثم قم بالتجارب. ولكن من الصعب دائمًا إجراء تجارب مع التدفق ، يوصون باستخدام مقاييس من الدرجة الثانية
ومقال من Google .
يستخدمون أيضًا شيء مثل الرسم البياني المعرفي التجاري ، الذي يصف مجال الموضوع: العلامات التجارية والمنتجات وما إلى ذلك. تم إنشاء الرسم البياني بالكامل تلقائيًا ، بدون إشراف. يتم تمييز العلامات التجارية بفئات ، وهذا أمر مهم ، لأنه بشكل عام ليس من الممكن دائمًا عدم الإشراف لعزل العلامة التجارية ككل ، ولكن في موضوع فئة معينة ، تكون الإشارة أقوى. لسوء الحظ ، لم أجد أعمالًا مفتوحة بطريقتهم.
إعلانات جوجل
نفس المتأنق الذي تحدث أمس عن التهم يقول ، كل شيء حزين ومتغطرس. سار على عدة مواضيع.
الجزء الأول: التخصيص العشوائي القوي للإعلان. لدينا عُقدًا في الميزانية (إعلانات) وعُقد عبر الإنترنت (مستخدمين) ، وهناك أيضًا بعض الأوزان بينهما. أنت الآن بحاجة إلى اختيار الإعلانات التي تظهر العقدة الجديدة. يمكنك القيام بذلك بجشع (دائمًا بالوزن الأقصى) ، ولكن بعد ذلك نخاطر بضرورة وضع ميزانية قبل الأوان والحصول على حل غير فعال (الحد النظري هو 1/2 من الحد الأقصى). يمكنك التعامل مع هذا بطرق مختلفة ، في الواقع ، هنا لدينا صراع تقليدي بين Revenu و wellfair.
عند اختيار طريقة التخصيص ، يمكن للمرء أن يفترض ترتيبًا عشوائيًا لظهور العقد عبر الإنترنت وفقًا لبعض التوزيع ، ولكن في الممارسة العملية قد يكون هناك أيضًا ترتيب عدائي (أي مع بعض عناصر التأثير المعاكس). الأساليب في هذه الحالات مختلفة ، فهي توفر روابط لأحدث مقالاتهم:
1 و
2 .
الجزء الثاني: التعلم الإدراكي / التسعير القوي. نحاول الآن حل مسألة اختيار سعر الحجز لزيادة إيرادات المواقع الإعلانية.
وننظر أيضًا في استخدام مزادات أخرى مثل
مزاد Myerson ، و
BINTAC ،
والعودة إلى المزاد من السعر الأول في حالة الاتصال بالحجز. إنهم لا يدخلون في التفاصيل ، يرسلون إلى
مقالتهم .
الجزء الثالث: التجميع عبر الإنترنت. مرة أخرى ، نحل مشكلة زيادة الدخل ، ولكن الآن نذهب من الجانب الآخر. إذا كان بإمكانك شراء الإعلانات بشكل مجمّع (تجميع دون اتصال) ، فيمكنك في كثير من الحالات تقديم حل أكثر مثالية. ولكن لا يمكنك القيام بذلك في مزاد عبر الإنترنت ، فأنت بحاجة إلى بناء نماذج معقدة بالذاكرة ، وفي الظروف القاسية لا يقوم RTB بدفعها.
ثم يظهر نموذج سحري ، حيث يتم تقليل كل الذاكرة إلى رقم واحد (حساب مصرفي) ، ولكن الوقت ينفد ، ويبدأ مكبر الصوت في التقليب المحموم عبر الشرائح. , ,
.
Deep Policy optimization by Alibaba
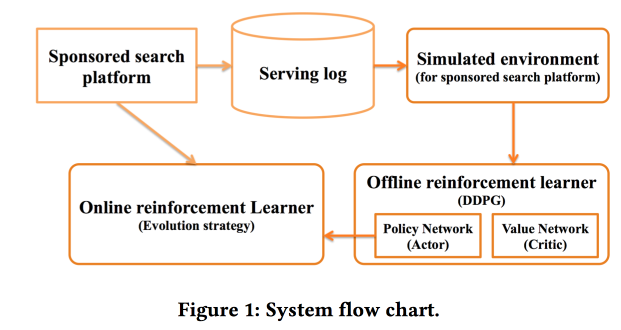
«sponsored search». RL, — .
.
offline- , , online-, .
CTR ,
DDPG .
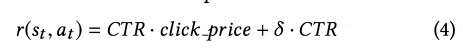
- , « »:
Criteo Large Scale Benchmark for Uplift Modeling
( ). Criteo
Criteo-UPLIFT1 (450 ) .
. -, , ( ). — (, ).
? . - , — , (AUUC).
Qini- (
Gini ), Qini, .
. : , . .
revert label. , , , , ; . , , .
, . .
Deep Net with Attention for Multi-Touch Attribution
, ,
Adobe . , , ! , attention- LSTM, . LSTM- .
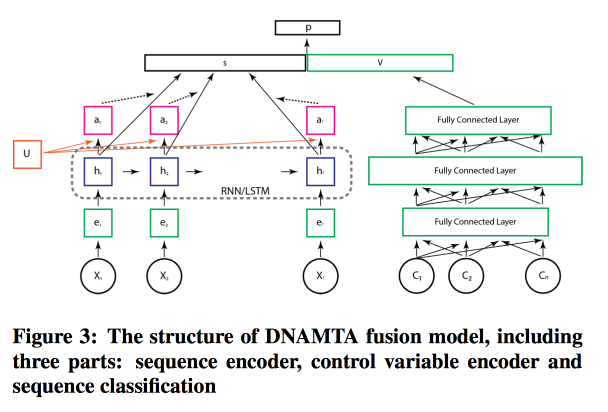
, attention- .
الخلاصة
ثم كانت هناك الجلسة الافتتاحية الرهيبة مع فيديو IMAX في أفضل تقليد للمقاطع الدعائية الضخمة ، شكرًا جزيلًا لكل من ساهم في تنظيم هذا كله - سجل KDD من جميع النواحي (بما في ذلك رعاية 1.2 مليون دولار) ، كلمات فراق من لورد بايتس (وزير الابتكار) المملكة المتحدة) وجلسة ملصق لم تعد هناك قوة فيها. يجب أن نستعد للغد.