ملاحظة perev. : مؤلف المقالة الأصلية ، نيكولاس ليفا ، هو مهندس حلول سيسكو الذي قرر المشاركة مع أقرانه ، مهندسي الشبكات ، كيف تعمل شبكة Kubernetes من الداخل. للقيام بذلك ، يستكشف أبسط تكوين له في المجموعة ، ويستخدم بنشاط الحس السليم ، ومعرفته بالشبكات وأدوات لينكس / Kubernetes القياسية. اتضح بشكل كبير ، ولكن من الواضح جدا.
بالإضافة إلى حقيقة أن دليل
Kubersey Hightower's
Kubernetes The Hard Way يعمل فقط (
حتى على AWS! ) ، أحببت الحفاظ على الشبكة نظيفة وبسيطة. وهذه فرصة عظيمة لفهم دور واجهة شبكة الحاويات (
CNI ) ، على سبيل المثال. بعد قولي هذا ، سأضيف أن شبكة Kubernetes ليست بديهية جدًا حقًا ، خاصة للمبتدئين ... ولا تنس أيضًا أنه "
ببساطة لا يوجد شيء مثل شبكة للحاويات".
على الرغم من وجود مواد جيدة بالفعل حول هذا الموضوع (انظر الروابط
هنا ) ، إلا أنني لم أجد مثلًا لأجمع بين كل ما هو ضروري مع استنتاجات الفرق التي يحبها ويكرهها مهندسو الشبكات ، مما يوضح ما يحدث بالفعل وراء الكواليس. لذلك ، قررت جمع المعلومات من مصادر عديدة - آمل أن يساعدك ذلك وأن تفهم بشكل أفضل كيف يرتبط كل شيء مع بعضها البعض. هذه المعرفة مهمة ليس فقط لاختبار نفسك ، ولكن أيضًا لتبسيط عملية تشخيص المشكلات. يمكنك اتباع المثال في مجموعتك من
Kubernetes The Hard Way : يتم أخذ جميع عناوين IP والإعدادات من هناك (اعتبارًا من عمليات مايو 2018 ، قبل استخدام
حاويات Nabla ).
وسنبدأ من النهاية ، عندما يكون لدينا ثلاث وحدات تحكم وثلاث عقد عمل:
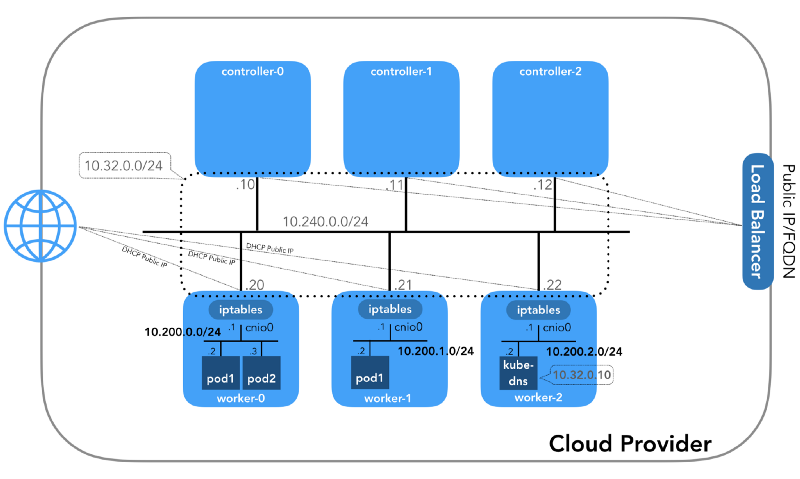
قد تلاحظ أن هناك أيضًا ثلاث شبكات فرعية خاصة على الأقل هنا! القليل من الصبر ، وسيتم النظر فيها جميعًا. تذكر أنه على الرغم من أننا نشير إلى بادئات IP محددة للغاية ، إلا أنها مأخوذة ببساطة من
Kubernetes The Hard Way ، لذا فهي ذات أهمية محلية فقط ،
ولديك مطلق الحرية في اختيار أي كتلة عناوين أخرى
لبيئتك وفقًا لـ
RFC 1918 . في حالة IPv6 ، سيكون هناك مقالة مدونة منفصلة.
الشبكة المضيفة (10.240.0.0/24)
هذه شبكة داخلية تشكل جميع العقد جزءًا منها. محدد بواسطة علامة
--private-network-ip في
GCP أو خيار
--private-ip-address في
AWS عند تخصيص موارد الحوسبة.
تهيئة عقد وحدة التحكم في GCP
for i in 0 1 2; do gcloud compute instances create controller-${i} \
(
controllers_gcp.sh )
تهيئة عقد وحدة التحكم في AWS
for i in 0 1 2; do declare controller_id${i}=`aws ec2 run-instances \
(
controllers_aws.sh )
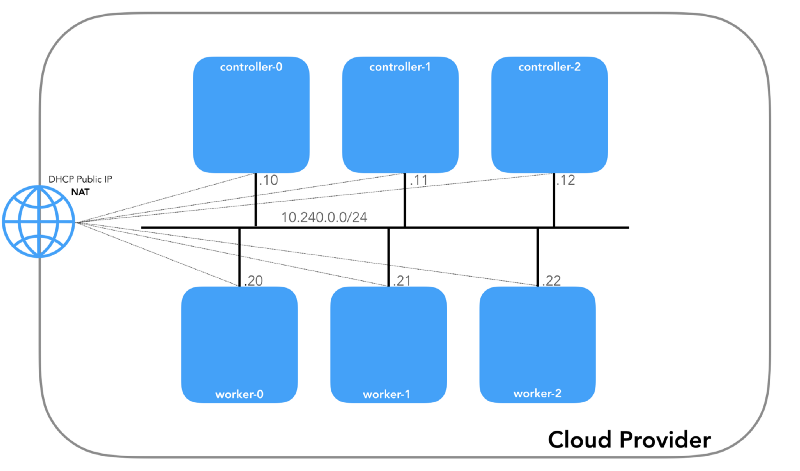
سيكون لكل مثيل عنوانين IP: خاص من الشبكة المضيفة (وحدات التحكم -
10.240.0.1${i}/24 ، العمال -
10.240.0.2${i}/24 )
10.240.0.2${i}/24 ، يتم تعيينه من قبل مزود السحابة ، والذي سنتحدث عنه لاحقًا كيفية الوصول إلى
NodePorts .
Gcp
$ gcloud compute instances list NAME ZONE MACHINE_TYPE PREEMPTIBLE INTERNAL_IP EXTERNAL_IP STATUS controller-0 us-west1-c n1-standard-1 10.240.0.10 35.231.XXX.XXX RUNNING worker-1 us-west1-c n1-standard-1 10.240.0.21 35.231.XX.XXX RUNNING ...
أوس
$ aws ec2 describe-instances --query 'Reservations[].Instances[].[Tags[?Key==`Name`].Value[],PrivateIpAddress,PublicIpAddress]' --output text | sed '$!N;s/\n/ /' 10.240.0.10 34.228.XX.XXX controller-0 10.240.0.21 34.173.XXX.XX worker-1 ...
يجب أن تكون جميع العقد قادرة على تنفيذ الأمر ping لبعضها البعض إذا كانت
سياسات الأمان صحيحة (وإذا
ping تثبيت
ping على المضيف).
شبكة الموقد (10.200.0.0/16)
هذه هي الشبكة التي تعيش فيها القرون. تستخدم كل عقدة عمل شبكة فرعية من هذه الشبكة. في حالتنا ،
POD_CIDR=10.200.${i}.0/24 worker-${i} .
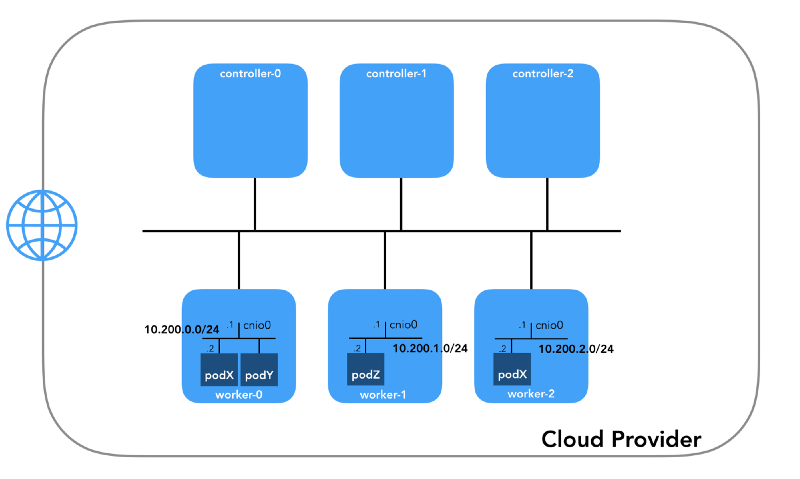
لفهم كيفية تكوين كل شيء ، تراجع خطوة للوراء وانظر إلى
نموذج شبكة Kubernetes ، الذي يتطلب ما يلي:
- يمكن لجميع الحاويات التواصل مع أي حاويات أخرى دون استخدام NAT.
- يمكن لجميع العقد التواصل مع جميع الحاويات (والعكس صحيح) دون استخدام NAT.
- يجب أن يكون عنوان IP الذي تراه الحاوية هو نفسه الذي يراه الآخرون.
يمكن تنفيذ كل هذا بعدة طرق ، ويمرر Kubernetes إعداد الشبكة إلى
المكون الإضافي CNI .
"إن المكوّن الإضافي CNI مسؤول عن إضافة واجهة شبكة إلى مساحة اسم شبكة الحاوية (على سبيل المثال ، أحد طرفي زوج veth ) وإجراء التغييرات اللازمة على المضيف (على سبيل المثال ، توصيل الطرف الثاني من veth بجسر). ثم يجب عليه تعيين واجهة IP وتكوين المسارات وفقًا لقسم إدارة عنوان IP عن طريق استدعاء البرنامج المساعد IPAM المطلوب. " (من مواصفات واجهة شبكة الحاويات )
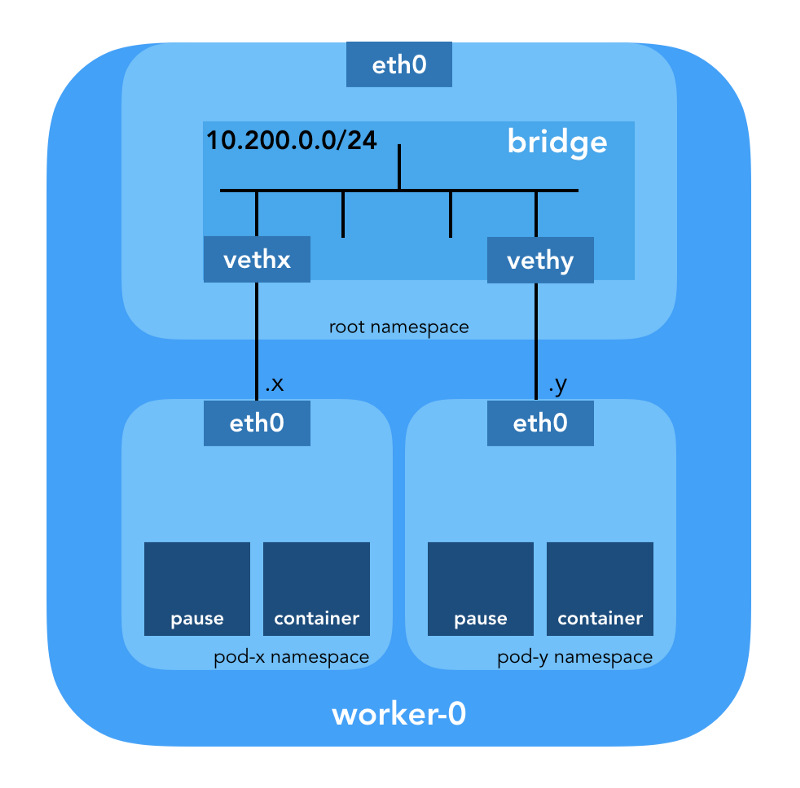
مساحة اسم الشبكة
"تلف مساحة الاسم مورد النظام العالمي إلى تجريد مرئي للعمليات في مساحة الاسم هذه بحيث يكون لها مثيلها المعزول الخاص بها للمورد العام. تكون التغييرات في المورد العالمي مرئية للعمليات الأخرى المضمنة في مساحة الاسم هذه ، ولكنها غير مرئية للعمليات الأخرى. " ( من صفحة دليل مساحات الأسماء )
يوفر Linux سبعة مساحات أسماء مختلفة (
Cgroup و
IPC و
Network و
Mount و
PID و
User و
UTS ). تحدد مساحات أسماء الشبكة (
CLONE_NEWNET ) موارد الشبكة المتاحة للعملية: "لكل مساحة اسم شبكة أجهزة شبكة خاصة بها وعناوين IP وجداول توجيه IP و
/proc/net directory وأرقام المنافذ وما إلى ذلك"
( من مقالة " مساحات الأسماء قيد التشغيل ") .
أجهزة Ethernet الافتراضية (Veth)
يوفر "زوج شبكة ظاهري (veth) تجريدًا في شكل" ماسورة "" ، والتي يمكن استخدامها لإنشاء الأنفاق بين مساحات أسماء الشبكة أو لإنشاء جسر إلى جهاز شبكة فعلي في مساحة شبكة أخرى. عندما يتم تحرير مساحة الاسم ، يتم تدمير جميع أجهزة veth الموجودة فيها ". (من صفحة الدليل الخاصة بمساحات أسماء الشبكة )
انزل إلى الأرض وانظر كيف يرتبط كل ذلك بالمجموعة. أولاً ،
المكونات الإضافية للشبكة في Kubernetes متنوعة ، ومكونات CNI الإضافية واحدة (
لماذا لا CNM؟ ).
يخبر Kubelet في كل عقدة
وقت تشغيل الحاوية
بالشبكة الإضافية التي يجب استخدامها. تقع واجهة شبكة الحاويات (
CNI ) بين وقت تشغيل الحاوية وتنفيذ الشبكة. ويقوم البرنامج المساعد CNI بالفعل بإعداد الشبكة.
"تم تحديد المكوِّن الإضافي CNI بتمرير --network-plugin=cni سطر الأوامر --network-plugin=cni إلى Kubelet. يقرأ Kubelet الملف من --cni-conf-dir (الافتراضي هو /etc/cni/net.d ) ويستخدم تكوين CNI من هذا الملف لتكوين الشبكة لكل ملف. " (من متطلبات البرنامج المساعد للشبكة )
الثنائيات الحقيقية
-- cni-bin-dir الإضافي CNI في
-- cni-bin-dir (الافتراضي هو
/opt/cni/bin ).
يرجى ملاحظة أن
kubelet.service استدعاء
--network-plugin=cni تشمل
--network-plugin=cni :
[Service] ExecStart=/usr/local/bin/kubelet \\ --config=/var/lib/kubelet/kubelet-config.yaml \\ --network-plugin=cni \\ ...
بادئ ذي بدء ، تقوم Kubernetes بإنشاء مساحة اسم شبكة للموقد ، حتى قبل استدعاء أي مكونات إضافية. يتم تنفيذ ذلك باستخدام حاوية
pause الخاصة ، "التي تعمل بمثابة" الحاوية الرئيسية "لجميع حاويات الموقد"
(من مقالة " The Pause Almighty Pause Container ") . ثم تقوم Kubernetes بتنفيذ البرنامج المساعد CNI لإرفاق حاوية
pause بالشبكة. تستخدم جميع حاويات pod
netns pause هذه.
{ "cniVersion": "0.3.1", "name": "bridge", "type": "bridge", "bridge": "cnio0", "isGateway": true, "ipMasq": true, "ipam": { "type": "host-local", "ranges": [ [{"subnet": "${POD_CIDR}"}] ], "routes": [{"dst": "0.0.0.0/0"}] } }
يشير
تكوين CNI المستخدم إلى استخدام المكوّن الإضافي
bridge لتكوين
bridge برنامج Linux (L2) في مساحة اسم الجذر التي تسمى
cnio0 (
الاسم الافتراضي هو
cni0 ) ، والذي يعمل كبوابة (
"isGateway": true ).

سيتم أيضًا تكوين زوج veth لربط الموقد بالجسر الذي تم إنشاؤه حديثًا:
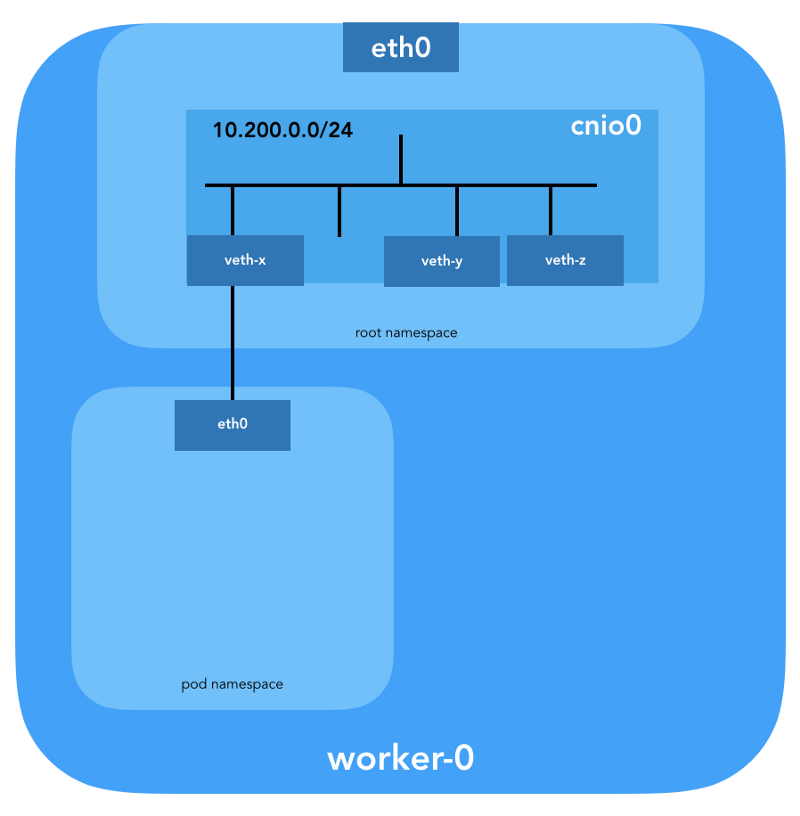
لتعيين معلومات L3 ، مثل عناوين IP ، يتم استدعاء
البرنامج المساعد IPAM (
ipam ). في هذه الحالة ، يتم استخدام نوع
host-local ، "الذي يقوم بتخزين الحالة محليًا على نظام ملف المضيف ، مما يضمن تفرد عناوين IP على مضيف واحد"
(من host-local ) . يعيد المكوِّن الإضافي IPAM هذه المعلومات إلى المكوّن الإضافي السابق (
bridge ) ، بحيث يمكن تهيئة جميع المسارات المحددة في التهيئة (
"routes": [{"dst": "0.0.0.0/0"}] ). إذا لم
gw تحديد
gw ،
يتم أخذه من الشبكة الفرعية . يتم تكوين المسار الافتراضي أيضًا في مساحة اسم شبكة الموقد ، مشيرًا إلى الجسر (الذي تم تكوينه كأول شبكة فرعية IP للموقد).
وآخر التفاصيل المهمة: طلبنا التنكر (
"ipMasq": true ) لحركة المرور القادمة من شبكة الموقد. لا نحتاج إلى NAT حقًا هنا ، ولكن هذا هو التكوين في
Kubernetes The Hard Way . لذلك ، من أجل الاكتمال ، يجب أن أذكر أن الإدخالات في
iptables لمكون
bridge الإضافي تم تكوينها لهذا المثال المحدد. جميع الحزم من الموقد ، التي لا يكون المستلم ضمن النطاق
224.0.0.0/4 ،
ستكون خلف NAT ، والتي لا تلبي تمامًا متطلبات "يمكن لجميع الحاويات التواصل مع أي حاويات أخرى دون استخدام NAT." حسنًا ، سوف نثبت سبب عدم الحاجة إلى NAT ...

توجيه الموقد
الآن نحن مستعدون لتخصيص القرون. دعونا نلقي نظرة على جميع مساحات الشبكة لأسماء إحدى عقد العمل ونحلل واحدة منها بعد إنشاء نشر
nginx من هنا . سنستخدم
lsns مع خيار
-t لتحديد نوع مساحة الاسم المطلوب (أي
net ):
ubuntu@worker-0:~$ sudo lsns -t net NS TYPE NPROCS PID USER COMMAND 4026532089 net 113 1 root /sbin/init 4026532280 net 2 8046 root /pause 4026532352 net 4 16455 root /pause 4026532426 net 3 27255 root /pause
باستخدام الخيار
-i إلى
ls يمكننا العثور على أرقام inode الخاصة بهم:
ubuntu@worker-0:~$ ls -1i /var/run/netns 4026532352 cni-1d85bb0c-7c61-fd9f-2adc-f6e98f7a58af 4026532280 cni-7cec0838-f50c-416a-3b45-628a4237c55c 4026532426 cni-912bcc63-712d-1c84-89a7-9e10510808a0
يمكنك أيضًا سرد جميع مساحات أسماء الشبكات باستخدام
ip netns :
ubuntu@worker-0:~$ ip netns cni-912bcc63-712d-1c84-89a7-9e10510808a0 (id: 2) cni-1d85bb0c-7c61-fd9f-2adc-f6e98f7a58af (id: 1) cni-7cec0838-f50c-416a-3b45-628a4237c55c (id: 0)
لمشاهدة جميع العمليات التي تعمل في مساحة الشبكة
cni-912bcc63–712d-1c84–89a7–9e10510808a0 (
4026532426 ) ، يمكنك تشغيل الأمر التالي ، على سبيل المثال:
ubuntu@worker-0:~$ sudo ls -l /proc/[1-9]*/ns/net | grep 4026532426 | cut -f3 -d"/" | xargs ps -p PID TTY STAT TIME COMMAND 27255 ? Ss 0:00 /pause 27331 ? Ss 0:00 nginx: master process nginx -g daemon off; 27355 ? S 0:00 nginx: worker process
يمكن ملاحظة أنه بالإضافة إلى
pause في هذا الجراب ، أطلقنا
nginx . تشترك حاوية
pause في مساحات أسماء
net و
ipc مع جميع حاويات pod الأخرى. تذكر PID من
pause - 27255 ؛ سنعود إليها.
الآن دعونا نرى ما يقوله
kubectl عن هذا الجراب:
$ kubectl get pods -o wide | grep nginx nginx-65899c769f-wxdx6 1/1 Running 0 5d 10.200.0.4 worker-0
مزيد من التفاصيل:
$ kubectl describe pods nginx-65899c769f-wxdx6
Name: nginx-65899c769f-wxdx6 Namespace: default Node: worker-0/10.240.0.20 Start Time: Thu, 05 Jul 2018 14:20:06 -0400 Labels: pod-template-hash=2145573259 run=nginx Annotations: <none> Status: Running IP: 10.200.0.4 Controlled By: ReplicaSet/nginx-65899c769f Containers: nginx: Container ID: containerd://4c0bd2e2e5c0b17c637af83376879c38f2fb11852921b12413c54ba49d6983c7 Image: nginx ...
نرى اسم الجراب -
nginx-65899c769f-wxdx6 - ومعرّف إحدى
nginx-65899c769f-wxdx6 (
nginx ) ، ولكن لم يتم قول أي شيء عن
pause . حفر عقدة عمل أعمق لتتناسب مع جميع البيانات. تذكر أن
Kubernetes The Hard Way لا تستخدم
Docker ، وبالتالي للحصول على تفاصيل حول الحاوية ، نشير إلى
حاوية أدوات وحدة التحكم - ctr
(انظر أيضًا المقالة " تكامل الحاوية مع Kubernetes ، واستبدال Docker ، جاهزة للإنتاج " - نقل تقريبًا ) :
ubuntu@worker-0:~$ sudo ctr namespaces ls NAME LABELS k8s.io
k8s.io الحاوية (
k8s.io ) ، يمكنك الحصول على معرف حاوية
nginx :
ubuntu@worker-0:~$ sudo ctr -n k8s.io containers ls | grep nginx 4c0bd2e2e5c0b17c637af83376879c38f2fb11852921b12413c54ba49d6983c7 docker.io/library/nginx:latest io.containerd.runtime.v1.linux
...
pause أيضًا:
ubuntu@worker-0:~$ sudo ctr -n k8s.io containers ls | grep pause 0866803b612f2f55e7b6b83836bde09bd6530246239b7bde1e49c04c7038e43a k8s.gcr.io/pause:3.1 io.containerd.runtime.v1.linux 21640aea0210b320fd637c22ff93b7e21473178de0073b05de83f3b116fc8834 k8s.gcr.io/pause:3.1 io.containerd.runtime.v1.linux d19b1b1c92f7cc90764d4f385e8935d121bca66ba8982bae65baff1bc2841da6 k8s.gcr.io/pause:3.1 io.containerd.runtime.v1.linux
معرف حاوية
nginx المنتهي بـ
…983c7 يتطابق مع ما حصلنا عليه من
kubectl . دعنا نرى ما إذا كان بإمكاننا معرفة حاوية
pause التي تنتمي إلى
nginx pod:
ubuntu@worker-0:~$ sudo ctr -n k8s.io task ls TASK PID STATUS ... d19b1b1c92f7cc90764d4f385e8935d121bca66ba8982bae65baff1bc2841da6 27255 RUNNING 4c0bd2e2e5c0b17c637af83376879c38f2fb11852921b12413c54ba49d6983c7 27331 RUNNING
هل تتذكر أن العمليات مع PID 27331 و 27355 تعمل في مساحة اسم الشبكة
cni-912bcc63–712d-1c84–89a7–9e10510808a0 ؟
ubuntu@worker-0:~$ sudo ctr -n k8s.io containers info d19b1b1c92f7cc90764d4f385e8935d121bca66ba8982bae65baff1bc2841da6 { "ID": "d19b1b1c92f7cc90764d4f385e8935d121bca66ba8982bae65baff1bc2841da6", "Labels": { "io.cri-containerd.kind": "sandbox", "io.kubernetes.pod.name": "nginx-65899c769f-wxdx6", "io.kubernetes.pod.namespace": "default", "io.kubernetes.pod.uid": "0b35e956-8080-11e8-8aa9-0a12b8818382", "pod-template-hash": "2145573259", "run": "nginx" }, "Image": "k8s.gcr.io/pause:3.1", ...
... و:
ubuntu@worker-0:~$ sudo ctr -n k8s.io containers info 4c0bd2e2e5c0b17c637af83376879c38f2fb11852921b12413c54ba49d6983c7 { "ID": "4c0bd2e2e5c0b17c637af83376879c38f2fb11852921b12413c54ba49d6983c7", "Labels": { "io.cri-containerd.kind": "container", "io.kubernetes.container.name": "nginx", "io.kubernetes.pod.name": "nginx-65899c769f-wxdx6", "io.kubernetes.pod.namespace": "default", "io.kubernetes.pod.uid": "0b35e956-8080-11e8-8aa9-0a12b8818382" }, "Image": "docker.io/library/nginx:latest", ...
نعرف الآن على وجه اليقين أي الحاويات تعمل في هذا
nginx-65899c769f-wxdx6 (
nginx-65899c769f-wxdx6 ) ومساحة اسم الشبكة (
cni-912bcc63–712d-1c84–89a7–9e10510808a0 ):
- nginx (رقم التعريف:
4c0bd2e2e5c0b17c637af83376879c38f2fb11852921b12413c54ba49d6983c7 ) ؛ - وقفة (ID:
d19b1b1c92f7cc90764d4f385e8935d121bca66ba8982bae65baff1bc2841da6 ).

كيف يتم توصيل هذا تحت (
nginx-65899c769f-wxdx6 ) بالشبكة؟ نستخدم PID 27255 الذي تم تلقيه مسبقًا من
pause لتشغيل الأوامر في مساحة اسم شبكتها (
cni-912bcc63–712d-1c84–89a7–9e10510808a0 ):
ubuntu@worker-0:~$ sudo ip netns identify 27255 cni-912bcc63-712d-1c84-89a7-9e10510808a0
لهذه الأغراض ، سوف نستخدم
nsenter مع الخيار
-t الذي يحدد PID المستهدف ، و
-n دون تحديد ملف للدخول إلى مساحة اسم الشبكة للعملية المستهدفة (27255). إليك ما سيقوله
ip link show :
ubuntu@worker-0:~$ sudo nsenter -t 27255 -n ip link show 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 3: eth0@if7: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP mode DEFAULT group default link/ether 0a:58:0a:c8:00:04 brd ff:ff:ff:ff:ff:ff link-netnsid 0
... و
ifconfig eth0 :
ubuntu@worker-0:~$ sudo nsenter -t 27255 -n ifconfig eth0 eth0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500 inet 10.200.0.4 netmask 255.255.255.0 broadcast 0.0.0.0 inet6 fe80::2097:51ff:fe39:ec21 prefixlen 64 scopeid 0x20<link> ether 0a:58:0a:c8:00:04 txqueuelen 0 (Ethernet) RX packets 540 bytes 42247 (42.2 KB) RX errors 0 dropped 0 overruns 0 frame 0 TX packets 177 bytes 16530 (16.5 KB) TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
هذا يؤكد أن عنوان IP الذي تم الحصول عليه سابقًا من خلال
kubectl get pod تم تكوينه على واجهة
eth0 . تعد هذه الواجهة جزءًا من
زوج veth ، أحد طرفيه في الموقد ، والآخر في مساحة اسم الجذر. لمعرفة واجهة الطرف الثاني ، نستخدم
ethtool :
ubuntu@worker-0:~$ sudo ip netns exec cni-912bcc63-712d-1c84-89a7-9e10510808a0 ethtool -S eth0 NIC statistics: peer_ifindex: 7
نرى أن
ifindex العيد هو 7. تأكد من أنه في مساحة اسم الجذر. يمكن القيام بذلك باستخدام
ip link :
ubuntu@worker-0:~$ ip link | grep '^7:' 7: veth71f7d238@if3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master cnio0 state UP mode DEFAULT group default
للتأكد من ذلك أخيرًا ، دعنا نرى:
ubuntu@worker-0:~$ sudo cat /sys/class/net/veth71f7d238/ifindex 7
رائع ، الآن كل شيء واضح مع الرابط الافتراضي. باستخدام
brctl دعنا نرى من يتصل بجسر Linux:
ubuntu@worker-0:~$ brctl show cnio0 bridge name bridge id STP enabled interfaces cnio0 8000.0a580ac80001 no veth71f7d238 veth73f35410 vethf273b35f
لذا ، الصورة كما يلي:
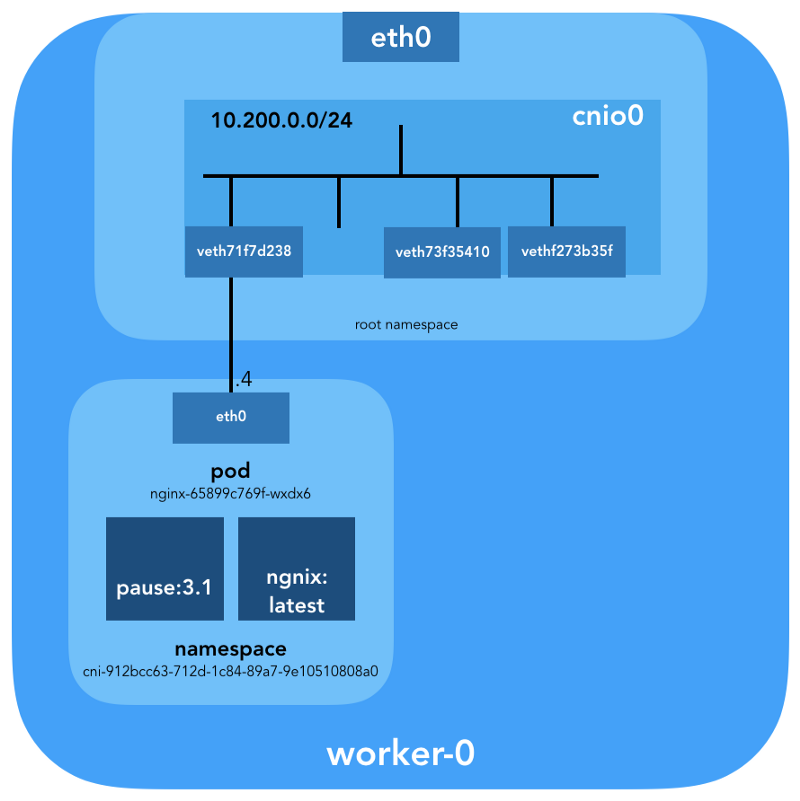
فحص التوجيه
كيف نوجه حركة المرور بالفعل؟ دعونا نلقي نظرة على جدول التوجيه في لوحة مساحة اسم الشبكة:
ubuntu@worker-0:~$ sudo ip netns exec cni-912bcc63-712d-1c84-89a7-9e10510808a0 ip route show default via 10.200.0.1 dev eth0 10.200.0.0/24 dev eth0 proto kernel scope link src 10.200.0.4
على الأقل نحن نعرف كيفية الوصول إلى مساحة اسم الجذر (
default via 10.200.0.1 ). الآن دعنا نرى جدول توجيه المضيف:
ubuntu@worker-0:~$ ip route list default via 10.240.0.1 dev eth0 proto dhcp src 10.240.0.20 metric 100 10.200.0.0/24 dev cnio0 proto kernel scope link src 10.200.0.1 10.240.0.0/24 dev eth0 proto kernel scope link src 10.240.0.20 10.240.0.1 dev eth0 proto dhcp scope link src 10.240.0.20 metric 100
نحن نعرف كيفية إعادة توجيه الحزم إلى جهاز توجيه VPC (
يحتوي VPC
على جهاز توجيه "ضمني" ، والذي
يحتوي عادةً على عنوان ثانٍ من مساحة عنوان IP الرئيسية للشبكة الفرعية). الآن: هل يعرف جهاز توجيه VPC كيفية الوصول إلى شبكة كل موقد؟ لا ، لم يفعل ذلك ، لذلك يُفترض أنه سيتم تكوين المسارات بواسطة مكون CNI الإضافي أو
يدويًا (كما في الدليل). يبدو أن
المكوّن الإضافي AWS CNI يفعل ذلك لنا في AWS. تذكر أن هناك
العديد من المكونات الإضافية لـ CNI ، ونحن نفكر في مثال
لتكوين شبكة بسيط :
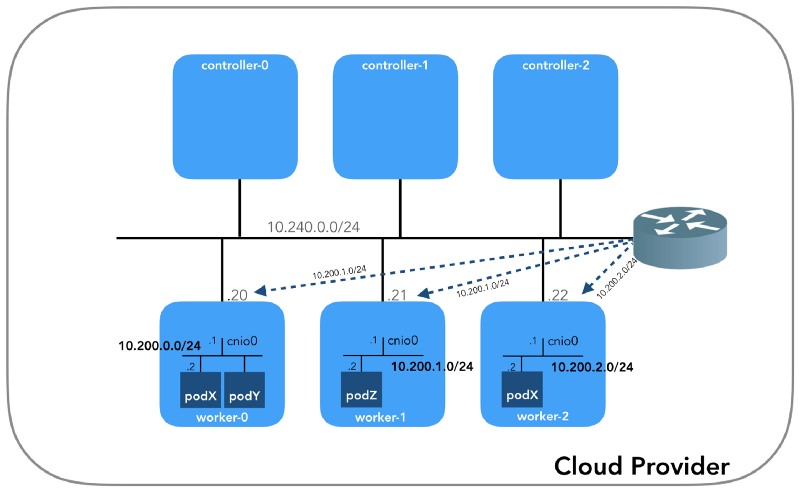
الغمر العميق في NAT
kubectl create -f busybox.yaml بإنشاء
kubectl create -f busybox.yaml متطابقين مع وحدة تحكم النسخ المتماثل:
apiVersion: v1 kind: ReplicationController metadata: name: busybox0 labels: app: busybox0 spec: replicas: 2 selector: app: busybox0 template: metadata: name: busybox0 labels: app: busybox0 spec: containers: - image: busybox command: - sleep - "3600" imagePullPolicy: IfNotPresent name: busybox restartPolicy: Always
(
busybox.yaml )
نحصل على:
$ kubectl get pods -o wide NAME READY STATUS RESTARTS AGE IP NODE busybox0-g6pww 1/1 Running 0 4s 10.200.1.15 worker-1 busybox0-rw89s 1/1 Running 0 4s 10.200.0.21 worker-0 ...
يجب أن تكون الأصوات من حاوية إلى أخرى ناجحة:
$ kubectl exec -it busybox0-rw89s -- ping -c 2 10.200.1.15 PING 10.200.1.15 (10.200.1.15): 56 data bytes 64 bytes from 10.200.1.15: seq=0 ttl=62 time=0.528 ms 64 bytes from 10.200.1.15: seq=1 ttl=62 time=0.440 ms --- 10.200.1.15 ping statistics --- 2 packets transmitted, 2 packets received, 0% packet loss round-trip min/avg/max = 0.440/0.484/0.528 ms
لفهم حركة حركة المرور ، يمكنك إلقاء نظرة على الحزم باستخدام
tcpdump أو
conntrack :
ubuntu@worker-0:~$ sudo conntrack -L | grep 10.200.1.15 icmp 1 29 src=10.200.0.21 dst=10.200.1.15 type=8 code=0 id=1280 src=10.200.1.15 dst=10.240.0.20 type=0 code=0 id=1280 mark=0 use=1
تتم ترجمة عنوان IP المصدر من pod 10.200.0.21 إلى عنوان IP الخاص بالمضيف 10.240.0.20.
ubuntu@worker-1:~$ sudo conntrack -L | grep 10.200.1.15 icmp 1 28 src=10.240.0.20 dst=10.200.1.15 type=8 code=0 id=1280 src=10.200.1.15 dst=10.240.0.20 type=0 code=0 id=1280 mark=0 use=1
في iptables ، يمكنك أن ترى أن الأعداد في تزايد:
ubuntu@worker-0:~$ sudo iptables -t nat -Z POSTROUTING -L -v Chain POSTROUTING (policy ACCEPT 0 packets, 0 bytes) pkts bytes target prot opt in out source destination ... 5 324 CNI-be726a77f15ea47ff32947a3 all -- any any 10.200.0.0/24 anywhere /* name: "bridge" id: "631cab5de5565cc432a3beca0e2aece0cef9285482b11f3eb0b46c134e457854" */ Zeroing chain `POSTROUTING'
من ناحية أخرى ، إذا قمت بإزالة
"ipMasq": true من تكوين المكون الإضافي CNI ، يمكنك مشاهدة ما يلي (يتم تنفيذ هذه العملية حصريًا للأغراض التعليمية - لا نوصي بتغيير التكوين على مجموعة عمل!):
$ kubectl get pods -o wide NAME READY STATUS RESTARTS AGE IP NODE busybox0-2btxn 1/1 Running 0 16s 10.200.0.15 worker-0 busybox0-dhpx8 1/1 Running 0 16s 10.200.1.13 worker-1 ...
يجب أن يمر Ping:
$ kubectl exec -it busybox0-2btxn -- ping -c 2 10.200.1.13 PING 10.200.1.6 (10.200.1.6): 56 data bytes 64 bytes from 10.200.1.6: seq=0 ttl=62 time=0.515 ms 64 bytes from 10.200.1.6: seq=1 ttl=62 time=0.427 ms --- 10.200.1.6 ping statistics --- 2 packets transmitted, 2 packets received, 0% packet loss round-trip min/avg/max = 0.427/0.471/0.515 ms
وفي هذه الحالة - بدون استخدام NAT:
ubuntu@worker-0:~$ sudo conntrack -L | grep 10.200.1.13 icmp 1 29 src=10.200.0.15 dst=10.200.1.13 type=8 code=0 id=1792 src=10.200.1.13 dst=10.200.0.15 type=0 code=0 id=1792 mark=0 use=1
لذا ، تحققنا من أن "جميع الحاويات يمكنها التواصل مع أي حاويات أخرى دون استخدام NAT."
ubuntu@worker-1:~$ sudo conntrack -L | grep 10.200.1.13 icmp 1 27 src=10.200.0.15 dst=10.200.1.13 type=8 code=0 id=1792 src=10.200.1.13 dst=10.200.0.15 type=0 code=0 id=1792 mark=0 use=1
الشبكة العنقودية (10.32.0.0/24)
قد تكون لاحظت في مثال
busybox أن عناوين IP المعينة لـ
busybox كانت مختلفة في كل حالة. ماذا لو أردنا جعل هذه الحاويات متاحة للاتصال من المداخن الأخرى؟ يمكن للمرء أن يأخذ عناوين IP الحالية من جراب ، لكنها ستتغير. لهذا السبب ، تحتاج إلى تكوين مورد
Service ، والذي سيرسل طلبات الوكيل إلى العديد من المداخن قصيرة العمر.
"الخدمة في Kubernetes عبارة عن تجريد يحدد المجموعة المنطقية للمداخن والسياسات التي يمكن من خلالها الوصول إليها." (من وثائق خدمات Kubernetes )
هناك طرق مختلفة لنشر الخدمة ؛ النوع الافتراضي هو
ClusterIP ، الذي يقوم بتعيين عنوان IP من كتلة CIDR للكتلة (على سبيل المثال ، يمكن الوصول إليه فقط من المجموعة). أحد الأمثلة على ذلك هو إضافة مجموعة DNS التي تم تكوينها في Kubernetes The Hard Way.
# ... apiVersion: v1 kind: Service metadata: name: kube-dns namespace: kube-system labels: k8s-app: kube-dns kubernetes.io/cluster-service: "true" addonmanager.kubernetes.io/mode: Reconcile kubernetes.io/name: "KubeDNS" spec: selector: k8s-app: kube-dns clusterIP: 10.32.0.10 ports: - name: dns port: 53 protocol: UDP - name: dns-tcp port: 53 protocol: TCP # ...
(
kube-dns.yaml )
يوضح
kubectl أن
Service تتذكر نقاط النهاية وترجمتها:
$ kubectl -n kube-system describe services ... Selector: k8s-app=kube-dns Type: ClusterIP IP: 10.32.0.10 Port: dns 53/UDP TargetPort: 53/UDP Endpoints: 10.200.0.27:53 Port: dns-tcp 53/TCP TargetPort: 53/TCP Endpoints: 10.200.0.27:53 ...
كيف بالضبط؟ ..
iptables مرة أخرى. دعنا نذهب عبر القواعد التي تم إنشاؤها لهذا المثال. يمكن رؤية القائمة الكاملة باستخدام الأمر
iptables-save .
بمجرد إنشاء الحزم بواسطة العملية (
OUTPUT ) أو الوصول إلى واجهة الشبكة (
PREROUTING ) ، فإنها تمر عبر سلاسل
iptables التالية:
-A PREROUTING -m comment --comment "kubernetes service portals" -j KUBE-SERVICES -A OUTPUT -m comment --comment "kubernetes service portals" -j KUBE-SERVICES
تتوافق الأهداف التالية مع حزم TCP المرسلة إلى المنفذ 53 عند 10.32.0.10 ، ويتم إرسالها إلى المستلم 10.200.0.27 باستخدام المنفذ 53:
-A KUBE-SERVICES -d 10.32.0.10/32 -p tcp -m comment --comment "kube-system/kube-dns:dns-tcp cluster IP" -m tcp --dport 53 -j KUBE-SVC-ERIFXISQEP7F7OF4 -A KUBE-SVC-ERIFXISQEP7F7OF4 -m comment --comment "kube-system/kube-dns:dns-tcp" -j KUBE-SEP-32LPCMGYG6ODGN3H -A KUBE-SEP-32LPCMGYG6ODGN3H -p tcp -m comment --comment "kube-system/kube-dns:dns-tcp" -m tcp -j DNAT --to-destination 10.200.0.27:53
نفس الشيء لحزم UDP (المستلم 10.32.0.10:53 → 10.200.0.27:53):
-A KUBE-SERVICES -d 10.32.0.10/32 -p udp -m comment --comment "kube-system/kube-dns:dns cluster IP" -m udp --dport 53 -j KUBE-SVC-TCOU7JCQXEZGVUNU -A KUBE-SVC-TCOU7JCQXEZGVUNU -m comment --comment "kube-system/kube-dns:dns" -j KUBE-SEP-LRUTK6XRXU43VLIG -A KUBE-SEP-LRUTK6XRXU43VLIG -p udp -m comment --comment "kube-system/kube-dns:dns" -m udp -j DNAT --to-destination 10.200.0.27:53
هناك أنواع أخرى من
Services في Kubernetes. على وجه الخصوص ، تتحدث Kubernetes The Hard Way عن
NodePort - راجع
اختبار الدخان: الخدمات .
kubectl expose deployment nginx --port 80 --type NodePort
ينشر
NodePort الخدمة على عنوان IP لكل عقدة ،
NodePort على منفذ ثابت (يطلق عليه
NodePort ). يمكن
NodePort الوصول إلى
NodePort من خارج الكتلة. يمكنك التحقق من المنفذ المخصص (في هذه الحالة - 31088) باستخدام
kubectl :
$ kubectl describe services nginx ... Type: NodePort IP: 10.32.0.53 Port: <unset> 80/TCP TargetPort: 80/TCP NodePort: <unset> 31088/TCP Endpoints: 10.200.1.18:80 ...
تحت متاح الآن من الإنترنت كـ
http://${EXTERNAL_IP}:31088/ . هنا
EXTERNAL_IP هو عنوان IP العام
لأي نسخة عاملة . في هذا المثال ، استخدمت عنوان IP العام
للعامل -0 . يتم استلام الطلب من قبل مضيف بعنوان IP داخلي 10.240.0.20 (يعمل مزود السحابة في NAT العامة) ، ومع ذلك ، يتم بدء الخدمة بالفعل على مضيف آخر (
العامل 1 ، والذي يمكن رؤيته بواسطة عنوان IP لنقطة النهاية - 10.200.1.18):
ubuntu@worker-0:~$ sudo conntrack -L | grep 31088 tcp 6 86397 ESTABLISHED src=173.38.XXX.XXX dst=10.240.0.20 sport=30303 dport=31088 src=10.200.1.18 dst=10.240.0.20 sport=80 dport=30303 [ASSURED] mark=0 use=1
يتم إرسال الحزمة من
worker-0 إلى
worker-1 ، حيث تجد المستلم:
ubuntu@worker-1:~$ sudo conntrack -L | grep 80 tcp 6 86392 ESTABLISHED src=10.240.0.20 dst=10.200.1.18 sport=14802 dport=80 src=10.200.1.18 dst=10.240.0.20 sport=80 dport=14802 [ASSURED] mark=0 use=1
هل هذه الدائرة مثالية؟ ربما لا ، لكنها تعمل. في هذه الحالة ، تكون قواعد
iptables المبرمجة كما يلي:
-A KUBE-NODEPORTS -p tcp -m comment --comment "default/nginx:" -m tcp --dport 31088 -j KUBE-SVC-4N57TFCL4MD7ZTDA -A KUBE-SVC-4N57TFCL4MD7ZTDA -m comment --comment "default/nginx:" -j KUBE-SEP-UGTFMET44DQG7H7H -A KUBE-SEP-UGTFMET44DQG7H7H -p tcp -m comment --comment "default/nginx:" -m tcp -j DNAT --to-destination 10.200.1.18:80
بمعنى آخر ، يتم بث عنوان مستلم الحزم ذات المنفذ 31088 على 10.200.1.18. كما يبث الميناء من 31088 إلى 80.
لم
LoadBalancer إلى نوع آخر من الخدمة -
LoadBalancer - مما يجعل الخدمة متاحة للجمهور باستخدام موازن تحميل موفر السحابة ، ولكن تبين أن المقالة كبيرة بالفعل.
الخلاصة
قد يبدو أن هناك الكثير من المعلومات ، لكننا لمسنا فقط قمة جبل الجليد. في المستقبل سأتحدث عن IPv6 و IPVS و eBPF واثنين من مكونات CNI الإضافية المثيرة للاهتمام.
ملاحظة من المترجم
اقرأ أيضا في مدونتنا: