
واليوم ، أخيرا ، بدأ البرنامج الرئيسي للمؤتمر. كان معدل القبول هذا العام 8 ٪ فقط ، أي يجب أن يكون الأفضل من أفضل الأفضل. يتم فصل التدفقات التطبيقية والبحثية بشكل واضح ، بالإضافة إلى وجود العديد من الأنشطة المنفصلة ذات الصلة. تبدو التدفقات التطبيقية أكثر إثارة للاهتمام ، هناك تقارير بشكل رئيسي من التخصصات (Google و Amazon و Alibaba وما إلى ذلك). سأخبرك عن العروض التي تمكنت من حضورها.
البيانات من أجل الخير
بدأ اليوم بعرض تقديمي طويل بما فيه الكفاية بحيث تكون البيانات مفيدة وتستخدم للصالح العام.
تتحدث أستاذة في جامعة كاليفورنيا (من الجدير بالذكر أن هناك الكثير من النساء في KDD ، سواء بين الطلاب أو بين المتحدثين). يتم التعبير عن كل هذا في اختصار FATES:
- النزاهة - لا يوجد تحيز في توقعات النموذج ، كل شيء محايد تجاه الجنس ومتسامح.
- المساءلة - يجب أن يكون هناك شخص أو شيء مسؤول عن القرارات التي تتخذها الآلة.
- الشفافية - الشفافية وقابلية تفسير القرارات.
- الأخلاق - عند العمل مع البيانات ، يجب التركيز بشكل خاص على الأخلاق والخصوصية.
- السلامة والأمن - يجب أن يكون النظام آمنًا (وليس ضارًا) ومحميًا (مقاومًا للتأثيرات المتلاعبة من الخارج)
لسوء الحظ ، فإن هذا البيان يعبر عن رغبة ويرتبط بالواقع بشكل ضعيف. لن يكون النموذج صحيحًا سياسيًا إلا إذا تمت إزالة جميع العلامات منه ؛ دائمًا ما تكون مسؤولية النقل إلى شخص معين صعبة للغاية ؛ وكلما زاد تطور DS ، زادت صعوبة تفسير ما يجري داخل النموذج ؛ على الأخلاق والخصوصية ، كانت هناك بعض الأمثلة الجيدة في اليوم الأول ، ولكن بخلاف ذلك ، غالبًا ما يتم التعامل مع البيانات بحرية تامة.
حسنًا ، لا يمكن للمرء أن يفشل في الاعتراف بأن النماذج الحديثة غالبًا ما تكون غير آمنة (يمكن للطيار الآلي التخلص من سيارة بسائق) وليست محمية (يمكنك اختيار أمثلة تكسر عمل الشبكة العصبية دون حتى معرفة كيفية عمل الشبكة). عمل حديث مثير للاهتمام من قبل
DeepExplore : نظام للبحث عن نقاط الضعف في الشبكات العصبية يولد ، من بين أمور أخرى ، صورًا تجعل الطيار الآلي يوجه بطريقة خاطئة.

فيما يلي تعريف آخر لعلوم البيانات على أنه "DS هو دراسة استخراج بيانات نموذج القيمة". من حيث المبدأ ، جيد جدا. في بداية الخطاب ، ذكر المتحدث على وجه التحديد أن DS غالبًا ما ينظر إلى البيانات فقط من لحظة التحليل ، في حين أن دورة الحياة الكاملة أوسع بكثير ، وهذا ، من بين أمور أخرى ، ينعكس في التعريف.
حسنًا ، كانت هناك بعض الأمثلة على العمل المختبري.
مرة أخرى سنقوم بتحليل مهمة تقييم تأثير العديد من العوامل على النتيجة ، ولكن ليس من موقع الإعلان ، ولكن بشكل عام. هناك
مقال لم ينشر بعد. ضع في اعتبارك ، على سبيل المثال ، السؤال حول أي الممثلين يختارون للفيلم من أجل جمع شباك التذاكر الجيد. نقوم بتحليل قوائم التمثيل لأعلى الأفلام ربحا ونحاول التنبؤ بمساهمة كل من الممثلين. لكن! هناك ما يسمى
بالإرباكات التي تؤثر على مدى فعالية الممثل (على سبيل المثال ، ستالون ستسير على ما يرام في فيلم الحركة المثيرة ، ولكن ليس في الكوميديا الرومانسية). لاختيار الحق ، تحتاج إلى العثور على كل الإرباك وتقييمها ، لكننا لن نتأكد أبدًا من أننا وجدنا الجميع. في الواقع ، تقترح المقالة نهجًا جديدًا - غير مؤسس. بدلاً من تسليط الضوء على الإرباكات ، نقدم بشكل صريح المتغيرات الكامنة ونقيمها في وضع غير خاضع للرقابة ، ثم ندرس النموذج بناءً عليها. يبدو كل شيء غريبًا بما فيه الكفاية ، لأنه يبدو وكأنه متغير بسيط من التضمين ، ما هو جديد ليس واضحًا.
تم عرض بعض الصور الجميلة ، أمثلة على كيفية تقدم الذكاء الاصطناعي في جامعتهم ، وما إلى ذلك.
التجارة الإلكترونية والتنميط
ذهبت إلى قسم التطبيق على التجارة. في البداية كانت هناك بعض التقارير المثيرة للاهتمام ، وفي النهاية كان هناك قدر معين من العصيدة ، ولكن قبل كل شيء.
نمذجة المستخدم الجديد والتنبؤ بالوقت
عمل Snapchat المثير للاهتمام في التنبؤ بالتدفقات الخارجية. يستخدم الرجال الفكرة ، التي ركضناها بنجاح منذ حوالي 4 سنوات: قبل التنبؤ بالتدفق ، يحتاج المستخدمون إلى تقسيمهم إلى مجموعات وفقًا لنوع السلوك. في الوقت نفسه ، اتضح أن مساحة النواقل من خلال أنواع الإجراءات ضعيفة إلى حد ما ، من بين عدد قليل من أنواع التفاعلات (كان علينا ، في الوقت المناسب ، تحديد مجموعة من العلامات من أجل الانتقال من ثلاثمائة إلى واحد ونصف) ، لكنها تثري المساحة بإحصاءات إضافية وتعتبرها سلسلة زمنية ونتيجة لذلك ، لا يتم الحصول على المجموعات حول ما يفعله المستخدمون ، ولكن حول
عدد المرات التي يفعلون فيها.
ملاحظة مهمة: تمتلك الشبكة "جوهر" أكثر المستخدمين اتصالًا ونشاطًا بإحكام مع حجم 1.7 مليون شخص. في الوقت نفسه ، يعتمد سلوك المستخدم والاحتفاظ به بشكل كبير على ما إذا كان يمكنه التواصل مع شخص من "القلب".
ثم نبدأ في بناء نموذج. لنأخذ الوافدين الجدد بعد أسبوعين (511 ألف) ، وميزات بسيطة وشبكات الأنا (الحجم والكثافة) ، ومعرفة ما إذا كانوا مرتبطين بـ "القلب" ، وما إلى ذلك. نحن نطعم سلوك المستخدم باستخدام LSTM ونحصل على دقة توقعات التدفق أعلى قليلاً من توقعات تسجيل الدخول (بنسبة 7-8٪). ولكن بعد ذلك يبدأ المرح. لأخذ تفاصيل المجموعات الفردية بعين الاعتبار ، سنقوم بتدريب العديد من LSTMs بالتوازي ، وسنرفق طبقة اهتمام في الأعلى. ونتيجة لذلك ، يبدأ هذا المخطط في العمل على حد سواء للتكتل (أي من LSTM تلقى الاهتمام) وعلى توقعات التدفق. إنه يعطي زيادة أخرى + 5-7 ٪ في الجودة ، ويبدو logreg شاحبًا بالفعل. لكن! في الواقع ، سيكون من الإنصاف مقارنته مع logreg مجزأة تم تدريبه بشكل منفصل للمجموعات (والتي يمكن الحصول عليها بطرق أبسط).
سألت عن قابلية التفسير: بعد كل شيء ، غالبًا ما يتم التنبؤ بالتدفقات الخارجية ليس من أجل الحصول على توقعات ، ولكن من أجل فهم العوامل التي تؤثر عليها. كان المتحدث على استعداد واضح لهذا السؤال: لهذا ، يتم استخدام وتحليل مجموعات مخصصة ، من تلك التي تكون فيها توقعات التدفق أعلى تتميز عن غيرها.
تمثيل المستخدم العالمي
يتحدث شباب علي بابا عن كيفية بناء جمعيات المستخدمين. اتضح أن وجود العديد من عمليات إرسال المستخدم أمر سيئ: لم يتم الانتهاء من العديد منها ، يتم إهدار القوى. تمكنوا من تقديم عرض تقديمي عالمي وإظهار أنه يعمل بشكل أفضل. بطبيعة الحال على الشبكات العصبية. الهندسة المعمارية قياسية إلى حد ما ، بالفعل في شكل أو آخر تم وصفه مرارًا وتكرارًا في المؤتمر. يتم إدخال الحقائق من سلوك المستخدم في الإدخال ، ونحن نبني عليها ، ونقدمها كلها إلى LSTM ، ونعلق طبقة انتباه في الأعلى ، وبجانبها شبكة إضافية للميزات الثابتة ، تتوج بمهام متعددة (في الواقع ، العديد من الشبكات الصغيرة لمهمة محددة) . نقوم بتدريب كل هذا معًا ، وسيكون الناتج باهتمام هو تضمين المستخدم.
هناك العديد من الإضافات الأكثر تعقيدًا: بالإضافة إلى الاهتمام البسيط ، فإنها تضيف شبكة اهتمام "متعمقة" ، وتستخدم أيضًا نسخة معدلة من LSTM - خاصية LSTM ذات البوابة
المهام التي يتم تشغيل كل هذا حولها: توقع نسبة النقر إلى الظهور ، توقع تفضيل السعر ، تعلم الترتيب ، الموضة بعد التنبؤ ، توقع تفضيلات المتجر. تتضمن مجموعة البيانات لمدة 10 أيام 6 * 10
9 أمثلة للتدريب.
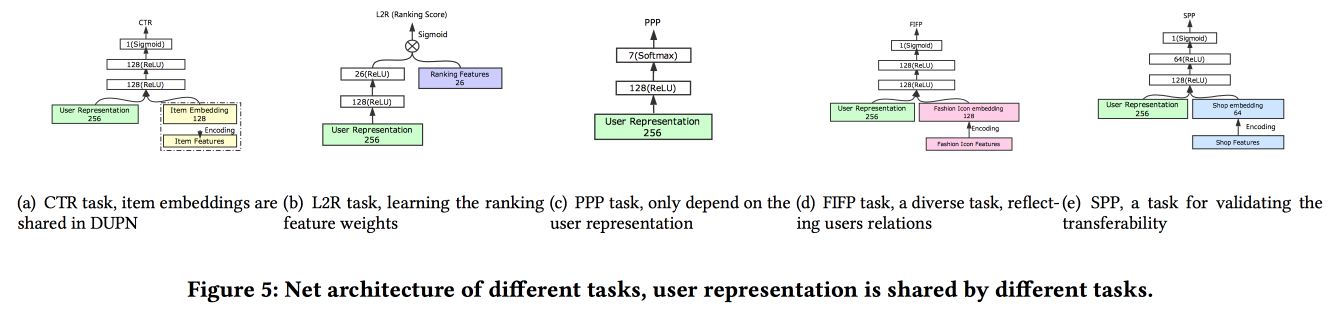
ثم كان هناك شخص غير متوقع: قاموا بتدريب كل هذا على TensorFlow ، على مجموعة وحدة المعالجة المركزية من 2000 جهاز مع 15 نواة لكل منها ، يستغرق الأمر 4 أيام لإكمال البيانات لمدة 10 أيام. لذلك ، يستمرون في إعادة التدريب يومًا بعد يوم (10 ساعات في هذه المجموعة). لم يكن لدى GPU / FPGA الوقت المطلوب للسؤال :(. تتم إضافة مهمة جديدة إما من خلال إعادة التدريب ككل ، أو من خلال إعادة تدريب شبكة ضحلة (ضبط netwrok الدقيق). في وقت التشغيل للاستدلال ، يتم تخزين العروض (الإخراج مع الانتباه لمستخدمين محددين) ويتم حساب رؤوس الشبكات فقط من أجل أظهر اختبار A / B للمهام المحددة زيادة بنسبة 2-3٪ لمختلف المؤشرات.
التنبؤ بعائد المنتج الإلكتروني
يتنبأون بإعادة البضائع من قبل المستخدم بعد الشراء ،
يتم تقديم
العمل من قبل شركة IBM. لسوء الحظ ، لا يوجد نص في الوصول المفتوح حتى الآن. تعد إعادة البضائع مشكلة خطيرة تبلغ قيمتها 200 مليار دولار سنويًا. لبناء توقعات للعائدات ، يستخدم نموذجًا للفرط الهجائي الذي يربط المنتجات والسلال ، باستخدام هذه السلة التي يحاولون العثور على أقربها بواسطة hypergraph ، وبعد ذلك يقدرون احتمالية العودة. لمنع العودة ، فإن المتجر عبر الإنترنت لديه العديد من الاحتمالات ، على سبيل المثال ، تقديم خصم لإزالة منتجات معينة من السلة.
لاحظنا على الفور أن هناك فرقًا كبيرًا بين السلال ذات التكرارات (على سبيل المثال ، قميصان متطابقان بأحجام مختلفة) وبدون ذلك ، يجب أن نبني على الفور نماذج مختلفة لهاتين الحالتين.
تسمى الخوارزمية العامة HyperGo:
- نحن نبني hypergraph لتمثيل المشتريات والعائدات مع معلومات من المستخدم والمنتج والسلة.
- بعد ذلك ، نستخدم قطع الرسم البياني المحلي استنادًا إلى المشي العشوائي للحصول على معلومات محلية للتنبؤ.
- نحن نعتبر السلال بشكل منفصل مع أخذ وبدون أخذ.
- نستخدم طرق بايزي لتقييم تأثير منتج فردي في السلة.
مقارنة جودة توقعات العائد مع KNN للسلال ، المرجحة وفقًا لجاكارد KNN ، مع التقنين بعدد التكرارات ، نحصل على زيادة في النتيجة. ظهر رابط إلى GitHub على الشرائح ، لكنهم لم يتمكنوا من العثور على مصدرهم ، ولا يوجد رابط في المقالة.
OpenTag: فتح استخراج قيمة السمة من ملفات تعريف المنتج
عمل مثير للاهتمام بما فيه الكفاية من الأمازون. التحدي: تعدين الحقائق المختلفة لأليكسا للإجابة على الأسئلة بشكل أفضل. يقولون كم هو معقد كل شيء ، الأنظمة القديمة لا تعرف كيفية العمل مع كلمات جديدة ، غالبًا ما تتطلب عددًا كبيرًا من القواعد المكتوبة بخط اليد والاستدلال ، والنتائج حتى. بالطبع ، ستساعد الشبكات العصبية ذات بنية الاهتمام المألوفة والمدمجة بالفعل على حل جميع المشاكل ، ولكننا سنجعل LSTM مزدوجًا ، وسنقوم أيضًا بتدوين
الحقل العشوائي الشرطي في الأعلى.

سنحل مشكلة وضع علامات على سلسلة من الكلمات. ستوضح العلامات من أين نبدأ وننهي تسلسلات من سمات معينة (على سبيل المثال ، طعم وتكوين طعام الكلاب) ، وسيحاول LSTM التنبؤ بها. يتم استخدام التدريب النموذجي النشط كقطعة ونحور نحو الميكانيكي التركي. لتحديد الأمثلة التي يجب إرسالها لمزيد من الترميز ، استخدم التوجيه "لأخذ تلك الأمثلة حيث يتم تبديل العلامات في الغالب بين العصور".
التعلم ونقل معرفات التمثيل في التجارة الإلكترونية
في عملهم
، يعود الزملاء من علي بابا مرة أخرى إلى قضية بناء التضمين ، هذه المرة لا ينظرون فقط إلى المستخدمين ، ولكن إلى المعرفات من حيث المبدأ: للمنتجات والعلامات التجارية والفئات والمستخدمين ، إلخ. يتم استخدام جلسات التفاعل كمصدر للبيانات ، كما يتم أخذ السمات الإضافية في الاعتبار. يتم استخدام Skipgrams كخوارزمية رئيسية.
المتحدث لديه نطق ثقيل جدا بلكنة صينية قوية ، لفهم ما يحدث يكاد يكون مستحيلا. إحدى "حيل" العمل هي آليات نقل التمثيلات مع نقص المعلومات ، على سبيل المثال ، من العناصر إلى المستخدم من خلال حساب المتوسط (بسرعة ، لست بحاجة إلى تعلم النموذج بأكمله). من العناصر القديمة ، يمكنك تهيئة عناصر جديدة (على ما يبدو عن طريق تشابه المحتوى) ، بالإضافة إلى نقل وجهة نظر المستخدم من مجال (إلكترونيات) إلى مجال آخر (ملابس).
بشكل عام ، ليس من الواضح تمامًا أين توجد الجدة هنا ، على ما يبدو ، يجب حفر التفاصيل ؛ بالإضافة إلى ذلك ، ليس من الواضح كيف يقارن هذا بالقصة السابقة حول التمثيلات الموحدة للمستخدمين.
اختيار المعلمات على الإنترنت لمشاكل التصنيف على شبكة الإنترنت
عمل مثير جدا للاهتمام من الأصدقاء على LinkedIn. جوهر العمل هو تحديد المعلمات المثلى لعملية الخوارزمية على الإنترنت ، مع مراعاة العديد من الأهداف المتنافسة. كنطاق ، ضع في اعتبارك الشريط وحاول زيادة عدد الجلسات لأنواع معينة:
- جلسة مع بعض الإجراءات الفيروسية (VA).
- استئناف جلسة التقديم (JA).
- تفاعل المحتوى في جلسة التغذية (EFS).
دالة الترتيب في الخوارزمية هي متوسط مرجح لتوقعات التحويل لهذه الأهداف الثلاثة. في الواقع ، الأوزان هي تلك المعلمات التي سنحاول تحسينها عبر الإنترنت. في البداية ، يصيغون مهمة عمل على أنها "تعظيم عدد جلسات الفيروس مع الحفاظ على النوعين الآخرين على الأقل عند مستوى معين" ، ولكن بعد ذلك يقومون بتحويلهم قليلاً لسهولة التحسين.
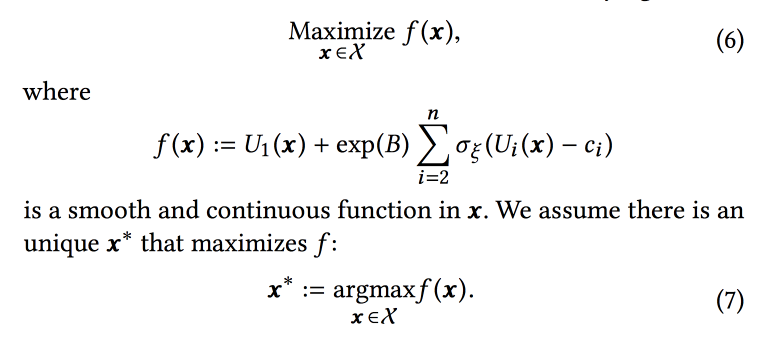
نقوم بمحاكاة البيانات مع مجموعة من التوزيعات ذات الحدين (سيقوم المستخدم بالتحويل إلى الهدف المطلوب أم لا ، بعد رؤية الشريط بمعلمات معينة) ، حيث يكون احتمال النجاح مع المعلمات المعينة هو
عملية غوسية (خاصة بكل نوع من أنواع التحويل). بعد ذلك ، نستخدم أداة أخذ
العينات من Thompson مع
ماكينات الألعاب "
القوية بشكل غير محدود" لتحديد المعلمات المثلى (ليس عبر الإنترنت ، ولكن في وضع عدم الاتصال على البيانات التاريخية ، وذلك لفترة طويلة). يقدمون بعض النصائح: استخدم نقاط جريئة لبناء الشبكة الأولية وتأكد من إضافة أخذ عينات
إبسيلون-الجشع (مع احتمال محاولة إبسيلون نقطة عشوائية في الفضاء) ، وإلا يمكنك تجاوز الحد الأقصى العالمي.
يحاكيون أخذ العينات في وضع عدم الاتصال مرة واحدة في الساعة (تحتاج إلى الكثير من العينات) ، والنتيجة هي توزيع معين للمعلمات المثلى. علاوة على ذلك ، عندما يدخل مستخدم من هذا التوزيع ، فإنه يأخذ معلمات محددة لإنشاء الشريط (من المهم القيام بذلك بشكل متسق مع البذور من معرف المستخدم للتهيئة بحيث لا يتغير شريط المستخدم بشكل جذري).
وفقًا لنتائج تجربة A / B ، فقد حصلوا على زيادة في إرسال السير الذاتية بنسبة 12٪ وإعجابات بنسبة 3٪. شارك بعض الملاحظات:
- من الأسهل أخذ عينة أكثر من محاولة إضافة المزيد من المعلومات إلى النموذج (على سبيل المثال ، يوم الأسبوع / الساعة).
- نحن نفترض استقلالية الأهداف في هذا النهج ، ولكن من غير الواضح ما إذا كانت (بالأحرى لا). ومع ذلك ، يعمل النهج.
- يجب أن تحدد الأعمال الأهداف والعتبات.
- من المهم استبعاد شخص من العملية والسماح له بعمل شيء مفيد.
بالقرب من التحسين الفوري للإعلام القائم على النشاط
عمل آخر من LinkedIn ، هذه المرة حول إدارة الإشعارات. لدينا أشخاص وأحداث وقنوات توصيل وأهداف طويلة المدى لزيادة تفاعل المستخدم دون سلبية كبيرة في شكل شكاوى وإلغاء الاشتراك من عمليات الدفع. المهمة مهمة وصعبة ، وعليك أن تفعل كل شيء بشكل صحيح: إلى الأشخاص المناسبين في الوقت المناسب لإرسال المحتوى المناسب على القناة المناسبة وبالكمية المناسبة.
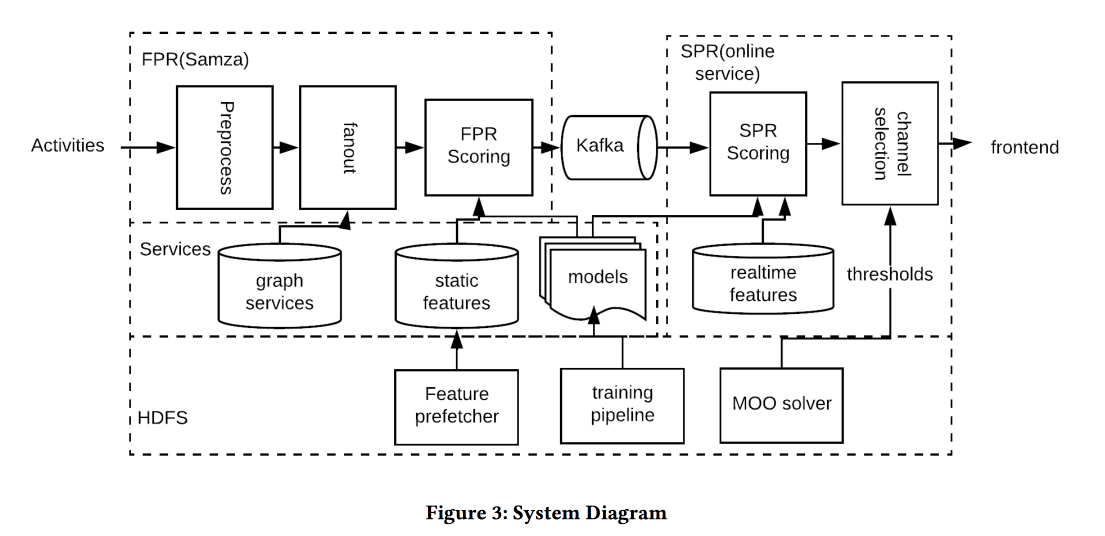
بنية النظام في الصورة أعلاه ، جوهر ما يحدث هو تقريبا ما يلي:
- نقوم بتصفية أي بريد مزعج عند الإدخال.
- الأشخاص المناسبون: خوذة لكل شخص مرتبط بقوة بالمؤلف / المحتوى ، وتحقيق التوازن بين عتبة قوة التواصل وإدارة التغطية والأهمية.
- الوقت المناسب: إرسال المحتوى فورًا ، والذي يعتبر الوقت مهمًا (أحداث الأصدقاء) ، ويمكن الاحتفاظ بالباقي لقنوات أقل ديناميكية.
- المحتوى الصحيح: استخدم logreg! يتم بناء نموذج تنبؤي للنقرة على كومة من العلامات ، بشكل منفصل للحالة عندما يكون الشخص في التطبيق وعندما لا يكون.
- القناة الصحيحة: لقد حددنا عتبات مختلفة للملاءمة ، والأكثر صرامة للدفع ، أقل - إذا كان المستخدم الآن في التطبيق ، حتى أقل - للبريد (يحتوي على جميع أنواع الملخصات / الإعلانات).
- الحجم الصحيح: نموذج الختان بالحجم في المخرج ، كما أنه ينظر في مدى الصلة بالموضوع ، فمن المستحسن القيام بذلك بشكل فردي (العتبة الجيدة هي الحد الأدنى من النقاط المرسلة خلال الأيام القليلة الماضية)
في اختبار A / B حصل على زيادة قليلة في عدد الجلسات.
التخصيص في الوقت الحقيقي باستخدام التضمينات لترتيب البحث في Airbnb
وكانت هذه
أفضل ورقة تطبيق من AirBnB. الهدف: تحسين إصدار المواضع ونتائج البحث. نقرر من خلال بناء عمليات دمج المواضع والمستخدمين في مساحة واحدة من أجل تقييم التشابه بشكل أكبر. من المهم أن نتذكر أن هناك سجل طويل المدى (تفضيلات المستخدم) وقصير المدى (نية المستخدم / الجلسة الحالية).
بدون مزيد من اللغط ، نستخدم لبناء مواضع word2vec على تسلسلات النقر في جلسات البحث (جلسة واحدة - مستند واحد). ولكن ما زلنا نقوم ببعض التعديلات (KDD ، بعد كل شيء):
- نأخذ الجلسة التي كان فيها تحفظ.
- ما هو محجوز في نهاية المطاف ، نحمله كسياق عالمي لجميع عناصر الجلسة أثناء تحديث W2V.
- يتم أخذ عينات سلبية في التدريب في نفس المدينة.

يتم التحقق من فعالية هذا النموذج بثلاث طرق قياسية:
- التحقق من عدم الاتصال بالإنترنت: مدى السرعة التي يمكننا من خلالها رفع الفندق المناسب في جلسة البحث.
- الاختبار من قبل المقيّمين: قام ببناء أداة خاصة لتصور تلك المماثلة.
- اختبار A / B: المفسد ، نما نسبة النقر إلى الظهور بشكل ملحوظ ، لم تزد الحجوزات ، لكنها تحدث الآن في وقت سابق
نحن نحاول ترتيب نتائج نتائج البحث ليس فقط في وقت مبكر ، ولكن أيضًا لإعادة الترتيب (وبالتالي في الوقت الحقيقي) عند استلام رد - النقر على جملة واحدة وتجاهل أخرى. يتمثل النهج في جمع الأماكن التي تم النقر عليها وتجاهلها في مجموعتين ، والعثور على عمليات التضمين في كل مركز مركزي (توجد صيغة خاصة) ، ثم في التصنيف نرفع مثل النقرات ، مثل انخفاض مثل التخطي.
تلقى اختبار A / B زيادة في الحجوزات ، وصمد النهج لاختبار الزمن: تم اختراعه قبل عام ونصف ولا يزال يدور في الإنتاج.
وإذا كنت بحاجة إلى البحث في مدينة أخرى؟ لن تتمكن من تحديد الأولويات من خلال النقرات ، ولا توجد معلومات حول موقف المستخدمين من الأماكن في هذه التسوية. للتغلب على هذه المشكلة ، نقدم "تضمين المحتوى". أولاً ، سنقوم بإنشاء مساحة منفصلة بسيطة من العلامات (رخيصة / باهظة الثمن ، في الوسط / في الضواحي ، وما إلى ذلك) بحجم حوالي 500 ألف نوع (للأماكن والأشخاص). بعد ذلك ، نبني التضمينات حسب النوع. عند التعلم لا تنسى أن تضيف سلبيات واضحة على الرفض (عندما لم يؤكد صاحب المكان الحجز).
الشبكات العصبية التلافيفية البيانية لأنظمة التوصية على نطاق الويب
العمل من موقع Pinterest بناءً على توصية الدبابيس. نحن نعتبر دبابيس مستخدم الرسم البياني الثنائي ونضيف ميزات الشبكة إلى التوصيات. الرسم البياني كبير جدًا - 3 مليارات دبابيس ، 16 مليار تفاعل ؛ تعذر إنشاء تضمين الرسم البياني الكلاسيكي. ,
GraphSAGE , ( , message passing),
PinSAGE . , , .
« »:
- max margin loss.
- CPU/GPU: CPU ( GPU ) GPU. , .
- , random walk-.
- Curriculum Learning: hard negative-. .
- Map reduce, .
, , . , /-.
Q&R: A Two-Stage Approach Toward Interactive Recommendation
« , , ?» — YouTube
. : « ?». «» (, , YouTube , ).
YouTube Video-RNN, ID . , ID , (post fusion). (- -
GRU , LSTM LSTM).

7 , 8-, . , 8 % , --. /-
interleaving- +0,7 % , +1,23 % .
: 18 % , +4 % .
Graph and social nets
, , , .
Graph Classification using Structural Attention
, « ». , , .
, , .
, LSTM , attention-, , . . , , , .
: , , . attention, , LSTM self-attention, ( ). «», , .
, baseline — . ,
TreeLSTM .
SpotLight: Detecting Anomalies in Streaming Graphs
, , -, , . « ». , , .
«» . - - , .
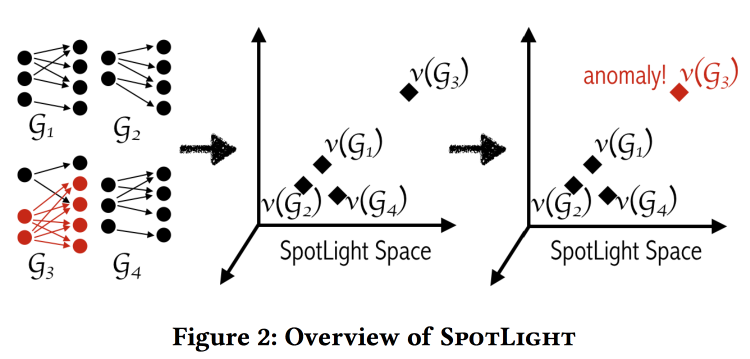
: , . . . , / .
, .
labeled DARPA dataset . , baseline- (.. ).
Adversarial Attacks on Graph Networks
. Adversary , , ..: / . , — ( — )? .
, :
- «» .
- «» .
- «» .
- , (poisoning).
. , , , — . . .
, unnoticeability: , ?
Multi-Round Influence maximization
. , , .
, ( , ).
-- :
- : , .
- : , .
- - : inffluencer- . , .
Reverse-Reachable sets: inffluencer-, , .
EvoGraph: An Effective and Efficient Graph Upscaling Method for Preserving Graph Properties
. ,
, .
, , power law. , , «» , : «» .

, , .
.
data science . في الحقيقة. , . .
All models are wrong, but some are useful — data science, , , . «» ( , , adversarial ..)
www.embo.org/news/articles/2015/the-numbers-speak-for-themselves — (overfitting, selection bias, , ..)
1762
The Equitable Life Assurance Society , .
تواجه شركات التأمين الآن وقتًا عصيبًا: في عام 2011 ، تم حظر التمييز على أساس الجنس أخيرًا ، والآن لا يمكن أخذ الجنس في الاعتبار في التأمين (وهو أمر صعب للغاية - حتى إذا قمت بإخفاء صراحة لميزة "الجنس" ، فمن المرجح أن النموذج يقترب منه لأسباب أخرى). أدى هذا إلى تأثير مثير للاهتمام في المملكة المتحدة:- تقود النساء بدقة أكبر ويقل احتمال تعرضهن للحوادث ، لذا كان التأمين أرخص بالنسبة لهن.
- بعد التسوية ، ارتفعت تكلفة التأمين على النساء ، وانخفضت بالنسبة للرجال.
- يعمل السوق: ونتيجة لذلك ، هناك عدد أكبر من الرجال وعدد أقل من النساء على الطرق.
- مع انخفاض متوسط "دقة" السائقين على الطرق ، كان هناك المزيد من الحوادث.
- وبعد ذلك ، بدأ التأمين بالطبع في الارتفاع في الأسعار.
- بدأ التأمين على السفر في غسل السائقين الأنيقين بشكل أكثر صعوبة.
ونتيجة لذلك ، حصلوا على "دوامة الموت".
يردد هذا الموضوع الأداء الافتتاحي لليوم. F - الإنصاف ، هذه قلعة سحابية لا يمكن الوصول إليها. تتعلم نماذج ML فصل الأمثلة (بما في ذلك الأشخاص) في مساحة السمات ، وبالتالي لا يمكن أن تكون "عادلة" حسب التعريف.