
كثير من الأشخاص الذين يدرسون التعلم الآلي على دراية بمشروع OpenAI ، أحد مؤسسيها هو Elon Musk ،
ويستخدمون منصة
OpenAI Gym كوسيلة لتدريب نماذج شبكاتهم العصبية.
تحتوي صالة الألعاب الرياضية على مجموعة كبيرة من البيئات ، بعضها أنواع مختلفة من المحاكاة البدنية: حركات الحيوانات والبشر
والروبوتات . تستند هذه المحاكاة إلى محرك
MuJoCo الفيزيائي ، وهو مجاني للأغراض التعليمية والعلمية.
في هذه المقالة ، سنقوم بإنشاء محاكاة فيزيائية بسيطة للغاية مشابهة لبيئة OpenAI Gym ، ولكن استنادًا إلى محرك الفيزياء المجاني Bullet (
PyBullet ). وكذلك إنشاء وكيل للعمل مع هذه البيئة.
PyBullet هي وحدة بيثون لخلق بيئة محاكاة فيزيائية تعتمد على محرك فيزياء الفيزياء. غالبًا ما يتم استخدامه ، مثل MuJoCo ، كإثارة للروبوتات المختلفة ، المهتمين بالحبر ، هناك
مقالة تحتوي على أمثلة حقيقية.
هناك
QuickStartGuide جيد جدًا لـ PyBullet يحتوي على روابط إلى أمثلة على صفحة المصدر على
GitHub .
يتيح لك PyBullet تحميل النماذج التي تم إنشاؤها بالفعل بتنسيق URDF أو SDF أو MJCF. توجد في المصادر مكتبة من
النماذج بهذه التنسيقات ، بالإضافة إلى بيئات جاهزة تمامًا لمحاكاة
الروبوتات الحقيقية.في حالتنا ، نحن أنفسنا سنخلق البيئة باستخدام PyBullet. ستكون واجهة البيئة
مشابهة لواجهة OpenAI Gym. بهذه الطريقة يمكننا تدريب وكلائنا في بيئتنا وفي بيئة الجمنازيوم.
يمكن رؤية جميع الرموز (iPython) ، بالإضافة إلى تشغيل البرنامج في
Google Colaboratory .
البيئة
تتكون بيئتنا من كرة يمكن أن تتحرك على طول المحور الرأسي ضمن نطاق معين من الارتفاعات. للكرة كتلة ، وتعمل الجاذبية عليها ، ويجب على الوكيل ، من خلال التحكم في القوة العمودية المطبقة على الكرة ، أن يصل بها إلى الهدف. يتغير ارتفاع الهدف مع كل إعادة تشغيل للتجربة.

المحاكاة بسيطة للغاية ، وفي الواقع يمكن اعتبارها محاكاة لبعض المحرك الأساسي.
للعمل مع البيئة ، يتم استخدام 3 طرق:
إعادة تعيين (إعادة تشغيل التجربة وإنشاء جميع كائنات البيئة) ،
خطوة (تطبيق الإجراء المحدد والحصول على حالة البيئة الناتجة) ،
تقديم (عرض مرئي للبيئة).
عند تهيئة البيئة ، من الضروري ربط جسمنا بالمحاكاة الفيزيائية. هناك خياران للاتصال: مع واجهة رسومية (GUI) وبدون (DIRECT). في حالتنا ، هو DIRECT.
pb.connect(pb.DIRECT)
إعادة تعيين
مع كل تجربة جديدة ، نقوم بإعادة ضبط محاكاة
pb.resetSimulation () وإنشاء جميع كائنات البيئة مرة أخرى.
في PyBullet ، تحتوي الكائنات على شكلين:
شكل تصادم
وشكل مرئي . يتم استخدام الأول من قبل المحرك المادي لحساب تصادم الأشياء ، ولتسريع حساب الفيزياء ، عادة ما يكون له شكل أبسط من كائن حقيقي. والثاني اختياري ، ويستخدم فقط عند تشكيل صورة الكائن.
يتم جمع النماذج في كائن واحد (الجسم) -
MultiBody . يمكن أن يتكون الجسم من شكل واحد (
CollisionShape / Visual Shape pair) ، كما في حالتنا ، أو عدة.
بالإضافة إلى الأشكال التي يتكون منها الجسم ، من الضروري تحديد كتلته وموقعه واتجاهه في الفضاء.
بضع كلمات حول الأجسام متعددة الأغراض.كقاعدة ، في الحالات الحقيقية ، لمحاكاة الآليات المختلفة ، يتم استخدام الهيئات التي تتكون من العديد من الأشكال. عند إنشاء الجسم ، بالإضافة إلى الشكل الأساسي للاصطدامات والتصور ، يتم نقل الجسم سلاسل من أشكال الكائنات الفرعية (
الروابط ) ، وموقعها واتجاهها بالنسبة إلى الكائن السابق ، بالإضافة إلى أنواع الاتصالات (المفاصل) للأشياء فيما بينها (
المفصل ). يمكن أن تكون أنواع التوصيلات ثابتة أو منشورية (انزلاق على نفس المحور) أو دورانية (تدور على محور واحد). يسمح لك آخر نوعين من التوصيلات بتعيين معلمات الأنواع المقابلة من المحركات (
JointMotor ) ، مثل قوة التمثيل أو السرعة أو عزم الدوران ، وبالتالي محاكاة محركات "مفاصل" الروبوت. مزيد من التفاصيل في
الوثائق .
سنقوم بإنشاء 3 أجسام: الكرة والطائرة (الأرض) ومؤشر الهدف. سيكون للجسم الأخير فقط شكل تصور وكتلة صفرية ، وبالتالي لن يشارك في التفاعل الجسدي بين الأجسام:
تحديد خطورة ووقت خطوة المحاكاة.
pb.setGravity(0,0,-10) pb.setTimeStep(1./60)
لمنع الكرة من السقوط مباشرة بعد بدء المحاكاة ، نوازن الجاذبية.
pb_force = 10 * PB_BallMass pb.applyExternalForce(pb_ballId, -1, [0,0,pb_force], [0,0,0], pb.LINK_FRAME)
خطوة
يختار الوكيل الإجراءات بناءً على الحالة الحالية للبيئة ، وبعد ذلك يستدعي طريقة
الخطوة ويتلقى حالة جديدة.
يتم تحديد نوعين من الإجراءات: زيادة ونقص القوة المؤثرة على الكرة. حدود القوة محدودة.
بعد تغيير القوة المؤثرة على الكرة ، يتم إطلاق خطوة جديدة من المحاكاة المادية
pb.stepSimulation () ، ويتم إرجاع المعلمات التالية إلى الوكيل:
المراقبة - الملاحظات (حالة البيئة)
مكافأة - مكافأة للعمل المثالي
تم - علم نهاية التجربة
معلومات -
معلومات إضافية
كحالة البيئة ، يتم إرجاع 3 قيم: المسافة إلى الهدف ، والقوة الحالية المطبقة على الكرة ، وسرعة الكرة. يتم إرجاع القيم بشكل طبيعي (0..1) ، لأن المعلمات البيئية التي تحدد هذه القيم يمكن أن تختلف اعتمادًا على رغبتنا.
تكون مكافأة الإجراء المثالي هي 1 إذا كانت الكرة قريبة من الهدف (ارتفاع الهدف زائد / ناقص قيمة
التدوير المقبولة
TARGET_DELTA ) و 0 في حالات أخرى.
تكتمل التجربة إذا خرجت الكرة خارج المنطقة (سقطت على الأرض أو طارت عاليا). إذا وصلت الكرة إلى الهدف ، تنتهي التجربة أيضًا ، ولكن فقط بعد وقت معين (
STEPS_AFTER_TARGET خطوات التجربة). وبالتالي ، يتم تدريب وكيلنا ليس فقط للتحرك نحو الهدف ، ولكن أيضًا للتوقف وقربه. بالنظر إلى أن المكافأة عندما تكون قريبًا من الهدف هي 1 ، يجب أن تكون التجربة الناجحة تمامًا مكافأة إجمالية تساوي
STEPS_AFTER_TARGET .
كمعلومات إضافية لعرض الإحصائيات ، يتم إرجاع إجمالي عدد الخطوات التي تم تنفيذها في التجربة ، بالإضافة إلى عدد الخطوات التي تم تنفيذها في الثانية.
تقديم
يحتوي PyBullet على خيارين لعرض الصور - يعتمد GPU على OpenGL ووحدة المعالجة المركزية على أساس TinyRenderer. في حالتنا ، يمكن تنفيذ وحدة المعالجة المركزية فقط.
للحصول على الإطار الحالي للمحاكاة ، من الضروري تحديد
مصفوفة الأنواع ومصفوفة الإسقاط ، ثم الحصول على صورة
RGB لحجم معين من الكاميرا.
camTargetPos = [0,0,5]
في نهاية كل تجربة ، يتم إنشاء مقطع فيديو بناءً على الصور التي تم جمعها.
ani = animation.ArtistAnimation(plt.gcf(), render_imgs, interval=10, blit=True,repeat_delay=1000) display(HTML(ani.to_html5_video()))
وكيل
تم أخذ كود مستخدم GitHub
jaara كأساس للوكيل ، كمثال بسيط ومفهوم لتنفيذ التدريب التعزيزي لبيئة الصالة الرياضية.
يحتوي العامل على شيئين:
الذاكرة - مخزن لتشكيل أمثلة التدريب
والدماغ نفسه هو الشبكة العصبية التي يدربها.
تم إنشاء الشبكة العصبية المدربة على TensorFlow باستخدام مكتبة Keras ، والتي تم
تضمينها مؤخرًا بشكل كامل في TensorFlow.
تحتوي الشبكة العصبية على بنية بسيطة - 3 طبقات ، أي طبقة مخفية واحدة فقط.
تحتوي الطبقة الأولى على 512 خلية عصبية ولها عدد من المدخلات يساوي عدد معلمات حالة الوسط (3 معلمات: المسافة إلى الهدف وقوة الكرة وسرعتها). الطبقة المخفية لها بعد يساوي الطبقة الأولى - 512 خلية عصبية ، عند الخرج يتم توصيلها بطبقة الإخراج. يتوافق عدد الخلايا العصبية لطبقة الإخراج مع عدد الإجراءات التي يقوم بها الوكيل (إجراءان: تقليل وزيادة قوة التمثيل).
وبالتالي ، يتم توفير حالة النظام لمدخلات الشبكة ، وعند الإخراج لدينا فائدة لكل من الإجراءات.
بالنسبة للطبقتين
الأوليين ، يتم استخدام
ReLU (الوحدة الخطية
المصححة )
كوظائف تنشيط ،
للأخيرة -
دالة خطية (مجموع قيم الإدخال بسيطة).
كدالة للخطأ ،
MSE (خطأ قياسي) ، كخوارزمية تحسين -
RMSprop (
انتشار الجذر التربيعي المربع).
model = Sequential() model.add(Dense(units=512, activation='relu', input_dim=3)) model.add(Dense(units=512, activation='relu')) model.add(Dense(units=2, activation='linear')) opt = RMSprop(lr=0.00025) model.compile(loss='mse', optimizer=opt)
بعد كل خطوة محاكاة ، يحفظ الوكيل نتائج هذه الخطوة في شكل قائمة
(ق ، أ ، ص ، ق) :
ق - الملاحظة السابقة (حالة البيئة)
أ - الإجراء المكتمل
ص - مكافأة وردت للعمل المنجز
s_ - الملاحظة النهائية بعد الإجراء
بعد ذلك ، يتلقى الوكيل من الذاكرة مجموعة عشوائية من الأمثلة للفترات السابقة ويشكل حزمة تدريب (
دفعة ).
تؤخذ الحالة الأولية للخطوات العشوائية المحددة من الذاكرة كقيم إدخال (
X ) للرزمة.
يتم حساب القيم الفعلية لمخرجات التعلم (
Y ' ) على النحو التالي: عند إخراج (
Y ) للشبكة العصبية لـ s ستكون هناك قيم
للدالة Q لكل من الإجراءات
Q (s) . من هذه المجموعة ، اختار الوكيل الإجراء بأعلى قيمة
Q (s ، a) = MAX (Q (s)) ، وأكمله وحصل على الجائزة. ستكون قيمة
Q الجديدة للإجراء المحدد
a Q (s، a) = Q (s، a) + DF * r ، حيث
DF هو عامل الخصم. ستظل قيم المخرجات المتبقية كما هي.
STATE_CNT = 3 ACTION_CNT = 2 batchLen = 32
يتم تدريب الشبكة على العبوة المشكلة
self.model.fit(x, y, batch_size=32, epochs=1, verbose=0)
بعد اكتمال التجربة ، يتم إنشاء مقطع فيديو
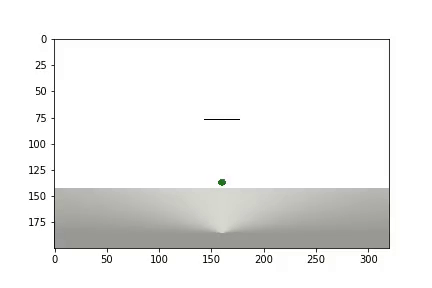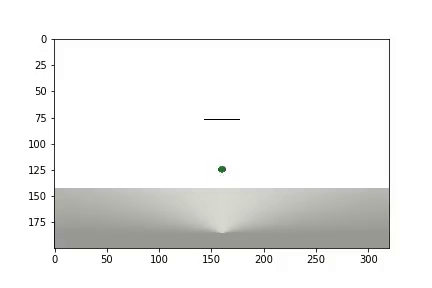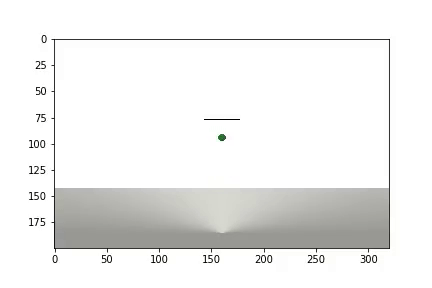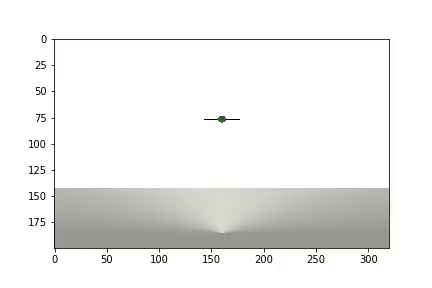
ويتم عرض الإحصائيات
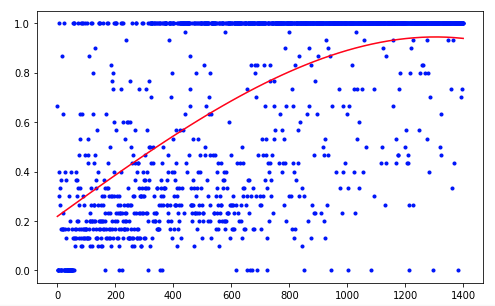
يحتاج الوكيل إلى 1200 تجربة لتحقيق نتيجة 95٪ (عدد الخطوات الناجحة). وبحلول التجربة الخمسين ، تعلم الوكيل تحريك الكرة إلى الهدف (تختفي التجارب غير الناجحة).
لتحسين النتائج ، يمكنك محاولة تغيير حجم طبقات الشبكة (LAYER_SIZE) أو معلمة عامل الخصم (GAMMA) أو معدل الانخفاض في احتمال اختيار إجراء عشوائي (LAMBDA).
وكيلنا لديه أبسط بنية - DQN (Deep Q-Network). في مثل هذه المهمة البسيطة ، يكفي الحصول على نتيجة مقبولة.
باستخدام ، على سبيل المثال ، يجب أن توفر بنية DDQN (Double DQN) تدريبًا أكثر سلاسة ودقة. وستكون شبكة RDQN (Recurrent DQN) قادرة على تتبع أنماط التغير البيئي بمرور الوقت ، مما سيجعل من الممكن التخلص من معلمة سرعة الكرة ، مما يقلل من عدد معلمات إدخال الشبكة.
يمكنك أيضًا توسيع المحاكاة لدينا بإضافة كتلة كرة متغيرة أو زاوية ميل حركتها.
لكن هذه هي المرة القادمة.