قبل عام ، أضفنا إلى وكيلنا مجموعة من المقاييس من سمات قرص SMART على خوادم العملاء. في تلك اللحظة ، لم نقم بإضافتها إلى الواجهة وعرضها للعملاء. الحقيقة هي أننا لا نأخذ المقاييس من خلال smartctl ، ولكننا نسحب ioctl مباشرة من الشفرة بحيث تعمل هذه الوظيفة بدون تثبيت smartmontools على خوادم العملاء.
لا يقوم الوكيل بإزالة جميع السمات المتاحة ، ولكن فقط الأكثر أهمية في رأينا وأقل السمات الخاصة بالبائع (وإلا ، فسيتعين عليك الحفاظ على قاعدة قرص مشابهة لـ smartmontools).
الآن ، توصلت الأيدي أخيرًا إلى النقطة للتحقق مما صورناه هناك. وتقرر البدء بالسمة "مؤشر تآكل الوسائط" ، والتي توضح النسبة المئوية لمورد تسجيل SSD المتبقي. تحت القص بعض القصص في الصور حول كيفية إنفاق هذا المورد في الحياة الحقيقية على الخوادم.
هل هناك قتلى SSDs؟
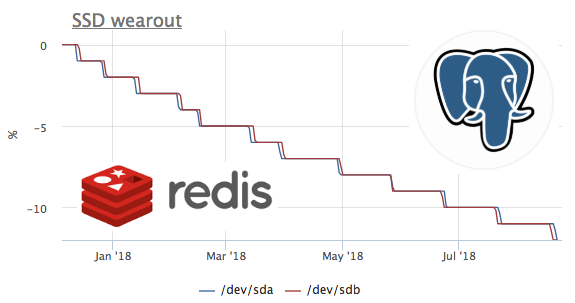
ويعتقد أن ssds الجديدة الأكثر إنتاجية يتم إصدارها في كثير من الأحيان أكثر من القديمة التي تمكنت من القتل. لذلك ، أول شيء كان من المثير للاهتمام أن ننظر إلى أكثر القتلى من حيث تسجيل قرص الموارد. الحد الأدنى لجميع عملاء SSD هو 1٪.
كتبنا على الفور إلى العميل حول هذا الأمر ، وتبين أنه ديديك في hetzner. استبدال دعم الاستضافة على الفور SSD:

سيكون من المثير للاهتمام للغاية أن نرى كيف يبدو الموقف من وجهة نظر نظام التشغيل عندما تتوقف SSD عن خدمة سجل (نحن نبحث الآن عن فرصة لنسخ SSD عمدا من أجل إلقاء نظرة على مقاييس هذا السيناريو :)
ما مدى سرعة قتل SSDs؟
نظرًا لأننا بدأنا في جمع المقاييس قبل عام ، ولا نقوم بحذف المقاييس ، فمن الممكن إلقاء نظرة على هذا المقياس في الوقت المناسب. لسوء الحظ ، تم توصيل الخادم ذو أعلى معدل تدفق بـ okmeter قبل شهرين فقط.

في هذا الرسم البياني ، نرى كيف أحرقوا 8٪ من موارد التسجيل خلال شهرين. أي ، بنفس ملف التسجيل ، ستكون هذه ssd كافية لـ 100 / (8/2) = 25 شهرًا. لا أعرف الكثير أو القليل ، لكن دعنا نرى أي نوع من الحمل موجود؟

نرى أن ceph فقط يعمل مع القرص ، لكننا نفهم أن ceph هو مجرد طبقة. في هذه الحالة ، يعمل عميل ceph كمخزن لمجموعة kubernetes على عدة عقد ، دعنا نرى ما يولد داخل k8s أكبر عدد من عمليات الكتابة على القرص:

لا تتطابق القيم المطلقة على الأرجح بسبب حقيقة أن ceph يعمل في المجموعة ويزداد السجل من redis بسبب تكرار البيانات. لكن ملف تعريف التحميل يسمح لك أن تقول بثقة أن السجل يبدأ إعادة تمامًا. دعونا نرى ما يحدث على الفجل:

هنا يمكنك أن ترى أنه في المتوسط يتم تنفيذ أقل من 100 طلب في الثانية ، الأمر الذي يمكن أن يغير البيانات. تذكر أن redis به طريقتان لكتابة البيانات على القرص :
- RDB - لقطات دورية لقاعدة البيانات بأكملها إلى القرص ، عند بدء إعادة التشغيل ، نقرأ التفريغ الأخير في الذاكرة ، ونفقد البيانات بين المكبات
- AOF - نكتب سجل لجميع التغييرات ، في البداية يفقد redis هذا السجل وتظهر جميع البيانات في الذاكرة ، نفقد فقط البيانات بين fsync من هذا السجل
كما يعتقد الجميع بالفعل في هذه الحالة ، يتم استخدام RDB بتردد تفريغ قدره دقيقة واحدة:

SSD + RAID
وفقًا لملاحظاتنا ، هناك ثلاثة تكوينات رئيسية لنظام القرص الفرعي للخوادم مع وجود SSDs:
- في SSDs 2 الخادم التي تم جمعها في الغارة 1 ويعيش كل شيء هناك
- يحتوي الخادم على HDD + raid-10 من ssd ، وعادة ما يتم استخدامه لـ RDBMSs الكلاسيكية (النظام ، WAL وجزء من البيانات على محرك الأقراص الثابتة ، وعلى SSD البيانات الأكثر سخونة من حيث القراءة)
- الخادم لديه SSD قائم بذاته (JBOD) ، وعادة ما يستخدم لنوع nosql كاساندرا
إذا تم جمع ssd في raid-1 ، ينتقل التسجيل إلى كلا القرصين ، بحيث يذهب التآكل بنفس السرعة:
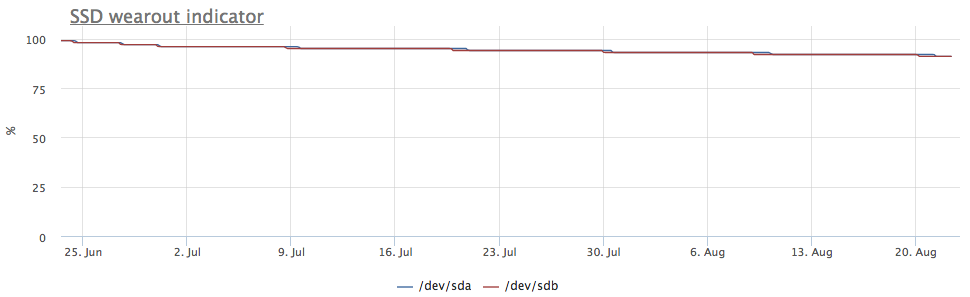
لكن الخادم لفت نظري ، حيث كانت الصورة مختلفة:

في هذه الحالة ، يتم تركيب أقسام mdraid فقط (جميع صفائف raid-1):

تظهر مقاييس التسجيل أيضًا أن هناك المزيد من الإدخالات على / dev / sda:

اتضح أن أحد الأقسام على / dev / sda يستخدم للتبديل ، وملاحظة i / o على هذا الخادم ملحوظة تمامًا:

استهلاك SSD و PostgreSQL
في الواقع ، أردت أن أرى معدل تآكل ssd في العديد من عمليات الكتابة في Postgres ، ولكن كقاعدة عامة ، يتم استخدامها بعناية فائقة في قواعد بيانات ssd المحملة ويذهب التسجيل الضخم إلى محرك الأقراص الثابتة. أثناء البحث عن حالة مناسبة ، صادفت خادمًا مثيرًا للاهتمام للغاية:

كان ارتداء اثنين من SSD في الغارة 1 لمدة 3 أشهر 4 ٪ ، ولكن وفقًا لسرعة تسجيل WAL ، يكتب هذا postgres أقل من 100 كيلو بايت / ثانية:
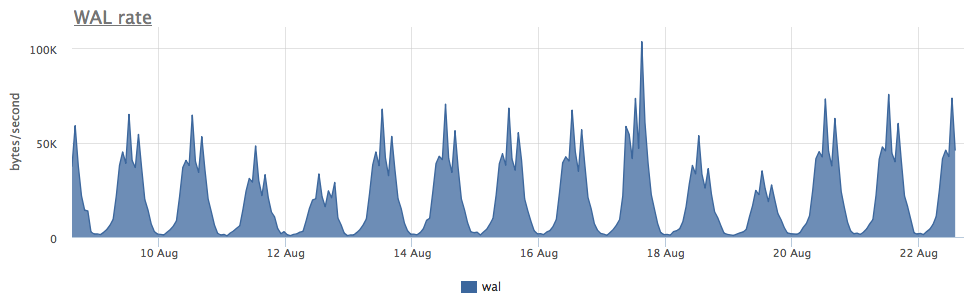
اتضح أن postgres يستخدم ملفات مؤقتة بنشاط ، يعمل معها إنشاء دفق مستمر من الكتابة إلى القرص:

نظرًا لأن postgresql مع التشخيص جيد جدًا ، يمكننا ، حتى الطلب ، معرفة ما نحتاج إلى إصلاحه بالضبط:

كما ترى هنا ، يقوم هذا SELECT بالتحديد بإنشاء مجموعة من الملفات المؤقتة. بشكل عام ، في SELECT postgres ، يقومون أحيانًا بإنشاء سجل بدون أي ملفات مؤقتة - هنا تحدثنا بالفعل عن هذا.
المجموع
- لا يعتمد مقدار الكتابة إلى القرص الذي ينشئه Redis + RDB على عدد التعديلات في قاعدة البيانات ، ولكن على حجم قاعدة البيانات + الفاصل الزمني للتفريغ (وبشكل عام ، هذا هو أعلى مستوى لتضخيم الكتابة في مخازن البيانات التي أعرفها)
- المبادلة المستخدمة بنشاط على ssd سيئة ، ولكن إذا كنت بحاجة إلى إضافة ارتعاش إلى تآكل ssd (لموثوقية raid-1) ، فقد يكون خيارًا :)
- بالإضافة إلى WAL وملفات البيانات ، لا يزال بإمكان قواعد البيانات كتابة جميع أنواع البيانات المؤقتة على القرص.
نحن في okmeter.io نعتقد أنه من أجل الوصول إلى الجزء السفلي من سبب المشكلة ، يحتاج المهندس إلى الكثير من المقاييس حول جميع طبقات البنية التحتية. نحن نبذل قصارى جهدنا للمساعدة :)