
تمكنت من جمع محطة العمل الخاصة بي كطالب. منطقياً ، كنت أفضل حلول الحوسبة AMD. لأنه رخيصة مربحة من حيث السعر / الجودة. لقد التقطت المكونات لفترة طويلة ، وفي النهاية حصلت على 40k مع مجموعة من FX-8320 و RX-460 2GB. في البداية بدت هذه المجموعة مثالية! قمت أنا وزميلي في الغرفة بتعدين مونيرو قليلاً وأظهرت مجموعتي 650h / s مقابل 550h / s على مجموعة من i5-85xx و Nvidia 1050Ti. صحيح ، من مجموعتي في الغرفة كان الجو حارًا قليلاً في الليل ، ولكن هذا تقرر عندما اشتريت مبرد برج لوحدة المعالجة المركزية.
الحكاية انتهت
كان كل شيء يشبه القصة الخيالية بالضبط حتى أصبحت مهتمًا بتعلم الآلة في مجال رؤية الكمبيوتر. بشكل أكثر دقة - حتى اضطررت للعمل مع صور الإدخال بدقة أكثر من 100 × 100 بكسل (حتى هذه اللحظة ، تعاملت FX 8-core الخاصة بي بسرعة). الصعوبة الأولى كانت مهمة تحديد العواطف. 4 طبقات ResNet وصورة إدخال 100x100 و 3000 صورة في مجموعة التدريب. والآن - 9 ساعات من التدريب 150 عصرًا على وحدة المعالجة المركزية.
بالطبع ، بسبب هذا التأخير ، تعاني عملية التنمية التكرارية. في العمل ، كان لدينا Nvidia 1060 6GB وتدريبًا على هيكل مشابه (على الرغم من تدريب الانحدار هناك لتوطين الكائنات) ، حلقت في 15-20 دقيقة - 8 ثوانٍ لحقبة 3.5k صور. عندما يكون لديك مثل هذا التباين تحت أنفك ، يصبح التنفس أكثر صعوبة.
حسنًا ، تخمين تحركتي الأولى بعد كل هذا؟ نعم ، ذهبت للمساومة 1050Ti مع جارتي. مع الجدل حول عدم جدوى CUDA بالنسبة له ، مع عرض لاستبدال بطاقتي مقابل رسوم إضافية. ولكن دون جدوى. والآن أقوم بنشر RX 460 الخاص بي على Avito ومراجعة 1050Ti العزيزة على موقعي Citylink و TechnoPoint. حتى في حالة البيع الناجح للبطاقة ، كان عليّ العثور على 10 آلاف أخرى (أنا طالب ، وإن كنت عاملاً).
جوجل
حسنًا انا ذاهب الى جوجل كيفية استخدام راديون تحت Tensorflow. مع العلم أن هذه كانت مهمة غريبة ، لم أكن آمل بشكل خاص في العثور على أي شيء معقول. اجمع تحت Ubuntu ، سواء بدأ أو لا ، احصل على لبنة - عبارات تنتزع من المنتديات.
وهكذا ذهبت في الاتجاه الآخر - لم أقوم بـ Google Tensorflow AMD Radeon ، ولكن Keras AMD Radeon. يرشدني على الفور إلى صفحة PlaidML . أبدأ تشغيله في 15 دقيقة (على الرغم من أنني اضطررت إلى الرجوع إلى الإصدار السابق من Keras إلى 2.0.5) وتعيين الشبكة للتعلم. الملاحظة الأولى - العصر 35 ثانية بدلاً من 200.
الصعود للاستكشاف
مؤلفو PlaidML هم vertex.ai ، وهو جزء من مجموعة مشروعات Intel (!). هدف التطوير هو الحد الأقصى عبر النظام الأساسي. بالطبع ، هذا يضيف الثقة للمنتج. يقول مقالهم أن PlaidML قادر على المنافسة مع Tensorflow 1.3 + cuDNN 6 بسبب "التحسين الشامل".
ومع ذلك ، فإننا نواصل. تكشف لنا المقالة التالية إلى حد ما عن الهيكل الداخلي للمكتبة. والفرق الرئيسي من جميع الأطر الأخرى هو التوليد التلقائي لحسابات الحساب (في تدوين Tensorflow ، "النواة" هي العملية الكاملة لأداء عملية معينة في رسم بياني). بالنسبة لتوليد kernel التلقائي في PlaidML ، تعتبر الأبعاد الدقيقة لجميع الموتر والثوابت والخطوات وأحجام الالتواء وقيم الحدود التي ستضطر إلى العمل بها لاحقًا مهمة جدًا. على سبيل المثال ، يقال أن إنشاء المزيد من النوى الفعالة يختلف لـ 1 و 32 دفعات أو لفائف ذات أحجام 3x3 و 7x7. باستخدام هذه البيانات ، سيولد الإطار نفسه الطريقة الأكثر فعالية لموازاة وتنفيذ جميع العمليات لجهاز معين بخصائص محددة. إذا ألقيت نظرة على Tensorflow ، عند إنشاء عمليات جديدة ، نحتاج إلى تنفيذ النواة لهم أيضًا - والتطبيقات مختلفة تمامًا للنواة ذات الخيوط الفردية أو متعددة الخيوط أو المتوافقة مع CUDA. على سبيل المثال من الواضح أن PlaidML أكثر مرونة.
نذهب أبعد من ذلك. التنفيذ مكتوب في بلاط اللغة المكتوبة ذاتيا. تتمتع هذه اللغة بالمزايا الرئيسية التالية - قرب بناء الجملة من الرموز الرياضية (ولكن بالجنون!):
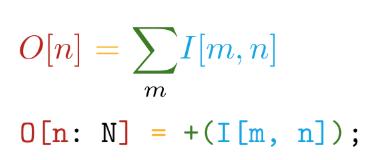
والتمييز التلقائي لجميع العمليات المعلنة. على سبيل المثال ، في TensorFlow ، عند إنشاء عملية مخصصة جديدة ، يوصى بشدة أن تكتب دالة لحساب التدرجات. وبالتالي ، عند إنشاء عملياتنا الخاصة بلغة التجانب ، نحتاج فقط إلى تحديد ما نريد حسابه دون التفكير في كيفية النظر في ذلك فيما يتعلق بالأجهزة.
بالإضافة إلى ذلك ، يتم إجراء تحسين أمثل للعمل مع DRAM ونظير لذاكرة التخزين المؤقت L1 في وحدة معالجة الرسومات. أذكر الجهاز التخطيطي:
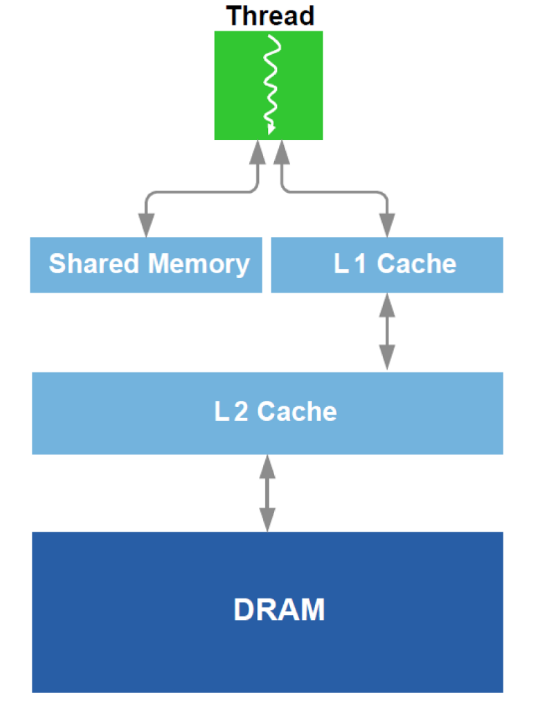
للتحسين ، يتم استخدام جميع البيانات المتاحة حول الجهاز - حجم ذاكرة التخزين المؤقت وعرض خط ذاكرة التخزين المؤقت وعرض النطاق الترددي DRAM وما إلى ذلك. توفر الطرق الرئيسية قراءة متزامنة لكتل كبيرة بما يكفي من DRAM (محاولة لتجنب العنوان إلى مناطق مختلفة) وتحقيق أن البيانات التي تم تحميلها في ذاكرة التخزين المؤقت تُستخدم عدة مرات (محاولة لتجنب إعادة تحميل نفس البيانات عدة مرات).
تتم جميع التحسينات خلال الحقبة الأولى من التدريب ، مع زيادة وقت الجولة الأولى بشكل كبير:
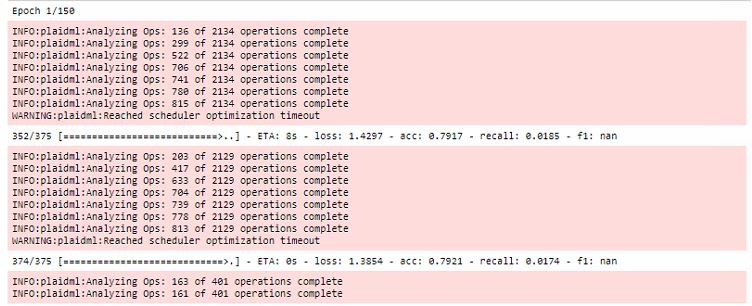
بالإضافة إلى ذلك ، تجدر الإشارة إلى أن هذا الإطار مرتبط بـ OpenCL . الميزة الرئيسية لـ OpenCL هي أنه معيار للأنظمة غير المتجانسة ولا شيء يمنعك من تشغيل kernel على وحدة المعالجة المركزية . نعم ، هذا هو المكان الذي يكمن فيه أحد الأسرار الرئيسية لـ PlaidML عبر الأنظمة الأساسية.
الخلاصة
بالطبع ، التدريب على RX 460 لا يزال أبطأ بمقدار 5-6 مرات من 1060 ، ولكن يمكنك مقارنة فئات الأسعار لبطاقات الفيديو! ثم حصلت على RX 580 8 جيجابايت (لقد أقرضوني!) وتم تقليل الوقت المستغرق لتشغيل العصر إلى 20 ثانية ، وهو ما يمكن مقارنته تقريبًا.
تحتوي مدونة vertex.ai على رسوم بيانية صادقة (المزيد هو الأفضل):
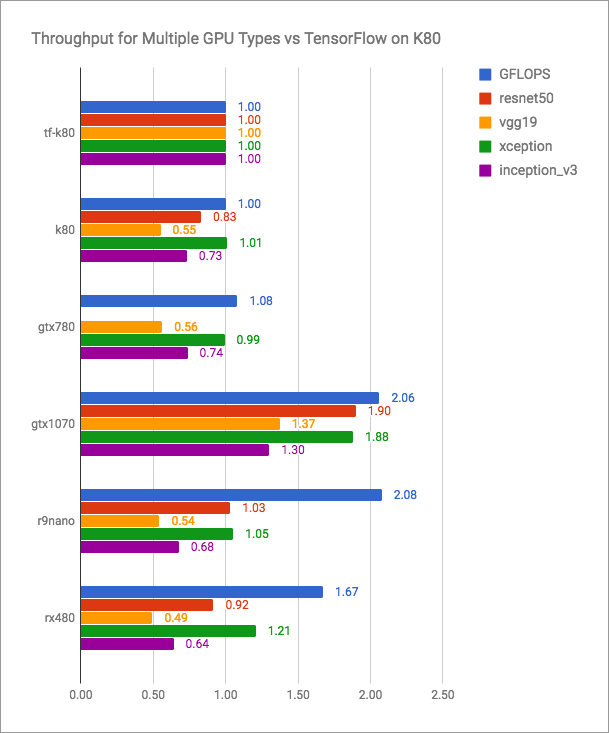
يمكن ملاحظة أن PlaidML قادر على المنافسة مع Tensorflow + CUDA ، ولكن بالتأكيد ليس أسرع للإصدارات الحالية. لكن مطوري PlaidML ربما لا يخططون للدخول في مثل هذه المعركة المفتوحة. هدفهم هو العالمية ، عبر منصة.
سأترك هنا جدولًا غير مقارن تمامًا بقياسات أدائي:
| جهاز حوسبة | وقت تشغيل العصر (الدفعة - 16) ، ق |
|---|
| AMD FX-8320 tf | 200 |
| RX 460 2GB منقوشة | 35 |
| RX 580 8 جيجابايت منقوشة | 20 |
| 1060 TF 6GB | 8 |
| 1060 6GB منقوشة | 10 |
| انتل i7-2600 TF | 185 |
| انتل i7-2600 منقوشة | 240 |
| GT 640 منقوشة | 46 |
أحدث مشاركة مدونة vertex.ai وآخر التعديلات على المستودع مؤرخة في مايو 2018. يبدو أنه إذا لم يتوقف مطورو هذه الأداة عن إصدار إصدارات جديدة والمزيد من الأشخاص الذين أساء إليهم Nvidia على دراية بـ PlaidML ، فإنهم سيتحدثون عن vertex.ai في كثير من الأحيان.
كشف راديونز الخاص بك!