منذ فترة ، قمت بتنشيط نسخة تجريبية مجانية تحت Google من أجل السحابة الخاصة بهم ، لم أحل مشكلتي ، اتضح أن Google تمنح 300 دولارًا لمدة 12 شهرًا للتجربة ، ولكن على عكس توقعاتي ، يتم فرض حدود أخرى إلى جانب حد الميزانية. على سبيل المثال ، لم أسمح باستخدام أجهزة افتراضية مع أكثر من 8 vcpu في منطقة واحدة. بعد نصف عام ، قررت استخدام ميزانية التجربة للتعرّف على dataproc ، وهي مجموعة منتقاة مسبقًا من Google. تتمثل المهمة في محاولة تقييم مدى سهولة إطلاق مشروع على وصول Google ، سواء كان ذلك منطقيًا أم أنه من الأفضل التركيز فورًا على أجهزتي والتفكير في الإدارة. لدي شعور غامض بأن الأجهزة الحديثة وكبار السن يجب أن يتكيفوا بسهولة مع قواعد البيانات الصغيرة التي تحتوي على عشرات أو مئات غيغابايت ، ويتم تحميلها بوحشية ، إن لم يكن مجموعة البيانات بأكملها ، فإن الغالبية العظمى في ذاكرة المجموعة. قد لا تكون هناك حاجة لبعض البيانات الفرعية المنفصلة لمخازن البيانات.
باختصار ، أعجبت dataproc بسهولة الإطلاق والإعدادات ، مقارنة مع Oracle و Cloudera. في المرحلة الأولى ، لعبت مع مجموعة عقدة واحدة على 8 vCpu ، يسمح الحد الأقصى منها بتجربة مجانية تمامًا. إذا نظرت إلى البساطة ، فإن التكنولوجيا الخاصة بهم تسمح بالفعل للهندوسيين ببدء مجموعة في غضون 15 دقيقة ، وتحميل بيانات العينة وإعداد التقارير باستخدام أداة BI عادية ، دون أي نوافذ فرعية وسيطة. بعض المعرفة العميقة بحدوب لم تعد مطلوبة على الإطلاق.
من حيث المبدأ ، رأيت أن الشيء رائع لبداية سريعة ولأموال معقولة يمكنك تشغيل نموذج أولي وتقييم نوع الأجهزة التي تحتاجها لمهمة. ومع ذلك ، من الواضح أن مجموعة أكبر ، في عشرات العقد ، ستأكل أكثر بكثير من استئجار + زوجين من المسؤولين الذين ينظرون إلى المجموعة. بعيدًا عن حقيقة أن السحابة ستبدو قابلة للحياة اقتصاديًا. حاولت الخطوة الأولى تقييم خيار دقيق تمامًا مع مجموعة عقدة واحدة 8 vCpu و 0.5 تيرابايت من البيانات الأولية. من حيث المبدأ ، فإن اختبارات شرارة + hadoop على مجموعات أكبر ممتلئة بالفعل على الإنترنت ، لكنني أخطط لاختبار الخيار أكبر قليلاً في وقت لاحق.
في ساعة واحدة فقط ، بحثت في البرامج النصية لإنشاء نسخة احتياطية للكتلة ، وأعدت جدارها الناري وإعداد خادم ادخار ، مما سمح لـ jdbc بالاتصال بـ sql من Windows المنزلي. أمضيت ساعتين أو ثلاث ساعات أخرى في تحسين إعدادات الشرارة الافتراضية وتحميل طاولتين صغيرتين بحجم 10 غيغابايت (حجم ملفات البيانات في Oracle). دفعت الجداول بأكملها في الذاكرة (تغيير ذاكرة التخزين المؤقت للجدول ؛) وكان من الممكن العمل معها من جهاز Windows الخاص بي من Dbeaver و Tableau (عبر موصل شرارة SQL).
افتراضيًا ، استخدمت شرارة منفذًا واحدًا فقط على 4 vCpu ، وحررت شرارة defaults.conf ، وثبت 3 منفذين ، و 2 vCpu لكل منهما ولم أتمكن منذ فترة طويلة من فهم سبب وجود حاسوب منفرد واحد فقط في عملي. اتضح أنني لم أعدل الذاكرة ، فالخيوط الأخرى لم تستطع ببساطة تخصيص الذاكرة. قمت بتعيين 6.5 غيغابايت على executer ، وبعد ذلك بدأ الثلاثة في الارتفاع كما هو متوقع.
بعد ذلك ، قررت اللعب بحجم صوت أكثر خطورة قليلاً ومهمة أقرب إلى DWH من اختبارات TPC-DS. بالنسبة للمبتدئين ، قمت رسميًا بإنشاء جداول بمعامل قياس 500 للأداة الرسمية. حصلت على شيء مثل 480 غيغابايت من البيانات الأولية (نص محدد). اختبار TPC-DS هو DWH نموذجي ، مع الحقائق والأبعاد. لم أكن أفهم كيفية إنشاء البيانات مباشرة على تخزين google ، واضطررت إلى إنشاء أجهزة افتراضية على القرص ثم نسخها إلى تخزين google. جوجل ، كما أفهمها ، تعتقد أن غطاء المحرك يعمل بشكل مثالي مع تخزين جوجل والسرعة هناك أفضل قليلاً مما لو كانت البيانات داخل المجموعة على HDFS. في هذه الحالة ، ينتقل جزء من الحمل من HDFS إلى تخزين google.
بعد الاتصال من خلال Dbeaver ، قمت بتحويل الملفات النصية إلى أجهزة لوحية قائمة على الباركيه مع تغليف سريع باستخدام أوامر SQL. 480 جيجا بايت من البيانات النصية معبأة في ملفات الباركيه 187 جيجا بايت. استغرقت العملية حوالي ساعتين ، واحتلت أكبر طاولة في النص 188 غيغابايت ، وقام 3 شرطيين بتحويلها إلى باركيه في 74 دقيقة ، وكان حجم السيارة الرياضية متعددة الاستخدامات 66.8 غيغابايت. على سطح المكتب الخاص بي مع نفس 8 vCpu (i7-3770k) أعتقد أن "إدراج في جدول حدد * ..." في جدول أوراكل مع كتلة 8 كيلو سيستغرق يومًا ، والمقدار الذي سيستغرقه ملف البيانات أمر مخيف.
بعد ذلك ، راجعت أداء أدوات BI على مثل هذا التكوين ، وقمت ببناء تقرير بسيط في Tableua
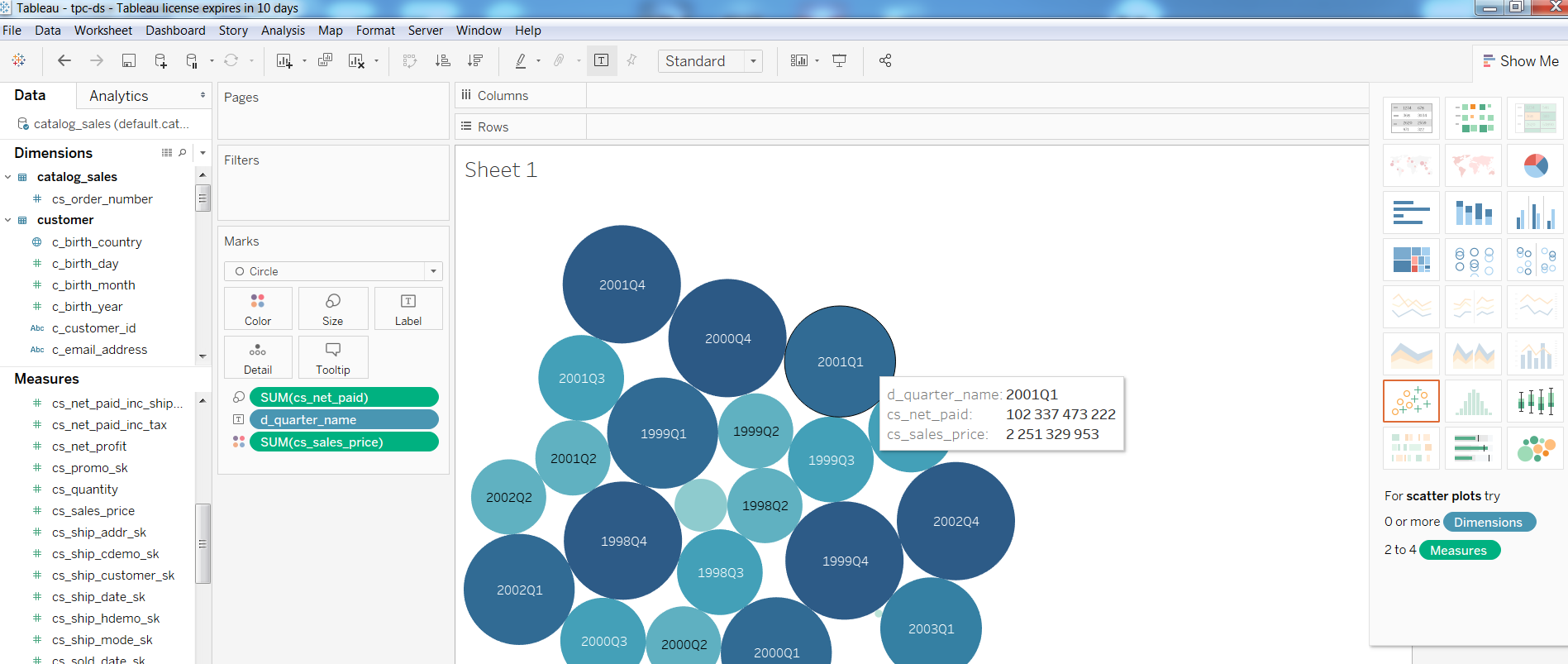
بالنسبة إلى الاستفسارات ، Query1 من اختبار TPC-DS
الاستعلام 1WITH customer_total_return AS (SELECT sr_customer_sk AS ctr_customer_sk, sr_store_sk AS ctr_store_sk, Sum(sr_return_amt) AS ctr_total_return FROM store_returns, date_dim WHERE sr_returned_date_sk = d_date_sk AND d_year = 2001 GROUP BY sr_customer_sk, sr_store_sk) SELECT c_customer_id FROM customer_total_return ctr1, store, customer WHERE ctr1.ctr_total_return > (SELECT Avg(ctr_total_return) * 1.2 FROM customer_total_return ctr2 WHERE ctr1.ctr_store_sk = ctr2.ctr_store_sk) AND s_store_sk = ctr1.ctr_store_sk AND s_state = 'TN' AND ctr1.ctr_customer_sk = c_customer_sk ORDER BY c_customer_id LIMIT 100;
اكتمل في 1:08 ، Query2 بمشاركة أكبر الجداول (كتالوج_المبيعات ، مبيعات الويب)
الاستعلام 2 WITH wscs AS (SELECT sold_date_sk, sales_price FROM (SELECT ws_sold_date_sk sold_date_sk, ws_ext_sales_price sales_price FROM web_sales) UNION ALL (SELECT cs_sold_date_sk sold_date_sk, cs_ext_sales_price sales_price FROM catalog_sales)), wswscs AS (SELECT d_week_seq, Sum(CASE WHEN ( d_day_name = 'Sunday' ) THEN sales_price ELSE NULL END) sun_sales, Sum(CASE WHEN ( d_day_name = 'Monday' ) THEN sales_price ELSE NULL END) mon_sales, Sum(CASE WHEN ( d_day_name = 'Tuesday' ) THEN sales_price ELSE NULL END) tue_sales, Sum(CASE WHEN ( d_day_name = 'Wednesday' ) THEN sales_price ELSE NULL END) wed_sales, Sum(CASE WHEN ( d_day_name = 'Thursday' ) THEN sales_price ELSE NULL END) thu_sales, Sum(CASE WHEN ( d_day_name = 'Friday' ) THEN sales_price ELSE NULL END) fri_sales, Sum(CASE WHEN ( d_day_name = 'Saturday' ) THEN sales_price ELSE NULL END) sat_sales FROM wscs, date_dim WHERE d_date_sk = sold_date_sk GROUP BY d_week_seq) SELECT d_week_seq1, Round(sun_sales1 / sun_sales2, 2), Round(mon_sales1 / mon_sales2, 2), Round(tue_sales1 / tue_sales2, 2), Round(wed_sales1 / wed_sales2, 2), Round(thu_sales1 / thu_sales2, 2), Round(fri_sales1 / fri_sales2, 2), Round(sat_sales1 / sat_sales2, 2) FROM (SELECT wswscs.d_week_seq d_week_seq1, sun_sales sun_sales1, mon_sales mon_sales1, tue_sales tue_sales1, wed_sales wed_sales1, thu_sales thu_sales1, fri_sales fri_sales1, sat_sales sat_sales1 FROM wswscs, date_dim WHERE date_dim.d_week_seq = wswscs.d_week_seq AND d_year = 1998) y, (SELECT wswscs.d_week_seq d_week_seq2, sun_sales sun_sales2, mon_sales mon_sales2, tue_sales tue_sales2, wed_sales wed_sales2, thu_sales thu_sales2, fri_sales fri_sales2, sat_sales sat_sales2 FROM wswscs, date_dim WHERE date_dim.d_week_seq = wswscs.d_week_seq AND d_year = 1998 + 1) z WHERE d_week_seq1 = d_week_seq2 - 53 ORDER BY d_week_seq1;
تم الانتهاء في 4:33 دقيقة ، Query3 في 3.6 ، Query4 في 32 دقيقة.
إذا كان شخص ما مهتمًا بالإعدادات ، فقم بقص ملاحظاتي حول إنشاء مجموعة. من حيث المبدأ ، لا يوجد سوى بضعة أوامر gcloud وإعداد HIVE_SERVER2_THRIFT_PORT.
ملاحظاتخيار كتلة العقدة واحد:
مجموعات بيانات dclap - gcloud - المنطقة الأوروبية الشمالية 1 إنشاء test1 \
- شبكة فرعية افتراضية \
- شريط دلو 1 \
- منطقة اوروبا شمالا 1 أ \
- عقدة واحدة \
- نوع الماكينة المسؤول n1-highmem-8 \
- مدير قرص تمهيد بحجم 500 \
- صورة الإصدار 1.3 \
--initialization-Actions gs: //dataproc-initialization-actions/hue/hue.sh \
--initialization-Actions gs: //dataproc-initialization-actions/zeppelin/zeppelin.sh \
--initialization-Actions gs: //dataproc-initialization-actions/hive-hcatalog/hive-hcatalog.sh \
- مشروع 123
خيار لـ 3 عقد:
مجموعات بيانات dclap gcloud - المنطقة الأوروبية الشمالية 1 \
إنشاء كتلة الاختبار 1 - الشريط دلو 1 \
- شبكة فرعية افتراضية - منطقة أوروبا-شمال 1-أ \
- نوع الماكينة المسؤول n1-standard-1 \
- مدير - قرص تمهيد - حجم 10 - عدد العاملين 2 \
- عامل من نوع الجهاز n1-standard-1 - عامل - قرص تمهيد - حجم 10 \
--initialization-Actions gs: //dataproc-initialization-actions/hue/hue.sh \
--initialization-Actions gs: //dataproc-initialization-actions/zeppelin/zeppelin.sh \
--initialization-Actions gs: //dataproc-initialization-actions/hive-hcatalog/hive-hcatalog.sh \
- مشروع 123
حساب gcloud - مشروع = 123 \
قواعد جدار الحماية إنشاء allow-dataproc \
- الاتجاه = INGRESS - الأولوية = 1000 - الشبكة = افتراضي \
- العمل = السماح - القواعد = tcp: 8088 ، tcp: 50070 ، tcp: 8080 ، tcp: 10010 ، tcp: 10000 \
- نطاقات المصدر = xxx.xxx.xxx.xxx / 32 - علامات الهدف = dataproc
في العقدة الرئيسية:
sudo su - vi /usr/lib/spark/conf/spark-env.sh
التغيير: تصدير HIVE_SERVER2_THRIFT_PORT = 10010
sudo -u spark /usr/lib/spark/sbin/start-thriftserver.sh
يتبع ...