
لذلك انتهى اليوم الخامس والأخير من KDD. تمكنت من سماع بعض التقارير المثيرة للاهتمام من Facebook و Google AI ، وتذكر تكتيكات كرة القدم وتوليد بعض المواد الكيميائية. حول هذا وليس فقط - تحت قطع. نراكم بعد عام في أنكوريج ، عاصمة ألاسكا!
في تعلم البيانات الضخمة لمشاكل البيانات الصغيرة
كان تقرير الصباح من
الأستاذ الصيني صعبًا. من الواضح أن المتحدث تم تحميله بشكل حر أثناء التحضير ، وغالبًا ما ضلل ، وبدأ في تخطي الشرائح ، وبدلاً من التحدث عن الحياة ، حاول تحميل الدماغ النائم بالرياضيات.
تمحور المخطط العام للقصة حول فكرة أنه لا يوجد دائمًا الكثير من البيانات. هناك ، على سبيل المثال ، ذيل طويل فيه العديد من الأمثلة المتنوعة. هناك مجموعات بيانات تحتوي على عدد كبير من الفئات ، والتي على الرغم من أنها كبيرة في حد ذاتها ، إلا أن لديها عدد قليل من السجلات لكل فئة. كمثال على مجموعة البيانات هذه ، استشهد
Omniglot - أحرف مكتوبة بخط اليد من 50 حرفًا أبجديًا و 1623 فئة و 20 صورة لكل فصل في المتوسط. ولكن في الواقع ، من هذا المنظور ، يمكنك أيضًا التفكير في مجموعات البيانات الخاصة بمهام التوصيات ، عندما يكون لدينا الكثير من المستخدمين وليس الكثير من التقييمات لكل منها على حدة.
ما الذي يمكن القيام به لجعل الحياة أسهل لل ML في مثل هذه الحالة؟ بادئ ذي بدء. حاول جلب المعرفة من مجال الموضوع فيها. يمكن القيام بذلك في مجموعة متنوعة من الأشكال: وهي هندسة الميزات ، وتنظيم محدد ، وتحسين بنية الشبكة. حل آخر شائع هو نقل التعلم ، وأعتقد أن كل من عمل مع الصور تقريبًا بدأ بترقية بعض ImageNet من بياناتهم. في حالة Omniglot ، سيكون المتبرع الطبيعي للنقل
MNIST .
يمكن أن يكون أحد أشكال النقل هو
التعلم متعدد المهام ، والذي تم التحدث عنه حول KDD عدة مرات. يمكن اعتبار تطوير MTL منهج
التعلم التلوي - من خلال تدريب الخوارزمية على عينات من مجموعة متنوعة من المهام ، يمكننا تعلم ليس فقط المعلمات ، ولكن أيضًا المعلمات الفائقة (بالطبع ، فقط إذا كان إجراءنا مختلفًا).
استمرارًا لموضوع المهام المتعددة ، يمكننا أن نصل إلى مفهوم التعلم المستمر مدى الحياة ، والذي يمكن أن يظهر بشكل أوضح من خلال مثال الروبوتات. يجب أن يكون الروبوت قادرًا على حل المشكلات المختلفة ، وعند تعلم مهمة جديدة لاستخدام الخبرة السابقة. ولكن يمكنك التفكير في هذا النهج مع مثال Omniglot: بعد تعلم إحدى الشخصيات ، يمكنك المتابعة إلى التعلم التالي ، باستخدام التجربة المتراكمة. صحيح أن هناك مشكلة
نسيان كارثية خطيرة تنتظرنا على هذا المسار ، عندما تبدأ الخوارزمية في نسيان ما تعلمته من قبل (تنصح بتنظيم
EWC لمكافحة هذا).
بالإضافة إلى ذلك ، تحدث المتحدث عن العديد من أعماله في هذا الاتجاه.
العمليات العصبية (تشبيه للعملية الغوسية للشبكات العصبية)
والتعلم بالتحول والنقل (تحسين التعلم عن طريق النقل للحالة عندما لا نأخذ نموذجًا مدربًا سابقًا كأساس ، ولكن ندرب نموذجنا في وضع المهام المتعددة).
صور ونصوص
قررت اليوم السير على التقارير التطبيقية في الصباح حول العمل مع النصوص والصور ومقاطع الفيديو.
خدمة تحويل الجسم
يزداد تواتر المنشورات بسرعة كبيرة ، ومن الصعب العمل على ذلك ، خاصة بالنظر إلى حقيقة أن البحث بأكمله تقريبًا يتم إجراؤه في النص.
تقدم IBM خدماتها لتمييز مرفقات المعرفة العلمية 3.0. يبدو سير العمل الرئيسي مثل هذا:
- Parsim PDF ، التعرف على النص في الصور.
- نتحقق مما إذا كان هناك نموذج لهذا الشكل من النص ، إذا كان الأمر كذلك ، فإننا نصنع مقتطفًا لغويًا به.
- إذا لم يكن هناك نموذج ، نرسله للتعليق التوضيحي والتدريب.
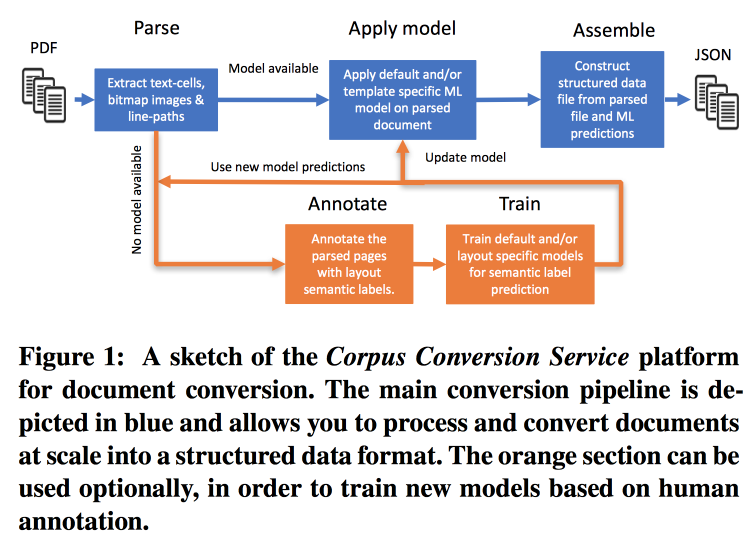
لتدريب النماذج ، نبدأ بالتجمع حسب الهيكل. ضمن مجموعة باستخدام التعهيد الجماعي ، نقوم بتصميم عدة صفحات. اتضح تحقيق الدقة> 98٪ عند التدريب على تعليم 200-300 وثيقة. هناك اختلال قوي في الطبقة في الترميز (يتم تمييز كل شيء تقريبًا كنص) ، لذلك تحتاج إلى النظر في دقة جميع الفئات ومصفوفة الخلط.
النماذج لها هيكل هرمي. على سبيل المثال ، يتعرف أحد النماذج على جدول ، ويقتطع الآخر من الصفوف / الأعمدة / الرؤوس (ونعم ، يمكن تضمين الجدول في جدول). كنموذج ، يتم استخدام شبكة تلافيفية.
لكل هذا ، قاموا بتجميع ناقل على Docker مع Kubernetes وهم على استعداد لتنزيل مجموعة النصوص الخاصة بك مقابل رسوم معقولة. يمكن أن تعمل ليس فقط مع نص PDF ، ولكن أيضًا مع عمليات المسح ؛ فهي تدعم اللغات الشرقية. بالإضافة إلى مجرد سحب النص ، فهم يعملون على استخراج الرسم البياني المعرفي ، ويعدون بإخبار التفاصيل عن KDD التالي.
توسيع طلب بحث نادر من خلال شبكات الخصومة التوليدية في الإعلان على شبكة البحث
تحقق محركات البحث أكبر قدر من المال من الإعلانات ، ويتم عرض الإعلانات اعتمادًا على ما يبحث عنه المستخدم. لكن المقارنة ليست واضحة دائمًا. على سبيل المثال ، بناء على طلب تذاكر الخطوط الجوية ، فإن عرض إعلانات تذاكر الحافلات الرخيصة ليس صحيحًا تمامًا ، ولكن expedia ستبلي بلاءً حسنًا ، ولكن لا يمكنك فهم ذلك بالكلمات الرئيسية. قد تساعد نماذج التعلم الآلي ، لكنها لا تعمل بشكل جيد مع الاستعلامات النادرة.
لحل هذه المشكلة ، لتوسيع استعلام البحث ،
سنقوم بتدريب GAN الشرطي وفقًا لنموذج التسلسل إلى التسلسل. نحن نستخدم الشبكات المتكررة (2-طبقة GRU) كمعمارية. نحن نقوم بتعديل min-max من GAN ، محاولين استهدافه بإضافة الكلمات الرئيسية التي كانت هناك نقرات على الإعلانات.
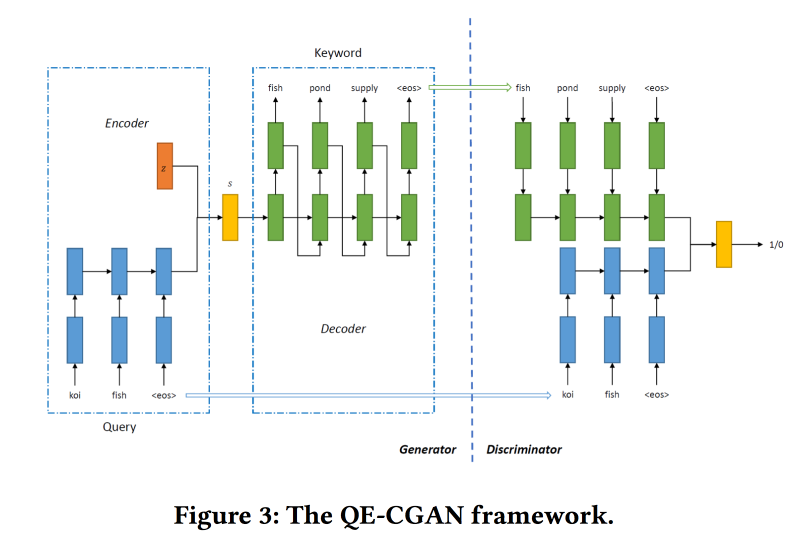
مجموعة بيانات للتدريب على 14 مليون استفسار و 4 ملايين كلمة رئيسية إعلانية. يعمل النموذج المقترح بشكل أفضل على الذيل الطويل للطلب ، والذي تم تنفيذه من أجله. ولكن في الرأس ، الأداء ليس أعلى.
التعلم التعاوني العميق للمقياس لفهم الفيديو
يتم تقديم
العمل من قبل الرجال من Google AI. يريدون إنشاء تضمينات فيديو جيدة ثم استخدامها في مقاطع فيديو وتوصيات وتوصيات وشروح تلقائية مماثلة ، وما إلى ذلك. يعمل على النحو التالي:
- من الفيديو ، نأخذ عينات من الإطارات - صورة وقطعة من المسار الصوتي.
- نستخرج ميزات من الصور التي تعلمها Inception مسبقًا.
- نفعل نفس الشيء مع الجزء الصوتي (لم يتم عرض بنية الشبكة المحددة). في العلامات التي تم الحصول عليها ، نعلق شبكات متصلة بالكامل مع سحب الإطارات. نقوم بالتطبيع بواسطة L2.
- بعد ذلك ، نقطة مثيرة للاهتمام - نحن نحاول التأكد من أن مقاطع الفيديو المماثلة قريبة من حيث التشابه التعاوني. للقيام بذلك ، عند التدريب ، نستخدم الخسارة الثلاثية (نأخذ شيئًا ، ونأخذ عينة منه متشابهة ومختلفة ، ونتأكد من أن التضمينات غير المتشابهة أبعد من الأصل عن المتشابهة). لا تنس أنك بحاجة إلى استخدام التعدين السلبي.

يتم استخدامها لبداية باردة في مقاطع فيديو مشابهة ، ولكن هناك مشكلتان: من خلال التشابه البصري ، يمكنهم العثور على مقاطع فيديو بلغة أخرى أو مقاطع فيديو حول موضوع مختلف (خاصة ذات الصلة بتنسيق الفيديو "board and lecturer"). ننصحك باستخدام معلومات وصفية إضافية حول الفيديو.
هناك مشكلة في التوصيات: تحتاج إلى مطابقة سجل التصفح و 5 مليار مقطع فيديو من Youtube. لتسريع العمل ، نحسب للمستخدم متجه متوسط التضمين لمقاطع الفيديو التي تمت مشاهدتها. فحصها في
الأفلام ، ضخ المقطورات من يوتيوب للتحليل. أظهروا أنه بالنسبة للمستخدمين الذين لديهم عدد قليل من التقييمات ، فإنه يعمل بشكل أفضل.
في مشكلة التعليق التوضيحي للفيديو ، يتم استخدام نهج
مزيج الخبراء : فهم يتدربون على تسجيل الدخول للتضمين لكل تعليق توضيحي محتمل. تم الفحص على
Youtube-8 وأظهر نتيجة جيدة جدًا.
توضيح الاسم في AMiner: التكتل والصيانة والإنسان في الحلقة
AMiner - رسم بياني للأكاديمية ، يقدم خدمات مختلفة للعمل مع الأدب. إحدى المشاكل: تصادم أسماء المؤلفين والكيانات. يتم تقديم خوارزمية تلقائية مع شكل من أشكال التعلم النشط للحل.
تتكون العملية من ثلاث مراحل: باستخدام البحث النصي ، نجمع المرشحين (مستندات بأسماء مماثلة للمؤلفين) ، وكتلة (مع التحديد التلقائي لعدد المجموعات) وبناء ملفات تعريف.

للنظر في التشابه في التكتل ، تحتاج إلى نوع من العرض (الانبعاث). يمكن الحصول عليها باستخدام النموذج العالمي (عبر الرسم البياني) أو محلي (لأولئك المرشحين الذين أخذوا عينات). أنماط المصيد العالمية التي يمكن نقلها إلى مستندات جديدة ، ويساعد المحلي على مراعاة الخصائص الفردية - سنجمع. للحصول على عمليات التضمين العالمية ، يستخدمون أيضًا شبكة سيامي المدربة على خسارة ثلاثية ، وللشركات المحلية - برنامج ترميز تلقائي للرسم البياني (تم ترك الصور في المقالة من أجل توفير المساحة).
السؤال الأكثر إيلامًا هو كم عدد العناقيد لدي؟ لا
يتدرج نهج
X-يعني إلى عدد كبير من العناقيد ، يتم استخدام RNN للتنبؤ بعددهم: يتم أخذ عينات التجمعات K من مجموعة محددة ، ثم أمثلة N من هذه العناقيد. يدربون الشبكة للكشف عن العدد الأولي للمجموعات.

تصل البيانات بسرعة كافية ، 500 ألف في الشهر ، لكن الأمر يستغرق أسابيع لتشغيل النموذج بأكمله. للتهيئة السريعة ، يستخدمون اختيار المرشحين للبحث عن النص و IPN للتضمين العالمي. نقطة مهمة: يتم تضمين الأشخاص الذين يحددون ما يجب وما لا ينبغي أن يكون في المجموعة في عملية التعلم. على هذه البيانات ، يتم إعادة تدريب النموذج.
Rosetta: نظام واسع النطاق لاكتشاف النص والتعرف عليه في الصور
سيقدم الرجال من FB حلهم لاستخراج النصوص من الصور. يعمل النموذج على مرحلتين: الشبكة الأولى تحدد النص ، والثانية تتعرف عليه.
تم استخدام
Faster-RCNN ككاشف مع استبدال ResNet بـ
SuffleNet لتسريع العمل. للاعتراف ، استخدموا ResNet18 وتدربوا باستخدام
فقدان CTC .
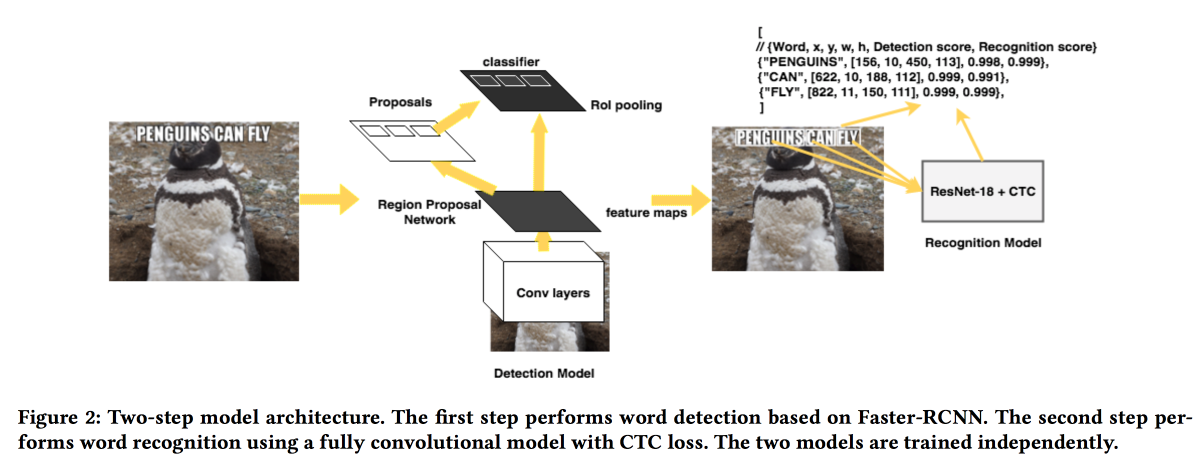
لتحسين التقارب ، استخدمنا عدة حيل:
- أثناء التدريب ، تم إدخال ضوضاء صغيرة في نتيجة الكاشف.
- تم تمديد النصوص أفقيا بنسبة 20 ٪.
- تعلم المناهج المستخدمة - أمثلة معقدة بشكل تدريجي (بعدد الشخصيات).
علوم طبيعية
تم تخصيص قسم المحتوى الأخير في المؤتمر ل "العلوم الطبيعية". القليل من الكيمياء وكرة القدم والمزيد.
تم التحكم في معدل الاكتشاف الخاطئ للكشف عن تأثير العلاج غير المتجانس للتجربة التي يتم التحكم فيها عبر الإنترنت
عمل مثير للاهتمام للغاية على تحليل اختبارات أ / ب. تكمن المشكلة في معظم أنظمة التحليل في أنها تنظر إلى متوسط التأثير ، بينما في الواقع ، غالبًا ما يتفاعل بعض المستخدمين مع التغيير بشكل إيجابي والبعض الآخر بشكل سلبي ، ويمكن تحقيق المزيد إذا فهمت من ذهب هذه الميزة ومن الذي لا.

يمكنك تقسيم المستخدمين إلى مجموعات نموذجية مسبقًا وتقييم التأثير
حسبهم ، ولكن مع زيادة عدد المجموعات
النموذجية ، يزداد عدد الإيجابيات الكاذبة (يمكنك محاولة تقليلها باستخدام طريقة
Bonferoni ، ولكنها محافظة للغاية). بالإضافة إلى ذلك ، تحتاج إلى معرفة المجموعات مسبقًا. يقترح الرجال استخدام مزيج من عدة طرق: الجمع بين آلية الكشف عن التأثير غير المتجانسة (HTE) وطرق التصفية الإيجابية الكاذبة.
لاكتشاف تأثير غير متجانس ، مصفوفة مع
x=0/1 0/1 (في المجموعة أم لا) ويتحول التأثير إلى مصفوفة حيث بدلاً من
0/1 يكمن الرقم
(x — p)/p(1-p) ، حيث
p هو احتمال الإدراج في الاختبار. بعد ذلك ، يتم تدريس نموذج للتنبؤ بتأثير
x (الانحدار الخطي أو اللاسو). هؤلاء المستخدمون الذين تختلف النتيجة لديهم بشكل كبير عن التوقعات هم مرشحون للانفصال إلى تأثير "غير متجانس".
بعد ذلك ، جربنا طريقتين للمرشح الإيجابي الكاذب:
بنجامين-هوخبرغ ونوكوفس . الأول أسهل في التنفيذ ، لكن الثاني أكثر مرونة وأظهر نتائج أكثر إثارة للاهتمام.
لعنة الفائز: تقدير التحيز للتأثيرات الإجمالية للميزات في التجارب التي يتم التحكم فيها عبر الإنترنت
تحدث الرجال من AirBnB قليلاً عن كيفية تحسين نظام تحليل التجارب. تكمن المشكلة الرئيسية في أنه عند تجربة الكثير من التحيزات ، فقد أخذنا بعين الاعتبار انحياز الاختيار في هذا العمل - فنحن نختار التجارب بأفضل النتائج
المرصودة ، ولكن هذا يعني أننا سنختار في كثير من الأحيان التجارب التي تكون فيها النتيجة المرصودة عالية جدًا بالنسبة إلى التجربة الحقيقية.
ونتيجة لذلك ، عند الجمع بين التجارب ، يكون التأثير النهائي أقل من مجموع تأثيرات التجارب. ولكن بمعرفة هذا التحيز ، يمكنك محاولة تقييمه وطرحه باستخدام الجهاز الإحصائي (بافتراض أن الفرق بين التأثيرات الحقيقية والملاحظة يتم توزيعه بشكل طبيعي). باختصار ، شيء من هذا القبيل:

وإذا قمت بإضافة
bootstrap ، يمكنك حتى بناء فواصل الثقة لتقدير غير متحيز للتأثير.
اكتشاف تلقائي للتكتيكات في بيانات مباراة كرة القدم المكانية الزمانية
عمل مثير للاهتمام في الكشف عن تكتيكات فرق كرة القدم. تتوفر بيانات المباراة في شكل تسلسل من الإجراءات (تمرير / لمسة / ضرب ، وما إلى ذلك) ، حوالي 2000 إجراء لكل مباراة. الجمع بين السمات المستمرة (الإحداثيات / الوقت) والمتميزة (اللاعب). من المهم توسيع البيانات باستخدام معرفة مجال الموضوع (أضف دور المشغل ونوع التمرير ، على سبيل المثال) ، لكنها لا تعمل دائمًا. بالإضافة إلى ذلك ، تهتم أنواع مختلفة من المستخدمين بأنواع مختلفة من الأنماط: المدربون - الناجحون ، المهاجمون - الدفاعيون ، الصحفيون - الفريدون.
الطريقة المقترحة هي كما يلي:
- يقسم التدفق إلى مراحل لانتقال الكرة بين الفرق.
- مراحل الكتلة باستخدام تشويه الوقت الديناميكي كمسافة . كيفية تحديد عدد التكتلات ، لم يتم إخبارها.
- نرتب المجموعات حسب الغرض (الذي نبحث عنه تكتيكات).
- نقوم بتقليل الأنماط داخل الكتلة (تعدين النمط المتسلسل CM-SPADE ) ، ونتخلى عن الإحداثيات وفقًا لأجزاء المجال (الجناح الأيسر / الأيمن ، الوسط ، الجزاء).
- رتب الأنماط مرة أخرى.
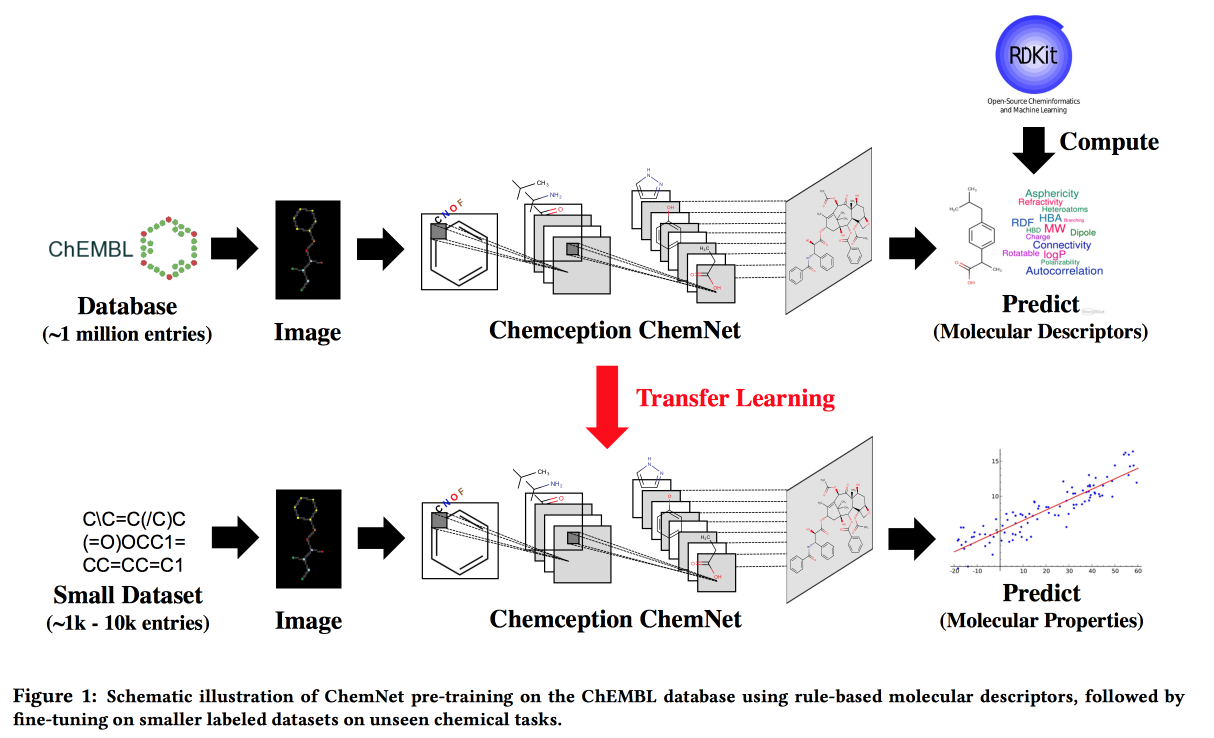
استخدام التسميات المستندة إلى القواعد للتعلم تحت الإشراف الضعيف: ChemNet للملكية الكيميائية القابلة للتحويل ص
اعمل على المواقف التي لا توجد فيها بيانات كبيرة ، ولكن هناك نماذج نظرية ذات قواعد هرمية. باستخدام النظرية ، نبني شبكة عصبية "خبيرة". ينطبق على مهمة تطوير المركبات الكيميائية ذات الخصائص المرغوبة.
أود ، عن طريق القياس بالصور ، أن أحصل على شبكة تتوافق فيها الطبقات مع مستويات مختلفة من التجريد: الذرات / المجموعات الوظيفية / الأجزاء / الجزيئات. في الماضي ، كانت هناك طرق لمجموعات البيانات الكبيرة التي تحمل علامة ، على سبيل المثال ، SMILE2Vect: استخدم
SMILE لترجمة صيغة إلى نص ، ثم تطبيق تقنيات لبناء التضمين للنصوص.
ولكن ماذا لو لم يكن هناك مجموعة بيانات كبيرة ملحوظة؟ نحن نعلم ChemNet باستخدام
RDKit للأهداف التي يمكنها التنبؤ بها ، ثم نقوم بنقل التعلم لحل المشكلة. نظهر أنه يمكننا التنافس مع النماذج المدربة على البيانات المصنفة. يمكنك التعلم في الطبقات ، مما يعني تحقيق الهدف - لكسر الطبقات حسب مستوى التجريد.
PrePeP - أداة لتحديد وتوصيف مركبات تداخل الفحص الشامل
نقوم بتطوير المخدرات ، واستخدام علم البيانات لاختيار المرشحين. هناك جزيئات تتفاعل مع العديد من المواد. لا يمكن استخدامها كأدوية ، ولكن غالبًا ما تنبثق في المراحل الأولية من الاختبار. هذه هي جزيئات
PAINS التي سنقوم بتصفية.
هناك صعوبات: يتم تفريغ البيانات والغطرسة (107 آلاف) ، والفصول غير متوازنة (إيجابية 0.5 ٪) ، ويريد الكيميائيون الحصول على نموذج مفسر. اجمع البيانات من بنية الرسم البياني (
gSpan ) للجزيء وبصمات الأصابع الكيميائية. لقد كافحوا مع التوازن من خلال تعبئة العينات السالبة ، وتعليم الأشجار ، والتنبؤات المجمعة بأغلبية الأصوات.