 لجعل الرصد مفيدًا ، يجب علينا وضع سيناريوهات مختلفة للمشكلات المحتملة وتصميم لوحات المعلومات والمشغلات بطريقة تجعلهم يفهمون على الفور سبب الحادث.
لجعل الرصد مفيدًا ، يجب علينا وضع سيناريوهات مختلفة للمشكلات المحتملة وتصميم لوحات المعلومات والمشغلات بطريقة تجعلهم يفهمون على الفور سبب الحادث.
في بعض الحالات ، نتفهم جيدًا كيفية عمل هذا المكون أو ذاك من مكونات البنية التحتية ، ومن ثم يُعرف مقدمًا المقاييس التي ستكون مفيدة. وأحيانًا نزيل جميع المقاييس الممكنة تقريبًا بأقصى قدر من التفاصيل ، ثم ننظر إلى كيفية ظهور مشكلات معينة عليها.
سنلقي نظرة اليوم على كيفية ولماذا يمكن أن تتضخم ملصقات Post-Ahead Log (WAL). كالعادة - أمثلة من الحياة الواقعية في الصور.
قليلا من نظرية WAL في postgresql
يتم تسجيل أي تغيير في قاعدة البيانات لأول مرة في WAL ، وفقط بعد ذلك يتم تغيير البيانات الموجودة في الصفحة الموجودة في ذاكرة التخزين المؤقت العازلة ويتم وضع علامة عليها على أنها متسخة - والتي يجب حفظها على القرص. بالإضافة إلى ذلك ، يتم بدء عملية CHECKPOINT بشكل دوري ، مما يحفظ جميع الصفحات المتسخة إلى القرص ويحفظ رقم مقطع WAL ، حتى تتم كتابة جميع الصفحات التي تم تغييرها بالفعل على القرص.
إذا تعطل postgresql فجأة لسبب ما وبدأ تشغيله مرة أخرى ، فسيتم تشغيل جميع أجزاء WAL من نقطة التفتيش الأخيرة أثناء عملية الاسترداد.
لن تكون مقاطع WAL التي تسبق نقطة التحقق مفيدة لنا لاستعادة قاعدة بيانات ما بعد التعطل ، ولكن في postgres يشارك WAL أيضًا في عملية النسخ المتماثل ، ويمكن أيضًا تكوين نسخة احتياطية لجميع الأجزاء لـ Point In Time Recovery - PITR.
مهندس متمرس ربما يفهم بالفعل كل شيء ، كيف ينكسر في الحياة الحقيقية :)
دعونا مشاهدة الرسوم البيانية!
WAL تورم # 1
يقوم وكيل المراقبة الخاص بنا لكل مثيل موجود من postgres بحساب المسار على القرص إلى الدليل باستخدام wal ويزيل كلاً من الحجم الإجمالي وعدد الملفات (الأجزاء):
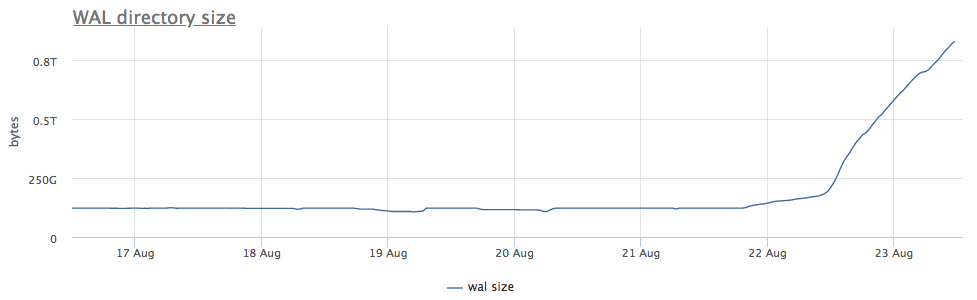
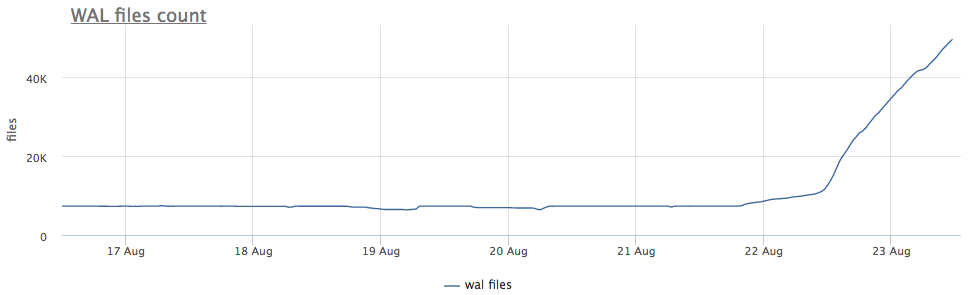
بادئ ذي بدء ، نحن ننظر إلى المدة التي كنا نديرها نقطة تفتيش.
نأخذ المقاييس من pg_stat_bgwriter:
- checkpoints_timed - عداد عمليات إطلاق نقاط التفتيش التي حدثت بشرط تجاوز الوقت من نقطة التفتيش الأخيرة بأكثر من pg_settings.checkpoint_timeout
- checkpoints_req - عداد بداية نقطة التفتيش بشرط تجاوز حجم وول من آخر نقطة تفتيش
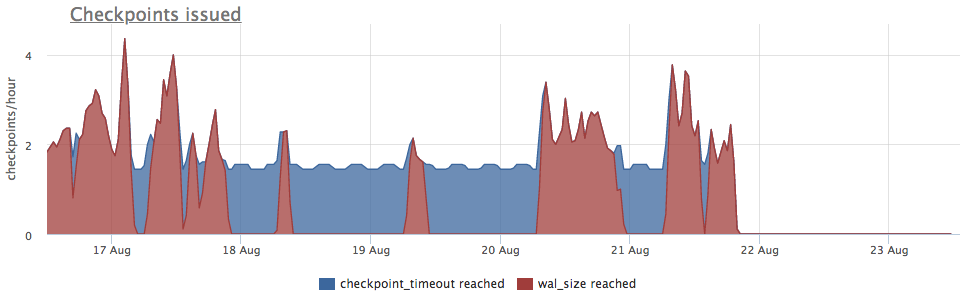
نرى أن نقطة التفتيش لم تطلق لفترة طويلة. في هذه الحالة ، من المستحيل فهم سبب عدم بدء هذه العملية بشكل مباشر (ولكن سيكون ذلك رائعًا بالطبع) ، لكننا نعلم أنه في postgres تنشأ الكثير من المشاكل بسبب المعاملات الطويلة!
نتحقق من:

علاوة على ذلك ، من الواضح ما يجب القيام به:
- إنهاء المعاملة
- التعامل مع أسباب طوله
- انتظر ، ولكن تحقق من وجود مساحة كافية
نقطة أخرى مهمة: على النسخ المتماثلة المتصلة بهذا الخادم ، فال منتفخ أيضًا !
أرشيفي WAL
أذكرك في بعض الأحيان: النسخ المتماثل ليس نسخة احتياطية!
يجب أن يسمح لك النسخ الاحتياطي الجيد بالاسترداد في أي وقت. على سبيل المثال ، إذا قام شخص ما "عن طريق الخطأ"
DELETE FROM very_important_tbl;
ثم يجب أن نكون قادرين على استعادة قاعدة البيانات إلى الحالة بالضبط قبل هذه المعاملة. وهذا ما يسمى PITR (الاستعادة في وقت معين) ويتم تنفيذه في postgresql مع نسخ احتياطية دورية كاملة لقاعدة البيانات + حفظ جميع مقاطع WAL بعد التفريغ.
يعد إعداد archive_command مسؤولاً عن النسخ الاحتياطي لـ wal ، ويبدأ postgres فقط الأمر الذي حددته ، وإذا اكتمل بدون خطأ ، فسيتم نسخ المقطع بنجاح. إذا حدث خطأ ، فسيحاول حتى النصر ، سيقع الجزء على القرص.
حسنًا ، وعلى سبيل التوضيح - رسومات وول أرشفة مكسورة:
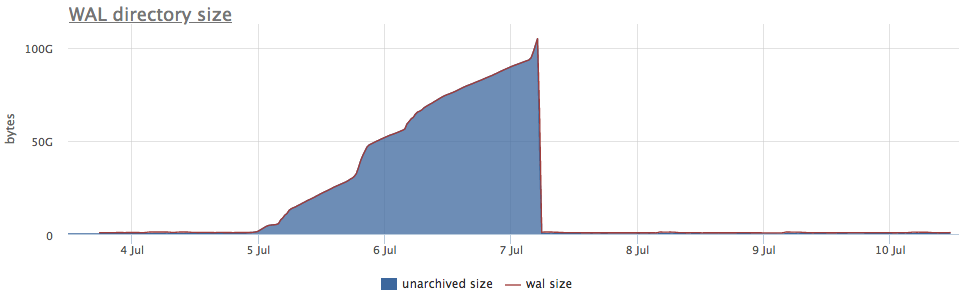
هنا ، بالإضافة إلى حجم جميع شرائح وول ، هناك حجم غير مؤرشف - هذا هو حجم الأجزاء التي لم يتم حفظها بنجاح.
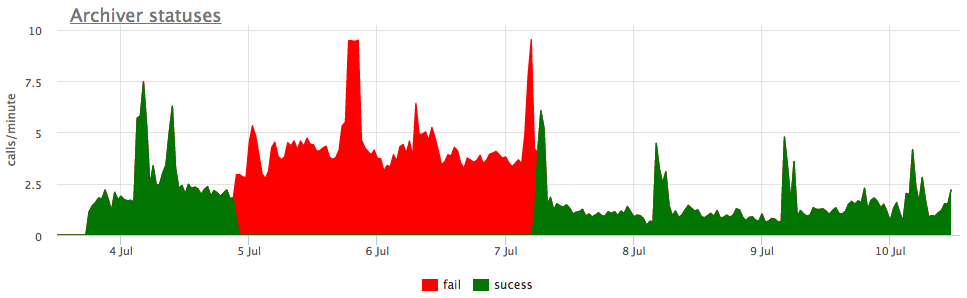
نحن نعتبر الحالات وفقًا للعدادات من pg_stat_archiver. بالنسبة لعدد الملفات ، قمنا بعمل تشغيل تلقائي لجميع العملاء ، لأنه غالبًا ما ينهار ، خاصة عند استخدام بعض التخزين السحابي كوجهة (S3 ، على سبيل المثال).
تأخر التكرار
دفق النسخ المتماثل قيد التقدم يعمل من خلال نقل ولعب النسخ المتماثلة. إذا كانت النسخة المتماثلة متأخرة لسبب ما ولم تفقد عددًا معينًا من الأجزاء ، فسيخزن المعالج مقاطع pg_settings.wal_keep_segments لذلك. إذا تأخرت النسخة المتماثلة عن عدد أكبر من الأجزاء ، فلن تتمكن بعد ذلك من الاتصال بالسيد (يجب إعادة سكبها).
من أجل ضمان الحفاظ على أي عدد من القطع المطلوبة ، ظهرت وظيفة فتحات النسخ المتماثل في 9.4 ، والتي سيتم مناقشتها لاحقًا.
فتحات النسخ المتماثل
إذا تم تكوين النسخ المتماثل باستخدام فتحة النسخ المتماثل وكان هناك اتصال متماثل ناجح واحد على الأقل بالفتحة ، ففي حالة اختفاء النسخة المتماثلة ، ستخزن postgres جميع أجزاء wal الجديدة حتى نفد المكان.
أي أن فتحة النسخ المنسية يمكن أن تسبب تورمًا. ولكن لحسن الحظ ، يمكننا مراقبة حالة الفتحات من خلال pg_replication_slots.
إليك ما يبدو في مثال حي:
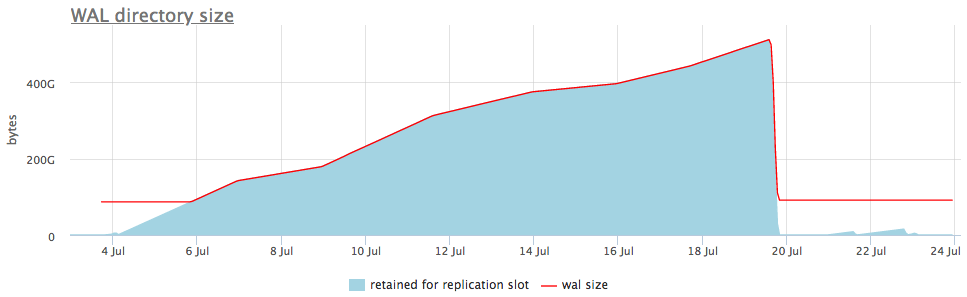

في الرسم البياني العلوي ، بجوار حجم wal ، نعرض دائمًا إما فتحة تحتوي على الحد الأقصى من الأجزاء المتراكمة ، ولكن هناك أيضًا رسم بياني مفصل يعرض الفتحة المنتفخة.
بمجرد أن نفهم نوع الفتحة التي تجمع البيانات ، يمكننا إما إصلاح النسخ المتماثلة المرتبطة بها ، أو ببساطة حذفها.
لقد استشهدت بالحالات الأكثر شيوعًا للتورم ، لكني متأكد من وجود حالات أخرى (توجد أخطاء في postgres أيضًا في بعض الأحيان). لذلك ، من المهم مراقبة حجم وول والاستجابة للمشكلات قبل نفاد مساحة القرص وستتوقف قاعدة البيانات عن تقديم الطلبات.
تعرف خدمة المراقبة لدينا بالفعل كيفية جمع كل هذا والتصور والتنبيه بشكل صحيح. ولدينا أيضًا خيار تسليم محلي لأولئك الذين لا تناسبهم السحابة.