
يتحدث الجميع الآن كثيرًا عن الذكاء الاصطناعي وتطبيقه في جميع مجالات الشركة. ومع ذلك ، هناك بعض المجالات التي هيمن فيها نوع واحد من النماذج ، منذ العصور القديمة ، على ما يسمى "الصندوق الأبيض" - الانحدار اللوجستي. أحد هذه المجالات هو تسجيل الائتمان المصرفي.
هناك عدة أسباب لذلك:
- يمكن تفسير معاملات الانحدار بسهولة على عكس "الصناديق السوداء" مثل التعزيز ، والتي يمكن أن تتضمن أكثر من 500 متغير
- لا تزال الإدارة غير موثوقة من قبل الإدارة بسبب صعوبة تفسير النماذج
- هناك متطلبات غير مكتوبة للجهة التنظيمية لتفسير النماذج: في أي وقت ، على سبيل المثال ، قد يطلب البنك المركزي تفسيرًا - لماذا تم رفض قرض للمقترض
- تستخدم الشركات برامج التنقيب عن البيانات الخارجية (على سبيل المثال ، عامل التعدين السريع ، أو SAS Enterprise Miner ، أو STATISTICA أو أي حزمة أخرى) التي تتيح لك التعرف بسرعة على كيفية بناء النماذج دون حتى مهارات البرمجة
تجعل هذه الأسباب من المستحيل تقريبًا استخدام نماذج معقدة للتعلم الآلي في بعض المجالات ، لذا من المهم أن تكون قادرًا على "ضغط الحد الأقصى" من الانحدار اللوجستي البسيط ، الذي يسهل تفسيره وتفسيره.
في هذا المنشور ، سنتحدث عن كيفية التخلي عن حزم استخراج البيانات الخارجية لصالح حلول المصادر المفتوحة في شكل Python ، وزيادة سرعة التطوير عدة مرات ، وكذلك تحسين جودة جميع النماذج.
عملية التهديف
تبدو العملية الكلاسيكية لبناء نماذج التسجيل على الانحدار كما يلي:
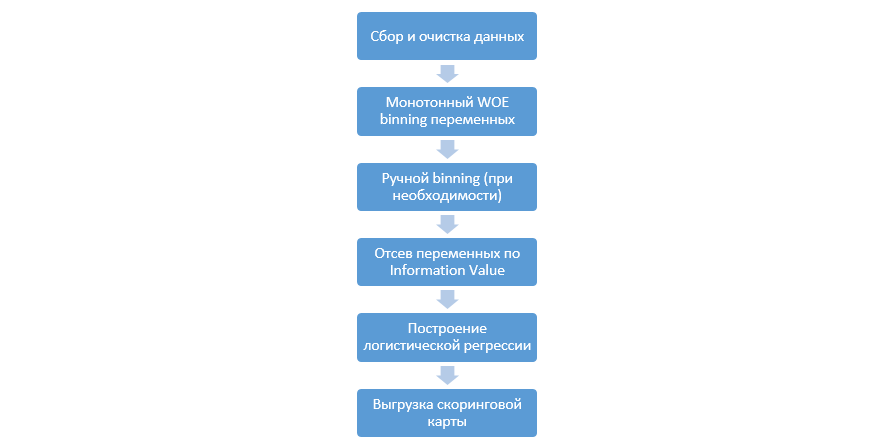
يمكن أن تختلف من شركة إلى أخرى ، ولكن المراحل الرئيسية لا تزال ثابتة. نحتاج دائمًا إلى إجراء تجميع للمتغيرات (على النقيض من نموذج التعلم الآلي ، حيث لا يلزم في معظم الحالات الترميز القاطع فقط) ، وفحصها حسب قيمة المعلومات (IV) ، والتحميل اليدوي لجميع المعاملات وصناديق الاندماج اللاحق في DSL.
نجح هذا النهج في بناء بطاقات تسجيل النقاط بشكل جيد في التسعينات ، لكن تقنيات حزم استخراج البيانات الكلاسيكية قديمة جدًا ولا تسمح باستخدام تقنيات جديدة ، مثل ، على سبيل المثال ، تسوية L2 في الانحدار ، والتي يمكن أن تحسن بشكل كبير من جودة النماذج.
في مرحلة ما ، كدراسة ، قررنا إعادة إنتاج جميع الخطوات التي يقوم بها المحللون عند بناء النقاط ، واستكمالها بمعرفة علماء البيانات ، وأتمتة العملية بأكملها قدر الإمكان.
تحسين بايثون
كأداة تطوير ، اخترنا Python لبساطتها ومكتباتها الجيدة ، وبدأنا في لعب جميع الخطوات بالترتيب.
الخطوة الأولى هي جمع البيانات وتوليد المتغيرات - هذه المرحلة هي جزء مهم من عمل المحللين.
في Python ، يمكنك تحميل البيانات التي تم جمعها من قاعدة البيانات باستخدام pymysql.
كود للتحميل من قاعدة البياناتdef con(): conn = pymysql.connect( host='10.100.10.100', port=3306, user='******* ', password='*****', db='mysql') return conn; df = pd.read_sql(''' SELECT * FROM idf_ru.data_for_scoring ''', con=con())
بعد ذلك ، نستبدل القيم النادرة والمفقودة بفئة منفصلة لمنع الاحتواء ، وتحديد الهدف ، وحذف الأعمدة الإضافية ، والقسمة حسب القطار والاختبار.
إعداد البيانات def filling(df): cat_vars = df.select_dtypes(include=[object]).columns num_vars = df.select_dtypes(include=[np.number]).columns df[cat_vars] = df[cat_vars].fillna('_MISSING_') df[num_vars] = df[num_vars].fillna(np.nan) return df def replace_not_frequent(df, cols, perc_min=5, value_to_replace = "_ELSE_"): else_df = pd.DataFrame(columns=['var', 'list']) for i in cols: if i != 'date_requested' and i != 'credit_id': t = df[i].value_counts(normalize=True) q = list(t[t.values < perc_min/100].index) if q: else_df = else_df.append(pd.DataFrame([[i, q]], columns=['var', 'list'])) df.loc[df[i].value_counts(normalize=True)[df[i]].values < perc_min/100, i] =value_to_replace else_df = else_df.set_index('var') return df, else_df cat_vars = df.select_dtypes(include=[object]).columns df = filling(df) df, else_df = replace_not_frequent_2(df, cat_vars) df.drop(['credit_id', 'target_value', 'bor_credit_id', 'bchg_credit_id', 'last_credit_id', 'bcacr_credit_id', 'bor_bonuses_got' ], axis=1, inplace=True) df_train, df_test, y_train, y_test = train_test_split(df, y, test_size=0.33, stratify=df.y, random_state=42)
يبدأ الآن المرحلة الأكثر أهمية في التسجيل للتراجع - تحتاج إلى كتابة WOE-binning للمتغيرات الرقمية والفئوية. في المجال العام ، لم نجد خيارات جيدة ومناسبة لنا وقررنا كتابة أنفسنا. تم أخذ مقالة عام 2017 هذه كأساس للتنظيم العددي ، بالإضافة إلى
هذا ، القاطع ، كتبوا هم أنفسهم من الصفر. كانت النتائج مثيرة للإعجاب (ارتفع جيني في الاختبار بنسبة 3-5 مقارنة بخوارزميات binning لبرامج استخراج البيانات الخارجية).
بعد ذلك ، يمكنك إلقاء نظرة على الرسوم البيانية أو الجداول (التي نكتبها بعد ذلك في excel) كيف يتم تقسيم المتغيرات إلى مجموعات والتحقق من الرتابة:
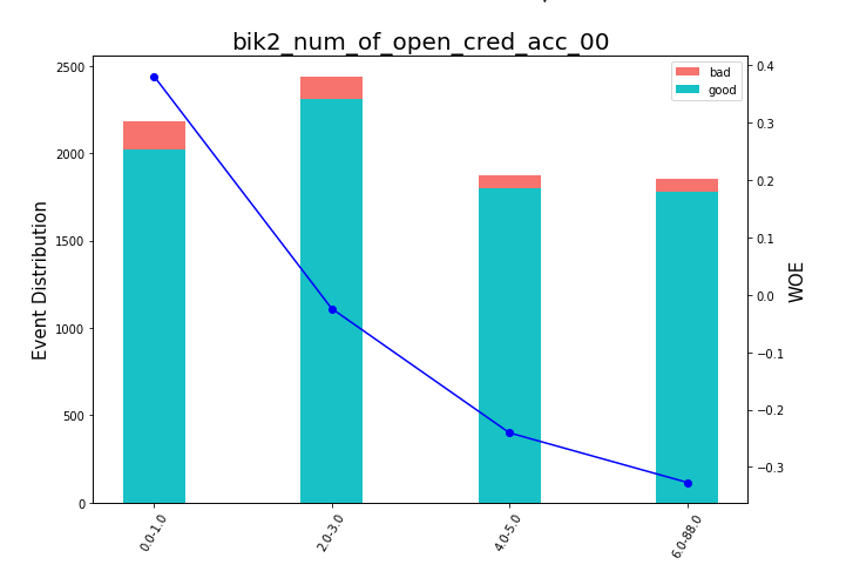
تقديم مخططات الفول def plot_bin(ev, for_excel=False): ind = np.arange(len(ev.index)) width = 0.35 fig, ax1 = plt.subplots(figsize=(10, 7)) ax2 = ax1.twinx() p1 = ax1.bar(ind, ev['NONEVENT'], width, color=(24/254, 192/254, 196/254)) p2 = ax1.bar(ind, ev['EVENT'], width, bottom=ev['NONEVENT'], color=(246/254, 115/254, 109/254)) ax1.set_ylabel('Event Distribution', fontsize=15) ax2.set_ylabel('WOE', fontsize=15) plt.title(list(ev.VAR_NAME)[0], fontsize=20) ax2.plot(ind, ev['WOE'], marker='o', color='blue')
تمت كتابة وظيفة تجميع يدوي بشكل منفصل ، وهو أمر مفيد ، على سبيل المثال ، في حالة المتغير "إصدار نظام التشغيل" ، حيث تم تجميع جميع هواتف Android و iOS يدويًا.
وظيفة binning اليدوية def adjust_binning(df, bins_dict): for i in range(len(bins_dict)): key = list(bins_dict.keys())[i] if type(list(bins_dict.values())[i])==dict: df[key] = df[key].map(list(bins_dict.values())[i]) else:
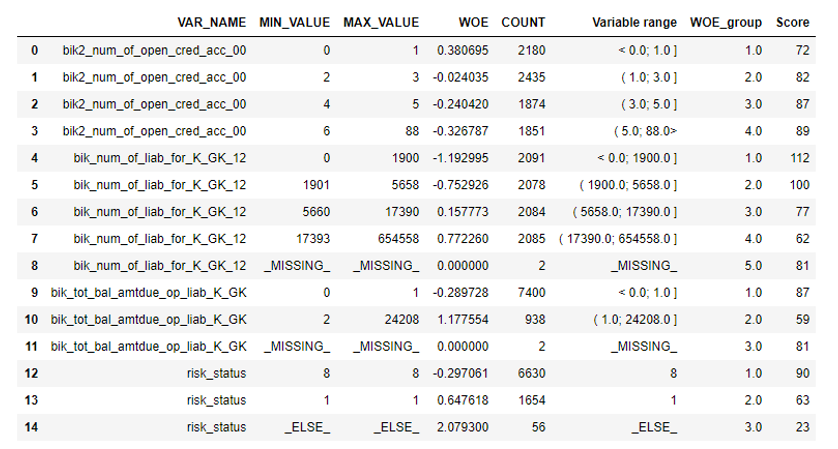
الخطوة التالية هي اختيار المتغيرات حسب قيمة المعلومات. يتم قطع القيمة الافتراضية 0.1 (جميع المتغيرات أدناه ليس لديها قوة تنبؤية جيدة).
بعد ذلك ، تم إجراء فحص الارتباط. من بين المتغيرين المترابطين ، تحتاج إلى إزالة المتغير الأقل IV. تم قطع الإزالة 0.75.
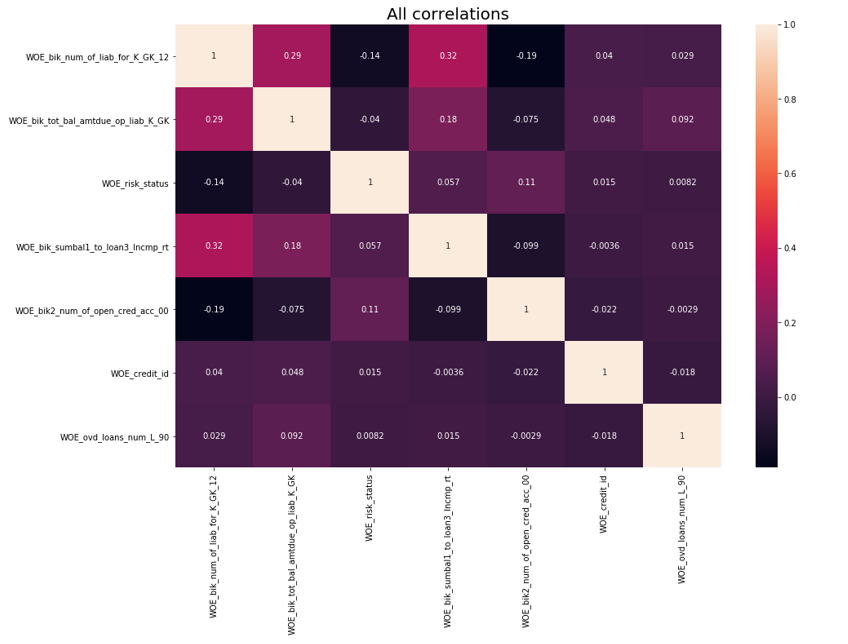
إزالة الارتباط def delete_correlated_features(df, cut_off=0.75, exclude = []):
بالإضافة إلى التحديد عن طريق IV ، أضفنا بحثًا متكررًا عن العدد الأمثل للمتغيرات باستخدام طريقة
RFE من sklearn.
كما نرى في الرسم البياني ، بعد 13 متغيرًا لا تتغير الجودة ، مما يعني أنه يمكن حذف المتغيرات الإضافية. للتراجع ، يعتبر أكثر من 15 متغيرًا في التسجيل شكلًا سيئًا ، والذي يتم تصحيحه في معظم الحالات باستخدام RFE.
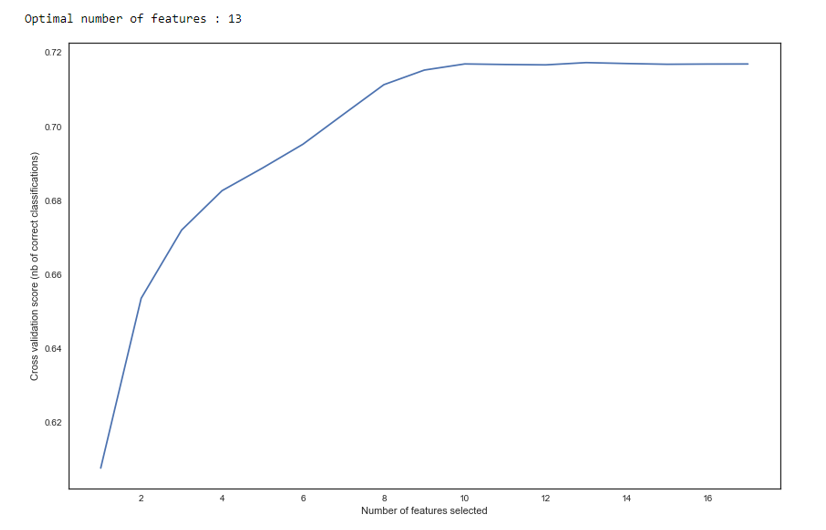
RFE def RFE_feature_selection(clf_lr, X, y): rfecv = RFECV(estimator=clf_lr, step=1, cv=StratifiedKFold(5), verbose=0, scoring='roc_auc') rfecv.fit(X, y) print("Optimal number of features : %d" % rfecv.n_features_)
بعد ذلك ، تم بناء الانحدار وتقييم مقاييسه على التحقق المتبادل وأخذ العينات الاختبارية. عادة ما ينظر الجميع إلى معامل جيني (مقالة جيدة عنه
هنا ).
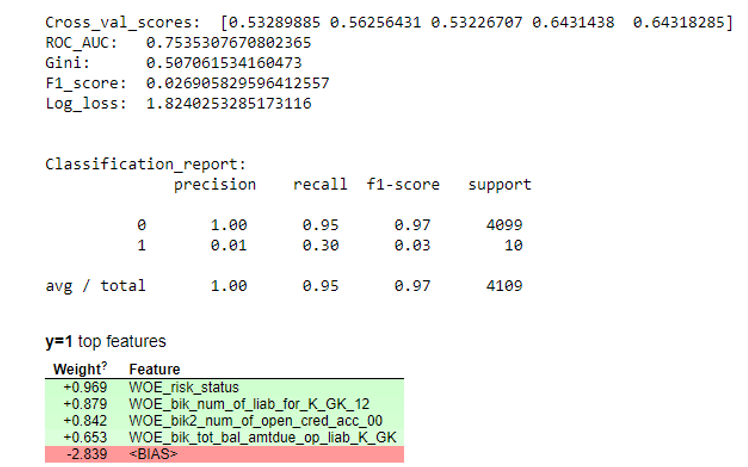
نتائج المحاكاة def plot_score(clf, X_test, y_test, feat_to_show=30, is_normalize=False, cut_off=0.5):
عندما نتأكد من أن جودة النموذج تناسبنا ، فمن الضروري كتابة جميع النتائج (معاملات الانحدار ، ومجموعات الحاويات ، والرسوم البيانية والمتغيرات الثباتية في Gini ، وما إلى ذلك) في excel. لهذا ، من الملائم استخدام xlsxwriter ، والتي يمكن أن تعمل مع كل من البيانات والصور.
أمثلة على أوراق التفوق:
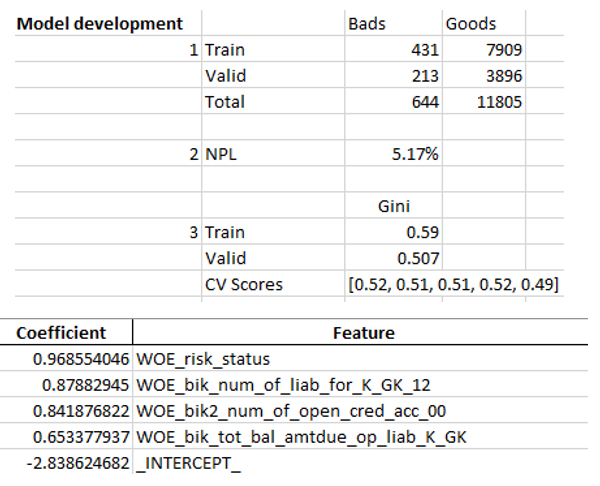
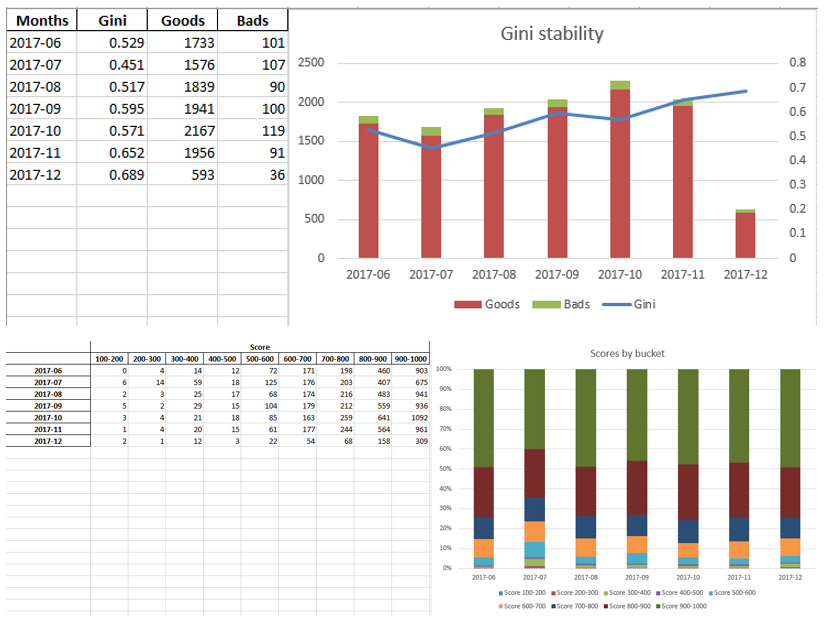
في النهاية ، تنظر إدارة التفوق النهائي مرة أخرى من قبل الإدارة ، وبعد ذلك يتم منحها لتكنولوجيا المعلومات لتضمين النموذج في الإنتاج.
الملخص
كما رأينا ، يمكن أتمتة جميع مراحل التسجيل تقريبًا بحيث لا يحتاج المحللون إلى مهارات البرمجة لبناء النماذج. في حالتنا ، بعد إنشاء هذا الإطار ، يحتاج المحلل فقط إلى جمع البيانات وتحديد العديد من المعلمات (حدد المتغير الهدف ، والأعمدة التي يجب إزالتها ، والحد الأدنى لعدد الصناديق ، ومعامل القطع لربط المتغيرات ، وما إلى ذلك) ، وبعد ذلك يمكنك تشغيل البرنامج النصي في python ، التي ستبني النموذج وتنتج التفوق مع النتائج المرجوة.
بالطبع ، في بعض الأحيان يكون من الضروري تصحيح الرمز لاحتياجات مشروع معين ، ولا يمكنك فعل ذلك بزر واحد لتشغيل البرنامج النصي أثناء النمذجة ، ولكن حتى الآن نرى جودة أفضل من حزم استخراج البيانات المستخدمة في السوق بفضل تقنيات مثل تجميع مثالي ورتيب ، والتحقق من الارتباط ، RFE ، نسخة منتظمة من الانحدار ، إلخ.
وهكذا ، بفضل استخدام Python ، قللنا بشكل كبير من وقت تطوير بطاقات التسجيل ، وكذلك خفضنا تكاليف العمالة للمحللين.