كل يوم ، يقوم المستخدمون بملايين الأنشطة عبر الإنترنت. يحتاج مشروع FACETz DMP إلى تنظيم هذه البيانات وتقسيمها لتحديد تفضيلات المستخدم. في المقالة ، سنتحدث عن كيفية تقسيم الفريق لجمهور من 600 مليون شخص ، ومعالجة 5 مليارات حدث يوميًا والعمل مع الإحصائيات باستخدام Kafka و HBase.
تستند المادة إلى نص
تقرير أعده Artyom Marinov ، متخصص البيانات الضخمة في Directual ، من مؤتمر SmartData 2017.
اسمي Artyom Marinov ، أود أن أتحدث عن كيفية إعادة تصميم بنية مشروع FACETz DMP عندما عملت في Data Centric Alliance. لماذا فعلنا ذلك ، ما أدى إلى ذلك ، أي طريق ذهبنا وما المشاكل التي واجهناها.
DMP (منصة إدارة البيانات) هي منصة لجمع ومعالجة وتجميع بيانات المستخدم. البيانات هي الكثير من الأشياء المختلفة. المنصة لديها حوالي 600 مليون مستخدم. هذه هي الملايين من ملفات تعريف الارتباط التي تنتقل عبر الإنترنت وتقوم بعدة أحداث. بشكل عام ، يبدو يوم في المتوسط شيئًا مثل هذا: نرى حوالي 5.5 مليار حدث في اليوم ، بطريقة ما تنتشر يومًا بعد يوم ، وفي الذروة تصل إلى حوالي 100 ألف حدث في الثانية.

الأحداث هي إشارات المستخدم المختلفة. على سبيل المثال ، زيارة إلى موقع: نرى المتصفح الذي ينتقل المستخدم منه ، ووكيل المستخدم ، وكل شيء يمكننا استخراجه. في بعض الأحيان نرى كيف ولأي استفسار بحث جاء إلى الموقع. يمكن أن يكون أيضًا بيانات مختلفة من العالم غير المتصل ، على سبيل المثال ، ما يدفعه مع كوبونات الخصم وما إلى ذلك.
نحن بحاجة إلى حفظ هذه البيانات ووضع علامة على المستخدم في ما يسمى مجموعات شرائح الجمهور. على سبيل المثال ، قد تكون الأجزاء "امرأة" "تحب القطط" وتبحث عن "خدمة سيارات" ، "لديها سيارة أقدم من ثلاث سنوات".
لماذا تقسم المستخدم؟ هناك العديد من التطبيقات لهذا ، على سبيل المثال ، الإعلان. يمكن لشبكات الإعلانات المختلفة تحسين خوارزميات عرض الإعلانات. إذا كنت تعلن عن خدمة سيارتك ، يمكنك إعداد حملة بطريقة تعرض فقط الأشخاص الذين لديهم سيارة قديمة المعلومات ، باستثناء أصحاب السيارات الجديدة. يمكنك تغيير محتوى الموقع ديناميكيًا ، ويمكنك استخدام البيانات للتسجيل - هناك العديد من التطبيقات.
يتم الحصول على البيانات من العديد من الأماكن المختلفة تمامًا. يمكن أن تكون إعدادات البكسل المباشرة - وهذا إذا كان العميل يريد تحليل جمهوره ، فهو يضع البكسل على الموقع ، وهي صورة غير مرئية يتم تنزيلها من خادمنا. خلاصة القول هي أننا نرى زيارة المستخدم لهذا الموقع: يمكنك حفظه ، والبدء في تحليل صورة المستخدم وفهمها ، وكل هذه المعلومات متاحة لعملائنا.

يمكن الحصول على البيانات من مختلف الشركاء الذين يرون الكثير من البيانات ويريدون تحقيق الدخل منها بطرق مختلفة. يمكن للشركاء توفير البيانات في الوقت الفعلي والقيام بعمليات تحميل دورية في شكل ملفات.
المتطلبات الرئيسية:
- قابلية التوسع الأفقية
- تقييم حجم الجمهور ؛
- راحة المراقبة والتطوير ؛
- معدل رد فعل جيد للأحداث.
أحد المتطلبات الرئيسية للنظام هو قابلية التوسع الأفقي. هناك لحظة بحيث عندما تقوم بتطوير بوابة أو متجر على الإنترنت ، يمكنك تقدير عدد المستخدمين (كيف ستنمو ، وكيف ستتغير) وفهم تقريبًا كم الموارد اللازمة ، وكيف سيعيش المتجر ويتطور بمرور الوقت.
عندما تقوم بتطوير نظام أساسي مشابه لـ DMP ، يجب أن تكون مستعدًا لحقيقة أن أي موقع كبير - الأمازون الشرطي - يمكنه وضع البكسل الخاص بك فيه ، وسيكون عليك العمل مع حركة المرور لهذا الموقع بالكامل ، بينما لا يجب أن تسقط ، والمؤشرات لا يجب أن تتغير الأنظمة بطريقة أو بأخرى من هذا.
من المهم أيضًا أن تكون قادرًا على فهم حجم جمهور معين حتى يتمكن المعلن المحتمل أو أي شخص آخر من وضع خطة إعلامية. على سبيل المثال ، يأتي شخص إليك ويطلب منك معرفة عدد النساء الحوامل من نوفوسيبيرسك الذين يبحثون عن رهن عقاري من أجل تقييم ما إذا كان من المنطقي استهدافهم أم لا.
من وجهة نظر التطوير ، يجب أن تكون قادرًا على مراقبة كل ما يحدث في نظامك ببرود ، وتصحيح جزء من حركة المرور الحقيقية ، وما إلى ذلك.
أحد أهم متطلبات النظام هو معدل رد فعل جيد للأحداث. كلما استجابت الأنظمة بشكل أسرع للأحداث ، كان ذلك أفضل. إذا كنت تبحث عن تذاكر مسرحية ، فعندما ترى نوعًا من عروض الخصم بعد يوم أو يومين أو حتى ساعة - قد يكون هذا غير ذي صلة ، حيث يمكنك بالفعل شراء تذاكر أو الذهاب إلى عرض. عندما تبحث عن مثقاب - أنت تبحث عنه ، ابحث عن ، اشترِ ، علق رفًا ، وبعد يومين بدأ القصف: "اشترِ مثاقبًا!".
كما كان من قبل
المقالة ككل عن هندسة إعادة التدوير. أود أن أخبركم ما هي نقطة انطلاقنا ، وكيف عمل كل شيء قبل التغييرات.
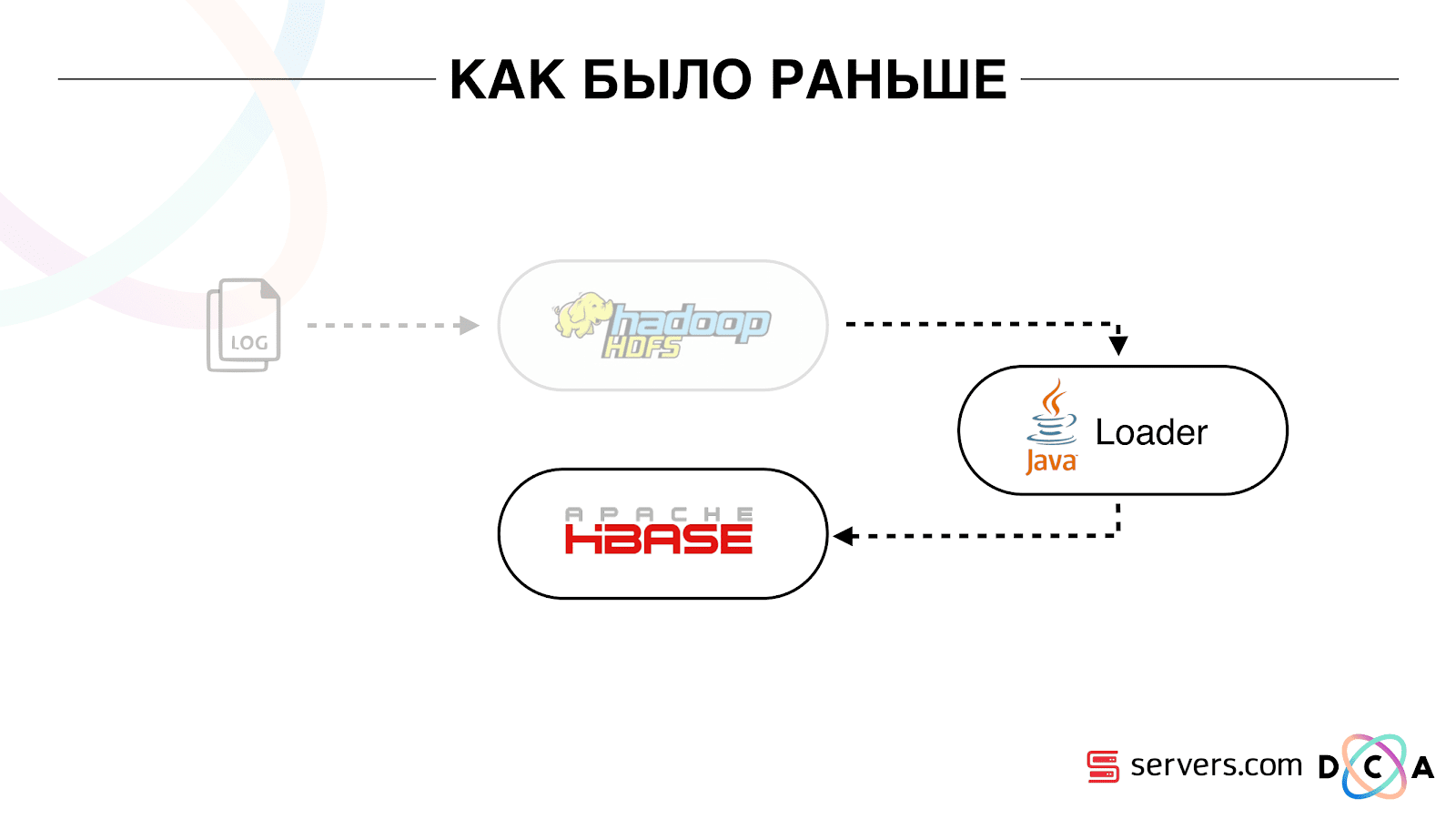
تم تخزين جميع البيانات التي كانت لدينا ، سواء كانت دفق بيانات مباشر أو سجلات ، على تخزين الملفات الموزعة HDFS. ثم كانت هناك عملية معينة بدأت بشكل دوري ، وأخذت جميع الملفات غير المعالجة من HDFS وحولتها إلى طلبات تخصيب البيانات في HBase ("طلبات PUT").
كيف نقوم بتخزين البيانات في HBase
هذا هو قاعدة بيانات عمود سلسلة زمنية. لديها مفهوم صف مفتاح - هذا هو المفتاح الذي تخزن بياناتك تحته. نستخدم معرف المستخدم كمفتاح ، معرف المستخدم ، الذي ننشئه عندما نرى المستخدم للمرة الأولى. داخل كل مفتاح ، يتم تقسيم البيانات إلى عائلة العمود - كيانات على مستوى يمكنك إدارة المعلومات التعريفية لبياناتك. على سبيل المثال ، يمكنك تخزين ألف نسخة من السجلات لـ "بيانات" عائلة العمود وتخزينها لمدة شهرين ، وبالنسبة لعائلة العمود "الخام" - كل عام ، كخيار.
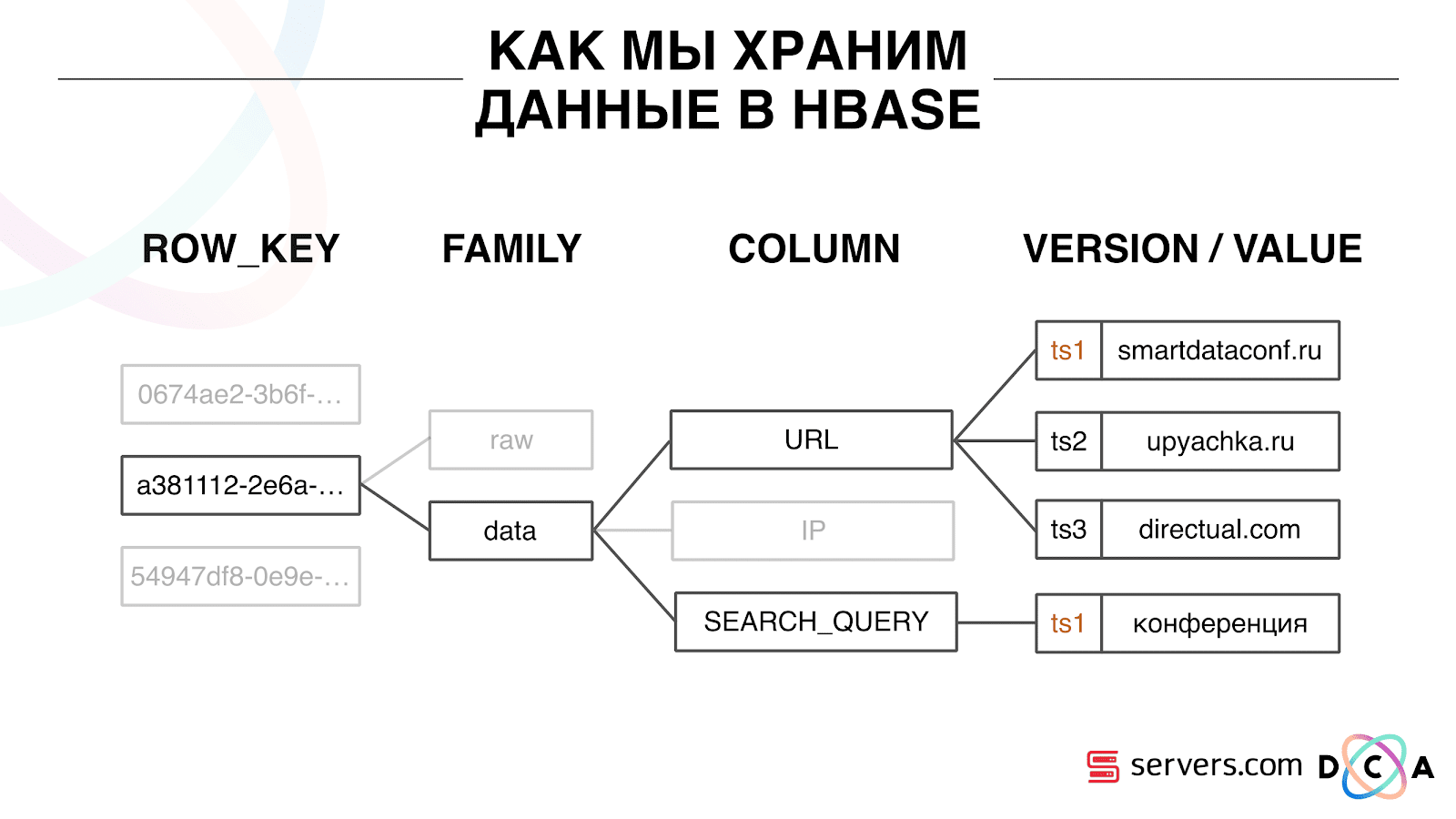
داخل عائلة العمود ، هناك العديد من مؤهلات العمود (فيما يلي العمود). نستخدم سمات المستخدم المختلفة كعمود. يمكن أن يكون عنوان URL الذي ذهب إليه وعنوان IP واستعلام البحث. والأهم من ذلك ، يتم تخزين الكثير من المعلومات داخل كل عمود. داخل عنوان URL للعمود ، يمكن الإشارة إلى أن المستخدم ذهب إلى smartdataconf.ru ، ثم إلى بعض المواقع الأخرى. ويتم استخدام الطابع الزمني كإصدار - سترى سجلًا مرتبًا لزيارات المستخدم. في حالتنا ، يمكننا تحديد وصول المستخدم إلى موقع smartdataconf باستخدام الكلمة الرئيسية "مؤتمر" ، لأن لديهم نفس الطابع الزمني.
العمل مع HBase
هناك عدة خيارات للعمل مع HBase. يمكن أن تكون طلبات PUT (طلب تغيير البيانات) ، طلب GET ("أعطني جميع البيانات الموجودة على المستخدم Vasya" وما إلى ذلك). يمكنك تشغيل طلبات SCAN - المسح المتسلسل متعدد الخيوط لجميع البيانات في HBase. استخدمنا هذا سابقًا للترميز في شرائح الجمهور.
كانت هناك مهمة تسمى Analytics Engine ، تم تشغيلها مرة واحدة في اليوم وفحص HBase في سلاسل محادثات متعددة. لكل مستخدم ، رفعت القصة بأكملها من HBase وأدارتها من خلال مجموعة من النصوص التحليلية.

ما هو النص التحليلي؟ هذا نوع من الصندوق الأسود (فئة جافا) ، الذي يتلقى جميع بيانات المستخدم كمدخل ويعطي مجموعة من الأجزاء التي يعتبرها مناسبة كمخرجات. نعطي كل شيء للنص الذي نراه - IP ، والزيارات ، UserAgent ، وما إلى ذلك ، وفي الإخراج الذي تقدمه البرامج النصية: "هذه امرأة ، تحب القطط ، لا تحب الكلاب".
أعطيت هذه البيانات للشركاء ، تم النظر في الإحصاءات. كان من المهم بالنسبة لنا أن نفهم عدد النساء بشكل عام ، وعدد الرجال ، وعدد الأشخاص الذين يحبون القطط ، وكم من يملك أو لا يمتلك سيارة ، وما إلى ذلك.
قمنا بتخزين الإحصائيات في MongoDB وكتبنا بزيادة عداد قطعة معين لكل يوم. كان لدينا رسم بياني لحجم كل قطعة لكل يوم.
كان هذا النظام جيدًا لوقته. سمح للقياس أفقياً ، والنمو ، والسماح بتقدير حجم الجمهور ، ولكن كان لديه عدد من العوائق.
لم يكن من الممكن دائمًا فهم ما يحدث في النظام ، للنظر في السجلات. بينما كنا في المضيف السابق ، غالبًا ما كانت المهمة تقع لأسباب مختلفة. كان هناك مجموعة Hadoop من أكثر من 20 خادمًا ، مرة واحدة في اليوم تعطل أحد الخوادم بثبات. أدى ذلك إلى حقيقة أن المهمة يمكن أن تسقط جزئيًا ولا تحسب البيانات. كان من الضروري الحصول على وقت لإعادة تشغيله ، وبالنظر إلى أنه عمل لعدة ساعات ، كان هناك عدد من الفروق الدقيقة المحددة.
الشيء الأساسي الذي لم تحققه الهندسة المعمارية الحالية هو أن وقت رد الفعل على الحدث كان طويلًا جدًا. حتى أن هناك قصة حول هذا الموضوع. كانت هناك شركة أصدرت قروضًا صغيرة للسكان في المناطق ، وقمنا بالشراكة معهم. يأتي عميلهم إلى الموقع ، ويملأ طلبًا للحصول على قروض صغيرة ، وتحتاج الشركة إلى تقديم إجابة في غضون 15 دقيقة: هل هم على استعداد لتقديم قرض أم لا. إذا كنت مستعدًا ، فقد قاموا على الفور بتحويل الأموال إلى البطاقة.
كل شيء يعمل نوع جيد. قرر العميل التحقق من كيفية حدوث ذلك بشكل عام: فقد أخذوا كمبيوتر محمول منفصلًا ، وقاموا بتثبيت نظام نظيف ، وزاروا العديد من الصفحات على الإنترنت وذهبوا إلى موقعهم. يرون أن هناك طلبًا ، وردًا نقول أنه لا توجد بيانات حتى الآن. يسأل العميل: "لماذا لا توجد بيانات؟"
نوضح: هناك فجوة معينة قبل أن يتخذ المستخدم إجراءً. يتم إرسال البيانات إلى HBase ، ومعالجتها ، وعندها فقط يتلقى العميل النتيجة. يبدو أنه إذا لم ير المستخدم الإعلان - فكل شيء على ما يرام ، فلن يحدث شيء سيئ. ولكن في هذه الحالة ، قد لا يتم منح المستخدم قرضًا بسبب التأخير.
هذه ليست حالة معزولة ، وكان من الضروري التحول إلى نظام الوقت الحقيقي. ماذا نريد منها؟

نريد كتابة البيانات إلى HBase بمجرد أن نراها. لقد رأينا زيارة ، وأثرينا كل ما نعرفه ، وأرسلناه إلى التخزين. بمجرد تغيير البيانات الموجودة في التخزين ، تحتاج إلى تشغيل المجموعة الكاملة من النصوص التحليلية التي لدينا. نريد راحة المراقبة والتطوير ، والقدرة على كتابة نصوص جديدة ، وتصحيحها إلى أجزاء من حركة المرور الحقيقية. نريد أن نفهم ما هو النظام مشغول الآن.
أول شيء بدأناه هو حل المشكلة الثانية: تقسيم المستخدم فورًا بعد تغيير البيانات عنه في HBase. في البداية ، كان لدينا عقد عمل (تم إطلاق مهام تقليل الخريطة عليها) تقع في نفس المكان مثل HBase. في عدد من الحالات ، كان جيدًا جدًا - يتم إجراء العمليات الحسابية بجوار البيانات ، وتعمل المهام بسرعة كبيرة ، تمر حركة مرور قليلة عبر الشبكة. من الواضح أن المهمة تستهلك بعض الموارد ، لأنها تدير مخطوطات تحليلية معقدة.
عندما نذهب إلى العمل في الوقت الحقيقي ، تتغير طبيعة الحمل على HBase. ننتقل إلى قراءات عشوائية بدلا من القراءات المتسلسلة. من المهم أن الحمل على HBase متوقع - لا يمكننا السماح لشخص ما بتشغيل المهمة على مجموعة Hadoop وإفساد أداء HBase.
أول شيء فعلناه هو نقل HBase لفصل الخوادم. كما قام بتعديل BlockCache و BloomFilter. ثم قمنا بعمل جيد حول كيفية تخزين البيانات في HBase. لقد أعادوا صياغة النظام الذي تحدثت عنه في البداية ، وحصدوا البيانات نفسها.

من الواضح: قمنا بتخزين IP كسلسلة ، وأصبحنا طويلاً في الأرقام. تم تصنيف بعض البيانات ، وتنفيذ أشياء المفردات ، وهلم جرا. خلاصة القول هي أنه بسبب هذا ، تمكنا من هز HBase مرتين تقريبًا - من 10 تيرابايت إلى 5 تيرابايت. يحتوي HBase على آلية مشابهة للمشغلات في قاعدة بيانات عادية. هذه آلية المعالج. كتبنا معالجًا مشتركًا ، عندما يتحول المستخدم إلى HBase ، يرسل معرف المستخدم إلى Kafka.
معرف المستخدم في Kafka. علاوة على ذلك هناك "مفصل" خدمة معينة. يقرأ دفق معرفات المستخدم ويعمل عليها جميع النصوص نفسها التي كانت من قبل ، تطلب بيانات من HBase. تم إطلاق العملية على 10٪ من حركة المرور ، ونظرنا في كيفية عملها. كل شئ كان جيد جدا.

بعد ذلك ، بدأنا في زيادة الحمل ورأينا عددًا من المشاكل. أول شيء رأيناه هو أن الخدمة تعمل ، وشرائح ، ثم تسقط عن كافكا ، وتربطها وتبدأ العمل مرة أخرى. خدمات عديدة - تساعد بعضها البعض. ثم يقع الفصل التالي ، والآخر وهكذا في دائرة. في الوقت نفسه ، لا يتم تقريب مجموعة المستخدمين للتقسيم.
كان هذا بسبب خصوصية آلية ضربات القلب في كافكا ، ثم لا يزال الإصدار 0.8. نبض القلب هو عندما يخبر المستهلكون السمسار عما إذا كانوا على قيد الحياة أم لا ، في حالتنا ، تقارير أداة التصنيف. حدث ما يلي: تلقينا حزمة كبيرة من البيانات ، وأرسلناها للمعالجة. لفترة من الوقت كان يعمل ، بينما كان يعمل - لم يتم إرسال نبضات القلب. يعتقد السماسرة أن المستهلك مات ، وأوقفه.
عمل المستهلك حتى النهاية ، وأهدر وحدات المعالجة المركزية الثمينة ، حاول أن يقول أن حزمة البيانات قد تم حلها ويمكن أخذ الحزمة التالية ، ولكن تم رفضه لأن الآخر أخذ ما كان يعمل معه. لقد أصلحناه من خلال جعل نبض حرارة الخلفية لدينا ، ثم جاءت الحقيقة نسخة أحدث من كافكا حيث قمنا بإصلاح هذه المشكلة.
ثم طرح السؤال: ما نوع الأجهزة التي يجب أن يركب عليها مُصنِّعو التجزئة لدينا. التجزئة هي عملية كثيفة الاستخدام للموارد (مرتبطة بوحدة المعالجة المركزية). من المهم ألا تستهلك الخدمة الكثير من وحدة المعالجة المركزية فحسب ، بل تقوم أيضًا بتحميل الشبكة. الآن تصل حركة المرور إلى 5 جيجابت / ثانية. كان السؤال: مكان وضع الخدمات ، على العديد من الخوادم الصغيرة أو الكبيرة قليلاً.
في تلك اللحظة ، انتقلنا بالفعل إلى
servers.com على المعدن. تحدثنا مع الرجال من الخوادم ، وساعدونا ، وجعلوا من الممكن اختبار عمل حلنا على عدد صغير من الخوادم باهظة الثمن ، وعلى العديد من الخوادم الرخيصة الثمن التي تحتوي على وحدات معالجة مركزية قوية. لقد اخترنا الخيار المناسب ، بحساب تكلفة الوحدة لمعالجة حدث واحد في الثانية. بالمناسبة ، وقع الاختيار على قوة كافية بما يكفي وفي نفس الوقت بأسعار معقولة للغاية Dell R230 ، أطلقوه - كل ذلك نجح.
من المهم أنه بعد أن يقوم القاطع بتمييز المستخدم إلى شرائح ، تعود نتيجة تحليله إلى Kafka ، في موضوع معين نتيجة التقسيم.
علاوة على ذلك ، يمكننا الاتصال بهذه البيانات بشكل مستقل من قبل المستهلكين المختلفين الذين لن يتدخلوا مع بعضهم البعض. هذا يسمح لنا بإعطاء البيانات بشكل مستقل لكل شريك ، سواء كان ذلك بعض الشركاء الخارجيين ، DSP الداخلي ، Google ، الإحصائيات.
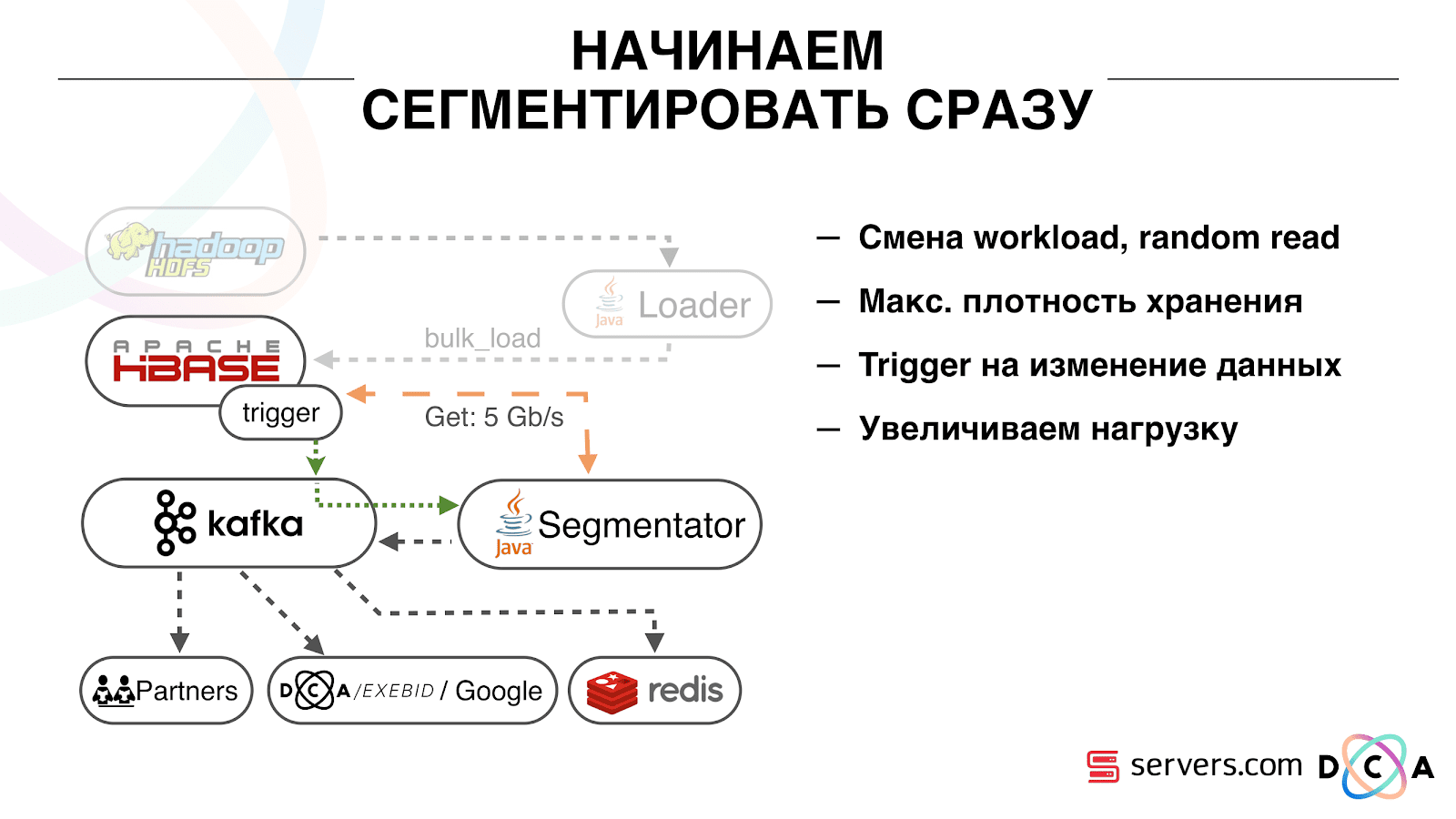
مع الإحصائيات ، هناك أيضًا نقطة مثيرة للاهتمام: في وقت سابق كان بإمكاننا زيادة قيمة العدادات في MongoDB ، وعدد المستخدمين في شريحة معينة ليوم معين. الآن ، لا يمكن القيام بذلك لأننا نحلل الآن كل مستخدم بعد أن يكمل حدثًا ، أي عدة مرات في اليوم.
لذلك ، كان علينا حل مشكلة حساب العدد الفريد للمستخدمين في ساحة المشاركات. للقيام بذلك ، استخدمنا بنية بيانات HyperLogLog وتنفيذها في Redis. هيكل البيانات احتمالي. هذا يعني أنه يمكنك إضافة معرفات المستخدم هناك ، لن يتم تخزين المعرفات نفسها ، لذلك يمكنك تخزين الملايين من المعرفات الفريدة في HyperLogLog المضغوط للغاية ، وسيستغرق ذلك ما يصل إلى 12 كيلو بايت لكل مفتاح.
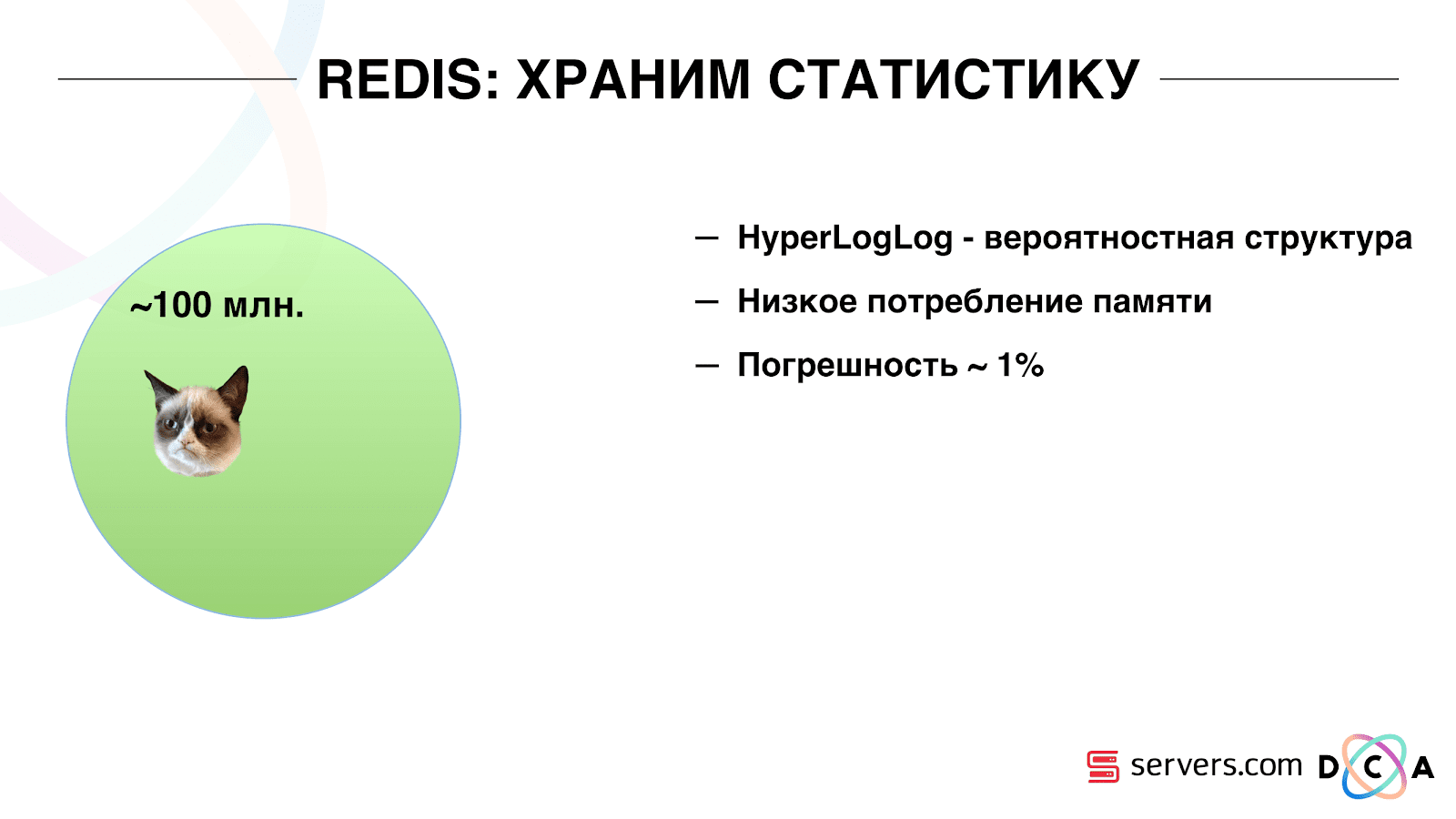
لا يمكنك الحصول على المعرفات بنفسك ، ولكن يمكنك معرفة حجم هذه المجموعة. نظرًا لأن بنية البيانات احتمالية ، فهناك بعض الأخطاء. على سبيل المثال ، إذا كان لديك شريحة "تحب القطط" ، تقدم طلبًا لحجم هذه الشريحة ليوم معين ، فستتلقى 99.2 مليون وهذا سيعني شيئًا مثل "من 99 مليون إلى 100 مليون".
أيضا في HyperLogLog يمكنك الحصول على حجم اتحاد عدة مجموعات. لنفترض أن لديك قسمين: "يحب الأختام" و "يحب الكلاب". دعنا نقول أول 100 مليون ، والمليون الثاني ، يمكن للمرء أن يسأل: "كم عدد الحيوانات التي يحبونها؟" واحصل على الجواب "حوالي 101 مليون" مع خطأ 1٪. سيكون من المثير للاهتمام حساب مقدار حب كل من القطط والكلاب في نفس الوقت ، ولكن القيام بذلك أمر صعب للغاية.

من ناحية ، يمكنك معرفة حجم كل مجموعة ، ومعرفة حجم الاتحاد ، وإضافة وطرح واحد من الآخر والحصول على التقاطع. ولكن نظرًا لحقيقة أن حجم الخطأ يمكن أن يكون أكبر من حجم التقاطع النهائي ، يمكن أن تكون النتيجة النهائية على شكل "من -50 إلى 50 ألفًا".

لقد عملنا قليلاً على كيفية زيادة الأداء عند كتابة البيانات على Redis. في البداية ، وصلنا إلى 200 ألف عملية في الثانية. ولكن عندما يكون لدى كل مستخدم أكثر من 50 شريحة - تسجيل معلومات حول كل مستخدم - 50 عملية. اتضح أننا محدودون جدًا في النطاق الترددي ، وفي هذا المثال ، لا يمكننا كتابة معلومات حول أكثر من 4 آلاف مستخدم في الثانية ، وهذا أقل عدة مرات مما نحتاجه.
قمنا بإجراء "إجراء مخزن" منفصل في Redis عبر Lua ، وقمنا بتحميله هناك وبدأنا في تمرير سلسلة إليه مع قائمة كاملة بمقاطع مستخدم واحد. الإجراء الداخلي سيؤدي إلى قطع السلسلة التي تم تمريرها إلى تحديثات HyperLogLog الضرورية وحفظ البيانات ، لذلك وصلنا إلى حوالي مليون تحديث في الثانية.
القليل من الاهتمام: Redis مترابط واحد ، يمكنك تثبيته في قلب معالج واحد ، وبطاقة شبكة إلى أخرى وتحقيق أداء 15 ٪ آخر ، مما يوفر تبديل السياق. بالإضافة إلى ذلك ، فإن النقطة المهمة هي أنه لا يمكنك ببساطة تجميع بنية البيانات ، لأن عمليات الحصول على قوة اتحادات المجموعات لا يتم تجميعها
كافكا هي أداة رائعة
ترى أن كافكا هي أداة النقل الرئيسية في النظام.
لها جوهر "الموضوع". هذا هو المكان الذي تكتب فيه البيانات ، ولكن في الجوهر - قائمة الانتظار. في حالتنا ، هناك العديد من قوائم الانتظار. واحد منهم هو معرفات المستخدمين الذين من الضروري تقسيمهم. والثاني هو نتائج تجزئة.
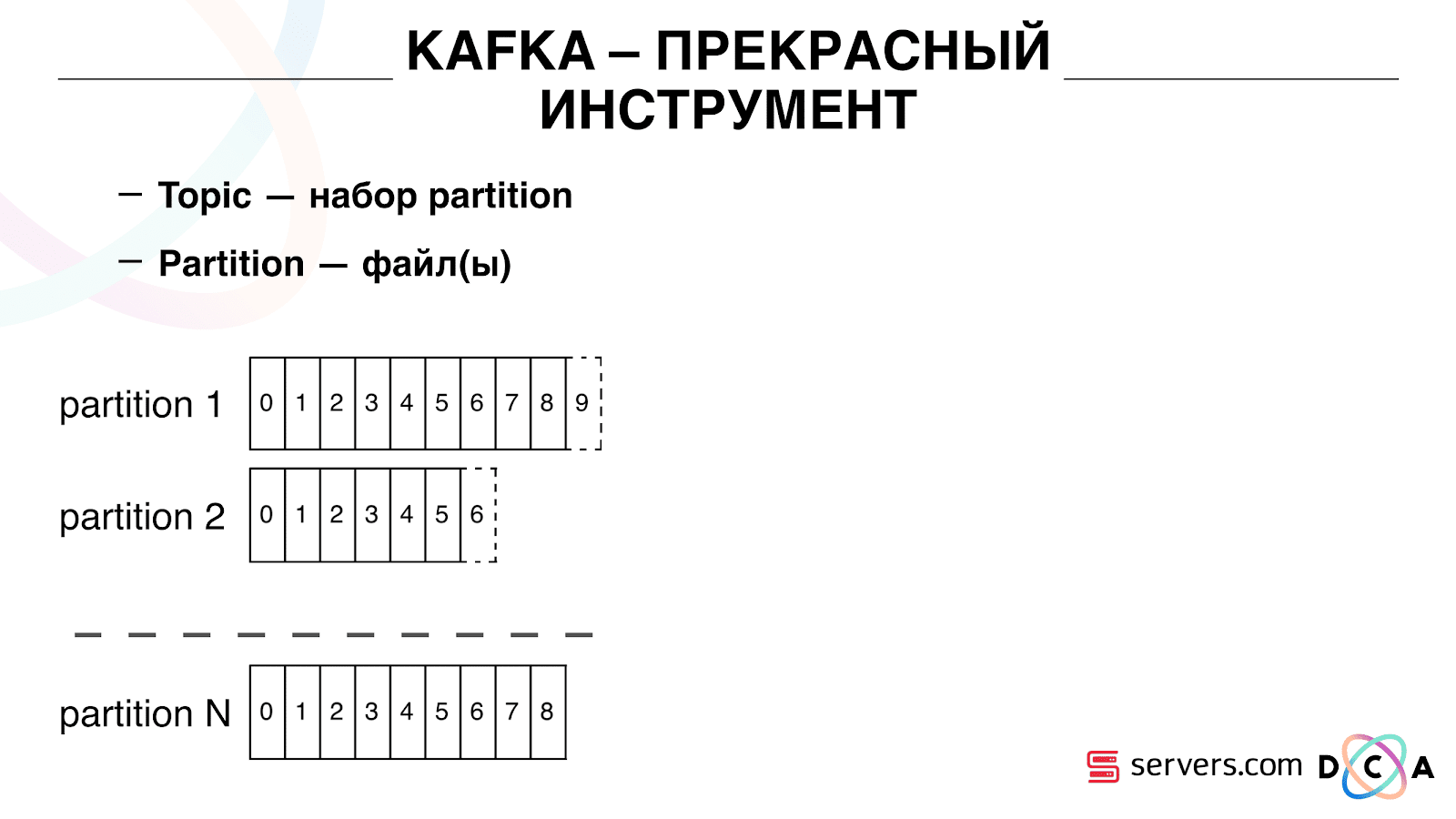
الموضوع عبارة عن مجموعة من الأقسام. ينقسم إلى بعض القطع. كل قسم هو ملف على القرص الصلب. عندما يكتب المنتجون بياناتهم ، يكتبون أجزاء من النص في نهاية القسم. عندما يقرأ عملاؤك البيانات ، فإنهم ببساطة يقرؤون من هذه الأقسام.
الشيء المهم هو أنه يمكنك ربط العديد من مجموعات المستهلكين بشكل مستقل ، وسوف تستهلك البيانات دون التدخل مع بعضها البعض. يتم تحديد ذلك باسم مجموعة المستهلكين ويتم تحقيقه على النحو التالي.
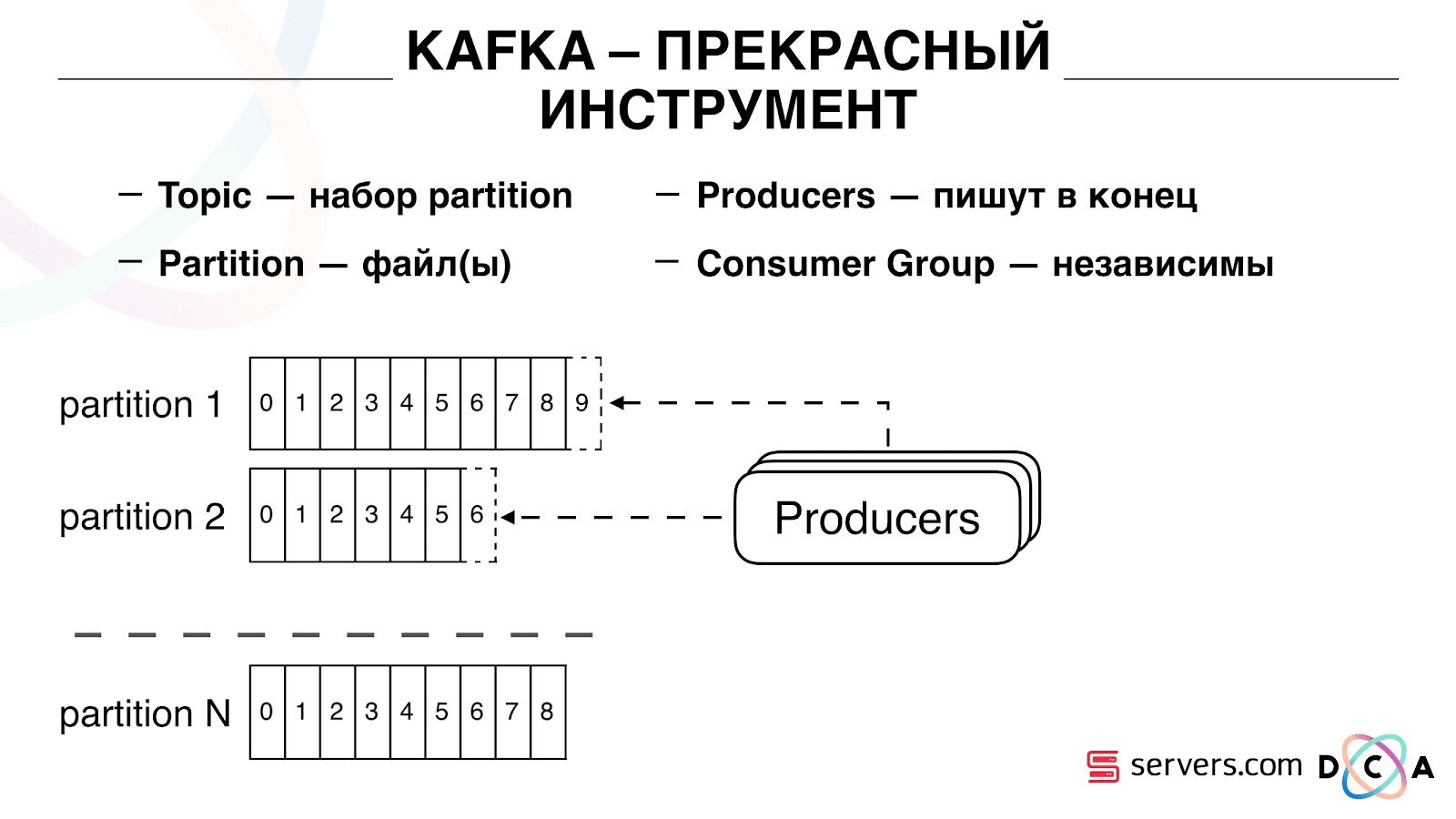
هناك شيء مثل الإزاحة ، وهو المكان الذي توجد فيه مجموعة المستهلكين الآن في كل قسم. على سبيل المثال ، تستهلك المجموعة "أ" الرسالة السابعة من القسم 1 ، والخامسة من القسم 2. المجموعة B ، مستقلة عن A ، لها تعويض آخر.
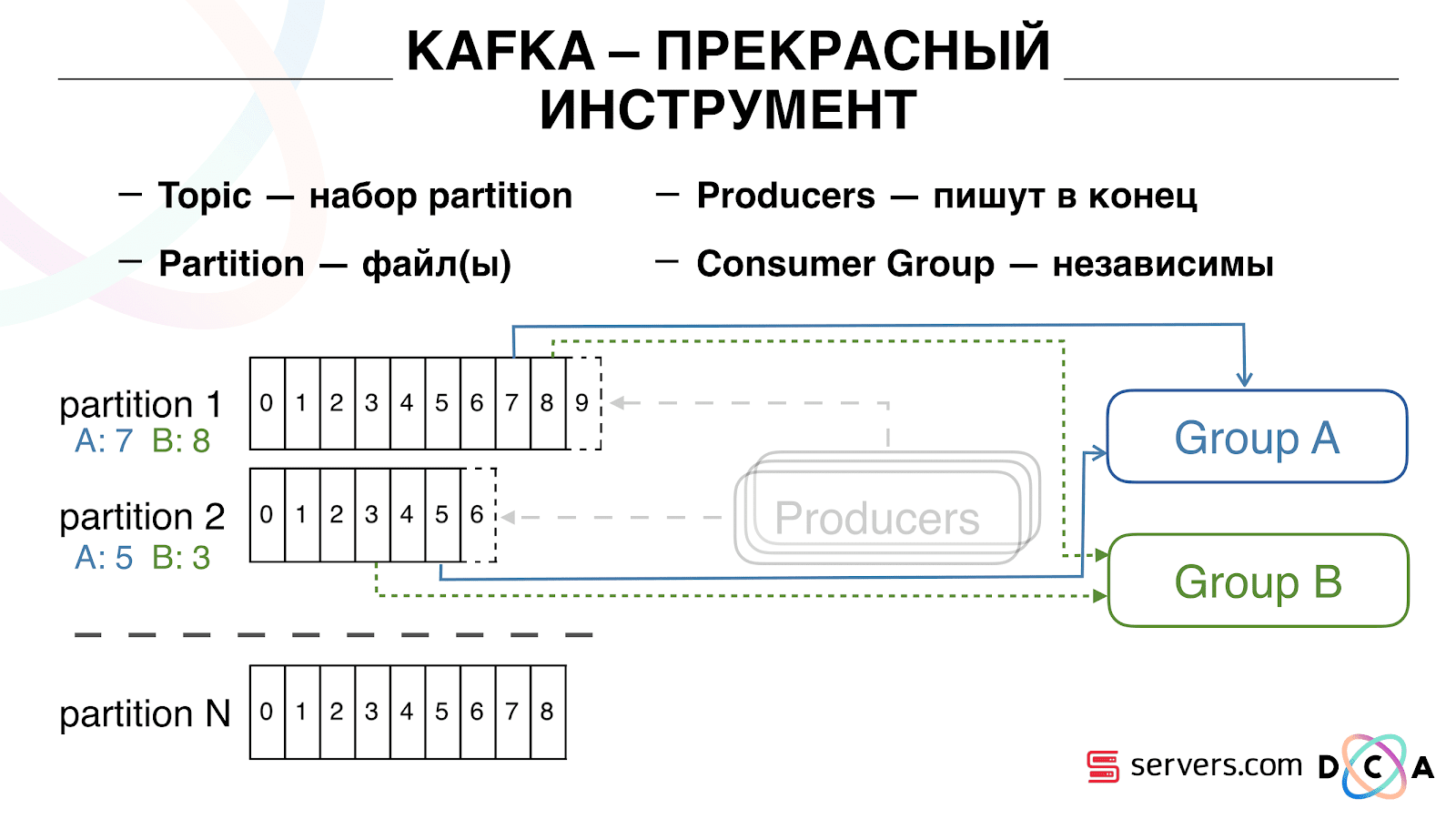 يمكنك توسيع مجموعة المستهلكين الخاصة بك أفقيًا ، إضافة عملية أو خادم آخر. سيحدث هذا إعادة تعيين القسم (سيخصص وسيط كافكا لكل مستهلك قائمة أقسام للاستهلاك) وهذا يعني أن مجموعة المستهلك الأولى ستبدأ في استهلاك القسم 1 فقط ، والثانية تستهلك القسم الثاني فقط. ، يتلقى كل مستهلك قائمة أقسام حديثة للمعالجة.
يمكنك توسيع مجموعة المستهلكين الخاصة بك أفقيًا ، إضافة عملية أو خادم آخر. سيحدث هذا إعادة تعيين القسم (سيخصص وسيط كافكا لكل مستهلك قائمة أقسام للاستهلاك) وهذا يعني أن مجموعة المستهلك الأولى ستبدأ في استهلاك القسم 1 فقط ، والثانية تستهلك القسم الثاني فقط. ، يتلقى كل مستهلك قائمة أقسام حديثة للمعالجة. إنه مريح للغاية. أولاً ، يمكنك معالجة الإزاحة لكل مجموعة من المستهلكين. تخيل أن هناك شريكًا تقوم بنقل البيانات إليه من هذا الموضوع مع نتائج التقسيم. يكتب أنه فقد عن طريق الخطأ آخر يوم من البيانات نتيجة لخلل. وأنت ، بالنسبة لمجموعة المستهلكين لهذا العميل ، ما عليك سوى التراجع يومًا واحدًا وسكب يوم البيانات بالكامل عليه. يمكننا أيضًا أن يكون لدينا مجموعة المستهلكين الخاصة بنا ، والاتصال بحركة الإنتاج ، ومشاهدة ما يحدث ، وتصحيح البيانات الحقيقية.لذا ، فقد حققنا أننا بدأنا في تقسيم المستخدمين إلى شرائح عند التغيير ، ويمكننا ربط مستهلكين جدد بشكل مستقل ، وكتابة الإحصائيات ويمكننا مشاهدتها. تحتاج الآن إلى الحصول على البيانات المكتوبة إلى HBase فور وصولها إلينا.
إنه مريح للغاية. أولاً ، يمكنك معالجة الإزاحة لكل مجموعة من المستهلكين. تخيل أن هناك شريكًا تقوم بنقل البيانات إليه من هذا الموضوع مع نتائج التقسيم. يكتب أنه فقد عن طريق الخطأ آخر يوم من البيانات نتيجة لخلل. وأنت ، بالنسبة لمجموعة المستهلكين لهذا العميل ، ما عليك سوى التراجع يومًا واحدًا وسكب يوم البيانات بالكامل عليه. يمكننا أيضًا أن يكون لدينا مجموعة المستهلكين الخاصة بنا ، والاتصال بحركة الإنتاج ، ومشاهدة ما يحدث ، وتصحيح البيانات الحقيقية.لذا ، فقد حققنا أننا بدأنا في تقسيم المستخدمين إلى شرائح عند التغيير ، ويمكننا ربط مستهلكين جدد بشكل مستقل ، وكتابة الإحصائيات ويمكننا مشاهدتها. تحتاج الآن إلى الحصول على البيانات المكتوبة إلى HBase فور وصولها إلينا.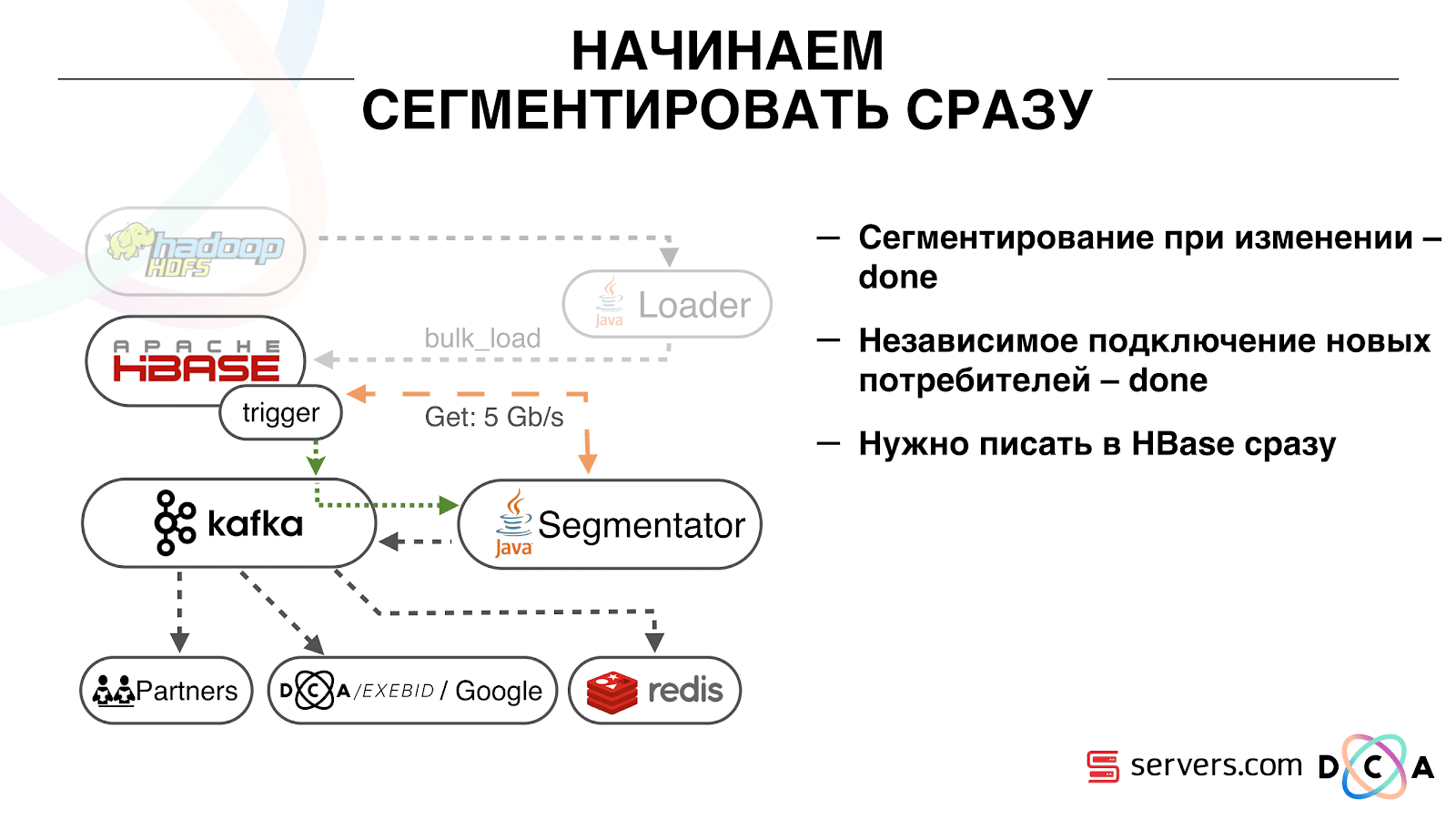 كيف فعلنا ذلك. كان هناك تحميل بيانات دفعة. كان هناك Batch Loader ، وعالج ملفات سجل نشاط المستخدم: إذا قام مستخدم بـ 10 زيارات ، جاءت الدفعة لـ 10 أحداث ، تم تسجيلها في HBase في عملية واحدة. كان هناك حدث واحد فقط لكل تجزئة. نريد الآن كتابة كل حدث منفصل في التخزين. سنقوم بزيادة دفق الكتابة ودفق القراءة بشكل كبير. كما سيزداد عدد الأحداث لكل تجزئة.
كيف فعلنا ذلك. كان هناك تحميل بيانات دفعة. كان هناك Batch Loader ، وعالج ملفات سجل نشاط المستخدم: إذا قام مستخدم بـ 10 زيارات ، جاءت الدفعة لـ 10 أحداث ، تم تسجيلها في HBase في عملية واحدة. كان هناك حدث واحد فقط لكل تجزئة. نريد الآن كتابة كل حدث منفصل في التخزين. سنقوم بزيادة دفق الكتابة ودفق القراءة بشكل كبير. كما سيزداد عدد الأحداث لكل تجزئة. أول شيء فعلناه هو Port HBase إلى SSD. بالوسائل القياسية ، لا يتم ذلك بشكل خاص. تم ذلك باستخدام HDFS. يمكنك القول أن الدليل المحدد على HDFS يجب أن يكون على مثل هذه المجموعة من الأقراص. كانت هناك مشكلة رائعة في حقيقة أنه عندما أخذنا HBase إلى SSD وأطلقنا عليها اسمًا ، وصلت جميع اللقطات إلى هناك أيضًا ، وانتهت SSDs لدينا بسرعة كبيرة.تم حل هذا أيضًا ، بدأنا في تصدير اللقطات بشكل دوري إلى ملف ، والكتابة إلى دليل HDFS آخر وحذف جميع المعلومات الوصفية حول اللقطات. إذا كنت بحاجة إلى الاستعادة - خذ الملف المحفوظ واستورده واستعادته. لحسن الحظ ، هذه العملية نادرة جدًا.أيضًا على SSD ، قاموا بإخراج Write Ahead Log ، MemStore الملتوية ، وقاموا بتشغيل كتلة التخزين المؤقت على خيار الكتابة. يسمح لك بوضعها على الفور في ذاكرة التخزين المؤقت للكتلة عند تسجيل البيانات. هذا مريح للغاية لأنه في حالتنا ، إذا سجلنا البيانات ، فمن المرجح جدًا قراءتها على الفور. هذا أعطى أيضا بعض المزايا.بعد ذلك ، قمنا بتحويل جميع مصادر البيانات لدينا لكتابة البيانات إلى Kafka. بالفعل من كافكا ، قمنا بتسجيل البيانات في HDFS للحفاظ على التوافق مع الإصدارات السابقة ، بما في ذلك حتى يتمكن محللونا من العمل مع البيانات وتشغيل مهام MapReduce وتحليل نتائجهم.قمنا بتوصيل مجموعة مستهلكين منفصلة تكتب البيانات إلى HBase. هذا ، في الواقع ، غلاف يقرأ من كافكا ويشكل PUTs في HBase.
أول شيء فعلناه هو Port HBase إلى SSD. بالوسائل القياسية ، لا يتم ذلك بشكل خاص. تم ذلك باستخدام HDFS. يمكنك القول أن الدليل المحدد على HDFS يجب أن يكون على مثل هذه المجموعة من الأقراص. كانت هناك مشكلة رائعة في حقيقة أنه عندما أخذنا HBase إلى SSD وأطلقنا عليها اسمًا ، وصلت جميع اللقطات إلى هناك أيضًا ، وانتهت SSDs لدينا بسرعة كبيرة.تم حل هذا أيضًا ، بدأنا في تصدير اللقطات بشكل دوري إلى ملف ، والكتابة إلى دليل HDFS آخر وحذف جميع المعلومات الوصفية حول اللقطات. إذا كنت بحاجة إلى الاستعادة - خذ الملف المحفوظ واستورده واستعادته. لحسن الحظ ، هذه العملية نادرة جدًا.أيضًا على SSD ، قاموا بإخراج Write Ahead Log ، MemStore الملتوية ، وقاموا بتشغيل كتلة التخزين المؤقت على خيار الكتابة. يسمح لك بوضعها على الفور في ذاكرة التخزين المؤقت للكتلة عند تسجيل البيانات. هذا مريح للغاية لأنه في حالتنا ، إذا سجلنا البيانات ، فمن المرجح جدًا قراءتها على الفور. هذا أعطى أيضا بعض المزايا.بعد ذلك ، قمنا بتحويل جميع مصادر البيانات لدينا لكتابة البيانات إلى Kafka. بالفعل من كافكا ، قمنا بتسجيل البيانات في HDFS للحفاظ على التوافق مع الإصدارات السابقة ، بما في ذلك حتى يتمكن محللونا من العمل مع البيانات وتشغيل مهام MapReduce وتحليل نتائجهم.قمنا بتوصيل مجموعة مستهلكين منفصلة تكتب البيانات إلى HBase. هذا ، في الواقع ، غلاف يقرأ من كافكا ويشكل PUTs في HBase.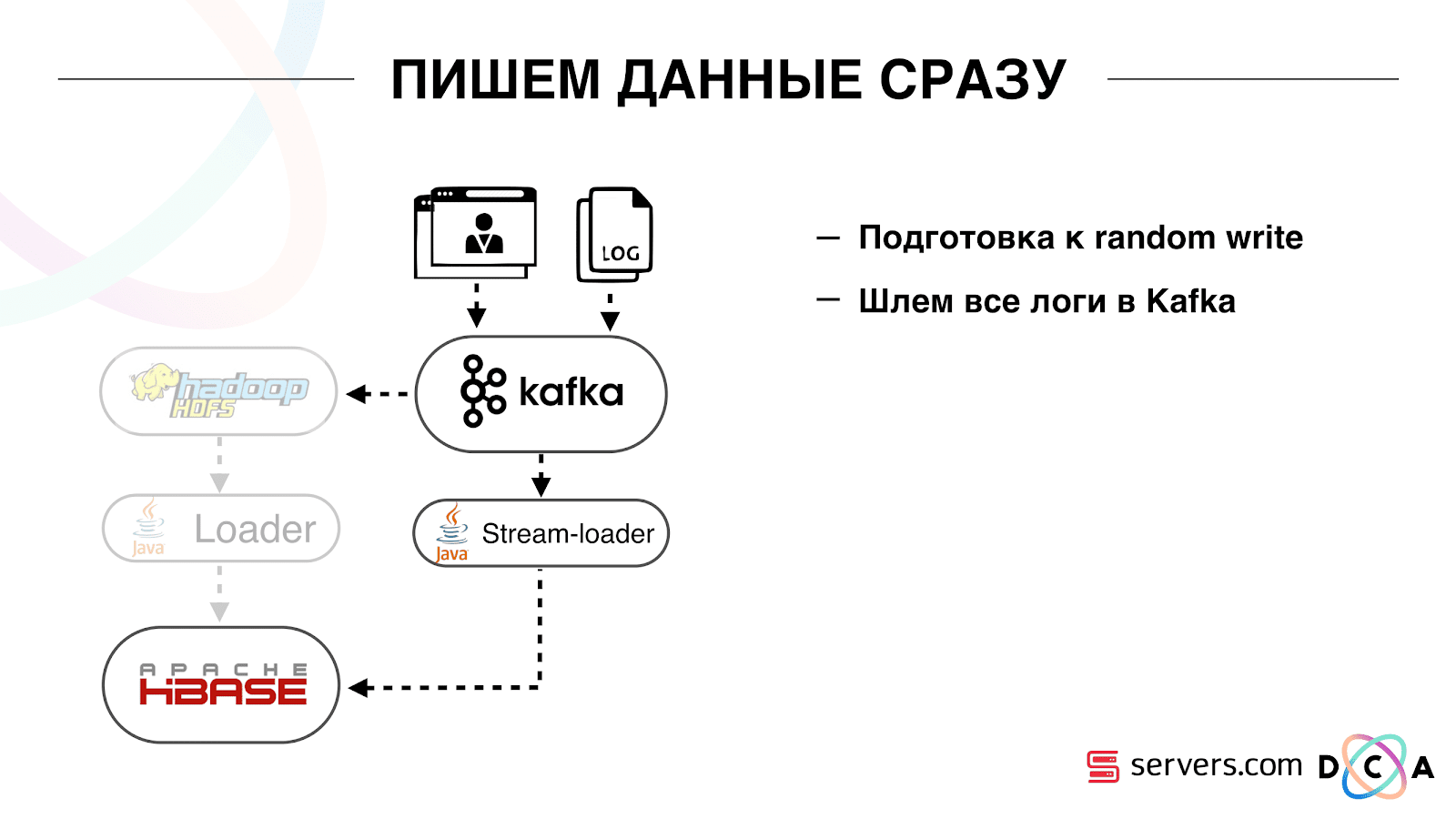 أطلقنا دائرتين بالتوازي حتى لا يكسر التوافق العكسي ولا يقلل من أداء النظام. تم إطلاق مخطط جديد فقط عند نسبة معينة من حركة المرور. بنسبة 10٪ ، كان كل شيء رائعًا. ولكن عند الحمل الأكبر ، لا يمكن لمجزات التجزئة التعامل مع تدفق التجزئة.
أطلقنا دائرتين بالتوازي حتى لا يكسر التوافق العكسي ولا يقلل من أداء النظام. تم إطلاق مخطط جديد فقط عند نسبة معينة من حركة المرور. بنسبة 10٪ ، كان كل شيء رائعًا. ولكن عند الحمل الأكبر ، لا يمكن لمجزات التجزئة التعامل مع تدفق التجزئة. نجمع المقياس "كم عدد الرسائل الموجودة في كافكا قبل أن يقرأ من هناك". هذا مقياس جيد. في البداية ، جمعنا المقياس "كم عدد الرسائل الأولية الآن" ، لكنه لا يقول أي شيء خاص. أنت تنظر: "لدي مليون رسالة خام" ، فماذا؟ لتفسير هذا المليون ، تحتاج إلى معرفة مدى سرعة عمل أداة التصنيف (المستهلك) ، وهو أمر غير واضح دائمًا.باستخدام هذا المقياس ، ستلاحظ على الفور أن البيانات يتم كتابتها إلى قائمة الانتظار ، مأخوذة منه ومعرفة مقدار انتظارهم للمعالجة. رأينا أنه لم يكن لدينا وقت للتجزئة ، وكانت الرسالة في قائمة الانتظار قبل عدة ساعات من قراءتها.يمكنك فقط إضافة السعة ، ولكنها ستكون
نجمع المقياس "كم عدد الرسائل الموجودة في كافكا قبل أن يقرأ من هناك". هذا مقياس جيد. في البداية ، جمعنا المقياس "كم عدد الرسائل الأولية الآن" ، لكنه لا يقول أي شيء خاص. أنت تنظر: "لدي مليون رسالة خام" ، فماذا؟ لتفسير هذا المليون ، تحتاج إلى معرفة مدى سرعة عمل أداة التصنيف (المستهلك) ، وهو أمر غير واضح دائمًا.باستخدام هذا المقياس ، ستلاحظ على الفور أن البيانات يتم كتابتها إلى قائمة الانتظار ، مأخوذة منه ومعرفة مقدار انتظارهم للمعالجة. رأينا أنه لم يكن لدينا وقت للتجزئة ، وكانت الرسالة في قائمة الانتظار قبل عدة ساعات من قراءتها.يمكنك فقط إضافة السعة ، ولكنها ستكون باهظة الثمن فقط. لذلك ، حاولنا التحسين.التحجيم الذاتي
لدينا HBase. المستخدم يتغير ، معرفه يطير في كافكا. يتم تقسيم الموضوع إلى أقسام ، ويتم تحديد القسم الهدف بواسطة معرف المستخدم. هذا يعني أنه عندما ترى المستخدم "Vasya" - يذهب إلى القسم 1. عندما ترى "Petya" - إلى القسم 2. هذا مناسب - يمكنك تحقيق أنك سترى مستهلكًا واحدًا في مثيل واحد من خدمتك ، والثاني - من ناحية أخرى.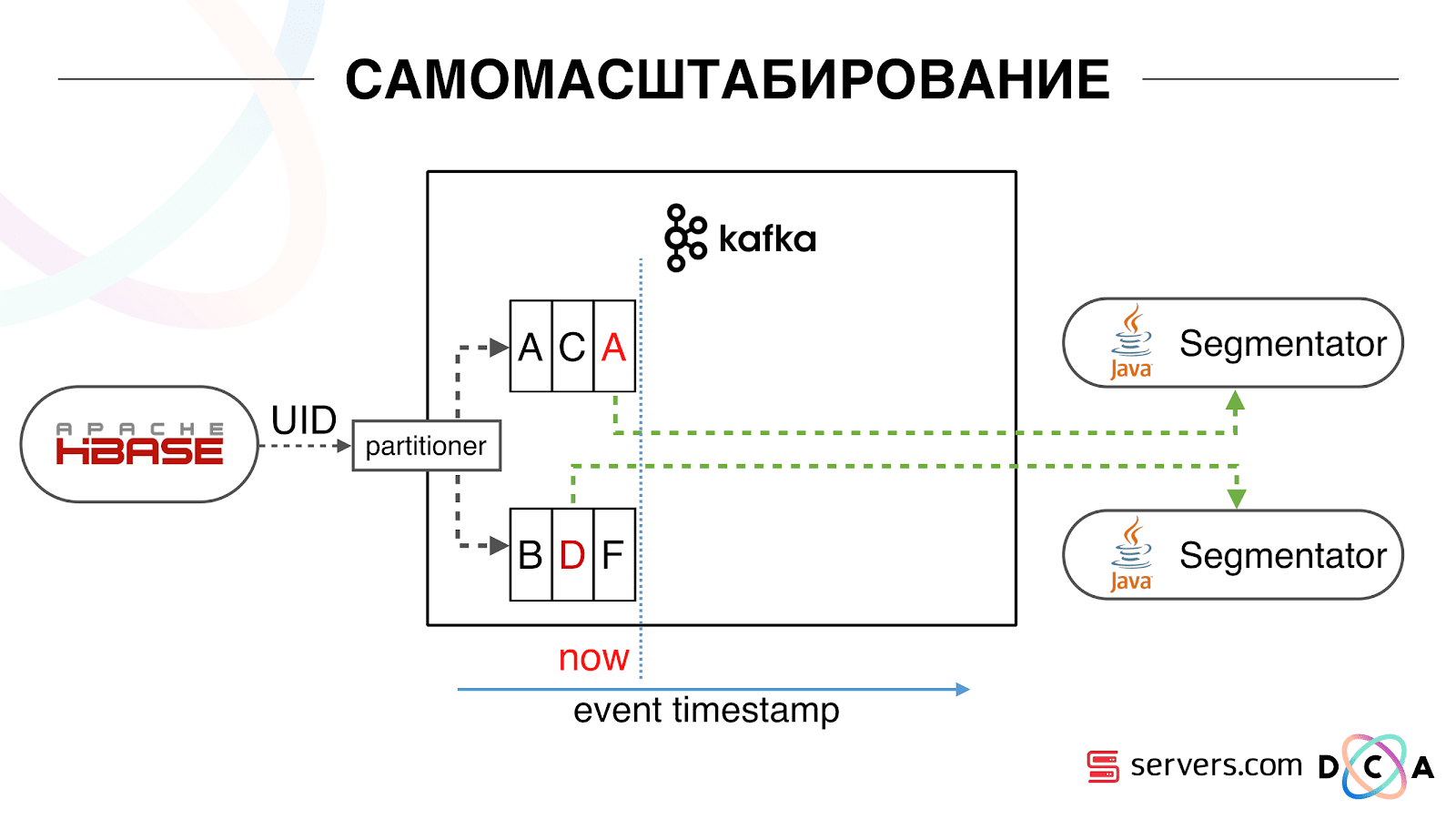 بدأنا بمراقبة ما كان يحدث. أحد سلوكيات المستخدم المعتادة على الإنترنت هي الذهاب إلى بعض مواقع الويب وفتح عدة علامات تبويب خلفية. والثاني هو الذهاب إلى الموقع وإجراء بضع نقرات للوصول إلى الصفحة المقصودة.ننظر إلى قائمة انتظار التقسيم ونرى ما يلي: زار المستخدم أ الصفحة. تأتي 5 أحداث أخرى من هذا المستخدم - يشير كل منها إلى فتح صفحة. نقوم بمعالجة كل حدث من المستخدم. ولكن في الواقع ، تحتوي البيانات الموجودة في HBase على جميع الزيارات الخمس. نعالج جميع الزيارات الخمس لأول مرة ، والمرة الثانية ، وهكذا - نحن نهدر موارد وحدة المعالجة المركزية.
بدأنا بمراقبة ما كان يحدث. أحد سلوكيات المستخدم المعتادة على الإنترنت هي الذهاب إلى بعض مواقع الويب وفتح عدة علامات تبويب خلفية. والثاني هو الذهاب إلى الموقع وإجراء بضع نقرات للوصول إلى الصفحة المقصودة.ننظر إلى قائمة انتظار التقسيم ونرى ما يلي: زار المستخدم أ الصفحة. تأتي 5 أحداث أخرى من هذا المستخدم - يشير كل منها إلى فتح صفحة. نقوم بمعالجة كل حدث من المستخدم. ولكن في الواقع ، تحتوي البيانات الموجودة في HBase على جميع الزيارات الخمس. نعالج جميع الزيارات الخمس لأول مرة ، والمرة الثانية ، وهكذا - نحن نهدر موارد وحدة المعالجة المركزية.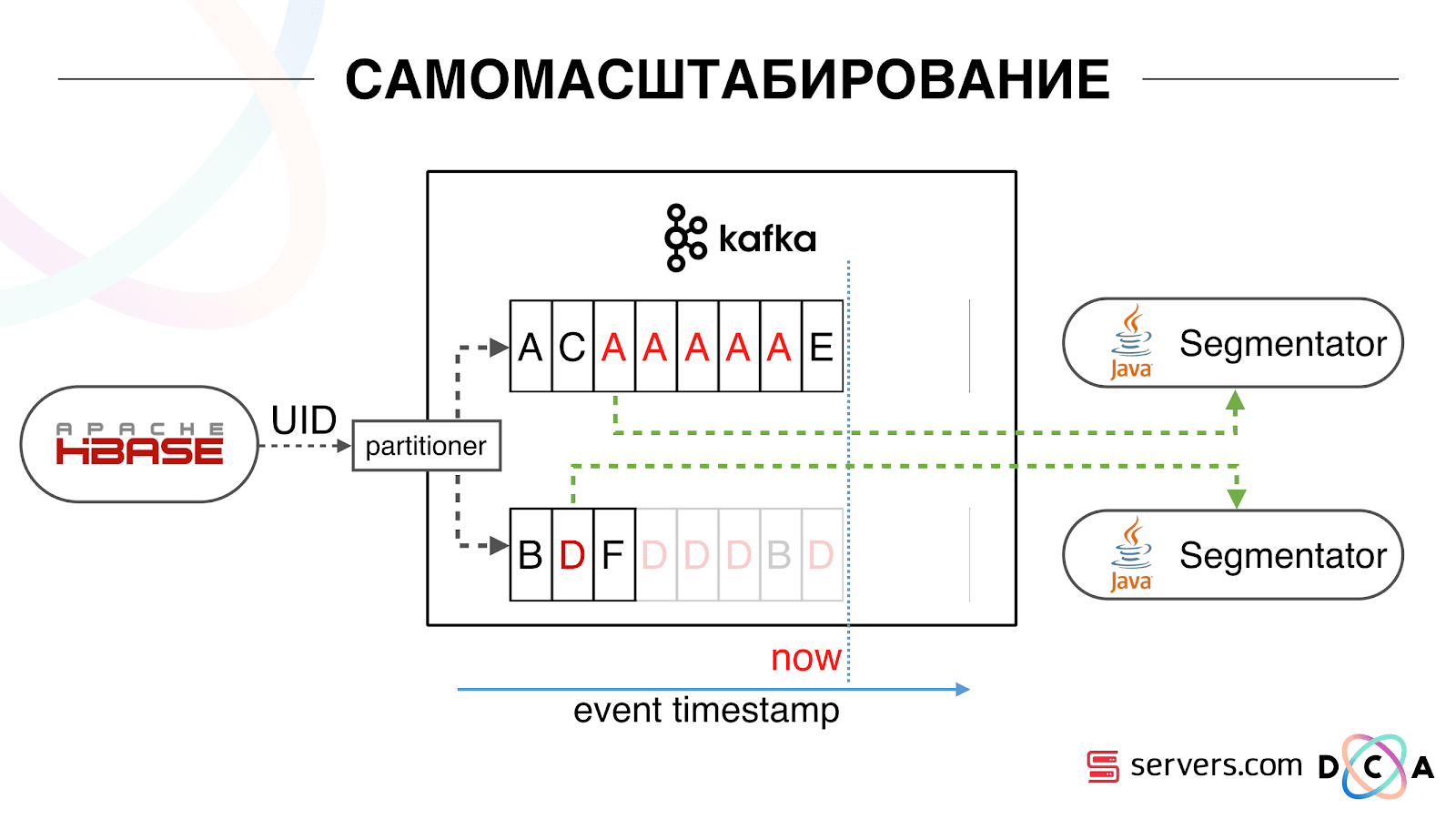 لذلك ، بدأنا بتخزين ذاكرة تخزين مؤقت محلية معينة على كل من المقاطع مع تاريخ آخر مرة قمنا فيها بتحليل هذا المستخدم. أي ، قمنا بمعالجتها ، كتب معرف المستخدم والطابع الزمني الخاص به إلى ذاكرة التخزين المؤقت. تحتوي كل رسالة kafka أيضًا على طابع زمني - نحن ببساطة نقارنها: إذا كان الطابع الزمني في قائمة الانتظار أقل من تاريخ التجزئة الأخيرة - فقد قمنا بالفعل بتحليل المستخدم لهذه البيانات ، ويمكنك ببساطة تخطي هذا الحدث.يمكن أن تكون أحداث المستخدم (Red A) مختلفة ، وهي خارج الترتيب. يمكن للمستخدم فتح العديد من علامات تبويب الخلفية ، وفتح عدة روابط متتالية ، وربما يحتوي الموقع على العديد من شركائنا في وقت واحد ، ويرسل كل منهم هذه البيانات.يمكن لبكسلنا رؤية زيارة المستخدم ، ثم إجراء آخر - سنرسل خوذته إلى أنفسنا. وصلت خمسة أحداث ، نقوم بمعالجة أول أحمر A. إذا وصل الحدث ، فهو موجود بالفعل في HBase. نرى الأحداث ، من خلال مجموعة من البرامج النصية. نرى الحدث التالي ، وهناك كل الأحداث نفسها ، لأنها مسجلة بالفعل. نعيد تشغيله مرة أخرى ونحفظ ذاكرة التخزين المؤقت بالتاريخ ونقارنه بالطابع الزمني للحدث.
لذلك ، بدأنا بتخزين ذاكرة تخزين مؤقت محلية معينة على كل من المقاطع مع تاريخ آخر مرة قمنا فيها بتحليل هذا المستخدم. أي ، قمنا بمعالجتها ، كتب معرف المستخدم والطابع الزمني الخاص به إلى ذاكرة التخزين المؤقت. تحتوي كل رسالة kafka أيضًا على طابع زمني - نحن ببساطة نقارنها: إذا كان الطابع الزمني في قائمة الانتظار أقل من تاريخ التجزئة الأخيرة - فقد قمنا بالفعل بتحليل المستخدم لهذه البيانات ، ويمكنك ببساطة تخطي هذا الحدث.يمكن أن تكون أحداث المستخدم (Red A) مختلفة ، وهي خارج الترتيب. يمكن للمستخدم فتح العديد من علامات تبويب الخلفية ، وفتح عدة روابط متتالية ، وربما يحتوي الموقع على العديد من شركائنا في وقت واحد ، ويرسل كل منهم هذه البيانات.يمكن لبكسلنا رؤية زيارة المستخدم ، ثم إجراء آخر - سنرسل خوذته إلى أنفسنا. وصلت خمسة أحداث ، نقوم بمعالجة أول أحمر A. إذا وصل الحدث ، فهو موجود بالفعل في HBase. نرى الأحداث ، من خلال مجموعة من البرامج النصية. نرى الحدث التالي ، وهناك كل الأحداث نفسها ، لأنها مسجلة بالفعل. نعيد تشغيله مرة أخرى ونحفظ ذاكرة التخزين المؤقت بالتاريخ ونقارنه بالطابع الزمني للحدث. بفضل هذا ، حصل النظام على خاصية قابلية التوسع الذاتي. المحور الصادي هو النسبة المئوية لما نفعله بمعرفات المستخدمين عند وصولهم إلينا. الأخضر - العمل الذي قمنا به ، أطلق نص التجزئة. الأصفر - لم نفعل ذلك ، لأن مجزأة بالفعل هذه البيانات بالضبط.
بفضل هذا ، حصل النظام على خاصية قابلية التوسع الذاتي. المحور الصادي هو النسبة المئوية لما نفعله بمعرفات المستخدمين عند وصولهم إلينا. الأخضر - العمل الذي قمنا به ، أطلق نص التجزئة. الأصفر - لم نفعل ذلك ، لأن مجزأة بالفعل هذه البيانات بالضبط.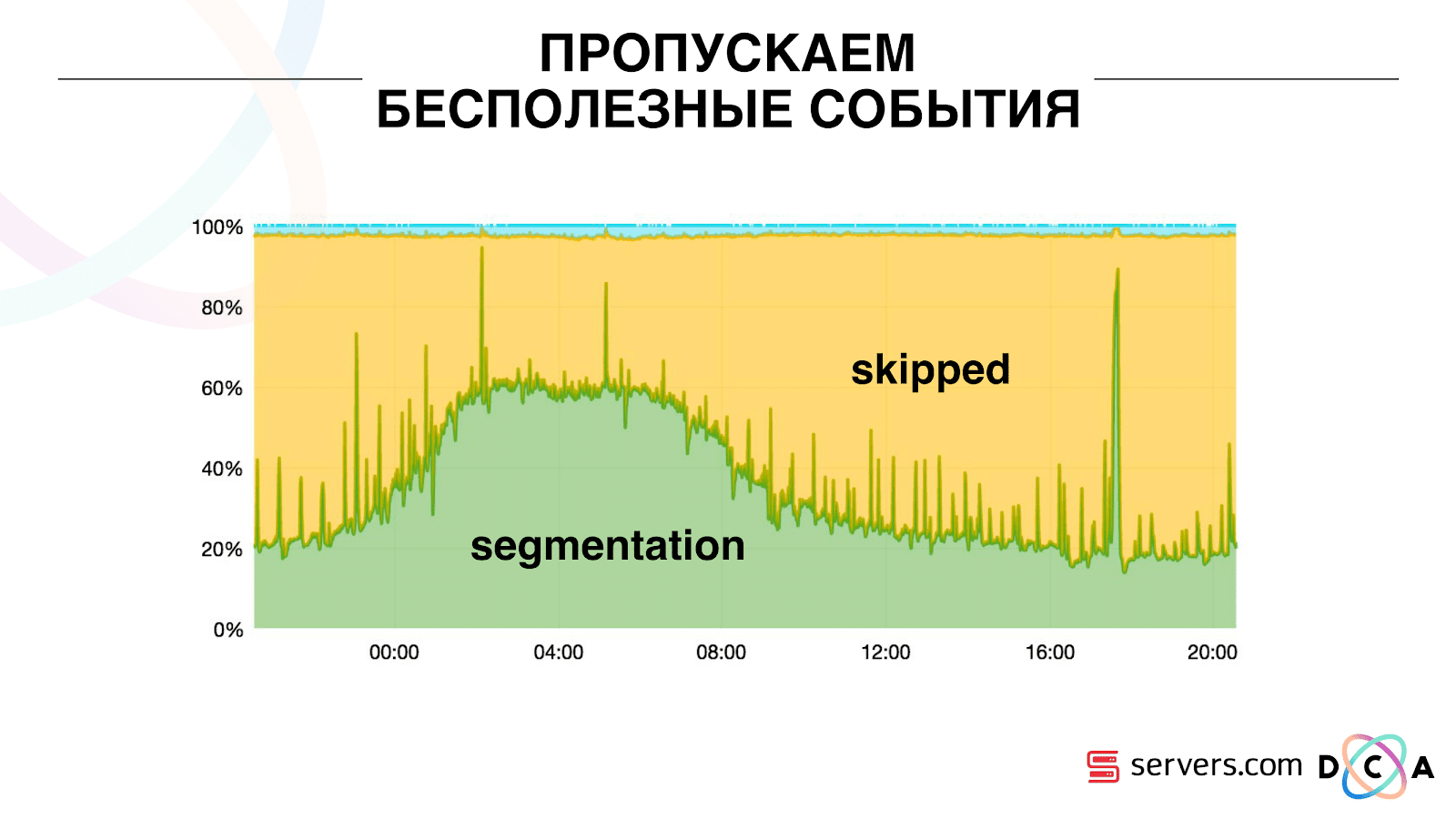 يمكن ملاحظة أن هناك موارد في الليل ، وهناك تدفق أقل للبيانات ، ويمكنك تقسيم كل حدث ثاني. يوم موارد أصغر ، ونقسم 20٪ فقط من الأحداث. قفزة في نهاية اليوم - قام الشريك بتحميل ملفات البيانات التي لم نرها من قبل ، ويجب أن يتم تجزئتها "بصدق".النظام نفسه يتكيف مع نمو الحمل. إذا كان لدينا شريك كبير جدًا ، فإننا نعالج نفس البيانات ولكن بشكل أقل تكرارًا. في هذه الحالة ، ستتدهور خصائص النظام في المساء ، سيتم تأجيل التجزئة ليس لمدة 2-3 ثوان ، ولكن لمدة دقيقة. في الصباح ، أضف الخوادم والعودة إلى النتائج المرجوة.وبالتالي ، قمنا بحفظ حوالي 5 مرات على الخوادم. الآن نعمل على 10 خوادم ، وسيستغرق الأمر 50-60.الشيء الأزرق الصغير في الأعلى هو البوتات. هذا هو الجزء الأصعب من التجزئة. لديهم عدد كبير من الزيارات ، يخلقون حمولة كبيرة جدًا على المكواة. نرى كل بوت على خادم منفصل. يمكننا أن نجمع عليه ذاكرة تخزين مؤقت محلية مع قائمة سوداء من الروبوتات. قدمنا مكافحة بسيطة للاحتيال: إذا قام المستخدم بعدد كبير من الزيارات لفترة معينة ، فعندئذ هناك شيء خاطئ به ، نضيفه إلى القائمة السوداء لفترة من الوقت. هذا شريط أزرق صغير ، حوالي 5٪. أعطونا 30٪ توفير آخر على وحدة المعالجة المركزيةوهكذا ، حققنا ما نراه خط الأنابيب الكامل لمعالجة البيانات في كل مرحلة. نرى مقاييس لمقدار الرسالة في كافكا. في المساء ، كان هناك شيء باهت في مكان ما ، زاد وقت المعالجة إلى دقيقة ، ثم تم تحريره وإعادته إلى طبيعته.
يمكن ملاحظة أن هناك موارد في الليل ، وهناك تدفق أقل للبيانات ، ويمكنك تقسيم كل حدث ثاني. يوم موارد أصغر ، ونقسم 20٪ فقط من الأحداث. قفزة في نهاية اليوم - قام الشريك بتحميل ملفات البيانات التي لم نرها من قبل ، ويجب أن يتم تجزئتها "بصدق".النظام نفسه يتكيف مع نمو الحمل. إذا كان لدينا شريك كبير جدًا ، فإننا نعالج نفس البيانات ولكن بشكل أقل تكرارًا. في هذه الحالة ، ستتدهور خصائص النظام في المساء ، سيتم تأجيل التجزئة ليس لمدة 2-3 ثوان ، ولكن لمدة دقيقة. في الصباح ، أضف الخوادم والعودة إلى النتائج المرجوة.وبالتالي ، قمنا بحفظ حوالي 5 مرات على الخوادم. الآن نعمل على 10 خوادم ، وسيستغرق الأمر 50-60.الشيء الأزرق الصغير في الأعلى هو البوتات. هذا هو الجزء الأصعب من التجزئة. لديهم عدد كبير من الزيارات ، يخلقون حمولة كبيرة جدًا على المكواة. نرى كل بوت على خادم منفصل. يمكننا أن نجمع عليه ذاكرة تخزين مؤقت محلية مع قائمة سوداء من الروبوتات. قدمنا مكافحة بسيطة للاحتيال: إذا قام المستخدم بعدد كبير من الزيارات لفترة معينة ، فعندئذ هناك شيء خاطئ به ، نضيفه إلى القائمة السوداء لفترة من الوقت. هذا شريط أزرق صغير ، حوالي 5٪. أعطونا 30٪ توفير آخر على وحدة المعالجة المركزيةوهكذا ، حققنا ما نراه خط الأنابيب الكامل لمعالجة البيانات في كل مرحلة. نرى مقاييس لمقدار الرسالة في كافكا. في المساء ، كان هناك شيء باهت في مكان ما ، زاد وقت المعالجة إلى دقيقة ، ثم تم تحريره وإعادته إلى طبيعته. يمكننا مراقبة كيفية تأثير إجراءاتنا مع النظام على صبيبه ، ويمكننا معرفة مدى تشغيل النص البرمجي ، وأين يلزم التحسين ، وما الذي يمكن حفظه. يمكننا أن نرى حجم الأجزاء ، وديناميكيات حجم الأجزاء ، وتقييم ارتباطها وتقاطعها. يمكن القيام بذلك لأحجام قطعة أكثر أو أقل.
يمكننا مراقبة كيفية تأثير إجراءاتنا مع النظام على صبيبه ، ويمكننا معرفة مدى تشغيل النص البرمجي ، وأين يلزم التحسين ، وما الذي يمكن حفظه. يمكننا أن نرى حجم الأجزاء ، وديناميكيات حجم الأجزاء ، وتقييم ارتباطها وتقاطعها. يمكن القيام بذلك لأحجام قطعة أكثر أو أقل.ماذا تريد صقله؟
لدينا مجموعة Hadoop مع بعض موارد الحوسبة. إنه مشغول - يعمل المحللون عليه خلال النهار ، لكنه في الليل مجاني عمليًا. بشكل عام ، يمكننا أن نضع حاويات ونقطع أداة التقطيع كعملية منفصلة داخل مجموعتنا. نريد تخزين الإحصاءات بشكل أكثر دقة من أجل حساب حجم التقاطع بشكل أكثر دقة. نحتاج أيضًا إلى تحسين على وحدة المعالجة المركزية. هذا يؤثر بشكل مباشر على تكلفة القرار.لتلخيص: كافكا جيدة ، ولكن ، كما هو الحال مع أي تقنية أخرى ، تحتاج إلى فهم كيفية عملها في الداخل وما يحدث لها. على سبيل المثال ، ضمان أولوية الرسالة يعمل فقط داخل القسم. إذا قمت بإرسال رسالة تذهب إلى أقسام مختلفة ، فليس من الواضح بأي ترتيب ستتم معالجتها.البيانات الحقيقية مهمة جدا. إذا لم نجرّب اختبارًا على عدد الزيارات الحقيقية ، فمن المحتمل ألا نشاهد مشاكل في برامج التتبُّع في جلسات المستخدم. سيطور شيئا في الفراغ ، يركض ويستلقي. من المهم مراقبة ما تعتبره ضروريًا للمراقبة ، وليس مراقبة ما لا تعتقده.دقيقة من الدعاية. إذا أعجبك هذا التقرير من مؤتمر SmartData ، يرجى ملاحظة أنه سيتم عقد SmartData 2018 في سان بطرسبرج في 15 أكتوبر ، وهو مؤتمر لأولئك المنغمسين في عالم التعلم الآلي والتحليل ومعالجة البيانات. سيحتوي البرنامج على الكثير من الأشياء المثيرة للاهتمام ، يحتوي الموقع بالفعل على أول المتحدثين والتقارير.