يعد التعرف التلقائي على الصور الملتقطة بالسواتل أو الصور الجوية أكثر الطرق الواعدة للحصول على معلومات حول موقع الأشياء المختلفة على الأرض. يرتبط رفض تجزئة الصورة يدويًا بشكل خاص عندما يتعلق الأمر بمعالجة مساحات كبيرة من سطح الأرض في وقت قصير.
في الآونة الأخيرة ، أتيحت لي الفرصة لتطبيق المهارات النظرية وتجربة نفسي في مجال التعلم الآلي في مشروع تجزئة الصورة الحقيقية. الهدف من المشروع هو التعرف على حوامل الغابات ، وهي تيجان الأشجار في صور الأقمار الصناعية عالية الدقة. تحت هذا الخفض ، سوف أشارك تجربتي ونتائجي.
عندما يتعلق الأمر بمعالجة الصور ، يمكن إعطاء التقسيم التعريف التالي - هذا هو التواجد على صورة المناطق المميزة الموصوفة بالتساوي في هذه المساحة من الميزات.
يُميّز بين السطوع والكفاف والملمس والتجزئة الدلالية.
إن تقسيم الصورة الدلالية (أو الدلالي) هو إبراز مناطق في الصورة ، كل منها يتوافق مع سمة معينة. بشكل عام ، يصعب تحليل مشاكل التجزئة الدلالية ، لذلك يتم استخدام الشبكات العصبية التلافيفية التي تظهر نتائج جيدة حاليًا على نطاق واسع لتجزئة الصورة.
بيان المشكلة
يتم حل مشكلة التجزئة الثنائية - يتم تغذية الصور الملونة (صور الأقمار الصناعية عالية الدقة) لمدخلات الشبكة العصبية ، والتي من الضروري إبراز مناطق البكسل التي تنتمي إلى نفس الفئة - الأشجار.
بيانات المصدر
تحت تصرفي كان هناك مجموعة من مربعات صور الأقمار الصناعية لمنطقة مستطيلة تناسب المضلع. بداخله ، وتحتاج إلى البحث عن الأشجار. يتم تقديم المضلع أو المضلع المتعدد كملف GeoJSON. في حالتي ، كانت البلاطات بتنسيق png بحجم 256 × 256 بكسل بالألوان الحقيقية. (للأسف ، بدون IR) ترقيم البلاط في شكل / zoom/x/y.png.
من المضمون أن يتم الحصول على جميع البلاط في المجموعة من صور الأقمار الصناعية التي تم التقاطها في نفس الوقت تقريبًا من العام (أواخر الربيع - أوائل الخريف ، اعتمادًا على مناخ منطقة معينة) ويوم بزاوية مماثلة للسطح ، حيث تم السماح بغطاء سحابي طفيف.
إعداد البيانات
نظرًا لأن مساحة المضلع المطلوب قد تكون أقل من هذه المنطقة المستطيلة ، فإن أول شيء يجب القيام به هو استبعاد تلك المربعات التي تتجاوز حدود المضلع. للقيام بذلك ، تم كتابة برنامج نصي بسيط يحدد البلاط الضروري من مضلع ملف GeoJSON. يعمل على النحو التالي. بادئ ذي بدء ، يتم
تحويل إحداثيات جميع رؤوس المضلع إلى أرقام تجانب وإضافتها إلى صفيف. هناك أيضًا تعويض متعلق بالأصل. من أجل الفحص البصري ، يتم إنشاء صورة حيث يساوي بكسل واحد مربع واحد. يتم تعبئة المضلع في الصورة بالفعل مع مراعاة الإزاحة باستخدام PIL. بعد ذلك ، يتم نقل الصورة إلى مصفوفة ، حيث يتم تحديد المربعات الضرورية ، والتي تقع داخل المضلع.
from PIL import Image, ImageDraw
 نتيجة مرئية لتحويل مضلع إلى مجموعة من البلاط
نتيجة مرئية لتحويل مضلع إلى مجموعة من البلاطنموذج الشبكة
لحل مشاكل تجزئة الصورة ،
هناك عدد من نماذج الشبكات العصبية التلافيفية. قررت استخدام
U-Net ، الذي أثبت نفسه في مهام تجزئة الصورة الثنائية. تتكون بنية U-Net مما يسمى مسارات التقلص والمسارات التوسعية ، والتي يتم توصيلها بواسطة probros في مراحل الحجم المناسبة ، وتقليل دقة الصورة أولاً ، ثم زيادتها ، ثم دمجها مسبقًا مع بيانات الصورة والمرور عبر طبقات أخرى الالتواء. وبالتالي ، تعمل الشبكة كنوع من المرشحات. يتم تقديم كتل الضغط وإلغاء الضغط كمجموعة من الكتل ذات بعد معين. وتتكون كل كتلة من العمليات الأساسية: الالتفاف و ReLu والحد الأقصى للتجمع. هناك تطبيقات لنموذج U-Net على Keras و Tensorflow و Caffe و PyTorch. لقد استخدمت Keras.
إنشاء مجموعة تدريب
لتعلم نموذج Unet هذا ، تحتاج إلى صور. أول شيء في رأسي جاء بفكرة أخذ بيانات OpenStreetMap وإنشاء أقنعة للتدريب بناءً عليها. ولكن كما اتضح في حالتي ، فإن دقة المضلعات التي أحتاجها تترك الكثير مما هو مرغوب فيه. كنت بحاجة أيضًا إلى وجود أشجار مفردة لا يتم رسمها دائمًا. لذلك ، كان عليّ التخلي عن مثل هذا المشروع. ولكن يجدر القول ، بالنسبة لأشياء أخرى ، مثل الطرق أو المباني ، يمكن أن يكون هذا النهج
فعالاً .

نظرًا لأنه كان يجب التخلي عن فكرة إنشاء عينة تدريب تلقائيًا استنادًا إلى بيانات OSM ، فقد قررت تحديد منطقة صغيرة يدويًا. للقيام بذلك ، استخدمت محرر JOSM ، حيث استخدمت صور التضاريس المتاحة كركيزة ، والتي قمت بوضعها على خادم محلي. ثم ظهرت مشكلة أخرى - لم أجد فرصة لتشغيل عرض شبكة البلاط باستخدام أدوات JOSM العادية. لذلك ، بدأ زوجان من الأسطر البسيطة في .htaccess على نفس الخادم من دليل مختلف بإصدار مربع فارغ مع حد بكسل لأي طلب من النموذج grid_tile / z / x / y.png وإضافة مثل هذه الطبقة المرتجلة إلى JOSM. يا لها من دراجة.
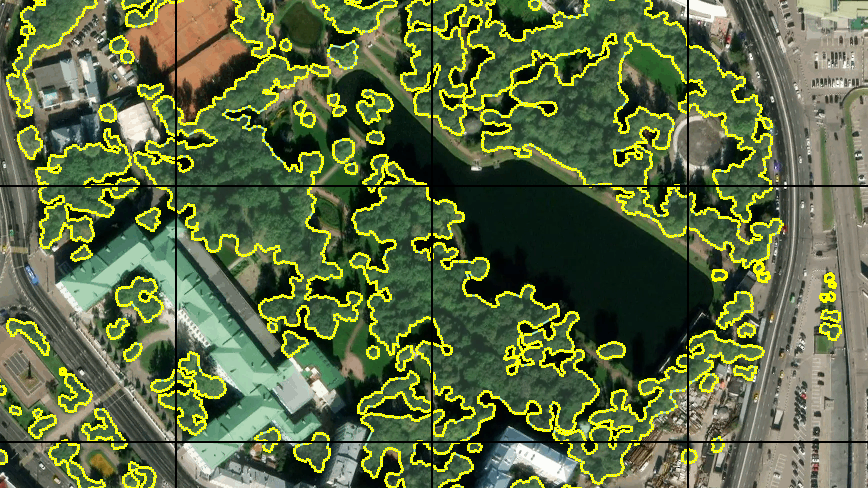
أولاً ، قمت بتمييز حوالي 30 بلاط. مع لوحة الرسم و "وضع الرسم السريع" في JOSM ، لم يستغرق الأمر الكثير من الوقت. أدركت أن مثل هذه الكمية ليست كافية للتدريب الكامل ، لكنني قررت البدء بهذا. علاوة على ذلك ، سيكون التدريب على الكثير من البيانات سريعًا بما يكفي.
التدريب والنتيجة الأولى
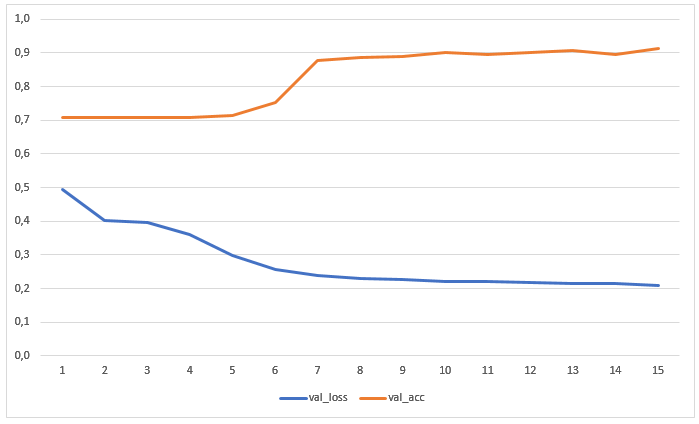
تم تدريب الشبكة لمدة 15 حقبة دون زيادة البيانات مسبقًا. يوضح الرسم البياني قيم الخسائر والدقة في عينة الاختبار:
تبين أن نتيجة التعرف على الصور التي لم تكن في التدريب ولا في عينة الاختبار كانت معقولة تمامًا:

بعد دراسة أكثر شمولاً للنتائج ، أصبحت بعض المشاكل واضحة. كانت العديد من الأخطاء في مناطق الظل للصور - إما أن الشبكة عثرت على أشجار في الظل حيث لم تكن موجودة ، أو العكس تمامًا. كان هذا متوقعًا ، نظرًا لوجود عدد قليل من الأمثلة في مجموعة التدريب. لكنني لم أتوقع أن يتم التعرف على بعض قطع سطح الماء والأسقف المظلمة من الملف المعدني (من المفترض) كأشجار. كان هناك أيضا عدم دقة مع المروج. تقرر تحسين العينة بإضافة عدد أكبر من الصور مع أقسام مثيرة للجدل ، وبالتالي تضاعفت العينة التدريبية تقريبًا.
زيادة البيانات
لزيادة حجم البيانات ، قررت تدوير الصورة بزاوية عشوائية. بادئ ذي بدء ، حاولت الوحدة النمطية القياسية keras.preprocessing.image.ImageDataGenerator. عند التدوير أثناء الحفاظ على المقياس ، تظل المساحات الفارغة عند حواف الصور ، والتي يتم تعيين
حشوها بواسطة معلمة
fill_mode . يمكنك ببساطة ملء هذه المناطق بالألوان من خلال تحديدها
بالسيرة الذاتية ، لكنني أردت
دورانًا كاملاً ، على أمل أن يكون الاختيار أكثر اكتمالًا ، وقمت بتنفيذ المولد بنفسي. هذا سمح بزيادة الحجم بأكثر من عشر مرات.
 fill_mode = الأقرب
fill_mode = الأقربيعمل مولد بياناتي على لصق أربع بلاطات مجاورة في بلاطة ذات مصدر واحد تبلغ 512 × 512 بكسل. يتم اختيار زاوية الدوران بشكل عشوائي ، مع مراعاة ذلك ، يتم حساب الفواصل المسموح بها لـ x و y لمركز البلاط الناتج ، حيث لا تتجاوز التجانب الأصلي. يتم اختيار إحداثيات المركز بشكل عشوائي مع مراعاة الفترات المسموح بها. بالطبع ، كل هذه التحولات تنطبق على زوج قناع البلاط. كل هذا يتكرر لمجموعات مختلفة من البلاط المجاور. من مجموعة واحدة يمكنك الحصول على أكثر من اثني عشر قطعة من البلاط مع أقسام مختلفة من التضاريس تدور في زوايا مختلفة.
 مثال على نتيجة المولد
مثال على نتيجة المولدالتعلم بمزيد من البيانات
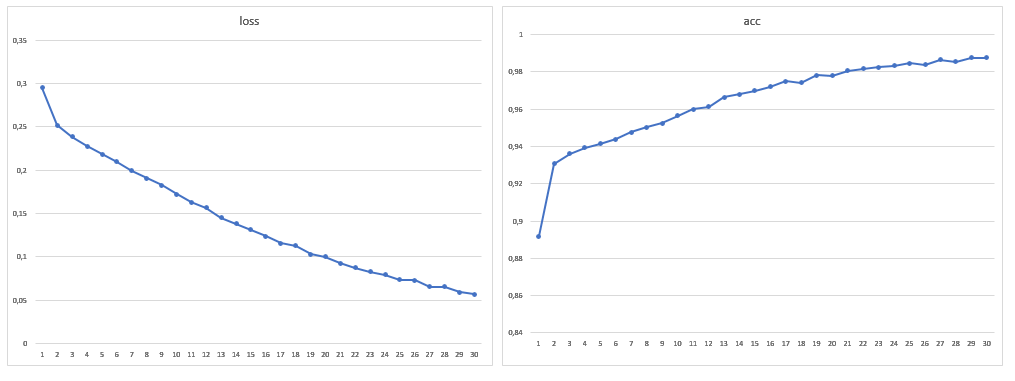
ونتيجة لذلك ، كان حجم عينة التدريب 1881 صورة ، كما قمت بزيادة عدد العصور إلى 30:
بعد تدريب النموذج على حجم جديد من البيانات ، لم يعد يتم الكشف عن مشاكل التقسيم الخاطئ للأسقف والمياه. لم يكن من الممكن التخلص من الأخطاء في الظل على الإطلاق ، لكنها أصبحت أقل في العين ، وكذلك الأخطاء في المروج. وتجدر الإشارة إلى أن الغالبية العظمى من الأخطاء بشكل عام هي أن الشبكة ترى الأشجار حيث لا توجد ، وليس العكس. يمكن تحسين الدقة المحققة باستخدام صور الأقمار الصناعية مع عدد كبير من القنوات وتعديل بنية الشبكة لمهمة معينة.

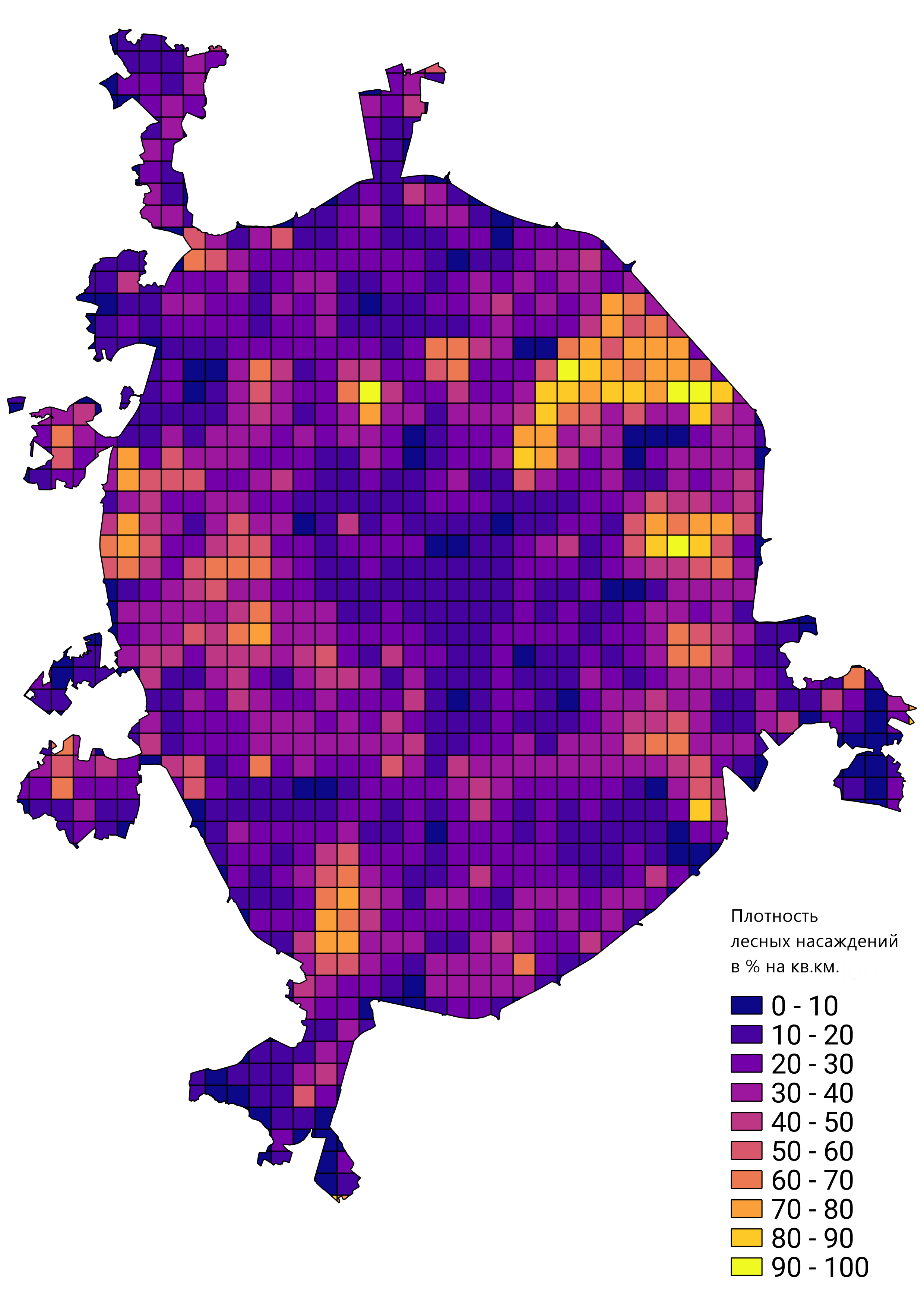
بشكل عام ، كنت راضيًا عن نتيجة العمل المنجز ، وتم تطبيق النموذج الأولي للشبكة المدربة لحل المشكلات الحقيقية. على سبيل المثال ، حساب كثافة حوامل الغابات في موسكو: