في فيلم Mission Impossible 3 ، تم عرض عملية إنشاء أقنعة التجسس الشهيرة ، والتي بفضلها لا يمكن تمييز بعض الشخصيات عن الآخرين. وفقًا للمؤامرة ، كان مطلوبًا في البداية تصوير الشخص الذي أراد البطل أن يتحول إليه من عدة زوايا. في عام 2018 ، قد لا تتم طباعة نموذج وجه ثلاثي الأبعاد بسيط ، ولكن على الأقل تم إنشاؤه في شكل رقمي - واستنادًا إلى صورة واحدة فقط. وصف باحث في VisionLabs بالتفصيل العملية في حدث Yandex "
العالم من خلال عيون الروبوتات " من سلسلة البيانات والعلوم ، مع تفاصيل عن طرق وصيغ محددة.
- مساء الخير. اسمي نيكولاي ، أعمل لدى VisionLabs ، شركة رؤية الكمبيوتر. ملفنا الشخصي الرئيسي هو التعرف على الوجوه ، ولكن لدينا أيضًا تقنيات قابلة للتطبيق في الواقع المعزز والظاهري. على وجه الخصوص ، لدينا تقنية لبناء وجه ثلاثي الأبعاد من صورة واحدة ، واليوم سأتحدث عنه.

لنبدأ بقصة حول ما هو عليه. على الشريحة ، ترى الصورة الأصلية لجاك ما ونموذج ثلاثي الأبعاد مبني من هذه الصورة في شكلين: مع وبدون بنية ، مجرد هندسة. هذه هي المهمة التي نقوم بحلها.

نريد أيضًا أن نكون قادرين على تحريك هذا النموذج ، وتغيير اتجاه نظرتنا ، وتعبير الوجه ، وإضافة تعابير الوجه ، وما إلى ذلك.
التطبيق في مناطق مختلفة. الأكثر وضوحا هي الألعاب ، بما في ذلك VR. يمكنك أيضًا القيام بغرف تركيب افتراضية - جرب النظارات واللحية وتسريحات الشعر. يمكنك إجراء الطباعة ثلاثية الأبعاد ، لأن بعض الأشخاص مهتمون بالإكسسوارات المخصصة لوجوههم. ويمكنك إنشاء وجوه للروبوتات: سواء من خلال الطباعة أو العرض على شاشة ما على الروبوت.

سأبدأ بإخبارك بكيفية إنشاء الوجوه ثلاثية الأبعاد بشكل عام ، ثم سننتقل إلى مهمة إعادة البناء ثلاثية الأبعاد كمهمة جيل معكوس. بعد ذلك ، سنركز على الرسوم المتحركة وننتقل إلى التحديات التي تنشأ في هذا المجال.

ما هي مهمة توليد الوجوه؟ نود الحصول على طريقة ما لتوليد وجوه ثلاثية الأبعاد تختلف في الشكل والتعبير. هنا صفين مع أمثلة. يعرض الصف الأول وجوهًا بأشكال مختلفة ، تنتمي كما لو كانت لأشخاص مختلفين. وأسفل نفس الوجه بتعبير مختلف.

إحدى الطرق لحل مشكلة التوليد هي النماذج القابلة للتشوه. يمثل الوجه الموجود في أقصى اليسار على الشريحة نوعًا من النموذج المتوسط الذي يمكننا تطبيق التشوهات عليه من خلال ضبط أشرطة التمرير. فيما يلي ثلاثة منزلقات. في الصف العلوي توجد وجوه في اتجاه زيادة كثافة شريط التمرير ، في الصف السفلي - في اتجاه التناقص. وبالتالي ، سيكون لدينا العديد من المعلمات القابلة للتخصيص. من خلال تثبيتها ، يمكنك إعطاء الناس أشكالًا مختلفة.

مثال على نموذج قابل للتشويه هو نموذج Face Basel الشهير ، الذي بني من مسح الوجه. لبناء نموذج قابل للتشوه ، تحتاج أولاً إلى اصطحاب عدد قليل من الأشخاص ، وإحضارهم إلى مختبر خاص وتصوير وجوههم بمعدات خاصة ، وترجمتها إلى 3D. ثم ، بناءً على ذلك ، يمكنك إنشاء وجوه جديدة.

كيف يتم ترتيبها رياضيا؟ يمكننا تخيل نموذج ثلاثي الأبعاد للوجه كمتجه في الفضاء ثلاثي الأبعاد. هنا n هو عدد القمم في النموذج ، كل قمة تتوافق مع ثلاثة إحداثيات ثلاثية الأبعاد ، وبالتالي نحصل على إحداثيات 3n.

إذا كان لدينا مجموعة من عمليات المسح ، فسيتم تمثيل كل مسح بواسطة هذا الناقل ، ولدينا مجموعة من هذه المتجهات.
علاوة على ذلك ، يمكننا بناء وجوه جديدة كمجموعات خطية من المتجهات من قاعدة بياناتنا. في الوقت نفسه ، نود أن تكون المعاملات ذات مغزى. من الواضح أنها لا يمكن أن تكون تعسفية تمامًا ، وسأوضح قريبًا السبب. يمكن تعيين أحد القيود بحيث تقع جميع المعاملات في النطاق من 0 إلى 1. يجب القيام بذلك ، لأنه إذا كانت المعاملات عشوائية تمامًا ، فستظهر الوجوه غير قابلة للتصديق.

هنا أود أن أعطي المعلمات بعض المعنى الاحتمالي. أي أننا نريد أن ننظر إلى مجموعة من المعلمات ونفهم ما إذا كان من المحتمل أن يتحول الشخص أم لا. من خلال هذا ، نريد أن تتوافق التشوهات المنخفضة مع الوجوه المشوهة.

إليك كيفية القيام بذلك. يمكننا تطبيق طريقة المكون الرئيسي على مجموعة من عمليات المسح. عند الإخراج ، نحصل على متوسط الوجه S0 ، ونحصل على المصفوفة V ، ومجموعة من المكونات الرئيسية ، ونحصل أيضًا على اختلافات في البيانات على طول المكونات الرئيسية. ثم يمكننا إلقاء نظرة جديدة على جيل الوجوه ، سنقوم بتمثيل الوجوه كوجه متوسط ، بالإضافة إلى مصفوفة المكونات الرئيسية ، مضروبة في متجه المعلمات.
قيمة المعلمات هي كثافة أشرطة التمرير التي تحدثت عنها في إحدى الشرائح السابقة. ويمكننا أيضًا تعيين بعض القيمة الاحتمالية لمتجه المعلمات. على وجه الخصوص ، يمكننا أن نتفق على أن هذا الناقل يكون غاوسيًا.

وبالتالي ، نحصل على طريقة تسمح لك بإنشاء وجوه ثلاثية الأبعاد ، ويتم التحكم في هذا الجيل من خلال المعلمات التالية. كما في الشريحة السابقة ، لدينا مجموعتان من المعلمات ، متجهان α id و α exp ، وهما نفس الشيء في الشريحة السابقة ، ولكن α id مسؤول عن شكل الوجه ، وستكون α exp مسؤولة عن العاطفة.
يظهر أيضًا ناقل T جديد - ناقل نسيج. له نفس أبعاد متجه الشكل ، ولكل قمة في هذا المتجه ثلاث قيم RGB. وبالمثل ، يتم إنشاء متجه نسيج باستخدام متجه المعلمة β. هنا لم يتم إضفاء الطابع الرسمي على المعلمات التي ستكون مسؤولة عن إضاءة الوجه وموقفه ، ولكنها موجودة أيضًا.

فيما يلي أمثلة على الوجوه التي يمكن إنشاؤها باستخدام نموذج مشوه. يرجى ملاحظة أنها تختلف في الشكل ولون البشرة ويتم رسمها أيضًا في ظروف الإضاءة المختلفة.
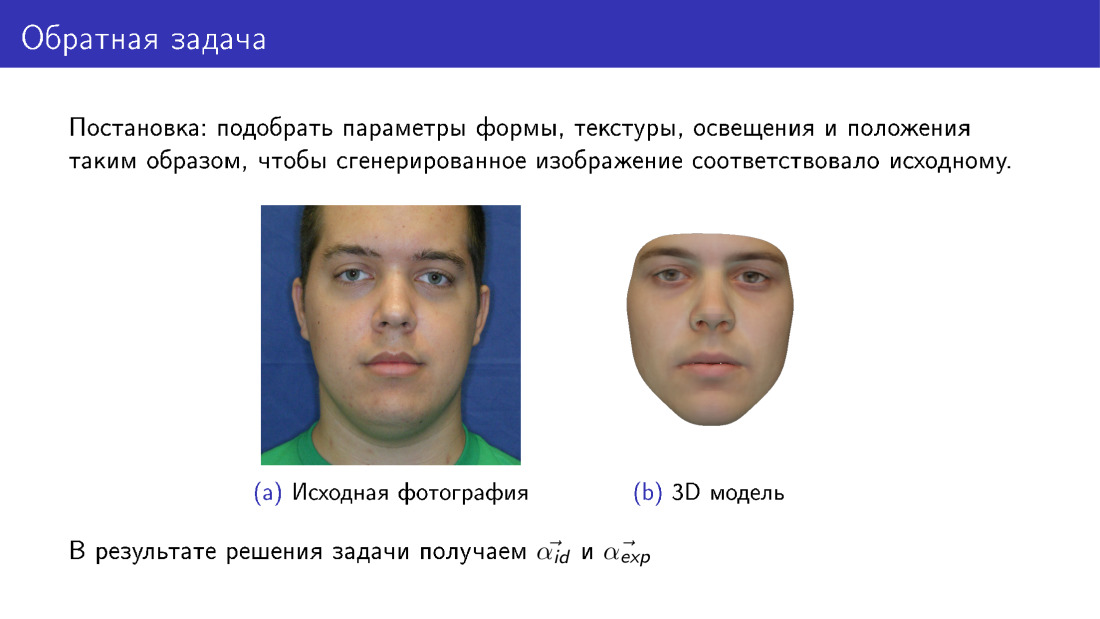
الآن يمكننا الانتقال إلى إعادة الإعمار ثلاثية الأبعاد. وهذا ما يسمى بالمشكلة العكسية ، لأننا نريد تحديد هذه المعلمات للنموذج القابل للتشوه بحيث يكون الوجه الذي نرسم منه مشابهًا قدر الإمكان للنسخة الأصلية. تختلف هذه الشريحة عن الشريحة الأولى هنا ، على اليمين ، الوجه اصطناعي بالكامل. إذا تم التقاط نسيجنا من الشريحة الأولى من صورة فوتوغرافية ، فعندئذٍ تم أخذ النسيج من نموذج قابل للتشوه.
في الخرج ، سيكون لدينا جميع المعلمات ، على الشريحة α معرف و α exp معروضة ، وسيكون لدينا أيضًا إضاءة ، معلمات نسيج ، إلخ.

قلنا إننا نريد التأكد من أن النموذج الذي تم إنشاؤه يبدو كصورة. يتم تحديد هذا التشابه باستخدام وظيفة الطاقة. هنا نأخذ فقط اختلاف بكسل لكل بكسل للصور في تلك البكسلات حيث نعتقد أن الوجه مرئي. على سبيل المثال ، إذا تم تدوير الوجه ، فسيحدث تداخل. على سبيل المثال ، سيتم تغطية جزء من عظم الوجنة من الأنف. ويجب أن تعرض مصفوفة الرؤية M مثل هذا التداخل.
في جوهرها ، إعادة البناء ثلاثية الأبعاد لتقليل وظيفة الطاقة هذه. ولكن من أجل حل مشكلة التقليل هذه ، سيكون من الجيد الحصول على التهيئة والتنظيم. التنظيم ضروري لسبب واضح ، حيث قلنا أننا إذا لم ننظم المعلمات ونجعلها تعسفية تمامًا ، فيمكننا الحصول على وجوه مشوهة. هناك حاجة إلى التهيئة لأن المهمة ككل معقدة ، ولها حد أدنى محلي ، ولا تريد التعامل معها.

كيف يمكن أن تتم التهيئة؟ لهذا ، يمكنك استخدام 68 نقطة رئيسية للوجه. منذ 2013-2014 ، ظهرت الكثير من الخوارزميات التي تسمح باكتشاف 68 نقطة بدقة جيدة إلى حد ما ، وهي الآن تقترب من تشبع دقتها. لذلك ، لدينا طريقة لاكتشاف 68 نقطة من الوجه بشكل موثوق.
يمكننا إضافة مصطلح جديد إلى وظيفة طاقتنا ، والتي ستقول أننا نريد أن تتطابق إسقاطات 68 نقطة من النموذج مع النقاط الرئيسية للوجه. نحدد هذه النقاط على النموذج ، ثم نقوم بطريقة ما بتشويه النموذج ، ولفه ، وإسقاط النقاط ، والتأكد من تطابق مواضع النقاط. في الصورة اليسرى توجد نقاط بلونين ، البنفسجي والأصفر. تم الكشف عن بعض النقاط بواسطة الخوارزمية ، بينما تم عرض نقاط أخرى من النموذج. وضع علامات على النموذج على اليمين ، ولكن بالنسبة للنقاط على طول حافة الوجه ، لم يتم وضع علامة على نقطة واحدة ، ولكن خط كامل. يتم ذلك لأنه عندما يتم تدوير الوجه ، يجب أن تتغير علامات هذه النقاط ، ويتم تحديد النقطة بخط.

هذا هو المصطلح الذي تحدثت عنه ، إنه الاختلاف المنسق بين متجهين الذي يصف النقاط الرئيسية للوجه والنقاط الرئيسية المتوقعة من النموذج.

دعونا نعود إلى التنظيم وننظر في المشكلة برمتها من منظور الاستنتاج البايزي. تتناسب احتمالية كون المتجه α لشيء معين في صورة معروفة متناسبًا مع ناتج احتمالية مراقبة الصورة لـ α معين ، مضروبًا في الاحتمال α. إذا أخذنا اللوغاريتم السلبي لهذا التعبير ، والذي سيتعين علينا تقليله ، فسوف نرى أن المصطلح المسؤول عن التنظيم سيكون له شكل ملموس هنا. على وجه الخصوص ، هذا هو المصطلح الثاني. بالإشارة إلى أننا قد افترضنا سابقًا أن المتجه α هو Gaussian ، نرى أن المصطلح المسؤول عن التنظيم هو مجموع مربعات المعلمات التي تم تقليلها إلى اختلافات على طول المكونات الرئيسية.

لذا ، يمكننا كتابة وظيفة الطاقة الكاملة ، والتي تحتوي على ثلاثة مصطلحات. المصطلح الأول مسؤول عن النسيج ، عن فرق البكسل بين الصورة المولدة والصورة المستهدفة. الفصل الثاني مسؤول عن النقاط الرئيسية ، والثالث مسؤول عن التنظيم.
لا يتم تحسين معاملات المصطلحات في عملية التصغير ، يتم تعيينها ببساطة.
هنا ، يتم تمثيل دالة الطاقة كدالة لجميع المعلمات. α id - معلمات شكل الوجه ، معلمات التعبير α exp ، معلمات β - النسيج ، p - معلمات أخرى تحدثنا عنها ولكن لم يتم إضفاء الطابع الرسمي عليها ، وهي معلمات الموضع والإضاءة.
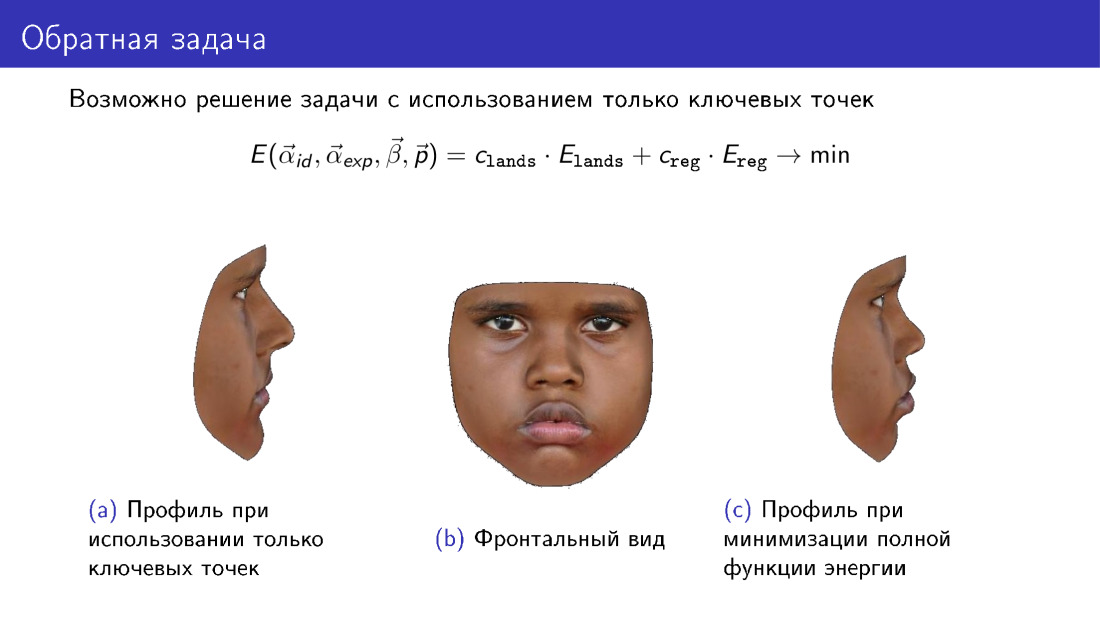
دعونا نتناول هذه الملاحظة. يمكن تبسيط وظيفة الطاقة هذه. من خلاله ، يمكنك التخلص من المصطلح المسؤول عن الملمس ، واستخدام المعلومات المرسلة بـ 68 نقطة فقط. وهذا سيسمح لك ببناء نوع من النماذج ثلاثية الأبعاد. ومع ذلك ، انتبه إلى ملف تعريف النموذج. على اليسار يوجد نموذج مبني فقط عند النقاط الرئيسية. على اليمين يوجد نموذج يستخدم الملمس عند البناء. لاحظ أن الملف الشخصي على اليمين أكثر اتساقًا مع الصورة المركزية ، التي تمثل المنظر الأمامي للوجه.

الرسوم المتحركة مع الخوارزمية الحالية لبناء نموذج ثلاثي الأبعاد للوجه تعمل بكل بساطة. تذكر أنه عند إنشاء نموذج ثلاثي الأبعاد ، نحصل على متجهين للمعلمات ، أحدهما مسؤول عن الشكل والآخر للتعبير. هذه المتغيرات من المعلمات للمستخدم والصورة الرمزية سيكون لها دائمًا الخاصة بها. لدى المستخدم متجه واحد لمعلمات النموذج ، والصورة الرمزية لها واحدة مختلفة. ومع ذلك ، يمكننا أن نجعل المتجهات المسؤولة عن التعبير تصبح نفسها بالنسبة لهم. سنأخذ المعلمات المسؤولة عن تعبير الوجه للمستخدم ، ونستبدلها ببساطة في نموذج الصورة الرمزية. وبالتالي سننقل تعبير الوجه للمستخدم إلى الصورة الرمزية.
لنتحدث عن تحديين في هذا المجال: سرعة العمل والنموذج المحدود القابل للتشويه.

السرعة هي حقا مشكلة يعد تقليل وظيفة الطاقة الإجمالية مهمة مكثفة للغاية من الناحية الحسابية. على وجه الخصوص ، يمكن أن يستغرق الأمر من 20 إلى 40 ، بمتوسط 30 ثانية. هذا طويل بما فيه الكفاية. إذا قمنا ببناء نموذج ثلاثي الأبعاد عند النقاط الرئيسية فقط ، فسوف يتحول بشكل أسرع بكثير ، ولكن الجودة ستعاني من ذلك.

كيف تتعامل مع هذه المشكلة؟ يمكنك استخدام المزيد من الموارد ، يحل بعض الناس هذه المشكلة على GPU. يمكن استخدام النقاط الرئيسية فقط ، ولكن الجودة ستعاني. ويمكنك استخدام طرق التعلم الآلي.

دعونا نرى في الترتيب. إليك عمل عام 2016 ، حيث يتم نقل تعبيرات وجه المستخدم إلى فيديو معين ، يمكنك التحكم في الفيديو باستخدام وجهك. هنا ، يتم تنفيذ نموذج 3D في الوقت الحقيقي باستخدام GPU.

فيما يلي الأساليب التي تستخدم التعلم الآلي. الفكرة هي أنه يمكننا أولاً أخذ قاعدة كبيرة من الوجوه ، لكل وجه باستخدام خوارزمية طويلة ولكنها دقيقة لبناء نماذج ثلاثية الأبعاد ، وتقديم كل نموذج كمجموعة من المعلمات ، ثم تدريب الشبكة للتنبؤ بهذه المعلمات. على وجه الخصوص ، في هذا العمل لعام 2016 ، يتم استخدام ResNet ، الذي يأخذ صورة إلى الإدخال ، ويعطي معلمات النموذج للإخراج.

يمكن تمثيل نموذج ثلاثي الأبعاد بطريقة أخرى. في هذا العمل لعام 2017 ، لا يتم تقديم النموذج ثلاثي الأبعاد كمجموعة من المعلمات ، ولكن كمجموعة من voxels. تتوقع الشبكة الثعالب ، وتحول الصورة إلى تمثيل ثلاثي الأبعاد. تجدر الإشارة إلى أن خيارات التدريب على الشبكة ممكنة والتي لا تتطلب نماذج ثلاثية الأبعاد على الإطلاق.

يعمل هذا على النحو التالي. هنا الجزء الأكثر أهمية هو الطبقة ، والتي يمكن أن تأخذ معلمات النموذج القابل للتشوه كمدخل وتقديم الصورة. لديها خاصية رائعة بحيث من خلالها يمكنك القيام بالانتشار الخلفي للخطأ. تقبل الشبكة صورة كمدخل ، وتتنبأ بالمعلمات ، وتغذي هذه المعلمات إلى طبقة تعرض الصورة ، وتقارن هذه الصورة بالإدخال ، وتتلقى خطأ ، وتعيد نشر الخطأ وتستمر في التعلم. وبالتالي ، تتعلم الشبكة التنبؤ بمعلمات النموذج ثلاثي الأبعاد ، مع وجود صور فقط كبيانات تدريب. وهو مثير جدا للاهتمام.

تحدثنا كثيرًا عن الدقة - على وجه الخصوص ، أنها تعاني إذا تخلصنا من بعض المصطلحات من وظيفة الطاقة. لنقم بإضفاء الطابع الرسمي على ما يعنيه هذا ، وكيف يمكنك تقييم دقة إعادة بناء الوجه ثلاثي الأبعاد. للقيام بذلك ، نحتاج إلى قاعدة من عمليات مسح الحقيقة التي تم الحصول عليها باستخدام معدات خاصة ، باستخدام طرق فيما يتعلق ببعض ضمانات الدقة. إذا كانت هذه القاعدة موجودة ، فيمكننا مقارنة نماذجنا المعاد بناؤها بالحقيقة الأساسية. يتم ذلك ببساطة: نحن نحسب متوسط المسافة من رؤوس نموذجنا ، التي بنيناها ، إلى القمم في الحقيقة الأرضية ، ونطبع حجم المسح. يجب القيام بذلك لأن الوجوه مختلفة ، بعضها أكبر ، وبعضها أصغر ، والخطأ على الوجه الصغير سيكون أصغر ، ببساطة لأن الوجه نفسه أصغر. لذلك ، هناك حاجة إلى التطبيع.

أود التحدث عن عملنا ، سيكون في ورش العمل ، هناك ECCV. نحن نفعل أشياء مماثلة ، نعلم MobileNet للتنبؤ بمعلمات نموذج قابل للتشوه. كبيانات تدريب ، نستخدم نماذج ثلاثية الأبعاد مصممة للصور الفوتوغرافية من مجموعة بيانات 300 وات. تقييم الدقة بناءً على عمليات المسح BU4DFE.
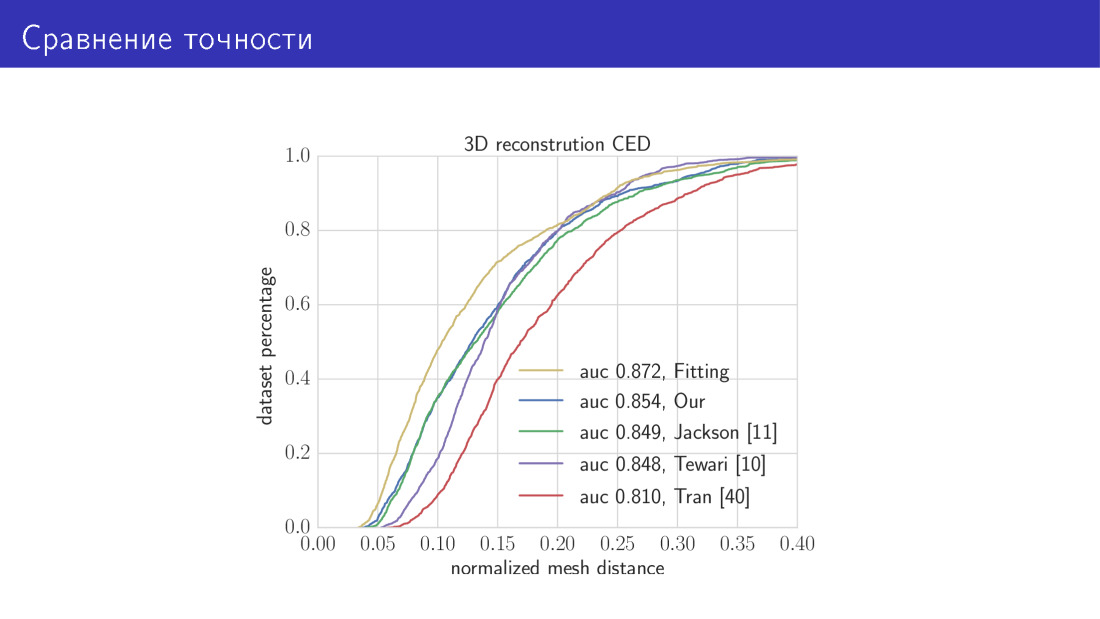
ها هي النتيجة. قارنا الخوارزميتين لدينا مع الحالة الفنية. المنحنى الأصفر في هذا الرسم البياني هو خوارزمية تستغرق 30 ثانية وتتكون من تقليل وظيفة الطاقة الإجمالية. هنا على طول المحور X هو الخطأ الذي تحدثنا عنه للتو ، وهو متوسط المسافة بين القمم. المحور ص هو جزء من الصور يكون فيه هذا الخطأ أصغر من ذلك على المحور س. في هذا الرسم البياني ، كلما ارتفع المنحنى ، كان ذلك أفضل. المنحنى التالي هو شبكتنا القائمة على MobileNet. بعد ذلك ، الأعمال الثلاثة التي تحدثنا عنها. شبكة التنبؤ المعلمة وشبكة التنبؤ voxel.
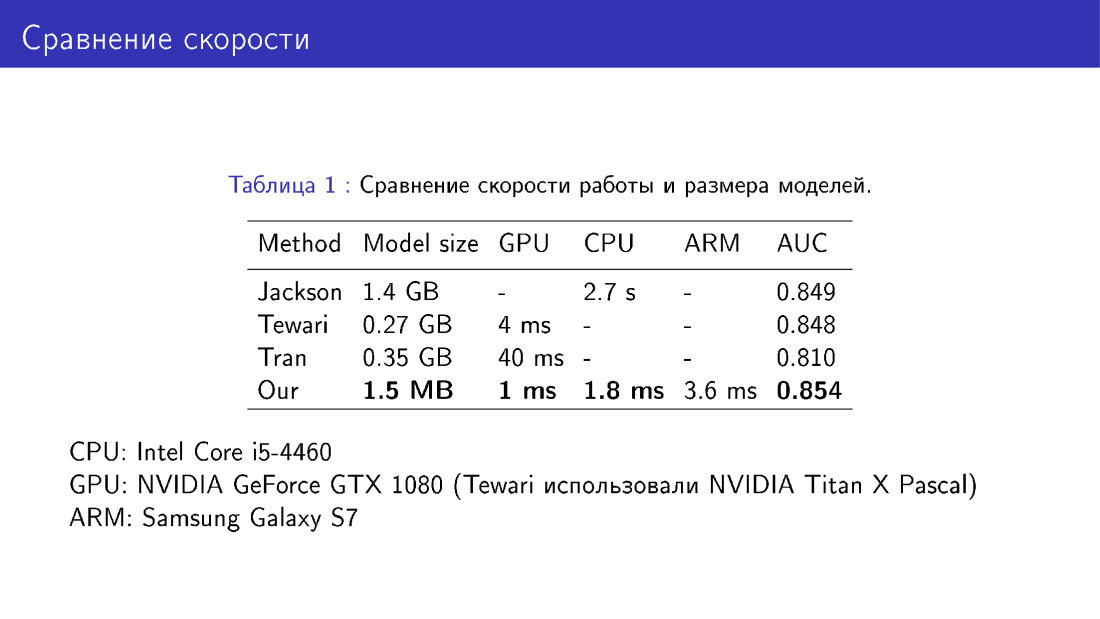
قمنا أيضًا بمقارنة شبكتنا مع أقرانهم من حيث حجم النموذج وسرعته. هذا فوز لأننا نستخدم MobileNet ، وهو أمر سهل للغاية.
التحدي الثاني هو محدودية النموذج المشوه.

انتبه إلى الوجه الأيسر ، وانظر إلى أجنحة الأنف. هناك ظلال على أجنحة الأنف. لا تتوافق حدود الظلال مع حدود الأنف في الصورة ، وبالتالي يتم الحصول على عيب. قد يكون السبب في ذلك أن النموذج القابل للتشوه ، من حيث المبدأ ، غير قادر على بناء أنف الشكل المطلوب ، لأنه تم الحصول على هذا النموذج القابل للتشوه من عمليات مسح لـ 200 وجه فقط. نود أن يكون الأنف صحيحًا ، كما في الصورة الصحيحة. وبالتالي ، فإننا بحاجة إلى تجاوز إطار النموذج القابل للتشوه بطريقة أو بأخرى.

يمكن القيام بذلك باستخدام تشوه غير معلمي للشبكة. فيما يلي ثلاث مهام نود حلها: تعديل الجزء المحلي من الوجه ، على سبيل المثال ، الأنف ، ثم تضمينه في النموذج الأصلي للوجه ، وحتى يبقى كل شيء آخر دون تغيير.

يمكن القيام بذلك على النحو التالي. دعونا نعود إلى تسمية الشبكة كمتجه في الفضاء ثلاثي الأبعاد ونلقي نظرة على عامل المتوسط. هذا هو عامل في S مع رأس يستبدل كل قمة بمتوسط جيرانها. جيران الذروة هي تلك التي ترتبط بها عن طريق الحافة.
سنحدد وظيفة طاقة معينة تصف موضع قمة الرأس بالنسبة لجيرانها. نريد أن يبقى موقف القمة بالنسبة لجيرانها دون تغيير ، أو على الأقل لا يتغير كثيرًا. ولكن في نفس الوقت ، سنقوم بتعديل S. بطريقة ما تسمى وظيفة الطاقة هذه داخلية ، لأنه سيكون هناك أيضًا مصطلح خارجي ، والذي سيقول أنه ، على سبيل المثال ، يجب أن يأخذ الأنف شكلًا معينًا.
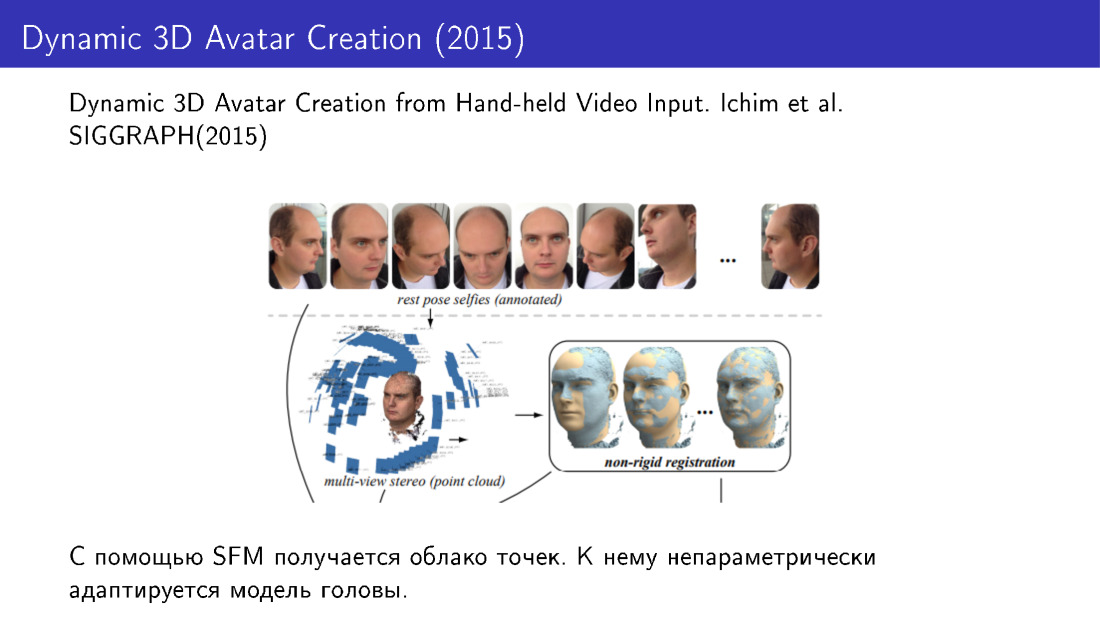
تم استخدام هذه التقنيات ، على سبيل المثال ، في عمل عام 2015. لقد واجهوا 3D إعادة الإعمار من عدة صور. التقطنا عدة صور من الهاتف ، وتلقينا سحابة نقطية ، ثم قمنا بتكييف نموذج الوجه مع هذه السحابة باستخدام تعديلات غير معلمية.
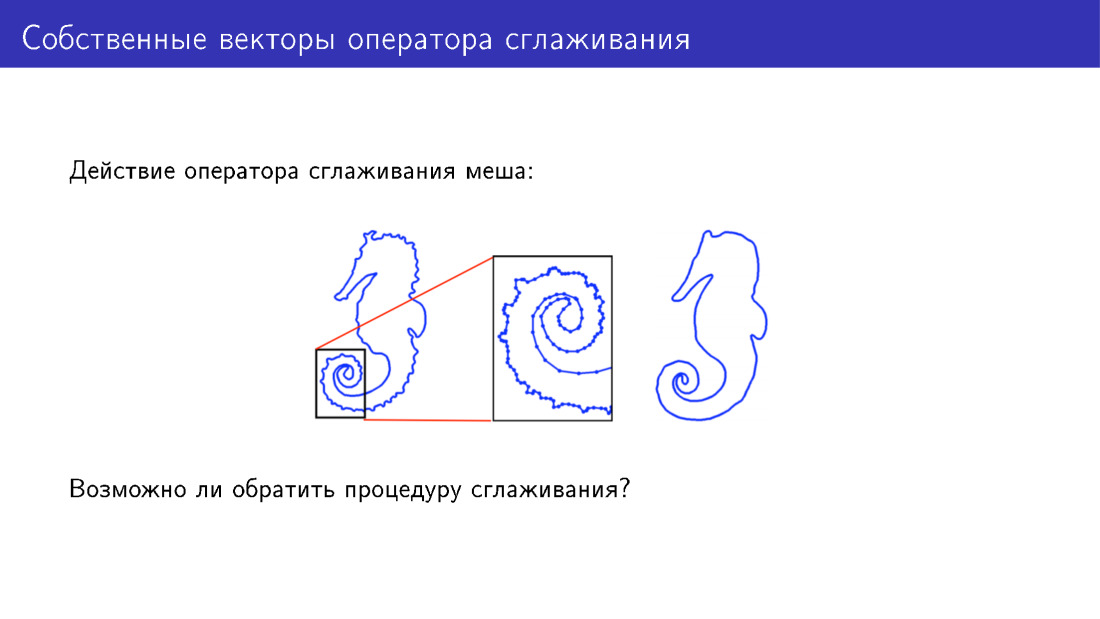
يمكنك تجاوز النموذج المشوه بطريقة أخرى. دعونا نتحدث عن عمل عامل التنعيم. هنا ، من أجل البساطة ، يتم تقديم شبكة ثنائية الأبعاد تم تطبيق هذا المشغل عليها. هناك العديد من التفاصيل حول النموذج على اليسار ؛ على النموذج على اليمين ، تم تلطيف هذه التفاصيل. ولكن هل يمكننا فعل شيء لإضافة التفاصيل بدلاً من إزالتها؟

. .
? -: - . . , 2016 . , .