كجزء من دعم المنتج ، نحن نخدم باستمرار طلبات المستخدمين. هذه عملية قياسية. ومثل أي عملية ، تحتاج إلى تقييم وتحسين نقدي بشكل منتظم.
نحن نعرف بعض المشكلات المنهجية التي يمكن حلها ، وإذا أمكن ، بدون جذب موارد إضافية:
- أخطاء في إرسال التطبيقات: نحصل على شيء "غريب" ، وأحيانًا تحصل فرق أخرى على شيء "خاصتنا".
- من الصعب تقييم "تعقيد" التطبيق. إذا كان التطبيق معقدًا ، يمكن نقله إلى محلل قوي ، ومع واحد بسيط ، سيتعامل المبتدئ.
سيؤثر حل أي من هذه المشكلات بشكل إيجابي على سرعة معالجة التطبيقات.
يبدو تطبيق التعلم الآلي ، كما يتم تطبيقه على تحليل محتوى التطبيق ، فرصة حقيقية لتحسين عملية الإرسال.
في حالتنا ، يمكن صياغة المشكلة من خلال مشاكل التصنيف التالية:
- تأكد من تعيين الطلب بشكل صحيح لـ:
- وحدة التكوين (واحدة من 5 داخل التطبيق أو "الآخرين")
- فئات الخدمة (الحادث ، طلب المعلومات ، طلب الخدمة)
- تقدير الوقت المتوقع لإغلاق الطلب (كمؤشر عالي المستوى "للتعقيد").
ماذا وكيف سنعمل
لإنشاء الخوارزمية ، سوف نستخدم "المجموعة القياسية": Python مع مكتبة scikit-learning.
لتطبيق حقيقي ، سيتم تنفيذ سيناريوهين:
تدريب:
- الحصول على بيانات "التدريب" من متعقب التطبيق
- تشغيل خوارزمية لتدريب نموذج ، حفظ نموذج
إستعمال:
- تلقي البيانات من تعقب التطبيق للتصنيف
- تحميل النموذج ، تصنيف التطبيق ، حفظ النتائج
- تحديث التطبيقات في تعقب على أساس التصنيف
يمكن تنفيذ كل ما يتعلق بخط الأنابيب (التفاعل مع المتتبع) على أي شيء. في هذه الحالة ، تم كتابة نصوص powerhell ، على الرغم من أنه كان من الممكن الاستمرار في الثعبان.
ستتلقى خوارزمية التعلم الآلي بيانات التصنيف / التدريب في شكل ملف .csv. سيتم أيضًا إخراج النتائج التي تمت معالجتها إلى ملف .csv.
بيانات الإدخال
من أجل جعل الخوارزمية مستقلة قدر الإمكان عن رأي فرق الخدمة ، سنأخذ في الاعتبار فقط البيانات الواردة من منشئ التطبيق كمعلمات إدخال للنموذج:
- الوصف المختصر / العنوان (النص)
- وصف تفصيلي للمشكلة إن وجد (نص). هذه هي الرسالة الأولى في تدفق اتصالات التطبيق.
- اسم العميل (الموظف ، الفئة)
- أسماء الموظفين الآخرين المدرجين في قائمة المراقبة عند الطلب (قائمة الموظفين)
- وقت تقديم الطلب (التاريخ / الوقت).
مجموعة بيانات التدريب
لتدريب الخوارزميات ، تم استخدام البيانات المتعلقة بالمكالمات المغلقة على مدى السنوات الثلاث الماضية - ~ 3،500 تسجيل.
بالإضافة إلى ذلك ، من أجل تعليم المصنف التعرف على وحدات التكوين "الأخرى" ، تمت إضافة التطبيقات المغلقة التي تمت معالجتها من قبل الأقسام الأخرى لوحدات التكوين الأخرى إلى مجموعة التدريب. إجمالي السجلات الإضافية - حوالي 17000.
لجميع هذه الطلبات الإضافية ، سيتم تعيين وحدة التكوين على "أخرى"
المعالجة
نص
المعالجة المسبقة للنص بسيطة للغاية:
- نترجم كل شيء إلى أحرف صغيرة
- اترك فقط الأرقام والحروف - استبدل الباقي بمسافات
قائمة الإخطار (قائمة المراقبة)
القائمة متاحة للتحليل في شكل سلسلة يتم فيها عرض الأسماء في شكل اسم العائلة ، الاسم الأول ، ويفصل بينها بفاصلة منقوطة. للتحليل ، سنقوم بتحويله إلى قائمة سلاسل.
من خلال دمج القوائم ، نحصل على مجموعة من الأسماء الفريدة استنادًا إلى جميع تطبيقات مجموعة التدريب. ستشكل هذه القائمة العامة متجهًا للأسماء.
مدة معالجة الطلب
لأغراضنا (إدارة الأولويات ، تخطيط الإصدار) ، يكفي أن نعزو التطبيق إلى فئة معينة حسب مدة الخدمة. كما يسمح لك بنقل المهمة من الانحدار إلى التصنيف مع عدد قليل من الفئات.
نص
- اجمع بين "العنوان" و "وصف المشكلة".
- قم بالمرور إلى TfidfVectoriser لتكوين ناقل كلمة
اسم الطالب
نظرًا لأنه من المتوقع أن يكون الشخص الذي أنشأ التطبيق سمة مهمة لمزيد من التصنيف - سنقوم بترجمته إلى واحد من الترميز بشكل فردي باستخدام DictionaryVectorisor
أسماء الأشخاص المدرجين في قائمة الإشعارات
سيتم تحويل قائمة الأشخاص المدرجة في تطبيقات قائمة المراقبة إلى متجه على أساس جميع الأسماء التي تم إعدادها سابقًا: إذا كان الشخص في القائمة ، فسيتم تعيين المكون المقابل على 1 ، وإلا - إلى 0. يمكن أن يحتوي تطبيق واحد على عدة أشخاص في قائمة المراقبة - على التوالي ، عدة مكونات سيكون لها قيمة واحدة.
تاريخ الإنشاء
سيتم تقديم تاريخ الإنشاء كمجموعة من السمات العددية - السنة والشهر ويوم الشهر ويوم الأسبوع.
يتم ذلك على افتراض أن:
- تختلف سرعة معالجة التطبيق بمرور الوقت
- سرعة المعالجة لها عامل موسمي
- يمكن أن يساعد يوم الأسبوع (خاصة تطبيقات عطلة نهاية الأسبوع) في تحديد وحدة التكوين وفئة الخدمة
نموذج التدريب
خوارزمية التصنيف
بالنسبة لجميع مهام التصنيف الثلاث ، تم استخدام الانحدار اللوجستي. يدعم التصنيف متعدد الفئات (في نموذج One-vs-All) ، يتعلم بسرعة كبيرة.
لتدريب النماذج التي تحدد فئة الخدمة ومدة معالجة التطبيقات ، سنستخدم فقط التطبيقات التي من الواضح أنها تنتمي إلى وحدات التكوين الخاصة بنا.
نتائج التعلم
تحديد وحدات التكوين
يوضح النموذج مؤشرات عالية من الاكتمال والدقة عند تعيين التطبيقات لوحدات التكوين. أيضا ، يحدد النموذج بشكل جيد الأحداث عندما تشير التطبيقات إلى وحدات التكوين الأجنبية.
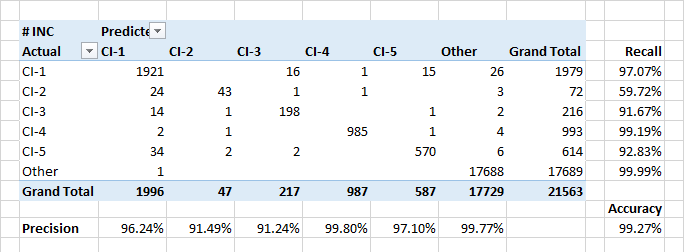
يُعزى الاستيفاء المنخفض نسبيًا لفئة CI-2 جزئيًا إلى أخطاء التصنيف الحقيقية في البيانات. بالإضافة إلى ذلك ، تقدم CI-2s تطبيقات "فنية" يتم تنفيذها على CIs أخرى. لذلك ، من حيث الوصف والمستخدمين المعنيين ، قد تكون هذه التطبيقات مشابهة لتطبيقات الفئات الأخرى.
أهم سمات تصنيف التطبيقات على أنها CI-؟ كان متوقعًا أسماء عملاء التطبيقات والأشخاص المدرجين في ورقة التنبيه. ولكن كانت هناك بعض الكلمات الرئيسية التي كانت في أول 30 كه في الأهمية. لا يهم تاريخ إنشاء التطبيق.
تعريف فئة التطبيق
تبين أن جودة التصنيف حسب الفئات أقل إلى حد ما.
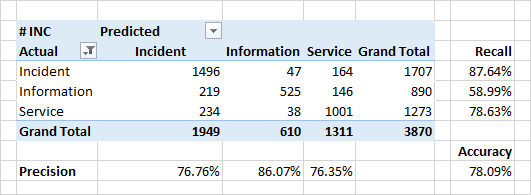
يعد وجود أخطاء حقيقية في بيانات المصدر سببًا خطيرًا للغاية لعدم تطابق الفئات والفئات المتوقعة في بيانات المصدر. لعدد من الأسباب التنظيمية ، قد يكون التصنيف غير صحيح. على سبيل المثال ، بدلاً من "حادث" (عيب في النظام ، سلوك غير متوقع للنظام) ، قد يتم وضع علامة على التطبيق على أنه "معلومات" ("هذه ليست خطأ - هذه ميزة") أو "خدمة" ("نعم ، إنها معطلة ، لكننا فقط أعيد تشغيلها - و كل شيء سيكون على ما يرام ").
تحديد مثل هذه التناقضات هي واحدة من مهام المصنف.
السمات الهامة للتصنيف في حالة الفئات هي كلمات من محتوى التطبيقات. بالنسبة للحوادث ، هذه هي الكلمات "خطأ" ، "إصلاح" ، "متى". هناك أيضًا كلمات تشير إلى بعض وحدات النظام - هذه هي الوحدات التي يعمل بها المستخدمون بشكل مباشر ويلاحظون ظهور أخطاء مباشرة أو غير مباشرة.
من المثير للاهتمام ، بالنسبة للتطبيقات التي تم تعريفها على أنها "خدمة" - تحدد الكلمات الرئيسية أيضًا بعض وحدات النظام. فرصة للتفكير والتحقق منها وإصلاحها في النهاية.
تحديد وقت معالجة التطبيق
كان الأضعف هو توقع مدة معالجة الطلبات.
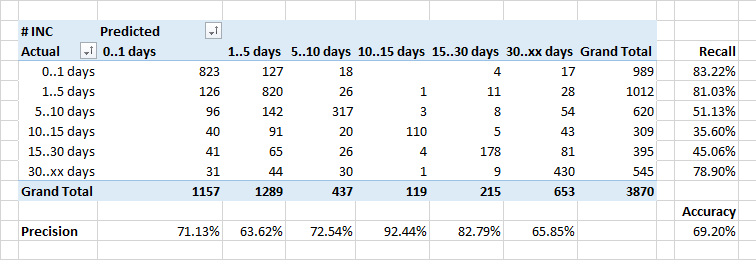
بشكل عام ، يجب أن يبدو اعتماد عدد التطبيقات التي تم إغلاقها لفترة معينة بشكل مثالي مثل معكوس الأس. ولكن مع الأخذ في الاعتبار حقيقة أن بعض الحوادث تتطلب تصحيحات في النظام ، ويتم ذلك كجزء من الإصدارات المنتظمة ، تزداد مدة تنفيذ بعض التطبيقات بشكل مصطنع.
لذلك ، ربما يصنف المصنف بعض التطبيقات "الطويلة" على أنها "أسرع" - فهو لا يعرف توقيت الإصدارات المخططة ، ويعتقد أن التطبيق يحتاج إلى إغلاق أسرع.
هذا أيضًا سبب وجيه للتفكير ...
تطبيق النموذج كفئة
يتم تنفيذ النموذج كفئة تضم جميع فئات التعلم المعرفية القياسية المستخدمة - التحجيم ، والتوجيه ، والمصنف والإعدادات الهامة.
يتم تنفيذ التحضير والتدريب والاستخدام اللاحق للنموذج كطرق صفية ، بناءً على الأشياء المساعدة.
يتيح لك تطبيق الكائن إنشاء إصدارات مشتقة من النموذج بشكل ملائم تستخدم فئات أخرى من المصنفات و / أو توقع قيم السمات الأخرى لمجموعة البيانات الأصلية. كل هذا يتم عن طريق تجاوز الأساليب الافتراضية.
ومع ذلك ، قد تظل جميع إجراءات إعداد البيانات مشتركة لجميع الخيارات.
بالإضافة إلى ذلك ، فإن تنفيذ النموذج في شكل كائن جعل من الممكن بشكل طبيعي حل مشكلة التخزين الوسيط للنموذج المدرّب بين جلسات الاستخدام - من خلال التسلسل / إلغاء التسلسل.
لتسلسل النموذج ، تم استخدام آلية Python القياسية ، المخلل / غير المنتقى.
نظرًا لأنه يسمح لك بتسلسل العديد من الكائنات في نفس الملف ، فإن هذا سيساعد على حفظ استرداد العديد من النماذج المتضمنة في تدفق المعالجة العامة باستمرار.
الخلاصة
النماذج الناتجة ، حتى لو كانت بسيطة نسبيًا ، تعطي نتائج مثيرة للاهتمام للغاية:
- حددت "الإغفالات" المنهجية في التصنيف حسب الفئة
- أصبح من الواضح أجزاء النظام التي ترتبط بالمشكلات (على ما يبدو - ليس بدون سبب)
- من الواضح أن أوقات معالجة الطلبات تعتمد على العوامل الخارجية التي تحتاج إلى تحسين بشكل منفصل.
لا يزال يتعين علينا إعادة بناء العمليات الداخلية بناءً على "التلميحات" الواردة. ولكن حتى هذه التجربة الصغيرة جعلت من الممكن تقييم قوة طرق التعلم الآلي. وأيضًا ، أثار اهتمامًا إضافيًا من الفريق بتحليل العملية الخاصة بهم وتحسينها.