ضع في اعتبارك سيناريو واحد حيث قد يكون نموذج التعلم الآلي الخاص بك عديم القيمة.
هناك قول مأثور:
"لا تقارن التفاح بالبرتقال" . ولكن ماذا لو كنت بحاجة إلى مقارنة مجموعة من التفاح مع البرتقال مع مجموعة أخرى ، ولكن توزيع الفاكهة في المجموعتين مختلف؟ هل يمكنك العمل مع البيانات؟ وكيف ستفعل ذلك؟
في الحالات الحقيقية ، هذا الوضع شائع. عند تطوير نماذج التعلم الآلي ، نواجه موقفًا يعمل فيه نموذجنا بشكل جيد مع مجموعة التدريب ، ولكن جودة النموذج تنخفض بشكل حاد على بيانات الاختبار.
وهذا لا يتعلق بإعادة التدريب. لنفترض أننا بنينا نموذجًا يعطي نتيجة ممتازة في التحقق المتقاطع ، ولكنه يُظهر نتيجة ضعيفة في الاختبار. لذلك في عينة الاختبار هناك معلومات لا نأخذها بعين الاعتبار.
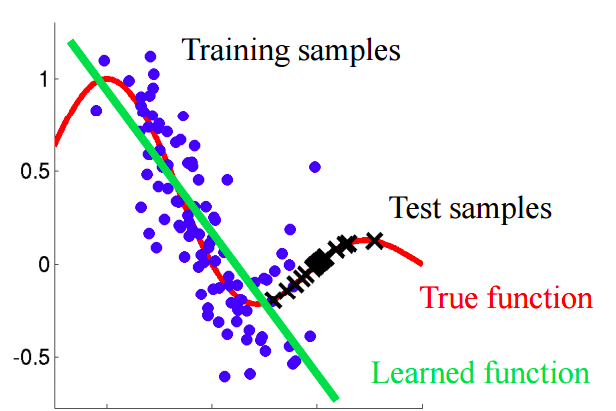
تخيل الموقف الذي نتوقع فيه سلوك العملاء في المتجر. إذا كانت عينات التدريب والاختبار تبدو مثل الصورة أدناه ، فهذه مشكلة واضحة:
في هذا المثال ، يتم تدريب النموذج على البيانات التي تقل فيها قيمة السمة "عمر العميل" عن متوسط قيمة السمة المماثلة في الاختبار. في عملية التعلم ، لم يرَ النموذج أبدًا القيم الأكبر لسمة "العمر". إذا كان العمر ميزة مهمة للنموذج ، فيجب ألا يتوقع المرء نتائج جيدة في عينة الاختبار.في هذا النص ، سنتحدث عن الأساليب "الساذجة" التي تسمح لنا بتحديد هذه الظواهر ومحاولة القضاء عليها.
التحول المتغاير
دعونا نعطي تعريفًا أكثر دقة لهذا المفهوم. يشير
التغاير إلى قيم الخصائص ، ويشير
التحول المتغير إلى حالة يكون فيها توزيع قيم الخصائص في عينات التدريب والاختبار لها خصائص (معلمات) مختلفة.
في مشاكل العالم الحقيقي مع عدد كبير من المتغيرات ، يصعب اكتشاف التحول المتغير. تناقش المقالة طريقة تحديد ، وكذلك محاسبة التحول المتغير في البيانات.
الفكرة الرئيسية
إذا كان هناك تحول في البيانات ، فعند خلط العينات ، يمكننا بناء مصنف يمكنه تحديد ما إذا كان الكائن ينتمي إلى عينة تدريب أو اختبار.دعونا نفهم سبب ذلك. دعونا نعود إلى المثال مع العملاء ، حيث كان العمر علامة "متغيرة" لعينات التدريب والاختبار. إذا أخذنا المصنف (على سبيل المثال ، بناءً على غابة عشوائية) وحاولنا تقسيم العينة المختلطة إلى تدريب واختبار ، فإن العمر سيكون علامة مهمة جدًا لمثل هذا التصنيف.
التنفيذ
دعونا نحاول تطبيق الفكرة الموصوفة على مجموعة بيانات حقيقية. استخدم
مجموعة البيانات من مسابقة Kaggle.
الخطوة 1: إعداد البيانات
أولاً ، سنتبع سلسلة من الخطوات القياسية: التنظيف ، وملء الفراغات ، وإجراء ترميز التسمية للعلامات الفئوية. لم تكن هناك حاجة إلى مجموعة البيانات المعنية ، لذا تخطى وصفها.
import pandas as pd
الخطوة 2: إضافة مؤشر مصدر البيانات
من الضروري إضافة مؤشر مؤشر جديد إلى جزئي مجموعة البيانات - التدريب والاختبار. بالنسبة لعينة التدريب بالقيمة "1" ، للاختبار ، على التوالي ، "0".
الخطوة 3: الجمع بين عينات التعلم والاختبار
تحتاج الآن إلى دمج مجموعتي البيانات. نظرًا لأن مجموعة بيانات التدريب تحتوي على عمود من القيم المستهدفة "الهدف" ، وهو ليس في مجموعة بيانات الاختبار ، يجب حذف هذا العمود.
الخطوة 4: بناء المصنف واختباره
لأغراض التصنيف ، سنستخدم "تصنيف الغابات العشوائية" ، الذي سنقوم بتكوينه للتنبؤ بملصقات مصدر البيانات في مجموعة البيانات المدمجة. يمكنك استخدام أي مصنف آخر.
from sklearn.ensemble import RandomForestClassifier import numpy as np rfc = RandomForestClassifier(n_jobs=-1, max_depth=5, min_samples_leaf = 5) predictions = np.zeros(y.shape)
نستخدم تقسيم عشوائي طبقي من 4 أضعاف. بهذه الطريقة سنحتفظ بنسبة التسميات "is_train" في كل مرة كما في العينة المدمجة الأصلية. لكل قسم ندرب المصنف على غالبية القسم ونتوقع تسمية الفئة للجزء المؤجل الأصغر.
from sklearn.model_selection import StratifiedKFold, cross_val_score skf = StratifiedKFold(n_splits=4, shuffle=True, random_state=100) for fold, (train_idx, test_idx) in enumerate(skf.split(x, y)): X_train, X_test = x[train_idx], x[test_idx] y_train, y_test = y[train_idx], y[test_idx] rfc.fit(X_train, y_train) probs = rfc.predict_proba(X_test)[:, 1]
الخطوة 5: تفسير النتائج
نحن نحسب قيمة مقياس ROC AUC لمصنفنا. استنادًا إلى هذه القيمة ، نستنتج إلى أي مدى يكشف المصنف عن تحول متغير في البيانات.
إذا قام المصنف c بفصل الكائنات جيدًا في مجموعات بيانات التدريب والاختبار ، فيجب أن تكون قيمة مقياس ROC AUC أكبر بكثير من 0.5 ، قريبًا بشكل مثالي من 1. تشير هذه الصورة إلى تحول متغير قوي في البيانات.أوجد قيمة ROC AUC:
from sklearn.metrics import roc_auc_score print('ROC-AUC:', roc_auc_score(y_true=y, y_score=predictions))
القيمة الناتجة قريبة من 0.5. وهذا يعني أن مصنّف الجودة الخاص بنا هو نفسه مُتنبئ العلامات العشوائية. لا يوجد دليل على تحول متغير في البيانات.
نظرًا لأن مجموعة البيانات مأخوذة من Kaggle ، فإن النتيجة يمكن التنبؤ بها إلى حد كبير. كما هو الحال في مسابقات التعلم الآلي الأخرى ، يتم التحقق من البيانات بعناية لضمان عدم وجود تحولات.
ولكن يمكن تطبيق هذا النهج في مشكلات أخرى لعلم البيانات للتحقق من وجود تحول متغير قبل بدء الحل مباشرةً.
خطوات أخرى
لذا ، إما أن نلاحظ تحولًا متباينًا أم لا. ماذا تفعل لتحسين جودة النموذج في الاختبار؟
- إزالة الميزات المتحيزة
- استخدم أوزان أهمية الكائن بناءً على تقديرات معامل الكثافة
إزالة الميزات المتحيزة:
ملاحظة: الطريقة قابلة للتطبيق إذا كان هناك تحول متغير في البيانات.- استخرج أهمية السمات من مصنف الغابة العشوائية ، الذي أنشأناه ودربناه سابقًا.
- أهم العلامات هي بالتحديد تلك التي تكون متحيزة وتتسبب في حدوث تحول في البيانات.
- بدءًا من الأهم ، احذف على أساس واحد ، وقم ببناء النموذج المستهدف وإلقاء نظرة على جودته. اجمع كل العلامات التي لا تنخفض جودة النموذج لها.
- تخلص من الخصائص المجمعة من البيانات وقم ببناء النموذج النهائي.
 تتيح لك هذه الخوارزمية إزالة العلامات من السلة الحمراء في الرسم التخطيطي.
تتيح لك هذه الخوارزمية إزالة العلامات من السلة الحمراء في الرسم التخطيطي.استخدام أوزان أهمية الكائن بناءً على تقديرات معامل الكثافة
ملاحظة: الطريقة قابلة للتطبيق بغض النظر عما إذا كان هناك تحول متغير في البيانات.دعونا نلقي نظرة على التوقعات التي تلقيناها في القسم السابق. لكل كائن ، يحتوي التنبؤ على احتمالية أن ينتمي هذا الكائن إلى مجموعة التدريب لمصنفنا.
predictions[:10]
على سبيل المثال ، بالنسبة للكائن الأول ، يعتقد المصنف العشوائي للغابة أنه ينتمي إلى مجموعة التدريب باحتمال 0.397. اتصل بهذه القيمة
. أو يمكننا القول أن احتمال الانتماء إلى بيانات الاختبار هو 0.603. وبالمثل ، نسمي الاحتمال
.
الآن خدعة صغيرة: لكل عنصر في مجموعة بيانات التدريب ، نحسب المعامل
.
المعامل
يخبرنا عن مدى قرب كائن من مجموعة التدريب لاختبار البيانات. الفكرة الرئيسية:
يمكننا استخدامها مثل الأوزان في أي من النماذج لزيادة وزن تلك الملاحظات التي تبدو مشابهة لعينة الاختبار. بشكل بديهي ، هذا منطقي ، لأن نموذجنا سيكون أكثر توجهاً نحو البيانات كما هو الحال في مجموعة اختبار.يمكن حساب هذه الأوزان باستخدام الكود:
import seaborn as sns import matplotlib.pyplot as plt plt.figure(figsize=(20,10)) predictions_train = predictions[:len(trn)] weights = (1./predictions_train) - 1. weights /= np.mean(weights)
يمكن نقل المعاملات التي تم الحصول عليها إلى النموذج ، على سبيل المثال ، على النحو التالي:
rfc = RandomForestClassifier(n_jobs=-1,max_depth=5) m.fit(X_train, y_train, sample_weight=weights)

بضع كلمات حول الرسم البياني الناتج:
- تتوافق قيم الوزن الأكبر مع الملاحظات الأكثر تشابهًا مع عينة الاختبار.
- ما يقرب من 70٪ من العناصر من مجموعة التدريب لها وزن قريب من 1 ، وبالتالي ، فهي في فضاء فرعي مشابه بالتساوي لمجموعة التدريب ومجموعة الاختبار. هذا يتوافق مع قيمة AUC التي حسبناها سابقًا.
الخلاصة
نأمل أن يساعدك هذا المنشور في تحديد "التحول المشترك" في البيانات ومكافحته.
المراجع
[1] Shimodaira، H. (2000). تحسين الاستدلال التنبئي في ظل التحول المتغير من خلال ترجيح دالة احتمالية السجل. مجلة التخطيط والاستدلال الإحصائي ، 90 ، 227-244.
[2] Bickel، S. et al. (2009). التعلم التمييزي في ظل التحول المتغير. مجلة أبحاث التعلم الآلي ، 10 ، 2137-2155
[3]
github.com/erlendd/covariate-shift-adaption[4]
رابط إلى مجموعة البيانات المستخدمةملاحظة يمكن الاطلاع على الكمبيوتر المحمول مع رمز من المقالة
هنا .