 الجيل الثالث من معالج الموترإن Google Tensor Processor
الجيل الثالث من معالج الموترإن Google Tensor Processor عبارة عن دائرة متكاملة للأغراض الخاصة (
ASIC ) تم تطويرها من الأساس من قبل Google لأداء مهام التعلم الآلي. يعمل في العديد من منتجات Google الرئيسية ، بما في ذلك الترجمة والصور ومساعد البحث و Gmail. توفر Cloud TPU مزايا قابلية التوسع وسهولة الاستخدام لجميع المطورين وعلماء البيانات الذين يطلقون نماذج التعلم الآلي المتطورة في Google Cloud. في Google Next '18 ، أعلنا أن Cloud TPU v2 متاح الآن لجميع المستخدمين ، بما في ذلك
الحسابات التجريبية المجانية ، و Cloud TPU v3 متاح لاختبار ألفا.

لكن الكثير من الناس يتساءلون - ما الفرق بين وحدة المعالجة المركزية ووحدة معالجة الرسومات ووحدة TPU؟ لقد أنشأنا موقعًا
تجريبيًا حيث يوجد العرض التقديمي والرسوم المتحركة للإجابة على هذا السؤال. في هذا المنشور ، أود أن أتطرق إلى ميزات معينة لمحتوى هذا الموقع.
كيف تعمل الشبكات العصبية؟
قبل البدء في مقارنة CPU و GPU و TPU ، دعنا نرى ما هو نوع الحسابات المطلوبة لتعلم الآلة - وبالتحديد للشبكات العصبية.
تخيل ، على سبيل المثال ، أننا نستخدم شبكة عصبية أحادية الطبقة للتعرف على الأرقام المكتوبة بخط اليد ، كما هو موضح في الرسم البياني التالي:
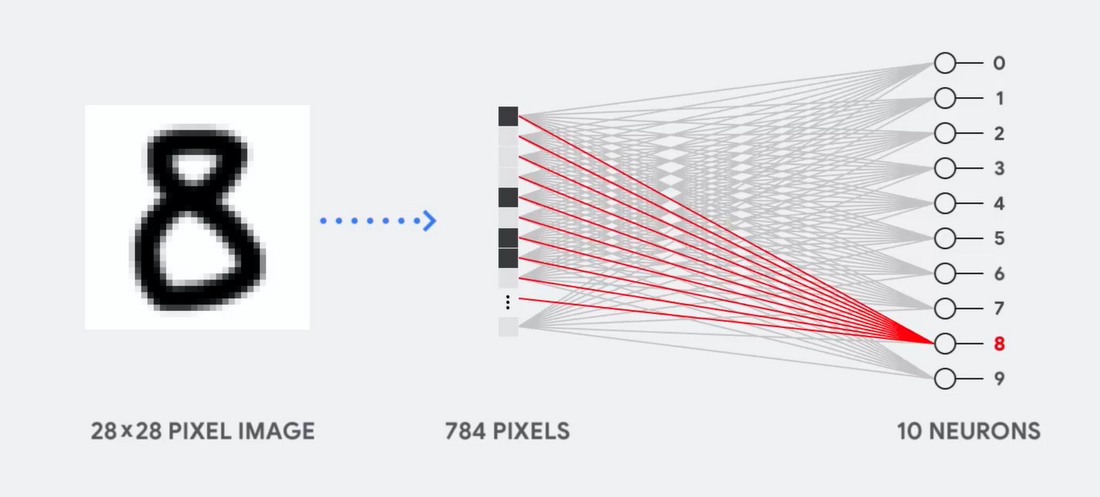
إذا كانت الصورة عبارة عن شبكة بحجم 28x28 بكسل بمقياس رمادي ، فيمكن تحويلها إلى متجه من 784 قيمة (قياسات). يأخذ العصبون الذي يتعرف على الرقم 8 هذه القيم ويضربها بقيم المعلمات (الخطوط الحمراء في الرسم التخطيطي).
تعمل المعلمة كمرشح ، وتستخرج ميزات البيانات التي تشير إلى تشابه الصورة والشكل 8:

هذا هو أبسط تفسير لتصنيف البيانات حسب الشبكات العصبية. ضرب البيانات بالمعلمات المقابلة لها (تلوين النقاط) وإضافتها (مجموع النقاط على اليمين). تشير أعلى نتيجة إلى أفضل تطابق بين البيانات المدخلة والمعلمة المقابلة ، والتي ، على الأرجح ، ستكون الإجابة الصحيحة.
ببساطة ، تحتاج الشبكات العصبية إلى القيام بعدد كبير من مضاعفات وإضافات البيانات والمعلمات. غالبًا ما ننظمها في شكل
ضرب المصفوفات ، والتي قد تواجهها في الجبر في المدرسة. لذلك ، تكمن المشكلة في إجراء عدد كبير من مضاعفات المصفوفة في أسرع وقت ممكن ، وإنفاق أقل قدر ممكن من الطاقة.
كيف تعمل وحدة المعالجة المركزية؟
كيف تتعامل وحدة المعالجة المركزية مع هذه المهمة؟ وحدة المعالجة المركزية هي معالج للأغراض العامة يعتمد على
بنية فون نيومان . هذا يعني أن وحدة المعالجة المركزية تعمل مع البرامج والذاكرة على النحو التالي:
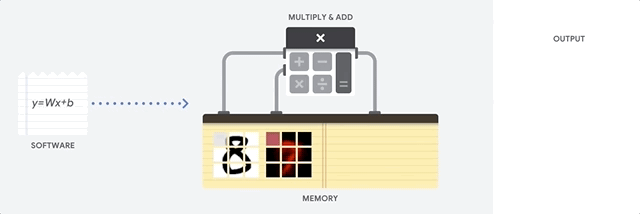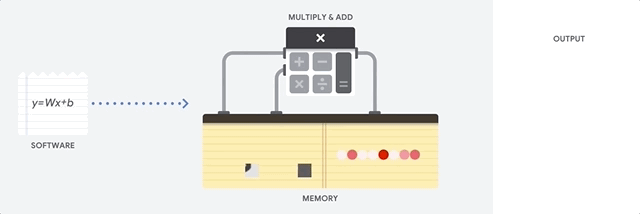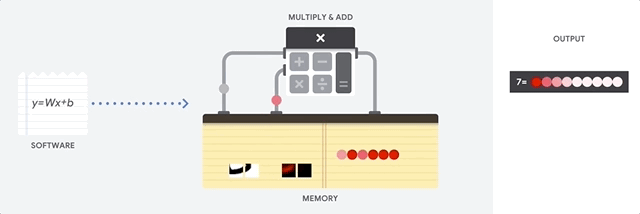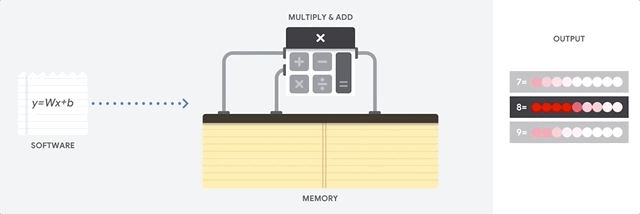
الميزة الرئيسية لوحدة المعالجة المركزية هي المرونة. بفضل هندسة فون نيومان ، يمكنك تنزيل برامج مختلفة تمامًا لملايين الأغراض المختلفة. يمكن استخدام وحدة المعالجة المركزية لمعالجة الكلمات والتحكم في محرك الصواريخ والمعاملات المصرفية وتصنيف الصور باستخدام الشبكة العصبية.
ولكن نظرًا لأن وحدة المعالجة المركزية مرنة للغاية ، فإن الجهاز لا يعرف دائمًا مسبقًا العملية التالية حتى يقرأ التعليمات التالية من البرنامج. تحتاج وحدة المعالجة المركزية إلى تخزين نتائج كل عملية حسابية في الذاكرة الموجودة داخل وحدة المعالجة المركزية (ما يسمى التسجيلات أو
ذاكرة التخزين المؤقت L1 ). يصبح الوصول إلى هذه الذاكرة ناقصًا في بنية وحدة المعالجة المركزية ، والمعروفة باسم اختناق بنية فون نيومان. وعلى الرغم من أن كمية هائلة من الحسابات للشبكات العصبية تجعل الخطوات المستقبلية قابلة للتنبؤ بها ، فإن كل وحدة معالجة
منطقية (ALU ، مكون يخزن ويتحكم في المضاعفات والمضيفات) تؤدي العمليات بشكل تسلسلي ، وتصل إلى الذاكرة في كل مرة ، مما يحد من الإنتاجية الإجمالية ويستهلك كمية كبيرة من الطاقة .
كيف يعمل GPU
لزيادة الإنتاجية مقارنة بوحدة المعالجة المركزية ، تستخدم GPU استراتيجية بسيطة: لماذا لا تدمج آلاف وحدات ALU في المعالج؟ تحتوي وحدة معالجة الرسومات الحديثة على حوالي 2500 - 5000 وحدة ALU على المعالج ، مما يجعل من الممكن إجراء الآلاف من المضاعفات والإضافات في كل مرة.

تعمل هذه البنية بشكل جيد مع التطبيقات التي تتطلب موازاة هائلة ، مثل ، على سبيل المثال ، ضرب المصفوفة في الشبكة العصبية. مع حمل التدريب النموذجي للتعلم العميق (GO) ، يزداد معدل النقل في هذه الحالة بترتيب الحجم مقارنةً بوحدة المعالجة المركزية. لذلك ، تعد وحدة معالجة الرسومات اليوم أكثر معالجات المعالج شيوعًا لـ GO.
لكن GPU لا يزال معالجًا للأغراض العامة يجب أن يدعم مليون تطبيق وبرنامج مختلف. وهذا يعيدنا إلى المشكلة الأساسية لعنق فن العمارة فون نيومان. لكل عملية حساب في الآلاف من وحدات ALU ، GPU ، من الضروري الرجوع إلى التسجيلات أو الذاكرة المشتركة من أجل قراءة نتائج الحساب المتوسطة وحفظها. نظرًا لأن وحدة معالجة الرسوميات (GPU) تؤدي حوسبة أكثر توازناً على آلاف وحدات ALU الخاصة بها ، فإنها تنفق أيضًا طاقة أكثر نسبيًا على الوصول إلى الذاكرة وتستهلك مساحة كبيرة.
كيف يعمل TPU؟
عندما قمنا بتطوير TPU في Google ، قمنا ببناء بنية مصممة لمهمة معينة. بدلاً من تطوير معالج للأغراض العامة ، قمنا بتطوير معالج مصفوفة متخصص في العمل مع الشبكات العصبية. لن تتمكن شركة TPU من العمل مع معالج الكلمات أو التحكم في محركات الصواريخ أو تنفيذ المعاملات المصرفية ، ولكن يمكنها معالجة عدد كبير من المضاعفات والإضافات للشبكات العصبية بسرعة لا تصدق ، مع استهلاك طاقة أقل وتركيب مناسب في حجم مادي أصغر.
الشيء الرئيسي الذي يسمح له بالقيام بذلك هو الإزالة الجذرية لعنق فن العمارة فون نيومان. نظرًا لأن المهمة الرئيسية لـ TPU هي معالجة المصفوفة ، كان مطورو الدائرة على دراية بجميع خطوات الحساب اللازمة. لذلك ، تمكنوا من وضع الآلاف من المضاعفات والمضافات ، وربطهم جسديًا ، لتشكيل مصفوفة فيزيائية كبيرة. وهذا ما يسمى
بنية المصفوفة ذات الأنابيب . في حالة Cloud TPU v2 ، يتم استخدام صفيفين من خطوط الأنابيب يبلغ حجمها 128 × 128 ، مما يعطي إجمالي 32768 وحدة ALU لقيم النقطة العائمة 16 بت على معالج واحد.
دعونا نرى كيف يقوم صفيف خط الأنابيب بإجراء حسابات لشبكة عصبية. أولاً ، تقوم مادة TPU بتحميل المعلمات من الذاكرة إلى مصفوفة من المضاعفات والمضيفات.

يقوم الـ TPU بعد ذلك بتحميل البيانات من الذاكرة. عند الانتهاء من كل عملية ضرب ، تنتقل النتيجة إلى العوامل التالية أثناء إجراء الإضافات. لذلك ، سيكون الناتج هو مجموع كل مضاعفات البيانات والمعلمات. طوال عملية الحوسبة الحجمية ونقل البيانات ، الوصول إلى الذاكرة غير ضروري تمامًا.
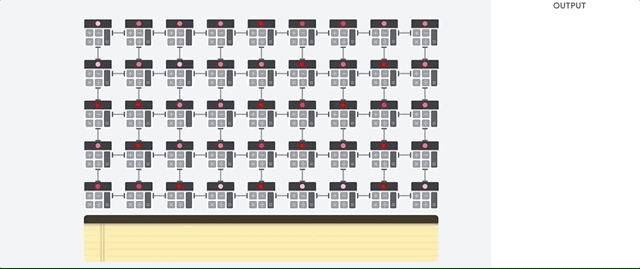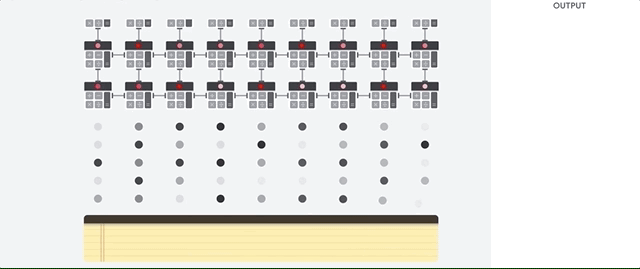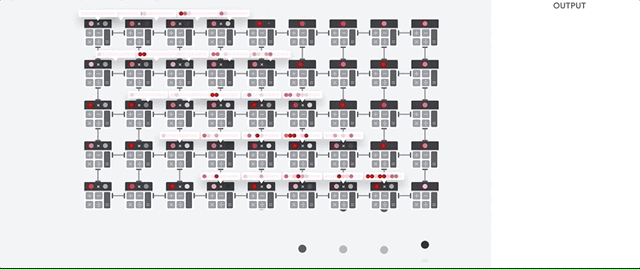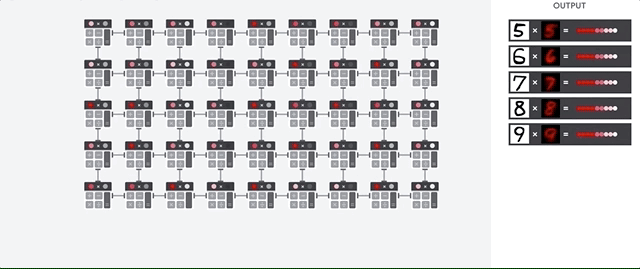
لذلك ، تُظهر TPU إنتاجية أكبر عند الحساب للشبكات العصبية ، وتستهلك طاقة أقل بكثير وتستهلك مساحة أقل.
ميزة: 5 مرات أقل تكلفة
ما هي فوائد بنية TPU؟ التكلفة. إليك تكلفة Cloud Cloud v2 لشهر أغسطس 2018 ، وقت كتابة هذا التقرير:
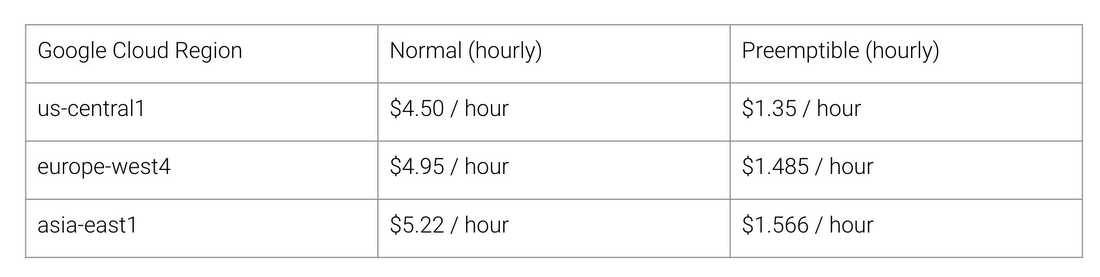
تكلفة العمل العادية و TPU لمناطق مختلفة من Google Cloud
تقوم جامعة ستانفورد بتوزيع مجموعة من اختبارات
DAWNBench التي تقيس أداء أنظمة التعلم العميق. هناك يمكنك إلقاء نظرة على مجموعات مختلفة من المهام والنماذج ومنصات الحوسبة ، بالإضافة إلى نتائج الاختبار المقابلة.
في وقت نهاية المسابقة في أبريل 2018 ، كان الحد الأدنى لتكلفة التدريب على المعالجات ذات الهندسة المعمارية بخلاف TPU 72.40 دولارًا (للتدريب ResNet-50 بدقة 93 ٪ على ImageNet في
الحالات الفورية ). مع Cloud TPU v2 ، يمكن إجراء هذا التدريب مقابل 12.87 دولارًا. هذا أقل من 1/5 من التكلفة. هذه هي قوة العمارة المصممة خصيصًا للشبكات العصبية.