
لسوء الحظ ، لا توجد معلومات كافية على الإنترنت عن ترحيل التطبيقات الحقيقية وعملية إنتاج مجموعة Percona XtraDB (المشار إليها فيما يلي باسم PXC). سأحاول تصحيح هذا الوضع وسأخبر عن تجربتنا مع قصتي. لن تكون هناك تعليمات تثبيت خطوة بخطوة ولا ينبغي اعتبار المقالة بديلاً عن التوثيق خارج النطاق ، ولكن كمجموعة من التوصيات.
المشكلة
أنا أعمل كمسؤول نظام في
Ultimate-Guitar.com . نظرًا لأننا نقدم خدمة ويب ، فمن الطبيعي أن يكون لدينا خلفية وقاعدة بيانات ، وهو جوهر الخدمة. يعتمد وقت تشغيل الخدمة بشكل مباشر على أداء قاعدة البيانات.
تم استخدام Percona MySQL 5.7 كقاعدة بيانات. تم تنفيذ الحجز باستخدام سيد مخطط النسخ المتماثل الرئيسي. تم استخدام العبيد لقراءة بعض البيانات.
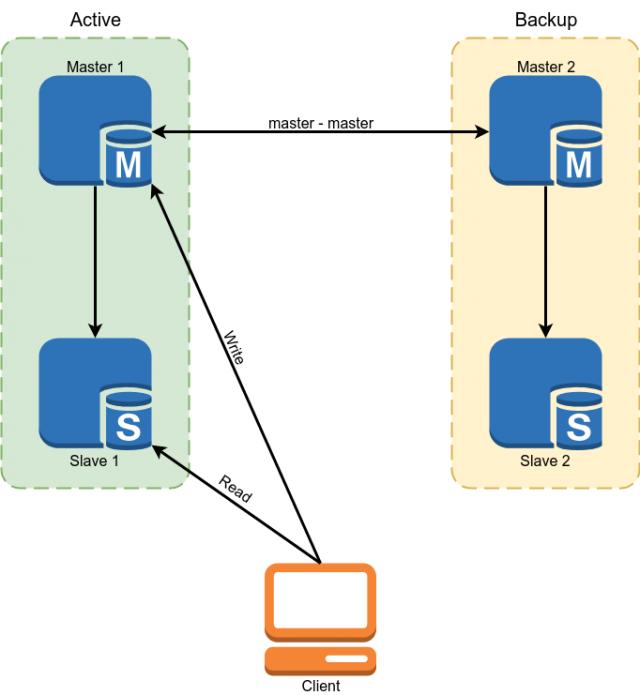
لكن هذا المخطط لم يناسبنا العيوب التالية:
- نظرًا لحقيقة أنه في نسخ MySQL ، يمكن أن يتأخر العبيد غير المتزامنين إلى أجل غير مسمى. يجب قراءة جميع البيانات الهامة من المعلم.
- من الفقرة السابقة يتبع تعقيد التنمية. لم يتمكن المطور من تقديم طلب إلى قاعدة البيانات فحسب ، بل كان عليه أن يفكر في ما إذا كان جاهزًا في كل حالة معينة للتراكم في الرقيق وإذا لم يكن كذلك ، فقم بقراءة البيانات من المعالج.
- التبديل اليدوي في حالة وقوع حادث. كان تنفيذ التبديل التلقائي مشكلة بسبب حقيقة أن بنية MySQL لا تحتوي على حماية مدمجة ضد انقسام الدماغ. سيتعين علينا أن نكتب لأنفسنا حكما منطقيا معقدا لاختيار سيد. عند الكتابة إلى كلا السادة ، يمكن أن تنشأ النزاعات في نفس الوقت ، وتكسر النسخ المتماثل الرئيسي وتؤدي إلى الدماغ الكلاسيكي المنقسم.
بعض الأرقام الجافة ، حتى تفهم ما عملنا معه:
حجم قاعدة البيانات: 300 جيجا بايت
QPS: ~ 10 كيلو
نسبة RW: 96/4٪
تكوين الخادم الرئيسي:
وحدة المعالجة المركزية: 2x E5-2620 v3
ذاكرة الوصول العشوائي: 128 جيجابايت
SSD: Intel Optane 905p 960 Gb
الشبكة: 1 جيجابت / ثانية
لدينا تحميل OLTP كلاسيكي مع الكثير من القراءة ، والذي يجب القيام به بسرعة كبيرة وبكمية صغيرة من الكتابة. الحمل على قاعدة البيانات صغير جدًا نظرًا لأن التخزين المؤقت يستخدم بنشاط في Redis و Memcached.
اختيار القرار
كما كنت قد خمنت من العنوان ، اخترنا PXC ، ولكن هنا سأشرح لماذا اخترناه.
كان لدينا 4 خيارات:
- تغيير DBMS
- نسخ مجموعة MySQL
- قم بتثبيت الوظائف اللازمة بأنفسنا باستخدام البرامج النصية أعلى سيد النسخ المتماثل الرئيسي.
- مجموعة MySQL Galera (أو شوكاتها ، على سبيل المثال PXC)
عمليا خيار تغيير قاعدة البيانات لم يؤخذ في الاعتبار ، لأنه التطبيق كبير ، في العديد من الأماكن مرتبط بوظيفة الخلية أو بناء الجملة ، والترحيل إلى PostgreSQL ، على سبيل المثال ، سيستغرق الكثير من الوقت والموارد.
كان الخيار الثاني هو النسخ المتماثل لمجموعة MySQL. ومن المزايا التي لا شك فيها أنها تتطور في فرع الفانيليا من MySQL ، مما يعني أنها ستنتشر في المستقبل وسيكون لديها مجموعة كبيرة من المستخدمين النشطين.
ولكن لديه بعض العوائق. أولاً ، يفرض المزيد من القيود على مخطط التطبيق وقاعدة البيانات ، مما يعني أنه سيكون من الصعب الترحيل. ثانيًا ، يحل النسخ المتماثل الجماعي مشكلة التسامح مع الخطأ وتقسيم الدماغ ، ولكن التكرار في المجموعة لا يزال غير متزامن.
كما أننا لم نحب الخيار الثالث للعديد من الدراجات ، والذي لا بد لنا من تنفيذه عند حل المشكلة بهذه الطريقة.
سمح Galera بحل مشكلة تجاوز الفشل MySQL بالكامل وحل المشكلة جزئيًا من حيث صلة البيانات على العبيد. جزئيا لأنه يتم الحفاظ على التزامن النسخ المتماثل. بعد تنفيذ معاملة على عقدة محلية ، يتم دفع التغييرات إلى العقد المتبقية بشكل غير متزامن ، لكن الكتلة تضمن أن العقد لا تتأخر كثيرًا وإذا بدأت في التأخير ، فإنها تبطئ العمل بشكل مصطنع. يضمن نظام المجموعة أنه بعد تنفيذ المعاملة ، لا يمكن لأي شخص تنفيذ تغييرات متضاربة حتى على العقدة التي لم تقم بعد بتكرار التغييرات.
بعد الترحيل ، يجب أن يبدو مخطط تشغيل قاعدة البيانات كما يلي:
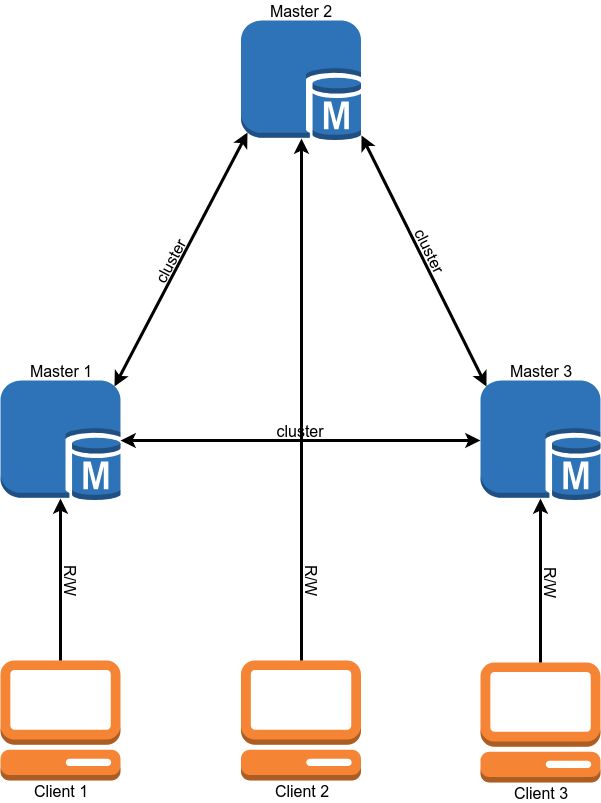
الهجرة
لماذا يعتبر الترحيل العنصر الثاني بعد اختيار الحل؟ الأمر بسيط - تحتوي المجموعة على عدد من المتطلبات التي يجب أن يتبعها التطبيق وقاعدة البيانات ، ونحن بحاجة إلى تلبيتها قبل الترحيل.
- محرك InnoDB لجميع الطاولات. MyISAM والذاكرة والواجهة الخلفية الأخرى غير مدعومة. تم إصلاحه بكل بساطة - نقوم بتحويل جميع الجداول إلى InnoDB.
- Binlog بتنسيق ROW. لا يحتاج نظام المجموعة إلى binlog للعمل ، وإذا لم تكن بحاجة إلى عبيد كلاسيكيين ، فيمكنك إيقاف تشغيله ، ولكن يجب أن يكون تنسيق binlog هو ROW.
- يجب أن تحتوي جميع الجداول على مفتاح أساسي / أجنبي. هذا مطلوب للكتابة المتزامنة الصحيحة إلى نفس الجدول من العقد المختلفة. بالنسبة لتلك الجداول التي لا تحتوي على مفتاح فريد ، يمكنك استخدام المفتاح الأساسي المركب أو الزيادة التلقائية.
- لا تستخدم "LOCK TABLES" أو "GET_LOCK () / RELEASE_LOCK ()" أو "FLUSH TABLES {{table}} WITH READ LOCK" أو مستوى العزل "SERIALIZABLE" للمعاملات.
- لا تستخدم استعلامات "CREATE TABLE ... AS SELECT" ، مثل تجمع بين المخطط وتغيير البيانات. يمكن تقسيمها بسهولة إلى استعلامين ، أولهما ينشئ جدولًا ، والثاني يملأ البيانات.
- لا تستخدم "DISCARD TABLESPACE" و "IMPORT TABLESPACE" ، مثل لا يتم نسخها
- اضبط الخيارات "innodb_autoinc_lock_mode" على "2". يمكن أن يؤدي هذا الخيار إلى إتلاف البيانات عند العمل مع النسخ المتماثل لـ STATEMENT ، ولكن نظرًا لأنه يسمح فقط بالنسخ المتماثل لـ ROW في المجموعة ، فلن تكون هناك مشاكل.
- نظرًا لأن "log_output" يتم دعم "FILE" فقط. إذا كان لديك إدخال سجل في الجدول ، فسيتعين عليك إزالته.
- معاملات XA غير مدعومة. إذا تم استخدامها ، فسيتعين عليك إعادة كتابة الرمز بدونها.
يجب أن أشير إلى أنه يمكن إزالة كل هذه القيود تقريبًا إذا قمت بتعيين المتغير "pxc_strict_mode = PERMISSIVE" ، ولكن إذا كانت بياناتك مهمة بالنسبة لك ، فمن الأفضل عدم القيام بذلك. إذا كان لديك مجموعة 'pxc_strict_mode = ENFORCING' ، فلن تسمح لك MySQL بتنفيذ العمليات المذكورة أعلاه أو منع بدء العقدة.
بعد أن استوفينا جميع متطلبات قاعدة البيانات واختبار تشغيل تطبيقنا بدقة في بيئة التطوير ، يمكننا المتابعة إلى المرحلة التالية.
نشر الكتلة وتكوينها
لدينا العديد من قواعد البيانات التي تعمل على خوادم قواعد البيانات الخاصة بنا وقواعد البيانات الأخرى لا تحتاج إلى الترحيل إلى الكتلة. لكن حزمة مع كتلة MySQL تحل محل الخلية الكلاسيكية. كان لدينا العديد من الحلول لهذه المشكلة:
- استخدم المحاكاة الافتراضية وابدأ المجموعة في VM. لم نحب هذا الخيار نظرًا للتكاليف العامة الكبيرة (مقارنة بالباقي) وظهور كيان آخر يحتاج إلى الصيانة
- قم بإنشاء نسختك من الحزمة ، والتي ستضع الخلية في مكان غير قياسي. وبالتالي ، سيكون من الممكن أن يكون لديك العديد من إصدارات الخلية على خادم واحد. خيار جيد إذا كان لديك العديد من الخوادم ، ولكن الدعم المستمر لحزمتك ، والذي يحتاج إلى التحديث بانتظام ، يمكن أن يستغرق الكثير من الوقت.
- استخدم Docker.
لقد اخترنا Docker ، لكننا نستخدمه في الخيار الأدنى. لتخزين البيانات يتم استخدام الحجم المحلي. يتم استخدام وضع التشغيل "- net host" لتقليل وقت استجابة الشبكة وحمل وحدة المعالجة المركزية.
كان علينا أيضًا إنشاء نسختنا الخاصة من صورة Docker. والسبب هو أن الصورة القياسية من بيركونا لا تدعم وضع الاستعادة عند بدء التشغيل. وهذا يعني أنه في كل مرة يتم فيها إعادة تشغيل المثيل ، فإنه لا يجري مزامنة IST سريعة ، والتي تقوم بتحميل التغييرات الضرورية فقط ، ولكن SST بطيئة ، والتي تعيد تحميل قاعدة البيانات تمامًا.
مشكلة أخرى هي حجم الكتلة. في نظام المجموعة ، تقوم كل عقدة بتخزين مجموعة البيانات بالكامل. لذلك ، قراءة المقاييس بشكل مثالي مع زيادة حجم الكتلة. مع التسجيل ، فإن الوضع هو عكس ذلك - عند الالتزام ، يتم التحقق من صحة كل معاملة لعدم وجود تعارضات في جميع العقد. بطبيعة الحال ، كلما زاد عدد العقد ، زاد الوقت الذي يستغرقه الالتزام.
هنا لدينا أيضًا العديد من الخيارات:
- 2 عقد + حكم. 2 عقد + حكم. خيار جيد للاختبارات. أثناء نشر العقدة الثانية ، يجب ألا يسجل المعلم.
- 3 عقد. الإصدار الكلاسيكي. توازن السرعة والموثوقية. يرجى ملاحظة أنه في هذا التكوين يجب أن تمتد عقدة واحدة الحمل بأكمله ، لأن عند إضافة العقدة الثالثة ، ستكون الثانية هي الجهة المانحة.
- 4+ عقد. مع وجود عدد زوجي من العقد ، من الضروري إضافة حكم لتجنب انقسام الدماغ. خيار يعمل بشكل جيد مع كمية كبيرة جدًا من القراءة. تتزايد موثوقية الكتلة أيضًا.
لقد استقرنا حتى الآن على الخيار بثلاث عقد.
ينسخ تكوين الكتلة بشكل شبه كامل تكوين MySQL المستقل ويختلف فقط في عدد قليل من الخيارات:
"Wsrep_sst_method = xtrabackup-v2" يقوم هذا الخيار بتعيين طريقة نسخ العقد. الخيارات الأخرى هي mysqldump و rsync ، لكنهما تحجبان العقدة طوال مدة النسخ. لا أرى أي سبب لاستخدام طريقة النسخ غير xtrabackup-v2.
"Gcache" هو تناظرية من binlog الكتلة. هو مخزن دائري (في ملف) ذو حجم ثابت يتم كتابة جميع التغييرات فيه. إذا قمت بإيقاف تشغيل إحدى عقد نظام المجموعة ثم أعدت تشغيلها ، فستحاول قراءة التغييرات المفقودة من Gcache (مزامنة IST). إذا لم يكن بها التغييرات المطلوبة من العقدة ، فستكون هناك حاجة إلى إعادة تحميل العقدة بالكامل (مزامنة SST). يتم تعيين حجم gcache كما يلي: wsrep_provider_options = 'gcache.size = 20G؛'.
wsrep_slave_threads على عكس النسخ المتماثل الكلاسيكي في مجموعة ، من الممكن تطبيق عدة "مجموعات كتابة" على نفس قاعدة البيانات بالتوازي. يشير هذا الخيار إلى عدد العمال الذين يطبقون التغييرات. من الأفضل عدم ترك القيمة الافتراضية 1 ، لأنه أثناء تطبيق العامل لمجموعة كتابة كبيرة ، سينتظر الباقي في قائمة الانتظار وسيبدأ النسخ المتماثل للعقدة في التأخر. ينصح البعض بتعيين هذه المعلمة على 2 * خيطات وحدة المعالجة المركزية ، ولكن أعتقد أنك بحاجة إلى النظر في عدد عمليات الكتابة المتزامنة التي لديك.
استقرنا على القيمة 64. عند القيمة الأقل ، لم تتمكن الكتلة في بعض الأحيان من تطبيق جميع مجموعات الكتابة من قائمة الانتظار أثناء رشقات الحمل (على سبيل المثال ، عند بدء تيجان ثقيلة).
wsrep_max_ws_size يقتصر حجم المعاملة الواحدة في نظام المجموعة على 2 غيغابايت. لكن المعاملات الكبيرة لا تتناسب بشكل جيد مع مفهوم PXC. من الأفضل إكمال 100 معاملة بقيمة 20 ميجابايت لكل منها لكل 2 جيجابايت. لذلك ، قمنا أولاً بتحديد حجم المعاملة في المجموعة إلى 100 ميجابايت ، ثم خفضنا الحد إلى 50 ميجابايت.
إذا قمت بتمكين الوضع الصارم ، يمكنك ضبط المتغير "
binlog_row_image " على "الحد الأدنى". سيؤدي هذا إلى تقليل حجم الإدخالات في binlog عدة مرات (10 مرات في الاختبار من Percona). سيوفر هذا مساحة على القرص ويسمح بالمعاملات التي لا تتناسب مع الحد "binlog_row_image = full".
حدود SST. بالنسبة إلى Xtrabackup ، المستخدم لملء العقد ، يمكنك تعيين حد لاستخدام الشبكة وعدد سلاسل العمليات وطريقة الضغط. يعد ذلك ضروريًا حتى عندما يتم ملء العقدة ، لا يبدأ الخادم المانحة في التباطؤ. للقيام بذلك ، تتم إضافة قسم "sst" إلى ملف my.cnf:
[sst] rlimit = 80m compressor = "pigz -3" decompressor = "pigz -dc" backup_threads = 4
نحن نقصر سرعة النسخ على 80 ميجا بايت / ثانية. نحن نستخدم pigz للضغط ، هذه نسخة متعددة الخيوط من gzip.
GTID إذا كنت تستخدم العبيد الكلاسيكيين ، أوصي بتمكين GTID على الكتلة. سيسمح لك هذا بتوصيل الرقيق بأي عقدة في الكتلة دون إعادة تحميل الرقيق.
بالإضافة إلى ذلك ، أريد أن أتحدث عن آليتين عنقوديتين ، ومعنىهما وتكوينهما.
التحكم في التدفق
التحكم في التدفق هو طريقة لإدارة تحميل الكتابة في كتلة. لا يسمح بتأخر العقد في النسخ المتماثل. بهذه الطريقة ، يتم تحقيق النسخ المتماثل "شبه المتزامن". آلية التشغيل بسيطة للغاية - بمجرد أن يصل طول قائمة انتظار الاستقبال إلى القيمة المحددة ، فإنها ترسل رسالة "إيقاف التحكم في التدفق" إلى العقد الأخرى ، والتي تخبرهم بالتوقف مؤقتًا عند تنفيذ معاملات جديدة حتى تنتهي العقدة المتأخرة من ترتيب قائمة الانتظار .
يتبع ذلك عدة أشياء:
- سيحدث التسجيل في المجموعة بسرعة أبطأ العقدة. (ولكن يمكن تشديده.)
- إذا كان لديك الكثير من التعارضات عند تنفيذ المعاملات ، فيمكنك تكوين التحكم في التدفق بشكل أكثر قوة ، مما يجب أن يقلل من عددها.
- يعد الحد الأقصى للفاصل الزمني للعقدة في نظام المجموعة ثابتًا ، ولكن ليس حسب الوقت ، ولكن بعدد المعاملات في قائمة الانتظار. يعتمد وقت التأخير على متوسط حجم المعاملة وعدد wsrep_slave_threads.
يمكنك عرض إعدادات التحكم بالانسياب مثل هذا:
mysql> SHOW GLOBAL STATUS LIKE 'wsrep_flow_control_interval_%';
wsrep_flow_control_interval_low | 36
wsrep_flow_control_interval_high | 71
بادئ ذي بدء ، نحن مهتمون بالمعلمة wsrep_flow_control_interval_high. يتحكم في طول قائمة الانتظار ، وبعد ذلك يتم تشغيل إيقاف مؤقت FC. يتم حساب هذه المعلمة بواسطة الصيغة: gcs.fc_limit * √N (حيث N = عدد العقد في المجموعة.).
المعلمة الثانية هي wsrep_flow_control_interval_low. وهي مسؤولة عن قيمة طول قائمة الانتظار ، عند الوصول إلى إيقاف FC. يحسب بواسطة الصيغة: wsrep_flow_control_interval_high * gcs.fc_factor. بشكل افتراضي ، gcs.fc_factor = 1.
وبالتالي ، من خلال تغيير طول قائمة الانتظار ، يمكننا التحكم في تأخر النسخ المتماثل. سيؤدي تقليل طول قائمة الانتظار إلى زيادة الوقت الذي تقضيه الكتلة في الإيقاف المؤقت لـ FC ، ولكنها تقلل من تأخر العقد.
يمكنك تعيين متغير الجلسة "
wsrep_sync_wait = 7". سيؤدي ذلك إلى إجبار PXC على تنفيذ طلبات القراءة أو الكتابة فقط بعد تطبيق جميع مجموعات الكتابة في قائمة الانتظار الحالية. وبطبيعة الحال ، سيؤدي ذلك إلى زيادة وقت الاستجابة للطلبات. تتناسب الزيادة في الكمون بشكل مباشر مع طول قائمة الانتظار.
من المستحسن أيضًا تقليل الحد الأقصى لحجم المعاملة إلى الحد الأدنى الممكن ، حتى لا تنزلق المعاملات الطويلة عن طريق الخطأ.
EVS أو طرد تلقائي
تتيح لك هذه الآلية التخلص من العقد غير المستقرة (على سبيل المثال ، فقدان الحزمة أو التأخير الطويل) أو التي تستجيب ببطء. بفضل ذلك ، لن تؤدي مشاكل الاتصال مع عقدة واحدة إلى وضع المجموعة بالكامل ، ولكنها تسمح بتعطيل العقدة وتستمر في العمل في الوضع العادي. هذه الآلية مفيدة بشكل خاص عندما تعمل الكتلة من خلال WAN أو أجزاء من الشبكة التي لا تخضع لسيطرتك. بشكل افتراضي ، يتم إيقاف تشغيل EVS.
لتمكينه ، أضف الخيار "evs.version = 1؛" إلى معلمة
wsrep_provider_options و "evs.auto_evict = 5؛" (عدد العمليات التي يتم بعدها إيقاف تشغيل العقدة. وتعطل القيمة 0 EVS). هناك أيضًا العديد من المعلمات التي تسمح لك بضبط EVS:
- evs.delayed_margin الوقت الذي تستغرقه العقدة للرد. بشكل افتراضي ، ثانية واحدة ، ولكن عند العمل على شبكة محلية ، يمكن تقليلها إلى 0.05-0.1 ثانية أو أقل.
- evs.inactive_check_period فترة الشيكات. افتراضي 0.5 ثانية
في الواقع ، الوقت الذي يمكن أن تعمل فيه العقدة في حالة حدوث مشاكل قبل تشغيل EVS هو evs.inactive_check_period * evs.auto_evict. يمكنك أيضًا تعيين "evs.inactive_timeout" وسيتم التخلص من العقدة التي لا تستجيب على الفور ، بشكل افتراضي 15 ثانية.
فارق بسيط مهم هو أن هذه الآلية نفسها لن تعيد العقدة مرة أخرى عند استعادة الاتصال. يجب إعادة تشغيله يدويًا.
أنشأنا EVS في المنزل ، ولكن لم تتح لنا الفرصة لاختباره في المعركة.
موازنة التحميل
حتى يتمكن العملاء من استخدام موارد كل عقدة بالتساوي وتنفيذ الطلبات فقط على عقد الكتلة الحية ، نحتاج إلى موازن تحميل. تقدم بيركونا حلين:
- ProxySQL. هذا هو الوكيل L7 لـ MySQL.
- هابروكسي. لكن Haproxy لا يعرف كيفية التحقق من حالة عقدة نظام المجموعة وتحديد ما إذا كانت جاهزة لتنفيذ الطلبات. لحل هذه المشكلة ، يُقترح استخدام نص برمجي إضافي للبيركونا
في البداية أردنا استخدام ProxySQL ، ولكن بعد قياس الأداء اتضح أن الكمون يفقد إلى Haproxy بنحو 15-20٪ حتى عند استخدام الوضع fast_forward (إعادة كتابة الاستعلام والتوجيه والعديد من وظائف ProxySQL الأخرى لا تعمل في هذا الوضع ، يتم تشغيل الطلبات على حالتها) .
Haproxy أسرع ، لكن نص بيركونا لديه بعض العوائق.
أولاً ، هو مكتوب بلغة باش ، والتي لا تساهم في تخصيصها. المشكلة الأكثر خطورة هي أنه لا يخزن نتيجة فحص MySQL. وبالتالي ، إذا كان لدينا 100 عميل ، يفحص كل منهم حالة العقدة مرة واحدة كل ثانية ، فسيقدم البرنامج النصي طلبًا إلى MySQL كل 10 مللي ثانية. إذا بدأ MySQL في العمل ببطء لسبب ما ، فسيبدأ البرنامج النصي للتحقق في إنشاء عدد كبير من العمليات ، وهو ما لن يحسن الوضع بالتأكيد.
تقرر كتابة
حل لا يرتبط فيه فحص حالة MySQL واستجابة Haproxy ببعضهما البعض. يتحقق البرنامج النصي من حالة العقدة في الخلفية على فترات منتظمة ويخزن النتيجة مؤقتًا. يعطي خادم الويب Haproxy النتيجة المخبأة.
مثال على تكوين Haproxylisten db
bind 127.0.0.1:3302
mode tcp
balance first
default-server inter 200 rise 6 fall 6
option httpchk HEAD /
server node1 192.168.0.1:3302 check port 9200 id 1
server node2 192.168.0.2:3302 check port 9200 backup id 2
server node3 192.168.0.3:3302 check port 9200 backup id 3
listen db_slave
bind 127.0.0.1:4302
mode tcp
balance leastconn
default-server inter 200 rise 6 fall 6
option httpchk HEAD /
server node1 192.168.0.1:3302 check port 9200 backup
server node2 192.168.0.2:3302 check port 9200
server node3 192.168.0.3:3302 check port 9200
يوضح هذا المثال تكوين معالج واحد. تعمل خوادم الكتلة المتبقية كعبيد.
المراقبة
لرصد حالة الكتلة ، استخدمنا Prometheus + mysqld_exporter و Grafana لتصور البيانات. لأن يقوم mysqld_exporter بجمع مجموعة من المقاييس لإنشاء لوحات تحكم بنفسك مملة للغاية. يمكنك أخذ
لوحات تحكم جاهزة
من بيركونا وتخصيصها بنفسك.
نستخدم أيضًا Zabbix لجمع المقاييس والتنبيهات العنقودية الأساسية.
مقاييس الكتلة الرئيسية التي تريد مراقبتها:
- يجب تعيين wsrep_cluster_status على "أساسي" في جميع العقد. إذا كانت القيمة "غير أساسية" ، فقد هذه العقدة الاتصال بنصاب الكتلة.
- wsrep_cluster_size عدد العقد في المجموعة. وهذا يشمل أيضًا العقد "المفقودة" ، والتي يجب أن تكون في الكتلة ، ولكن لسبب ما غير متوفرة. عندما يتم إيقاف تشغيل العقدة برفق ، تنخفض قيمة هذا المتغير.
- يشير wsrep_local_state إلى ما إذا كانت العقدة عضوًا نشطًا في المجموعة وجاهزة للعمل.
- wsrep_evs_state معلمة مهمة إذا قمت بتشغيل الإخلاء التلقائي (إيقاف التشغيل افتراضيًا). يشير هذا المتغير إلى أن EVS تعتبر هذه العقدة سليمة.
- wsrep_evs_evict_list قائمة العقد التي تم طرحها بواسطة EVS من المجموعة. في الوضع الطبيعي ، يجب أن تكون القائمة فارغة.
- wsrep_evs_delayed قائمة المرشحين لإزالة EVS. يجب أن يكون فارغًا أيضًا.
مقاييس الأداء الرئيسية:
- wsrep_evs_repl_latency يظهر (الحد الأدنى / المتوسط / الحد الأقصى / الانحراف الكبير / حجم الحزمة) تأخير الاتصال داخل المجموعة. أي أنها تقيس كمون الشبكة. قد تشير زيادة القيم إلى التحميل الزائد على الشبكة أو عقد الكتلة. يتم تسجيل هذا المقياس حتى عند إيقاف تشغيل EVS.
- wsrep_flow_control_paused_ns الوقت (في ns) منذ بدء العقدة التي قضتها في وقفة التحكم بالانسياب. من الناحية المثالية ، يجب أن يكون 0. يشير نمو هذه المعلمة إلى مشاكل في أداء الكتلة أو نقص "wsrep_slave_threads". يمكنك تحديد العقدة التي تبطئ بواسطة المعلمة " wsrep_flow_control_sent ".
- wsrep_flow_control_paused النسبة المئوية للوقت الذي انقضى منذ آخر تنفيذ لـ "حالة FLUSH STATUS" ، التي قضت العقدة في فترة التحكم المؤقت في التدفق. بالإضافة إلى المتغير السابق ، يجب أن يميل إلى الصفر.
- يشير wsrep_flow_control_status إلى ما إذا كان التحكم بالانسياب قيد التشغيل حاليًا. في عقدة بدء إيقاف مؤقت لـ FC ، ستكون قيمة هذا المتغير قيد التشغيل.
- wsrep_local_recv_queue_avg متوسط طول قائمة انتظار الاستلام. يشير نمو هذه المعلمة إلى وجود مشاكل في أداء العقدة.
- wsrep_local_send_queue_avg متوسط طول قائمة انتظار الإرسال. يشير نمو هذه المعلمة إلى مشاكل في أداء الشبكة.
لا توجد توصيات عالمية بشأن قيم هذه المعلمات. من الواضح أنها يجب أن تميل إلى الصفر ، ولكن عند التحميل الحقيقي ، لن يكون هذا هو الحال على الأرجح ، وعليك أن تحدد بنفسك مكان مرور حدود الحالة الطبيعية للكتلة.
النسخ الاحتياطي
النسخ الاحتياطي للكتلة لا يختلف عمليا عن الخلية المستقلة. لاستخدام الإنتاج ، لدينا العديد من الخيارات.
- قم بإزالة النسخة الاحتياطية من إحدى العقد "كسب" باستخدام xtrabackup. الخيار الأسهل ، ولكن سيتم تبديد أداء مجموعة النسخ الاحتياطي.
- استخدم العبيد الكلاسيكيين والنسخ الاحتياطي من النسخ المتماثلة.
النسخ الاحتياطية مع الإصدار المستقل وإصدار الكتلة الذي تم إنشاؤه باستخدام xtrabackup محمولة فيما بينها. أي أنه يمكن نشر النسخة الاحتياطية المأخوذة من المجموعة إلى الخلية المستقلة والعكس صحيح. بطبيعة الحال ، يجب أن تتطابق النسخة الرئيسية من MySQL ، ويفضل أن تكون النسخة الثانوية. النسخ الاحتياطية التي يتم إجراؤها باستخدام mysqldump محمولة بشكل طبيعي أيضًا.
التحذير الوحيد هو أنه بعد نشر النسخة الاحتياطية ، يجب تشغيل البرنامج النصي mysql_upgrade ، والذي سيتحقق من هيكل بعض جداول النظام ويصححها.
ترحيل البيانات
الآن بعد أن اكتشفنا التكوين والمراقبة وأشياء أخرى ، يمكننا البدء في الترحيل إلى المنتج.
كان ترحيل البيانات في مخططنا بسيطًا جدًا ، لكننا أخطأنا قليلاً ؛).
وسيلة الإيضاح - يتم توصيل سيد 1 وسيد 2 بواسطة سيد النسخ المتماثل الرئيسي. التسجيل يذهب فقط لإتقان 1. Master 3 هو خادم نظيف.
خطتنا للترحيل (في الخطة سأحذف العمليات مع العبيد من أجل البساطة وسأتحدث فقط عن الخوادم الرئيسية).
المحاولة 1
- إزالة النسخة الاحتياطية لقاعدة البيانات من الرئيسي 1 باستخدام xtrabackup.
- نسخ النسخة الاحتياطية لإتقان 3 وتشغيل الكتلة في وضع عقدة واحدة.
- قم بإعداد النسخ المتماثل الرئيسي بين الأساسيين 3 و 1.
- قم بتحويل القراءة والكتابة إلى المعلم 3. تحقق من التطبيق.
- في الصفحة الرئيسية 2 ، أوقف تشغيل النسخ المتماثل وابدأ MySQL المجمعة. نحن في انتظاره لنسخ قاعدة البيانات من المعلم 3. أثناء النسخ ، كان لدينا مجموعة من عقدة واحدة في حالة "المتبرع" ولا تزال عقدة أخرى لا تعمل. أثناء النسخ ، حصلنا على مجموعة من الأقفال وفي النهاية سقطت كل العقد مع خطأ (لا يمكن إتمام إنشاء عقدة جديدة بسبب الأقفال الميتة). لقد كلفتنا هذه التجربة الصغيرة أربع دقائق من التوقف.
- بدّل القراءة والكتابة إلى إتقان 1.
لم يعمل الترحيل نظرًا لحقيقة أنه عند اختبار الدائرة في بيئة التطوير على قاعدة البيانات ، لم يكن هناك أي حركة مرور للكتابة تقريبًا ، وعند تكرار نفس الدائرة تحت الحمل ، ظهرت مشاكل.
قمنا بتغيير نظام الهجرة بشكل طفيف لتجنب هذه المشاكل وأعدنا المحاولة ، للمرة الثانية بنجاح ؛).
المحاولة 2
- نعيد تشغيل الرئيسي 3 بحيث يعمل مرة أخرى في وضع العقدة المفردة.
- نرفع الكتلة MySQL مرة أخرى على سيد 2. في الوقت الحالي ، انتقلت حركة المرور من النسخ المتماثل فقط إلى الكتلة ، لذلك لم تكن هناك مشاكل متكررة مع الأقفال وتمت إضافة العقدة الثانية بنجاح إلى الكتلة.
- مرة أخرى ، قم بتحويل القراءة والكتابة إلى الماجستير 3. نتحقق من تشغيل التطبيق.
- تعطيل النسخ المتماثل الرئيسي مع الرئيسي 1. قم بتشغيل mysql للكتلة على الرئيسي 1 وانتظر حتى يبدأ. لكي لا تخطو على نفس أشعل النار ، من المهم ألا يكتب التطبيق إلى العقدة المانحة (لمزيد من التفاصيل ، انظر القسم الخاص بموازنة التحميل). بعد بدء العقدة الثالثة ، سيكون لدينا مجموعة كاملة الوظائف من ثلاث عقد.
- يمكنك إزالة نسخة احتياطية من إحدى عقد الكتلة وإنشاء عدد العبيد الكلاسيكيين الذين تحتاجهم.
الفرق بين المخطط الثاني والمخطط الأول هو أننا قمنا بتبديل حركة المرور إلى الكتلة فقط بعد رفع العقدة الثانية في الكتلة.
استغرق هذا الإجراء حوالي 6 ساعات بالنسبة لنا.
متعدد سيد
بعد الترحيل ، عملت مجموعتنا في وضع رئيسي واحد ، أي أن السجل بأكمله ذهب إلى أحد الخوادم ، وتمت قراءة البيانات فقط من الباقي.
بعد تبديل الإنتاج إلى الوضع متعدد الأسطر ، واجهنا مشكلة - نشأت تعارضات المعاملات أكثر من المتوقع. كان الأمر سيئًا بشكل خاص مع الاستعلامات التي تعدل العديد من السجلات ، على سبيل المثال ، تحديث قيمة جميع السجلات في جدول. يتم تنفيذ المعاملات التي تم تنفيذها بنجاح على نفس العقدة بالتسلسل على الكتلة بالتوازي وتتلقى معاملة أطول خطأ حالة توقف تام. لن أتأخر ، بعد عدة محاولات لإصلاح هذا على مستوى التطبيق ، تخلينا عن فكرة المعلم المتعدد.
الفروق الدقيقة الأخرى
- قد تكون الكتلة عبدا. عند استخدام هذه الوظيفة ، أوصي بإضافة كافة العقد باستثناء تلك التي هي خيار الرقيق "skip_slave_start = 1". خلاف ذلك ، ستبدأ كل عقدة جديدة النسخ المتماثل من الرئيسي ، مما سيؤدي إما إلى أخطاء النسخ المتماثل أو تلف البيانات على النسخة المتماثلة.
- كما قلت للمتبرع ، لا تستطيع العقدة خدمة العملاء بشكل صحيح. يجب أن نتذكر أنه في مجموعة من ثلاث عقد ، تكون المواقف ممكنة عندما تطير عقدة واحدة ، والثانية هي متبرع وتبقى عقدة واحدة فقط لخدمة العملاء.
الاستنتاجات
بعد الهجرة وبعض الوقت من العملية ، توصلنا إلى الاستنتاجات التالية.
- تعمل مجموعة جاليرا ومستقرة تمامًا (على الأقل طالما لم تكن هناك قطرات غير طبيعية من العقد أو سلوكها غير الطبيعي). من حيث التسامح مع الخطأ ، حصلنا على ما نريده بالضبط.
- إن بيانات بيركونا المتعددة الماجستير هي في المقام الأول تسويق. نعم ، من الممكن استخدام المجموعة في هذا الوضع ، ولكن هذا سيتطلب تغييرًا عميقًا للتطبيق لنموذج الاستخدام هذا.
- لا يوجد نسخ متزامن ، ولكننا نتحكم الآن في الحد الأقصى للفاصل الزمني للعقد (في المعاملات). إلى جانب تحديد الحد الأقصى لحجم المعاملة وهو 50 ميغابايت ، يمكننا التنبؤ بدقة إلى حد كبير بمدة التأخر القصوى للعقد. أصبح من السهل على المطورين كتابة التعليمات البرمجية.
- في المراقبة ، نلاحظ قمم قصيرة المدى في نمو قائمة انتظار النسخ المتماثل. والسبب في شبكتنا 1 جيجابت / ثانية. من الممكن تشغيل مجموعة على مثل هذه الشبكة ، ولكن تظهر مشاكل أثناء رشقات الحمل. نخطط الآن لترقية الشبكة إلى 10 جيجابت / ثانية.
ما مجموعه ثلاث "قائمة أمنيات" تلقينا حوالي واحد ونصف. الشرط الأكثر أهمية هو التسامح مع الخطأ.
ملف تكوين PXC للمهتمين:
my.cnf[mysqld]
#Main
server-id = 1
datadir = /var/lib/mysql
socket = mysql.sock
port = 3302
pid-file = mysql.pid
tmpdir = /tmp
large_pages = 1
skip_slave_start = 1
read_only = 0
secure-file-priv = /tmp/
#Engine
innodb_numa_interleave = 1
innodb_flush_method = O_DIRECT
innodb_flush_log_at_trx_commit = 2
innodb_file_format = Barracuda
join_buffer_size = 1048576
tmp-table-size = 512M
max-heap-table-size = 1G
innodb_file_per_table = 1
sql_mode = "NO_ENGINE_SUBSTITUTION,NO_AUTO_CREATE_USER,ERROR_FOR_DIVISION_BY_ZERO"
default_storage_engine = InnoDB
innodb_autoinc_lock_mode = 2
#Wsrep
wsrep_provider = "/usr/lib64/galera3/libgalera_smm.so"
wsrep_cluster_address = "gcomm://192.168.0.1:4577,192.168.0.2:4577,192.168.0.3:4577"
wsrep_cluster_name = "prod"
wsrep_node_name = node1
wsrep_node_address = "192.168.0.1"
wsrep_sst_method = xtrabackup-v2
wsrep_sst_auth = "USER:PASS"
pxc_strict_mode = ENFORCING
wsrep_slave_threads = 64
wsrep_sst_receive_address = "192.168.0.1:4444"
wsrep_max_ws_size = 50M
wsrep_retry_autocommit = 2
wsrep_provider_options = "gmcast.listen_addr=tcp://192.168.0.1:4577; ist.recv_addr=192.168.0.1:4578; gcache.size=30G; pc.checksum=true; evs.version=1; evs.auto_evict=5; gcs.fc_limit=80; gcs.fc_factor=0.75; gcs.max_packet_size=64500;"
#Binlog
expire-logs-days = 4
relay-log = mysql-relay-bin
log_slave_updates = 1
binlog_format = ROW
binlog_row_image = minimal
log_bin = mysql-bin
log_bin_trust_function_creators = 1
#Replication
slave-skip-errors = OFF
relay_log_info_repository = TABLE
relay_log_recovery = ON
master_info_repository = TABLE
gtid-mode = ON
enforce-gtid-consistency = ON
#Cache
query_cache_size = 0
query_cache_type = 0
thread_cache_size = 512
table-open-cache = 4096
innodb_buffer_pool_size = 72G
innodb_buffer_pool_instances = 36
key_buffer_size = 16M
#Logging
log-error = /var/log/stdout.log
log_error_verbosity = 1
slow_query_log = 0
long_query_time = 10
log_output = FILE
innodb_monitor_enable = "all"
#Timeout
max_allowed_packet = 512M
net_read_timeout = 1200
net_write_timeout = 1200
interactive_timeout = 28800
wait_timeout = 28800
max_connections = 22000
max_connect_errors = 18446744073709551615
slave-net-timeout = 60
#Static Values
ignore_db_dir = "lost+found"
[sst]
rlimit = 80m
compressor = "pigz -3"
decompressor = "pigz -dc"
backup_threads = 8
مصادر وروابط مفيدة
→
صورة Docker الخاصة بنا←
مجموعة بيرسونا إكسترابد 5.7 التوثيق→
رصد حالة الكتلة - توثيق مجموعة جاليرا→
متغيرات حالة Galera - توثيق مجموعة Galera