تمتلئ مساحة العالم المحيط بالأحداث الفردية وسلاسلها - تنعكس هذه الأحداث في وسائل الإعلام ، في حسابات المدونين والأشخاص العاديين على الشبكات الاجتماعية. لا يمكن الحصول على صورة للواقع المحيط ، تدعي درجة معينة من الموضوعية ، إلا إذا جمعنا وجهات نظر مختلفة حول نفس المشكلة. مُصنِّف الأحداث هو الأداة التي "تجمع" المعلومات التي تم جمعها: نسخ وصف الأحداث. بعد ذلك ، وفر الوصول إلى المعلومات حول الأحداث للمستخدمين من خلال أدوات البحث والتوصيات والتمثيلات المرئية للتسلسل الزمني للأحداث.
سنتحدث اليوم عن نظامنا ، وبشكل أكثر دقة حول جوهر برامجه ، تحت الاسم الرمزي "Varya" - تكريمًا للمطور الرئيسي.
لا يمكننا بعد ذكر اسم الشركة الناشئة ، بناءً على طلب إدارة Habrahabr ، فقد قدمنا الآن طلبًا لتعيين حالة بدء التشغيل. ومع ذلك ، يمكننا أن نخبرك عن الوظيفة وأفكارنا الآن. يضمن نظامنا مدى ملاءمة معلومات الحدث للمستخدم وإدارة البيانات المختصة - في النظام ، يحدد كل مستخدم نفسه ما يجب مشاهدته وقراءته ، والتحكم في البحث والتوصيات.
مشروعنا هو شركة ناشئة مع فريق من 8 أشخاص ذوي كفاءات في تصميم الأنظمة المعقدة تقنيًا وخوارزميًا والبرمجة والتسويق والإدارة.
يعمل الفريق معًا في كل يوم معًا على المشروع - وقد تم بالفعل تنفيذ خوارزميات لتصنيف المعلومات والبحث عنها وتقديمها. لا يزال تطبيق الخوارزميات المتعلقة بالتوصيات للمستخدم متقدمًا: بناءً على علاقة الأحداث والأشخاص وتحليل نشاط المستخدم واهتماماته.
ما المهام التي نحلها ولماذا نتحدث عنها؟ نحن نساعد الناس في الحصول على معلومات تفصيلية حول الأحداث على أي نطاق ، بغض النظر عن مكان وزمان حدوثها.
يوفر المشروع للمستخدمين نظامًا أساسيًا لمناقشة الأحداث في دائرة من الأشخاص ذوي التفكير المماثل ، ويسمح لك بمشاركة تعليق أو نسختك الخاصة مما حدث. تم إنشاء منصة وسائل الإعلام الاجتماعية لأولئك الذين يرغبون في معرفة "فوق المتوسط" ولديهم رأي شخصي حول الأحداث الرئيسية في الماضي والحاضر والمستقبل.
يجد المستخدمون أنفسهم محتوى مفيدًا وينشئونه في مساحة الوسائط ويراقبون موثوقيته. نحتفظ بذكرى أحداث حياتهم.
الآن المشروع في مرحلة MVP ، نحن نختبر فرضيات حول وظائف وعمل المصنف من أجل تحديد الاتجاه الصحيح لمزيد من التطوير. في هذه المقالة سوف نتحدث عن التقنيات التي نحل بها مهامنا ونتشارك أفضل ممارساتنا.
يتم حل مهمة معالجة الكلمات الآلية بواسطة محركات البحث: Yandex ، Google ، Bing ، إلخ. يمكن أن يبدو النظام المثالي للعمل مع تدفق المعلومات وعزل الأحداث فيها كما يلي.
تم إنشاء بنية تحتية مشابهة لـ Yandex و Google للنظام ، ويتم فحص الإنترنت بالكامل في الوقت الفعلي للحصول على التحديثات ، ثم يتم تخصيص نواة الأحداث في دفق المعلومات ، والتي يتم تكوين تكتلات إصداراتها والمحتوى ذي الصلة حولها. يعتمد تنفيذ البرنامج للخدمة على شبكة عصبية عميقة التعلم و / أو حل قائم على مكتبة Yandex - CatBoost.
رائع ومع ذلك ، ليس لدينا حتى الآن مثل هذا الحجم من البيانات ، ولا توجد موارد حوسبة مقابلة للاستيعاب.
يعد التصنيف حسب الموضوع مهمة شائعة ، وهناك العديد من الخوارزميات لحلها: مصنِّفات Bayes الساذجة ، ووضع Dirichlet الكامن ، وتعزيز أشجار القرار والشبكات العصبية. كما هو الحال ، في جميع مشاكل التعلم الآلي ، عند استخدام الخوارزميات الموصوفة ، تنشأ مشكلتان:
أولا ، أين تحصل على الكثير من البيانات؟
ثانيًا ، كيف نضعها بثمن غاضب؟
ما النهج الذي اخترناه لنظام قائم على الأحداث؟
منتجنا يعمل مع الأحداث. الأحداث تختلف إلى حد ما عن المقالات العادية.
للتغلب على "البداية الباردة" ، قررنا استخدام مشروعي WikiMedia: Wikipedia و Wikinews. يمكن لمقالة ويكيبيديا أن تصف العديد من الأحداث (على سبيل المثال ، تاريخ تطور Sun Microsystems ، سيرة Mayakovsky أو مسار الحرب الوطنية العظمى).
المصادر الأخرى لمعلومات الحدث هي قنوات RSS. تحدث الأخبار بطرق مختلفة: تحتوي المقالات التحليلية الكبيرة على العديد من الأحداث ، مثل نصوص ويكيبيديا ، ورسائل إعلامية قصيرة من مصادر مختلفة تمثل نفس الحدث.
وهكذا ، فإن المقالة والأحداث تشكل علاقات كثير إلى كثير. ولكن في مرحلة MVP ، نفترض أن مقالة واحدة هي حدث واحد.
بالنظر إلى واجهة Google أو Yandex ، قد تعتقد أن محركات البحث تبحث فقط عن الكلمات الرئيسية. هذا فقط لتجار التجزئة على الإنترنت بسيطة للغاية. معظم محركات البحث متعددة المعايير ، ومحرك مشروعنا ليس استثناءً. علاوة على ذلك ، يتم عرض كل المعلمات التي تم أخذها في الاعتبار أثناء البحث في واجهة المستخدم. يحتوي مشروعنا على قائمة من المعلمات التي يحددها المستخدم ، مثل:
المواضيع والكلمات الرئيسية -
"ماذا؟" ؛ الموقع -
"أين؟" ؛ التاريخ -
"متى؟" ؛
يعرف أولئك الذين يكتبون محركات البحث أن الكلمات الرئيسية وحدها تسبب الكثير من المشاكل. حسنًا ، بقية الخيارات ليست بهذه البساطة.
موضوع الحدث شيء صعب للغاية. تم تصميم دماغ الإنسان بحيث يحب تصنيف كل شيء ، ويختلف العالم الحقيقي بشدة مع هذا. تريد المقالات الواردة تشكيل مجموعات الموضوعات الخاصة بها ، وهي ليست على الإطلاق تلك التي نوزعها نحن والمستخدمين المتحمسين لها.
لدينا الآن 15 موضوعًا رئيسيًا للأحداث ، وقد تم تعديل هذه القائمة عدة مرات ، وستنمو على الأقل.
يتم ترتيب المواقع والتواريخ بشكل رسمي أكثر قليلاً ، ولكن هنا توجد مطبات.
لذا ، لدينا مجموعة من المعايير الرسمية والبيانات الأولية التي نحتاج إلى تعيينها لهذه المعايير. وإليك كيف نقوم بذلك.
العنكبوت
تتمثل مهمة العنكبوت في طي المقالات الواردة بحيث يمكن البحث عنها بسرعة. للقيام بذلك ، يجب أن يكون العنكبوت قادرًا على نسب الموضوع والموقع والتاريخ إلى المقالات ، بالإضافة إلى بعض المعلمات الأخرى اللازمة للترتيب. يتلقى عنكبوت الإدخال نموذجًا نصيًا للمقال الذي أنشأه الزاحف. نموذج النص هو قائمة بأجزاء المقالة والنصوص المقابلة لها. على سبيل المثال ، تحتوي كل مقالة تقريبًا على عنوان رئيسي ونص أساسي. في الواقع ، لا تزال لديها الفقرة الأولى ، ومجموعة من الفئات التي يشير إليها هذا النص إلى مصدرها ، وقائمة بحقول مربع المعلومات (لويكيبيديا والمصادر التي تحتوي على علامات البيانات الوصفية). لا يزال هناك تاريخ نشر. بالنسبة للترتيب في محرك البحث ، سيكون من المهم بالنسبة لنا معرفة ما إذا كان ، على سبيل المثال ، يوجد تاريخ في الرأس أو في مكان ما في نهاية النص. يتم استخدام نموذج نصي لإنشاء نموذج موضوع ونموذج موقع ونموذج تاريخ ، ثم تتم إضافة النتيجة إلى الفهرس. يمكن كتابة مقالة منفصلة حول كل من هذه النماذج ، لذلك هنا سوف نعرض بإيجاز النهج.
الموضوع
يعد تحديد موضوع المستندات مهمة شائعة. يمكن أن يُنسب الموضوعات يدويًا بواسطة مؤلف المستند ، أو يمكن تحديدها تلقائيًا. بالطبع ، لدينا موضوعات نسبتها مصادر الأخبار وويكيبيديا إلى مستنداتنا ، لكن هذه الموضوعات ليست عن الأحداث. هل تجد غالبًا موضوع "الأعياد" في خلاصات الأخبار؟ بدلاً من ذلك ، سوف تلتقي بموضوع "المجتمع". كان لدينا هذا أيضًا في إحدى الإصدارات الأولى. لم نتمكن من تحديد ما يجب أن يتعلق بها ، واضطررنا إلى إزالته. بالإضافة إلى ذلك ، تحتوي جميع المصادر على مجموعة من المواضيع الخاصة بها.
نريد إدارة قائمة الموضوعات التي يتم عرضها لمستخدمينا في الواجهة ، لذا فإن مهمة تحديد موضوع المستند بالنسبة لنا هي مهمة التصنيف الغامض. تتطلب مهمة التصنيف أمثلة مصنفة ، أي قائمة بالمستندات التي تم بالفعل إسناد المواضيع التي نرغب بها. تشبه قائمتنا جميع قوائم المواضيع المتشابهة ، ولكنها لا تتطابق معها ، لذلك لم يكن لدينا عينة مسماة. يمكنك أيضًا الحصول عليها يدويًا أو تلقائيًا ، ولكن إذا تغيرت قائمة الموضوعات (وستتغير!) ، فلن يكون خيارًا يدويًا.
إذا لم يكن لديك عينة مصنفة ، يمكنك استخدام موضع Dirichlet الكامن وخوارزميات النمذجة المواضيعية الأخرى ، ومع ذلك ، فإن مجموعة تلك التي تحصل عليها ستكون هي التي تحولت ، وليس تلك التي تريدها.
هنا يجب أن نذكر نقطة أخرى: مقالاتنا تأتي من مصادر مختلفة. يتم بناء جميع النماذج المواضيعية بطريقة أو بأخرى على المفردات المستخدمة. بالنسبة للأخبار وويكيبيديا ، إنه مختلف ، ومختلف حتى الترددات العالية المنخولة.
وهكذا ، واجهنا مهمتين:
1. توصل إلى طريقة لوضع مستنداتنا بسرعة في وضع شبه تلقائي.
2. بناء نموذج موسع لمواضيعنا بناء على هذه الوثائق.
لحلها ، أنشأنا خوارزمية مختلطة تحتوي على المراحل الآلية واليدوية الموضحة في الشكل.
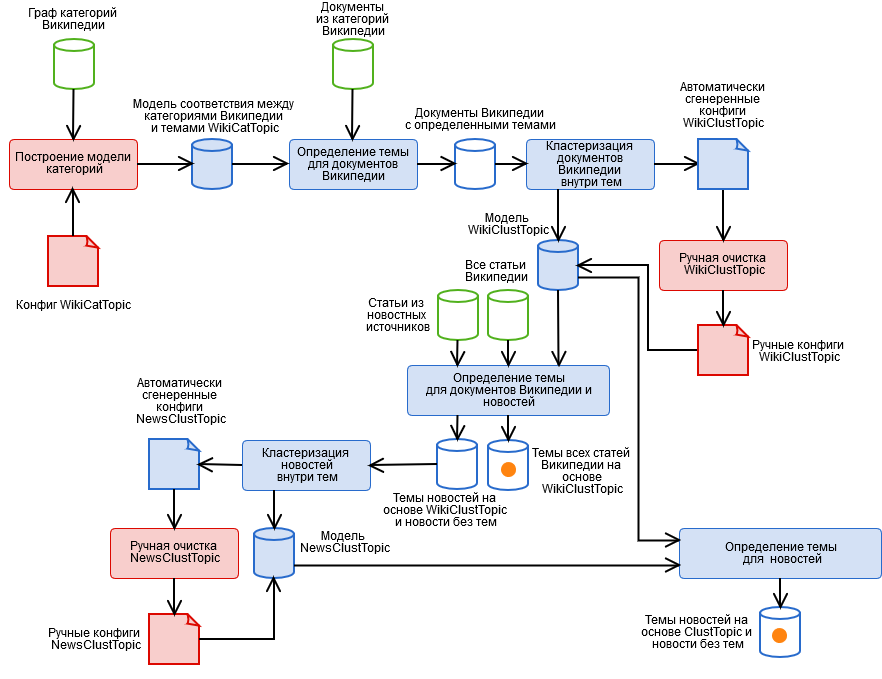
- ترميز فئات Wikipedia اليدوي والحصول على نموذج موضوع تصنيف WikiCatTopic. في هذه المرحلة ، تم إنشاء تكوين يقوم بتعيين مخطط فرعي لفئات WT في ويكيبيديا لكل موضوع لدينا T. ويكيبيديا هي علم الوجود الزائف. هذا يعني أنه إذا كان هناك شيء يندرج في فئة "العلوم" ، فقد لا يتعلق الأمر بالعلوم على الإطلاق ، على سبيل المثال ، من الفئة الفرعية غير المؤذية "تقنيات المعلومات" ، يمكنك في الواقع أن تأتي إلى أي مقالة ويكيبيديا. هناك حاجة إلى مقال منفصل حول كيفية التعايش مع هذا.
- اكتشف تلقائيًا مواضيع مستندات Wikipedia استنادًا إلى WikiCatTopic. يتم تعيين المستند إلى الموضوع T إذا كان يندرج ضمن إحدى فئات الرسم البياني CT. لاحظ أن هذه الطريقة تنطبق فقط على مقالات ويكيبيديا. لتعميم تعريف الموضوعات على النص التعسفي ، كان من الممكن بناء مجموعة من الكلمات لكل موضوع ، والنظر في مسافة جيب التمام للموضوع (وحاولنا ، لا شيء جيد) ، ولكن هنا يجب مراعاة ثلاثة أشياء.
- تحتوي هذه المواضيع على مقالات متنوعة للغاية ، لذلك فإن صورة الموضوع في مساحة الكلمة لن تكون متماسكة ، مما يعني أن "ثقة" مثل هذا النموذج في تحديد الموضوع منخفضة جدًا (بعد كل شيء ، تشبه المقالة مجموعة صغيرة من المقالات ، ولكن ليس للبقية).
- يختلف النص التعسفي ، بشكل أساسي الأخبار ، في تكوينه المعجمية عن ويكيبيديا ؛ وهذا أيضًا لا يضيف نموذجًا لـ "اليقين". بالإضافة إلى ذلك ، لا يمكن بناء بعض المواضيع على ويكيبيديا.
- المرحلة 1 هي عمل شاق للغاية ، والجميع كسالى للغاية للقيام بذلك.
- تجميع المستندات ضمن مواضيع بناءً على نتائج الفقرة 2 باستخدام طريقة k-الوسائل والحصول على نموذج عنقود لموضوع WikiClustTopic. خطوة بسيطة إلى حد ما ، والتي سمحت لنا بحل مشكلتين إلى حد كبير من الفقرة الثالثة. بالنسبة للمجموعات ، نقوم ببناء مجموعة من الكلمات ، ويتم تحديد الانتماء إلى موضوع على أنه أقصى مسافات جيب التمام لمجموعاتها. تم وصف النموذج في ملفات التكوين الخاصة بنا للمراسلات بين المجموعات ووثائق ويكيبيديا.
- التنظيف اليدوي لنموذج WikiClustTopic ، تمكين - تعطيل - نقل المجموعات. هنا عدنا أيضًا إلى المرحلة 1 ، عندما تم اكتشاف مجموعات غير صحيحة تمامًا.
- اكتشف تلقائيًا مواضيع WikiClustTopic لمستندات وأخبار ويكيبيديا.
- تجميع الأخبار ضمن مواضيع استنادًا إلى نتائج الفقرة 5 باستخدام طريقة k-الوسائل ، بالإضافة إلى الأخبار التي لم تتلق المواضيع ، والحصول على نموذج عنقود لموضوع NewsClustTopic. الآن لدينا نموذج موضوعي يأخذ في الاعتبار تفاصيل الأخبار (بالإضافة إلى معلومات لا تقدر بثمن حول جودة عمل الزاحف).
- التنظيف اليدوي لنموذج NewsClustTopic.
- إعادة رسم خرائط الموضوعات بناءً على النموذج المتكامل ClustTopic = WikiClustTopic + NewsClustTopic. بناءً على هذا النموذج ، يتم تحديد مواضيع المستندات الجديدة.
المواقع
التحديد التلقائي للموقع هو حالة خاصة لمهمة البحث عن الكيانات المسماة. ميزات المواقع هي كما يلي:
- جميع قوائم المواقع مختلفة ولا تتناسب معًا بشكل جيد. قمنا ببناء منطقتنا المختلطة ، والتي لا تأخذ في الاعتبار ليس فقط التسلسل الهرمي (تشمل روسيا منطقة نوفوسيبيرسك) ، ولكن أيضًا تغييرات الاسم التاريخية (على سبيل المثال ، أصبح RSFSR روسيا) استنادًا إلى: Geonames و Wikidata ومصادر أخرى مفتوحة. ومع ذلك ، لا يزال يتعين علينا كتابة محول علامة جغرافية باستخدام خرائط Google :)
- تتكون بعض المواقع من عدة كلمات ، على سبيل المثال ، نيجني نوفغورود ، ويجب أن تكون قادرًا على جمعها.
- المواقع مشابهة لكلمات أخرى ، وخاصة أسماء أولئك الذين تم تسميتهم على شرفهم: Kirov ، Zhukov ، Vladimir. هذا هو التماثل. لعلاج هذا ، قمنا بجمع إحصائيات حول مقالات ويكيبيديا التي تصف المستوطنات ، والتي يتم فيها العثور على سياقات أسماء المواقع ، وحاولنا أيضًا بناء قائمة بهذه الأسماء المختصرة باستخدام قواميس Open Corpora.
- لم تجهد البشرية الخيال كثيرًا ، وتسمى العديد من الأماكن نفسها. المثال المفضل لدينا: Karasuk في كازاخستان وروسيا ، بالقرب من نوفوسيبيرسك. هذا هو التماثل في فئة المواقع. نقوم بحلها ، مع الأخذ في الاعتبار المواقع الأخرى التي تم العثور عليها مع هذا الموقع ، وما إذا كانت الوالد أو الطفل لأحد الأسماء المختصرة. هذا الاستدلال ليس عالميًا ، ولكنه يعمل بشكل جيد.
التواريخ
التواريخ - تجسيد الشكلية مقارنة بالموضوعات والمواقع. لقد صنعنا محللًا قابلًا للتوسيع لهم في التعبيرات العادية ، ويمكننا تحليل ليس فقط كل يوم في الشهر ، ولكن أيضًا جميع أنواع الأشياء الأكثر إثارة للاهتمام ، مثل "نهاية شتاء 1941" و "في التسعينات من القرن التاسع عشر" و "الشهر الماضي "، مع مراعاة عصر الوثيقة وتاريخها الأساسي ، بالإضافة إلى محاولة استعادة السنة المفقودة. حول التواريخ تحتاج إلى معرفة أنها ليست كلها جيدة. على سبيل المثال ، في نهاية مقال حول أي معركة في الحرب العالمية الثانية ، قد يكون هناك افتتاح للنصب التذكاري بعد أربعين عامًا ، من أجل التعامل مع مثل هذه الحالات ، تحتاج إلى قطع المقالة إلى أحداث ، لكننا لا نقوم بذلك بعد. لذلك نحن نعتبر التواريخ الأكثر أهمية فقط: من العنوان والفقرات الأولى.
محرك البحث
محرك البحث عبارة عن أداة تقوم أولاً بالبحث عن المستندات عند الطلب ، وثانيًا ، ترتيبها بترتيب تنازلي ذي صلة بالاستعلام ، أي في تقليل الملاءمة. لحساب الصلة ، نستخدم العديد من المعلمات ، أكثر بكثير من مجرد التافه:
الدرجة التي تنتمي إليها الوثيقة للموضوع.
درجة ملكية وثيقة الموقع (عدد المرات وفي أي أجزاء من الوثيقة تم العثور على الموقع المحدد).
الدرجة التي يتطابق فيها المستند مع التاريخ (مع مراعاة عدد الأيام عند تقاطع الفترة الزمنية من الطلب وتواريخ المستند ، بالإضافة إلى عدد الأيام عند التقاطع ناقص الاتحاد).
طول الوثيقة. يجب أن تكون المقالات الطويلة أعلى.
حضور الصورة. الجميع يحب الصور ، يجب أن يكون هناك المزيد!
نوع مقالة ويكيبيديا. يمكننا فصل المقالات مع وصف الأحداث ، ويجب أن "تنبثق" في العينة.
مصدر المقال. يجب أن تكون الأخبار والمقالات المخصصة أعلى من ويكيبيديا.
كمحرك بحث ، نستخدم Apache Lucene.
الزاحف
مهمة الزاحف هي جمع المقالات للعنكبوت. في حالتنا ، هنا نقوم أيضًا بتضمين التنظيف الأساسي للنص ، وبناء نموذج نصي للمستند. الزاحف يستحق مقالة منفصلة.
ملاحظة نرحب بأي ملاحظات ، نحن ندعوك لاختبار مشروعنا - لتلقي رابط ، والكتابة في الرسائل الشخصية (لا يمكننا النشر هنا). اترك تعليقاتك تحت المقال ، أو إذا وصلت إلى خدمتنا - هناك مباشرة ، من خلال نموذج الملاحظات.