عندما يبحث الأشخاص في الإنترنت عن صورة أو مقطع فيديو ، غالبًا ما يضيفون عبارة "بجودة عالية". عادةً ما تشير الجودة إلى الدقة - يريد المستخدمون أن تكون الصورة كبيرة وفي نفس الوقت تبدو جيدة على شاشة الكمبيوتر الحديث أو الهاتف الذكي أو التلفزيون. ولكن ماذا لو لم يكن المصدر بجودة عالية موجودًا؟
اليوم سنخبر قراء هبر عن كيف يمكننا ، بمساعدة الشبكات العصبية ، زيادة دقة الفيديو في الوقت الفعلي. سوف تتعلم أيضًا كيف يختلف النهج النظري لحل هذه المشكلة عن النهج العملي. إذا لم تكن مهتمًا بالتفاصيل الفنية ، فيمكنك التمرير بأمان عبر المنشور - في النهاية ستجد أمثلة على عملنا.

هناك الكثير من محتوى الفيديو على الإنترنت بجودة ودقة منخفضة. يمكن أن تكون الأفلام التي تم تصويرها منذ عقود ، أو بث القنوات التلفزيونية ، والتي لأسباب مختلفة ليست في أفضل جودة. عندما يقوم المستخدمون بتمديد مثل هذا الفيديو إلى ملء الشاشة ، تصبح الصورة غائمة وضبابية. سيكون الحل المثالي للأفلام القديمة هو العثور على الفيلم الأصلي ومسحه ضوئيًا بمعدات حديثة واستعادته يدويًا ، ولكن هذا ليس ممكنًا دائمًا. لا تزال عمليات البث أكثر تعقيدًا - يجب معالجتها بشكل مباشر. في هذا الصدد ، فإن الخيار الأكثر قبولًا بالنسبة لنا للعمل هو زيادة الدقة وتنظيف القطع الأثرية باستخدام تقنية رؤية الكمبيوتر.
في الصناعة ، تسمى مهمة زيادة الصور ومقاطع الفيديو دون فقدان الجودة مصطلح الدقة الفائقة. لقد تم بالفعل كتابة العديد من المقالات حول هذا الموضوع ، ولكن تبين أن حقائق تطبيق "القتال" أكثر تعقيدًا وإثارة للاهتمام. باختصار حول المشاكل الرئيسية التي كان علينا حلها في تقنية DeepHD الخاصة بنا:
- يجب أن تكون قادرًا على استعادة التفاصيل التي لم تكن موجودة في الفيديو الأصلي نظرًا لانخفاض دقتها وجودتها ، "لإنهائها".
- تعمل حلول الدقة الفائقة على استعادة التفاصيل ، ولكنها تجعلها واضحة ومفصلة ليس فقط الكائنات الموجودة في الفيديو ، ولكن أيضًا التحف الفنية للضغط ، مما يؤدي إلى كره الجمهور.
- هناك مشكلة في جمع عينة التدريب - مطلوب عدد كبير من الأزواج التي يوجد فيها نفس الفيديو بجودة منخفضة وجودة عالية وعالية. في الواقع ، لا يوجد عادةً زوج جودة للمحتوى الضعيف.
- يجب أن يعمل الحل في الوقت الحقيقي.
اختيار التكنولوجيا
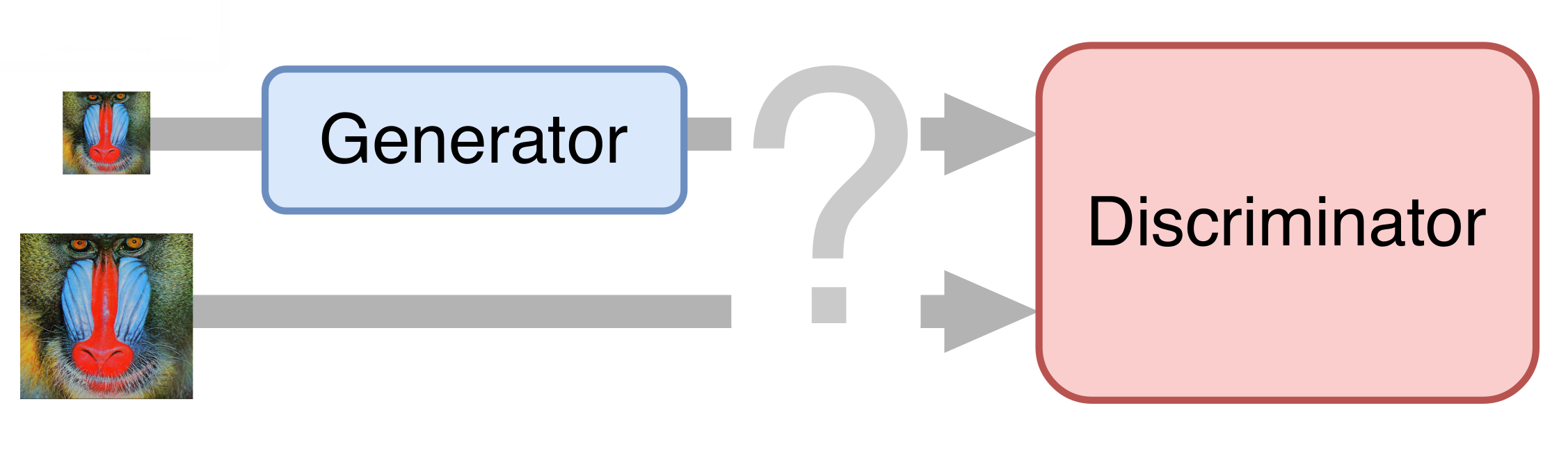
في السنوات الأخيرة ، أدى استخدام الشبكات العصبية إلى نجاح كبير في حل جميع مهام رؤية الكمبيوتر تقريبًا ، ومهمة الدقة الفائقة ليست استثناء. لقد وجدنا الحلول الواعدة بناءً على GAN (شبكات الخصومة التوليدية والشبكات المنافسة التوليدية). إنها تسمح لك بالحصول على صور واقعية عالية الوضوح ، تكملها بالتفاصيل المفقودة ، على سبيل المثال ، رسم الشعر والرموش على صور الأشخاص.

في أبسط الحالات ، تتكون الشبكة العصبية من جزأين. الجزء الأول - المولد - يأخذ صورة إدخال ويعيد تكبير مضاعف. الجزء الثاني - المميّز - يتلقى الصورة المولدة و "الحقيقية" كمدخل ، ويحاول تمييزها عن بعضها البعض.
إعداد مجموعة التدريب
للتدريب ، قمنا بجمع عشرات المقاطع بجودة UltraHD. أولاً ، قمنا بتقليلها إلى دقة 1080 بكسل ، وبالتالي الحصول على أمثلة مرجعية. ثم قمنا بخفض مقاطع الفيديو هذه إلى النصف ، وضغطها بمعدل بت مختلف على طول الطريق للحصول على شيء مشابه لمقطع فيديو حقيقي بجودة منخفضة. قسمنا مقاطع الفيديو الناتجة إلى إطارات واستخدمناها بطريقة لتدريب الشبكة العصبية.
الحجب
بالطبع ، أردنا الحصول على حل شامل: تدريب الشبكة العصبية على إنشاء فيديو عالي الجودة وجودة من الأصل. ومع ذلك ، تبين أن GANs متقلبة للغاية وحاولت باستمرار تحسين التحف ، بدلاً من إزالتها. لذلك ، كان عليّ تقسيم العملية إلى عدة مراحل. الأول هو قمع التحف من ضغط الفيديو ، والمعروف أيضًا باسم deblocking.
مثال على إحدى طرق الإصدار:

في هذه المرحلة ، قمنا بتقليل الانحراف المعياري بين الإطار المولد والإطار الأصلي. وبالتالي ، على الرغم من أننا قمنا بزيادة دقة الصورة ، إلا أننا لم نحصل على زيادة حقيقية في الدقة بسبب الانحدار إلى المتوسط: الشبكة العصبية ، التي لا تعرف فيها وحدات البكسل المحددة التي يمر بها حد معين في الصورة ، اضطرت إلى متوسط عدة خيارات ، والحصول على نتيجة ضبابية. الشيء الرئيسي الذي حققناه في هذه المرحلة هو القضاء على القطع الأثرية لضغط الفيديو ، لذا فإن الشبكة التوليدية في المرحلة التالية مطلوبة فقط لزيادة الوضوح وإضافة التفاصيل الصغيرة المفقودة ، والقوام. بعد المئات من التجارب ، اخترنا البنية المثلى من حيث الأداء والجودة ، والتي تذكرنا بشكل غامض بهندسة
DRCN :
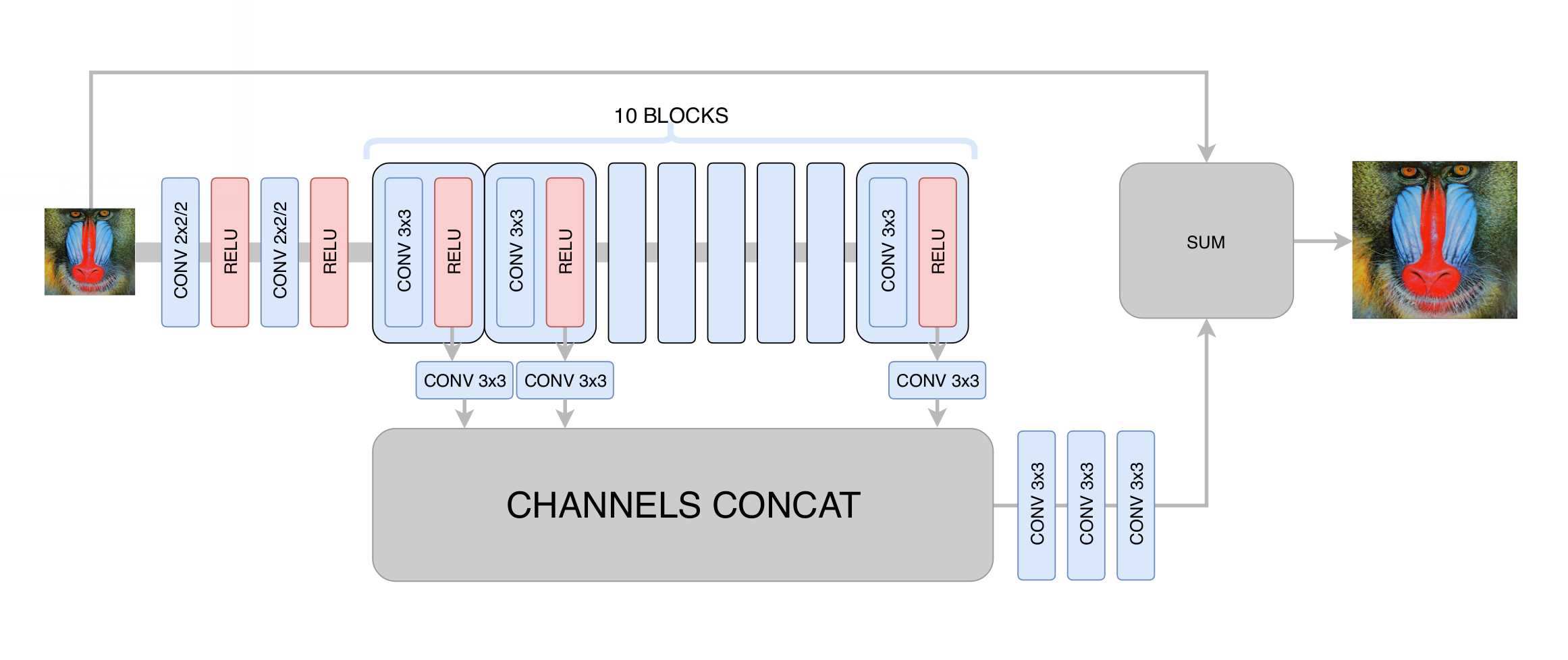
الفكرة الرئيسية لمثل هذه العمارة هي الرغبة في الحصول على العمارة الأكثر عمقًا ، في حين لا تواجه مشاكل مع التقارب في تدريبها. من ناحية ، تستخرج كل طبقة تلافيفية لاحقة المزيد والمزيد من الميزات المعقدة للصورة المدخلة ، مما يسمح لك بتحديد نوع الكائن عند نقطة معينة في الصورة واستعادة الأجزاء المعقدة والمتضررة بشدة. من ناحية أخرى ، تبقى المسافة في الرسم البياني للشبكة العصبية من أي من طبقاتها إلى المخرج صغيرة ، مما يحسن تقارب الشبكة العصبية ويجعل من الممكن استخدام عدد كبير من الطبقات.
التدريب الشبكي التوليدي
أخذنا بنية
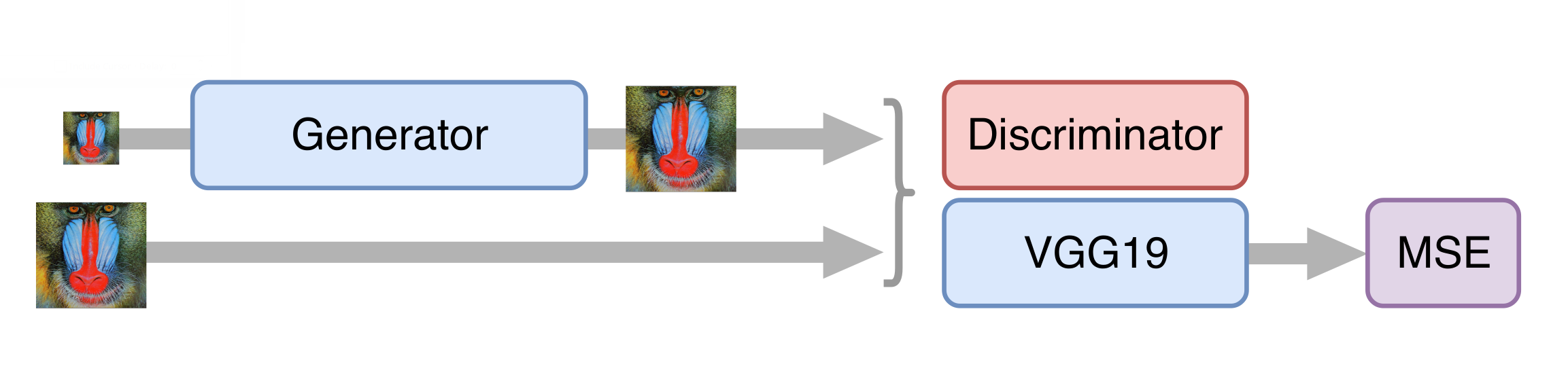
SRGAN كأساس للشبكة العصبية لزيادة الدقة. قبل تدريب شبكة تنافسية ، تحتاج إلى تدريب مسبق للمولد - قم بتدريبه بنفس الطريقة كما في مرحلة إلغاء الحظر. خلاف ذلك ، في بداية التدريب ، سيعيد المولد الضجيج فقط ، وسيبدأ المميّز على الفور في "الفوز" - سيتعلم بسهولة تمييز الضوضاء عن الإطارات الحقيقية ، ولن يعمل أي تدريب.

ثم ندرب GAN ، ولكن هناك بعض الفروق الدقيقة. من المهم بالنسبة لنا أن المولد لا يخلق إطارات واقعية فحسب ، بل يخزن أيضًا المعلومات المتاحة عليها. للقيام بذلك ، أضفنا وظيفة فقدان المحتوى إلى بنية GAN الكلاسيكية. وهي تمثل عدة طبقات من الشبكة العصبية VGG19 المدربة على مجموعة بيانات ImageNet القياسية. تقوم هذه الطبقات بتحويل الصورة إلى خريطة معالم تحتوي على معلومات حول محتويات الصورة. تقلل وظيفة الخسارة المسافة بين هذه البطاقات التي تم الحصول عليها من الإطارات المولدة والأصلية. أيضًا ، فإن وجود وظيفة الخسارة هذه يجعل من الممكن عدم إفساد المولد في الخطوات الأولى من التدريب ، عندما لا يكون المتدرب قد تم تدريبه بعد ويوفر معلومات غير مفيدة.
تسريع الشبكة العصبية
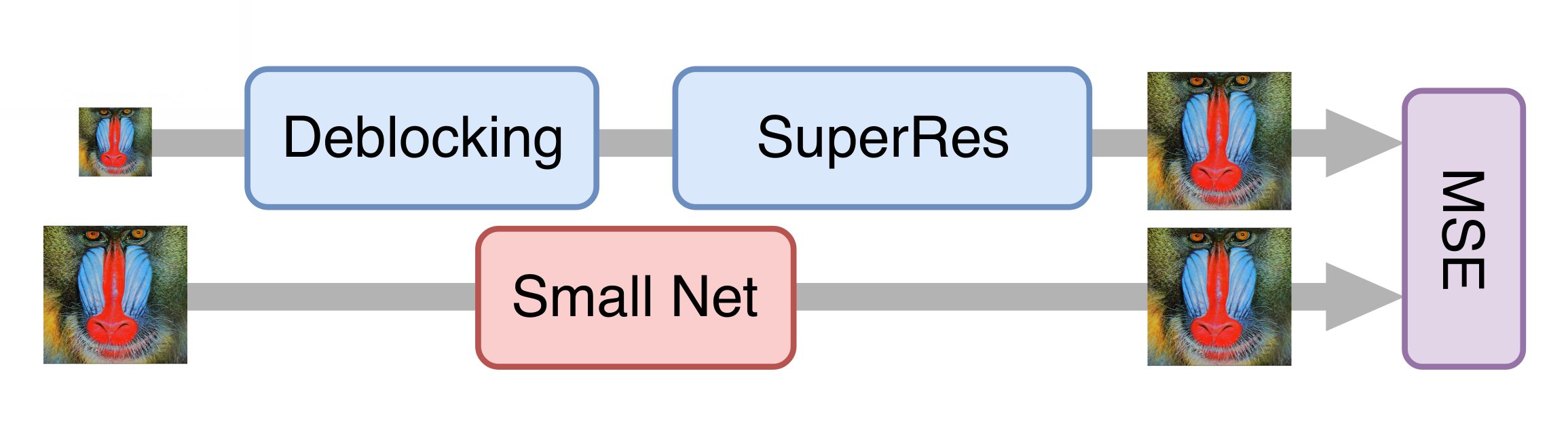
كل شيء سار على ما يرام ، وبعد سلسلة من التجارب ، حصلنا على نموذج جيد يمكن تطبيقه بالفعل على الأفلام القديمة. ومع ذلك ، كان لا يزال بطيئًا جدًا في معالجة بث الفيديو. اتضح أنه من المستحيل ببساطة تقليل المولد دون خسارة كبيرة في جودة النموذج النهائي. ثم جاء نهج تقطير المعرفة لمساعدتنا. تتضمن هذه الطريقة تدريب نموذج أخف بحيث يكرر نتائج نموذج أثقل. أخذنا الكثير من مقاطع الفيديو الحقيقية بجودة منخفضة ، وعالجناها باستخدام الشبكة العصبية التوليدية التي تم الحصول عليها في الخطوة السابقة ، وقمنا بتدريب الشبكة الأخف للحصول على نفس النتيجة من نفس الإطارات. نظرًا لهذه التقنية ، حصلنا على شبكة ليست أقل جودة من تلك الأصلية ، ولكن أسرع بعشر مرات منها: لمعالجة قناة تلفزيونية واحدة بدقة 576 بكسل ، يلزم وجود بطاقة NVIDIA Tesla V100 واحدة.
تقييم جودة الحلول
ربما تكون اللحظة الأكثر صعوبة عند العمل مع الشبكات التوليدية هي تقييم جودة النماذج الناتجة. لا توجد وظيفة خطأ واضحة ، على سبيل المثال ، عند حل مشكلة التصنيف. بدلاً من ذلك ، نحن نعرف فقط دقة المتميز ، والتي لا تعكس جودة المولد الذي يهمنا (يمكن للقارئ الذي كان على دراية جيدة بهذا المجال أن يقترح استخدام
مقياس Wasserstein ، ولكن للأسف ، أعطى نتيجة أسوأ بشكل ملحوظ).
ساعدنا الناس في حل هذه المشكلة. أظهرنا لمستخدمي أزواج خدمة
Yandex.Tolok من الصور ، أحدها كان المصدر والأخرى تمت معالجتها بواسطة شبكة عصبية ، أو تمت معالجة كليهما بواسطة إصدارات مختلفة من حلولنا. مقابل رسوم ، اختار المستخدمون فيديو أفضل من زوج ، لذلك حصلنا على مقارنة ذات دلالة إحصائية من الإصدارات حتى مع التغييرات التي يصعب رؤيتها بالعين. تفوز نماذجنا النهائية في أكثر من 70٪ من الحالات ، وهو عدد كبير جدًا ، نظرًا لأن المستخدمين يقضون بضع ثوانٍ فقط في تقييم بضع مقاطع فيديو.
كانت النتيجة المثيرة للاهتمام أيضًا حقيقة أن الفيديو بدقة 576 بكسل ، التي زادت بتقنية DeepHD إلى 720 بكسل ، يتفوق على نفس الفيديو الأصلي مع دقة 720 بكسل في 60٪ من الحالات - أي لا تؤدي المعالجة إلى زيادة دقة الفيديو فحسب ، بل تعمل أيضًا على تحسين إدراكه البصري.
أمثلة
في الربيع ، اختبرنا تقنية DeepHD على العديد من الأفلام القديمة التي يمكن مشاهدتها في KinoPoisk: "
قوس قزح " لمارك دونسكوي (1943) ، "
رافعات تحلق " بقلم ميخائيل كالاتوزوف (1957) ، "
يا عزيزي " للمخرج جوزيف خيفتس (1958) ، "
مصير رجل " سيرجي بوندارتشوك (1959) ، "
طفولة إيفان " بقلم أندريه تاركوفسكي (1962) ، "
والد الجندي " ريزو شخيدزه (1964) و "
تانجو طفولتنا" لألبرت ميرتشيان (1985).

يكون الفرق بين الإصدارات قبل وبعد المعالجة ملحوظًا بشكل خاص إذا نظرت في التفاصيل: دراسة تعابير الوجه للأبطال عن قرب ، والنظر في نسيج الملابس أو نمط النسيج. كان من الممكن تعويض بعض أوجه القصور في الرقمنة: على سبيل المثال ، لإزالة التعرض المفرط على الوجوه أو لجعل الأشياء الموضوعة في الظل أكثر وضوحًا.
في وقت لاحق ، بدأ استخدام تقنية DeepHD لتحسين جودة البث
لبعض القنوات في خدمة Yandex.Air. التعرف على هذا المحتوى سهل من خلال علامة
dHD .
الآن
على ياندكس بجودة محسنة ، يمكنك مشاهدة "ملكة الثلج" ، و "موسيقيو مدينة بريمن" ، و "جولدن أنتيلوب" وغيرها من الرسوم المتحركة الشهيرة في استوديو أفلام سويوز مولتفيلم. يمكن رؤية بعض الأمثلة في الديناميكيات في الفيديو:
بالنسبة للمشاهدين المتطلبين ، سيكون الفرق ملحوظًا بشكل خاص: أصبحت الصورة أكثر حدة ، وأوراق الشجر ، ورقاقات الثلج ، والنجوم في سماء الليل فوق الغابة وتفاصيل صغيرة أخرى أكثر وضوحًا.
المزيد أكثر.
روابط مفيدة
Jiwon Kim ، Jung Kwon Lee ، Kyoung Mu Lee الشبكة التلافيفية العودية العميقة للصورة فائقة الدقة [
arXiv: 1511.04491 ].
كريستيان ليديج وآخرون. الدقة الواقعية لصورة واحدة للصورة الواقعية باستخدام شبكة
الخصومة التوليدية [
arXiv: 1609.04802 ].
مهدي إس إم سجادي ، برنهارد سكولكوف ، مايكل هيرش EnhanceNet: صورة واحدة فائقة الدقة من خلال تركيب النسيج الآلي [
arXiv: 1612.07919 ].