لطالما أراد الناس تعليم الآلة فهم شخص ما. ومع ذلك ، الآن فقط نحن قريبون قليلاً من مؤامرات أفلام الخيال العلمي: يمكننا أن نطلب من أليس خفض الصوت ، مساعد Google - طلب سيارة أجرة أو سيري - ضبط المنبه. هناك حاجة إلى تقنيات معالجة اللغة في التطورات المتعلقة ببناء الذكاء الاصطناعي: في محركات البحث ، لاستخراج الحقائق ، وتقييم نغمة النص ، والترجمة الآلية والحوار.
سنتحدث عن المجالين الأخيرين: لديهم تاريخ غني وكان لهم تأثير كبير على معالجة اللغة. بالإضافة إلى ذلك ، سوف نتعامل مع الإمكانيات الأساسية لمعالجة اللغة الطبيعية عند إنشاء روبوت للدردشة جنبًا إلى جنب مع المتحدثين في دورتنا
AI Weekend ، لغوية الكمبيوتر آنا فلاسوفا.
كيف بدأ كل شيء؟
بدأ الحديث الأول عن معالجة اللغة الطبيعية باستخدام جهاز كمبيوتر في الثلاثينيات من القرن العشرين باستخدام المنطق الفلسفي لأير - فقد اقترح تمييز شخص ذكي عن آلة غبية باستخدام اختبار تجريبي. في عام 1950 ، اقترح آلان تورينج في المجلة الفلسفية
Mind اختبارًا حيث يجب على القاضي تحديد من يتحدث مع: شخص أو كمبيوتر. باستخدام الاختبار ، تم وضع معايير لتقييم عمل الذكاء الاصطناعي ، ولم يتم التشكيك في إمكانية بنائه. الاختبار له العديد من القيود والمساوئ ، ولكن كان له تأثير كبير على تطوير برامج الروبوت للدردشة.
المجال الأول حيث تم تطبيق معالجة اللغة بنجاح كان الترجمة الآلية. في عام 1954 ، عرضت جامعة جورجتاون بالتعاون مع IBM برنامجًا للترجمة الآلية من الروسية إلى الإنجليزية ، والذي عمل على أساس قاموس يضم 250 كلمة ومجموعة من 6 قواعد نحوية. كان البرنامج بعيدًا عما يمكن تسميته حقًا بالترجمة الآلية ، وترجم 49 عرضًا تم تحديده مسبقًا في عرض. حتى منتصف الستينيات ، كانت هناك محاولات كثيرة لإنشاء برنامج ترجمة يعمل بكامل طاقته ، ولكن في عام 1966 أعلنت اللجنة الاستشارية للمعالجة التلقائية للغة
(ALPAC) أن الترجمة الآلية هي اتجاه عقيم. توقف دعم الدولة لبعض الوقت ، وانخفض الاهتمام العام بالترجمة الآلية ، لكن البحث لم يتوقف عند هذا الحد.

بالتوازي مع محاولات تعليم الكمبيوتر لترجمة النص ، كان العلماء والجامعات بأكملها يفكرون في إنشاء روبوت يمكنه تقليد سلوك الكلام البشري. كان أول تنفيذ ناجح لبرنامج الدردشة الآلية هو المحاور الافتراضي ELIZA ، الذي كتبه جوزيف ويزنباوم عام 1966. سخرت إليزا من سلوك المعالج النفسي ، واستخلصت كلمات مهمة من عبارة المحاور وطرح سؤالًا مضادًا. يمكننا أن نفترض أن هذه كانت أول روبوت دردشة يعتمد على القواعد (الروبوت القائم على القواعد) ، وقد وضع الأساس لفئة كاملة من هذه الأنظمة. المقابلات مثل Cleverbot و WeChat Xiaoice و Eugene Goostman - اجتازوا اختبار Turing رسميًا في عام 2014 - وحتى Siri و Jarvis و Alexa ما كانوا ليظهروا بدون Eliza.
في عام 1968 ، طور Terry Grapes برنامج SHRDLU في LISP. نقلت أشياء بسيطة عند الطلب: المخاريط والمكعبات والكرات ، ويمكن أن تدعم السياق - فهمت العنصر الذي يجب نقله ، إذا تم ذكره سابقًا. كانت الخطوة التالية في تطوير برامج الروبوت للدردشة هي برنامج ALICE ، الذي طوره ريتشارد والاس لغة ترميز خاصة - AIML
(لغة ترميز الذكاء الاصطناعي الإنجليزية) . ثم ، في عام 1995 ، تم المبالغة في التوقعات من برنامج الدردشة: اعتقدوا أن ALICE ستكون أكثر ذكاءً من الشخص. بالطبع ، لم ينجح برنامج الدردشة الآلي في أن يكون أكثر ذكاءً ، ولبعض الوقت خاب أمل العمل في برامج الدردشة الآلية ، وتجاهل المستثمرون لفترة طويلة موضوع المساعدين الافتراضيين.
مسائل اللغة
اليوم لا تزال روبوتات الدردشة تعمل على أساس مجموعة من القواعد والسيناريوهات السلوكية ، ومع ذلك ، فإن اللغة الطبيعية غامضة وغامضة ، يمكن أن يكون للفكر طرق عديدة للعرض ، وبالتالي ، يعتمد النجاح التجاري لأنظمة الحوار على حل مشاكل معالجة اللغة. يجب تعليم الآلة كيفية تصنيف مجموعة كاملة من الأسئلة الواردة بوضوح وتفسيرها بوضوح.
يتم ترتيب جميع اللغات بشكل مختلف ، وهذا مهم جدًا للتحليل. من وجهة نظر التكوين الصرفي ، يمكن للعناصر المهمة للكلمة أن تنضم إلى الجذر بالتسلسل ، كما هو الحال ، على سبيل المثال ، في اللغات التركية ، أو يمكن أن تكسر الجذر ، كما هو الحال في العربية والعبرية. من وجهة نظر بناء الجملة ، تسمح بعض اللغات بالترتيب الحر للكلمات في عبارة ، بينما يتم تنظيم لغات أخرى بشكل أكثر صرامة. في النظم الكلاسيكية ، يلعب ترتيب الكلمات دورًا أساسيًا. بالنسبة للطرق الإحصائية الحديثة في البرمجة اللغوية العصبية ، ليس لها مثل هذه القيمة ، حيث أن المعالجة لا تحدث على مستوى الكلمات ، ولكن في جمل كاملة.
تنشأ صعوبات أخرى في تطوير روبوتات الدردشة فيما يتعلق بتطوير الاتصال متعدد اللغات. الآن كثيرًا ما لا يتواصل الناس بلغاتهم الأصلية ، فهم يستخدمون الكلمات بشكل غير صحيح. على سبيل المثال ، في عبارة "لقد شحنت قبل يومين ، ولكن البضائع لم تأت" ، من وجهة نظر المفردات ، يجب أن نتحدث عن تسليم الأشياء المادية ، على سبيل المثال ، السلع ، وليس عن المعاملات المالية الإلكترونية ، التي وصفها بهذه الكلمات شخص لا يتحدث باللغة الأم. ولكن في التواصل الحقيقي ، سيفهم الشخص المحاور بشكل صحيح ، وقد يواجه روبوت الدردشة مشاكل. في موضوعات معينة ، مثل الاستثمارات أو الأعمال المصرفية أو تكنولوجيا المعلومات ، غالبًا ما يتحول الأشخاص إلى لغات أخرى. لكن من غير المحتمل أن يفهم برنامج الدردشة ما هو على المحك ، لأنه من المرجح أن يتم تدريبه بلغة واحدة.
قصة نجاح: مترجمون آليون
قبل ظهور المساعدين الصوتيين ونشر روبوتات الدردشة على نطاق واسع ، كانت الترجمة الآلية هي المهمة الفكرية الأكثر طلبًا ، والتي تتطلب معالجة لغة طبيعية. يعود الحديث عن الشبكات العصبية والتعلم العميق إلى التسعينات ، وظهر أول كمبيوتر عصبي Mark-1 بشكل عام في عام 1958. ولكن في كل مكان لم يكن من الممكن استخدامها بسبب الأداء المنخفض لأجهزة الكمبيوتر وعدم وجود مجموعة كافية من اللغات. فقط فرق البحث الكبيرة يمكنها تحمل تكاليف إجراء البحوث في مجال الشبكات العصبية.
كان المترجمون الآليون في منتصف القرن العشرين بعيدًا عن Google Translate و Yandex.Translator ، ولكن مع ظهور كل طريقة جديدة لأفكار الترجمة التي تم تطبيقها بشكل أو بآخر حتى اليوم.
1970 كانت الترجمة
الآلية القائمة على القواعد (RBMT) أول محاولة لتعليم آلة للترجمة. تم الحصول على الترجمة كما في الصف الخامس مع قاموس ، ولكن في شكل أو آخر ، لا تزال قواعد المترجم الآلي أو روبوت الدردشة قيد الاستخدام.
1984 الترجمة الآلية القائمة على المثال
(EBMT) كانت قادرة على ترجمة حتى اللغات التي كانت مختلفة تمامًا عن بعضها البعض ، حيث كان من غير المجدي وضع أي قواعد. يستخدم جميع المترجمين الآليين الحديثين وبرامج الروبوت للدردشة أمثلة وأنماط جاهزة.
1990. الترجمة الآلية الإحصائية
(الإنجليزية SMT) في عصر تطور الإنترنت جعلت من الممكن ليس فقط استخدام فيلق اللغة الجاهزة ، ولكن حتى الكتب والمقالات المترجمة بحرية. زادت البيانات المتاحة جودة الترجمة. تستخدم الأساليب الإحصائية الآن بنشاط في معالجة اللغة.
الشبكات العصبية في خدمة البرمجة اللغوية العصبية
مع تطور معالجة اللغة الطبيعية ، تم حل العديد من المشاكل من خلال الأساليب الإحصائية الكلاسيكية والعديد من القواعد ، ولكن هذا لم يحل مشكلة الغموض والغموض في اللغة. إذا قلنا "القوس" بدون أي سياق ، فمن غير المرجح أن يفهم حتى المحاور الحي ما يُقال. يتم تحديد دلالات الكلمة في النص من خلال الكلمات المجاورة. ولكن كيف نفسر هذا للآلة إذا كانت تفهم التمثيل العددي فقط؟ وهكذا ولدت طريقة تحليل النص الإحصائي
word2vec (الكلمة الإنجليزية إلى المتجه) .
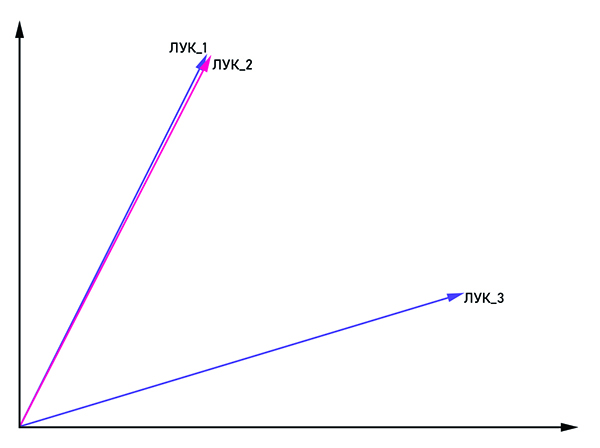 المتجهان bow_1 و bow_2 متوازيان ، لذلك هذه كلمة واحدة ، و bow_3 هي كلمة مترادفة.
المتجهان bow_1 و bow_2 متوازيان ، لذلك هذه كلمة واحدة ، و bow_3 هي كلمة مترادفة.الفكرة واضحة تمامًا من الاسم: تقديم الكلمة في شكل ناقل بإحداثيات (x
1 ، x
2 ، ...، x
n ). لمكافحة الاختراق ، يتم ربط الكلمات نفسها بالعلامة: "bow_1" و "bow_2" وما إلى ذلك. إذا كانت المتجهات bow_n و bow_m متوازية ، فيمكن اعتبارهما كلمة واحدة. خلاف ذلك ، هذه الكلمات هي الأسماء المترادفة. عند الإخراج ، يكون لكل كلمة تمثيل متجه خاص بها في الفضاء متعدد الأبعاد (يمكن أن يختلف بُعد مساحة المتجه من 50 إلى 1000).

يبقى السؤال ما هو نوع الشبكة العصبية التي يجب استخدامها لتدريب روبوت الدردشة المشروط. الاتساق مهم في الكلام البشري: نستخلص الاستنتاجات ونتخذ قرارات بناءً على ما ورد في الجملة السابقة أو حتى الفقرة. تعد الشبكة العصبية المتكررة (RNN) مثالية لهذه المعايير ، ولكن مع زيادة المسافة بين الأجزاء المتصلة من النص ، يجب زيادة حجم RNN ، مما يؤدي إلى انخفاض في جودة معالجة المعلومات. يتم حل هذه المشكلة عن طريق شبكة LSTM
(ذاكرة اللغة الإنجليزية طويلة المدى) . لديها ميزة واحدة مهمة - حالة الخلية ، والتي يمكن أن تظل ثابتة ، أو تتغير إذا لزم الأمر. وبالتالي ، لا تضيع المعلومات في السلسلة ، وهو أمر بالغ الأهمية لمعالجة اللغة الطبيعية.
يوجد اليوم عدد كبير من المكتبات لمعالجة اللغة الطبيعية. إذا تحدثنا عن لغة Python ، والتي غالبًا ما تستخدم لتحليل البيانات ، فهذه هي
NLTK و
Spacy . تشارك الشركات الكبرى أيضًا في تطوير مكتبات لـ NLP ، مثل
NLP Architect من Intel أو
PyTorch من باحثين من Facebook و Uber. على الرغم من هذا الاهتمام الكبير في الشركات واسعة النطاق في أساليب الشبكة العصبية لمعالجة اللغة ، إلا أن الحوارات المتماسكة يتم بناؤها بشكل أساسي على أساس الأساليب الكلاسيكية ، وتلعب الشبكة العصبية دورًا داعمًا في حل مشكلات المعالجة المسبقة وتصنيف الكلام.
كيف يمكن استخدام البرمجة اللغوية العصبية في الأعمال؟
تشمل التطبيقات الأكثر وضوحًا لمعالجة اللغات الطبيعية المترجمين الآليين ، وبرامج الروبوت للدردشة ، والمساعدين الصوتيين - وهو شيء نواجهه كل يوم. يمكن استبدال معظم موظفي مركز الاتصال بمساعدين افتراضيين ، حيث إن حوالي 80٪ من طلبات العملاء للبنوك تتعلق بمشكلات نموذجية إلى حد ما. سيتعامل روبوت الدردشة أيضًا بهدوء مع المقابلة الأولية للمرشح ويسجلها في اجتماع "مباشر". من الغريب أن الفقه هو اتجاه دقيق إلى حد ما ، لذلك حتى هنا يمكن أن يصبح روبوت الدردشة مستشارًا ناجحًا.

ليس اتجاه b2c هو الوحيد الذي يمكن فيه استخدام روبوتات الدردشة. في الشركات الكبيرة ، يكون تناوب الموظفين نشطًا جدًا ، لذلك يجب على الجميع المساعدة في التكيف مع البيئة الجديدة. نظرًا لأن أسئلة الموظف الجديد نموذجية إلى حد ما ، فإن العملية برمتها تتم بسهولة. ليست هناك حاجة للبحث عن شخص سيشرح كيفية إعادة تزويد الطابعة بالوقود ، والذي يجب الاتصال به في أي مشكلة. سيكون روبوت الدردشة الداخلي للشركة على ما يرام مع هذا.
باستخدام البرمجة اللغوية العصبية ، يمكنك قياس رضا المستخدم بدقة عن منتج جديد من خلال تحليل المراجعات على الإنترنت. إذا حدد البرنامج المراجعة على أنها سلبية ، فسيتم إرسال التقرير تلقائيًا إلى القسم المناسب ، حيث يعمل الأشخاص الأحياء معه بالفعل.
سوف تتسع إمكانيات معالجة اللغة فقط ، ومعها نطاق تطبيقها. إذا كان هناك 40 شخصًا يعملون في مركز الاتصال الخاص بشركتك ، فمن الجدير التفكير في الأمر: ربما من الأفضل استبدالهم بفريق من المبرمجين الذين سيجمعون روبوت دردشة لك؟
يمكنك معرفة المزيد حول إمكانيات معالجة اللغة في دورة
AI Weekend الخاصة بنا ، حيث ستتحدث آنا فلاسوفا بالتفصيل حول برامج الروبوت في إطار موضوع الذكاء الاصطناعي.