هل سبق لك أن قمت بتحليل الشواغر؟
سألوا السؤال ، ما هي التقنيات الأكثر طلبًا في سوق العمل؟ قبل شهر؟ قبل عام؟
كم مرة تفتح فرص العمل الجديدة في Java في منطقة معينة من مدينتك وإلى أي مدى يتم إغلاقها بنشاط؟
في هذه المقالة سأخبرك كيف يمكنك تحقيق النتيجة المرجوة وبناء نظام إبلاغ حول موضوع يهمنا. دعنا نذهب!
(مصدر الصورة)ربما الكثير منكم مألوف وحتى يستخدم مثل هذا المورد مثل
Headhunter.ru . يتم نشر الآلاف من الوظائف الشاغرة الجديدة في مختلف المجالات على هذا الموقع يوميًا. يحتوي HeadHunter أيضًا على واجهة برمجة تطبيقات تسمح للمطور بالتفاعل مع بيانات هذا المورد.
مجموعة أدوات
باستخدام مثال بسيط ، نعتبر إنشاء عملية للحصول على البيانات لنظام إعداد التقارير ، والذي يعتمد على العمل مع واجهة برمجة التطبيقات الخاصة بالموقع Headhunter.ru. كمخزن وسيط للمعلومات ، سنستخدم SQLite DBMS المضمنة ، وسيتم تخزين البيانات المعالجة في قاعدة بيانات NoSQL في MongoDB ، Python 3.4 كلغة رئيسية.
HH APIقدرات HeadHunter API واسعة النطاق
وموصوفة جيدًا في الوثائق الرسمية على
GitHib . بادئ ذي بدء ، هذه هي القدرة على إرسال الطلبات المجهولة التي لا تتطلب تفويضًا لتلقي معلومات الوظيفة بتنسيق JSON. في الآونة الأخيرة ، تم دفع عدد من الأساليب (طرق صاحب العمل) ، ولكن لن يتم أخذها في الاعتبار في هذه المهمة.
كل شاغر معلق على الموقع لمدة 30 يومًا ، وبعد ذلك ، إذا لم يتم تجديده ، سيتم أرشفته. إذا تم حفظ الشاغر قبل انقضاء 30 يومًا ، فقد أغلقه صاحب العمل.
تسمح لك واجهة HeadHunter API (المشار إليها فيما يلي باسم HH API) بتلقي مجموعة من الوظائف الشاغرة المنشورة لأي تاريخ في آخر 30 يومًا ، والتي سنستخدمها - سنقوم بجمع الوظائف الشاغرة المنشورة لكل يوم على أساس يومي .
التنفيذ
- ربط SQLite DB
import sqlite3 conn_db = sqlite3.connect('hr.db', timeout=10) c = conn_db.cursor()
- جدول لتخزين التغييرات في حالة العمل
من أجل الراحة ، سنحفظ محفوظات تغييرات حالة الوظائف الشاغرة (التوفر حسب التاريخ) في جدول خاص بقاعدة بيانات SQLite. بفضل جدول vacancy_history ، سنكون على دراية بتوافر الوظائف الشاغرة على الموقع في أي تاريخ تفريغ ، أي ما التواريخ التي كانت نشطة فيها.
c.execute(''' create table if not exists vacancy_history ( id_vacancy integer, date_load text, date_from text, date_to text )''')
- تصفية الشواغر
هناك قيود على أن طلبًا واحدًا لا يمكنه إرجاع أكثر من 2000 مجموعة ، وبما أنه يمكن أن يكون هناك العديد من الوظائف الشاغرة المنشورة على الموقع في يوم واحد ، سنضع مرشحًا في نص الطلب ، على سبيل المثال: الشواغر فقط في سانت بطرسبرغ (المنطقة = 2) ، عن طريق تخصص تكنولوجيا المعلومات (التخصص = 1)
path = ("/vacancies?area=2&specialization=1&page={}&per_page={}&date_from={}&date_to={}".format(page, per_page, date_from, date_to))
- شروط اختيار إضافية
ينمو سوق العمل بسرعة وحتى مع مراعاة عامل التصفية ، قد يتجاوز عدد الوظائف الشاغرة عام 2000 ، لذلك سنضع حدًا إضافيًا في شكل إطلاق منفصل لكل يوم: الشواغر للنصف الأول من اليوم والشواغر للنصف الثاني من اليوم
def get_vacancy_history(): ... count_days = 30 hours = 0 while count_days >= 0: while hours < 24: date_from = (cur_date.replace(hour=hours, minute=0, second=0) - td(days=count_days)).strftime('%Y-%m-%dT%H:%M:%S') date_to = (cur_date.replace(hour=hours + 11, minute=59, second=59) - td(days=count_days)).strftime('%Y-%m-%dT%H:%M:%S') while count == per_page: path = ("/vacancies?area=2&specialization=1&page={} &per_page={}&date_from={}&date_to={}" .format(page, per_page, date_from, date_to)) conn.request("GET", path, headers=headers) response = conn.getresponse() vacancies = response.read() conn.close() count = len(json.loads(vacancies)['items']) ...
حالة الاستخدام الأولىلنفترض أننا نواجه مهمة تحديد الوظائف الشاغرة التي تم إغلاقها لفترة زمنية معينة ، على سبيل المثال ، لشهر يوليو 2018. يتم حل هذه المشكلة على النحو التالي: نتيجة استعلام SQL بسيط إلى جدول vacancy_history ستعرض البيانات التي نحتاجها ، والتي يمكن تمريرها إلى DataFrame لمزيد من التحليل:
c.execute(""" select a.id_vacancy, date(a.date_load) as date_last_load, date(a.date_from) as date_publish, ifnull(a.date_next, date(a.date_load, '+1 day')) as date_close from ( select vh1.id_vacancy, vh1.date_load, vh1.date_from, min(vh2.date_load) as date_next from vacancy_history vh1 left join vacancy_history vh2 on vh1.id_vacancy = vh2.id_vacancy and vh1.date_load < vh2.date_load where date(vh1.date_load) between :date_in and :date_out group by vh1.id_vacancy, vh1.date_load, vh1.date_from ) as a where a.date_next is null """, {"date_in" : date_in, "date_out" : date_out}) date_in = dt.datetime(2018, 7, 1) date_out = dt.datetime(2018, 7, 31) closed_vacancies = get_closed_by_period(date_in, date_out) df = pd.DataFrame(closed_vacancies, columns = ['id_vacancy', 'date_last_load', 'date_publish', 'date_close']) df.head()
نحصل على نتيجة هذا النوع:
إذا أردنا التحليل باستخدام أدوات Excel أو أدوات BI للجهات الخارجية ، يمكننا تحميل الجدول vacancy_history إلى ملف csv لمزيد من التحليل:
مدفعية ثقيلة
ولكن ماذا لو احتجنا إلى إجراء تحليل بيانات أكثر تعقيدًا؟ هنا تأتي قاعدة بيانات NoSQL الموجهة للوثيقة MongoDB لإنقاذها ، مما يسمح لك بتخزين البيانات بتنسيق JSON.
يتم إطلاق الإجراءات المذكورة أعلاه لجمع الوظائف الشاغرة على أساس يومي ، لذلك ليست هناك حاجة لعرض جميع الوظائف الشاغرة في كل مرة وتلقي معلومات مفصلة لكل منها. سنأخذ فقط تلك التي تم استلامها في الأيام الخمسة الماضية.
- الحصول على مجموعة من الوظائف الشاغرة لآخر 5 أيام من قاعدة بيانات SQLite:
def get_list_of_vacancies_sql(): conn_db = sqlite3.connect('hr.db', timeout=10) conn_db.row_factory = lambda cursor, row: row[0] c = conn_db.cursor() items = c.execute(""" select distinct id_vacancy from vacancy_history where date(date_load) >= date('now', '-5 day') """).fetchall() conn_db.close() return items
- الحصول على مجموعة من الوظائف للأيام الخمسة الأخيرة من MongoDB:
def get_list_of_vacancies_nosql(): date_load = (dt.datetime.now() - td(days=5)).strftime('%Y-%m-%d') vacancies_from_mongo = [] for item in VacancyMongo.find({"date_load" : {"$gte" : date_load}}, {"id" : 1, "_id" : 0}): vacancies_from_mongo.append(int(item['id'])) return vacancies_from_mongo
- يبقى أن تجد الفرق بين المصفوفتين ، بالنسبة للوظائف الشاغرة غير الموجودة في MongoDB ، احصل على معلومات تفصيلية واكتبها في قاعدة البيانات:
sql_list = get_list_of_vacancies_sql() mongo_list = get_list_of_vacancies_nosql() vac_for_pro = [] s = set(mongo_list) vac_for_pro = [x for x in sql_list if x not in s] vac_id_chunks = [vac_for_pro[x: x + 500] for x in range(0, len(vac_for_pro), 500)]
- لذا ، لدينا مصفوفة تحتوي على وظائف شاغرة جديدة لم تتوفر بعد في MongoDB ، لكل منها سوف نتلقى معلومات تفصيلية باستخدام طلب في HH API ، قبل معالجتها مباشرة في MongoDB ، سنقوم بمعالجة كل مستند:
- نحضر كمية الأجور إلى ما يعادل الروبل.
- إضافة تخريج لمستوى متخصص لكل وظيفة شاغرة (جونيور / متوسط / كبير الخ)
يتم تنفيذ كل هذا في وظيفة معالجة الشواغر:
from nltk.stem.snowball import SnowballStemmer stemmer = SnowballStemmer("russian") def vacancies_processing(vacancies_list): cur_date = dt.datetime.now().strftime('%Y-%m-%d') for vacancy_id in vacancies_list: conn = http.client.HTTPSConnection("api.hh.ru") conn.request("GET", "/vacancies/{}".format(vacancy_id), headers=headers) response = conn.getresponse() if response.status != 404: vacancy_txt = response.read() conn.close() vacancy = json.loads(vacancy_txt)
- الحصول على معلومات تفصيلية عن طريق الوصول إلى HH API ، تم تلقي المعالجة المسبقة
سيقوم MongoDB بتنفيذ البيانات وإدراجها في العديد من التدفقات ، مع 500 وظيفة شاغرة في كل منها:
t_num = 1 threads = [] for vac_id_chunk in vac_id_chunks: print('starting', t_num) t_num = t_num + 1 t = threading.Thread(target=vacancies_processing, kwargs={'vacancies_list': vac_id_chunk}) threads.append(t) t.start() for t in threads: t.join()
تبدو المجموعة المأهولة بالسكان في MongoDB على النحو التالي:
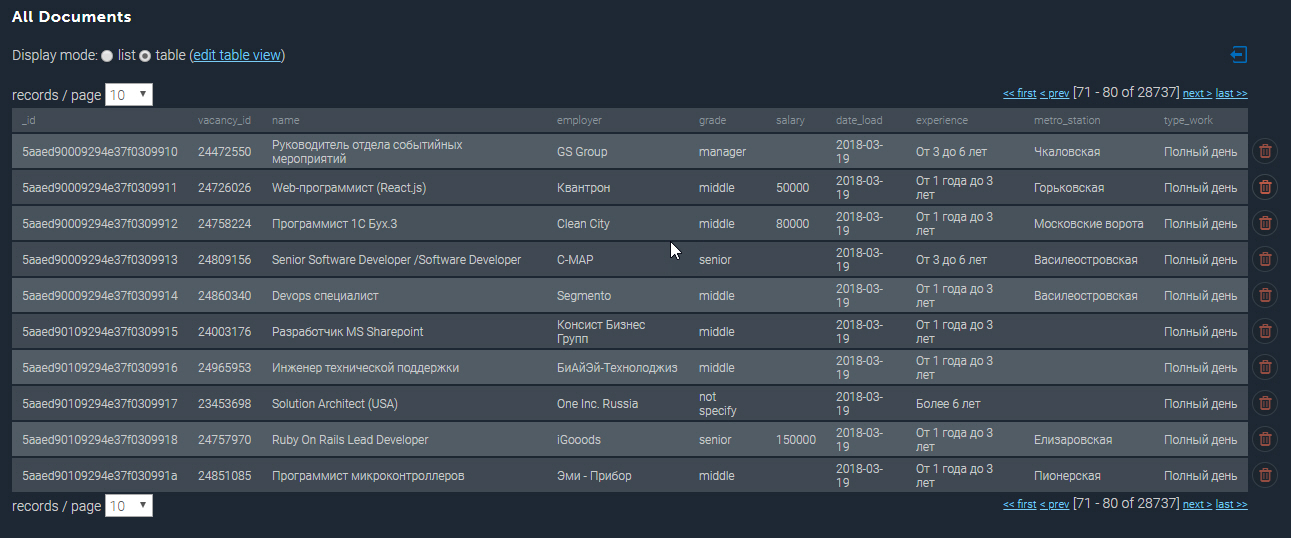
المزيد من الأمثلة
بوجود قاعدة البيانات المجمعة تحت تصرفنا ، يمكننا إجراء عينات تحليلية مختلفة. لذلك ، سأخرج أفضل 10 وظائف شاغرة بأجر مرتفع لمطوري Python في سانت بطرسبرغ:
cursor_mongo = VacancyMongo.find({"name" : {"$regex" : ".*[pP]ython*"}}) df_mongo = pd.DataFrame(list(cursor_mongo)) del df_mongo['_id'] pd.concat([df_mongo.drop(['employer'], axis=1), df_mongo['employer'].apply(pd.Series)['name']], axis=1)[['grade', 'name', 'salary_processed' ]].sort_values('salary_processed', ascending=False)[:10]
أعلى 10 وظائف Python الأعلى أجرا| الصف | الاسم | الاسم | معالجة الراتب |
|---|
| كبار | قائد فريق ويب / مهندس معماري (Python / Django / React) | Investex المحدودة | 293901.0 |
| كبار | مطور بايثون كبير في الجبل الأسود | بيتماستر | 277141.0 |
| كبار | مطور بايثون كبير في الجبل الأسود | بيتماستر | 275289.0 |
| الوسط | مطور ويب للجهة الخلفية (Python) | Soshace | 250000.0 |
| الوسط | مطور ويب للجهة الخلفية (Python) | Soshace | 250000.0 |
| كبار | مهندس بايثون الرائد لشركة سويسرية ناشئة | Assaia International AG | 250000.0 |
| الوسط | مطور ويب للجهة الخلفية (Python) | Soshace | 250000.0 |
| الوسط | مطور ويب للجهة الخلفية (Python) | Soshace | 250000.0 |
| كبار | فريق بايثون | ديجيتال | 230000.0 |
| كبار | المطور الرئيسي (Python ، PHP ، Javascript) | مجموعة IK | 220231.0 |
الآن دعونا نكتشف أي محطة مترو لديها أعلى تركيز للوظائف الشاغرة لمطوري جافا. باستخدام تعبير عادي ، أقوم بالتصفية حسب المسمى الوظيفي "Java" ، وأختار أيضًا تلك الوظائف فقط حيث يتم تحديد العنوان:
cursor_mongo = VacancyMongo.find({"name" : {"$regex" : ".*[jJ]ava[^sS]"}, "address" : {"$ne" : None}}) df_mongo = pd.DataFrame(list(cursor_mongo)) df_mongo['metro'] = df_mongo.apply(lambda x: x['address']['metro']['station_name'] if x['address']['metro'] is not None else None, axis = 1) df_mongo.groupby('metro')['_id'] \ .count() \ .reset_index(name='count') \ .sort_values(['count'], ascending=False) \ [:10]
وظائف لمطوري جافا في محطات المترو| المترو | العد |
|---|
| فاسيليستروفسكايا | 87 |
| بتروغرادسكايا | 68 |
| فيبورغ | 46 |
| ساحة لينين | 45 |
| Gorkovskaya | 45 |
| تشكالوفسكايا | 43 |
| نارفا | 32 |
| ساحة الانتفاضة | التاسع والعشرون |
| القرية القديمة | التاسع والعشرون |
| اليزاروفسكايا | 27 |
الملخص
لذا ، فإن القدرات التحليلية للنظام المطور واسعة حقًا ويمكن استخدامها لتخطيط بدء التشغيل أو فتح اتجاه جديد للنشاط.
ألاحظ أنه حتى الآن يتم تقديم الوظائف الأساسية للنظام فقط ، ومن المقرر في المستقبل تطويره في اتجاه التحليل من خلال الإحداثيات الجغرافية والتنبؤ بظهور الوظائف الشاغرة في منطقة معينة من المدينة.
يمكن العثور على شفرة المصدر الكاملة لهذه المقالة على الرابط إلى
GitHub الخاص بي.
تعليقات
PS على المقال مرحب بها ، يسعدني أن أجيب على جميع أسئلتك ومعرفة رأيك. شكرا لك!