في عرض NVIDIA SIGGRAPH 2018 ، كشف الرئيس التنفيذي للشركة Jensen Juan رسميًا عن بنية GPU التي طال انتظارها (والشائعات والمضاربات). سيتضمن الجيل التالي من وحدات معالجة الرسومات NVIDIA ، Turing ، عددًا من الميزات الجديدة وسيشهد العالم في وقت لاحق من هذا العام. على الرغم من أن التصور الاحترافي (ProViz) كان محور إعلانات اليوم ، نتوقع أن يتم استخدام البنية الجديدة في منتجات NVIDIA القادمة. مراجعة اليوم ليست مجرد قائمة بجميع ميزات تورينج.

العرض الهجين والشبكات العصبية: RT & Tensor Cores
إذن ما هو الأمر الخاص والجديد في هندسة تورينج؟ تم تصميم Marquee ، على الأقل لمجتمع NVIDIA ProViz ، للعرض المختلط ، الذي يجمع بين تتبع الأشعة مع التنقيط التقليدي.

تغيير كبير: أدرجت NVIDIA المزيد من معدات تتبع الأشعة في Turing لتقديم أسرع تتبع للأشعة في الأجهزة. جديد لـ Turing architecture هو وحدة الحوسبة المتخصصة RT RT ، كما تسميها NVIDIA ، حاليًا لا توجد معلومات كافية عنها ، من المعروف فقط أن وظيفتها هي دعم تتبع الأشعة. تسرع وحدات المعالج هذه من التحقق من تقاطع الأشعة والمثلثات ، وكذلك معالجة BVH (التسلسل الهرمي للأحجام المحيطة).
تدعي NVIDIA أن أسرع مكونات Turing يمكن أن تحسب 10 مليار (غيغا) أشعة في الثانية ، والتي بالمقارنة مع باسكال غير المتسارع هو تحسن 25 مرة في أداء تتبع الأشعة.
تشتمل بنية تورينج على نواة فولتا الموتر التي تم تعزيزها. نواة الموتر هي جانب مهم للعديد من مبادرات NVIDIA. إلى جانب تسريع تتبع الأشعة ، هناك أداة مهمة في NVIDIA "حقيبة خدعة سحرية" لتقليل عدد الأشعة المطلوبة في المشهد باستخدام تقليل تشويش الذكاء الاصطناعي لمسح الصورة ، وهنا تقوم نوى الموتر بشكل أفضل. بالطبع ، هذه ليست المنطقة الوحيدة التي تكون فيها جيدة - فكل الشبكات العصبية وإمبراطوريات الذكاء الاصطناعي من NVIDIA مبنية عليها.
يتميز تورينج بدعم لمجموعة واسعة من الدقة ، مما يعني أنه يمكن أن يتسارع بشكل كبير في أعباء العمل التي لا تتطلب متطلبات عالية الدقة. بالإضافة إلى وضع الدقة Volta FP16 ، تدعم نواة Turing Tensor INT8 وحتى INT4. هذا هو 2 و 4 مرات أسرع من FP16 ، على التوالي. على الرغم من أن NVIDIA لم ترغب في الخوض في التفاصيل في العرض التقديمي ، أود أن أقترح أنها تنفذ شيئًا مشابهًا لتغليف البيانات ، والذي يستخدم للعمليات ذات الدقة المنخفضة على نوى CUDA. على الرغم من الدقة المنخفضة للشبكة العصبية (يتم تقليل العائد - وفقًا لـ INT4 نحصل على 16 (!) قيمًا فقط) - هناك نماذج معينة تحتاج حقًا إلى هذا المستوى المنخفض من الدقة. ونتيجة لذلك ، ستظهر أوضاع الدقة المنخفضة إنتاجية جيدة ، خاصة في مهام الإخراج ، والتي ستسعد بلا شك بعض المستخدمين.
بالعودة إلى العرض الهجين بشكل عام ، من المثير للاهتمام أنه على الرغم من هذه التسارع الفردي الكبير ، يبدو وعد NVIDIA العام بمكاسب الأداء أكثر تواضعًا. على الرغم من أن الشركة تعد بزيادة الإنتاجية بمقدار 6 مرات مقارنة بـ Pascal ، فقد حان الوقت للسؤال عن الأجزاء التي يتم تسريعها ، وبالمقارنة مع تلك الأجزاء. سيخبرنا الوقت.
وفي الوقت نفسه ، من أجل الاستفادة بشكل أفضل من نواة الموتر خارج تتبع الشعاع ومهام التعلم العميق الضيقة ، ستقوم NVIDIA بنشر SDK ، NVIDIA NGX ، والتي ستسمح بدمج الشبكات العصبية في معالجة الصور. تتوقع NVIDIA استخدام الشبكات العصبية ونوى الموتر لمعالجة إضافية للصور والفيديو ، بما في ذلك طرق مثل تقنية Deep-Anti-Aliasing (DLAA) القادمة.
Turing SM: نوى INT مخصصة وذاكرة تخزين مؤقت واحدة وتظليل معدل متغير
جنبا إلى جنب مع RT وحبات الموتر ، تقدم بنية تورينج متعددة المعالجات (SM) نفسها حيل جديدة. على وجه الخصوص ، تم توريث أحد أحدث تغييرات Volta ، ونتيجة لذلك يتم تخصيص نوى Integer في كتلها الخاصة ، وليست جزءًا من نوى النقطة العائمة CUDA. الميزة هي إنشاء عنوان أسرع وأداء إضافة مضاعف (FMA).
أما بالنسبة لـ ALU (ما زلت في انتظار تأكيد Turing) - دعم العمليات الأسرع بدقة منخفضة (على سبيل المثال ، FP16 السريع). في فولتا ، يتم تنفيذ هذا كعمليات FP16 بتردد مزدوج بالنسبة إلى FP32 ، وعمليات INT8 بسرعة 4x. تدعم نواة Tensor بالفعل هذا المفهوم ، لذلك سيكون من المنطقي نقله إلى نواة CUDA.
تعد FP16 السريعة ، وتقنية الرياضيات Packed Packed ، وطرق أخرى لحزم عمليات صغيرة متعددة في عملية واحدة كبيرة ، كلها مكونات رئيسية لتحسين أداء وحدة معالجة الرسومات في وقت يتباطأ فيه قانون مور.
باستخدام أنواع بيانات كبيرة (دقيقة) فقط عند الضرورة ، يمكن تجميعها معًا للقيام بمزيد من العمل في نفس الفترة الزمنية. هذا مهم في المقام الأول لمخرجات الشبكات العصبية ، وكذلك لتطوير اللعبة. والحقيقة هي أنه ليست كل برامج التظليل تحتاج إلى دقة FP32 ، ويمكن أن يؤدي تقليل الدقة إلى تحسين الأداء وتقليل عرض النطاق الترددي للذاكرة المفيدة واستخدام ملف التسجيل.
يحتوي Turing SM على شيء تسميه NVIDIA "بنية ذاكرة التخزين المؤقت الموحدة". نظرًا لأنني ما زلت أتوقع مخططات SMID الرسمية من NVIDIA ، فليس من الواضح ما إذا كان هذا هو نفس التوحيد الذي رأيناه مع Volta - حيث تم دمج ذاكرة التخزين المؤقت L1 مع الذاكرة المشتركة - أو أن NVIDIA قد خطت خطوة أخرى إلى الأمام. على أي حال ، تدعي NVIDIA أنها عرضت الآن ضعف عرض النطاق الترددي بالنسبة إلى "الجيل السابق" ، ولكن ليس من الواضح ما إذا كان هذا يعني "باسكال" أو "فولتا" (هذا الأخير أكثر احتمالًا).
أخيرًا ، مخفيًا بشدة في بيان تورينج الصحفي ، تم ذكر دعم التظليل بمعدل متغير. هذه تقنية عرض رسومي صغيرة ومتطورة نسبيًا ، والتي لا تتوفر عنها سوى القليل من المعلومات (خاصة حول كيفية تنفيذها بواسطة NVIDIA). ولكن على مستوى عالٍ من التجريد ، يبدو أنه "تقنية الجيل التالي من NVIDIA التي تسمح لك بتطبيق التظليل بدرجات دقة مختلفة ، مما يسمح للمطورين بعرض مناطق مختلفة من الشاشة بدرجات دقة فعالة مختلفة لجودة التركيز (ووقت العرض) في المناطق التي تشتد الحاجة إليها" .
إطعام الوحش: دعم GDDR6
نظرًا لأن الذاكرة التي تستخدمها وحدات معالجة الرسومات تم تطويرها بواسطة شركات خارجية ، فلا توجد أسرار. تقوم شركة JEDEC وشركة Samsung و SK Hynix و Micron الكبيرة المكونة من 3 أعضاء بتطوير ذاكرة GDDR6 كخليفة لـ GDDR5 و GDDR5X. أكدت NVIDIA أن تورينج سيدعمها. اعتمادًا على الشركة المصنعة ، يتم الإعلان عن الجيل الأول من GDDR6 على أنه يحتوي على عرض نطاق ترددي للذاكرة يصل إلى 16 جيجابت / ثانية لكل ناقل ، وهو ضعف ضعف أحدث جيل من بطاقات NVIDIA GDDR5 ، وأسرع بنسبة 40٪ من أحدث بطاقات NVIDIA GDDR5X.
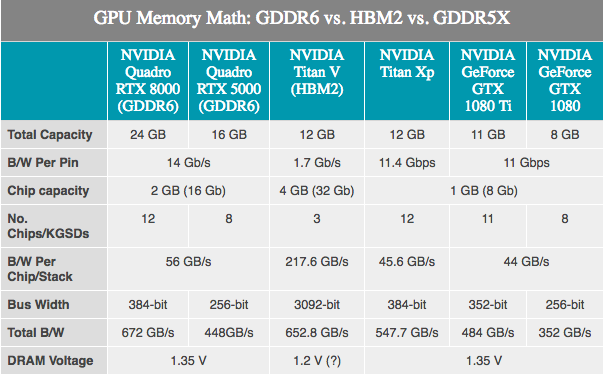
بالمقارنة مع GDDR5X ، لا يبدو GDDR6 بمثابة اختراق كبير ، حيث تم تطبيق العديد من ابتكارات GDDR6 بالفعل على GDDR5X. تتضمن التغييرات الأساسية هنا جهد تشغيل أقل (1.35 فولت) ، والذاكرة الداخلية مقسمة الآن: قناتان للذاكرة لكل دائرة دقيقة. للحصول على شريحة قياسية 32 بت - قناتان للذاكرة 16 بت ، في المجمل لدينا 16 قناة من هذا القبيل على بطاقة 256 بت. على الرغم من أن هذا بدوره يشير إلى وجود عدد كبير جدًا من القنوات ، إلا أن وحدات معالجة الرسومات ستحصل على أقصى فائدة من الابتكار ، لأنها تاريخيًا هي أكثر الأجهزة "موازية".

أكدت NVIDIA من جانبها أن بطاقات Turing Quadro الأولى ستستخدم GDDR6 بسرعة 14 جيجابت / ثانية. في الوقت نفسه ، أكدت NVIDIA أيضًا استخدام ذاكرة Samsung ، خاصة بالنسبة للأجهزة المتطورة بسعة 16 غيغابايت. هذا مهم لأنه يعني أنه يمكن تجهيز وحدة معالجة رسومات NVIDIA نموذجية بسعة 256 بت مع 8 وحدات قياسية والحصول على 16 جيجابايت من سعة الذاكرة الإجمالية ، أو حتى 32 جيجابايت إذا كانوا يستخدمون وضع المحارة (يسمح بمعالجة 32 جيجابايت من الذاكرة على 256 بت القياسي الحافلة).
جميع أنواع التفاصيل: NVLink و VirtualLink و 8 K HEVC
انتهت بالفعل بمراجعة بنية Turing ، وأكدت NVIDIA دعمًا عرضيًا لبعض ميزات الإدخال / الإخراج الخارجية الجديدة. سيكون دعم NVLink موجودًا في العديد من منتجات Turing على الأقل. تذكر أن NVIDIA تستخدمه في جميع بطاقات Quadro الثلاثة الجديدة. تقدم NVIDIA تكوين GPU ثنائي الاتجاه.
نقطة مهمة (قبل أن يتعمق جزء من جمهورنا الموجه نحو اللعبة في القراءة): لا يعني وجود NVLink في أجهزة Turing أنه سيتم استخدامه في بطاقات الفيديو الاستهلاكية. ربما يقتصر كل شيء على بطاقات Quadro و Tesla فقط.
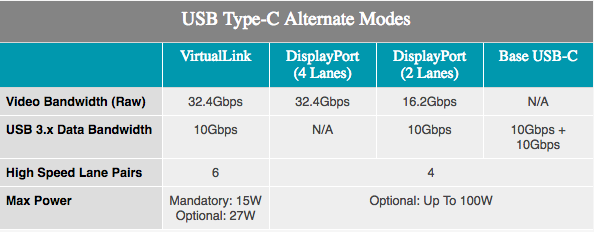
مع إضافة دعم VirtualLink ، سيكون لدى مشغلي ومستخدمي ProViz ما يمكن توقعه من VR. تم الإعلان عن وضع USB Type-C بديل في الشهر الماضي ويدعم طاقة 15 واط + ، ونقل بيانات 10 جيجابت / ثانية بفضل USB 3.1 Gen 2 و 4 نطاقات DisplayPort HBR3 على كابل واحد. بعبارة أخرى ، هذا اتصال DisplayPort 1.4 مع بيانات وقوة إضافية. يسمح هذا لبطاقة الفيديو بالتحكم المباشر في سماعة الرأس VR. المعيار مدعوم من قبل NVIDIA و AMD و Oculus و Valve و Microsoft ، لذا ستكون منتجات Turing هي الأولى من بين عدد من المنتجات التي ستدعم المعيار الجديد.
على الرغم من أن NVIDIA بالكاد تطرق إلى الموضوع ، فإننا نعلم أنه تم تحديث وحدة ترميز الفيديو NVENC في Turing. يضيف أحدث إصدار من NVENC دعمًا خاصًا لترميز HEKC 8K. وفي الوقت نفسه ، تمكنت NVIDIA من تحسين جودة برنامج التشفير ، مما سمح لها بتحقيق نفس الجودة كما كان من قبل ، مع معدل بت منخفض للفيديو بنسبة 25٪.
مؤشرات الأداء
إلى جانب مواصفات الأجهزة المعلنة ، تعرض NVIDIA العديد من الأرقام لأداء معدات Turing. وتجدر الإشارة إلى أننا لا نعرف إلا القليل جدًا هنا. يبدو أن المكونات تستند إلى وحدات تخزين Turing المضمنة بشكل كامل وجزئي مع 4608 نواة CUDA و 576 نواة موتر. ومع ذلك ، لم يتم الكشف عن الترددات ، نظرًا لأن هذه الأرقام تم تصنيفها لأجهزة Quadro ، فمن المحتمل أن نرى سرعات ساعة أقل من أي معدات استهلاكية.

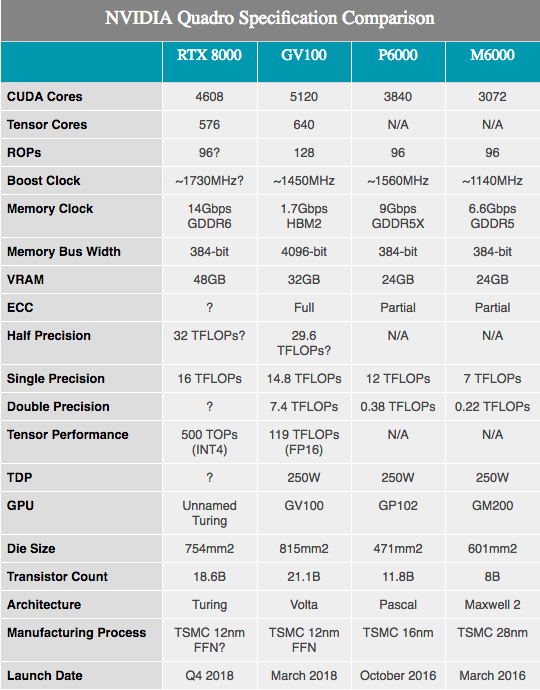
إلى جانب 10GigaRays / sec المذكورة أعلاه لنوى RT ، فإن أداء نوى NVIDIA هو 500 تريليون عملية موتر في الثانية (500T TOPs). كمرجع ، غالبًا ما تشير NVIDIA إلى وحدة معالجة الرسومات GV100 على أنها قادرة على تقديم أقصى 120T TOP ، ولكن هذا ليس الشيء نفسه. على وجه الخصوص ، على الرغم من أن GV100 مذكور في معالجة عمليات FP16 ، فقد تم الاستشهاد بأداء تورينج بدقة INT4 منخفضة للغاية ، وهو ما يعادل ربع حجم FP16 ، وبالتالي ، يزيد الإنتاجية أربع مرات. إذا قمنا بتطبيع الدقة ، فلا يبدو أن نواة Turing Tensor لديها أفضل إنتاجية لكل نواة ، ولكنها تقدم بدلاً من ذلك خيارات دقة أكثر من Volta. على أي حال ، فإن 576 نواة موتر في هذه الشريحة تضعها تقريبًا على قدم المساواة مع GV100 ، التي تحتوي على 640 من هذه النوى.
فيما يتعلق بنوى CUDA ، تدعي NVIDIA أن وحدة معالجة رسومات Turing يمكن أن تقدم 16 أداء TFLOPS. هذا أكبر قليلاً من أداء 15 TFLOPS مع الدقة الفردية لـ Tesla V100 ، أو حتى أكثر من 13.8 TFLOPS من Titan V. إذا كنت تبحث عن معلومات أكثر ملاءمة للمستهلكين ، فهذا يزيد بنسبة 32 ٪ عن Titan Xp. بعد أن قمنا برسم بعض الحسابات التقريبية على الورق ، يمكننا أن نفترض أن سرعة ساعة GPU تبلغ حوالي 1730 ميجاهرتز ، نظرًا لأنه على مستوى SM لم تكن هناك تغييرات إضافية من شأنها تغيير صيغ أداء ALU التقليدية.
وفي الوقت نفسه ، أعلنت NVIDIA أن بطاقات Quadro ستأتي بذاكرة GDDR6 تعمل بسرعة 14 جيجابت / ثانية. وبالنظر إلى أفضل اثنين من وحدات SKU Quadro التي تقدم 48 GB و 24 GB GDDR6 ، على التوالي ، نرى تقريبًا ناقل ذاكرة 384 بت على وحدة معالجة رسومات Turing. بالانتقال إلى الأرقام ، فإن هذا يصل إلى 672 جيجابايت / ثانية من عرض النطاق الترددي للذاكرة لبطاقتي Quadro العلويتين.
خلاف ذلك ، مع تغيير في الهندسة المعمارية ، من الصعب إجراء العديد من مقارنات الأداء المفيدة ، خاصة عند المقارنة مع باسكال. من ما رأيناه مع Volta ، تحسن الأداء العام لـ NVIDIA ، خاصةً في أعباء عمل الحوسبة جيدة التصميم. وبالتالي ، قد يكون تحسن أداء الورق بنسبة 33٪ تقريبًا مقارنة بكوادرو P6000 أكبر بكثير.
سأذكر الحجم الكريستالي لوحدة معالجة الرسومات الجديدة. تقع على 754 مم 2 ، وهي ليست كبيرة فحسب ، بل ضخمة. بالمقارنة مع وحدات معالجة الرسوميات الأخرى ، فإن NVIDIA GV100 فقط هي الثانية في الحجم ، والتي لا تزال حاليًا رائدة NVIDIA. ولكن مع وجود 18.6 مليار ترانزستور ، من السهل معرفة لماذا يجب أن تكون الشريحة الناتجة كبيرة جدًا. على ما يبدو ، لدى NVIDIA خططًا كبيرة لوحدة معالجة الرسومات هذه ، والتي ستتمكن في النهاية من تبرير وجود معالجين للرسومات الضخمة في مجموعة منتجاتها.
لم تحدد NVIDIA من جانبها رقم طراز محدد لوحدة معالجة الرسومات هذه - سواء كانت وحدة معالجة رسومات تقليدية من الفئة 102 أو حتى فئة 100. أتساءل عما إذا كنا سنرى تعديلًا لهذا النوع من GPU لمنتج استهلاكي بشكل أو بآخر ؛ إنها كبيرة جدًا لدرجة أن NVIDIA قد ترغب في الاحتفاظ بها لوحدات معالجة الرسومات Quadro و Tesla الأكثر ربحية.
صدر في الربع الرابع من 2018 إن لم يكن في وقت سابق
في الختام ، سأقول أنه إلى جانب الإعلان عن بنية Turing ، أعلنت NVIDIA أن أول 4 بطاقات Quadro تعتمد على وحدات معالجة رسومات Turing - Quadro RTX 8000 و RTX 6000 و RTX 5000 ستبدأ في الشحن في الربع الرابع من هذا العام. نظرًا لأن طبيعة هذا الإعلان مقلوبة إلى حد ما - عادةً ما تعلن NVIDIA أولاً عن مكونات المستهلك - لن أطبق نفس الجدول الزمني على بطاقات المستهلك التي لا تحتوي على مثل هذه المتطلبات الصارمة للتحقق. سنرى معدات تورينج في الربع الرابع من هذا العام ، إن لم يكن في وقت سابق. يمكن لأولئك الذين يرغبون في شراء Quadro البدء في توفير المال الآن: ستكلفك أفضل بطاقات Quadro RTX 8000 الجديدة حوالي 10000 دولار.
أخيرًا ، بالنسبة للمستهلكين الذين يستخدمون NVIDIA Tesla ، فإن إطلاق تورينج يترك فولتا في طي النسيان. لم تخبرنا NVIDIA ما إذا كانت تورينج ستتوسع في النهاية إلى مساحة Tesla الراقية - لتحل محل GV100 - أو ما إذا كان أفضل معالج Volta سيبقى سيد نطاقها لعدة قرون. ومع ذلك ، نظرًا لأن بطاقات Tesla الأخرى تعتمد حتى الآن على Pascal ، فهي أول المرشحين لتزاحم Turing في عام 2019.
شكرا لك على البقاء معنا. هل تحب مقالاتنا؟ هل تريد رؤية مواد أكثر إثارة للاهتمام؟ ادعمنا عن طريق تقديم طلب أو التوصية به لأصدقائك ،
خصم 30 ٪ لمستخدمي Habr على نظير فريد من خوادم مستوى الدخول التي اخترعناها لك: الحقيقة الكاملة حول VPS (KVM) E5-2650 v4 (6 نوى) 10GB DDR4 240GB SSD 1Gbps من 20 $ أو كيفية تقسيم الخادم؟ (تتوفر الخيارات مع RAID1 و RAID10 ، حتى 24 مركزًا وحتى 40 جيجابايت DDR4).
VPS (KVM) E5-2650 v4 (6 نوى) 10GB DDR4 240GB SSD 1Gbps حتى ديسمبر مجانًا عند الدفع لمدة ستة أشهر ، يمكنك الطلب
هنا .
ديل R730xd أرخص مرتين؟ فقط لدينا
2 x Intel Dodeca-Core Xeon E5-2650v4 128GB DDR4 6x480GB SSD 1Gbps 100 TV من 249 دولارًا في هولندا والولايات المتحدة! اقرأ عن
كيفية بناء مبنى البنية التحتية الطبقة باستخدام خوادم Dell R730xd E5-2650 v4 بتكلفة 9000 يورو مقابل سنت واحد؟