في هذه المقالة ، أود أن أتحدث عن بعض التقنيات للعمل مع البيانات عند تدريب نموذج. على وجه الخصوص ، كيفية سحب تجزئة الأشياء على المربعات ، وكذلك كيفية تدريب النموذج والحصول على ترميز مجموعة البيانات ، مع وضع علامة على عدد قليل من العينات.
التحدي
هناك عملية معينة لصنع البيتزا والصور من مراحلها المختلفة (بما في ذلك البيتزا فقط). من المعروف أنه إذا أفسدت وصفة العجين ، فسيكون هناك بثور بيضاء على القشرة. هناك أيضًا علامة ثنائية لجودة الاختبار لكل حالة بيتزا ، من قبل الخبراء. من الضروري تطوير خوارزمية تحدد جودة الاختبار بالصورة.
تتكون مجموعة البيانات من صور تم التقاطها من هواتف مختلفة ، في ظروف مختلفة وزوايا مختلفة. حالات البيتزا - 17 ك. مجموع الصور - 60 ك.
في رأيي ، فإن المهمة نموذجية تمامًا ومناسبة تمامًا لإظهار أساليب مختلفة لمعالجة البيانات. لحلها ، يجب عليك:
1. اختيار الصور حيث توجد قشرة بيتزا.
2. على الصور المحددة ، تسليط الضوء على الكعكة.
3. تدريب الشبكة العصبية في المناطق المختارة.
تصفية الصور
للوهلة الأولى ، يبدو أن أسهل طريقة هي إعطاء هذه المهمة للمشتركين ، ومن ثم تدريب مجموعة البيانات على البيانات النظيفة. ومع ذلك ، قررت أنه من الأسهل بالنسبة لي تحديد جزء صغير بنفسي من أن أشرح مع الناسخ أي زاوية كانت صحيحة. علاوة على ذلك ، لم يكن لدي معيار صعب للزاوية الصحيحة.
إذن هذا ما فعلته:
1. وضع علامة على 100 صورة حافة ؛

2. قمت بحساب الميزات بعد السحب العالمي من شبكة resnet-152 مع الأوزان من imagenet11k_places365 ؛
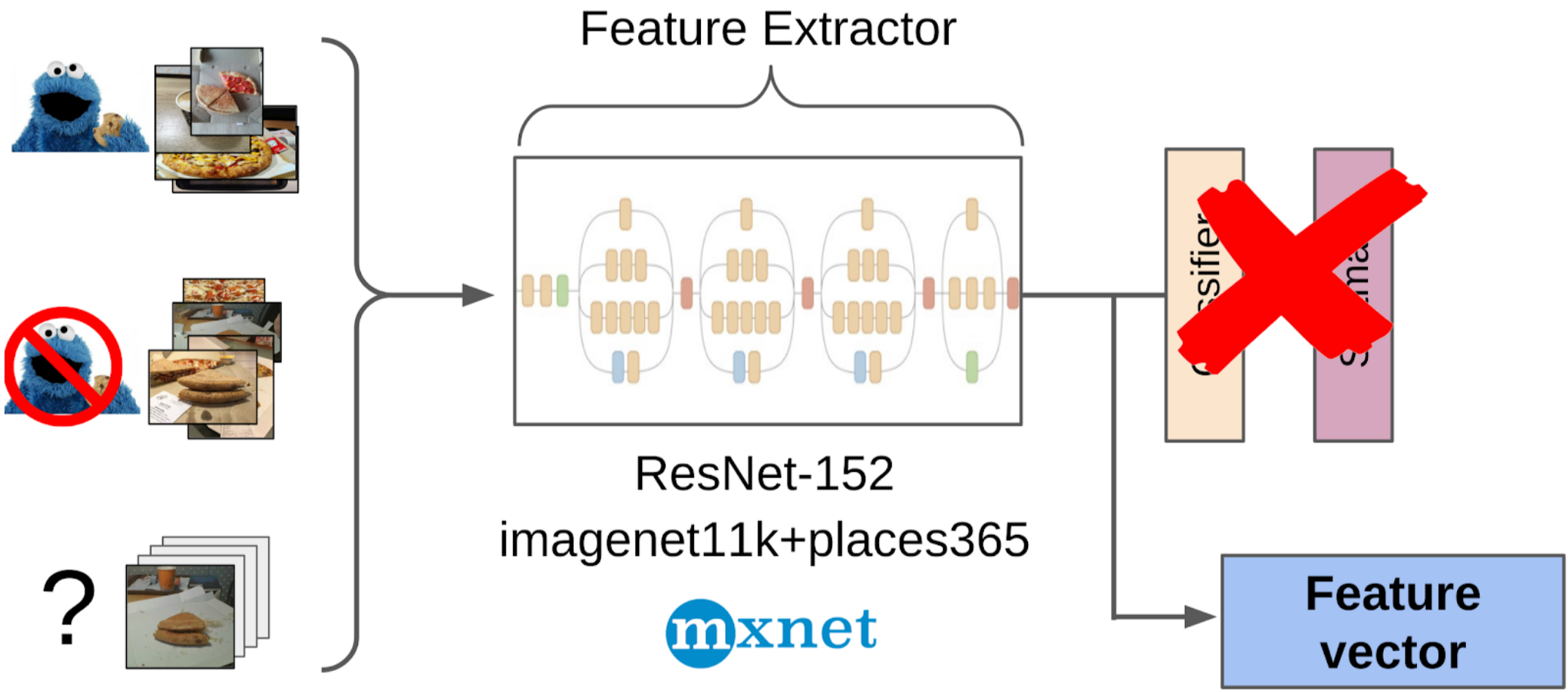
3. أخذ متوسط ميزات كل فئة ، حيث تلقى مرتكزين.
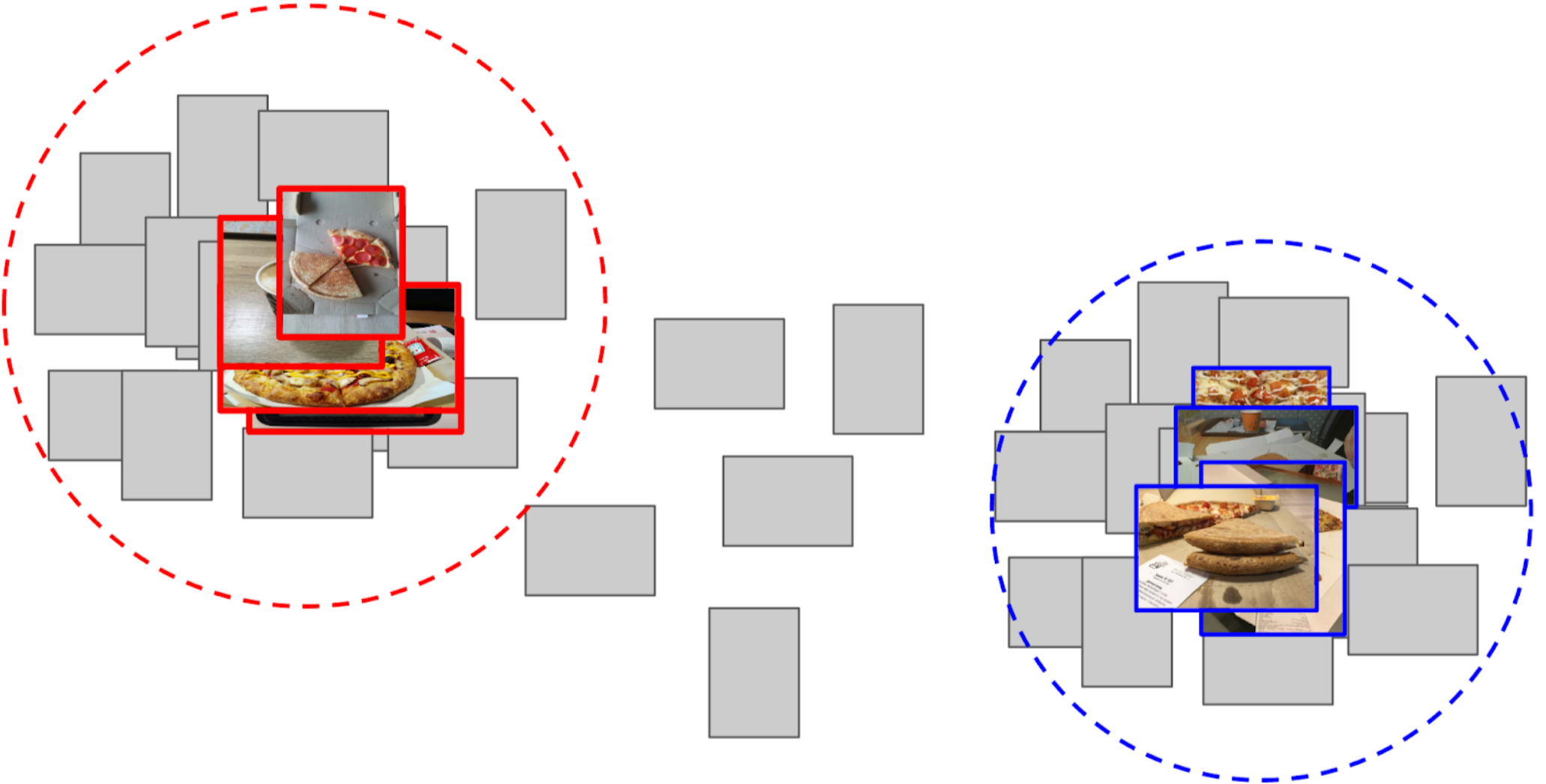
4. قمت بحساب المسافة من كل نقطة إرساء إلى جميع ميزات الصور المتبقية البالغ عددها 50 ألفًا ؛
5. أعلى 300 على مقربة من مرساة واحدة ذات صلة بالفئة الإيجابية ، أعلى 500 الأقرب إلى المرساة الأخرى سلبية ؛
6. لقد قمت بتدريب LightGBM على هذه العينات بنفس الميزات (يشار إلى XGboost في الصورة ، لأنه يحتوي على شعار ويمكن التعرف عليه بشكل أكبر ، لكن LightGBM ليس لديه شعار) ؛
7. باستخدام هذا النموذج ، حصلت على ترميز مجموعة البيانات بالكامل.

لقد استخدمت تقريبًا نفس النهج في مسابقات kaggle كخط
أساس .
شرح على الأصابع لماذا يعمل هذا النهجيمكن النظر إلى الشبكة العصبية على أنها تحول غير خطي قوي للصورة. في حالة التصنيف ، يتم تحويل الصورة إلى احتمالات الفئات التي كانت في مجموعة التدريب. ويمكن استخدام هذه الاحتمالات بشكل أساسي كميزات لـ Light GBM. ومع ذلك ، هذا وصف ضعيف إلى حد ما ، وفي حالة البيتزا ، سنقول أن فئة الكعكة هي 0.3 قطط و 0.7 كلاب بشكل مشروط ، والقمامة هي الباقية. بدلاً من ذلك ، يمكنك استخدام ميزات أقل تناقضًا بعد Global Average Pooling. لديهم مثل هذه الخاصية التي يتم إنشاء الميزات من عينات مجموعة التدريب ، والتي يجب فصلها بتحويل خطي (طبقة متصلة بالكامل مع Softmax). ومع ذلك ، نظرًا لعدم وجود بيتزا صريحة في قطار imagenet ، فمن الأفضل أن تأخذ تحولًا غير خطي في شكل أشجار لفصل فئات مجموعة التدريب الجديدة. من حيث المبدأ ، يمكنك الذهاب إلى أبعد من ذلك وأخذ ميزات من بعض الطبقات المتوسطة للشبكة العصبية. سيكونون أفضل من حيث أنهم لم يفقدوا بعد مكان الأشياء. لكنها أسوأ بكثير بسبب حجم ناقل الميزة. وإلى جانب ذلك ، فهي أقل خطية من أمام طبقة متصلة بالكامل.
انحراف طفيف
واشتكت المواد المستنفدة للأوزون مؤخرًا من أنه لا أحد يكتب عن فشلهم. تصحيح الوضع. منذ حوالي عام ، شاركت في مسابقة
Kaggle Sea Lions مع
Eugene Nizhibitsky . كانت المهمة هي حساب فقمة الفراء في الصور من الطائرة بدون طيار. تم تقديم الترميز ببساطة في شكل إحداثيات الذبيحة ، ولكن في مرحلة ما قام
فلاديمير إيغلوفيكوف بتمييزها بصناديق وشاركها بسخاء مع المجتمع. في ذلك الوقت ، اعتبرت نفسي
أبيًا من التجزئة الدلالية (بعد
Kaggle Dstl ) وقررت أن Unet سيسهل بشكل كبير مهمة العد إذا تعلمت تمييز القطط بشكل كلاسيكي.
شرح التجزئة الدلاليةالتقسيم الدلالي هو في الأساس تصنيف لكل بكسل على حدة. أي أن كل بكسل مصدر للصورة يجب أن يرتبط بفصل. في حالة التجزئة الثنائية (حالة المقالة) ، ستكون إما فئة إيجابية أو سلبية. في حالة التجزئة متعددة الطبقات ، سيتم تعيين فصل لكل بكسل من مجموعة التدريب (الخلفية ، العشب ، القط ، الرجل ، وما إلى ذلك). في حالة التجزئة الثنائية ، عملت بنية الشبكة العصبية
U-net بشكل جيد في ذلك الوقت. تتشابه هذه الشبكة العصبية في البنية مع جهاز التشفير التقليدي ، ولكن مع ميزات مرسلة من جزء التشفير إلى جهاز التشفير في مراحل الحجم المناسبة.

في شكل الفانيليا ، ومع ذلك ، لم يعد أحد يستخدمه ، ولكن على الأقل يضيفون Batch Norm. حسنًا ، كقاعدة عامة ، يأخذون جهاز
تشفير الدهون وينفخون جهاز التشفير. تم استبدال
البنى الشبيهة بشبكة U بشبكات تجزئة
FPN الجديدة ، والتي تُظهر أداءً جيدًا في بعض المهام. ومع ذلك ، لم تفقد البنى الشبيهة بـ Unet أهميتها حتى يومنا هذا. إنها تعمل بشكل جيد كخط أساس ، فهي سهلة التدريب ، ومن السهل جدًا تغيير عمق / حجم علم الأعصاب عن طريق تغيير رموز التشفير المختلفة.
وبناءً على ذلك ، بدأت في تعليم التجزئة ، كهدف في المرحلة الأولى فقط قطط الملاكمة. بعد المرحلة الأولى من التدريب ، توقعت القطار ونظرت كيف تبدو التوقعات. بمساعدة الاستدلال ، يمكن للمرء أن يختار الثقة المجردة من القناع ويقسم التنبؤات بشكل مشروط إلى مجموعتين: حيث كل شيء جيد وحيث كل شيء سيئ.

التوقعات التي يمكن فيها استخدام كل شيء جيدًا لتكرار التكرار التالي للنموذج. يمكن اختيار التنبؤات ، حيث يكون كل شيء سيئًا ، مع مناطق كبيرة بدون أختام ، وأيدي ملثمة ، ويتم إلقاءها أيضًا في القطار. وهكذا ، دربنا أنا ويوجين نموذجًا تكراريًا حتى تعلمنا تقطيع زعانف فقمة الفرو لكبار الأفراد.
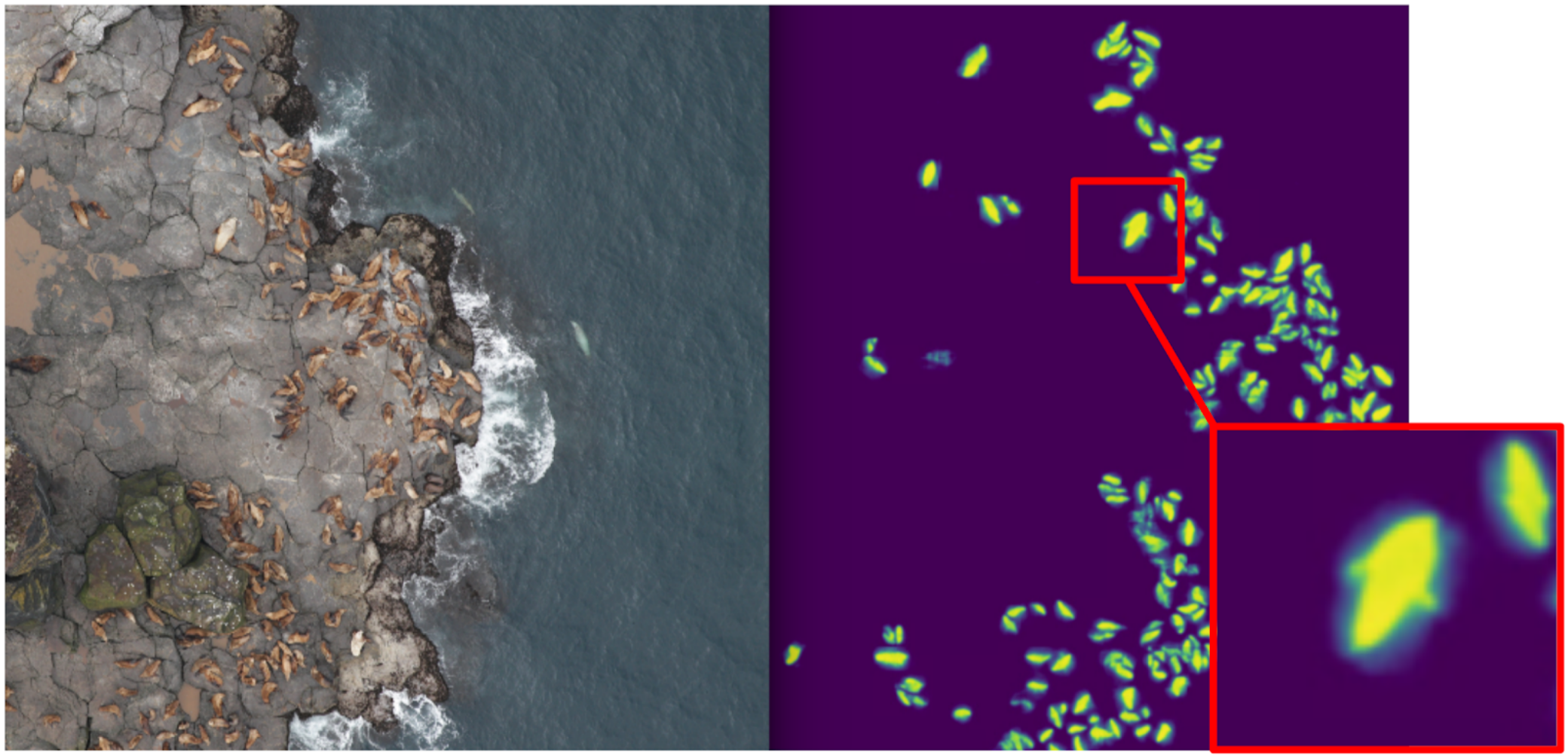
لكنها كانت فشلاً شرسًا: لقد أمضينا الكثير من الوقت في تعلم كيفية تقسيم القطط الرائعة و ... لم يساعد ذلك تقريبًا في حسابها. إن الافتراض بأن كثافة الأختام (عدد الأفراد لكل وحدة مساحة من القناع) ثابت لم ينجح ، لأن الطائرة بدون طيار على ارتفاعات مختلفة ، وكان للصور مقاييس مختلفة. وفي الوقت نفسه ، لا يزال التقسيم لا يميز الأفراد الفرديين إذا كانوا محاصرين - وهو ما حدث في كثير من الأحيان. وقبل
النهج المبتكر لفصل كائنات فريق Tocoder في DSB2018 ، كان هناك عام آخر. ونتيجة لذلك ، بقينا مع لا شيء ولكننا انتهينا في المركز 40 من أصل 600 فريق.
ومع ذلك ، خلصت إلى استنتاجين: التقسيم الدلالي هو نهج مناسب لتصور وتحليل تشغيل الخوارزمية ، ويمكن لحام الأقنعة من الصناديق ببعض الجهد.
ولكن نعود إلى البيتزا. من أجل إبراز الكعكة على الصور المحددة والمفلترة ، سيكون الخيار الأكثر صحة هو إعطاء المهمة للمشتركين. في ذلك الوقت ، قمنا بالفعل بتطبيق المربعات وخوارزمية التوافق عليها. لذلك قمت بإلقاء بضعة أمثلة وأعطيتها إلى الترميز. ونتيجة لذلك ، حصلت على 500 عينة بمساحة محددة بدقة من القشرة.
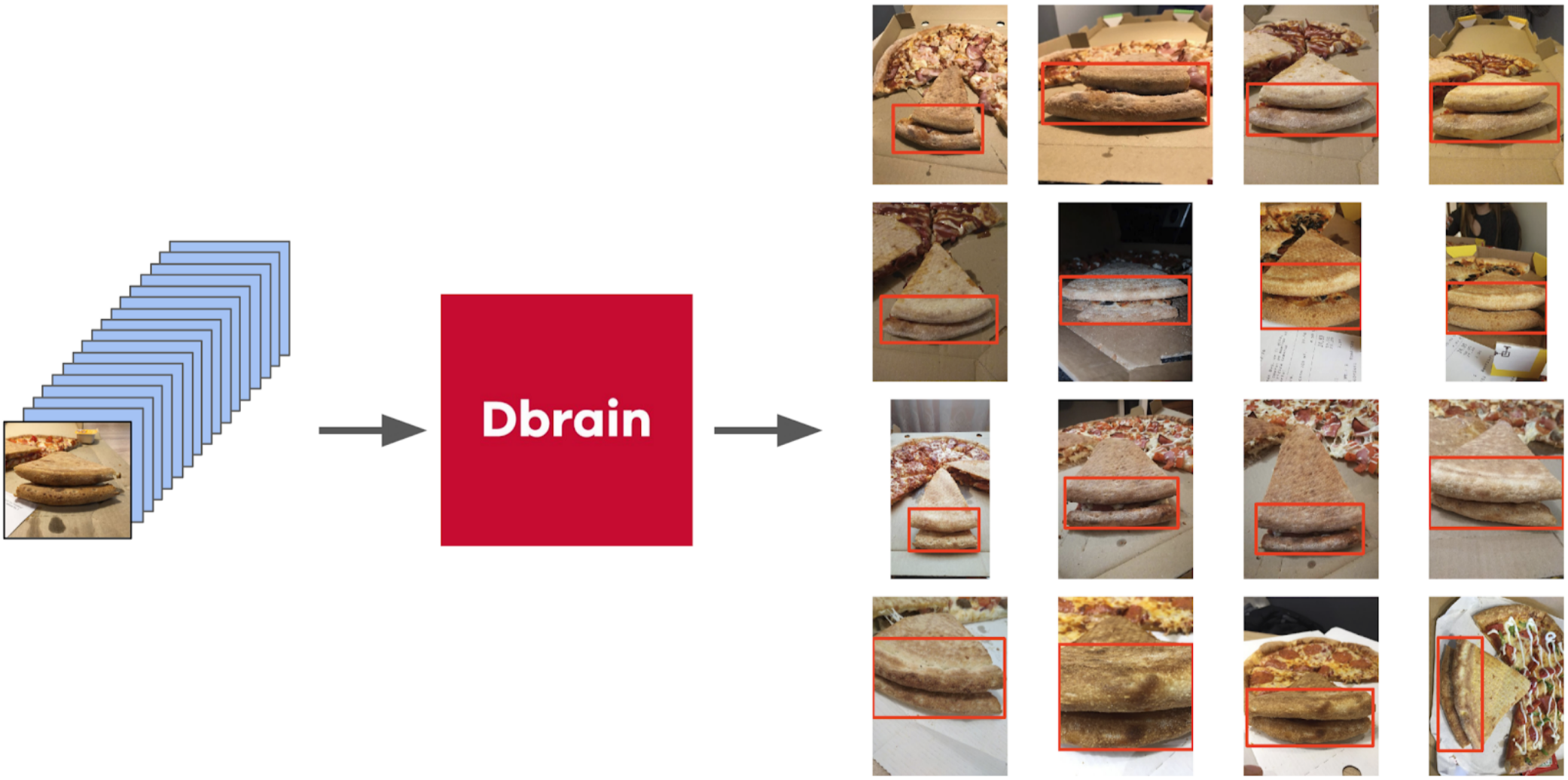
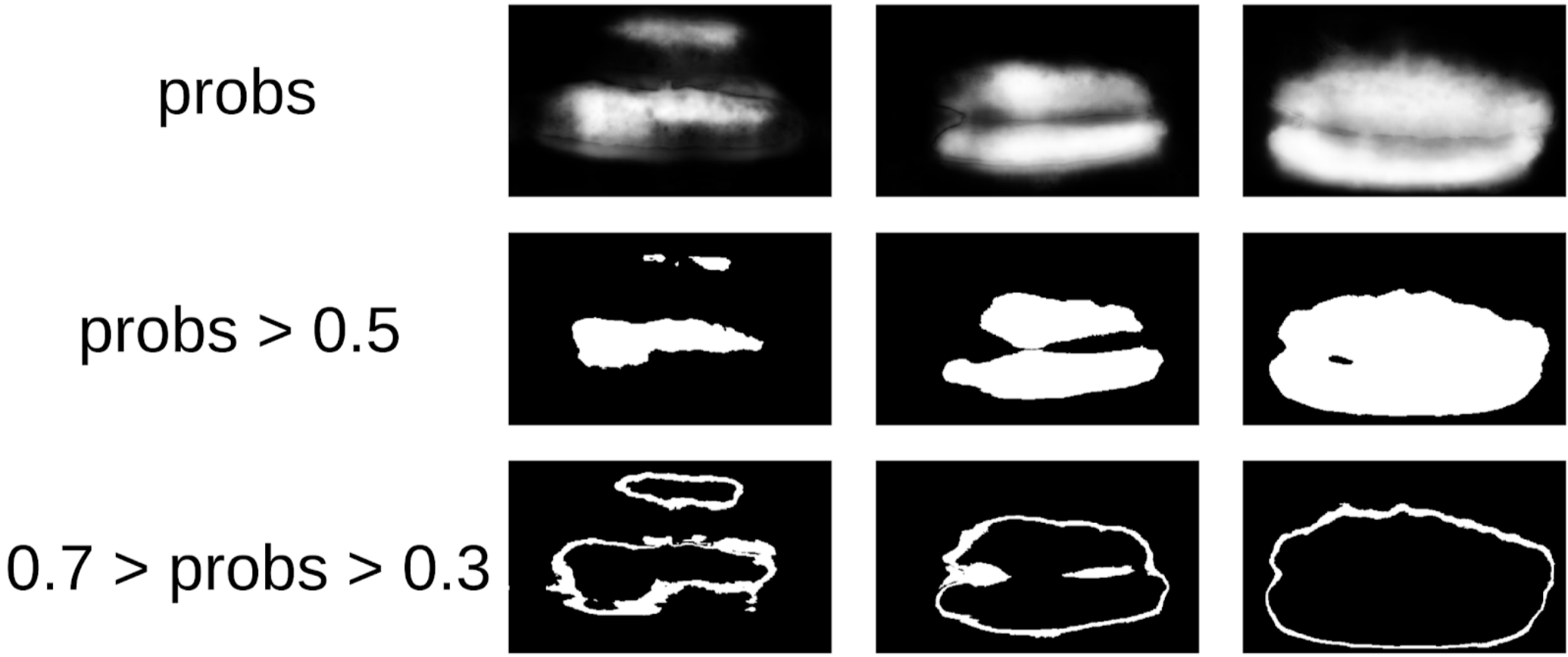
ثم استخرجت شفرتي من الأختام وتوجهت إلى الإجراء الحالي بشكل أكثر رسمية. بعد التكرار الأول للتدريب ، كان من الواضح أيضًا أنه تم تحديد النموذج بشكل خاطئ. ويمكن تحديد ثقة التوقعات على النحو التالي:
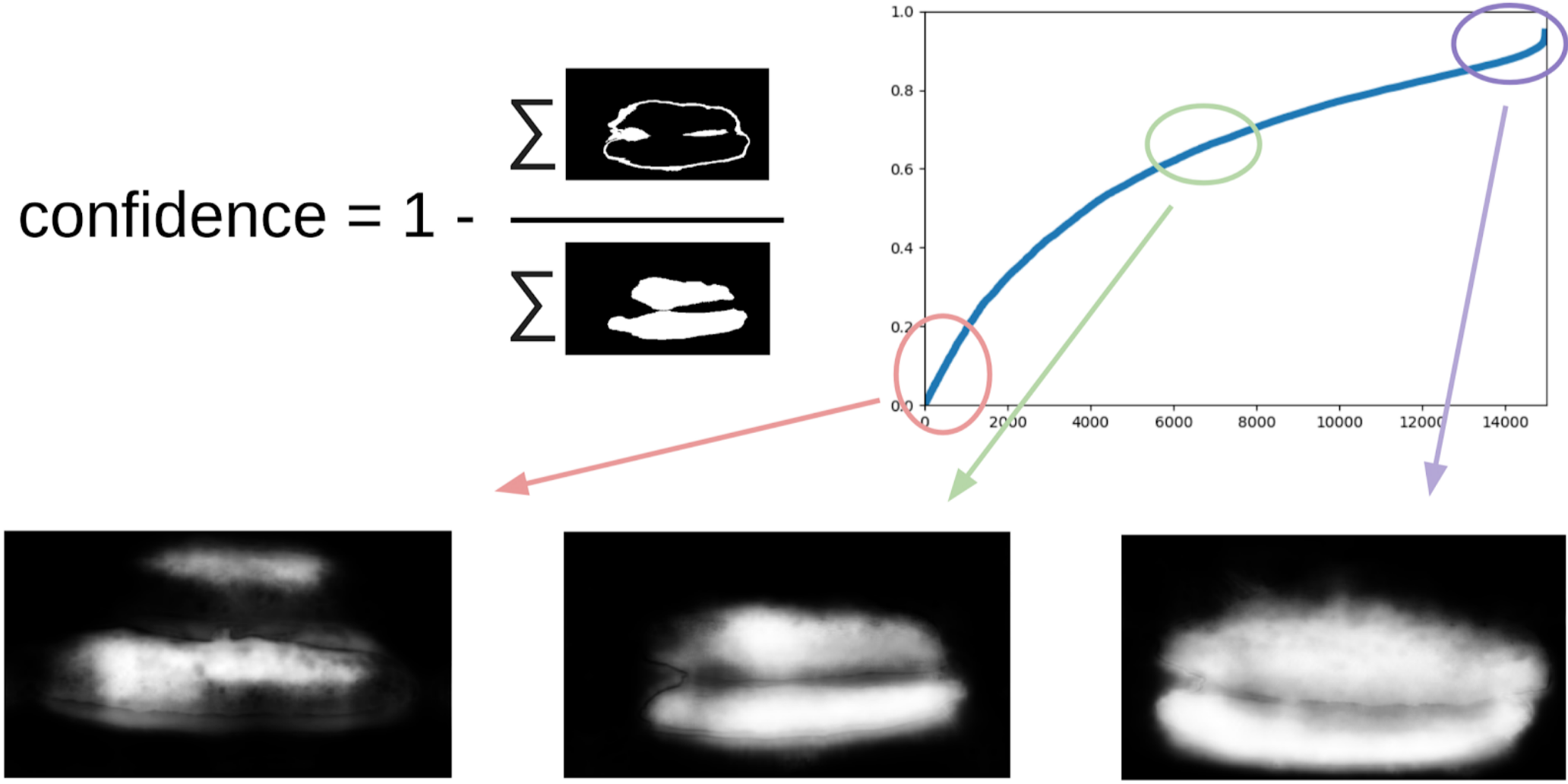
1 - (منطقة الرمادية) / (منطقة القناع) # سيكون هناك صيغة ، أعدك
الآن ، لإجراء التكرار التالي لسحب الصناديق على الأقنعة ، ستتنبأ مجموعة صغيرة بقطار TTA. يمكن اعتبار هذا إلى حد ما تقطير المعرفة WAAAAGH ، ولكن من الأصح استدعاء Pseudo Labeling.
بعد ذلك ، عليك أن تختار بعينيك عتبة معينة من الثقة ، بدءًا من تشكيلنا قطارًا جديدًا. وبشكل اختياري ، يمكنك تحديد العينات الأكثر تعقيدًا التي لم تستطع المجموعة التعامل معها. قررت أنه سيكون مفيدًا ، ورسمت حوالي 20 صورة في مكان ما أثناء هضم الغداء.
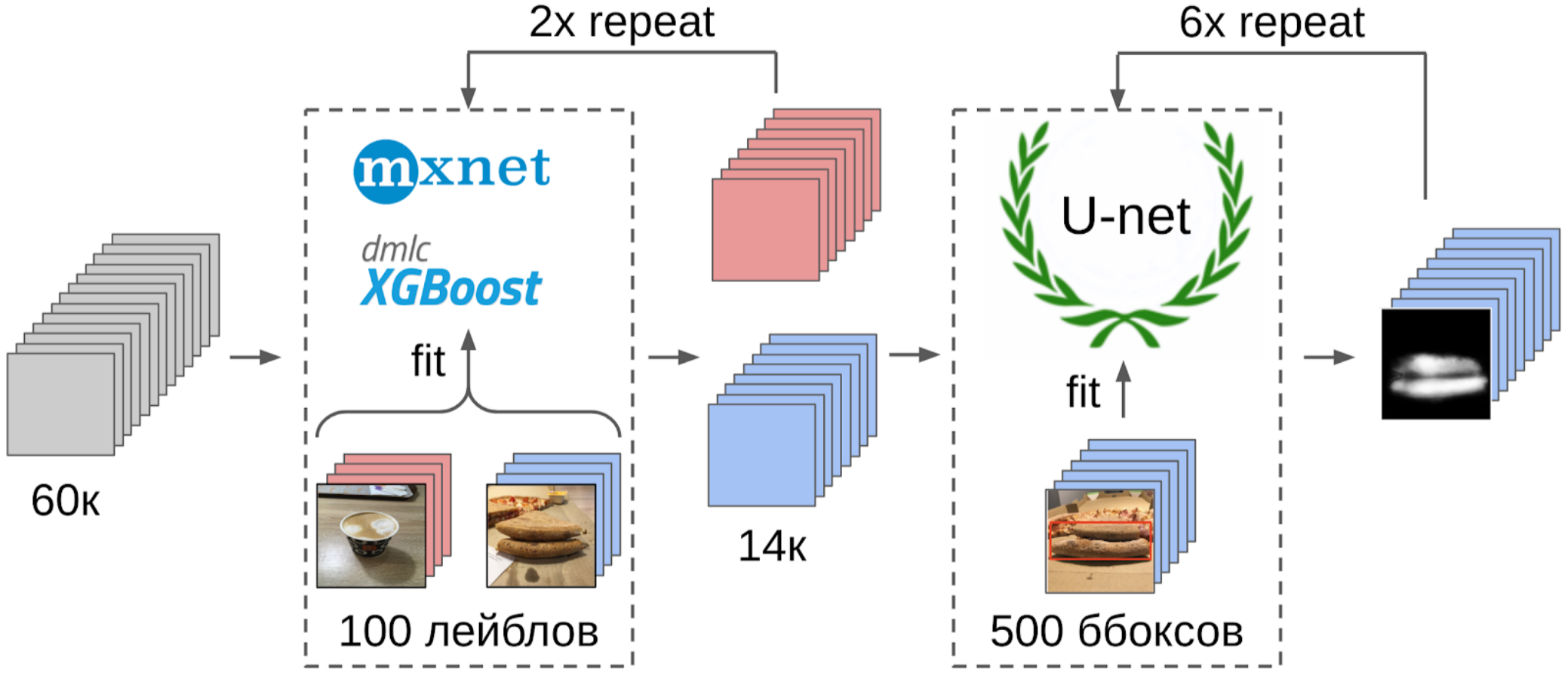
والآن الجزء الأخير من خط الأنابيب: نموذج التدريب. لإعداد العينات ، قمت باستخراج منطقة القناع من الكعكة. قمت أيضًا بتضخيم القناع قليلاً مع التوسيع وقمت بتطبيقه على الصورة لإزالة الخلفية ، حيث لا ينبغي أن تكون هناك معلومات حول جودة الاختبار. ثم قمت للتو بتقديم عدة نماذج من حديقة حيوانات Imagenet. في المجموع ، تمكنت من جمع حوالي 12 ألف عينة واثقة. لذلك ، لم أقم بتدريس الشبكة العصبية بأكملها ، ولكن فقط المجموعة الأخيرة من الالتواءات ، حتى لا يتم إعادة تدريب النموذج.
لماذا تحتاج إلى تجميد الطبقاتهناك ربحان من هذا: 1. تتعلم الشبكة بشكل أسرع ، لأنك لست بحاجة إلى قراءة التدرجات للطبقات المجمدة. 2. لم تتم إعادة تدريب الشبكة ، حيث تحتوي الآن على عدد أقل من المعلمات المجانية. يقال أن المجموعات القليلة الأولى من الالتواءات أثناء التدريب على Imagenet تولد علامات شائعة تمامًا مثل التحولات اللونية الحادة والقوام المناسب لفئة واسعة جدًا من الكائنات في التصوير الفوتوغرافي. هذا يعني أنه لا يمكنك تدريبهم أثناء Transer Learning.
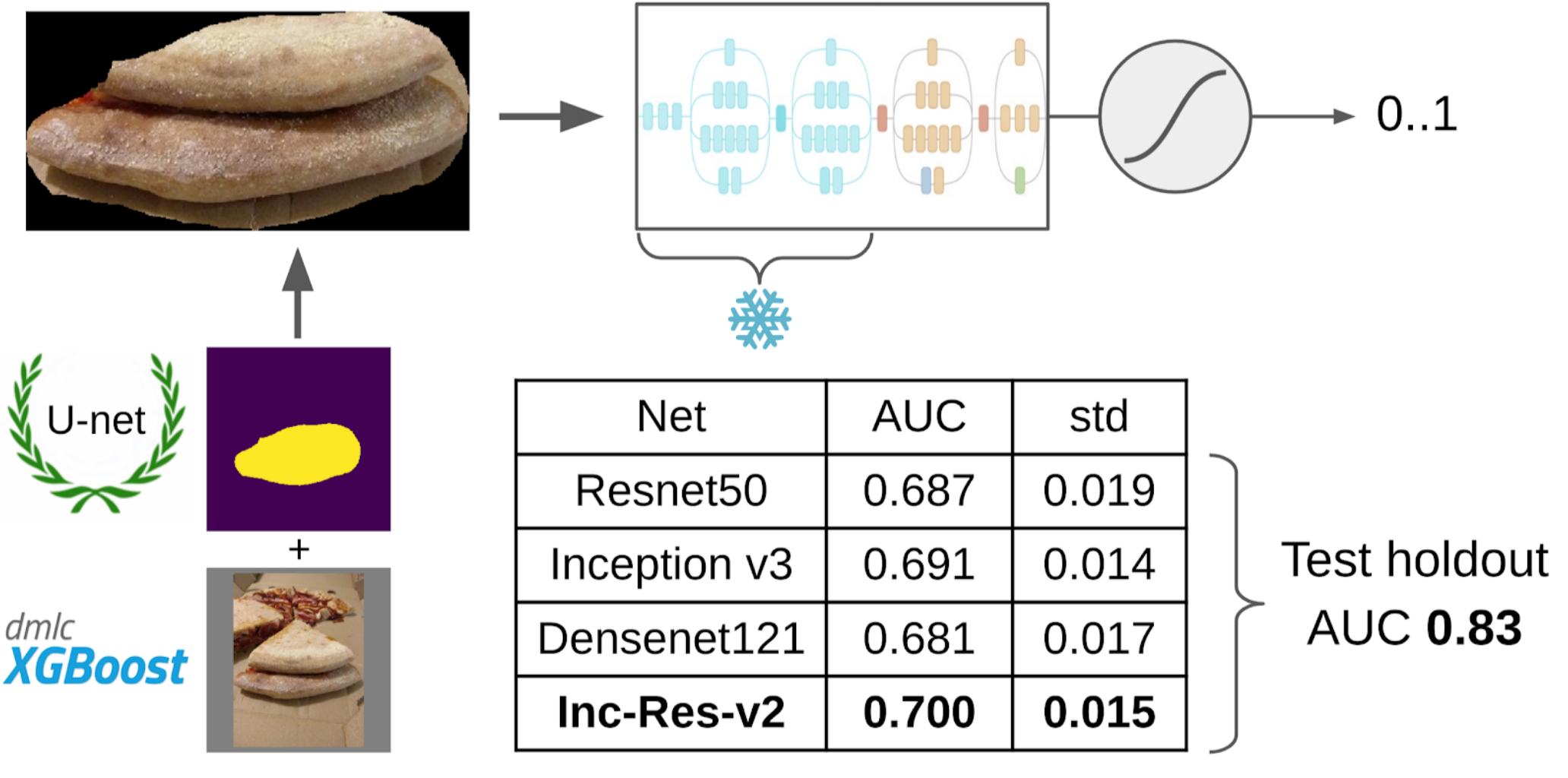
كان أفضل نموذج فردي هو Inception-Resnet-v2 ، وبالنسبة لها ، كان ROC-AUC على حظيرة واحدة 0.700. إذا لم تقم بتحديد أي شيء وإرسال الصور الخام كما هي ، فإن ROC-AUC هو 0.58. بينما كنت أقوم بتطوير الحل ، تم طهي الدفعة التالية من البيانات في بيتزا دودو ، وكان من الممكن اختبار خط الأنابيب بأكمله على معضلة صادقة. لقد تحققنا من خط الأنابيب بالكامل وحصلنا على ROC-AUC 0.83.
دعونا نلقي نظرة على الأخطاء الآن:
أعلى سلبي كاذب

يمكن أن نرى هنا أنها مرتبطة بخطأ في وضع علامة على الكعكة ، حيث توجد علامات واضحة على اختبار مدلل.
أعلى إيجابية كاذبة

هنا ترتبط الأخطاء بحقيقة أن النموذج الأول تم اختياره ليس بزاوية جيدة جدًا ، وبالتالي يصعب العثور على علامات رئيسية لجودة الاختبار.
الخلاصة
أحيانًا ما يزعجني الزملاء بأنني أحل العديد من المشكلات عن طريق التجزئة باستخدام Unet. ومع ذلك ، في رأيي ، هذا نهج قوي إلى حد ما ومريح. يسمح لك بتصور أخطاء النموذج وثقة تنبؤاته. بالإضافة إلى ذلك ، يبدو payline بأكمله بسيطًا جدًا ، والآن هناك مجموعة من المستودعات لأي إطار.