في هذه المقالة ، سنتحدث عن كيف ولماذا قمنا بتطوير
نظام التفاعل - آلية تنقل المعلومات بين تطبيقات العميل و 1 C: خوادم المؤسسة - من تعيين المهمة إلى التفكير من خلال تفاصيل الهندسة والتنفيذ.
نظام التفاعل (المشار إليه فيما يلي باسم CB) هو نظام رسائل موزع يتحمل الأخطاء مع تسليم مضمون. تم تصميم CB كخدمة محملة بشكل كبير مع قابلية عالية للتوسع ، وهي متاحة كخدمة عبر الإنترنت (يتم توفيرها بواسطة 1C) وكمنتج للدوران يمكن نشره على قدرات الخادم الخاصة به.
يستخدم CB التخزين الموزع
Hazelcast ومحرك البحث
Elasticsearch . سنتحدث أيضًا عن Java وكيف نقيس PostgreSQL أفقياً.

بيان المشكلة
لتوضيح سبب إنشاء نظام التفاعل ، سأخبرك قليلاً عن كيفية عمل تطوير تطبيقات الأعمال في 1C.
بادئ ذي بدء ، القليل عنا بالنسبة لأولئك الذين لا يعرفون حتى الآن ما نقوم به :) نحن نقوم بإنشاء منصة تكنولوجيا 1C: Enterprise. تتضمن المنصة أداة لتطوير تطبيقات الأعمال ، بالإضافة إلى وقت التشغيل ، والذي يسمح لتطبيقات الأعمال بالعمل في بيئة عبر الأنظمة الأساسية.
نموذج تطوير خادم العميل
تطبيقات الأعمال التي تم إنشاؤها على 1C: تعمل المؤسسة في بنية
خادم العميل ثلاثية المستويات "DBMS - خادم التطبيقات - العميل". يمكن تنفيذ رمز التطبيق المكتوب باللغة
المضمنة 1C على خادم التطبيق أو على العميل. يتم تنفيذ جميع الأعمال مع كائنات التطبيق (الدلائل والمستندات وما إلى ذلك) ، وكذلك القراءة والكتابة إلى قاعدة البيانات ، على الخادم فقط. يتم أيضًا تنفيذ وظيفة النماذج وواجهة الأوامر على الخادم. يتلقى العميل النماذج ويفتحها ويعرضها ، "يتواصل" مع المستخدم (تحذيرات ، أسئلة ...) ، حسابات صغيرة في النماذج التي تتطلب رد فعل سريع (على سبيل المثال ، مضاعفة السعر بالمبلغ) ، والعمل مع الملفات المحلية ، والعمل مع المعدات.
في رمز التطبيق ، يجب أن تشير رؤوس الإجراءات والوظائف بشكل صريح إلى المكان الذي سيتم فيه تنفيذ الرمز - باستخدام التوجيهات & على العميل / & على الخادم (& AtClient / & AtServer في إصدار اللغة الإنجليزية). سيصححني مطورو 1C الآن ، قائلين إن هناك بالفعل
المزيد من التوجيهات ، ولكن بالنسبة لنا هذا ليس ضروريًا الآن.
يمكن استدعاء رمز الخادم من رمز العميل ، ولكن لا يمكن استدعاء رمز العميل من رمز الخادم. هذا قيد أساسي قمنا به لعدد من الأسباب. على وجه الخصوص ، لأنه يجب كتابة رمز الخادم بحيث يتم تنفيذه بالتساوي ، بغض النظر عن المكان الذي يطلق عليه - من العميل أو من الخادم. وفي حالة استدعاء رمز الخادم من رمز خادم آخر ، يكون العميل غائبًا على هذا النحو. ولأنه أثناء تنفيذ رمز الخادم ، يمكن للعميل الذي تسبب في إغلاقه ، الخروج من التطبيق ، ولن يكون لدى الخادم أي شخص للاتصال به.
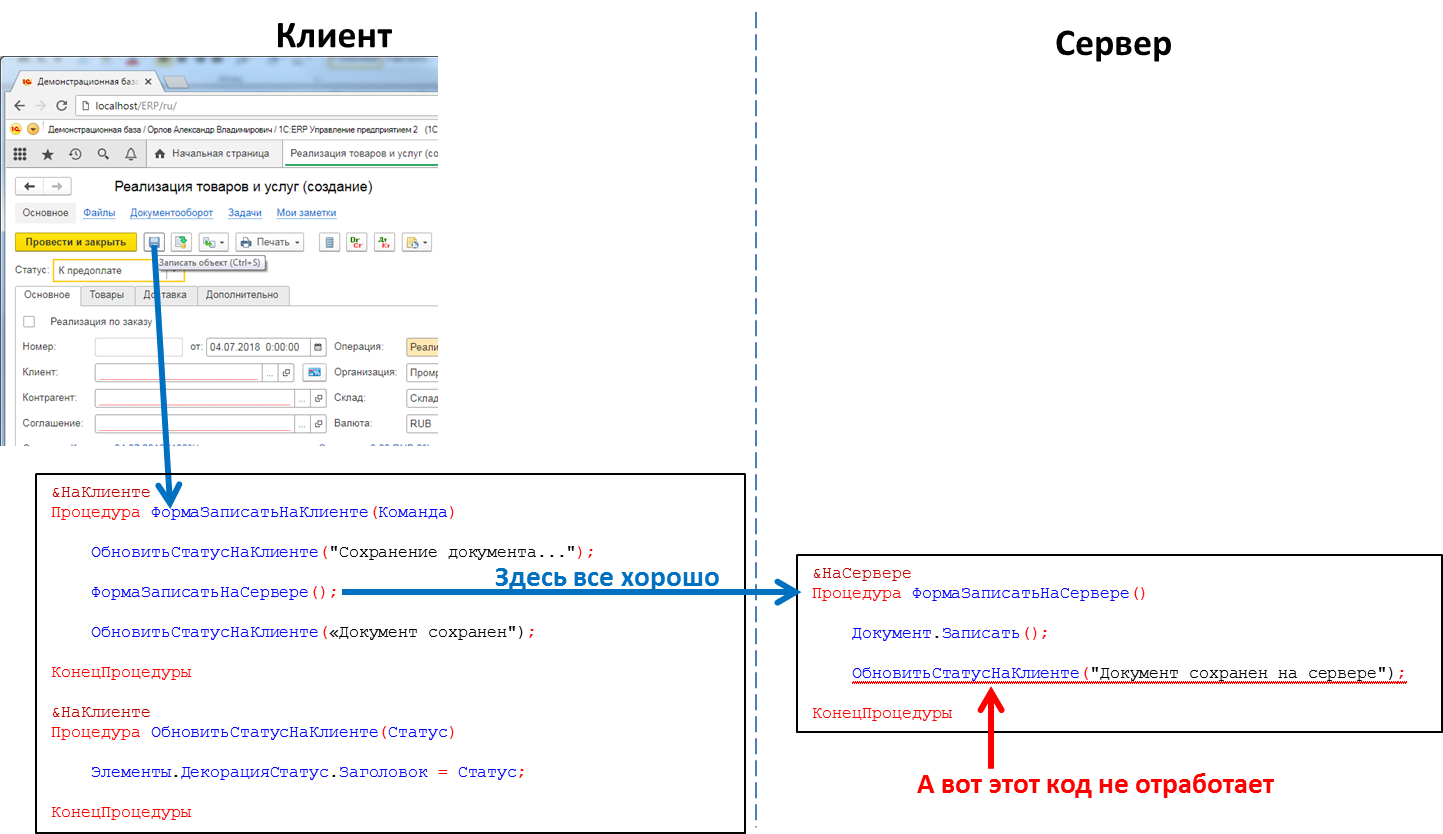 الرمز الذي يعالج النقر على الزر: ستعمل استدعاء إجراء الخادم من العميل ، ولن يعمل استدعاء إجراء العميل من الخادم
الرمز الذي يعالج النقر على الزر: ستعمل استدعاء إجراء الخادم من العميل ، ولن يعمل استدعاء إجراء العميل من الخادمهذا يعني أنه إذا أردنا إرسال بعض الرسائل إلى تطبيق العميل من الخادم ، على سبيل المثال ، أن تشكيل تقرير "التشغيل الطويل" قد انتهى ويمكن عرض التقرير ، فليس لدينا مثل هذه الطريقة. علينا أن نذهب إلى الحيل ، على سبيل المثال ، من رمز العميل لاستقصاء الخادم بشكل دوري. لكن هذا النهج يحمّل النظام بمكالمات غير ضرورية ، وفي الواقع لا يبدو أنيقًا للغاية.
وهناك أيضًا حاجة ، على سبيل المثال ، عند وصول مكالمة هاتفية لـ
SIP ، قم بإخطار تطبيق العميل بشأنها حتى يتمكن رقم المتصل من العثور عليها في قاعدة بيانات الطرف المقابل ويظهر معلومات المستخدم حول الطرف المقابل المتصل. أو ، على سبيل المثال ، عند استلام الطلب في المستودع ، قم بإخطار تطبيق العميل الخاص بهذا العميل. بشكل عام ، هناك العديد من الحالات التي تكون فيها هذه الآلية مفيدة.
انطلاق في الواقع
إنشاء محرك مراسلة. سريع وموثوق ، مع تسليم مضمون ، مع إمكانية البحث بمرونة عن الرسائل. بناءً على الآلية ، قم بتطبيق برنامج messenger (رسائل ، مكالمات فيديو) يعمل داخل تطبيقات 1C.
تصميم نظام قابل للقياس أفقيا. يجب إغلاق زيادة الحمل عن طريق زيادة عدد العقد.
التنفيذ
قررنا عدم تضمين جزء الخادم من CB مباشرة في النظام الأساسي 1C: Enterprise ، ولكن تنفيذه كمنتج منفصل ، والذي يمكن استدعاء API من رمز تطبيق 1C. تم ذلك لعدد من الأسباب ، كان أهمها جعل من الممكن تبادل الرسائل بين تطبيقات 1C المختلفة (على سبيل المثال ، بين إدارة التجارة والمحاسبة). يمكن تشغيل تطبيقات 1C المختلفة على إصدارات مختلفة من النظام الأساسي 1C: Enterprise ، وأن تكون على خوادم مختلفة ، إلخ. في مثل هذه الظروف ، يعتبر تنفيذ CB كمنتج منفصل يقع "على جانب" منشآت 1C هو الحل الأمثل.
لذا ، قررنا أن نجعل CB منتجًا منفصلًا. بالنسبة للشركات الصغيرة ، نوصي باستخدام خادم CB الذي قمنا بتثبيته في السحابة (wss: //1cdialog.com) لتجنب التكاليف المرتبطة بتثبيت الخادم وتكوينه محليًا. ومع ذلك ، قد يجد العملاء الكبار أنه من المناسب تثبيت خادم CB الخاص بهم في مرافقهم. استخدمنا نهجًا مشابهًا في منتج SaaS القائم على السحابة
1cFresh - يتم إصداره كمنتج تداول للتثبيت من قبل العملاء ويتم نشره أيضًا في سحبتنا
https://1cfresh.com/ .
التطبيق
لموازنة الحمل والتسامح مع الأخطاء ، لن ننشر تطبيق Java واحدًا ، ولكن عدة تطبيقات ، سنضع موازن تحميل أمامهم. إذا كنت بحاجة إلى نقل رسالة من عقدة إلى أخرى - استخدم النشر / الاشتراك في Hazelcast.
اتصال العميل بالخادم عن طريق websocket. وهي مناسبة تمامًا للأنظمة في الوقت الفعلي.
ذاكرة التخزين المؤقت الموزعة
اختر بين Redis و Hazelcast و Ehcache. في الفناء 2015. أطلقت Redis للتو مجموعة جديدة (جديدة للغاية ، مخيفة) ، هناك Sentinel مع مجموعة من القيود. لا يعرف Ehcache كيفية التجميع في مجموعة (ظهرت هذه الوظيفة لاحقًا). قررنا أن نحاول مع Hazelcast 3.4.
Hazelcast ذاهب إلى الكتلة خارج منطقة الجزاء. في وضع العقدة المفردة ، فهي ليست مفيدة للغاية ويمكن أن تتناسب فقط مع ذاكرة التخزين المؤقت - لا تعرف كيفية تفريغ البيانات إلى القرص ، فقد عقدة واحدة - فقد البيانات. ننشر العديد من ملفات Hazelcast التي نقوم بالنسخ الاحتياطي للبيانات المهمة فيما بينها. ذاكرة التخزين المؤقت ليست نسخة احتياطية - إنها ليست شفقة.
بالنسبة لنا ، Hazelcast هو:
- مستودع جلسات المستخدم. في كل مرة ، يعد الذهاب إلى قاعدة البيانات لجلسة ما وقتًا طويلاً ، لذلك نضع جميع الجلسات في Hazelcast.
- مخبأ. البحث عن ملف تعريف مستخدم - تحقق من ذاكرة التخزين المؤقت. كتب رسالة جديدة - ضعها في ذاكرة التخزين المؤقت.
- مواضيع لتوصيل مثيلات التطبيق. ينشئ Noda حدثًا ويضعه في موضوع Hazelcast. تتلقى عُقد التطبيق الأخرى المشتركة في هذا الموضوع وتعالج الحدث.
- أقفال الكتلة. على سبيل المثال ، ننشئ نقاشًا حول مفتاح فريد (مناقشة-فردية في إطار قاعدة بيانات 1C):
conversationKeyChecker.check(""); doInClusterLock("", () -> { conversationKeyChecker.check(""); createChannel(""); });
تم التحقق من عدم وجود قناة. أخذوا القفل ، فحصوا مرة أخرى ، خلقوا. إذا لم تتحقق من القفل بعد أخذها ، فهناك احتمال أن يتم فحص سلسلة رسائل أخرى في تلك اللحظة وستحاول الآن إنشاء نفس المناقشة - ولكنها موجودة بالفعل. من المستحيل القيام بالقفل من خلال قفل جافا المتزامن أو المعتاد. من خلال القاعدة - ببطء ، والقاعدة شفقة ، من خلال Hazelcast - ما تحتاجه.
اختيار DBMS
لدينا خبرة واسعة وناجحة في العمل مع PostgreSQL والتعاون مع مطوري DBMS هذا.
PostgreSQL ليس سهلاً مع المجموعة - فهو يحتوي على
XL ،
XC ،
Citus ، ولكن بشكل عام ، هذه ليست noSQL ، والتي تتسع خارج الصندوق. لم يكن NoSQL يعتبر المستودع الرئيسي ، كان يكفي أن نأخذ Hazelcast ، الذي لم نعمل معه من قبل.
نظرًا لأنك تحتاج إلى
قياس قاعدة بيانات علائقية ، فهذا يعني
المشاركة . كما تعلم ، عند التقسيم ، نقوم بتقسيم قاعدة البيانات إلى أجزاء منفصلة بحيث يمكن نقل كل منها إلى خادم منفصل.
تتضمن النسخة الأولى من تقسيم البيانات لدينا القدرة على توزيع كل من جداول تطبيقنا على خوادم مختلفة بنسب مختلفة. هناك الكثير من الرسائل على الخادم أ - من فضلك ، دعنا ننقل جزءًا من هذا الجدول إلى الخادم ب. مثل هذا الحل صرخ ببساطة حول التحسين المبكر ، لذلك قررنا أن نقتصر على نهج متعدد المستأجرين.
يمكنك أن
تقرأ عن متعدد المستأجرين ، على سبيل المثال ، على موقع
Citus Data .
في SV ، هناك مفاهيم للتطبيق والمشترك. التطبيق هو تثبيت محدد لتطبيق الأعمال ، مثل ERP أو المحاسبة ، مع المستخدمين وبيانات العمل. المشترك هو منظمة أو فرد تم تسجيل التطبيق نيابة عنه في خادم CB. يمكن للمشترك تسجيل عدة تطبيقات ، ويمكن لهذه التطبيقات تبادل الرسائل مع بعضها البعض. أصبح المشترك هو المستأجر في نظامنا. يمكن أن تكون رسائل العديد من المشتركين في قاعدة مادية واحدة ؛ إذا رأينا أن بعض المشتركين بدأوا في توليد الكثير من الحركة - فإننا نأخذها إلى قاعدة فعلية منفصلة (أو حتى خادم قاعدة بيانات منفصل).
لدينا قاعدة بيانات رئيسية حيث يتم تخزين جدول توجيه يحتوي على معلومات حول موقع جميع قواعد بيانات المشتركين.
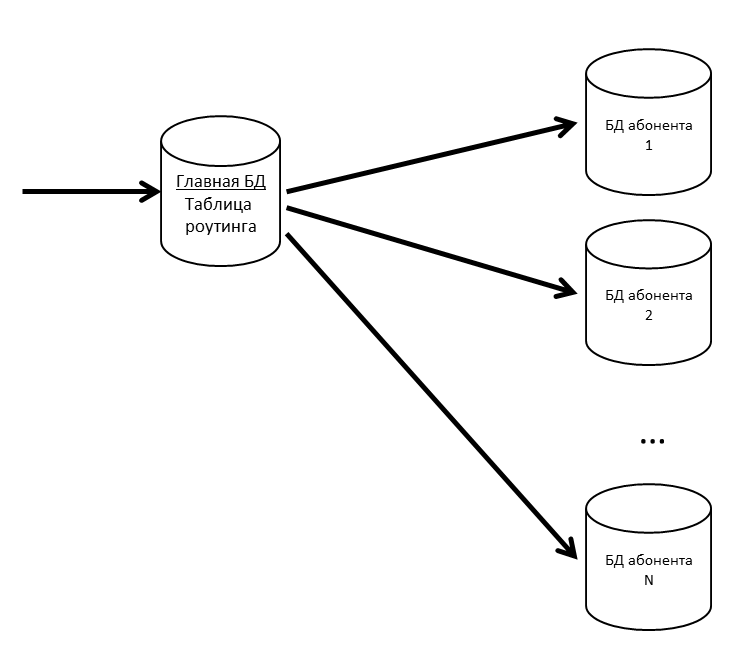
حتى لا تكون قاعدة البيانات الرئيسية اختناق ، فإننا نحتفظ بجدول التوجيه (والبيانات الأخرى المطلوبة بشكل متكرر) في ذاكرة التخزين المؤقت.
إذا بدأت قاعدة بيانات المشتركين في التباطؤ ، فسنقطعها إلى أقسام بالداخل. في مشاريع أخرى ، نستخدم pg_pathman لتقسيم الجداول الكبيرة.
نظرًا لأن فقدان رسائل المستخدم أمر سيء ، فإننا ندعم قواعد بياناتنا بالنسخ المتماثلة. يتيح لك الجمع بين النسخ المتزامنة وغير المتزامنة أن تكون آمنًا في حالة فقدان قاعدة البيانات الرئيسية. يحدث فقدان الرسالة فقط في حالة الفشل المتزامن لقاعدة البيانات الرئيسية والنسخة المتزامنة الخاصة بها.
إذا فقدت النسخة المتزامنة ، تصبح النسخة المتزامنة غير المتزامنة.
إذا فقدت قاعدة البيانات الرئيسية ، تصبح النسخة المتزامنة قاعدة البيانات الرئيسية ، وتصبح النسخة المتماثلة غير المتزامنة هي النسخة المتماثلة المتزامنة.
البحث المرن للبحث
نظرًا لأن CB ، من بين أمور أخرى ، هو أيضًا رسول ، فنحن بحاجة إلى بحث سريع ومريح ومرن ، مع الأخذ في الاعتبار التشكل ، عن طريق المطابقات غير الدقيقة. قررنا عدم إعادة اختراع العجلة واستخدام محرك بحث Elasticsearch المجاني ، استنادًا إلى مكتبة
Lucene . نقوم أيضًا بنشر Elasticsearch في مجموعة (رئيسية - بيانات - بيانات) للقضاء على المشاكل في حالة فشل عقد التطبيق.
على github ، وجدنا مكونًا إضافيًا
للمورفولوجيا الروسية لـ Elasticsearch واستخدامه. في فهرس Elasticsearch ، نقوم بتخزين جذور الكلمات (التي يحددها البرنامج المساعد) و N-grams. عندما يقوم المستخدم بإدخال النص للبحث ، نبحث عن النص المكتوب بين N-grams. عند تخزينها في الفهرس ، سيتم تقسيم كلمة "نصوص" إلى N-grams التالية:
[تلك ، التكنولوجيا ، tex ، النص ، النصوص ، ek ، eks ، ekst ، eksts ، ks ، kst ، kst ، kst ، st ، st ، أنت] ،
وكذلك سيتم حفظ جذر كلمة "نص". يسمح لك هذا الأسلوب بالبحث في البداية وفي المنتصف وفي نهاية الكلمة.
الصورة العامة
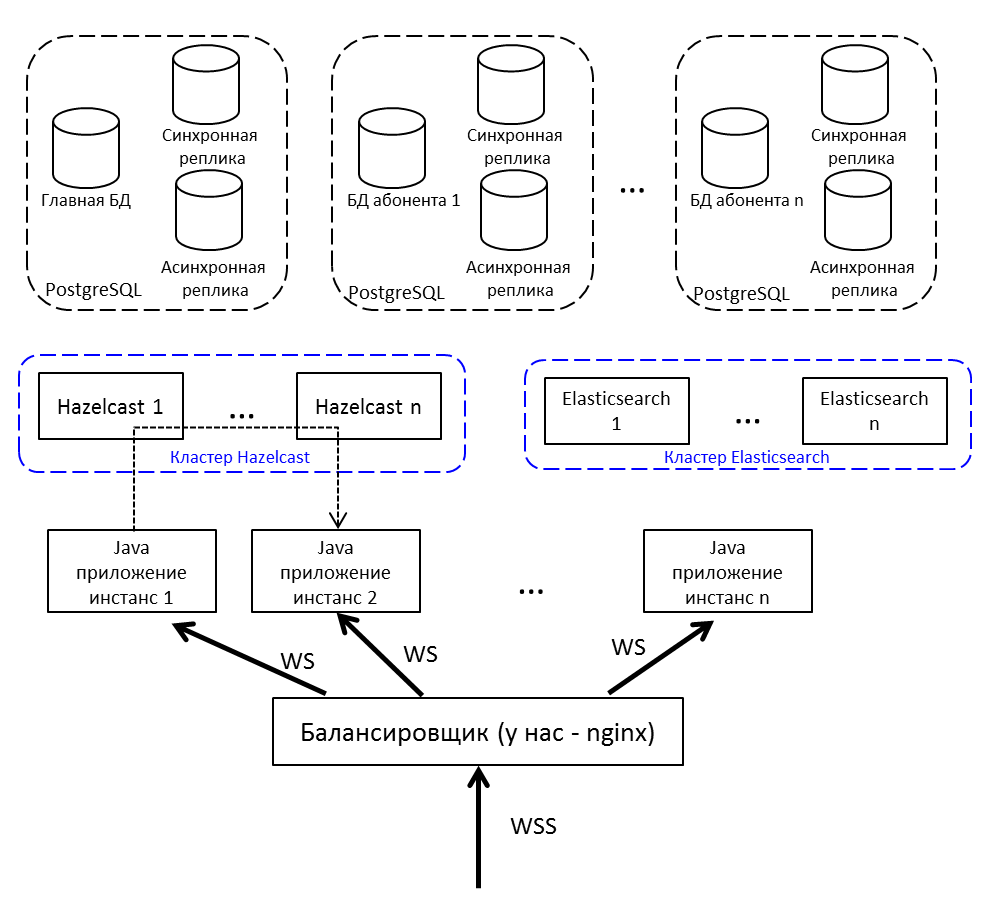
تكرار الصورة من بداية المقال ولكن بشرح:
- موازن الإنترنت لدينا nginx ، يمكن أن يكون أي.
- تتواصل مثيلات تطبيقات Java مع بعضها البعض من خلال Hazelcast.
- للعمل مع مقبس ويب نستخدم Netty .
- يتكون تطبيق Java المكتوب بلغة Java 8 ، من حزم OSGi . الخطط - الهجرة إلى Java 10 والانتقال إلى الوحدات النمطية.
التطوير والاختبار
في عملية تطوير واختبار CB ، واجهنا عددًا من الميزات المثيرة للاهتمام للمنتجات التي نستخدمها.
اختبار الحمل وتسرب الذاكرة
الافراج عن كل إطلاق CB هو اختبار الإجهاد. كانت ناجحة عندما:
- عمل الاختبار لعدة أيام ولم يكن هناك رفض للخدمة
- لم يتجاوز وقت الاستجابة للعمليات الرئيسية عتبة مريحة
- انخفاض الأداء مقارنة بالإصدار السابق لا يزيد عن 10٪
نملأ قاعدة الاختبار بالبيانات - ولهذا نحصل على معلومات حول أكثر المشتركين نشاطًا من خادم الإنتاج ، ونضرب أرقامه في 5 (عدد الرسائل والمناقشات والمستخدمين) ولذا نقوم باختبارها.
نقوم بإجراء اختبار الحمل لنظام التفاعل في ثلاثة تكوينات:
- اختبار الإجهاد
- اتصالات فقط
- تسجيل المشتركين
أثناء اختبار الإجهاد ، نبدأ عدة مئات من سلاسل المحادثات ، ويقومون بدون توقف بتحميل النظام: كتابة الرسائل وإنشاء المناقشات والحصول على قائمة بالرسائل. نقوم بمحاكاة إجراءات المستخدمين العاديين (الحصول على قائمة برسائلي غير المقروءة ، والكتابة إلى شخص ما) والحلول البرمجية (نقل حزمة من تكوين مختلف ، ومعالجة الإخطار).
على سبيل المثال ، هذا جزء من اختبار الضغط:
- يقوم المستخدم بتسجيل الدخول.
- طلبات المناقشات غير المقروءة
- فرصة 50٪ لقراءة الرسائل
- باحتمال 50٪ يكتب رسائل
- المستخدم التالي:
- مع احتمال 20٪ يخلق مناقشة جديدة.
- يختار عشوائيا أي من مناقشاته
- يذهب في الداخل
- طلبات الرسائل وملفات تعريف المستخدمين
- إنشاء خمس رسائل موجهة إلى مستخدمين عشوائيين من هذه المناقشة.
- خارج النقاش
- يكرر 20 مرة
- تسجيل الخروج ، يعود إلى بداية البرنامج النصي
- يدخل روبوت الدردشة إلى النظام (يحاكي تبادل الرسائل من رمز الحلول المطبقة)
- باحتمال 50٪ يخلق قناة جديدة لتبادل البيانات (مناقشة خاصة)
- باحتمال 50٪ يكتب رسالة إلى أي من القنوات الموجودة
ظهر سيناريو "الاتصالات فقط" لسبب ما. هناك موقف: قام المستخدمون بتوصيل النظام ، ولكنهم لم يشاركوا بعد. يقوم كل مستخدم في الساعة 09:00 بتشغيل الكمبيوتر وإنشاء اتصال بالخادم وهو صامت. هؤلاء الأشخاص خطرون ، هناك الكثير منهم - من الحزم التي لديهم PING / PONG فقط ، لكنهم يحافظون على الاتصال بالخادم (لا يمكنهم الاحتفاظ به - ولكن فجأة رسالة جديدة). يعيد الاختبار إظهار الموقف عندما يحاول عدد كبير من هؤلاء المستخدمين خلال نصف ساعة تسجيل الدخول إلى النظام. يبدو وكأنه اختبار ضغط ، لكنه يركز بدقة على هذا المدخل الأول - حتى لا يكون هناك إخفاقات (لا يستخدم الشخص النظام ، ولكنه يسقط بالفعل - من الصعب التوصل إلى شيء أسوأ).
سيناريو تسجيل المشترك ينشأ من الإطلاق الأول. لقد أجرينا اختبار الإجهاد وكنا متأكدين من أن النظام لا يتباطأ في المراسلات. لكن المستخدمين ذهبوا وبدأ التسجيل ينخفض في مهلة. عند التسجيل ، استخدمنا
/ dev / عشوائي ، والذي يرتبط بإنتروبيا النظام. لم يتمكن الخادم من تجميع ما يكفي من الإنتروبيا والتجميد لعشرات الثواني عند طلب SecureRandom جديد. هناك العديد من الطرق للخروج من هذا الموقف ، على سبيل المثال: التبديل إلى الأقل أمانًا / dev / urandom ، ووضع لوحة خاصة تولد الإنتروبيا ، وإنشاء أرقام عشوائية مقدمًا وتخزينها في التجمع. لقد أغلقنا المشكلة مؤقتًا مع أحد المجموعات ، ولكننا منذ ذلك الحين نجري اختبارًا منفصلاً لتسجيل المشتركين الجدد.
كمولد تحميل نستخدم
JMeter . لا يعرف كيف يعمل مع مقبس ويب ؛ هناك حاجة إلى مكون إضافي. أول نتائج البحث عن "jmeter websocket" هي
مقالات باستخدام BlazeMeter ، والتي توصي باستخدام
مكون إضافي من Maciej Zaleski .
معه قررنا أن نبدأ.
على الفور بعد بدء الاختبار الجاد ، وجدنا أن تسرب الذاكرة بدأ في JMeter.
البرنامج المساعد عبارة عن قصة كبيرة منفصلة ، مع 176 نجمة ولها 132 شوكة على جيثب. لم يلتزم المؤلف نفسه بها منذ عام 2015 (أخذناها في عام 2015 ، ثم لم يثر ذلك الشك) ، والعديد من مشكلات github حول تسرب الذاكرة ، و 7 طلبات سحب غير مغلقة.
إذا قررت إجراء اختبار الحمل باستخدام هذا البرنامج المساعد ، انتبه إلى المناقشات التالية:
- في بيئة متعددة الخيوط ، تم استخدام LinkedList المعتادة ، ونتيجة لذلك ، حصلوا على NPE في وقت التشغيل. يتم حلها إما عن طريق التبديل إلى ConcurrentLinkedDeque ، أو عن طريق الكتل المتزامنة. اختاروا الخيار الأول لأنفسهم ( https://github.com/maciejzaleski/JMeter-WebSocketSampler/issues/43 ).
- تسرب الذاكرة ، لا يؤدي الفصل إلى حذف معلومات الاتصال ( https://github.com/maciejzaleski/JMeter-WebSocketSampler/issues/44 ).
- في وضع الدفق (عندما لا يتم إغلاق مقبس الويب في نهاية العينة ، ولكن يتم استخدامه بشكل أكبر في الخطة) ، لا تعمل أنماط الاستجابة ( https://github.com/maciejzaleski/JMeter-WebSocketSampler/issues/19 ).
هذه واحدة من تلك الموجودة على جيثب. ماذا فعلنا:
- أخذوا شوكة Elyran Kogan (elyrank) - تم إصلاح المشاكل 1 و 3 فيه
- حل المشكلة 2
- تحديث رصيف الميناء من 9.2.14 إلى 9.3.12
- ملفوفة SimpleDateFormat في ThreadLocal ؛ SimpleDateFormat ليس آمنًا للخيط ، مما أدى إلى وقت تشغيل NPE
- إزالة تسرب آخر للذاكرة (تم إغلاق الاتصال بشكل غير صحيح عند قطع الاتصال)
ومع ذلك يتدفق!
بدأت الذاكرة لا تنتهي في يوم واحد ، ولكن في يومين. لم يكن هناك وقت متبقي على الإطلاق ، قرروا تشغيل عدد أقل من الخيوط ، ولكن على أربعة وكلاء. كان ينبغي أن يكون ذلك كافيا لمدة أسبوع على الأقل.
لقد مرت يومين ...
الآن بدأت الذاكرة تنفد في Hazelcast. كان من الواضح في السجلات أنه بعد يومين من الاختبار ، يبدأ Hazelcast في الشكوى من نقص الذاكرة ، وبعد فترة ، تنهار الكتلة ، وتستمر العقد في الموت بشكل فردي. قمنا بتوصيل JVisualVM بالبندق وشاهدنا "منشارًا صاعدًا" - كان يتصل بانتظام بـ GC ، لكنه لم يستطع مسح ذاكرته.
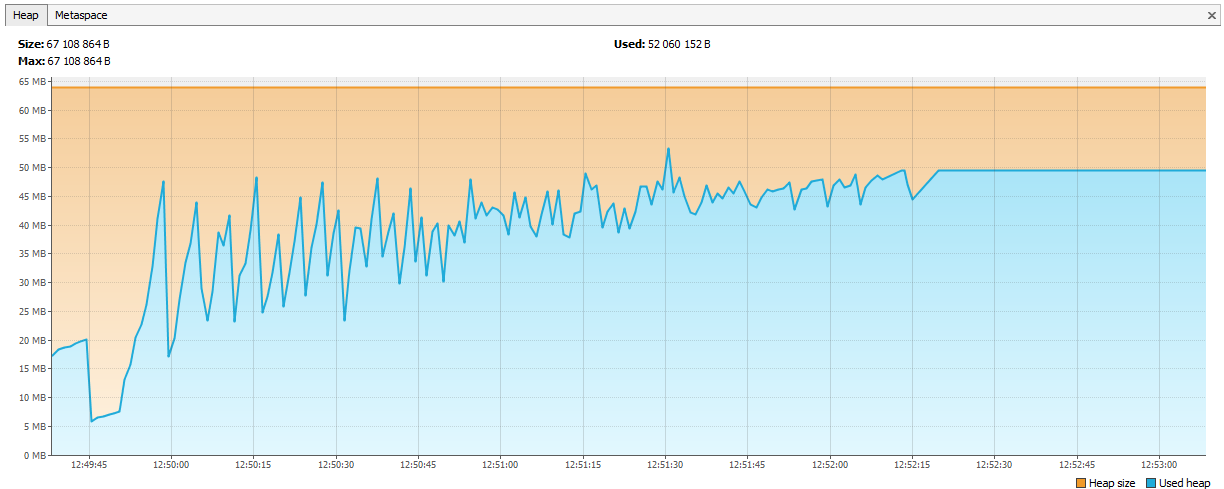
اتضح أنه في الإصدار 3.4 من البندق ، عند إزالة map / multiMap (map.destroy ()) ، لا يتم تحرير الذاكرة بالكامل:
github.com/hazelcast/hazelcast/issues/6317github.com/hazelcast/hazelcast/issues/4888الآن تم إصلاح الخطأ في 3.5 ، ولكن بعد ذلك كانت مشكلة. قمنا بإنشاء خرائط متعددة جديدة بأسماء ديناميكية وحذفها وفقًا لمنطقنا. يبدو الرمز مثل هذا:
public void join(Authentication auth, String sub) { MultiMap<UUID, Authentication> sessions = instance.getMultiMap(sub); sessions.put(auth.getUserId(), auth); } public void leave(Authentication auth, String sub) { MultiMap<UUID, Authentication> sessions = instance.getMultiMap(sub); sessions.remove(auth.getUserId(), auth); if (sessions.size() == 0) { sessions.destroy(); } }
اتصل:
service.join(auth1, "____UUID1"); service.join(auth2, "____UUID1");
تم إنشاء خريطة متعددة لكل اشتراك وتم حذفها عند عدم الحاجة إليها. قررنا أننا سنبدأ Map <String، Set> ، وسيكون المفتاح هو اسم الاشتراك ، وستكون القيم هي معرفات الجلسات (التي يمكنك من خلالها الحصول على معرفات المستخدم ، إذا لزم الأمر).
public void join(Authentication auth, String sub) { addValueToMap(sub, auth.getSessionId()); } public void leave(Authentication auth, String sub) { removeValueFromMap(sub, auth.getSessionId()); }
تقويم المخططات.
ماذا تعلمنا أيضًا عن اختبار الإجهاد
- يحتاج JSR223 إلى الكتابة في ذاكرة التخزين المؤقت لتجميع رائع وممكن - وهذا أسرع بكثير. رابط
- مخططات Jmeter-Plugins أسهل في الفهم من المعيار. رابط
حول تجربتنا مع Hazelcast
كان Hazelcast منتجًا جديدًا بالنسبة لنا ، وقد بدأنا العمل معه من الإصدار 3.4.1 ، والآن أصبح خادم الإنتاج لدينا الإصدار 3.9.2 (في وقت كتابة هذا التقرير ، كان أحدث إصدار من Hazelcast 3.10).
توليد الهوية
بدأنا بمعرفات صحيحة. دعونا نتخيل أننا بحاجة إلى Long أخرى لكيان جديد. لا يتناسب التسلسل مع قاعدة البيانات ، وتشارك الجداول في التقسيم - يتبين أن هناك معرّف الرسالة = 1 في DB1 ومعرف الرسالة = 1 في DB2 ، لا يمكنك وضع هذا المعرّف في Elasticsearch ، إما في Hazelcast ، ولكن أسوأ شيء هو إذا كنت ترغب في تقليل البيانات من قاعدتي بيانات إلى واحدة (على سبيل المثال ، تقرير أن قاعدة بيانات واحدة كافية لهؤلاء المشتركين). يمكنك إنشاء عدة AtomicLongs في Hazelcast والحفاظ على العداد هناك ، ثم يكون أداء الحصول على معرف جديد هو زيادة والحصول على وقت طلب في Hazelcast. ولكن هناك شيء أكثر مثالية حول Hazelcast - FlakeIdGenerator. يتم منح كل عميل نطاق معرف عند الاتصال ، على سبيل المثال ، الأول من 1 إلى 10000 ، والثاني من 10100 إلى 20000 ، وما إلى ذلك. الآن يمكن للعميل إصدار معرفات جديدة بشكل مستقل حتى ينتهي النطاق الصادر إليه. يعمل بسرعة ، ولكن عند إعادة تشغيل التطبيق (وعميل Hazelcast) ، يبدأ تسلسل جديد - ومن ثم الفجوات ، إلخ. بالإضافة إلى ذلك ، لم يتضح المطورون تمامًا لماذا تكون المعرفات عددًا صحيحًا ، لكنها تختلف بشكل مختلف. كلنا وزننا وانتقلنا إلى UUIDs.
بالمناسبة ، بالنسبة لأولئك الذين يريدون أن يكونوا مثل Twitter ، هناك مكتبة Snowcast - هذا تنفيذ Snowflake على رأس Hazelcast. يمكنك رؤيتها هنا:
github.com/noctarius/snowcastgithub.com/twitter/snowflakeلكننا لم نصل إلى يديها.
TransactionalMap.replace
مفاجأة أخرى: TransactionalMap.replace لا يعمل. هنا اختبار:
@Test public void replaceInMap_putsAndGetsInsideTransaction() { hazelcastInstance.executeTransaction(context -> { HazelcastTransactionContextHolder.setContext(context); try { context.getMap("map").put("key", "oldValue"); context.getMap("map").replace("key", "oldValue", "newValue"); String value = (String) context.getMap("map").get("key"); assertEquals("newValue", value); return null; } finally { HazelcastTransactionContextHolder.clearContext(); } }); } Expected : newValue Actual : oldValue
اضطررت إلى كتابة الاستبدال باستخدام getForUpdate:
protected <K,V> boolean replaceInMap(String mapName, K key, V oldValue, V newValue) { TransactionalTaskContext context = HazelcastTransactionContextHolder.getContext(); if (context != null) { log.trace("[CACHE] Replacing value in a transactional map"); TransactionalMap<K, V> map = context.getMap(mapName); V value = map.getForUpdate(key); if (oldValue.equals(value)) { map.put(key, newValue); return true; } return false; } log.trace("[CACHE] Replacing value in a not transactional map"); IMap<K, V> map = hazelcastInstance.getMap(mapName); return map.replace(key, oldValue, newValue); }
اختبار ليس فقط هياكل البيانات المنتظمة ، ولكن أيضًا اختبار إصدارات المعاملات الخاصة بها. يحدث أن IMap يعمل ، ولكن ذهب TransactionalMap.
قم بإرفاق JAR جديد بدون توقف
أولا ، قررنا تسجيل أشياء من فصولنا في Hazelcast. على سبيل المثال ، لدينا تطبيق فئة ، نريد حفظه وقراءته. حفظ:
IMap<UUID, Application> map = hazelcastInstance.getMap("application"); map.set(id, application);
نقرأ:
IMap<UUID, Application> map = hazelcastInstance.getMap("application"); return map.get(id);
كل شيء يعمل. ثم قررنا بناء فهرس في Hazelcast للبحث عنه:
map.addIndex("subscriberId", false);
وعند كتابة كيان جديد ، بدأوا في تلقي ClassNotFoundException. حاول Hazelcast تكملة المؤشر ، لكنه لم يكن يعرف أي شيء عن صفنا وأراد أن يكون لديه JAR مع هذا الفصل. لقد فعلنا ذلك ، نجح كل شيء ، ولكن ظهرت مشكلة جديدة: كيفية تحديث JAR دون إيقاف المجموعة تمامًا؟ Hazelcast لا تلتقط JAR الجديد أثناء ترقية pod-wise. في هذه اللحظة ، قررنا أنه يمكننا العيش جيدًا بدون البحث عن طريق الفهرس. بعد كل شيء ، إذا كنت تستخدم Hazelcast كمخزن ذي قيمة رئيسية ، فهل يعمل كل شيء؟ ليس بالفعل. هنا مرة أخرى ، السلوكيات المختلفة لـ IMap و TransactionalMap. عندما لا يهم IMap ، يطرح TransactionalMap خطأ.
IMap نكتب 5000 قطعة ، نقرأها. كل شيء متوقع.
@Test void get5000() { IMap<UUID, Application> map = hazelcastInstance.getMap("application"); UUID subscriberId = UUID.randomUUID(); for (int i = 0; i < 5000; i++) { UUID id = UUID.randomUUID(); String title = RandomStringUtils.random(5); Application application = new Application(id, title, subscriberId); map.set(id, application); Application retrieved = map.get(id); assertEquals(id, retrieved.getId()); } }
ولا يعمل في المعاملة ، نحصل على ClassNotFoundException:
@Test void get_transaction() { IMap<UUID, Application> map = hazelcastInstance.getMap("application_t"); UUID subscriberId = UUID.randomUUID(); UUID id = UUID.randomUUID(); Application application = new Application(id, "qwer", subscriberId); map.set(id, application); Application retrievedOutside = map.get(id); assertEquals(id, retrievedOutside.getId()); hazelcastInstance.executeTransaction(context -> { HazelcastTransactionContextHolder.setContext(context); try { TransactionalMap<UUID, Application> transactionalMap = context.getMap("application_t"); Application retrievedInside = transactionalMap.get(id); assertEquals(id, retrievedInside.getId()); return null; } finally { HazelcastTransactionContextHolder.clearContext(); } }); }
في 3.8 ، ظهرت آلية نشر فئة المستخدم. يمكنك تعيين عقدة رئيسية واحدة وتحديث ملف JAR عليه.
الآن قمنا بتغيير النهج تمامًا: نقوم بتسلسله في JSON وحفظه في Hazelcast. لا يحتاج Hazelcast إلى معرفة بنية فصولنا ، ولكن يمكننا التحديث بدون وقت تعطل. يتحكم التطبيق في إصدار كائنات المجال. يمكن تشغيل إصدارات مختلفة من التطبيق في نفس الوقت ، ومن الممكن أن يكتب تطبيق جديد كائنات بحقول جديدة ، لكن التطبيق القديم لا يعرف عن هذه الحقول. وفي الوقت نفسه ، يقرأ التطبيق الجديد الكائنات المسجلة بواسطة التطبيق القديم ، والتي لا توجد فيها حقول جديدة. نحن نتعامل مع مثل هذه المواقف داخل التطبيق ، ولكن من أجل البساطة ، لا نغير أو نحذف الحقول ، نقوم فقط بتوسيع الفئات بإضافة حقول جديدة.
كيف نقدم أداء عالي
أربع رحلات إلى Hazelcast - جيدة ، اثنتان إلى قاعدة البيانات - سيئة
يعد الانتقال إلى ذاكرة التخزين المؤقت للبيانات دائمًا أفضل من قاعدة البيانات ، ولكنك لا تريد تخزين السجلات التي لم تتم المطالبة بها. القرار حول ما يجب تخزينه مؤقتًا ، نؤجله إلى المرحلة الأخيرة من التطوير. عندما يتم ترميز الوظيفة الجديدة ، نقوم بتشغيل PostgreSQL لتسجيل جميع الاستعلامات (log_min_duration_statement إلى 0) وتشغيل اختبار الحمل لمدة 20 دقيقة. وباستخدام السجلات المجمعة ، يمكن للأدوات المساعدة مثل pgFouine و pgBadger إنشاء تقارير تحليلية. في التقارير ، نبحث في المقام الأول عن الاستفسارات البطيئة والمتكررة. بالنسبة للاستعلامات البطيئة ، نقوم ببناء خطة تنفيذ (شرح) وتقييم ما إذا كان يمكن تسريع مثل هذا الاستعلام. يتم تخزين الطلبات المتكررة لنفس بيانات الإدخال في ذاكرة التخزين المؤقت بشكل جيد. نحاول إبقاء الطلبات "مسطحة" ، جدول واحد لكل طلب.
العملية
تم إطلاق SV كخدمة عبر الإنترنت في ربيع عام 2017 ، حيث تم إصدار منتج SV منفصل في نوفمبر 2017 (في ذلك الوقت في حالة بيتا).
على مدار أكثر من عام من التشغيل ، لم تحدث مشكلات خطيرة في تشغيل الخدمة عبر الإنترنت من CB. نحن نراقب الخدمة عبر الإنترنت من خلال
Zabbix ،
ونجمعها وننتشر من
Bamboo .
يتم تسليم مجموعة توزيع خادم CB في شكل حزم أصلية: RPM ، DEB ، MSI. بالإضافة إلى Windows ، نقدم مثبتًا واحدًا على شكل EXE واحد ، يقوم بتثبيت الخادم و Hazelcast و Elasticsearch على جهاز واحد. في البداية أطلقنا على هذا الإصدار من التثبيت "عرض" ، ولكن أصبح من الواضح الآن أن هذا هو خيار النشر الأكثر شيوعًا.