
أنا أحب Ceph. أعمل معه منذ 4 سنوات (0.80.x- 12.2.6 ، 12.2.5). أحيانًا أكون شغوفًا به لدرجة أنني أقضي أمسيات وليالي في شركته ، وليس مع صديقتي. لقد واجهت مشاكل مختلفة في هذا المنتج ، وما زلت أعيش مع البعض حتى يومنا هذا. في بعض الأحيان كنت سعيدًا بقرارات سهلة ، وأحيانًا كنت أحلم بلقاء مطورين للتعبير عن سخطتي. لكن Ceph لا يزال يستخدم في مشروعنا ومن المحتمل أنه سيتم استخدامه في مهام جديدة ، على الأقل من قبلي. في هذه القصة ، سوف أشارك تجربتنا في تشغيل Ceph ، بطريقة ما سأعبر عن نفسي حول موضوع ما لا يعجبني في هذا الحل وربما ساعد أولئك الذين ينظرون إليه للتو. دفعتني الأحداث التي بدأت منذ حوالي عام عندما أحضرت Dell EMC ScaleIO ، المعروف الآن باسم Dell EMC VxFlex OS ، إلى كتابة هذا المقال.
هذا ليس بأي حال من الأحوال إعلانًا لشركة Dell EMC أو منتجها! أنا شخصياً لست جيدًا جدًا مع الشركات الكبيرة والصناديق السوداء مثل VxFlex OS. ولكن كما تعلمون ، كل شيء في العالم نسبي وباستخدام مثال VxFlex OS ، من الملائم جدًا إظهار ما هو Ceph من حيث التشغيل ، وسأحاول القيام بذلك.
معلمات حوالي 4 أرقام!
خدمات Ceph مثل MON ، OSD ، إلخ. لديها معلمات مختلفة لإعداد جميع أنواع النظم الفرعية. يتم تعيين المعلمات في ملف التكوين ، ويقرأها daemons في وقت الإطلاق. يمكن تغيير بعض القيم بشكل ملائم على الفور باستخدام آلية "الحقن" الموضحة أدناه. كل شيء رائع تقريبًا ، إذا حذفت لحظة وجود المئات من المعلمات:
المطرقة:
> ceph daemon mon.a config show | wc -l 863
مضيئة:
> ceph daemon mon.a config show | wc -l 1401
اتضح ~ 500 معلمة جديدة في عامين. بشكل عام ، المعلمة رائعة ، ليس من الرائع وجود صعوبات في فهم 80٪ من هذه القائمة. تصف الوثائق حسب تقديري ~ 20٪ وفي بعض الأماكن غامضة. يجب فهم معنى معظم المعلمات في github للمشروع أو في القوائم البريدية ، ولكن هذا لا يساعد دائمًا.
في ما يلي مثال على العديد من المعلمات التي كنت مهتمًا بها مؤخرًا ، فقد وجدتها في مدونة أحد Ceph-gadfly:
throttler_perf_counter = false // enable/disable throttler perf counter osd_enable_op_tracker = false // enable/disable OSD op tracking
تعليقات المدونة بروح أفضل الممارسات. كما لو أنني أفهم الكلمات وحتى ما تعنيه تقريبًا ، ولكن ما سيعطيني إياه ليس كذلك.
أو هنا: اختفى osd_op_threads في Luminous ولم تساعد المصادر إلا في إيجاد اسم جديد: سلاسل osd_peering_wq
أنا أيضًا أحب أن هناك خيارات شاملة بشكل خاص. يظهر المتأنق هنا أن زيادة rgw_num _rados_handles أمر جيد :
ويعتقد المتأنق الآخر أن> 1 أمر مستحيل بل خطير .
والشيء المفضل لدي هو عندما يعطي المبتدئون أمثلة على التكوين في مشاركات المدونة الخاصة بهم ، حيث يتم نسخ جميع المعلمات بلا تفكير (يبدو لي) من مدونة أخرى من نفس النوع ، وبالتالي فإن مجموعة من المعلمات التي لا يعرفها أحد باستثناء مؤلف الشفرة يتجول من التكوين لتكوين.
أنا أيضا أحرق بشدة مع ما فعلوه في Luminous. هناك ميزة رائعة جدًا - تغيير المعلمات بسرعة ، دون إعادة تشغيل العمليات. يمكنك ، على سبيل المثال ، تغيير معلمة OSD محددة:
> ceph tell osd.12 injectargs '--filestore_fd_cache_size=512'
أو ضع "*" بدلاً من 12 وسيتم تغيير القيمة في جميع OSDs. إنه رائع حقًا. ولكن ، مثل الكثير في Ceph ، يتم ذلك بالقدم اليسرى. تصميم Bai لا يمكن تغيير جميع قيم المعلمات بسرعة. بتعبير أدق ، يمكن تعيينها وستظهر متغيرة في الإخراج ، ولكن في الواقع ، تتم إعادة قراءة القليل منها وإعادة تطبيقها. على سبيل المثال ، لا يمكنك تغيير حجم تجمع مؤشر الترابط دون إعادة تشغيل العملية. حتى يفهم مدير الفريق أنه من غير المجدي تغيير المعلمة بهذه الطريقة - قرروا طباعة رسالة. مرحبًا.
على سبيل المثال:
> ceph tell mon.* injectargs '--mon_allow_pool_delete=true' mon.c: injectargs:mon_allow_pool_delete = 'true' (not observed, change may require restart) mon.a: injectargs:mon_allow_pool_delete = 'true' (not observed, change may require restart) mon.b: injectargs:mon_allow_pool_delete = 'true' (not observed, change may require restart)
غامض. في الواقع ، تصبح إزالة البرك ممكنة بعد الحقن. أي أن هذا التحذير غير ذي صلة بهذه المعلمة. حسنًا ، ولكن لا يزال هناك المئات من المعلمات ، بما في ذلك المعلمات المفيدة جدًا ، والتي تحتوي أيضًا على تحذير ولا توجد طريقة للتحقق من تطبيقها الفعلي. في الوقت الحالي ، لا أستطيع حتى أن أفهم من خلال الكود المعلمات التي يتم تطبيقها بعد الحقن والتي لا يتم تطبيقها. من أجل الموثوقية ، يجب عليك إعادة تشغيل الخدمات وهذا ، كما تعلم ، يثير الغضب. يغضب لأنني أعلم أن هناك آلية حقن.
ماذا عن VxFlex OS؟ عمليات مماثلة مثل MON (في VxFlex هو MDM) ، OSD (SDS في VxFlex) لديها أيضًا ملفات تكوين ، حيث يوجد العشرات من المعلمات للجميع. صحيح أن أسمائهم أيضًا لا تقول أي شيء ، لكن الخبر السار هو أننا لم نلجأ إليهم أبدًا للحرق مثلما حدث مع Ceph.
الدين الفني
عندما تبدأ التعارف مع Ceph مع الإصدار الأكثر صلة اليوم ، يبدو كل شيء على ما يرام ، وتريد كتابة مقال إيجابي. ولكن عندما تعيش معه في حث من الإصدار 0.80 ، فإن كل شيء لا يبدو وردية للغاية.
قبل الجوهرة ، كانت عمليات Ceph تعمل كجذر. قررت جويل أنه يجب أن تعمل من المستخدم ceph وهذا يتطلب تغيير الملكية لجميع الدلائل التي تستخدمها خدمات Ceph. يبدو أن هذا؟ تخيل OSD الذي يخدم قرص مغناطيسي SATA بسعة كاملة 2 تيرابايت. لذا ، فإن هذا القرص ، بالتوازي (مع الدلائل الفرعية المختلفة) مع استخدام القرص الكامل يستغرق 3-4 ساعات. تخيل ، على سبيل المثال ، لديك 3 مئات من هذه الأقراص. حتى إذا قمت بتحديث العقد (يتم تخزينها على الفور من 8 إلى 12 قرصًا) ، فستحصل على تحديث طويل إلى حد ما ، حيث ستحتوي المجموعة على OSD من إصدارات مختلفة ونسخة واحدة من البيانات أقل في وقت تحديث الخادم. بشكل عام ، اعتقدنا أنه من العبث وإعادة بناء حزم Ceph وترك OSD تعمل كجذر. قررنا أنه عندما ندخل أو نستبدل OSD ، سننقلها إلى مستخدم جديد. الآن نقوم بتغيير 2-3 محركات أقراص في الشهر وإضافة 1-2 ، أعتقد أنه يمكننا التعامل معها بحلول عام 2022).
الانفاق CRUSH
CRUSH هو قلب Ceph ، كل شيء يدور حوله. هذه هي الخوارزمية التي يتم من خلالها تحديد موقع البيانات بطريقة عشوائية زائفة وبفضل ذلك ، يكتشف العملاء الذين يعملون مع مجموعة RADOS أي OSD يتم تخزين البيانات (الكائنات) التي يحتاجونها. الميزة الرئيسية لـ CRUSH هي أنه لا توجد حاجة إلى أي خوادم بيانات وصفية ، مثل Luster أو IBM GPFS (الآن مقياس الطيف). يتيح CRUSH للعملاء و OSD التفاعل مباشرة مع بعضهم البعض. على الرغم من أنه من الصعب بالطبع مقارنة أنظمة تخزين الكائنات وملفات RADOS البدائية ، والتي أعطيتها كمثال ، ولكن أعتقد أن الفكرة واضحة.
بدورها ، تعد أنفاق CRUSH مجموعة من المعلمات / الأعلام التي تؤثر على تشغيل CRUSH ، مما يجعلها أكثر كفاءة ، على الأقل من الناحية النظرية.
لذلك ، عند الترقية من Hammer إلى Jewel (اختبار بشكل طبيعي) ، ظهر تحذير ، يقول أن ملف تعريف الأنفاق يحتوي على معلمات غير مثالية للإصدار الحالي (Jewel) ويوصى بتغيير الملف الشخصي إلى الوضع الأمثل. بشكل عام ، كل شيء واضح. يقول الرصيف أن هذا مهم جدًا وهذا هو الطريق الصحيح ، ولكن يُقال أيضًا أنه بعد تبديل البيانات سيكون هناك إعادة تمرد بنسبة 10 ٪ من البيانات. 10٪ - لا يبدو مخيفا ، لكننا قررنا اختباره. بالنسبة للكتلة ، فهي أقل بحوالي 10 مرات من المجموعة ، مع نفس العدد من PGs لكل OSD ، مليئة ببيانات الاختبار ، حصلنا على تمرد بنسبة 60 ٪! تخيل ، على سبيل المثال ، مع 100 تيرابايت من البيانات ، يبدأ 60 تيرابايت في الانتقال بين OSDs وهذا مع استمرار تحميل العميل الذي يتطلب وقت استجابة! إذا لم أقل بعد ، فنحن نقدم s3 وليس لدينا حمل أقل بكثير على rgw حتى في الليل ، منها 8 و 4 أخرى تحت مواقع الويب الثابتة. بشكل عام ، قررنا أن هذا لم يكن طريقنا ، خاصة وأن القيام بهذا إعادة بناء على الإصدار الجديد ، الذي لم نكن قد عملنا به في المنتج ، كان على الأقل متفائلًا للغاية. بالإضافة إلى ذلك ، كان لدينا مؤشرات دلو كبيرة تعيد البناء بشكل سيئ للغاية وكان هذا أيضًا سبب التأخير في تبديل الملف الشخصي. حول المؤشرات سيكون بشكل منفصل أقل قليلاً. في النهاية ، أزلنا التحذير وقررنا العودة إليه لاحقًا.
وعند تبديل الملف الشخصي في الاختبار ، سقط عملاء cephfs الموجودين في نواة CentOS 7.2 لأنهم لم يتمكنوا من العمل مع خوارزمية التجزئة الأحدث للملف الشخصي الجديد الذي جاء. نحن لا نستخدم cephfs في prod ، ولكن إذا اعتدنا على ذلك ، فسيكون هذا سببًا آخر لعدم تبديل الملف الشخصي.
بالمناسبة ، يقول الرصيف أنه إذا كان ما يحدث أثناء التمرد لا يناسبك ، فيمكنك التراجع عن الملف الشخصي. في الواقع ، بعد التثبيت النظيف لإصدار Hammer والترقية إلى Jewel ، يبدو الملف الشخصي كما يلي:
> ceph osd crush show-tunables { ... "straw_calc_version": 1, "allowed_bucket_algs": 22, "profile": "unknown", "optimal_tunables": 0, ... }
من المهم أن تكون "غير معروفة" وإذا حاولت إيقاف إعادة البناء عن طريق تحويلها إلى "إرث" (كما هو مذكور في الرصيف) أو حتى "مطرقة" ، فلن يتوقف التمرد ، بل سيستمر وفقًا للأنفاق الأخرى ، وليس " الأمثل ". بشكل عام ، كل شيء يحتاج إلى فحص دقيق وفحص مزدوج ، ceph غير موثوق به.
تجارة CRUSH
كما تعلمون ، كل شيء في هذا العالم متوازن ويتم تطبيق العيوب على جميع المزايا. عيب CRUSH هو أن PGs يتم توزيعها بشكل غير متساو عبر مختلف OSD حتى مع نفس وزن هذا الأخير. بالإضافة إلى ذلك ، لا يوجد شيء يمنع PGs مختلفة من النمو بسرعات مختلفة ، بينما ستنخفض وظيفة التجزئة. على وجه التحديد ، لدينا مجموعة من استخدام OSD بنسبة 48-84 ٪ ، على الرغم من حقيقة أن لديهم نفس الحجم وبالتالي الوزن. حتى أننا نحاول جعل الخوادم متساوية في الوزن ، ولكن هذا هو الأمر ، فقط كماليتنا ، لا أكثر. والتين مع حقيقة أن IO يتم توزيعه بشكل غير متساوٍ عبر الأقراص ، فإن أسوأ شيء هو أنه عندما تصل إلى الحالة الكاملة (95٪) على الأقل من قائمة OSD واحدة في المجموعة ، يتوقف التسجيل بالكامل وتتحول الكتلة للقراءة فقط. الكتلة كلها! ولا يهم أن الكتلة لا تزال مليئة بالمساحة. كل شيء ، النهائي ، يخرج! هذه ميزة معمارية لـ CRUSH. تخيل أنك في إجازة ، بعض OSD كسر علامة 85٪ (التحذير الأول بشكل افتراضي) ، ولديك 10٪ في المخزون لمنع التسجيل من التوقف. و 10٪ مع التسجيل المستمر ليس كثيرًا / طويلاً. من الناحية المثالية ، مع هذا التصميم ، يحتاج Ceph إلى شخص في الخدمة يمكنه اتباع التعليمات المعدة في مثل هذه الحالات.
لذا ، قررنا أنه يعني عدم توازن البيانات في الكتلة ، لأن كانت العديد من OSDs قريبة من علامة قريبة (85 ٪).
هناك عدة طرق:
أسهل طريقة مضيعة قليلاً وليست فعالة للغاية ، لأن قد لا تنتقل البيانات نفسها من قائمة OSD المزدحمة أو أن الحركة ستكون ضئيلة.
- تغيير الوزن الدائم لـ OSD (WEIGHT)
هذا يؤدي إلى تغيير في وزن كل التسلسل الهرمي (مصطلحات CRUSH) ، خادم OSD ، مركز البيانات ، إلخ. ونتيجة لذلك ، لنقل البيانات ، بما في ذلك ليس من تلك OSD التي تكون ضرورية.
لقد حاولنا وخفض وزن أحد OSD ، بعد أن تم ملء البيانات التي أعيدت بناء أخرى ، قللناها ، ثم الثالث ، وأدركنا أننا سنلعب هذا لفترة طويلة.
- تغيير وزن OSD غير الدائم (REWEIGHT)
هذا ما يتم من خلال استدعاء "ceph osd Reweight by by الاستفادة". هذا يؤدي إلى تغيير في ما يسمى بوزن تعديل OSD ، ولا يتغير وزن الجرافة الأعلى. ونتيجة لذلك ، تتم موازنة البيانات بين OSDs المختلفة لخادم واحد ، كما كانت ، دون تجاوز حدود مجموعة CRUSH. لقد أحببنا حقًا هذا النهج ، نظرنا في التشغيل الجاف للتغييرات التي سيتم إجراؤها وتنفيذها على المنتج. كان كل شيء على ما يرام حتى حصلت عملية إعادة التوازن على حصة في الوسط. مرة أخرى غوغل ، وقراءة الرسائل الإخبارية ، وتجربة خيارات مختلفة ، وفي النهاية اتضح أن التوقف كان بسبب عدم وجود بعض الانفاق في الملف الشخصي المذكور أعلاه. مرة أخرى وقعنا في ديون فنية. ونتيجة لذلك ، ذهبنا في مسار إضافة الأقراص وإعادة البناء الأكثر فعالية. لحسن الحظ ، ما زلنا بحاجة للقيام بذلك لأنه كان من المخطط تبديل ملف CRUSH بهامش كافٍ في السعة.
نعم ، نحن نعرف عن الموازن (المضيء والأعلى) ، وهو جزء من mgr ، والذي تم تصميمه لحل مشكلة التوزيع غير المتكافئ للبيانات عن طريق نقل PG بين OSDs ، على سبيل المثال ، في الليل. لكنني لم أسمع بعد ملاحظات إيجابية حول عمله ، حتى في التقليد الحالي.
ربما ستقول إن الدين التقني هو مشكلتنا البحتة وربما أوافق على ذلك. ولكن لمدة أربع سنوات مع Ceph في الوخز ، سجلنا وقت تعطل واحد فقط S3 ، والذي استمر لمدة ساعة كاملة. وبعد ذلك ، لم تكن المشكلة في RADOS ، ولكن في RGW ، التي ، بعد كتابة 100 خيط افتراضي ، علقت بشدة ولم يستوف معظم المستخدمين الطلبات. كان لا يزال على مطرقة. في رأيي ، هذا مؤشر جيد ويتم تحقيقه نظرًا لأننا لا نقوم بحركات مفاجئة ومتشككين في كل شيء في Ceph.
جي سي البرية
كما تعلم ، يعد حذف البيانات مباشرة من القرص مهمة صعبة إلى حد ما ، وفي الأنظمة المتقدمة ، يتأخر الحذف أو لا يتم على الإطلاق. Ceph هو أيضًا نظام متقدم ، وفي حالة RGW ، عند حذف كائن s3 ، لا يتم حذف كائنات RADOS المقابلة على الفور من القرص. تحدد RGW كائنات s3 على أنها محذوفة ، ويقوم دفق gc- منفصل بحذف الكائنات مباشرة من تجمعات RADOS ، وبالتالي يتم تأجيلها من الأقراص. بعد التحديث إلى Luminous ، تغير سلوك gc بشكل ملحوظ ، وبدأ في العمل بشكل أكثر قوة ، على الرغم من أن معلمات gc ظلت كما هي. بالكلمة بشكل ملحوظ ، أعني أننا بدأنا نرى gc تعمل على المراقبة الخارجية للخدمة من أجل القفز عن الكمون. ترافق ذلك مع ارتفاع IO في تجمع rgw.gc. لكن المشكلة التي نواجهها هي ملحمية أكثر بكثير من IO فقط. عند تشغيل gc ، يتم إنشاء الكثير من سجلات النموذج:
0 <cls> /builddir/build/BUILD/ceph-12.2.5/src/cls/rgw/cls_rgw.cc:3284: gc_iterate_entries end_key=1_01530264199.726582828
حيث 0 في البداية هو مستوى التسجيل الذي تتم طباعة هذه الرسالة عنده. كما كان ، لا يوجد مكان لخفض قطع الأشجار تحت الصفر. ونتيجة لذلك ، تم إنشاء ~ 1 غيغابايت من السجلات فينا بواسطة OSD واحد في غضون ساعتين ، وكان كل شيء على ما يرام إذا لم تكن عقد ceph بدون قرص ... نقوم بتحميل نظام التشغيل عبر PXE مباشرة في الذاكرة ولا نستخدم القرص المحلي أو NFS ، NBD لقسم النظام (/). اتضح خوادم عديمة الجنسية. بعد إعادة التشغيل ، يتم تدوير الدولة بأكملها عن طريق الأتمتة. كيف يعمل ، سأصف بطريقة أو بأخرى في مقال منفصل ، والآن من المهم أن يتم تخصيص 6 غيغابايت من الذاكرة لـ "/" ، منها ~ 4 مجانًا. نرسل جميع السجلات إلى Graylog ونستخدم سياسة تدوير السجل العدوانية نوعًا ما ولا نواجه عادةً أي مشاكل في تجاوز سعة القرص / ذاكرة الوصول العشوائي. ولكننا لم نكن مستعدين لهذا ، مع 12 OSDs ، تمت تعبئة الخادم "/" بسرعة كبيرة ، ولم يستجب الحاضرون في الوقت المحدد إلى الزناد في Zabbix و OSD بدأوا في التوقف بسبب عدم القدرة على كتابة سجل. ونتيجة لذلك ، قللنا من كثافة gc ، ولم تبدأ التذكرة بسبب كان موجودًا بالفعل ، وأضفنا نصًا برمجيًا إلى cron ، حيث نجبر سجلات OSD على الاقتطاع عند تجاوز كمية معينة دون انتظار تسجيل الدخول. بالمناسبة ، تم زيادة مستوى قطع الأشجار.
مجموعات التنسيب وقابلية التوسع الثناء
في رأيي ، PG هو التجريد الأصعب للفهم. PG مطلوب لجعل CRUSH أكثر فعالية. الغرض الرئيسي من PG هو تجميع الكائنات لتقليل استهلاك الموارد وزيادة الإنتاجية وقابلية التوسع. إن معالجة الأشياء مباشرة ، بشكل فردي ، دون دمجها في PG سيكون مكلفًا للغاية.
المشكلة الرئيسية لـ PG هي تحديد عددهم لتجمع جديد. من مدونة Ceph:
"إن اختيار العدد الصحيح من PGs للكتلة الخاصة بك هو نوع من الفن الأسود - وكابوس قابلية للاستخدام."
هذا دائمًا ما يكون خاصًا جدًا بتثبيت معين ويتطلب الكثير من التفكير والحساب.
التوصيات الرئيسية:
- الكثير من PGs على OSD سيئة ؛ سيكون هناك زيادة في الإنفاق على الموارد لصيانتها والفرامل أثناء إعادة التوازن / الاسترداد.
- قليل من PGs على OSD سيئ ، وسيعاني الأداء ، وسيتم ملء OSDs بشكل غير متساوٍ.
- يجب أن يكون الرقم PG مضاعفًا لدرجة 2. سيساعد ذلك في الحصول على "قوة CRUSH".
وهنا يحترق معي. PGs ليست محدودة في الحجم أو في عدد الكائنات. كم عدد الموارد (بالأرقام الحقيقية) اللازمة لخدمة PG واحد؟ هل تعتمد على حجمها؟ هل يعتمد على عدد النسخ المتماثلة لهذا PG؟ هل يجب أن آخذ حمامًا بخاريًا إذا كانت لدي ذاكرة كافية ووحدات معالجة مركزية سريعة وشبكة جيدة؟
وتحتاج أيضًا إلى التفكير في النمو المستقبلي للمجموعة. لا يمكن تقليل رقم PG - فقط زيادة. في الوقت نفسه ، لا يوصى بالقيام بذلك ، حيث سيؤدي ذلك ، في جوهره ، إلى تقسيم جزء من PG إلى إعادة بناء جديدة وبرية.
"تعد زيادة عدد PG الخاص بمجموعة واحدة من أكثر الأحداث تأثيرًا في مجموعة Ceph ، ويجب تجنبها في مجموعات الإنتاج إن أمكن."
لذلك ، عليك التفكير في المستقبل على الفور ، إن أمكن.
مثال حقيقي.
مجموعة من 3 خوادم مع 14 × 2 تيرابايت OSD لكل منها ، ما مجموعه 42 OSDs. النسخة 3 ، مكان مفيد ~ 28 تيرابايت. لاستخدامها تحت S3 ، تحتاج إلى حساب عدد PGs لتجمع البيانات وتجمع الفهرس. تستخدم RGW تجمعات أكثر ، ولكن الاثنين أساسيان.
نذهب إلى حاسبة PG (هناك مثل هذه الحاسبة) ، وننظر في 100 PG الموصى بها على OSD ، نحصل على 1312 PG فقط. ولكن ليس كل شيء بسيطًا جدًا: لدينا مجموعة تمهيدية - ستنمو الكتلة بالتأكيد ثلاث مرات في غضون عام ، ولكن سيتم شراء الحديد بعد ذلك بقليل. نقوم بزيادة "الهدف PGs لكل OSD" ثلاث مرات ، إلى 300 ونحصل على 4480 PG.
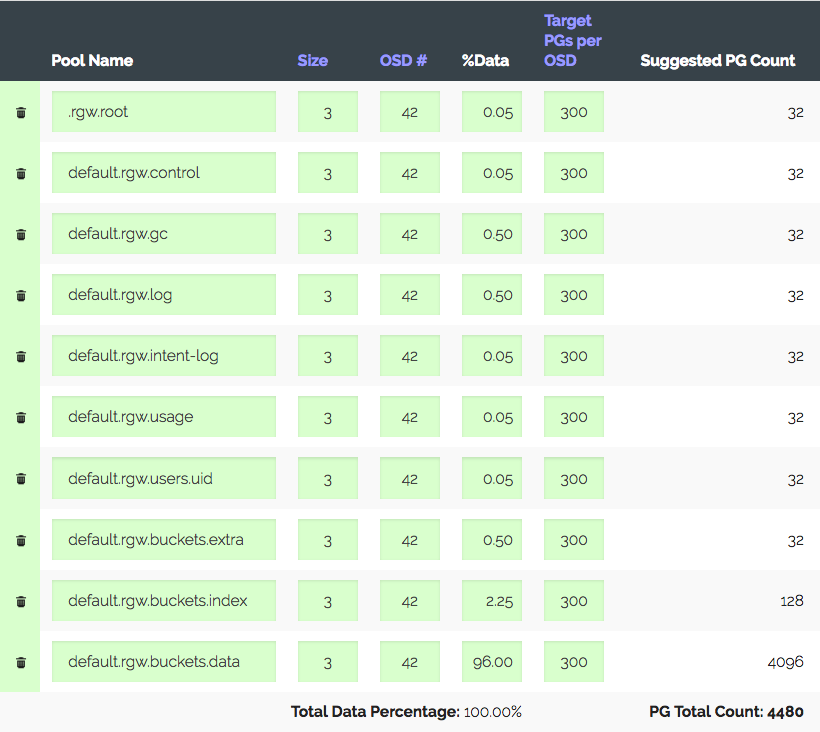
قم بتعيين عدد PGs للتجمعات المقابلة - نحصل على تحذير: وصل عدد كبير جدًا من PG لكل OSD ... تم الاستلام ~ 300 PG على OSD بحد 200 (مضيء). بالمناسبة كان 300. والشيء الأكثر إثارة للاهتمام هو أنه لا يُسمح لجميع PGs غير الضرورية بالتنظير ، وهذا ليس مجرد تحذير. نتيجة لذلك ، نعتقد أننا نفعل كل شيء بشكل صحيح ، ورفع الحدود ، وإيقاف التحذير ، والمضي قدما.
مثال حقيقي آخر هو أكثر إثارة للاهتمام.
S3 ، حجم قابل للاستخدام من 152 تيرابايت ، 252 OSD عند 1.81 تيرابايت ، ~ 105 PG على OSD. نمت المجموعة تدريجيًا ، وكان كل شيء على ما يرام حتى مع وجود القوانين الجديدة في بلدنا ، كانت هناك حاجة للنمو إلى 1 بيتابايت ، أي ~ 850 تيرابايت ، وفي الوقت نفسه تحتاج إلى الحفاظ على الأداء ، وهو الآن جيد جدًا لـ S3. لنفترض أننا أخذنا أقراصًا سعة 6 تيرابايت (5.7 ريال) مع مراعاة النسخة المتماثلة 3 نحصل على + 447 OSD. مع الأخذ بعين الاعتبار الحالية ، نحصل على 699 OSDs مع 37 PGs لكل منها ، وإذا أخذنا في الاعتبار الأوزان المختلفة ، فقد اتضح أن OSDs القديمة لديها فقط اثني عشر PGs. هل تخبرني كيف سيعمل هذا بشكل مقبول؟ من الصعب جدًا قياس أداء مجموعة تحتوي على عدد مختلف من PGs صناعيًا ، ولكن الاختبارات التي أجريتها تظهر أنه للحصول على الأداء الأمثل ، من الضروري أن يكون من 50 PG إلى 2 تيرابايت OSD. وماذا عن مزيد من النمو؟ بدون زيادة عدد PG ، يمكنك الانتقال إلى تعيين PG إلى OSD 1: 1. ربما لا أفهم شيئًا؟
نعم ، يمكنك إنشاء تجمع جديد لـ RGW مع العدد المطلوب من PGs وتعيين منطقة S3 منفصلة لها. أو حتى بناء تجمع جديد قريب. ولكن يجب أن تعترف بأن هذه كلها عكازات. وتبين أنه يبدو وكأنه Ceph قابل للتطوير بشكل جيد نظرًا لمفهومه ، يتدرج PG مع التحفظات. سيكون عليك إما العيش مع vorings معطل استعدادًا للنمو ، أو في مرحلة ما إعادة بناء جميع البيانات في المجموعة ، أو تسجيل نقاط في الأداء والعيش مع ما يحدث. أو خذها كلها.
أنا سعيد لأن مطوري Ceph يفهمون أن PG عبارة عن تجريد معقد وغير ضروري للمستخدم ومن الأفضل عدم معرفته بذلك.
"في Luminous ، اتخذنا خطوات رئيسية للقضاء نهائيًا على واحدة من أكثر الطرق شيوعًا لدفع مجموعتك إلى الخندق ، ونتطلع إلى المستقبل ، نهدف في النهاية إلى إخفاء PGs تمامًا حتى لا تكون شيئًا يجب على معظم المستخدمين معرفته أو فكر في ".
في vxFlex لا يوجد مفهوم PG أو أي نظائرها. ما عليك سوى إضافة أقراص إلى التجمع وهذا كل ما في الأمر. وهكذا تصل إلى 16 PB. تخيل ، لا شيء يحتاج إلى حساب ، لا توجد أكوام من حالات هذه PGs ، يتم التخلص من الأقراص بشكل موحد طوال فترة النمو. لأن يتم إعطاء الأقراص إلى vxFlex ككل (لا يوجد نظام ملفات فوقها) ولا توجد طريقة لتقييم الامتلاء ولا توجد مثل هذه المشكلة على الإطلاق. أنا لا أعرف حتى كيف أنقل لكم كم هو لطيف.
"بحاجة إلى انتظار SP1"
قصة أخرى عن "النجاح". كما تعلم ، يعد RADOS أكثر وحدات تخزين القيمة الرئيسية بدائية. S3 ، الذي تم تنفيذه على رأس RADOS ، هو أيضًا بدائي ، ولكنه لا يزال أكثر وظيفية. , S3 . , , RGW . — RADOS-, OSD. . , . OSD down. , , . , scrub' . , - 503, .
Bucket Index resharding — , (RADOS-) , , OSD, .
, , Jewel ! Hammer, .. -. ?
Hammer 20+ , , OSD Graylog , . , .. IO . Luminous, .. . Luminous, , . , . IO index-, , . , IO , . , … ; , :
, . , .. , .
, Hammer->Jewel - . OSD - . , OSD .
— , , . Hammer s3, . , . , , etag, body, . . , . Suspend . "" . , .
, 2 — , Cloudmouse. , Ceph, , .
vxFlex OS 2 . , . , . , . , , , Dell EMC.
. , ? . , . , Ceph, vxFlex . - . , .
9 ceph-devel : , CPU ( Xeon' !) IOPS All-NVMe Ceph 12.2.7 bluestore.
, , "" Ceph . ( Hammer) Ceph , s3 . , ScaleIO Ceph RBD . Ceph, — CPU. RDMA InfiniBand, jemalloc . , 10-20 , iops, io, Ceph . vxFlex . — Ceph system time, scaleio — io wait. , bluestore, , , -, , Ceph. ScaleIO . , , Ceph Dell EMC.
, , PG. (), IO. - PG IO, , . , nearfull. , .
vxFlex - , . ( ceph-volume), , .
Scrub
, . , , Ceph.
, . " " — - , . , 2 TB >50%, Ceph, . . , .
vxFlex OS , , . — bandwidth . . , .
, , vxFlex scrub-error. Ceph 2 .
Luminous — . . MGR- Zabbix (3 ). . , , - IO , gc, . — RGW .

. .
S3, "" :
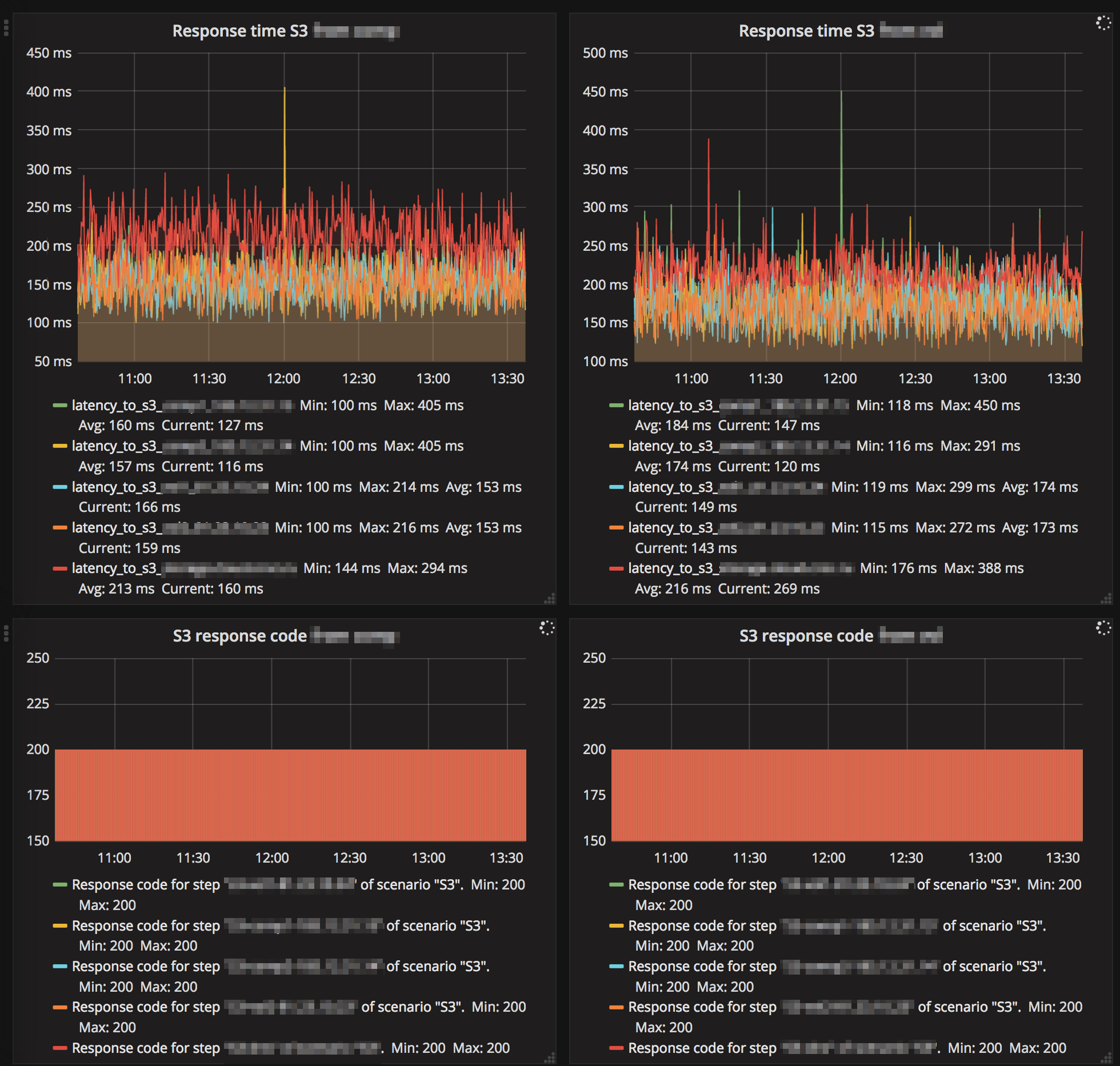
Ceph , , , , .
, eph Graylog GELF . , , OSD down, out, failed . , , OSD down , .
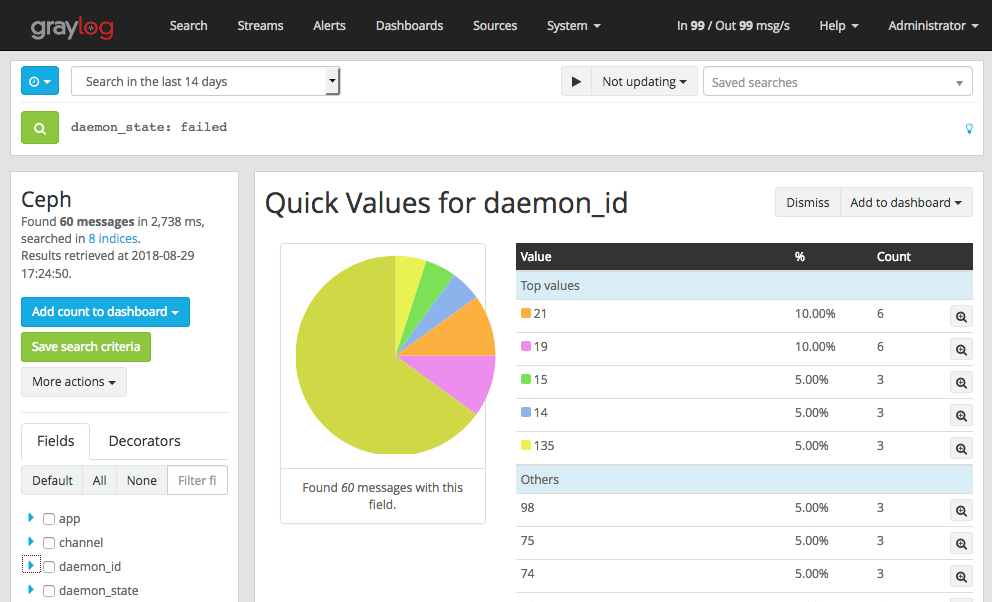
- , OSD heartbeat failed (. ). vm.zone_reclaim_mode=1 NUMA.
Ceph. c vxFlex . :
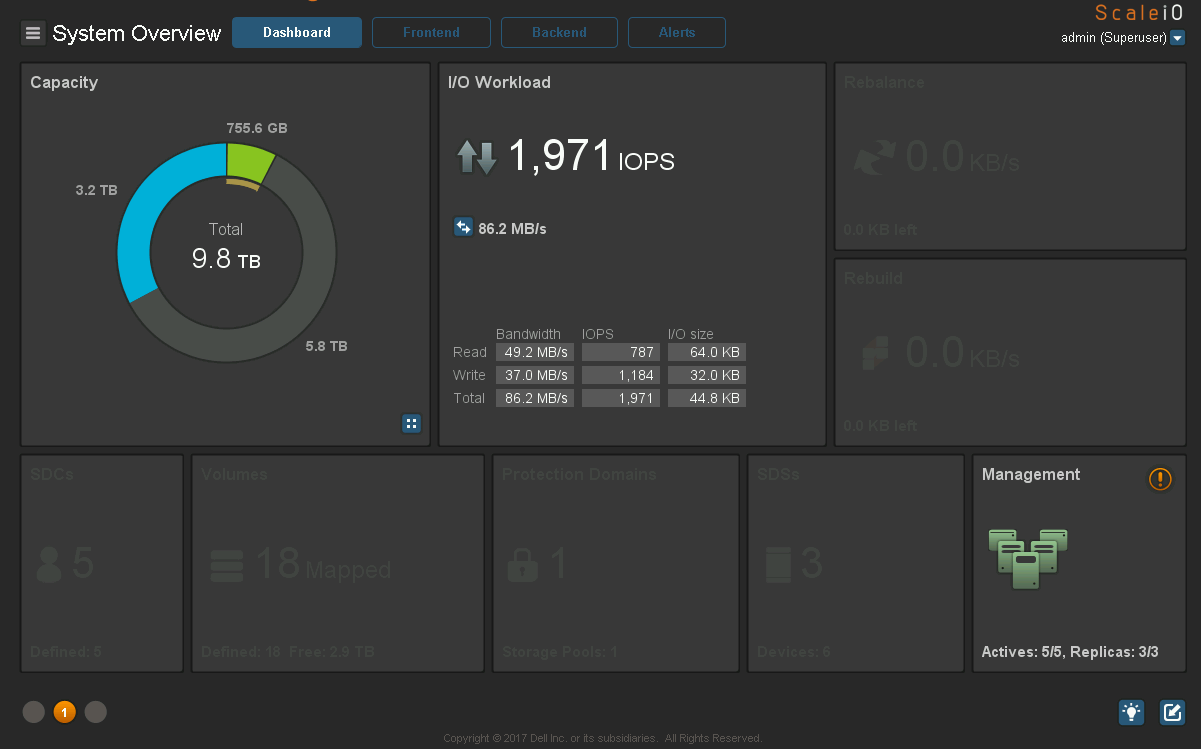
:

IO :
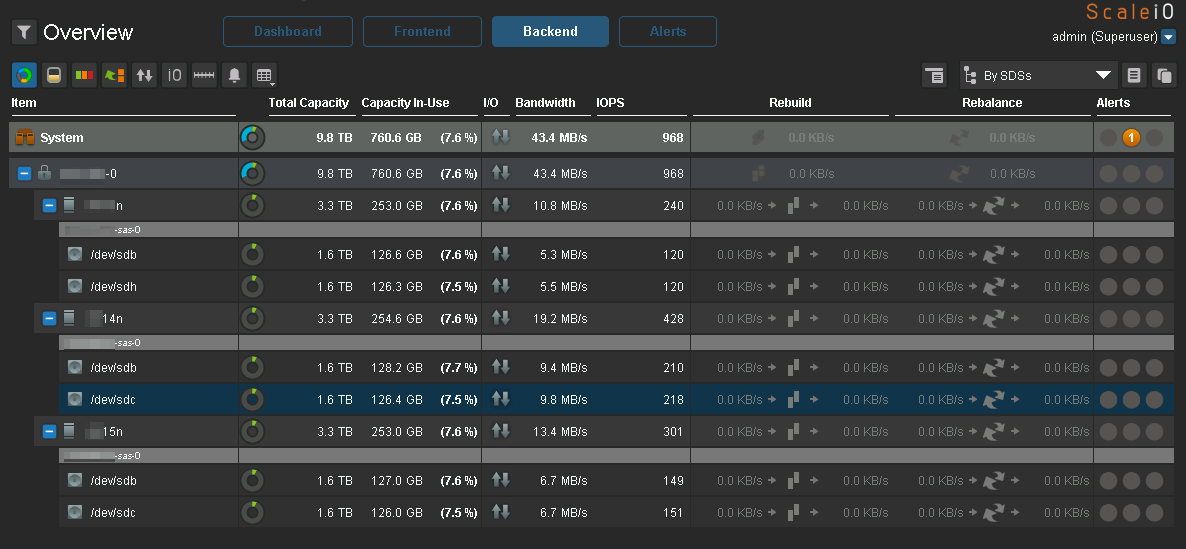
IO, Ceph.
:
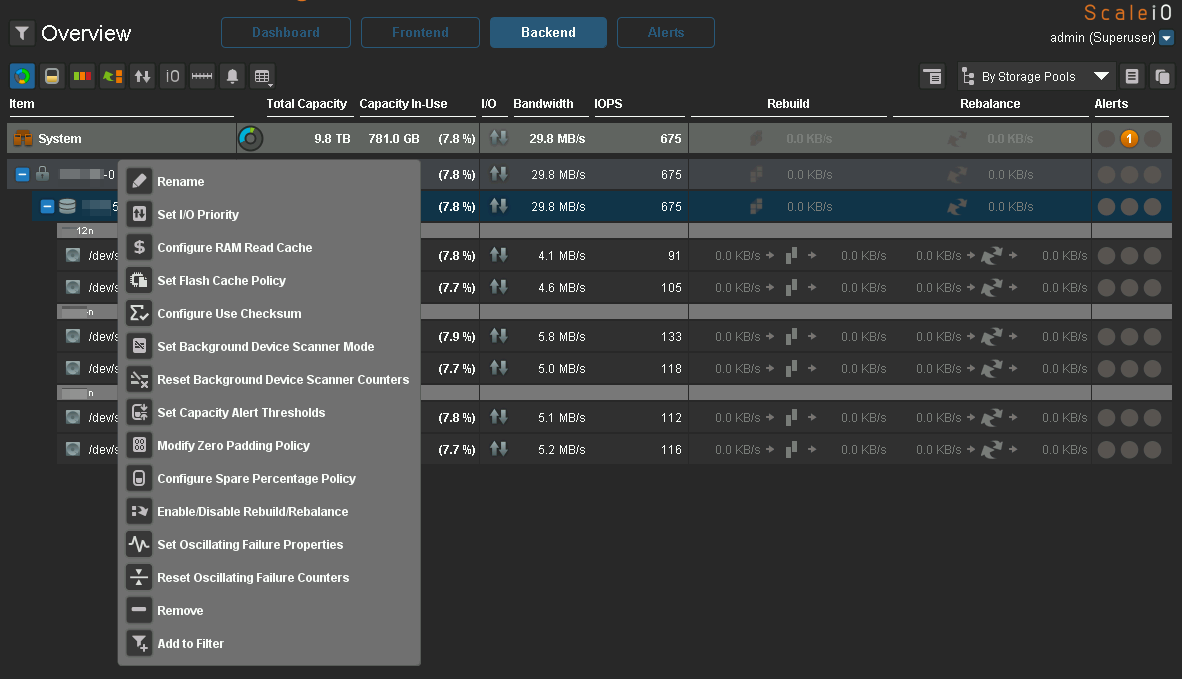
Ceph, Luminous . 2.0, Mimic , .
vxFlex
Degraded state , .
vxFlex — RH . 7.5 , . Ceph RBD cephfs — .
vxFlex Ceph. vxFlex — , , , .
16 PB, . eph 2 PB …
الخلاصة
, Ceph , , , Ceph — . .
, Ceph " ". , " , , R&D, - ". . " ", Ceph , , .
Ceph 2k18 , . 24/7 ( S3, , EBS), , Ceph . , . — . / maintenance backfilling , c Ceph , , .
Ceph ? , " ". Ceph. . , , , , …
!
HEALTH_OK!