
إن تقسيم الأشخاص الذين يستخدمون الشبكات العصبية لن يفاجئ أحدًا. هناك العديد من التطبيقات ، مثل Sticky Ai و Teleport Live و Instagram ، والتي تتيح لك أداء مثل هذه المهمة الصعبة على الهاتف المحمول في الوقت الفعلي.
لذا ، لنفترض أن كوكب الأرض يواجه حضارات خارج الأرض. ومن الأجانب من نظام النجوم Alpha Alpha ، يتم تلقي طلب لتطوير منتج جديد. لقد أحبوا حقًا تطبيق Sticky Ai ، والذي يسمح لك بقص الأشخاص وصنع الملصقات ، لذلك يريدون نقل التطبيق إلى سوقهم بين المجرات.
لسوء الحظ ، يتم تدريب شبكتنا العصبية ، التي يتم استخدامها في تطبيق التقسيم ، فقط على صور الجنس البشري ، وبالتالي فهي تعمل بشكل سيء على الأجانب. هناك حاجة ملحة لتوسيع مجموعة بياناتنا من قبل الأجانب.
بعد أن نطلب من الأجانب عدة آلاف من صورهم ، ننتقل إلى الترميز.
التحدي:
هناك صور غريبة ، لكل صورة تحتاج إلى إنشاء قناع أبيض وأسود يتم فيه تمييز الأجنبي باللون الأبيض والخلفية باللون الأسود.
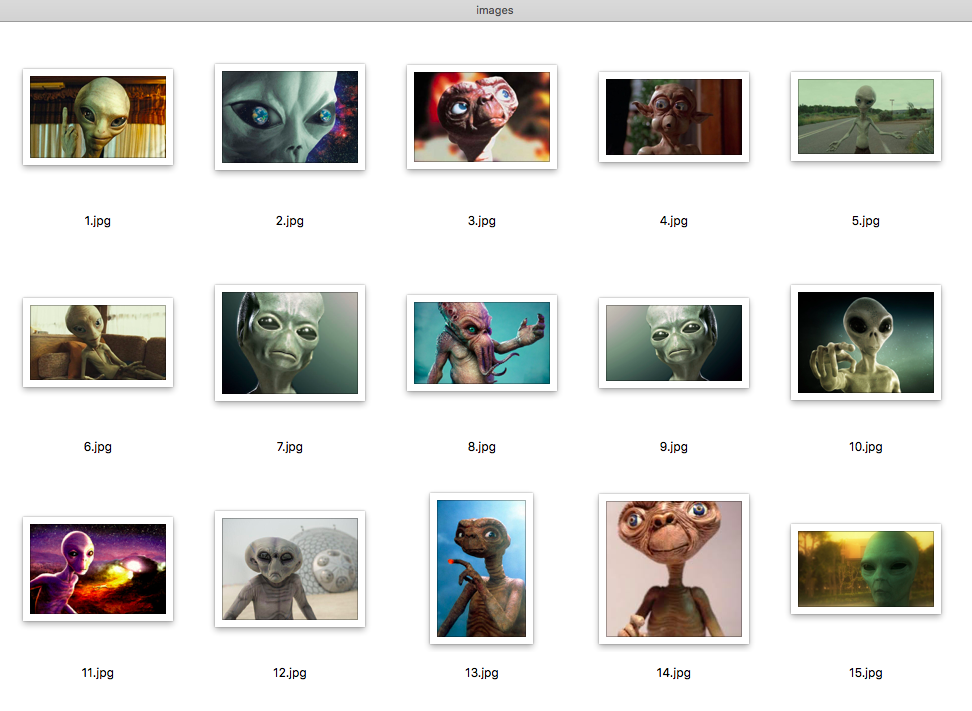
الحل:
بادئ ذي بدء ، تحتاج إلى عمل ToR للعمال المستقلين الذين سيضعون الصور. نظرًا لأننا بحاجة إلى جودة عالية جدًا ، فسوف نقوم بترميز الصور في Photoshop.
المفسدإذا لم نكن بحاجة إلى جودة جيدة جدًا ، أو كان الكائن المحدد بسيطًا جدًا ، فيمكن تنفيذ هذا الترميز باستخدام رؤوس مضلع. يتوفر هذا النوع من الترميز على Amazon Mechanical Turk و Yandex.Toloke ، حيث العمالة رخيصة جدًا.
من الممكن تكوين TOR في شكل مستند PDF من 10 صفحات ، ولكن:
- عادة ما لا يقرأ المترجمون المستقلون المعارف التقليدية ، ولكنهم يتصفحون.
- في المستند ، من الصعب أن تصف بالتفصيل خوارزمية كيفية الترميز بشكل صحيح وسريع.
- يستغرق تجميع المستند نفسه الكثير من الوقت.
لذلك ، الآن تخلينا تمامًا عن المعارف التقليدية في شكل مستند PDF ، ونقدم المهمة
نوع من تدريب الفيديو. بعد هذا الابتكار:
- تضاعفت إنتاجية المستقلين (منذ أن أظهر الفيديو الطريقة الأسرع والأفضل للترميز).
- تم تقليل الأسئلة التي طرحها المستقلون 3 مرات (حيث يظهر الفيديو كل خطوة).
- اتضح أنه يقلل من تكلفة الترميز بمقدار مرتين (نظرًا لأن سعر ساعة العمل لم يتغير ، ولكن العاملين لحسابهم الخاص يرتفعون مرتين بسرعة).
يجب إيلاء اهتمام خاص لطريقة الترميز في Photoshop. فوتوشوب هو برنامج مرن للغاية يمكن من خلاله تنفيذ الترميز بطرق مختلفة. لذلك ، من المستحسن تحديد جودة الترميز التي تحتاجها مسبقًا ، ودراسة أدوات التحديد المختلفة ، ومقارنتها مع بعضها البعض واختيار الأداة التي تكون فيها معالجة الصور هي الأسرع.
مثال:
هناك طريقتان لإبراز:
تستغرق الطريقة "أ" 5 دقائق لكل صورة.
تستغرق الطريقة ب 10 دقائق لكل صورة.
باستخدام الطريقة A ، يحدد المستغل المستقل 12 صورة في الساعة ، وبالتالي سيكون سعر الصورة 150/12 = 12.5 روبل.
باستخدام الطريقة B ، يحدد المستغل المستقل 6 صور في الساعة ، وبالتالي سيكون سعر الصورة 150/6 = 25 روبل.
لذا ، وجدنا أفضل طريقة لتمييز وتسجيل تعليمات الفيديو ، ما هي الخطوة التالية؟
يبقى للعثور على المستقلين. هناك العديد من عمليات التبادل المستقل مثل Fl.ru و Weblancer و Freelans.ru .
ولكن في الآونة الأخيرة ، كنا نستخدم خدمة العمل المستقل - WORK-ZILLA للأسباب التالية:
- هناك عمالة رخيصة إلى حد ما.
- الكثير من الفنانين.
- واجهة سهلة الاستخدام لإنشاء المهام.
لإنشاء مهمة:
نسجل ، نعيد التوازن ، انقر فوق "إرسال مهمة" ، حدد "تصميم" -> "معالجة الصور".

املأ العنوان والوصف ، وحدد الوقت لإكمال المهمة. بعد معالجة العديد من الأجانب ، لاحظت أن الأمر يستغرق 4 دقائق في المتوسط لكل صورة. على سبيل المثال تظهر 15 صورة في الساعة ، لذلك نحدد سعر صورة واحدة 150/15 = 10 روبل.

مباشرة بعد نشر المهمة ، يبدأ فناني الأداء في تقديم خدماتهم.
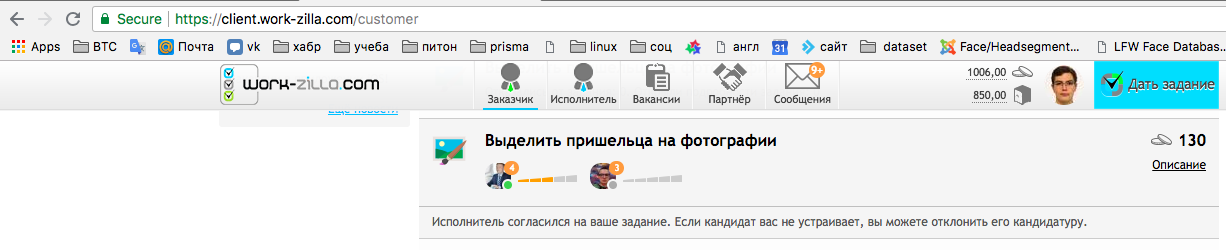
نختار أجمل صورة من خلال صورة الملف الشخصي التي تمر بها المراجعات ونؤكد بصفتنا مؤديًا ، نصدر الصور. كما ترون ، استغرق الأمر منا أقل من 15 دقيقة للعثور على موظف مستقل.
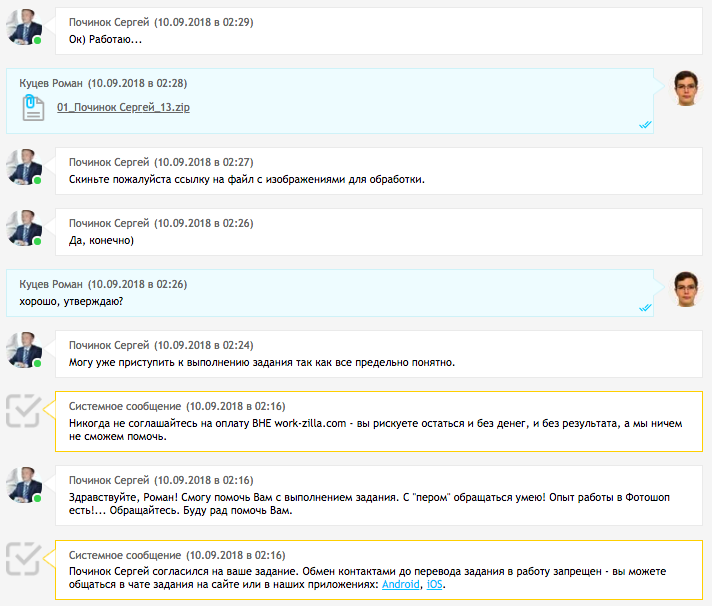
في صباح اليوم التالي ، أرسل المؤدي وظيفة.
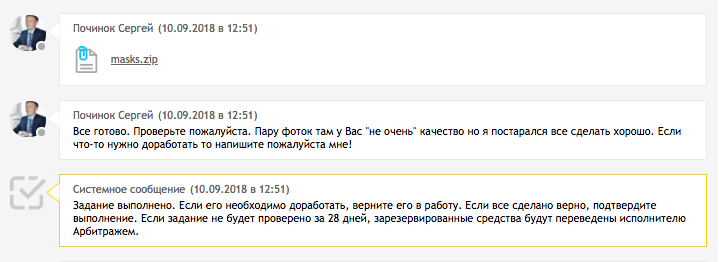
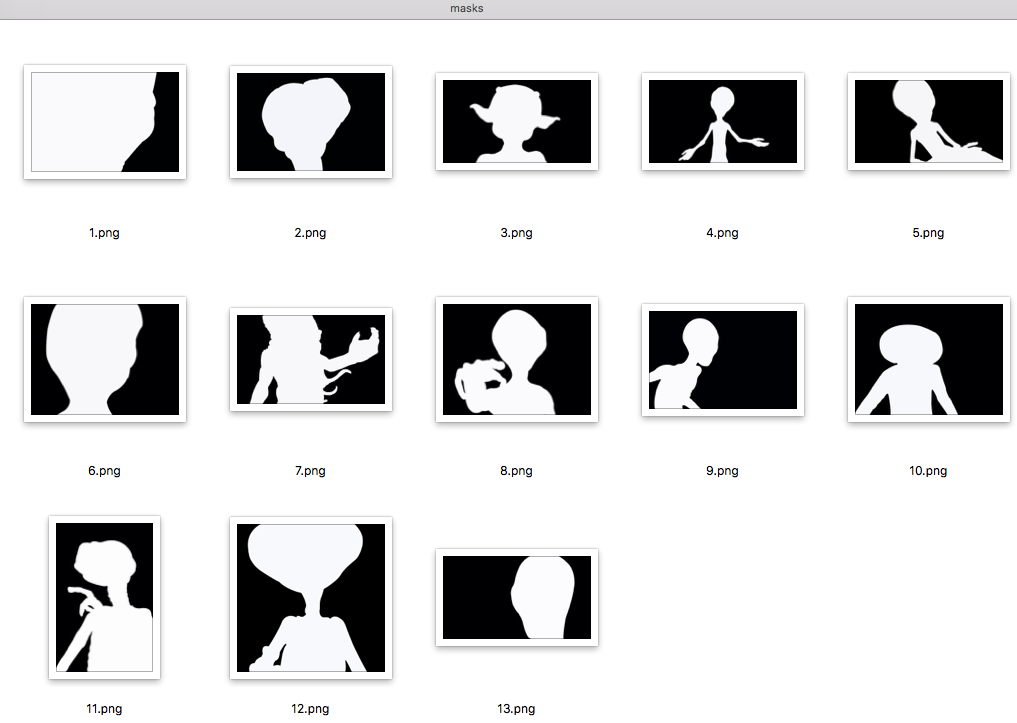
كيف تحقق ذلك الآن؟
بالطبع ، يمكنك فتح كل صورة في Photoshop ومعرفة مدى تسليط الضوء على كل شيء ، ولكن ماذا لو عمل 20 شخصًا معك في نفس الوقت وكل شخص يرسل 40 صورة في اليوم؟
أتمتة! لتسهيل التحقق ، قمت بتطبيق البرنامج النصي التالي على python:
import cv2 import numpy as np import os import shutil from __future__ import print_function from tqdm import tqdm_notebook as tqdm
يأخذ البرنامج النصي الصورة الأصلية ، القناع ، ويصنع مجموعة منها ، تتكون من الصورة الأصلية ، وتقطع الخلفية وتقطع الغريبة.
قم بتشغيل البرنامج النصي والحصول على مثل هذه الملصقات: بعد مراجعة الصور ، نلاحظ أن الفنان لم يحدد صورة واحدة بشكل جيد للغاية.

يرجى تصحيح الصورة.
بعد تصحيح صاحب العمل المستقل لجميع تعليقاتنا ، نؤكد العمل ونرسم تعليقات ممتنة للكاتب المستقل.
النتيجة:
لنفترض أنك بحاجة إلى 2000 صورة غريبة لتدريب شبكة عصبية.
بعد ذلك ، لتجميع مجموعة البيانات هذه ، ستحتاج إلى إنفاق 2000 × 10 = 20000 روبل فقط ، وإذا كنت تأخذ في الاعتبار أنه في المتوسط يقوم عامل مستقل واحد بمعالجة 40 صورة يوميًا و 10 أشخاص يعملون على الترميز ، فإن إنشاء مجموعة بيانات سيستغرق 2000 / (10 × 40) = 5 أيام.
ملاحظة
بالطبع ، لم نواجه بعد أجانب ، لن يقوم أي من فريق Prisma AI بتقسيم الأجانب ، ولكن مع هذا المثال أردت أن أبين لك مدى البساطة والفعالية من حيث التكلفة التي يمكنك من خلالها إنشاء مجموعة بيانات خاصة بك لأي مهمة ، سواء كانت الكشف عن المشاة لمركبة بدون طيار أو تحديد الغابات في صور الأقمار الصناعية.