ستركز هذه المقالة على موازنة التحميل في مشاريع الويب. يعتقد الكثيرون أن حل هذه المشكلة في توزيع الحمل بين الخوادم - أكثر دقة ، كلما كان ذلك أفضل. لكننا نعلم أن هذا ليس صحيحًا تمامًا.
يعد استقرار النظام أكثر أهمية من وجهة نظر الأعمال .
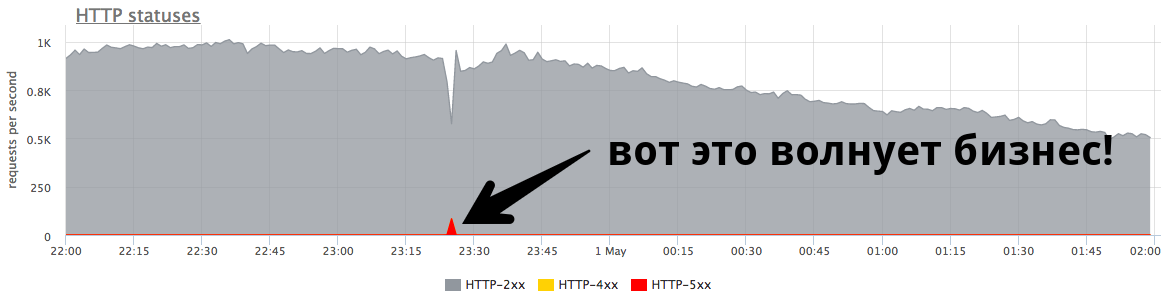
ذروة الدقيقة الصغيرة عند 84 RPS من "خمسمائة" هي خمسة آلاف خطأ تلقاه المستخدمون الحقيقيون. هذا كثير وهو مهم جدا. من الضروري البحث عن الأسباب ، والعمل على الأخطاء ومحاولة الاستمرار في منع مثل هذه المواقف.
تحدث نيكولاي سيفكو (
NikolaySivko ) في تقريره عن RootConf 2018 عن الجوانب الخفية وغير الشائعة جدًا لموازنة الحمل:
- وقت تكرار الطلب (إعادة المحاولة) ؛
- كيفية تحديد قيم المهلات ؛
- كيف لا تقتل الخوادم الأساسية في وقت وقوع الحادث / الازدحام ؛
- ما إذا كانت الفحوصات الطبية ضرورية ؛
- كيفية التعامل مع مشاكل الخفقان.
تحت فك القط من هذا التقرير.
حول المتحدث: نيكولاي سيفكو أحد مؤسسي موقع okmeter.io. عمل كمسؤول نظام وقائد مجموعة من المسؤولين. العملية تحت الإشراف على hh.ru. أسس خدمة المراقبة okmeter.io. كجزء من هذا التقرير ، فإن مراقبة تجربة التطوير هي المصدر الرئيسي للحالات.
ما الذي سنتحدث عنه؟
ستتحدث هذه المقالة عن مشاريع الويب. فيما يلي مثال للإنتاج المباشر: يعرض الرسم البياني الطلبات في الثانية لخدمة ويب معينة.
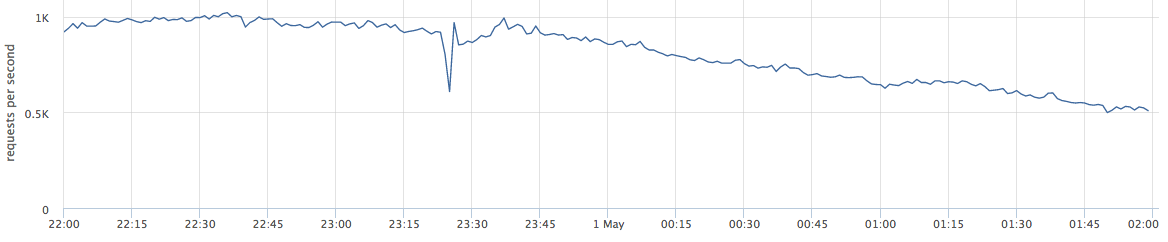
عندما أتحدث عن التوازن ، يرى الكثيرون أنه "نحن بحاجة إلى توزيع الحمل بين الخوادم - كلما كانت أكثر دقة ، كان ذلك أفضل".
في الواقع ، هذا ليس صحيحًا تمامًا. هذه المشكلة ذات صلة بعدد قليل جدًا من الشركات. في كثير من الأحيان ، تشعر الأعمال بالقلق بشأن الأخطاء واستقرار النظام.
الذروة الصغيرة على الرسم البياني هي "خمسمائة" ، والتي عاد الخادم في غضون دقيقة ، ثم توقف. من وجهة نظر شركة ، مثل متجر على الإنترنت ، هذه الذروة الصغيرة عند 84 RPS من "خمسمائة" هي 5040 خطأ للمستخدمين الحقيقيين. لم يجد البعض شيئًا في الكتالوج الخاص بك ، والبعض الآخر لم يتمكن من وضع البضائع في السلة. وهذا مهم جدا. على الرغم من أن هذه الذروة لا تبدو كبيرة جدًا على الرسم البياني ،
إلا أنها كثيرة في المستخدمين الحقيقيين .
كقاعدة عامة ، كل شخص لديه مثل هذه القمم ، ولا يستجيب المشرفون لها دائمًا. في كثير من الأحيان ، عندما يسأل رجال الأعمال ما هو ، يجيبون عليه:
- "هذا انفجار قصير!"
- "إنه مجرد إصدار متداول".
- "الخادم قد مات ، ولكن كل شيء في محله بالفعل."
- "Vasya غيرت شبكة واحدة من الخلفيات."
في كثير من الأحيان
لا يحاول الناس
حتى فهم أسباب حدوث ذلك ، ولا يقومون بأي عمل لاحق حتى لا يحدث مرة أخرى.
ضبط دقيق
دعوت إلى تقرير "الضبط الدقيق" (المهندس. الضبط الدقيق) ، لأنني اعتقدت أنه ليس كل شخص يصل إلى هذه المهمة ، ولكنه يستحق ذلك. لماذا لا يصلون هناك؟
- لا يصل الجميع إلى هذه المهمة ، لأنه عندما يعمل كل شيء ، يكون غير مرئي. هذا مهم جدا للمشاكل. لا تحدث Fakapa كل يوم ، وتتطلب مثل هذه المشكلة الصغيرة جهودًا جادة جدًا لحلها.
- انت بحاجة الى التفكير كثيرا. في كثير من الأحيان ، المشرف - الشخص الذي يقوم بتعديل التوازن - غير قادر على حل هذه المشكلة بشكل مستقل. التالي سنرى لماذا.
- يمسك المستويات الأساسية. ترتبط هذه المهمة ارتباطًا وثيقًا بالتطوير ، مع اعتماد القرارات التي تؤثر على منتجك والمستخدمين.
أؤكد أن الوقت قد حان للقيام بهذه المهمة لعدة أسباب:- العالم يتغير ، ويصبح أكثر ديناميكية ، وهناك العديد من الإصدارات. يقولون أنه من الصحيح الآن إطلاق 100 مرة في اليوم ، والإصدار هو fakap المستقبلية مع احتمال 50 إلى 50 (تمامًا مثل احتمال لقاء الديناصور)
- من وجهة نظر التكنولوجيا ، كل شيء ديناميكي للغاية. ظهرت Kubernetes وغيرهم من المنظمين. لا يوجد نشر قديم جيد ، عندما يتم إيقاف خلفية واحدة على بعض عناوين IP ، ويتم طرح التحديث ، وترتفع الخدمة. الآن في عملية الطرح في k8s تتغير قائمة IP upstream بالكامل.
- الخدمات الدقيقة: يتواصل الجميع الآن عبر الشبكة ، مما يعني أنك بحاجة إلى القيام بذلك بشكل موثوق. تلعب الموازنة دورًا مهمًا.
اختبار موقف
لنبدأ بحالات بسيطة وواضحة. للتوضيح ، سأستخدم منضدة اختبار. هذا هو تطبيق Golang يعطي http-200 ، أو يمكنك تبديله إلى وضع "إعطاء http-503".
نبدأ 3 حالات:
- 127.0.0.1:20001
- 127.0.0.1:20002
- 127.0.0.1:20003
نحن نقدم 100rps عبر yandex.tank عبر nginx.
Nginx خارج منطقة الجزاء:
upstream backends { server 127.0.0.1:20001; server 127.0.0.1:20002; server 127.0.0.1:20003; } server { listen 127.0.0.1:30000; location / { proxy_pass http://backends; } }
سيناريو بدائي
في مرحلة ما ، قم بتشغيل أحد الواجهات الخلفية في وضع إعطاء 503 ، ونحصل على ثلث الأخطاء بالضبط.
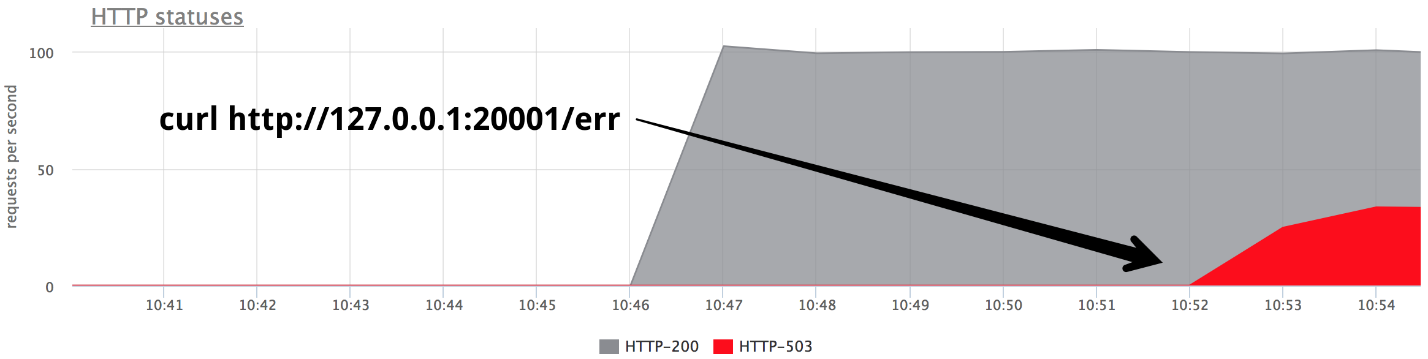
من الواضح أنه لا يوجد شيء يعمل خارج الصندوق: لا يقوم nginx بإعادة المحاولة خارج الصندوق إذا تلقى
أي رد من الخادم.
Nginx default: proxy_next_upstream error timeout;
في الواقع ، هذا منطقي تمامًا من جانب مطوري nginx: لا يحق لـ nginx أن تقرر لك ما تريد إعادة تسميته وما لا تريده.
تبعا لذلك ، نحن بحاجة إلى إعادة المحاولة - إعادة المحاولة ، ونبدأ في الحديث عنها.
إعادة المحاولة
من الضروري إيجاد حل وسط بين:
- طلب المستخدم مقدس ، تضار ، ولكن الإجابة. نريد الرد على المستخدم بأي ثمن ، فالمستخدم هو الأهم.
- من الأفضل الإجابة بخطأ من التحميل الزائد على الخوادم.
- تكامل البيانات (للطلبات غير المتعثرة) ، أي أنه من المستحيل تكرار أنواع معينة من الطلبات.
الحقيقة ، كالعادة ، هي في مكان ما بين - نحن مضطرون إلى الموازنة بين هذه النقاط الثلاث. دعونا نحاول أن نفهم ماذا وكيف.
قسمت المحاولات الفاشلة إلى 3 فئات:
1.
خطأ في النقللنقل HTTP هو TCP ، وكقاعدة عامة ، نتحدث هنا عن أخطاء إعداد الاتصال ومهلة إعداد الاتصال. في تقريري ، سأذكر 3 موازنات مشتركة (سنتحدث عن المبعوث أكثر قليلاً):
- nginx : أخطاء + مهلة (proxy_connect_timeout) ؛
- HAProxy : مهلة الاتصال ؛
- المبعوث : فشل الاتصال + الدفق المرفوض.
لدى Nginx الفرصة لتقول إن المحاولة الفاشلة هي خطأ اتصال ومهلة اتصال ؛ لدى HAProxy مهلة اتصال ، لدى Envoy أيضًا كل شيء قياسي وطبيعي.
2.
طلب مهلة:لنفترض أننا أرسلنا طلبًا إلى الخادم ، واتصلنا به بنجاح ، لكن الإجابة لم تأت إلينا ، وانتظرناها ونفهم أنه لم يعد هناك أي فائدة من الانتظار. وهذا ما يسمى مهلة الطلب:
- لدى Nginx : مهلة (prox_send_timeout * + proxy_read_timeout *) ؛
- HAProxy به OOPS :( - إنه غير موجود من حيث المبدأ. كثير من الناس لا يعرفون أن HAProxy ، إذا أقامت اتصالًا بنجاح ، لن تحاول أبدًا إعادة إرسال الطلب.
- يمكن للمبعوث أن يفعل كل شيء: مهلة || per_try_timeout.
3.
حالة HTTPجميع الموازنات ، باستثناء HAProxy ، قادرة على المعالجة ، إذا كانت الخلفية الخلفية تجيبك ، ولكن مع نوع من التعليمات البرمجية الخاطئة.
- nginx : http_ *
- HAProxy : OOPS :(
- المبعوث : 5xx ، خطأ البوابة (502 ، 503 ، 504) ، قابل للاسترجاع - 4xx (409)
المهلات
الآن دعونا نتحدث بالتفصيل عن المهلات ، يبدو لي أنه يستحق الانتباه إلى ذلك. لن يكون هناك مزيد من علم الصواريخ - هذه ببساطة معلومات منظمة حول ما يحدث بشكل عام وكيف يرتبط به.
ربط مهلة
مهلة الاتصال هي الوقت المناسب لإنشاء اتصال. هذه خاصية مميزة لشبكتك وخادمك المحدد ، ولا تعتمد على الطلب. عادةً ، يتم تعيين القيمة الافتراضية لمهلة الاتصال على صغيرة. في جميع البروكسيات ، تكون القيمة الافتراضية كبيرة بما يكفي ، وهذا خطأ - يجب أن تكون
وحدات ، وأحيانًا عشرات الملي ثانية (إذا كنا نتحدث عن شبكة داخل وحدة تحكم المجال DC واحدة).
إذا كنت ترغب في تحديد الخوادم التي بها مشكلات بشكل أسرع قليلاً من هذه الوحدات - عشرات المللي ثانية ، يمكنك ضبط الحمل على الواجهة الخلفية عن طريق تعيين تراكم صغير لاستلام اتصالات TCP. في هذه الحالة ، يمكنك ، عندما يكون تراكم التطبيق ممتلئًا ، أن تخبر Linux أن يعيد تعيينه لتجاوز التراكم. ثم ستتمكن من تصوير الخلفية الزائدة "السيئة" قبل وقت قصير من مهلة الاتصال:
fail fast: listen backlog + net.ipv4.tcp_abort_on_overflow
طلب مهلة
مهلة الطلب ليست من خصائص الشبكة ، ولكنها
خاصية لمجموعة من الطلبات (معالج). هناك طلبات مختلفة - تختلف في شدتها ، ولديها منطق مختلف تمامًا في الداخل ، ويحتاجون إلى الوصول إلى مستودعات مختلفة تمامًا.
Nginx نفسها
ليس لديها مهلة للطلب بأكمله. لديه:
- proxy_send_timeout: الوقت بين عمليتي كتابة ناجحتين للكتابة () ؛
- proxy_read_timeout: الوقت بين قراءتين ناجحتين ().
بمعنى ، إذا كان لديك خلفية ببطء ، بايت واحد من المرات ، يعطي شيئًا في مهلة ، ثم كل شيء على ما يرام. على هذا النحو ، لا يحتوي nginx على request_timeout. لكننا نتحدث عن المنبع. في مركز البيانات لدينا ، نحن نتحكم فيها ، على افتراض أن الشبكة لا تحتوي على لوريس بطيء ، ثم ، من حيث المبدأ ، يمكن استخدام وقت القراءة كوقت_الطلب.
المبعوث لديه كل شيء: مهلة || per_try_timeout.
حدد مهلة الطلب
الآن أهم شيء ، في رأيي ، هو request_timeout لوضعه. ننتقل من مقدار ما يجوز للمستخدم الانتظار - وهذا حد معين. من الواضح أن المستخدم لن ينتظر أكثر من 10 ثوانٍ ، لذا عليك الإجابة عليه بشكل أسرع.
- إذا أردنا معالجة فشل خادم واحد ، فيجب أن تكون المهلة أقل من الحد الأقصى المسموح به للمهلة: request_timeout <max.
- إذا كنت ترغب في الحصول على محاولتين مضمونتين لإرسال طلب إلى خادمتين مختلفتين ، فإن مهلة محاولة واحدة تساوي نصف هذا الفاصل الزمني المسموح به: per_try_timeout = 0.5 * كحد أقصى.
- هناك أيضًا خيار وسيط - محاولتان متفائلتان في حالة "خفوت" الواجهة الخلفية الأولى ، لكن الثانية سترد بسرعة: per_try_timeout = k * max (حيث k> 0.5).
هناك طرق مختلفة ، ولكن بشكل عام ،
اختيار مهلة صعب . ستكون هناك دائمًا حالات حدودية ، على سبيل المثال ، تتم معالجة المعالج نفسه في 99 ٪ من الحالات في 10 مللي ثانية ، ولكن هناك 1 ٪ من الحالات عندما ننتظر 500 مللي ثانية ، وهذا أمر طبيعي. يجب حل هذا.
مع هذا 1٪ ، يجب القيام بشيء ما ، لأن مجموعة الطلبات بأكملها يجب ، على سبيل المثال ، أن تتوافق مع اتفاقية مستوى الخدمة وتناسب 100 مللي ثانية. في كثير من الأحيان في هذه اللحظات يتم معالجة الطلب:
- يظهر الترحيل في تلك الأماكن حيث يستحيل إرجاع جميع البيانات في مهلة.
- يتم فصل المسؤول / التقارير إلى مجموعة منفصلة من عناوين URL لزيادة المهلة المخصصة لها ، ونعم لخفض طلبات المستخدمين.
- نقوم بإصلاح / تحسين تلك الطلبات التي لا تتناسب مع المهلة.
هنا نحتاج إلى اتخاذ قرار ، وهو ليس بسيطًا جدًا من وجهة نظر نفسية ، أنه إذا لم يكن لدينا وقت للإجابة على المستخدم في الوقت المخصص ، فسوف نعطي خطأ (كما هو الحال في قول صيني قديم: "إذا ماتت الفرس ، انزل!")
.بعد ذلك ، يتم تبسيط عملية مراقبة الخدمة من وجهة نظر المستخدم:
- إذا كانت هناك أخطاء ، كل شيء سيء ، يجب إصلاحه.
- إذا لم تكن هناك أخطاء ، فإننا نلائم وقت الاستجابة الصحيح ، فكل شيء على ما يرام.
إعادة المحاولة المضاربة # nifig
تأكدنا من أن اختيار قيمة المهلة أمر صعب للغاية. كما تعلمون ، لتبسيط شيء ما ، تحتاج إلى تعقيد شيء :)
إعادة المضاربة - طلب متكرر إلى خادم آخر ، والذي تم إطلاقه من قبل بعض الشروط ، ولكن لم يتم مقاطعة الطلب الأول. نأخذ الإجابة من الخادم الذي أجاب بشكل أسرع.
لم أر هذه الميزة في موازنات معروفة لي ، ولكن هناك مثال ممتاز مع Cassandra (حماية القراءة السريعة):
speculative_retry = N ms |
المئة المئويةبهذه الطريقة
ليس عليك أن تنتهي المهلة . يمكنك تركها عند مستوى مقبول وفي أي حال لديك محاولة ثانية للحصول على رد على الطلب.
تتمتع كاساندرا بفرصة مثيرة للاهتمام لتحديد المضاربة الثابتة أو الديناميكية ، ثم ستتم المحاولة الثانية من خلال النسبة المئوية لوقت الاستجابة. تجمع كاساندرا إحصائيات حول أوقات الاستجابة للطلبات السابقة وتقوم بتعديل قيمة مهلة محددة. هذا يعمل بشكل جيد.
في هذا النهج ، يعتمد كل شيء على التوازن بين الموثوقية والحمل الزائف. وليس الخوادم. أنت توفر الموثوقية ، ولكن في بعض الأحيان تحصل على طلبات إضافية إلى الخادم. إذا كنت في عجلة من أمرك في مكان ما وأرسلت طلبًا ثانيًا ، ولكن الطلب الأول لا يزال يتم الرد عليه ، فقد تلقى الخادم المزيد من التحميل. في حالة واحدة ، هذه مشكلة صغيرة.

اتساق المهلة جانب مهم آخر. سنتحدث أكثر عن إلغاء الطلب ، ولكن بشكل عام ، إذا كانت مهلة طلب المستخدم بأكمله 100 مللي ثانية ، فلن يكون من المنطقي تعيين مهلة الطلب في قاعدة البيانات لمدة ثانية واحدة. هناك أنظمة تسمح لك بالقيام بذلك بشكل ديناميكي: خدمة لخدمة نقل ما تبقى من الوقت الذي ستنتظر فيه الرد على هذا الطلب. الأمر معقد ، ولكن إذا كنت بحاجة إليه فجأة ، يمكنك بسهولة معرفة كيفية القيام بذلك في نفس المبعوث.
ما الذي تحتاج إلى معرفته أيضًا عن إعادة المحاولة؟
نقطة اللاعودة (V1)
هنا V1 ليس الإصدار 1. في الطيران هناك مثل هذا المفهوم - سرعة V1. هذه هي السرعة التي يستحيل بعدها إبطاء تسارع المدرج. من الضروري الإقلاع ، ثم اتخاذ قرار بشأن ما يجب القيام به بعد ذلك.
توجد نفس نقطة اللاعودة في موازنات التحميل:
عندما تتجاوز 1 بايت من الاستجابة لعميلك ، لا يمكن إصلاح الأخطاء . إذا ماتت الخلفية في هذه المرحلة ، فلن تساعدك أي محاولات إعادة المحاولة. يمكنك فقط تقليل احتمالية تشغيل مثل هذا السيناريو ، وإجراء إيقاف تشغيل لطيف ، أي إخبار تطبيقك: "أنت لا تقبل الطلبات الجديدة الآن ، ولكن يمكنك تعديل الطلبات القديمة!" ، ثم قم بإخفائها.
إذا كنت تتحكم في العميل ، فهذا بعض تطبيقات Ajax أو تطبيقات الهاتف المحمول الصعبة ، فقد يحاول تكرار الطلب ، وبعد ذلك يمكنك الخروج من هذا الموقف.
نقطة اللاعودة [المبعوث]
كان لدى المبعوث مثل هذه الحيلة الغريبة. هناك per_try_timeout - فهي تحدد المدة التي يمكن أن تستغرقها كل محاولة للحصول على رد على الطلب. إذا نجحت هذه المهلة ، ولكن الواجهة الخلفية بدأت بالفعل في الاستجابة للعميل ، فقد تمت مقاطعة كل شيء ، وتلقى العميل خطأ.
قام زميلي Pavel Trukhanov (
tru_pablo ) بعمل
رقعة ، وهي بالفعل في مبعوث رئيسي وستكون في 1.7. الآن يعمل كما ينبغي: إذا بدأ إرسال الاستجابة ، فلن تعمل سوى المهلة العالمية.
إعادة المحاولة: الحاجة إلى الحد
إعادة المحاولة جيدة ، ولكن هناك ما يسمى بالطلبات القاتلة: الاستعلامات الثقيلة التي تؤدي إلى منطق معقد للغاية تصل إلى قاعدة البيانات كثيرًا ولا تتناسب مع per_try_timeout في كثير من الأحيان. إذا أرسلنا إعادة المحاولة مرارًا وتكرارًا ، فإننا نقتل قاعدتنا. لأنه
في معظم خدمات قواعد البيانات (99.9٪) لا يوجد إلغاء للطلب .
إلغاء الطلب يعني أن العميل لم يخترق ، فأنت بحاجة إلى إيقاف كل العمل الآن. يعمل Golang بنشاط على تعزيز هذا النهج ، ولكن للأسف ينتهي بواجهة خلفية ، والعديد من مستودعات قواعد البيانات لا تدعم ذلك.
وفقًا لذلك ، يجب أن تكون عمليات إعادة المحاولة محدودة ، مما يسمح لجميع الموازنات تقريبًا (نتوقف عن التفكير في HAProxy من الآن فصاعدًا).
Nginx:- proxy_next_upstream_timeout (عالمي)
- proxt_read_timeout ** كـ per_try_timeout
- proxy_next_upstream_tries
المبعوث:- مهلة (عالمية)
- per_try_timeout
- num_retries
في Nginx ، يمكننا القول أننا نحاول إجراء عمليات إعادة المحاولة خلال النافذة X ، أي في فترة زمنية معينة ، على سبيل المثال ، 500 مللي ثانية ، نقوم بتنفيذ العديد من عمليات إعادة المحاولة بالشكل المناسب. أو هناك إعداد يحد من عدد العينات المتكررة. في
Envoy ، نفس الشيء هو الكمية أو المهلة (العالمية).
إعادة المحاولة: تطبيق [nginx]
خذ بعين الاعتبار مثال: قمنا بتعيين محاولات إعادة المحاولة في nginx 2 - وفقًا لذلك ، بعد أن استلمنا HTTP 503 ، نحاول إرسال طلب إلى الخادم مرة أخرى. ثم قم بإيقاف الواجهة الخلفية.
upstream backends { server 127.0.0.1:20001; server 127.0.0.1:20002; server 127.0.0.1:20003; } server { listen 127.0.0.1:30000; proxy_next_upstream error timeout http_503; proxy_next_upstream_tries 2; location / { proxy_pass http://backends; } }
فيما يلي الرسوم البيانية لمنضدة الاختبار لدينا. لا توجد أخطاء في الرسم البياني العلوي ، لأن هناك القليل جدًا منها. إذا تركت الأخطاء فقط ، فمن الواضح أنها كذلك.
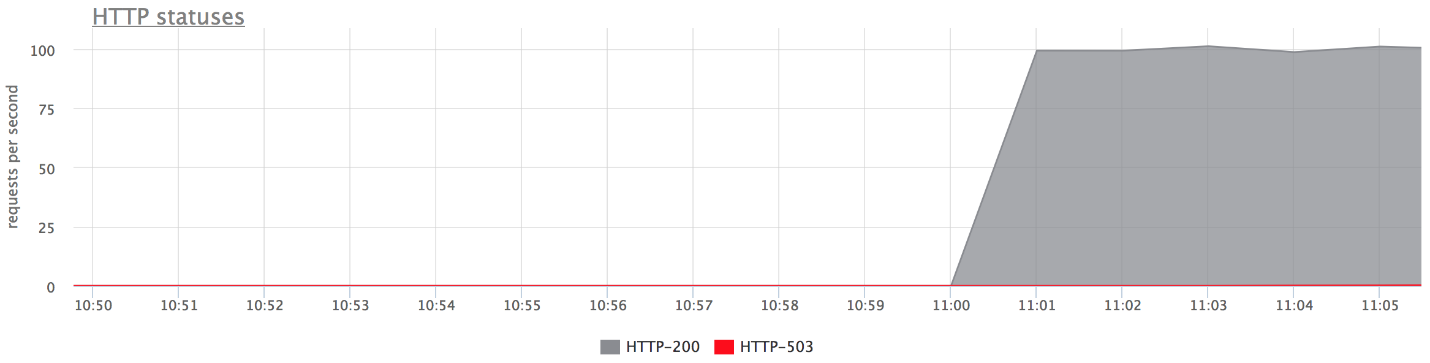
 ماذا حدث
ماذا حدث- proxy_next_upstream_tries = 2.
- في الحالة التي تقوم فيها بالمحاولة الأولى للخادم "الميت" ، والثانية - إلى "الميت" الآخر ، تحصل على HTTP-503 في حالة المحاولتين للخوادم "السيئة".
- هناك أخطاء قليلة ، نظرًا لأن nginx "يحظر" خادمًا سيئًا. أي أنه في nginx تم إرجاع بعض الأخطاء من الواجهة الخلفية ، فإنه يتوقف عن إجراء المحاولات التالية لإرسال طلب إليها. يحكم هذا المتغير fail_timeout.
ولكن هناك أخطاء وهذا لا يناسبنا.
ماذا تفعل حيال ذلك؟يمكننا إما زيادة عدد مرات إعادة المحاولة (ولكن بعد ذلك نعود إلى مشكلة "الطلبات القاتلة") ، أو يمكننا تقليل احتمالية وصول الطلب إلى خلفيات "ميتة". يمكن القيام بذلك عن طريق
الفحوصات الصحية.الفحوصات الصحية
أقترح اعتبار عمليات الفحص الصحي بمثابة تحسين لعملية اختيار خادم "مباشر".
هذا لا يعطي أي ضمانات. وفقًا لذلك ، أثناء تنفيذ طلب المستخدم ، من المرجح أن نصل إلى خوادم "مباشرة" فقط. يصل الموازن بانتظام إلى عنوان URL محدد ، ويجيبه الخادم: "أنا على قيد الحياة وجاهز".
الفحوصات الصحية: من حيث الواجهة الخلفية
من وجهة النظر الخلفية ، يمكنك القيام بأشياء مثيرة للاهتمام:
- تحقق من جاهزية تشغيل جميع الأنظمة الفرعية الأساسية التي تعتمد عليها عملية الواجهة الخلفية: يتم إنشاء العدد اللازم من الاتصالات بقاعدة البيانات ، ولدى التجمع اتصالات مجانية ، وما إلى ذلك ، إلخ.
- يمكنك تعليق المنطق الخاص بك على عنوان URL للتحقق من الصحة إذا كان الموازن المستخدم ليس ذكيًا جدًا (على سبيل المثال ، يمكنك أخذ موازن التحميل من المضيف). يمكن للخادم أن يتذكر أنه "في اللحظة الأخيرة أخطأت العديد من الأخطاء - ربما أكون نوعًا من خادم" خاطئ "، وفي الدقيقتين التاليتين سأرد بـ" خمسمائة "على الفحوصات الصحية. وبالتالي سأحظر نفسي! " يساعد هذا أحيانًا كثيرًا عندما يكون لديك موازن تحميل غير متحكم فيه.
- عادةً ، يكون الفاصل الزمني للفحص حوالي ثانية ، وتحتاج إلى معالج التحقق من الصحة حتى لا يقتل الخادم الخاص بك. يجب أن تكون خفيفة.
الفحوصات الصحية: التنفيذ
كقاعدة ، كل شيء هنا هو نفسه للجميع:
- طلب
- مهلة عليه ؛
- الفاصل الزمني الذي نقوم من خلاله بالتحقق. الوكلاء المخدوعون لديهم غضب ، أي بعض العشوائية بحيث لا تأتي جميع الفحوصات الصحية إلى الواجهة الخلفية مرة واحدة ، ولا تقتلها.
- الحد غير الصحي - الحد الأدنى لعدد الفحوصات الصحية الفاشلة التي يجب أن تمر حتى تتمكن الخدمة من وضع علامة عليها على أنها غير صحية.
- عتبة صحية - على العكس من ذلك ، كم عدد المحاولات الناجحة التي يجب أن تمر حتى يعود الخادم إلى التشغيل.
- منطق إضافي. يمكنك تحليل فحص الحالة + النص ، وما إلى ذلك.
تطبق Nginx وظائف الفحص الصحي فقط في الإصدار المدفوع من nginx +.
ألاحظ ميزة
Envoy ، لديها
وضع الذعر الاختيار الصحة
. عندما حظرنا ، بصفتنا "غير صحيين" ، أكثر من N٪ من المضيفين (يقولون 70٪) ، يعتقد أن جميع فحوصاتنا الصحية تكذب ، وأن جميع المضيفين على قيد الحياة. في حالة سيئة للغاية ، سيساعدك هذا في عدم مواجهة موقف حيث قمت بنفسك بإطلاق النار على ساقك وحظرت جميع الخوادم. هذه طريقة لتكون آمنًا مرة أخرى.
ضع كل ذلك معًا
عادة لفحوصات الصحة المحددة:
- أو nginx + ؛
- أو nginx + شيء آخر :)
في بلدنا ، هناك ميل لتعيين nginx + HAProxy ، لأن الإصدار المجاني من nginx لا يحتوي على فحوصات صحية ، وحتى 1.11.5 لم يكن هناك حد لعدد الاتصالات بالواجهة الخلفية. لكن هذا الخيار سيئ لأن HAProxy لا يعرف كيف يتقاعد بعد إنشاء اتصال. يعتقد الكثير من الناس أنه إذا أعاد HAProxy خطأً في إعادة محاولة nginx و nginx ، فسيكون كل شيء على ما يرام. ليس بالفعل. يمكنك الوصول إلى HAProxy آخر ونفس الخلفية ، لأن تجمعات الخلفية هي نفسها. لذا فأنت تقدم مستوى تجريد آخر لنفسك ، مما يقلل من دقة موازنتك ، وبالتالي ، توفر الخدمة.
لدينا nginx + Envoy ، ولكن إذا كنت مرتبكًا ، فيمكنك قصر نفسك على Envoy فقط.
أي نوع من المبعوثين؟
Envoy هو موازن تحميل الشباب العصري ، الذي تم تطويره في الأصل في Lyft ، مكتوبًا في C ++.
من خارج منطقة الجزاء ، يمكنه عمل مجموعة من الكعك حول موضوعنا اليوم. ربما رأيت أنها شبكة خدمة ل Kubernetes. كقاعدة ، يعمل Envoy كطائرة بيانات ، أي أنه يوازن حركة المرور مباشرة ، وهناك أيضًا طائرة تحكم توفر معلومات حول ما تحتاجه لتوزيع الحمل بين (اكتشاف الخدمة ، وما إلى ذلك).
سأخبركم ببضع كلمات عن كعكاته.
لزيادة احتمالية نجاح استجابة إعادة المحاولة في المرة التالية التي تحاول فيها ، يمكنك النوم قليلًا وانتظار ظهور الخلفية. بهذه الطريقة سنتعامل مع مشاكل قاعدة البيانات القصيرة. لدى المبعوث
تراجع عن إعادة المحاولة - توقف مؤقت بين إعادة المحاولة. علاوة على ذلك ، يزيد الفاصل الزمني للتأخير بين المحاولات بشكل كبير. تحدث إعادة المحاولة الأولى بعد 0-24 مللي ثانية ، والثانية بعد 0-74 مللي ثانية ، ثم يزيد الفاصل الزمني لكل محاولة لاحقة ، ويتم تحديد التأخير المحدد عشوائيًا من هذا الفاصل الزمني.
النهج الثاني ليس خاصًا بالمبعوث ، ولكنه نمط يسمى
كسر الدائرة (قاطع الدائرة أو المصهر). عندما تتضاءل الواجهة الخلفية ، نحاول في النهاية إنهاءها في كل مرة. هذا لأن المستخدمين في أي موقف غير مفهوم ينقرون على صفحة التحديث ، ويرسلون لك المزيد والمزيد من الطلبات الجديدة. يزعج موازنك ، ويرسل إعادة المحاولة ، ويزداد عدد الطلبات - الحمل يزداد ، وفي هذه الحالة سيكون من الجيد عدم إرسال الطلبات.
قاطع الدائرة يسمح لك فقط بتحديد أننا في هذه الحالة ، وسرعان ما نطلق النار على الخطأ ونعطي الخلفية "التقاط أنفاسهم".
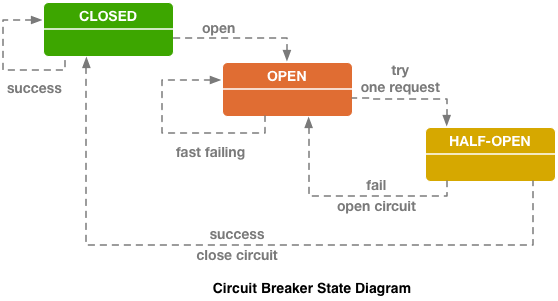 قواطع دوائر (hystrix مثل libs) ، أصلية على مدونة ebay.
قواطع دوائر (hystrix مثل libs) ، أصلية على مدونة ebay.أعلاه هي دائرة قواطع Hystrix. Hystrix هي مكتبة Java في Netflix تم تصميمها لتطبيق أنماط تحمل الخطأ.
- يمكن أن يكون "المصهر" في حالة "مغلقة" عندما يتم إرسال جميع الطلبات إلى الواجهة الخلفية ولا توجد أخطاء.
- عندما يتم تشغيل حد فشل معين ، أي أن بعض الأخطاء قد حدثت ، ينتقل قاطع الدائرة الكهربائية إلى الحالة "فتح". تقوم بإرجاع خطأ إلى العميل بسرعة ، ولا تصل الطلبات إلى الواجهة الخلفية.
- مرة واحدة في فترة زمنية معينة ، لا يزال يتم إرسال جزء صغير من الطلبات إلى الواجهة الخلفية. إذا تم تشغيل خطأ ، تظل الحالة "مفتوحة". إذا بدأ كل شيء في العمل بشكل جيد واستجاب ، فسيغلق "المصهر" ويستمر العمل.
في المبعوث ، على هذا النحو ، ليس هذا كل شيء. هناك حدود المستوى الأعلى على حقيقة أنه لا يمكن أن يكون هناك أكثر من N طلبات لمجموعة رئيسية محددة. إذا كان هناك المزيد ، هناك خطأ ما - نعرض خطأ. لا يمكن أن يكون هناك المزيد من عمليات إعادة المحاولة النشطة لـ N (أي عمليات إعادة المحاولة التي تحدث الآن).
لم يكن لديك إعادة المحاولة ، انفجر شيء ما - أرسل إعادة المحاولة. يفهم المبعوث أن أكثر من N غير طبيعي ، ويجب تصوير جميع الطلبات مع وجود خطأ.
كسر الدائرة [المبعوث]- أقصى اتصالات الكتلة (مجموعة المنبع)
- الحد الأقصى للطلبات المعلقة في المجموعة
- طلبات الكتلة القصوى
- إعادة محاولة الكتلة النشطة
يعمل هذا الشيء البسيط بشكل جيد ، فهو قابل للتكوين ، ولا يتعين عليك التوصل إلى معلمات خاصة ، والإعدادات الافتراضية جيدة جدًا.
قواطع دوائر: تجربتنا
اعتدنا أن يكون لدينا جامع مقاييس HTTP ، أي أن وكلاء مثبتين على خوادم عملائنا أرسلوا مقاييس إلى السحابة عبر HTTP. إذا كان لدينا أي مشاكل في البنية التحتية ، يكتب الوكيل المقاييس على قرصه ثم يحاول إرسالها إلينا.
ويقوم الوكلاء باستمرار بمحاولات لإرسال البيانات إلينا ، ولا يشعرون بالضيق لأننا بطريقة ما نرد بشكل غير صحيح ، ولا نغادر.
( , ) , , .
nginx limit req. , , , 200 RPS. , , , limit req.
TCP HTTP ( nginx limit req). . limit req .
, , .
Circuit breaker, , N , , - , , . , , spool .
Circuit breaker + request cancellation ( ). , N Cassandra, N Elastic, , — , . — , .
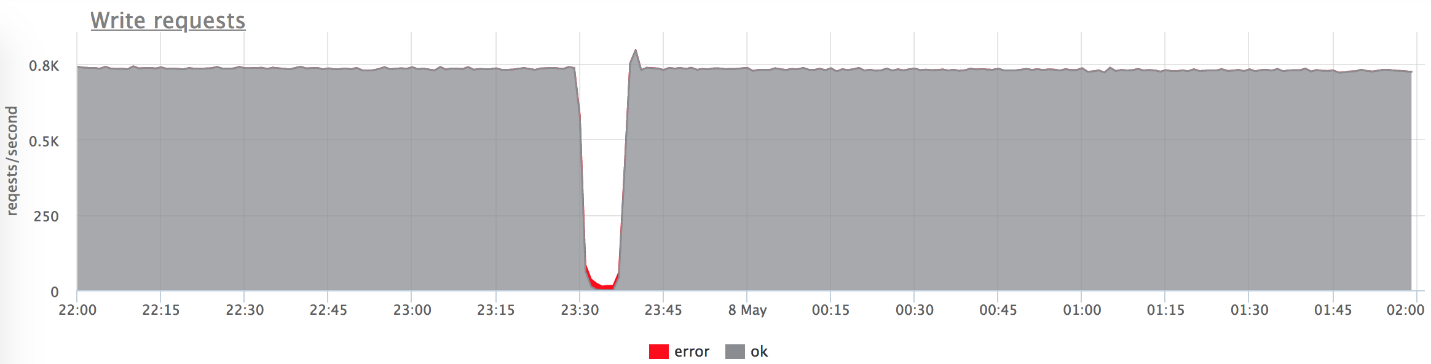
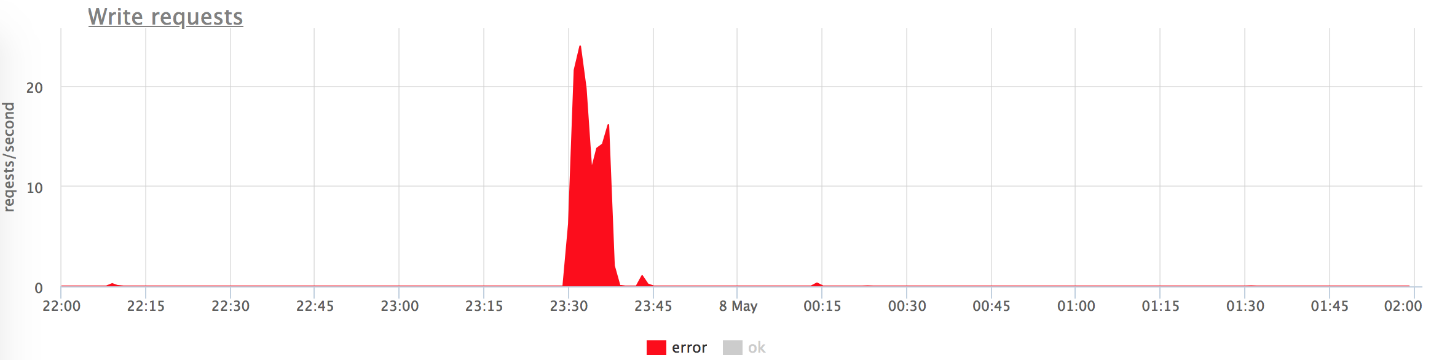
, (: — «», — «»). , 800 RPS 20-30. «», , .
— , .
, , — . .
, , , , Health checks — HTTP 200.
.
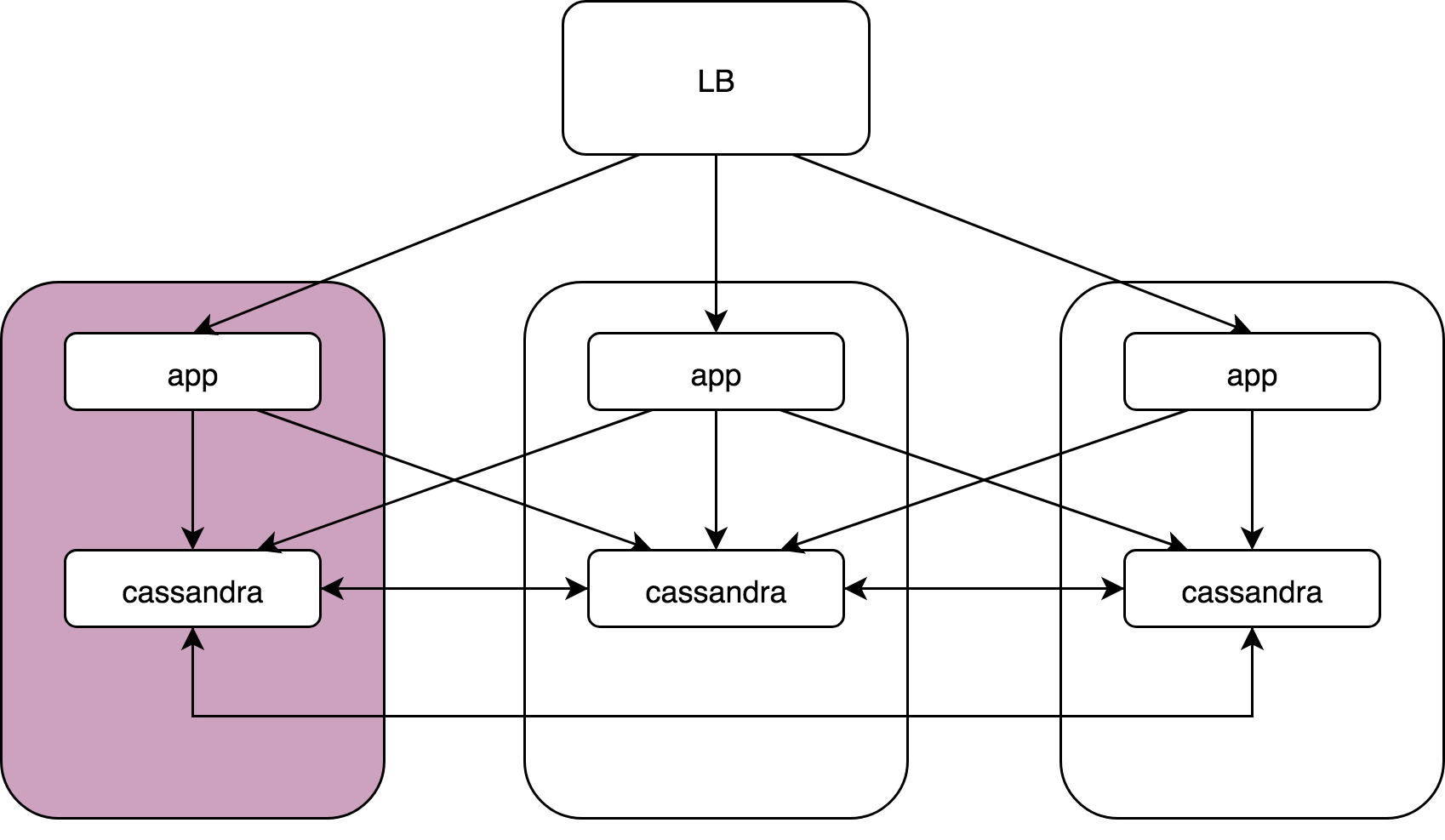
Load Balancer, 3 , Cassandra. Cassandra, Cassandra , Cassandra data noda.
— :
kernel: NETDEV WATCHDOG: eth0 (ixgbe): transmit queue 3 timed out.: ( ), 64 . , 1/64 . reboot, .
, , , . , , , . , , . , .
Cassandra: coordinator -> nodesCassandra, (speculative retries), . latency 99 , .
App -> cassandra coordinator. Cassandra «» , , , latency ..
gocql — cassandra client. . HostSelectionPolicy,
bitly/go-hostpool . Epsilon greedy , .
,
Epsilon-greedy .
(multi-armed bandit): , , N .
:
- « explore» — : 10 , , .
- « exploit» — .
, (10 — 30%)
round -
robin , , , . 70 — 90% .
Host-pool . . ( — , , ). . , , , .
«» () —Cassandra Cassandra coordinator-data. (nginx, Envoy — ) «» Application, Cassandra , , .
Envoy
Outlier detection :
- Consecutive http-5xx.
- Consecutive gateway errors (502,503,504).
- Success rate.
«» , - , . , . — , , . , , .
, «», max_ejection_percent. , outlier, . , 70% — , — , !
, — !
, , . , latency , :
,
, . , , , — , .
. 99% nginx/
HAProxy /Envoy. proxy , «».
proxy ( HAProxy:)),
, .DevOpsConf Russia Kubernetes . .
, — DevOps.
, , YouTube- — .