System.IO.Pipelines هي مكتبة جديدة تبسط تنظيم التعليمات البرمجية في .NET. من الصعب ضمان الأداء العالي والدقة إذا كان عليك التعامل مع التعليمات البرمجية المعقدة. تتمثل مهمة System.IO.Pipelines في تبسيط التعليمات البرمجية. مزيد من التفاصيل تحت الخفض!

نشأت المكتبة نتيجة لجهود فريق تطوير .NET Core لجعل Kestrel أحد
أسرع خوادم الويب في الصناعة . تم تصميمه في الأصل كجزء من تنفيذ Kestrel ، ولكنه تطور إلى واجهة برمجة تطبيقات قابلة لإعادة الاستخدام ، متوفرة في الإصدار 2.1 كواجهة برمجة تطبيقات BCL من الدرجة الأولى (System.IO.Pipelines).
ما هي المشاكل التي تحلها؟
لتحليل البيانات بشكل صحيح من دفق أو مأخذ ، تحتاج إلى كتابة كمية كبيرة من التعليمات البرمجية القياسية. في الوقت نفسه ، هناك العديد من المزالق التي تعقد الكود نفسه ودعمه.
ما الصعوبات التي تنشأ اليوم؟
لنبدأ بمهمة بسيطة. نحتاج إلى كتابة خادم TCP يتلقى رسائل مفصولة بخط (\ n) من العميل.
خادم TCP مع NetworkStream
الانحراف: كما هو الحال في أي مهمة تتطلب أداءً عاليًا ، يجب النظر في كل حالة محددة بناءً على ميزات التطبيق الخاص بك. قد لا يكون من المنطقي إنفاق الموارد على استخدام المناهج المختلفة ، والتي سيتم مناقشتها لاحقًا ، إذا لم يكن حجم تطبيق الشبكة كبيرًا جدًا.
يبدو رمز .NET العادي قبل استخدام خطوط الأنابيب شيئًا مثل هذا:
async Task ProcessLinesAsync(NetworkStream stream) { var buffer = new byte[1024]; await stream.ReadAsync(buffer, 0, buffer.Length);
راجع
sample1.cs على
جيثبمن المحتمل أن يعمل هذا الرمز مع الاختبار المحلي ، ولكن به عدد من الأخطاء:
- ربما بعد مكالمة واحدة إلى ReadAsync ، لن يتم تلقي الرسالة بالكامل (إلى نهاية السطر).
- يتجاهل نتيجة طريقة stream.ReadAsync () - كمية البيانات المنقولة بالفعل إلى المخزن المؤقت.
- لا يتعامل الرمز مع تلقي خطوط متعددة في مكالمة ReadAsync واحدة.
هذه هي أخطاء قراءة بيانات الدفق الأكثر شيوعًا. لتجنبها ، تحتاج إلى إجراء عدد من التغييرات:
- تحتاج إلى تخزين البيانات الواردة مؤقتًا حتى يتم العثور على خط جديد.
- من الضروري تحليل جميع الأسطر التي يتم إرجاعها إلى المخزن المؤقت.
async Task ProcessLinesAsync(NetworkStream stream) { var buffer = new byte[1024]; var bytesBuffered = 0; var bytesConsumed = 0; while (true) { var bytesRead = await stream.ReadAsync(buffer, bytesBuffered, buffer.Length - bytesBuffered); if (bytesRead == 0) {
انظر
sample2.cs على
جيثبأكرر: يمكن أن يعمل هذا مع الاختبار المحلي ، ولكن في بعض الأحيان يكون هناك سلاسل أطول من 1 كيلو بايت (1024 بايت). من الضروري زيادة حجم مخزن الإدخال المؤقت حتى يتم العثور على خط جديد.
بالإضافة إلى ذلك ، نقوم بتجميع المخازن المؤقتة في صفيف عند معالجة سلاسل طويلة. يمكننا تحسين هذه العملية باستخدام ArrayPool ، التي تتجنب إعادة تخصيص المخازن المؤقتة أثناء تحليل الخطوط الطويلة من العميل.
async Task ProcessLinesAsync(NetworkStream stream) { byte[] buffer = ArrayPool<byte>.Shared.Rent(1024); var bytesBuffered = 0; var bytesConsumed = 0; while (true) {
انظر sample3.cs على جيثبيعمل الرمز ، ولكن الآن تغير حجم المخزن المؤقت ، ونتيجة لذلك ، تظهر العديد من النسخ منه. يتم استخدام المزيد من الذاكرة أيضًا ، لأن المنطق لا يقلل من المخزن المؤقت بعد معالجة الخطوط. لتجنب ذلك ، يمكنك حفظ قائمة المخازن المؤقتة ، بدلاً من تغيير حجم المخزن المؤقت في كل مرة تصل سلسلة أطول من 1 كيلو بايت.
بالإضافة إلى ذلك ، نحن لا نزيد حجم المخزن المؤقت الذي يبلغ 1 كيلوبايت ، حتى يصبح فارغًا تمامًا. هذا يعني أننا سننقل مخازن أصغر وأصغر إلى ReadAsync ، ونتيجة لذلك ، سيزداد عدد المكالمات إلى نظام التشغيل.
سنحاول التخلص من هذا وسنخصص مخزنًا مؤقتًا جديدًا بمجرد أن يصبح حجم المخزن الحالي أقل من 512 بايت:
public class BufferSegment { public byte[] Buffer { get; set; } public int Count { get; set; } public int Remaining => Buffer.Length - Count; } async Task ProcessLinesAsync(NetworkStream stream) { const int minimumBufferSize = 512; var segments = new List<BufferSegment>(); var bytesConsumed = 0; var bytesConsumedBufferIndex = 0; var segment = new BufferSegment { Buffer = ArrayPool<byte>.Shared.Rent(1024) }; segments.Add(segment); while (true) {
انظر sample4.cs على جيثبونتيجة لذلك ، فإن الرمز معقد بشكل كبير. أثناء البحث عن المحدد ، نتتبع المخازن المؤقتة المعبأة. للقيام بذلك ، استخدم قائمة تعرض البيانات المخزنة مؤقتًا عند البحث عن فاصل أسطر جديد. نتيجة لذلك ، سيقبل ProcessLine و IndexOf القائمة بدلاً من البايت [] والإزاحة والعد. سيبدأ منطق التحليل في معالجة جزء واحد من المخزن المؤقت أو أكثر.
والآن سيقوم الخادم بمعالجة الرسائل الجزئية واستخدام الذاكرة المشتركة لتقليل الاستهلاك الكلي للذاكرة. ومع ذلك ، يجب إجراء عدد من التغييرات:
- من ArrayPoolbyte نستخدم فقط Byte [] - المصفوفات المدارة بشكل قياسي. بمعنى آخر ، عندما يتم تنفيذ وظائف ReadAsync أو WriteAsync ، ترتبط فترة صلاحية المخازن المؤقتة بوقت العملية غير المتزامنة (للتفاعل مع واجهات برمجة تطبيقات الإدخال / الإخراج الخاصة بنظام التشغيل). نظرًا لأنه لا يمكن نقل الذاكرة المثبتة ، فإن هذا يؤثر على أداء جامع القمامة ويمكن أن يسبب تجزئة الصفيف. قد تحتاج إلى تغيير تنفيذ التجمع ، اعتمادًا على المدة التي ستنتظرها العمليات غير المتزامنة للتنفيذ.
- يمكن تحسين الإنتاجية عن طريق قطع الارتباط بين منطق القراءة والعملية. نحصل على تأثير المعالجة المجمعة ، والآن سيكون منطق التحليل قادرًا على قراءة كميات كبيرة من البيانات ، ومعالجة كتل كبيرة من المخازن المؤقتة ، بدلاً من تحليل الخطوط الفردية. ونتيجة لذلك ، يصبح الرمز أكثر تعقيدًا:
- من الضروري إنشاء دورتين تعملان بشكل مستقل عن بعضهما البعض. سيقرأ الأول البيانات من المقبس ، والثاني سيحلل المخازن المؤقتة.
- المطلوب هو طريقة لإخبار منطق التحليل بأن البيانات أصبحت متاحة.
- من الضروري أيضًا تحديد ما يحدث إذا كانت الحلقة تقرأ البيانات من المقبس بسرعة كبيرة. نحتاج إلى طريقة لضبط دورة القراءة إذا كان منطق التحليل لا يواكبها. ويشار إلى ذلك عادة باسم "التحكم في التدفق" أو "مقاومة التدفق".
- يجب أن نتأكد من إرسال البيانات بشكل آمن. الآن يتم استخدام مجموعة المخازن المؤقتة من قبل كل من دورة القراءة ودورة التحليل ؛ وهي تعمل بشكل مستقل عن بعضها البعض على سلاسل مختلفة.
- يشترك منطق إدارة الذاكرة أيضًا في جزأين مختلفين من التعليمات البرمجية: استعارة البيانات من تجمع المخزن المؤقت ، الذي يقرأ البيانات من المقبس ، والعودة من تجمع المخزن المؤقت ، وهو منطق التحليل.
- يجب على المرء توخي الحذر الشديد في إعادة المخازن المؤقتة بعد تنفيذ منطق التحليل. خلاف ذلك ، هناك فرصة بأن نعيد المخزن المؤقت الذي لا يزال يكتب فيه منطق قراءة مأخذ التوصيل.
يبدأ التعقيد بالمرور من السقف (وهذا بعيد عن كل الحالات!). لإنشاء شبكة عالية الأداء ، تحتاج إلى كتابة رمز معقد للغاية.
الغرض من System.IO.Pipelines هو تبسيط هذا الإجراء.
خادم TCP و System.IO.Pipelines
دعونا نرى كيف يعمل System.IO.Pipelines:
async Task ProcessLinesAsync(Socket socket) { var pipe = new Pipe(); Task writing = FillPipeAsync(socket, pipe.Writer); Task reading = ReadPipeAsync(pipe.Reader); return Task.WhenAll(reading, writing); } async Task FillPipeAsync(Socket socket, PipeWriter writer) { const int minimumBufferSize = 512; while (true) {
انظر sample5.cs على جيثبتحتوي نسخة خط الأنابيب من قارئ الخط على حلقتين:
- يقرأ FillPipeAsync من مأخذ التوصيل ويكتب إلى PipeWriter.
- يقرأ ReadPipeAsync من PipeReader ويوزع الخطوط الواردة.
على عكس الأمثلة الأولى ، لا توجد مخازن مؤقتة مخصصة لهذا الغرض. هذه إحدى الوظائف الرئيسية لـ System.IO.Pipelines. يتم نقل جميع مهام إدارة المخزن المؤقت إلى تطبيقات PipeReader / PipeWriter.
الإجراء مبسط: نستخدم الكود فقط لمنطق الأعمال ، بدلاً من تطبيق إدارة المخزن المؤقت المعقدة.
في الحلقة الأولى ، يتم استدعاء PipeWriter.GetMemory (int) أولاً للحصول على قدر معين من الذاكرة من الكاتب الرئيسي. ثم يتم استدعاء PipeWriter.Advance (int) ، والذي يخبر PipeWriter بمقدار البيانات المكتوبة بالفعل إلى المخزن المؤقت. ويتبع ذلك استدعاء PipeWriter.FlushAsync () بحيث يمكن PipeReader الوصول إلى البيانات.
تستهلك الحلقة الثانية المخازن المؤقتة التي كتبها PipeWriter ولكن تم استلامها في الأصل من المقبس. عندما يتم إرجاع الطلب إلى PipeReader.ReadAsync () ، نحصل على ReadResult يحتوي على رسالتين مهمتين: البيانات التي يتم قراءتها في النموذج ReadOnlySequence ، بالإضافة إلى نوع البيانات المنطقية IsCompleted ، والتي تخبر القارئ ما إذا كان الكاتب قد انتهى من العمل (EOF). عندما يتم العثور على حرف نهاية الخط (EOL) ويتم تحليل السلسلة ، سنقوم بتقسيم المخزن المؤقت إلى أجزاء لتخطي الجزء الذي تمت معالجته بالفعل. بعد ذلك ، يتم استدعاء PipeReader.AdvanceTo ويخبر PipeReader عن كمية البيانات التي تم استهلاكها.
في نهاية كل دورة ، يكتمل كل من القارئ والكاتب. ونتيجة لذلك ، تطلق القناة الرئيسية جميع الذاكرة المخصصة.
System.io.pipelines
قراءة جزئية
بالإضافة إلى إدارة الذاكرة ، يؤدي System.IO.Pipelines وظيفة مهمة أخرى: فهو يقوم بمسح البيانات في القناة ، ولكنه لا يستهلكها.
يحتوي PipeReader على واجهتين رئيسيتين API: ReadAsync و AdvanceTo. يتلقى ReadAsync بيانات من القناة ، يخبر AdvanceTo موقع TubeReader أن القارئ لم يعد مطلوبًا من القارئ ، لذا يمكنك التخلص منها (على سبيل المثال ، إعادتها إلى تجمع المخزن المؤقت الرئيسي).
فيما يلي مثال لمحلل HTTP الذي يقرأ البيانات من مخازن بيانات القناة الجزئية حتى يتلقى خط بداية مناسب.

ReadOnlySequenceT
يخزن تنفيذ القناة قائمة المخازن المؤقتة ذات الصلة التي تم تمريرها بين PipeWriter و PipeReader. يعرض PipeReader.ReadAsync ReadOnlySequence ، وهو نوع جديد من BCL ويتكون من مقطع ReadOnlyMemory <T> واحد أو أكثر. إنه يشبه Span أو Memory ، مما يمنحنا الفرصة للنظر في المصفوفات والأوتار.
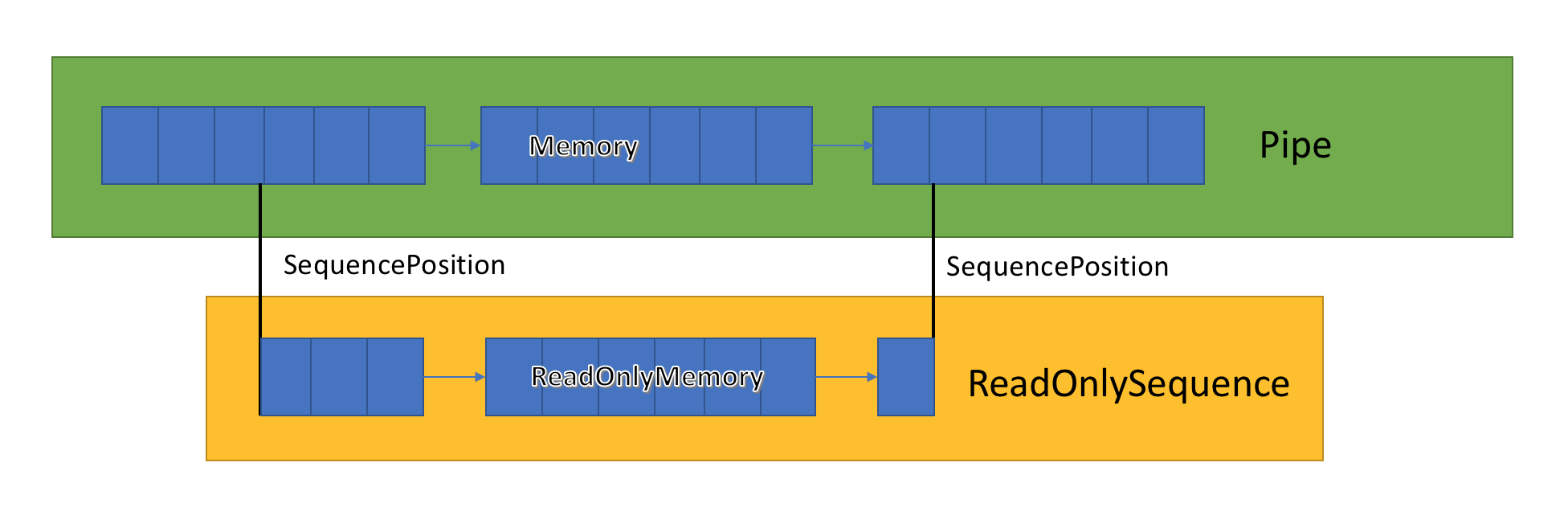
يوجد داخل القناة مؤشرات توضح مكان وجود القارئ والكاتب في المجموعة العامة للبيانات المميزة ، كما يتم تحديثها أثناء كتابة البيانات وقراءتها. SequencePosition هي نقطة واحدة في قائمة المخازن المؤقتة المرتبطة وتستخدم لفصل ReadOnlySequence بكفاءة <T>.
نظرًا لأن ReadOnlySequence <T> يدعم مقطعًا واحدًا أو أكثر ، فإن التشغيل القياسي للمنطق عالي الأداء هو فصل المسارات السريعة والبطيئة استنادًا إلى عدد الأجزاء.
كمثال ، هنا دالة تحول ASCII ReadOnlySequence إلى سلسلة:
string GetAsciiString(ReadOnlySequence<byte> buffer) { if (buffer.IsSingleSegment) { return Encoding.ASCII.GetString(buffer.First.Span); } return string.Create((int)buffer.Length, buffer, (span, sequence) => { foreach (var segment in sequence) { Encoding.ASCII.GetChars(segment.Span, span); span = span.Slice(segment.Length); } }); }
انظر
sample6.cs على
جيثبمقاومة التدفق والتحكم في التدفق
من الناحية المثالية ، تعمل القراءة والتحليل معًا: يستهلك دفق القراءة البيانات من الشبكة ويضعها في المخازن المؤقتة ، بينما ينشئ دفق التحليل هياكل البيانات المناسبة. يستغرق التحليل عادةً وقتًا أطول من مجرد نسخ كتل البيانات من الشبكة. ونتيجة لذلك ، يمكن أن يثقل دفق القراءة بسهولة دفق التحليل. لذلك ، سيضطر دفق القراءة إما إلى إبطاء أو استهلاك المزيد من الذاكرة لحفظ البيانات في دفق التحليل. لضمان الأداء الأمثل ، يلزم التوازن بين تردد الإيقاف المؤقت وتخصيص مساحة كبيرة من الذاكرة.
لحل هذه المشكلة ، يحتوي خط الأنابيب على وظيفتين للتحكم في تدفق البيانات: PauseWriterThreshold و ResumeWriterThreshold. يحدد PauseWriterThreshold مقدار البيانات التي يجب تخزينها مؤقتًا قبل أن يتم إيقاف PipeWriter.FlushAsync مؤقتًا. تحدد ResumeWriterThreshold مقدار الذاكرة التي يمكن أن يستهلكها القارئ قبل استئناف تشغيل المسجل.
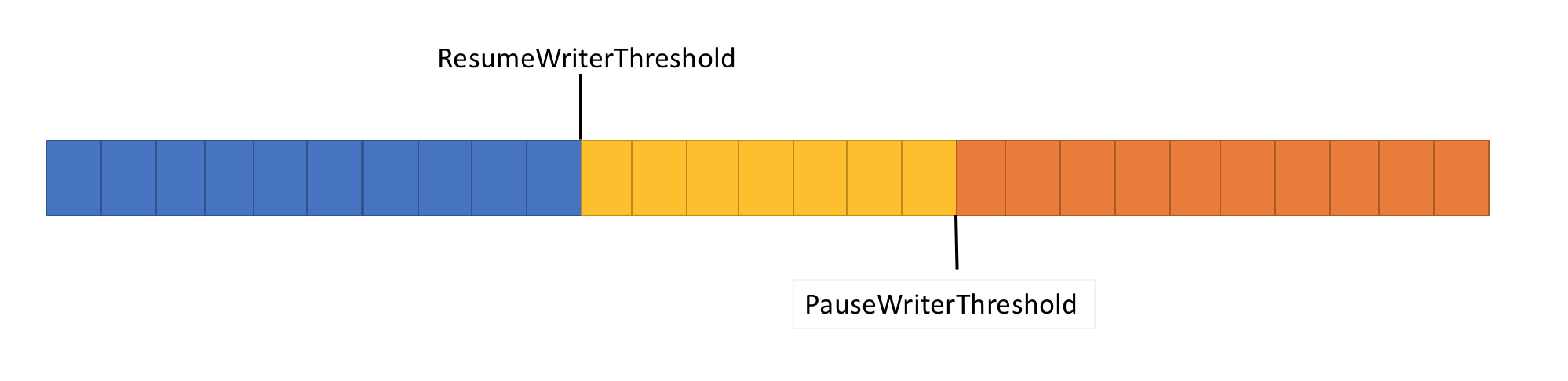
PipeWriter.FlushAsync "يقفل" عندما تتجاوز كمية البيانات في التدفق الموجه للأنابيب الحد المعين في PauseWriterThreshold ، و "يفتح" عندما يكون أقل من الحد المعين في ResumeWriterThreshold. لمنع تجاوز حد الاستهلاك ، يتم استخدام قيمتين فقط.
جدولة I / O
عند استخدام async / await ، عادة ما يتم استدعاء العمليات اللاحقة إما في سلاسل عمليات التجمع أو في SynchronizationContext الحالي.
عند إجراء الإدخال / الإخراج ، من المهم جدًا مراقبة مكان تنفيذه بعناية من أجل استخدام ذاكرة التخزين المؤقت للمعالج بشكل أفضل. هذا أمر بالغ الأهمية للتطبيقات عالية الأداء مثل خوادم الويب. يستخدم System.IO.Pipelines PipeScheduler لتحديد مكان تنفيذ عمليات الاسترجاعات غير المتزامنة. هذا يسمح لك بالتحكم بدقة في التدفقات التي تستخدم في I / O.
مثال على التطبيق العملي هو النقل Kestrel Libuv ، حيث يتم إجراء عمليات رد الاتصال I / O على قنوات مخصصة لحلقة الحدث.
هناك فوائد أخرى لقالب PipeReader.
- تدعم بعض الأنظمة الأساسية "الانتظار دون تخزين مؤقت": لست بحاجة إلى تخصيص مخزن مؤقت حتى تظهر البيانات المتاحة في النظام الأساسي. لذلك ، في Linux مع epoll ، لا يمكنك توفير مخزن مؤقت للقراءة حتى تصبح البيانات جاهزة. هذا يتجنب الموقف عندما يكون هناك العديد من مؤشرات الترابط في انتظار البيانات ، وتحتاج إلى حجز مساحة كبيرة من الذاكرة على الفور.
- يجعل خط الأنابيب الافتراضي من السهل كتابة اختبارات الوحدة لرمز الشبكة: منطق التحليل منفصل عن رمز الشبكة ، ولا تقوم اختبارات الوحدة إلا بتشغيل هذا المنطق في المخازن المؤقتة في الذاكرة ، بدلاً من استهلاكه مباشرة من الشبكة. كما أنه يسهل اختبار الأنماط المعقدة عن طريق إرسال بيانات جزئية. يستخدمه ASP.NET Core لاختبار مختلف جوانب أدوات تحليل http من Kestrel.
- تعتبر الأنظمة التي تسمح لكود المستخدم باستخدام المخازن الرئيسية لنظام التشغيل (على سبيل المثال ، واجهات برمجة تطبيقات Windows I / O المسجلة) مناسبة مبدئيًا لاستخدام خطوط الأنابيب لأن تطبيق PipeReader يوفر دائمًا المخازن المؤقتة.
أنواع أخرى ذات صلة
أضفنا أيضًا عددًا من أنواع BCL البسيطة الجديدة إلى System.IO.Pipelines:
- MemoryPoolT و IMemoryOwnerT و MemoryManagerT . تمت إضافة ArrayPoolT في .NET Core 1.0 ، وفي .NET Core 2.1 ، يوجد الآن تمثيل تجريدي أكثر عمومية لتجمع يعمل مع أي MemoryT. نحصل على نقطة القابلية للتوسعة التي تسمح لنا بتنفيذ استراتيجيات توزيع أكثر تقدمًا ، بالإضافة إلى إدارة المخزن المؤقت للتحكم (على سبيل المثال ، استخدام المخازن المؤقتة المحددة مسبقًا بدلاً من المصفوفات المدارة حصريًا).
- IBufferWriterT هو جهاز استقبال لتسجيل البيانات المخزنة المتزامنة (التي تنفذها PipeWriter).
- IValueTaskSource - لقد وجدت ValueTaskT منذ إصدار .NET Core 1.1 ، ولكن في .NET Core 2.1 اكتسبت أدوات فعالة للغاية توفر عمليات غير متزامنة دون انقطاع دون توزيع. انظر هنا لمزيد من المعلومات.
كيفية استخدام الناقلات؟
توجد واجهات برمجة التطبيقات في حزمة nuget
System.IO.Pipelines .
للحصول على مثال لتطبيق خادم .NET Server 2.1 الذي يستخدم خطوط الأنابيب لمعالجة الرسائل الصغيرة (من المثال أعلاه) ، انظر
هنا . يمكن البدء باستخدام تشغيل dotnet (أو Visual Studio). في المثال ، من المتوقع أن يتم نقل البيانات من مأخذ التوصيل على المنفذ 8087 ، ثم تتم كتابة الرسائل المستلمة على وحدة التحكم. يمكنك استخدام عميل ، مثل netcat أو معجون ، للاتصال بالمنفذ 8087. أرسل رسالة صغيرة وشاهد كيف تعمل.
يعمل خط الأنابيب حاليًا على Kestrel و SignalR ، ونأمل أن يجد تطبيقًا أوسع في العديد من مكتبات الشبكات ومكونات مجتمع .NET في المستقبل.