هذه الملاحظة هي نسخة مكتوبة من تقريري "كيفية إتلاف الأداء باستخدام كود غير فعال" من مؤتمر JPoint 2018. يمكنك مشاهدة مقاطع الفيديو والشرائح على صفحة المؤتمر . في الجدول ، تم وضع علامة على التقرير بكوب هجومي من العصائر ، لذلك لن يكون هناك أي شيء معقد للغاية ، هذا أكثر احتمالًا للمبتدئين.
موضوع التقرير:
- كيفية إلقاء نظرة على الرمز للعثور على الاختناقات فيه
- مضادات الاكتئاب الشائعة
- أشعل النار غير واضحة
- أشعل النار تجاوز
على الهامش ، أشاروا إلى بعض عدم الدقة / السهو في التقرير ، وقد لوحظوا هنا. التعليقات هي أيضا موضع ترحيب.
تأثير الأداء على الأداء
هناك فئة مستخدم:
class User { String name; int age; }
نحن بحاجة إلى مقارنة الكائنات مع بعضها البعض ، لذلك نعلن عن طرق equals و hashCode :
import lombok.EqualsAndHashCode; @EqualsAndHashCode class User { String name; int age; }
الكود قابل للتطبيق ، والسؤال مختلف: هل سيكون أداء هذا الكود هو الأفضل؟ للإجابة عليه ، دعنا نتذكر ميزات أسلوب Object::equals : فهي تُرجع نتيجة إيجابية فقط عندما تكون جميع الحقول التي تتم مقارنتها متساوية ، وإلا ستكون النتيجة سلبية. وبعبارة أخرى ، هناك فرق واحد يكفي بالفعل للحصول على نتيجة سلبية.
بعد @EqualsAndHashCode على الرمز الذي تم إنشاؤه لـ @EqualsAndHashCode سنرى شيئًا مثل هذا:
public boolean equals(Object that) {
يتوافق ترتيب التحقق من الحقول مع ترتيب إعلانها ، وهو في حالتنا ليس الحل الأفضل ، لأن مقارنة الأشياء باستخدام equals "أصعب" من مقارنة الأنواع البسيطة.
حسنًا ، دعنا نحاول إنشاء طرق equals/hashCode باستخدام الفكرة:
@Override public boolean equals(Object o) { if (this == o) { return true; } if (o == null || getClass() != o.getClass()) { return false; } User that = (User) o; return age == that.age && Objects.equals(name, that.name); }
تنشئ الفكرة رمزًا أكثر ذكاءً يعرف مدى تعقيد مقارنة الأنواع المختلفة من البيانات. حسنًا ، @EqualsAndHashCode صراحة equals/hashCode . الآن دعونا نرى ما يحدث عندما يمتد الفصل:
class User { List<T> props; String name; int age; }
إعادة إنشاء equals/hashCode
@Override public boolean equals(Object o) { if (this == o) { return true; } if (o == null || getClass() != o.getClass()) { return false; } User that = (User) o; return age == that.age && Objects.equals(props, that.props)
تتم مقارنة القوائم قبل مقارنة السلاسل ، وهو أمر لا معنى له عندما تكون السلاسل مختلفة. للوهلة الأولى ، لا يوجد فرق كبير ، لأن السلاسل ذات الطول المتساوي تتم مقارنتها بالعلامات (أي أن وقت المقارنة ينمو جنبًا إلى جنب مع طول السلسلة):
كان هناك عدم دقةإن أسلوب java.lang.String::equals تدخلي ، لذا لا توجد مقارنة تسجيل دخول عند التنفيذ.
الآن فكر في مقارنة ArrayList (كتطبيق القائمة الأكثر استخدامًا). عند فحص ArrayList ، نفاجأ عندما نجد أنه ليس لديه تطبيق خاص به equals ، ولكنه يستخدم تطبيقًا موروثًا:
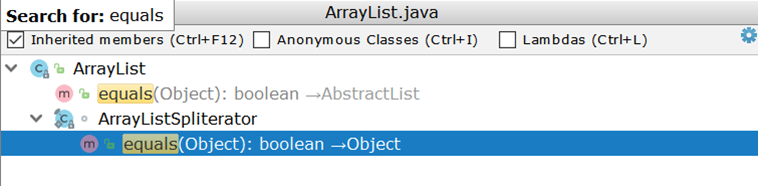
المهم هنا هو إنشاء اثنين من التكرارات والمرور الثنائي بينهما. افترض أن هناك ArrayList :
- في رقم واحد من 1 إلى 99
- في الرقم الثاني من 1 إلى 100
من الناحية المثالية ، سيكون من الكافي مقارنة أحجام القائمتين ، وإذا لم يتطابقوا ، فقم بإرجاع نتيجة سلبية على الفور (كما تفعل AbstractSet ) ، في الواقع ، سيتم إجراء 99 مقارنة ، وفي المائة فقط سوف يتضح أن القوائم مختلفة.
ماذا يوجد مع Kotlinites؟
data class User(val name: String, val age: Int);
هنا كل شيء يشبه لومبوك - ترتيب المقارنة يتوافق مع ترتيب الإعلان:
public boolean equals(Object o) { if (this == o) { return true; } if (o instanceof User) { User u = (User) o; if (Intrinsics.areEqual(name, u.name) && age == u.age) {
كحل مؤقت ، يمكنك تنظيم الإعلانات الميدانية يدويًا.
دعونا نعقد المهمة
void check(Dto dto) { SomeEntity entity = jpaRepository.findOne(dto.getId()); boolean valid = dto.isValid(); if (valid && entity.hasGoodRating()) {
يتضمن الرمز الوصول إلى قاعدة البيانات حتى عندما تكون نتيجة التحقق من الشروط التي يشير إليها السهم متوقعة مسبقًا. إذا كانت قيمة المتغير valid خاطئة ، فلن يتم تنفيذ التعليمات البرمجية في كتلة if مطلقًا ، مما يعني أنه يمكنك الاستغناء عن الطلب:
void check(Dto dto) { boolean valid = dto.isValid(); if (valid && hasGoodRating(dto)) {
ملاحظة من الهامشيمكن أن يكون الغرق غير مهم عندما يكون الكيان الذي تم إرجاعه من JpaRepository::findOne بالفعل في ذاكرة التخزين المؤقت للمستوى الأول - فلن يكون هناك أي طلب.
مثال مشابه بدون تفرع صريح:
boolean checkChild(Dto dto) { Long id = dto.getId(); Entity entity = jpaRepository.findOne(id); return dto.isValid() && entity.hasChild(); }
يتيح لك الإرجاع السريع تأخير الطلب:
boolean checkChild(Dto dto) { if (!dto.isValid()) { return false; } return jpaRepository.findOne(dto.getId()).hasChild(); }
إضافة واضحة إلى حد ما لم تظهر في التقريرتخيل أن شيكًا معينًا يستخدم كيانًا مشابهًا:
@Entity class ParentEntity { @ManyToOne(fetch = LAZY) @JoinColumn(name = "CHILD_ID") private ChildEntity child; @Enumerated(EnumType.String) private SomeType type;
إذا كان الشيك يستخدم نفس الكيان ، فيجب عليك التأكد من أن الاستدعاء إلى الكيانات / المجموعات الفرعية "البطيئة" يتم إجراؤها بعد الاستدعاء للحقول التي تم تحميلها بالفعل. للوهلة الأولى ، لن يكون لطلب واحد إضافي تأثير كبير على الصورة العامة ، ولكن كل شيء يمكن أن يتغير عند تنفيذ الإجراء في حلقة.
الخلاصة: ينبغي ترتيب سلاسل الإجراءات / الشيكات من أجل زيادة تعقيد العمليات الفردية ، ربما لن يتم تنفيذ بعضها.
دورات ومعالجة مجمعة
لا يحتاج المثال التالي إلى تفسيرات خاصة:
@Transactional void enrollStudents(Set<Long> ids) { for (Long id : ids) { Student student = jpaRepository.findOne(id);
نظرًا لاستعلامات قاعدة بيانات متعددة ، فإن الرمز بطيء.
ملاحظةيمكن أن enrollStudents الأداء بشكل أكبر إذا enrollStudents تنفيذ طريقة التسجيل enrollStudents خارج المعاملة: ثم سيتم تنفيذ كل استدعاء لـ osdjrJpaRepository::findOne في معاملة جديدة (انظر SimpleJpaRepository ) ، مما يعني تلقي اتصال بقاعدة البيانات وإعادته ، بالإضافة إلى إنشاء ذاكرة التخزين المؤقت للمستوى الأول وإعادتها.
الإصلاح:
@Transactional void enrollStudents(Set<Long> ids) { if (ids.isEmpty()) { return; } for (Student student : jpaRepository.findAll(ids)) { enroll(student); } }
دعنا نقيس وقت التشغيل (بالميكروثانية) لمجموعة من المفاتيح (10 و 100 قطعة) المعيار
ملاحظةإذا كنت تستخدم Oracle ومررت أكثر من 1000 مفتاح findAll على findAll ، فستحصل على الاستثناء ORA-01795: maximum number of expressions in a list is 1000 .
أيضًا ، قد يكون أداء الاستعلامات الثقيلة (مع العديد من المفاتيح) أسوأ من n الاستعلامات. كل هذا يتوقف على التطبيق المحدد ، لذلك يمكن أن يؤدي الاستبدال الميكانيكي للدورة إلى المعالجة الجماعية إلى تدهور الأداء.
مثال أكثر تعقيدًا حول نفس الموضوع
for (Long id : ids) { Region region = jpaRepository.findOne(id); if (region == null) {
في هذه الحالة ، لا يمكننا استبدال الحلقة بـ JpaRepository::findAll ، JpaRepository::findAll هذا سيكسر المنطق: جميع القيم التي تم الحصول عليها من JpaRepository::findAll لن تكون null ولن تعمل كتلة if .
حقيقة أن لكل مفتاح قاعدة بيانات سيساعدنا على حل هذه الصعوبة
إرجاع القيمة الفعلية أو غيابه. بمعنى أن قاعدة البيانات هي قاموس. تعطينا جافا من الصندوق تنفيذًا جاهزًا للقاموس - HashMap - الذي سنقوم على رأسه ببناء المنطق لاستبدال قاعدة البيانات:
Map<Long, Region> regionMap = jpaRepository.findAll(ids) .stream() .collect(Collectors.toMap(Region::getId, Function.identity())); for (Long id : ids) { Region region = map.get(id); if (region == null) { region = new Region(); region.setId(id); } use(region); }
مثال عكسي
ينشئ هذا الرمز دائمًا معاملة جديدة لحفظ قائمة الكيانات. يبدأ الترهل بمكالمات متعددة لطريقة تفتح معاملة جديدة:
الحل: قم بتطبيق طريقة Saver::save الفور لمجموعة البيانات بالكامل:
@Transactional public void audit(List<AuditDto> inserts) { List<AuditEntity> bulk = inserts .map(this::toEntities) .flatMap(List::stream)
يتم دمج الكثير من المعاملات في صفقة واحدة ، مما يعطي زيادة ملموسة (الوقت بالميكروثانية): المعيار
من الصعب إضفاء الطابع الرسمي على مثال للمعاملات المتعددة ، والذي لا يمكن قوله عن استدعاء JpaRepository::findOne في حلقة.
لا ينطبق هذا النهج على قاعدة البيانات فقط ، لذلك ذهب Tagir lany Valeev إلى أبعد من ذلك. وإذا كتبنا سابقًا مثل هذا:
List<Long> list = new ArrayList<>(); for (Long id : items) { list.add(id); }
وكل شيء على ما يرام ، الآن تقترح "الفكرة" تصحيح نفسها:
List<Long> list = new ArrayList<>(); list.addAll(items);
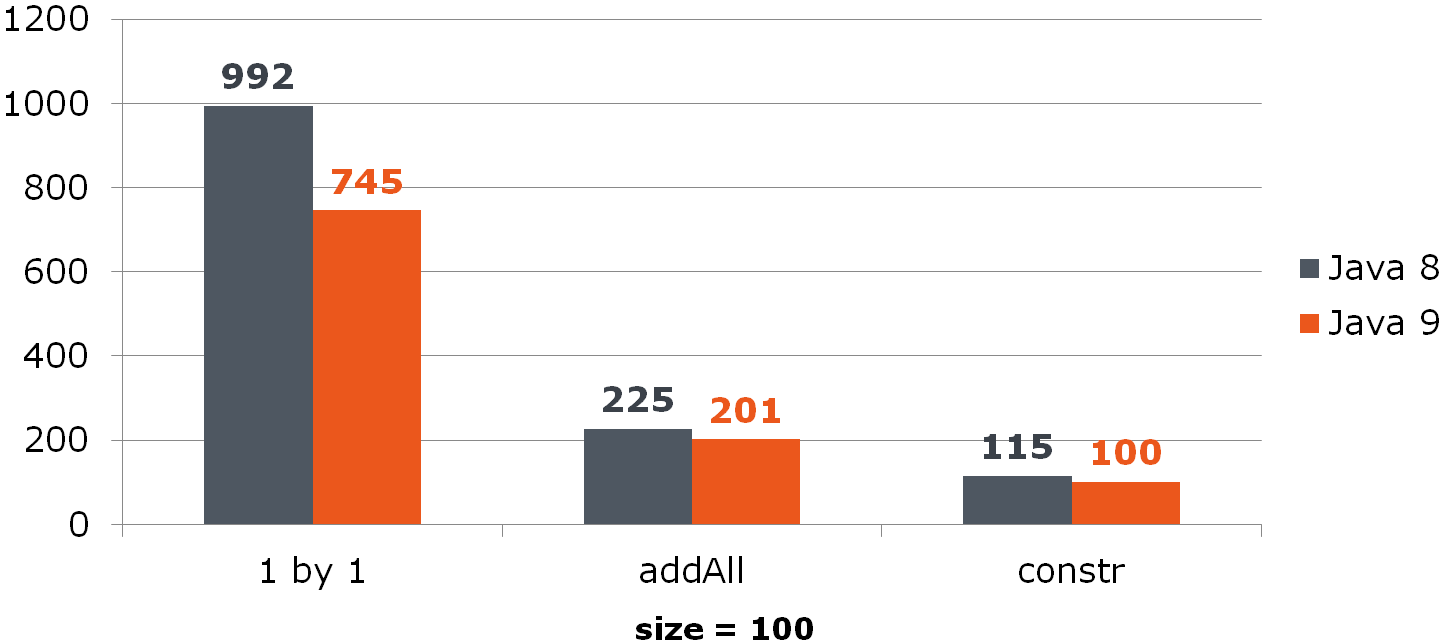
ولكن حتى هذا الخيار لا يرضيه دائمًا ، لأنه يمكنك جعله أقصر وأسرع:
List<Long> list = new ArrayList<>(items);
قارن (الوقت بالثواني)بالنسبة إلى ArrayList ، يعطي هذا التحسين زيادة ملحوظة:
بالنسبة لـ HashSet ، إنها ليست وردية:

المعيار
إزالة من ArrayList
for (int i = from; i < to; i++) { list.remove(from); }
تكمن المشكلة في تنفيذ أسلوب List::remove :
public E remove(int index) { Objects.checkIndex(index, size); modCount++; E oldValue = elementData(index); int numMoved = size - index - 1; if (numMoved > 0) { System.arraycopy(array, index + 1, array, index, numMoved);
الحل:
list.subList(from, to).clear();
ولكن ماذا لو تم استخدام القيمة البعيدة في التعليمات البرمجية المصدر؟
for (int i = from; i < to; i++) { E removed = list.remove(from); use(removed); }
الآن تحتاج إلى مراجعة القائمة المنظفة أولاً:
List<String> removed = list.subList(from, to); removed.forEach(this::use); removed.clear();
إذا كنت تريد حقًا الحذف في الدورة ، فإن تغيير اتجاه المرور عبر القائمة سيساعد في تخفيف الألم. معناه تغيير عدد أقل من العناصر بعد تنظيف الخلية:
قارن بين الطرق الثلاثة (تحت الأعمدة٪ العناصر المحذوفة من قائمة بحجم 100):
بالمناسبة ، هل لاحظ أحدهم الشذوذ؟
لنرى
إذا قمنا بحذف نصف جميع البيانات التي تنتقل من النهاية ، فسيتم حذف العنصر الأخير دائمًا وليس هناك إزاحة:
المعيار
الخلاصة: العمليات الجماعية غالبًا ما تكون أسرع من العمليات الفردية.
النطاق والأداء
لا يحتاج هذا الرمز إلى أي تفسيرات خاصة:
void leaveForTheSecondYear() { List<Student> naughty = repository.findNaughty(); List<Student> underAchieving = repository.findUnderAchieving();
نقوم بتضييق النطاق ، مما يعطي ناقص 1 استعلام:
void leaveForTheSecondYear() { List<Student> naughty = repository.findNaughty(); if (Settings.leaveBothCategories()) { List<Student> underAchieving = repository.findUnderAchieving();
وهنا يجب أن يسأل القارئ اليقظ: ماذا عن التحليل الساكن؟ لماذا لم تخبرنا Idea عن التحسن في الاستلقاء على السطح؟
والحقيقة هي أن إمكانيات التحليل الثابت محدودة: إذا كانت الطريقة معقدة (خاصة التفاعل مع قاعدة البيانات) وتؤثر على الحالة العامة ، فإن نقل تنفيذها يمكن أن يكسر التطبيق. المحلل الساكن قادر على الإبلاغ عن عمليات الإعدام البسيطة للغاية ، ولن يؤدي نقلها ، على سبيل المثال ، داخل الكتلة إلى كسر أي شيء.
يمكنك استخدام إبراز متغير كإرساتز ، ولكن مرة أخرى ، استخدمه بعناية ، لأن الآثار الجانبية ممكنة دائمًا. يمكنك استخدام التعليق التوضيحي @org.jetbrains.annotations.Contract(pure = true) ، المتوفر من مكتبة التعليقات التوضيحية jetbrains للإشارة إلى الأساليب عديمة الحالة :
الخلاصة: في كثير من الأحيان ، يزيد العمل الزائد من سوء الأداء.
معظم الأمثلة غير العادية
@Service public class RemoteService { private ContractCounter contractCounter; @Transactional(readOnly = true)
يفتح هذا التنفيذ معاملة حتى عندما لا تكون هناك حاجة للمعاملة (عائد سريع -1 من الطريقة).
كل ما عليك فعله هو إزالة المعاملات داخل طريقة ContractCounter::countContracts ، حيث تكون هناك حاجة إليها ، وإزالتها من الطريقة "الخارجية".
قارن وقت التنفيذ للحالة عند إرجاع -1 (ns): قارن استهلاك الذاكرة (بايت): المعيار
الخلاصة: يجب أن يتم تحرير وحدات التحكم والخدمات "الخارجية" من المعاملات (هذه ليست مسؤوليتهم) ويجب أن يتم أخذ منطق التحقق من بيانات الإدخال بالكامل ، والذي لا يتطلب الوصول إلى قاعدة البيانات ومكونات المعاملات ، هناك.
تحويل التاريخ / الوقت إلى سلسلة
إحدى المهام الأبدية هي تحويل التاريخ / الوقت إلى سلسلة. قبل G8 ، قمنا بذلك:
SimpleDateFormat formatter = new SimpleDateFormat("dd.MM.yyyy"); String dateAsStr = formatter.format(date);
مع إصدار JDK 8 ، حصلنا على LocalDate/LocalDateTime ، وبالتالي ، DateTimeFormatter
DateTimeFormatter formatter = ofPattern("dd.MM.yyyy"); String dateAsStr = formatter.format(localDate);
دعنا نقيس أدائها:
Date date = new Date(); LocalDate localDate = LocalDate.now(); SimpleDateFormat sdf = new SimpleDateFormat("dd.MM.yyyy"); DateTimeFormatter dtf = DateTimeFormatter.ofPattern("dd.MM.yyyy"); @Benchmark public String simpleDateFormat() { return sdf.format(date); } @Benchmark public String dateTimeFormatter() { return dtf.format(localDate); }
سؤال: لنفترض أن خدمتنا تتلقى بيانات من الخارج ولا يمكننا رفض java.util.Date . هل سيكون من المفيد بالنسبة لنا تحويل Date إلى LocalDate إذا تم تحويل الأخير بشكل أسرع إلى سلسلة؟ احسب:
@Benchmark public String measureDateConverted(Data data) { LocalDate localDate = toLocalDate(data.date); return data.dateTimeFormatter.format(localDate); } private LocalDate toLocalDate(Date date) { return date.toInstant().atZone(ZoneId.systemDefault()).toLocalDate(); }
وبالتالي ، فإن Date التحويل -> LocalDate مفيد عند استخدام "التسعة". في G8 ، ستلتهم تكاليف التحويل جميع مزايا DateTimeFormatter -a.
المعيار
الخلاصة: الاستفادة من الحلول الجديدة.
آخر "ثمانية"
في هذا الكود ، نرى تكرارًا واضحًا:
Iterator<Long> iterator = items
نقوم بإزالته:
Iterator<Long> iterator = items
دعونا نرى مدى تحسن الأداء: حق مدهش؟ لقد جادلت أعلاه أن العمل الزائد يحط من الأداء. ولكن هنا نزيل الفائض - (فجأة) يصبح أسوأ. لفهم ما يحدث ، خذ مكررين وانظر إليهما تحت عدسة مكبرة:
إفشاء Iterator iterator1 = items.stream().collect(toList()).iterator(); Iterator iterator2 = items.stream().iterator();

المكرر الأول هو ArrayList$Itr العادي.
المرور عبره بسيط: public boolean hasNext() { return cursor != size; } public E next() { checkForComodification(); int i = cursor; if (i >= size) { throw new NoSuchElementException(); } Object[] elementData = ArrayList.this.elementData; if (i >= elementData.length) { throw new ConcurrentModificationException(); } cursor = i + 1; return (E) elementData[lastRet = i]; }
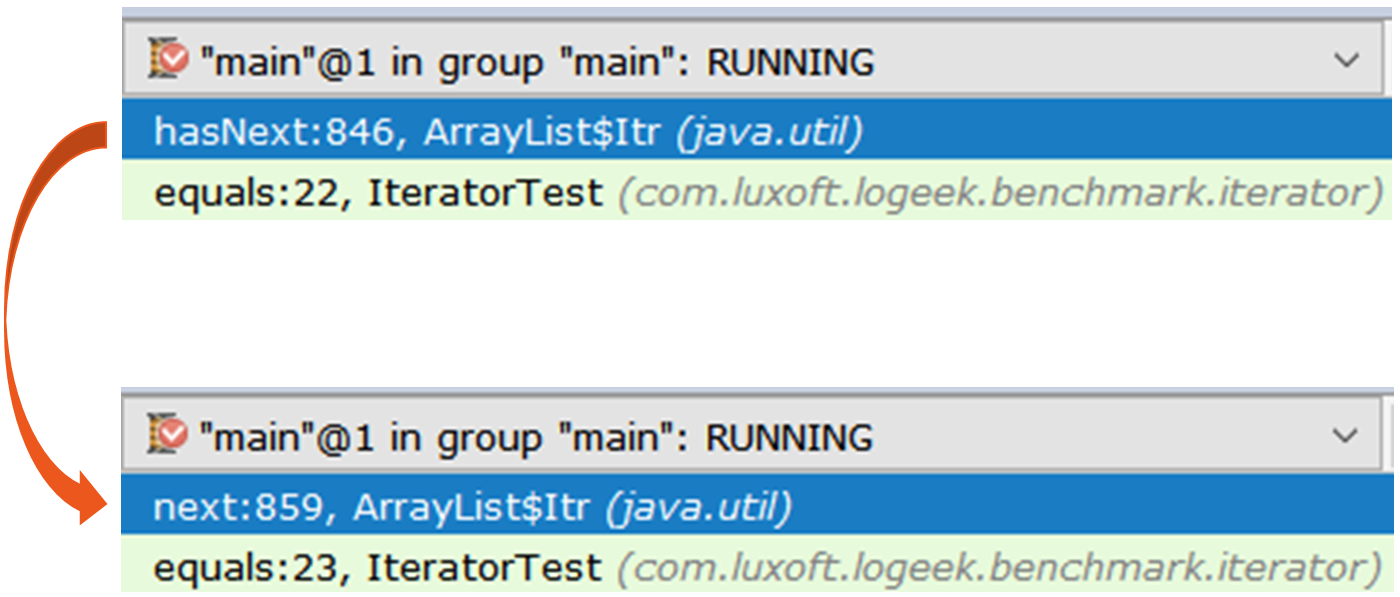
والثاني هو أكثر إثارة للاهتمام ، وهو Spliterators$Adapter ، والذي يعتمد على ArrayList$ArrayListSpliterator .
دعونا نلقي نظرة على تكرار المكرر من خلال المحلل المتزامن :
15.64% juArrayList$ArrayListSpliterator.tryAdvance 10.67% jusSpinedBuffer.clear 9.86% juSpliterators$1Adapter.hasNext 8.81% jusStreamSpliterators$AbstractWrappingSpliterator.fillBuffer 6.01% oojiBlackhole.consume 5.71% jusReferencePipeline$3$1.accept 5.57% jusSpinedBuffer.accept 5.06% cllbir.IteratorFromStreamBenchmark.iteratorFromStream 4.80% jlLong.valueOf 4.53% cllbiIteratorFromStreamBenchmark$$Lambda$8.885721577.apply
يمكن ملاحظة أنه يتم قضاء معظم الوقت في المرور من خلال المكرر ، على الرغم من أننا لا نحتاج إليه بشكل عام ، لأنه يمكن إجراء البحث على هذا النحو:
items .stream() .map(Long::valueOf) .forEach(bh::consume);
Stream::forEach الواضح أن Stream::forEach الفائز ، ولكن هذا غريب: لا يزال يعتمد على ArrayListSpliterator ، ولكن استخدامه تحسن بشكل ملحوظ.
دعنا نرى ملف التعريف: 29.04% oojiBlackhole.consume 22.92% juArrayList$ArrayListSpliterator.forEachRemaining 14.47% jusReferencePipeline$3$1.accept 8.79% jlLong.valueOf 5.37% cllbiIteratorFromStreamBenchmark$$Lambda$9.617691115.accept 4.84% cllbiIteratorFromStreamBenchmark$$Lambda$8.1964917002.apply 4.43% jusForEachOps$ForEachOp$OfRef.accept 4.17% jusSink$ChainedReference.end 1.27% jlInteger.longValue 0.53% jusReferencePipeline.map
في هذا الملف الشخصي ، يتم قضاء معظم الوقت في "ابتلاع" القيم داخل Blackhole . مقارنة بالمكرر ، يتم إنفاق جزء أكبر بكثير من الوقت مباشرة على تنفيذ كود Java. يمكن افتراض أن السبب هو انخفاض الوزن المحدد لمجموعة القمامة ، مقارنةً بالقوة الغاشمة المكررة. تحقق:
forEach:·gc.alloc.rate.norm 100 avgt 30 216,001 ± 0,002 B/op iteratorFromStream:·gc.alloc.rate.norm 100 avgt 30 416,004 ± 0,006 B/op
بالفعل ، يوفر Stream::forEach نصف استهلاك الذاكرة.
لماذا هو أسرع؟تبدو سلسلة المكالمات من البداية إلى الثقب الأسود كما يلي:
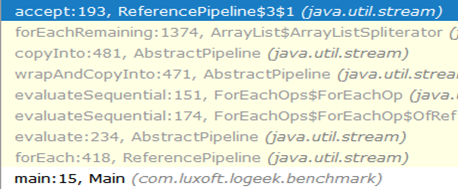
كما ترى ، اختفى استدعاء ArrayListSpliterator::tryAdvance من السلسلة ، وظهر ArrayListSpliterator::forEachRemaining :
ArrayListSpliterator::forEachRemaining تحقيق ArrayListSpliterator::forEachRemaining عالي السرعة باستخدام تمرير عبر الصفيف بأكمله في استدعاء أسلوب 1. عند استخدام مكرر ، يقتصر المقطع على عنصر واحد ، لذلك فنحن نرتاح دائمًا ضد ArrayListSpliterator::tryAdvance .
ArrayListSpliterator::forEachRemaining لديه حق الوصول إلى الصفيف بأكمله ArrayListSpliterator::forEachRemaining فوقه مع دورة حساب بدون مكالمات إضافية.
إشعار هاميرجى ملاحظة أن الاستبدال الميكانيكي
Iterator<Long> iterator = items .stream() .map(Long::valueOf) .collect(toList()) .iterator(); while (iterator.hasNext()) { bh.consume(iterator.next()); }
على
items .stream() .map(Long::valueOf) .forEach(bh::consume);
لا يكون دائمًا مكافئًا ، لأنه في الحالة الأولى نستخدم نسخة من البيانات لتمريرها دون التأثير على الدفق نفسه ، وفي الحالة الثانية ، يتم أخذ البيانات مباشرة من الدفق.
المعيار
الخلاصة: عند التعامل مع تمثيلات معقدة للبيانات ، كن مستعدًا لحقيقة أنه حتى قواعد "الحديد" (أضرار العمل الإضافية) تتوقف عن العمل. يوضح المثال أعلاه أن القائمة المتوسطة الزائدة على ما يبدو تعطي ميزة التنفيذ السريع للعد.
خدعتان
StackTraceElement[] trace = th.getStackTrace(); StackTraceElement[] newTrace = Arrays .asList(trace) .subList(0, depth) .toArray(new StackTraceElement[newDepth]);
أول شيء يلفت Collection::toArray هو "تحسن" فاسد ، أي تمرير مجموعة من الطول غير الصفري إلى أسلوب Collection::toArray . يشرح بالتفصيل لماذا هذا ضار.
المشكلة الثانية ليست واضحة للغاية ، ومن أجل فهمها يمكننا رسم موازٍ بين عمل المراجع والمؤرخ.
هذا ما يكتبه روبن كولينجوود عن هذا: . :
1)
2)
3)
, :
StackTraceElement[] trace = th.getStackTrace(); StackTraceElement[] newTrace = Arrays.copyOf(trace, depth);
List<T> list = getList(); Set<T> set = getSet(); return list.stream().allMatch(set::contains);
, , :
List<T> list = getList(); Set<T> set = getSet(); return set.containsAll(list);
:
interface FileNameLoader { String[] loadFileNames(); }
:
private FileNameLoader loader; void load() { for (String str : asList(loader.loadFileNames())) {
, forEach , :
private FileNameLoader loader; void load() { for (String str : loader.loadFileNames()) {
: :
, , , . , : "" ( ), "" ( ), .
→
→