 تحدثنا مؤخرًا عن سبب توصلنا إلى أداة تقسيم RFM الخاصة بنا ، مما يساعد على إجراء تحليل RFM في 20 ثانية ، وأظهرنا كيفية استخدام نتائجها في التسويق.
تحدثنا مؤخرًا عن سبب توصلنا إلى أداة تقسيم RFM الخاصة بنا ، مما يساعد على إجراء تحليل RFM في 20 ثانية ، وأظهرنا كيفية استخدام نتائجها في التسويق.
الآن نقول كيف يتم ترتيبه.
المهمة: كتابة خوارزمية تحليل RFM جديدة
لم نكن راضين عن الأساليب المتاحة لتحليل RFM. لذلك ، قررنا إنشاء أداة تقسيم خاصة بنا ، والتي:
- يعمل بشكل تلقائي بالكامل.
- يبني من 3 إلى 15 قطعة.
- يتكيف مع أي مجال من مجالات نشاط العميل (لا يهم ما هو: متجر لبيع الزهور أو أدوات كهربائية).
- يحدد عدد الأجزاء وموقعها بناءً على البيانات المتاحة ، وليس المعلمات المحددة مسبقًا التي لا يمكن أن تكون عالمية.
- وهي تحدد الشرائح بحيث يكون لها دائمًا عملاء (على عكس بعض الأساليب عندما تكون بعض الشرائح فارغة).
كيف تحل المشكلة
عندما أدركنا المهمة ، أدركنا أنها تجاوزت قوة الإنسان ، وطلبنا المساعدة من الذكاء الاصطناعي. لتعليم السيارة لتقسيم المستهلكين إلى شرائح ، قررنا استخدام طرق التجميع .
تُستخدم طرق التجميع للبحث عن بنية في البيانات واختيار مجموعات من الكائنات المتشابهة فيها - ما تحتاجه فقط لتحليل RFM.
يشير التكتل إلى طرق التعلم الآلي للفصل " التعلم بدون معلم ". يُدعى الفصل على هذا النحو لأن هناك بيانات ، ولكن لا أحد يعرف ماذا يفعل بها ، وبالتالي لا يمكنه تعليم الآلة.
لم نتمكن من العثور على الشركات التي تستخدم هذا النهج في السوق. على الرغم من أنهم وجدوا مقالًا واحدًا يجري فيه المؤلف بحثًا علميًا حول هذا الموضوع. ولكن ، كما فهمنا من تجربتنا الخاصة ، من العلوم إلى الأعمال ليست خطوة واحدة على الإطلاق.
المرحلة 1. معالجة البيانات
يجب تحضير البيانات للتجميع.
أولاً ، نتحقق منها لمعرفة القيم غير الصحيحة: القيم السلبية ، إلخ.
ثم نزيل الانبعاثات - المستهلكين بخصائص غير عادية. هناك القليل منها ، لكنها يمكن أن تؤثر بشكل كبير على النتيجة ، وليس للأفضل. لفصلها ، نستخدم طريقة التعلم الآلي الخاصة - عامل Outlier المحلي .

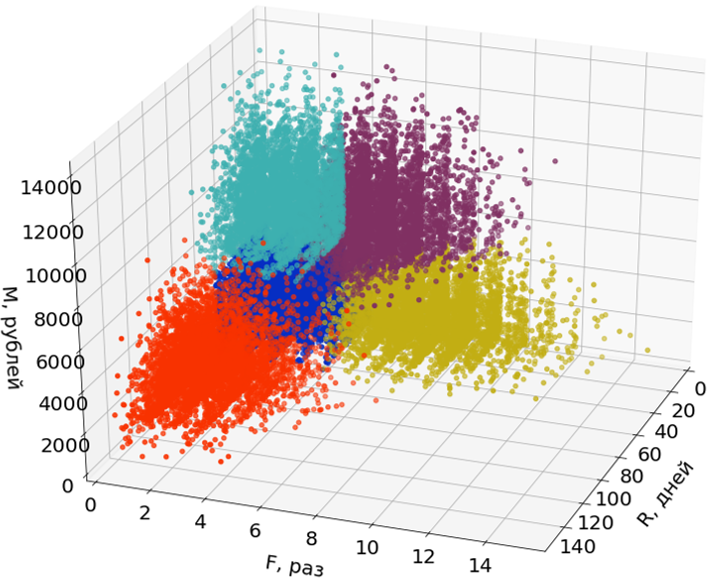
هنا في الصور ، أستخدم اثنين فقط من الأبعاد الثلاثة (R و M) من ثلاثة لتسهيل الإدراك.
لا تشارك الانبعاثات في بناء الأجزاء ، ولكن يتم تخصيصها لها بعد تشكيل الأجزاء.
المرحلة 2. تجميع المستهلك
سأوضح المصطلحات: من خلال المجموعات ، أعني مجموعات من الكائنات التي يتم الحصول عليها نتيجة استخدام خوارزميات التجميع ، والمقاطع كنتيجة نهائية ، أي نتيجة تحليل RFM.
هناك العشرات من خوارزميات التجميع. يمكن العثور على أمثلة على بعضها في وثائق حزمة التعلم والتعلم .
لقد جربنا ثمانية خوارزميات بتعديلات مختلفة. معظمهم لم يكن لديهم ذاكرة كافية. أو يميل وقت عملهم إلى ما لا نهاية. أعطت جميع الخوارزميات تقريبًا التي تمكنت من الناحية الفنية للتعامل مع المهمة نتائج رهيبة: على سبيل المثال ، اعتبرت DBSCAN الشهيرة 55 ٪ من الكائنات كضوضاء ، وقسمت الباقي إلى 4302 عنقود.
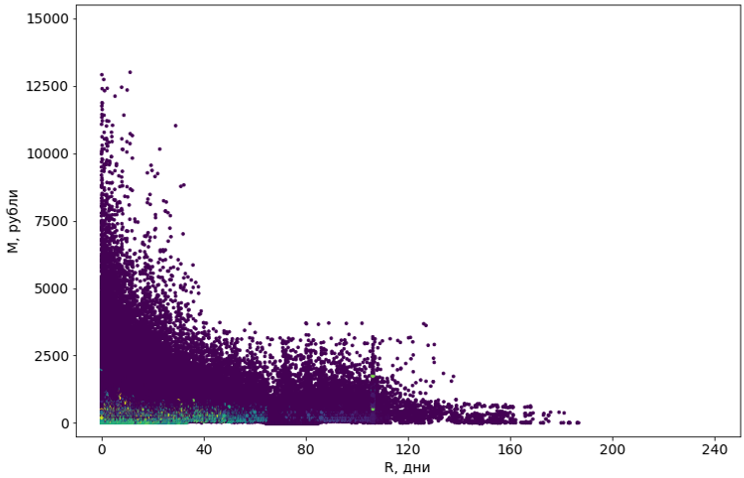
تعرف الأجسام البنفسجية بأنها "ضوضاء"
نتيجة لذلك ، اخترنا خوارزمية K-Means (K-يعني) لأنها لا تبحث عن مجموعات من النقاط ، ولكنها ببساطة تجمع النقاط حول المراكز. كما اتضح ، كان هذا هو القرار الصحيح.
لكن أولاً ، حللنا بعض المشكلات:
عدم الاستقرار. هذه مشكلة معروفة في معظم خوارزميات التجميع ، بما في ذلك K-Means. يكمن عدم الاستقرار في حقيقة أنه مع عمليات الإطلاق المتكررة ، يمكن أن تكون النتائج مختلفة ، حيث يتم استخدام عنصر العشوائية.
لذلك ، فإننا نجمع عدة مرات ، ثم نجمع مرة أخرى ، ولكن بالفعل مراكز التجمعات. كمراكز نهائية للمجموعات ، نأخذ مراكز المجموعات الناتجة (أي المجموعات التي تتكون من مراكز المجموعات الأولى).
عدد العناقيد. يمكن أن تكون البيانات مختلفة ، ويجب أن يكون عدد المجموعات مختلفًا أيضًا.
للعثور على العدد الأمثل للمجموعات لكل قاعدة عملاء ، نقوم بتنفيذ المجموعات باستخدام عدد مختلف من المجموعات ، ثم نختار أفضل نتيجة .
السرعة. إن خوارزمية K-يعني ليست سريعة جدًا ، ولكنها مقبولة (بضع دقائق لقاعدة متوسطة تضم عدة مئات الآلاف من المستهلكين). ومع ذلك ، نقوم بتشغيله عدة مرات: أولاً ، لزيادة الاستقرار ، وثانيًا ، لتحديد عدد المجموعات. وزمن التشغيل يزداد كثيرا.
للتسريع ، نستخدم تعديلًا في Mini Batch K-Means . يعيد حساب مراكز الكتلة في كل تكرار ليس لجميع الكائنات ، ولكن فقط لعينة فرعية صغيرة. تنخفض الجودة إلى حد ما ، ولكن يتم تقليل الوقت بشكل ملحوظ.
بمجرد أن حللنا هذه المشاكل ، بدأ التكتل يتقدم بنجاح.
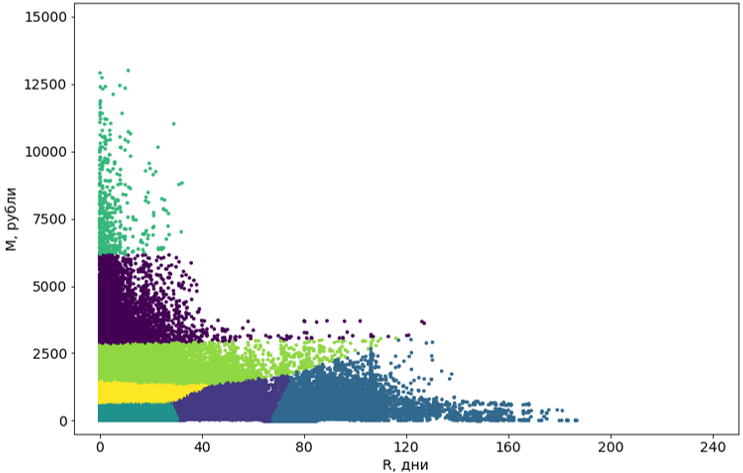
المرحلة 3. المعالجة اللاحقة للمجموعات
يجب إحضار المجموعات التي تم الحصول عليها باستخدام الخوارزمية إلى شكل مناسب للإدراك.
أولاً ، نحول هذه العناقيد من المنحنيات إلى مستطيلة. في الواقع ، هذا يجعلهم شرائح. إن مستطيلة الأجزاء هي أحد متطلبات نظامنا ، بالإضافة إلى ذلك ، تضيف الفهم إلى الأجزاء نفسها. للتحويل ، نستخدم خوارزمية أخرى لتعلم الآلة - شجرة القرار .
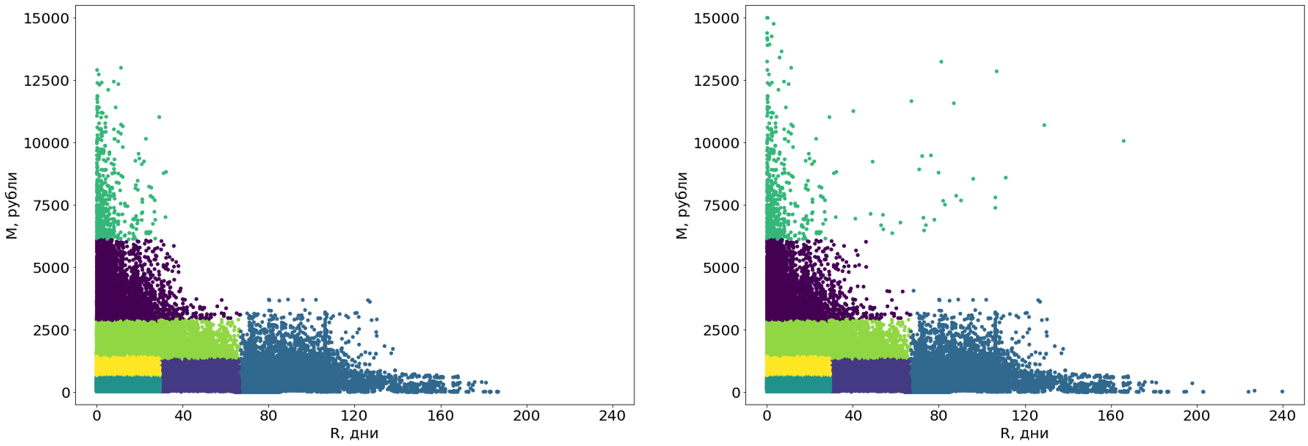
يتم بناء شجرة القرار على بيانات خالية من البيانات الخارجية ، ثم يتم تخصيص القيم المتطرفة إلى الأجزاء النهائية
ثانيًا ، فعلنا شيئًا رائعًا آخر - وصف الأجزاء. تصف خوارزمية خاصة ، باستخدام قاموس ، كل جزء بالروسية الحية ، بحيث لا يشعر الناس بالشوق عند النظر إلى أرقام بلا روح.

نتائج الاختبار
المنتج جاهز. ولكن قبل البدء في بيعه ، يجب اختباره. أي ، تحقق مما إذا كان تحليل RFM يتم تنفيذه كما أردنا.
نحن نعلم أن أفضل طريقة لفهم ما إذا كنا قد فعلنا شيئًا ذي قيمة هو معرفة مدى فائدة التحليل لعملائنا. وسنفعل ذلك. لكن هذا وقت طويل ، وستكون النتائج لاحقًا ، ونريد أن نعرف مدى نجاحنا في التعامل مع المهمة الآن.
لذلك ، كمقياس أبسط وأسرع ، استخدمنا طريقة "مجموعة التحكم التاريخية".
للقيام بذلك ، أخذنا العديد من قواعد البيانات وقمنا بتقسيمها باستخدام تحليل RFM في نقاط مختلفة في الماضي: قاعدة بيانات واحدة للولاية قبل ستة أشهر ، والأخرى قبل عام ، إلخ.
بناءً على كل تقسيم لكل قاعدة ، قمنا ببناء توقعاتنا لإجراءات العملاء من اللحظة المحددة إلى الوقت الحاضر. ثم قارنوا هذه التوقعات بالسلوك الفعلي للعملاء.

مثال تجريبي على مجموعة تحكم تاريخية بفترة تحكم مدتها ستة أشهر
في الصورة:
- تشير الأعمدة R و F و M بشكل تقليدي إلى حدود الأجزاء على طول كل محور. هذا هو نتيجة التقسيم الأساسي بالشكل الذي كان عليه قبل نصف عام.
- يعرض العمود "الحجم" حجم المقطع قبل ستة أشهر بالنسبة للحجم الإجمالي لقاعدة البيانات.
- يمثل العمودان "احتمال الشراء" و "المبلغ" بيانات عن سلوك المستهلك الحقيقي خلال الأشهر الستة القادمة.
- يتم تعريف احتمالية الشراء على أنها نسبة عدد المستهلكين من القطاع الذين أجروا عملية شراء إلى إجمالي عدد المستهلكين في القطاع.
- المبلغ - إجمالي المبلغ الذي ينفقه المستهلكون من القطاع بالنسبة للمبلغ الذي ينفقه المستهلكون من جميع القطاعات.
النتائج متناسقة. على سبيل المثال ، العملاء من القطاعات التي توقعنا تكرارًا لعمليات شراء عالية قد تم شراؤها كثيرًا.
على الرغم من أننا لا نستطيع ضمان التشغيل الصحيح للخوارزمية بنسبة 100 بالمائة بناءً على هذا الاختبار ، فقد قررنا أنها كانت ناجحة.
ماذا نفهم
التعلم الآلي قادر حقًا على مساعدة الأعمال التجارية في حل المشكلات غير القابلة للحل أو التي تم حلها بشكل سيئ للغاية.
لكن التحدي الحقيقي ليس المنافسة Kaggle. هنا ، بالإضافة إلى تحقيق جودة أفضل في مقياس معين ، تحتاج إلى التفكير في مدى عمل الخوارزمية ، وما إذا كانت ستكون مناسبة للأشخاص ، وبشكل عام ، ما إذا كان من الضروري حل المشكلة باستخدام ML أو يمكنك الخروج بطريقة أبسط.
وأخيرًا ، يؤدي عدم وجود مقياس رسمي للجودة إلى تعقيد المهمة عدة مرات ، لأنه من الصعب تقييم النتيجة بشكل صحيح.