في عالم التعلم الآلي ، أحد أشهر أنواع النماذج هو الشجرة الحاسمة والمجموعات المستندة إليها. مزايا الأشجار هي: سهولة التفسير ، ولا توجد قيود على نوع الاعتماد الأولي ، والمتطلبات اللينة على حجم العينة. كما أن للأشجار عيبًا كبيرًا - الميل إلى إعادة التدريب. لذلك ، دائمًا ما يتم دمج الأشجار في مجموعات: غابة عشوائية ، تعزيز التدرج ، إلخ. المهام النظرية والعملية المعقدة هي تأليف الأشجار ودمجها في مجموعات.
في نفس المقالة ، سيتم النظر في إجراء توليد التوقعات من نموذج مجموعة شجرة مدربة بالفعل ، وميزات التنفيذ في
XGBoost تعزيز التدرج الشائعة
XGBoost و
LightGBM . وكذلك سيتعرف القارئ على مكتبة
leaves لـ Go ، والتي تتيح لك عمل تنبؤات لمجموعات الشجرة دون استخدام C API للمكتبات الأصلية.
من أين تنمو الأشجار؟
فكر أولاً في الأحكام العامة. عادة ما يعملون مع الأشجار ، حيث:
- يحدث التقسيم في العقدة وفقًا لميزة واحدة
- شجرة ثنائية - كل عقدة لها سليل يسار ويمين
- في حالة السمة المادية ، تتكون قاعدة القرار من مقارنة قيمة السمة بقيمة العتبة
أخذت هذا الرسم التوضيحي من
وثائق XGBoost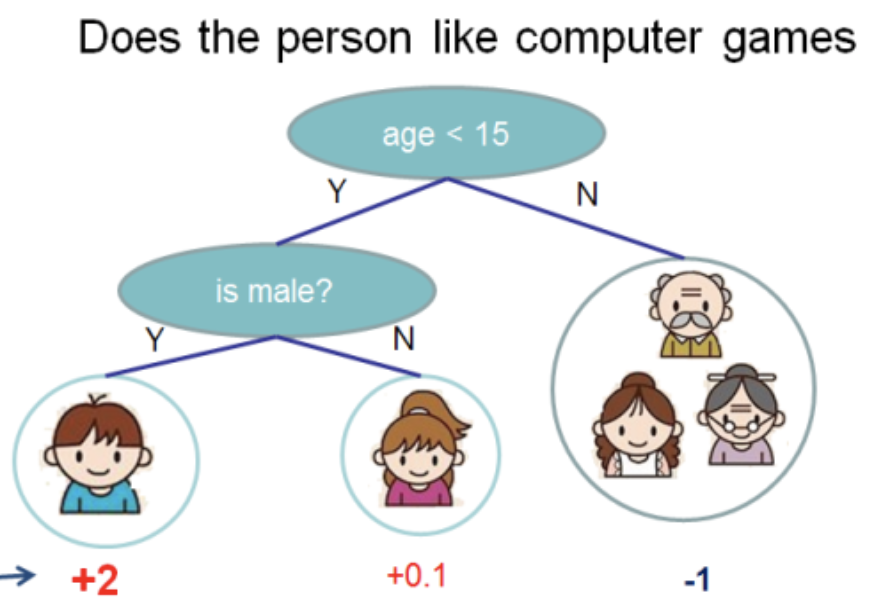
في هذه الشجرة لدينا عقدتان وقواعد قرار و 3 أوراق. تحت الدوائر ، يشار إلى القيم - نتيجة تطبيق الشجرة على شيء ما. عادة ، يتم تطبيق وظيفة التحويل على نتيجة حساب شجرة أو مجموعة شجرة. على سبيل المثال ،
السيني لمشكلة تصنيف ثنائية.
للحصول على تنبؤات من مجموعة الأشجار التي تم الحصول عليها من خلال تعزيز التدرج ، تحتاج إلى إضافة نتائج التنبؤات لجميع الأشجار:
double pred = 0.0; for (auto& tree: trees) pred += tree->Predict(feature_values);
فيما يلي ، سيكون هناك
C++ ، كما بهذه اللغة يتم كتابة
XGBoost و
LightGBM . سأحذف التفاصيل غير ذات الصلة وأحاول تقديم الرمز الأكثر إيجازًا.
بعد ذلك ، ضع في اعتبارك ما هو مخفي في
Predict وكيفية هيكلة بنية بيانات الشجرة.
أشجار XGBoost
يحتوي
XGBoost على عدة فئات (بمعنى OOP) من الأشجار. سوف نتحدث عن
RegTree (انظر
include/xgboost/tree_model.h ) ، وهو ، وفقًا للوثائق ، هو العنصر الرئيسي. إذا تركت التفاصيل المهمة فقط للتنبؤات ، فسيبدو أعضاء الفصل أبسط ما يمكن:
class RegTree {
يتم تطبيق قاعدة
GetNext في دالة
GetNext . تم تعديل الرمز قليلاً ، دون التأثير على نتيجة الحسابات:
يتبع شيئين من هنا:
RegTree يعمل فقط مع السمات الحقيقية (اكتب float )- يتم دعم القيم المميزة التي تم تخطيها
المحور هو فئة
Node . يحتوي على البنية المحلية للشجرة ، وقاعدة القرار وقيمة الورقة:
class Node { public:
يمكن تمييز الميزات التالية:
- يتم تمثيل الأوراق
cleft_ = -1 التي يكون cleft_ = -1 info_ تمثيل حقل info_ union ، أي هناك نوعان من البيانات (في نفس الحالة) يشتركان في جزء واحد من الذاكرة اعتمادًا على نوع العقدة- البت الأكثر أهمية في
sindex_ هو المسؤول عن المكان الذي يتم تخطي الكائن الخاص به
لكي أتمكن من تتبع المسار من استدعاء أسلوب
RegTree::Predict إلى تلقي الإجابة ، سأعطي الدالتين المفقودتين:
float RegTree::Predict(const RegTree::FVec& feat, unsigned root_id) const { int pid = this->GetLeafIndex(feat, root_id); return nodes_[pid].leaf_value; } int RegTree::GetLeafIndex(const RegTree::FVec& feat, unsigned root_id) const { auto pid = static_cast<int>(root_id); while (!nodes_[pid].IsLeaf()) { unsigned split_index = nodes_[pid].SplitIndex(); pid = this->GetNext(pid, feat.Fvalue(split_index), feat.IsMissing(split_index)); } return pid; }
في دالة
GetLeafIndex أسفل عقد الشجرة في حلقة حتى نصل إلى الورقة.
أشجار LightGBM
ليس لدى LightGBM بنية بيانات للعقدة. بدلاً من ذلك ، تحتوي بنية بيانات شجرة
Tree (
include/LightGBM/tree.h ملف
include/LightGBM/tree.h ) على صفائف من القيم ، حيث يتم استخدام رقم العقدة كمؤشر. يتم تخزين القيم في الأوراق أيضًا في صفائف منفصلة.
class Tree {
يدعم
LightGBM الميزات الفئوية. يتم توفير الدعم باستخدام حقل بت ، والذي يتم تخزينه في
cat_threshold_ لجميع العقد. في
cat_boundaries_ تخزين العقدة التي
cat_boundaries_ جزء من حقل البت. يتم تحويل حقل
threshold_ للحالة الفئوية إلى
int ويتوافق مع الفهرس في
cat_boundaries_ للبحث عن بداية حقل البت.
خذ بعين الاعتبار القاعدة الحاسمة للسمة الفئوية:
int CategoricalDecision(double fval, int node) const { uint8_t missing_type = GetMissingType(decision_type_[node]); int int_fval = static_cast<int>(fval); if (int_fval < 0) { return right_child_[node];; } else if (std::isnan(fval)) {
يمكن ملاحظة أنه ، اعتمادًا على
missing_type ، تقلل قيمة
NaN الحل تلقائيًا على طول فرع الشجرة الأيمن. خلاف ذلك ، يتم استبدال
NaN بـ 0. البحث عن قيمة في حقل بت بسيط للغاية:
bool FindInBitset(const uint32_t* bits, int n, int pos) { int i1 = pos / 32; if (i1 >= n) { return false; } int i2 = pos % 32; return (bits[i1] >> i2) & 1; }
على سبيل المثال ، بالنسبة للسمة
int_fval=42 التحقق مما إذا كان البت 41 (الترقيم من 0)
int_fval=42 في الصفيف.
هذا النهج له عيب واحد مهم: إذا كانت السمة الفئوية يمكن أن تأخذ قيمًا كبيرة ، على سبيل المثال 100500 ، فعند كل قاعدة قرار لهذه السمة ، سيتم إنشاء حقل بت يصل إلى 12564 بايت!
لذلك ، من المستحسن إعادة ترقيم قيم السمات الفئوية بحيث تنتقل باستمرار من 0 إلى القيمة القصوى .
من جهتي ، قمت بإجراء تغييرات توضيحية على
LightGBM وقبلتها .
لا يختلف التعامل مع السمات الجسدية كثيرًا عن
XGBoost ، وسوف أتخطى ذلك للإيجاز.
يترك - مكتبة للتنبؤات في Go
XGBoost و
LightGBM مكتبات قوية جدًا لبناء نماذج
LightGBM التدرج على أشجار القرار. لاستخدامها في خدمة الواجهة الخلفية ، حيث تكون هناك حاجة إلى خوارزميات التعلم الآلي ، من الضروري حل المهام التالية:
- التدريب الدوري للنماذج حاليا
- تسليم النماذج في خدمة الواجهة الخلفية
- نماذج الاستطلاع على الإنترنت
لكتابة خدمة خلفية محملة ،
Go هي لغة شائعة.
XGBoost أو
LightGBM خلال واجهة برمجة التطبيقات C و cgo ليس الحل الأسهل -
LightGBM البرنامج معقد ، نظرًا للمعالجة اللامبالية ، يمكنك التقاط
SIGTERM ، ومشاكل عدد سلاسل النظام (OpenMP داخل المكتبات مقابل خيوط وقت التشغيل).
لذا قررت كتابة مكتبة عن
Go للتنبؤات باستخدام نماذج مدمجة في
XGBoost أو
LightGBM . يطلق عليه
leaves .

الملامح الرئيسية للمكتبة:
LightGBM
- نماذج القراءة بتنسيق قياسي (نص)
- دعم السمات المادية والفئوية
- دعم القيم المفقودة
- تحسين العمل مع المتغيرات الفئوية
- تحسين التنبؤ مع هياكل بيانات التنبؤ فقط
- لنماذج
XGBoost
- نماذج القراءة من تنسيق قياسي (ثنائي)
- دعم القيم المفقودة
- تحسين التنبؤ
فيما يلي برنامج
Go يقوم بتحميل نموذج من القرص ويعرض التنبؤ:
package main import ( "bufio" "fmt" "os" "github.com/dmitryikh/leaves" ) func main() {
مكتبة API هي الحد الأدنى. لاستخدام نموذج
XGBoost ما
XGBoost سوى استدعاء طريقة
leaves.XGEnsembleFromReader بدلاً من الطريقة المذكورة أعلاه. يمكن إجراء التنبؤات على دفعات عن طريق استدعاء
PredictDense أو
model.PredictCSR .
model.PredictCSR . يمكن العثور على المزيد من سيناريوهات الاستخدام في
اختبارات الإجازات .
على الرغم من حقيقة أن
Go يعمل بشكل أبطأ من
C++ (ويرجع ذلك أساسًا إلى زيادة وقت التشغيل وعمليات التحقق من وقت التشغيل) ، بفضل عدد من التحسينات ، كان من الممكن تحقيق معدل تنبؤ مماثل للاتصال بـ C API للمكتبات الأصلية.
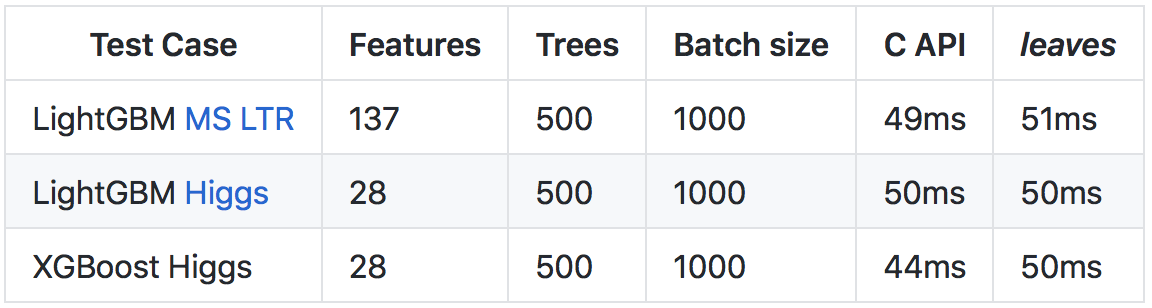
مزيد من التفاصيل حول نتائج وطرق المقارنات في
مستودع على جيثب .
انظر الجذر
آمل أن تفتح هذه المقالة الباب أمام تنفيذ الأشجار في
LightGBM و
LightGBM . كما ترون ، فإن التركيبات الأساسية بسيطة للغاية ، وأنا أشجع القراء على الاستفادة من المصدر المفتوح - لدراسة الرمز عندما تكون هناك أسئلة حول كيفية عمله.
بالنسبة لأولئك المهتمين بموضوع استخدام نماذج تعزيز التدرج في خدماتهم بلغة Go ، أوصي بأن تتعرف على مكتبة
الأوراق . باستخدام
leaves يمكنك بسهولة استخدام الحلول المتطورة الرائدة في التعلم الآلي في بيئة الإنتاج الخاصة بك ، تقريبًا دون فقدان السرعة مقارنةً بتطبيقات C ++ الأصلية.
حظا سعيدا!