 ترجمة المادة: قواعد التجربة من الإبهام
ترجمة المادة: قواعد التجربة من الإبهاميحاول أصحاب بوابات الويب ، من الأصغر إلى الأكبر ، مثل Amazon و Facebook و Google و LinkedIn و Microsoft و Yahoo ، تحسين مواقعهم من خلال تحسين المقاييس المختلفة ، من عدد مرات إعادة الاستخدام إلى وقتهم وإيراداتهم. لقد انجذبنا لآلاف التجارب على Amazon و Booking.com و LinkedIn و Microsoft ، ونريد مشاركة القواعد السبعة التي استخلصناها من هذه التجارب ونتائجها. نعتقد أن هذه القواعد قابلة للتطبيق على نطاق واسع عند تحسين الويب وأثناء التحليل خارج تجارب التحكم. على الرغم من وجود استثناءات.
لجعل هذه القواعد أكثر أهمية ، سنقدم أمثلة حقيقية من عملنا ، سيتم نشر معظمها لأول مرة. تم التعبير عن بعض القواعد في وقت سابق (على سبيل المثال ، "السرعة مهمة") ، لكننا استكملناها بافتراضات يمكن استخدامها في تصميم التجارب ، وشاركنا أمثلة إضافية حسنت فهمنا لأين تكون السرعة مهمة بشكل خاص وفي أي مناطق الويب صفحات ليست حرجة.
هذه المقالة لها غرضان.
أولاً : تعليم المجربين قواعد الذوق السليم التي تساعد على تحسين المواقع.
ثانيًا : تزويد مجتمع KDD بمواضيع جديدة لاستكشاف مدى انطباق هذه القواعد وتحسينها ووجود استثناءات.
مقدمة
يحاول مالكو بوابات الويب من الأصغر إلى أكبر العمالقة تحسين مواقعهم. تستخدم الشركات الرائدة اختبارات قياس الأداء (مثل اختبارات أ / ب) لتقييم التغييرات. يتم ذلك بواسطة Amazon [1] و Ebay و Etsy [2] و Facebook [3] و Google [4] و Groupon و Intuit [5] و LinkedIn [6] و Microsoft [7] و Netflix [8] و ShopDirect [9] و Yahoo و Zynga [10].
لقد اكتسبنا خبرة في تحسين مواقع الويب ، والعمل مع العديد من الشركات ، بما في ذلك Amazon و Booking.com و LinkedIn و Microsoft. على سبيل المثال ، يجري Bing و LinkedIn مئات التجارب المتوازية في أي وقت معين [6؛ 11]. نظرًا لتنوع وتعدد التجارب التي شاركنا فيها ، فقد تم تطوير قواعد عامة ، والتي سنناقشها هنا. يتم تأكيدها من خلال المشاريع الحقيقية ، ولكن هناك استثناءات لأي قاعدة (سنتحدث عنها أيضًا). على سبيل المثال ، تعد القاعدة 72 مثالًا جيدًا لقاعدة مفيدة مفيدة في المجال المالي. تدعي أنك بحاجة إلى مضاعفة النسبة المئوية للنمو السنوي في 72 لتحديد عدد السنوات التي ستضاعف فيها استثماراتك تقريبًا. في الحالات العادية ، تكون القاعدة مفيدة جدًا (عندما يتذبذب سعر الفائدة بين 4 و 12٪) ، ولكنها لا تعمل في المناطق الأخرى.
نظرًا لأن هذه القواعد تم صياغتها وفقًا لنتائج تجارب التحكم ، فهي قابلة للتطبيق بشكل جيد لتحسين الموقع والتحليل البسيط ، حتى إذا لم يتم إجراء تجارب التحكم على المواقع (على الرغم من أنه في هذه الحالة لن يكون من الممكن إجراء تقييم دقيق لتأثير التغييرات التي تم إجراؤها).
ما ستجده في هذه المقالة:
- قواعد مفيدة للتجربة مع مواقع الويب. إنهم ما زالوا يتطورون ، ونحتاج أيضًا إلى تقييم نطاق تطبيقهم ومعرفة ما إذا كانت هناك استثناءات جديدة لهذه القواعد. نوقشت أهمية استخدام تجارب التحكم في مقالة "التجارب المنظمة عبر الإنترنت على نطاق واسع" [11]
- تحسين القواعد السابقة. وقد تم بالفعل التعبير عن ملاحظات مثل "مسائل السرعة" من قبل مؤلفين آخرين [12 ، 13] ونحن [14]. لكننا قمنا ببعض الافتراضات عند تصميم التجربة ، وسنتحدث عن الدراسات التي تثبت أن السرعة في بعض مناطق الصفحة مهمة بشكل خاص ، وفي مناطق أخرى لا. لقد قمنا أيضًا بتحسين القاعدة القديمة "لآلاف المستخدمين" ، والتي تجيب على السؤال حول عدد الأشخاص المطلوبين لإجراء تجربة تحكم.
- يتم نشر أمثلة حقيقية لتجارب التحكم لأول مرة. تُستخدم تجارب التحكم في Amazon و Bing و LinkedIn كجزء من عملية التطوير [7؛ 11]. يمكن للعديد من الشركات التي لا تزال لا تستخدم تجارب التحكم أن تستفيد بشكل كبير من الأمثلة الإضافية للعمل مع التغييرات مع إدخال نماذج تطوير جديدة [7 ، 15]. ستستفيد الشركات التي تستخدم بالفعل تجارب التحكم من الأفكار الموصوفة.
التحكم في التجارب والبيانات وعملية استخلاص المعرفة من البيانات
سنناقش هنا التحكم في التجارب عبر الإنترنت التي يتم فيها تقسيم المستخدمين إلى مجموعات بشكل عشوائي (على سبيل المثال ، لإظهار خيارات موقع متنوعة). علاوة على ذلك ، يتم إجراء التقسيم على أساس مستمر ، أي أن كل مستخدم سيحصل على نفس التجربة طوال التجربة (سيظهر دائمًا نفس الإصدار من الموقع). يتم تسجيل تفاعل المستخدم مع الموقع (النقرات ومشاهدات الصفحة وما إلى ذلك) ، ويتم حساب المقاييس الرئيسية (نسبة النقر إلى الظهور ، وعدد الجلسات لكل مستخدم ، والعائد من المستخدم) على أساسه. يتم إجراء الاختبارات الإحصائية لتحليل المقاييس المحسوبة. وإذا كان الفرق بين مقاييس المجموعة الضابطة (التي شهدت النسخة القديمة من الموقع) والتجريبية (التي شهدت الإصدار الجديد) للمجموعة ذات دلالة إحصائية ، فيمكننا أيضًا القول باحتمالية عالية أن التغييرات التي تم إجراؤها ستؤثر على المقاييس التي تمت ملاحظتها في التجربة. التفاصيل موصوفة في "تجارب خاضعة للرقابة على شبكة الإنترنت: مسح ودليل عملي" [16].
شاركنا في العديد من التجارب التي كانت نتائجها غير صحيحة ، وقضينا الكثير من الوقت والجهد لفهم الأسباب وإيجاد طرق لإصلاحها. كثير من المزالق موصوفة في المادتين [17] و [18]. نريد تسليط الضوء على بعض الأسئلة حول البيانات المستخدمة في إجراء تجارب التحكم عبر الإنترنت ، وحول عملية الحصول على المعرفة من هذه البيانات:
- مصدر البيانات هو المواقع الحقيقية التي تحدثنا عنها أعلاه. لن تكون هناك معلومات مصطنعة. تعتمد جميع الأمثلة على تفاعل المستخدم الحقيقي ، ويتم حساب المقاييس بعد إزالة برامج التتبُّع [16].
- يتم أخذ مجموعات المستخدمين في الأمثلة بشكل عشوائي من التوزيع الموحد للجمهور المستهدف (أي المستخدمين الذين ، على سبيل المثال ، يجب عليهم النقر على الرابط لرؤية التغييرات قيد الدراسة) [16]. تعتمد طريقة تعريف المستخدم على الموقع: إذا لم يقم المستخدم بتسجيل الدخول ، يتم استخدام ملفات تعريف الارتباط ، وإذا قام بتسجيل الدخول ، فسيتم استخدام تسجيل دخوله.
- تتراوح أحجام مجموعات المستخدمين ، بعد مسح برامج التتبُّع ، من مئات الآلاف إلى الملايين (يشار إلى القيم الدقيقة في الأمثلة). في معظم التجارب ، يعد ذلك ضروريًا حتى يكون للاختلافات الطفيفة في المقاييس أهمية إحصائية عالية.
- كانت النتائج الملحوظة ذات دلالة إحصائية عند القيمة الاحتمالية <0.05 ، وعادة ما تكون أقل. تم استنساخ النتائج المذهلة (في القاعدة 1) مرة أخرى على الأقل ، بحيث تكون القيمة الاحتمالية التراكمية المستندة إلى اختبار الاحتمال التراكمي لـ Fisher أقل بكثير من اللازم.
- كل تجربة هي تجربتنا الشخصية ، تم التحقق منها من قبل واحد على الأقل من المؤلفين لوجود مطبات قياسية. تم إجراء كل تجربة لمدة أسبوع على الأقل. كانت مشاركات الجمهور التي عرضت خيارات الموقع مستقرة طوال فترة التجربة بأكملها (من أجل تجنب تأثير مفارقة سيمبسون) وتزامن النسب بين الجمهور الذي لاحظناه أثناء التجربة مع النسب التي حددناها عند بدء التجربة [17].
قواعد التجربة
تتعلق القواعد الثلاثة الأولى بتأثير التغييرات على المقاييس الرئيسية:
- يمكن أن يكون للتغييرات الصغيرة تأثير كبير ؛
- نادرا ما يكون للتغيير تأثير إيجابي كبير ؛
- من المرجح أن تكون محاولاتك لتكرار النجاحات الممتازة التي أعلن عنها الآخرون أقل نجاحًا.
القواعد الأربعة التالية مستقلة عن بعضها البعض ، ولكن كل منها مفيد جدًا.
القاعدة رقم 1: يمكن أن يكون للتغييرات الصغيرة تأثير كبير على المقاييس الرئيسية
يعرف أي شخص مر عبر حياة المواقع أن أي تغيير طفيف يمكن أن يكون له تأثير سلبي كبير على المقاييس الرئيسية. يمكن أن يؤدي خطأ جافا سكريبت صغير إلى جعل الدفع مستحيلًا ، ويمكن أن تتسبب الأخطاء الصغيرة التي تدمر المكدس في تعطل الخادم. لكننا سنركز على التغييرات الإيجابية في المقاييس الرئيسية. الخبر السار هو أن هناك العديد من الأمثلة التي أدى فيها تغيير بسيط إلى تحسن في المقاييس الرئيسية. كتب بريان أيزنبرغ أن إزالة حقل إدخال القسيمة في نموذج الشراء أدى إلى زيادة التحويل بنسبة 1000٪ على موقع Doctor Footcare على الويب [20]. كتب جاريد سبول أن إزالة شرط التسجيل وقت الشراء يجلب لمتاجر التجزئة الكبيرة 300 مليون دولار سنويًا [21].
ومع ذلك ، لم نر مثل هذه التغييرات الهامة في عملية التجارب الشخصية. لكننا رأينا تحسينات كبيرة من التغييرات الصغيرة مع عائد مرتفع بشكل مدهش على الاستثمار (نسبة عالية من الربح إلى تكلفة الجهد المستثمر).
نود أيضًا أن نلاحظ أننا نناقش تأثيرًا مستقرًا ، وليس "وميضًا على الشمس" أو ميزة ذات تأثير إخباري / فيروسي خاص. تم وصف مثال لشيء لا نبحث عنه في كتاب نعم! 50 طريقة مثبتة علميا لتكون مقنعة [22]. قام كولين زوت ، مؤلف برنامج تلفزيوني حطم رقمًا قياسيًا للمبيعات لمدة 20 عامًا على قناة Couch Store TV ، باستبدال ثلاث كلمات في شريط مؤشر المعلومات القياسي ، مما أدى إلى قفزة هائلة في عدد عمليات الشراء. بدلاً من عبارة "المشغلون ينتظرون ، يرجى الاتصال الآن" ، استنتج كولين "إذا كان المشغلون مشغولين ، يرجى الاتصال مرة أخرى." يشرح المؤلفون ذلك بالأدلة الاجتماعية التالية: يعتقد المشاهدون أنه إذا كان الخط مشغولًا ، فإن أشخاصًا مثلهم يشاهدون القناة الإخبارية يتصلون أيضًا.
إذا تم استخدام الحيل مثل تلك المذكورة أعلاه بانتظام ، فسيتم تسوية تأثيرها ، لأن المستخدمين يعتادون عليها. في تجارب التحكم في مثل هذه الحالات ، يختفي التأثير بسرعة. لذلك ، نوصي بإجراء تجربة لمدة أسبوعين على الأقل ومراقبة الديناميكيات. على الرغم من أن هذه الأشياء نادرة في الممارسة العملية [11؛ 18]. وقد ارتبطت الحالات التي لاحظنا فيها تأثيرًا إيجابيًا لتأثير مثل هذه التغييرات بأنظمة التوصية عندما يعطي التغيير في حد ذاته تأثيرًا قصير المدى أو عندما يتم استخدام الموارد النهائية للمعالجة.
على سبيل المثال ، عندما غيّر LinkedIn خوارزمية ميزة "الأشخاص الذين قد تعرفهم" ، لم ينتج عنه سوى زيادة لمرة واحدة في مقاييس النقرات. علاوة على ذلك ، حتى لو كانت الخوارزمية تعمل بشكل أفضل ، فإن كل مستخدم يعرف عددًا محدودًا من الأشخاص ، وبعد أن اتصل بمعارفه الرئيسيين ، سينخفض تأثير أي خوارزمية جديدة.
مثال: فتح الروابط في علامة تبويب جديدة. سلسلة من ثلاث تجارب
في أغسطس 2008 ، أجرت MSN UK تجربة لأكثر من 900000 مستخدم ، حيث تم فتح الرابط إلى HotMail في علامة تبويب جديدة (أو نافذة جديدة على المتصفحات القديمة). أبلغنا سابقًا [7] أن هذا التغيير البسيط (سطر واحد من التعليمات البرمجية) أدى إلى زيادة في مشاركة مستخدمي MSN. ازداد معدل التفاعل ، الذي تم قياسه بعدد النقرات لكل مستخدم في الصفحة الرئيسية ، بنسبة 8.9٪ بين هؤلاء المستخدمين الذين نقروا على HotMail.
في يونيو 2010 ، قمنا بإعادة إنتاج التجربة على جمهور من 2.7 مليون مستخدم MSN في الولايات المتحدة ، وكانت النتائج متشابهة. في الواقع ، هذا أيضًا مثال لميزة مع تأثير الحداثة. في اليوم الأول من طرحه لجميع المستخدمين ، كانت 20٪ من المراجعات سلبية. في الأسبوع الثاني ، انخفضت حصة المستائين إلى 4٪ ، وخلال الأسبوعين الثالث والرابع - إلى 2٪. كان التحسن في المقاييس الرئيسية مستقرًا طوال هذا الوقت.
في أبريل 2011 ، أجرت MSN في الولايات المتحدة تجربة كبيرة جدًا مع أكثر من 12 مليون مستخدم تم فتح صفحة تحتوي على نتائج بحث في علامة تبويب جديدة. نما معدل التفاعل ، الذي تم قياسه بالنقرات على المستخدم ، بنسبة هائلة بلغت 5٪. كانت هذه واحدة من أفضل الميزات المتعلقة بمشاركة المستخدم التي طبقتها MSN على الإطلاق ، وكان تغييرًا بسيطًا في التعليمات البرمجية.
تقوم جميع محركات البحث الرئيسية بتجربة فتح الروابط في علامات تبويب / نوافذ جديدة ، ولكن نتائج "صفحة نتائج البحث" ليست مثيرة للإعجاب.
مثال: لون الخط
في عام 2013 ، أجرى Bing سلسلة من التجارب مع ألوان الخطوط. يظهر خيار الفوز في الشكل 1 على اليمين. إليك كيفية تغيير الألوان الثلاثة:
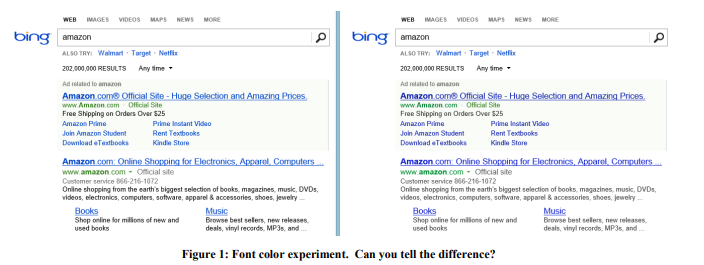
تكلفة مثل هذا التغيير؟ رخيص: فقط استبدل عدة ألوان في ملف CSS. وأظهرت نتيجة التجربة أن المستخدمين يحققون أهدافهم (التعريف الصارم للنجاح هو سر تجاري) بشكل أسرع ، وزاد تحقيق الدخل من هذه المراجعة بأكثر من 10 ملايين دولار سنويًا. كنا متشككين في مثل هذه النتائج المدهشة ، لذلك قمنا بإعادة إنتاج هذه التجربة على عينة أكبر بكثير من 32 مليون مستخدم ، وتم تأكيد النتائج.

مثال: العرض المناسب في الوقت المناسب
في عام 2004 ، احتوت صفحة البداية في أمازون على خانتين ، تم اختبار محتوياتهما تلقائيًا ، بحيث يتم عرض المحتوى الذي يعمل على تحسين المقياس الهدف بشكل أكثر تكرارًا. وصل عرض الحصول على بطاقة ائتمان من أمازون إلى الصدارة ، والذي كان مفاجئًا منذ ذلك الحين كان لهذا العرض عدد قليل جدًا من النقرات لكل ظهور. لكن الحقيقة هي أن هذا التطبيق كان مربحًا جدًا ، لذلك ، على الرغم من نسبة النقر إلى الظهور الصغيرة ، كانت القيمة المتوقعة عالية جدًا. ولكن فقط ما إذا تم اختيار مكان لمثل هذا الإعلان بنجاح؟ لا! ونتيجة لذلك ، تم نقل الاقتراح ، مع مثال بسيط على الفائدة ، إلى سلة التسوق التي يراها المستخدم بعد إضافة المنتج. وبالتالي ، تم التأكيد على ميزة هذا الاقتراح على مثال كل منتج. إذا أضاف المستخدم سلعًا إلى السلة ، فهذه نية واضحة لإجراء عملية شراء وقد حان الوقت لمثل هذا العرض.

أظهرت تجربة التحكم أن مثل هذا التغيير البسيط يجلب عشرات الملايين من الدولارات في السنة.
مثال: مضاد الفيروسات
الإعلان هو عمل مربح ، وغالبًا ما يحتوي البرنامج "المجاني" الذي يثبته المستخدمون على جزء ضار يسد الصفحات التي تحتوي على إعلانات. على سبيل المثال ، يوضح الشكل 2 كيف تبدو صفحة نتائج Bing لمستخدم لديه برنامج ضار أضاف الكثير من الإعلانات إلى الصفحة (مظللة باللون الأحمر).
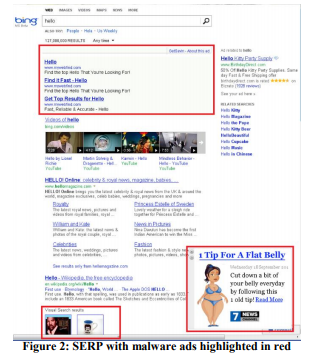
عادة لا يلاحظ المستخدمون أن الكثير من الإعلانات لا تظهر من خلال الموقع الذي يزورونه ، ولكن من خلال كود ضار قاموا بتثبيته عن طريق الخطأ. كانت التجربة صعبة التنفيذ ، ولكنها بسيطة نسبيًا من الناحية الإيديولوجية: تغيير الإجراءات الأساسية التي تعدل DOM ، وتحديد التطبيقات القادرة على تعديل الصفحة. تم إجراء التجربة على أكثر من 3.8 مليون مستخدم لديهم أجهزة كمبيوتر خاصة بهم كود خارجي قام بتحرير DOM. في مجموعة الاختبار ، تم حظر هذه التغييرات. أظهرت النتائج تحسنًا في جميع المقاييس الرئيسية ، بما في ذلك مقياس توجيهي مثل عدد الجلسات لكل مستخدم ، أي يأتي الناس إلى الموقع في كثير من الأحيان. بالإضافة إلى ذلك ، أكمل المستخدمون مهامهم بنجاح أكبر وأسرع ، وزادت الإيرادات السنوية بعدة ملايين من الدولارات. انخفضت سرعة تحميل الصفحة ، التي سنناقشها في القاعدة رقم 4 ، بمئات المللي ثانية للصفحات المتأثرة بالتجربة.
استغرق تغييران صغيران آخران على Bing ، وهما سريان تمامًا ، أيامًا للتطوير ، وأدى كل منهما إلى زيادة في عائدات الإعلانات بنحو 100 مليون دولار سنويًا. في تقرير ربع سنوي من Microsoft في أكتوبر 2013 ، قالت: "نمت عائدات الإعلانات من البحث بنسبة 47٪ بسبب زيادة الأرباح من كل بحث وكل صفحة". قدم هذان التغييران مساهمة كبيرة في نمو الأرباح المذكور.
بعد هذه الأمثلة ، قد تعتقد أن المنظمات يجب أن تركز على الكثير من التغييرات الصغيرة. ولكن أدناه سترى أن الأمر ليس كذلك على الإطلاق. نعم ، تحدث الاختراقات على أساس تغييرات صغيرة ، لكنها نادرة جدًا وغير متوقعة: في Bing ، ربما تحقق واحدة من كل 500 تجربة مثل هذه العائد على الاستثمار المرتفع والنتائج الإيجابية القابلة للتكرار. نحن لا ندعي أن هذه النتائج ستكون قابلة للتكرار في مجالات أخرى ، نريد فقط نقل الفكرة: إجراء تجارب بسيطة يستحق الجهد وقد يؤدي في النهاية إلى اختراق.
الخطر الناشئ عن التركيز على التغييرات الصغيرة هو تزايدية: يجب أن يكون لدى منظمة تحترم نفسها مجموعة من التغييرات مع عائد استثمار مرتفع محتمل ، ولكن في نفس الوقت ، يجب أن يكون هناك العديد من التغييرات الرئيسية من أجل الفوز بالجائزة الكبرى الكبرى [23].
القاعدة رقم 2: نادرا ما يكون للتغييرات تأثير إيجابي كبير على المقاييس الرئيسية
كما قال آل باتشينو في الفيلم كل يوم أحد ، يتم منح النصر سنتيمترًا بالسنتيمتر. يتم تشغيل مئات وآلاف التجارب سنويًا على مواقع مثل Bing. يفشل معظمهم ، وتلك التي تنجح تؤثر على المقياس الرئيسي بنسبة 0.1 ٪ -1.0 ٪ ، مما يضيف انخفاضًا إلى التأثير العام. التغييرات الصغيرة ذات التأثير الكبير الموصوفة في القاعدة السابقة تحدث ، لكنها نادرة.
من المهم ملاحظة شيئين:
- المقاييس الرئيسية ليست شيئًا محددًا يتعلق بميزة فردية يمكن تحسينها بسهولة ، بل هي مقياس مهم للمؤسسة بأكملها: على سبيل المثال ، عدد الجلسات لكل مستخدم [18] أو وقت الوصول إلى هدف المستخدم [24].
عند تطوير ميزة ، من السهل جدًا تحسين عدد النقرات على هذه الميزة بشكل ملحوظ (أو مقياس الميزة الأخرى) ببساطة عن طريق تمييزها أو تكبيرها. ولكن لزيادة نسبة النقر إلى الظهور للصفحة بأكملها أو تجربة المستخدم بالكامل - هذا هو التحدي. معظم الميزات تدفع فقط النقرات على الصفحة ، وتعيد توزيعها بين مناطق مختلفة. - يجب تقسيم المقاييس إلى شرائح صغيرة ، بحيث يكون تحسينها أسهل بكثير. على سبيل المثال ، هل يمكن للفريق تحسين المقاييس بسهولة لاستعلامات الطقس في Bing أو شراء البرامج التلفزيونية على Amazon؟ إضافة أداة مقارنة جيدة. ومع ذلك ، سيحل التحسن الذي طرأ على المقاييس الرئيسية بنسبة 10 بالمائة في مقاييس المنتج بأكمله بسبب حجم الشريحة. على سبيل المثال ، سيؤثر تحسن بنسبة 10 بالمائة في شريحة بنسبة 1 بالمائة على المشروع بأكمله بنحو 0.1٪ (تقريبًا ، لأنه إذا كانت مقاييس الشريحة مختلفة عن المتوسط ، فقد يكون التأثير مختلفًا أيضًا).
أهمية هذه القاعدة كبيرة لأن الأخطاء الإيجابية الكاذبة تحدث أثناء التجارب. هناك نوعان من الأسباب:
- السبب الأول هو بسبب الإحصائيات. إذا أجرينا ألف تجربة سنويًا ، فإن احتمال حدوث خطأ إيجابي كاذب يبلغ 0.05 يؤدي إلى حقيقة أنه بالنسبة لمقياس ثابت ، فسوف نحصل على نتيجة إيجابية خاطئة مئات المرات. وإذا استخدمنا عدة مقاييس غير مرتبطة ببعضها البعض ، فإن هذه النتيجة تزداد قوة فقط. حتى المواقع الكبيرة مثل Bing ليس لديها عدد كافٍ من الزيارات لزيادة الحساسية واستخلاص استنتاجات ذات قيمة أقل للمقاييس مثل عدد الجلسات لكل مستخدم.
- , , .
[11]. [25;26]. , , p-value 0,05 - . دع
ثم:
إذا كان لدينا احتمالًا أوليًا للنجاح يساوي ⅓ (كما قلنا في [7] ، فهذا هو متوسط القيمة بين التجارب في Microsoft) ، فإن الاحتمال الخلفي لتجربة إحصائية إيجابية حقًا هو 89٪. وإذا كانت التجربة واحدة من تلك التي تحدثنا عنها في القاعدة الأولى ، عندما يحتوي 1 فقط من أصل 500 على حل اختراق ، فإن الاحتمالية تنخفض إلى 3.1٪.
النتيجة المضحكة لهذه القاعدة هي حقيقة أن التمسك بشخص ما أسهل بكثير من التطور بمفرده. من المرجح أن يكون للقرارات المتخذة في شركة تركز على الأهمية الإحصائية تأثير إيجابي. على سبيل المثال ، إذا كان لدينا معدل نجاح للتجارب من 10 إلى 20٪ ، فعندما أجرينا اختبارات تلك الميزات التي كانت ناجحة وتم طرحها للمعركة في محركات البحث الأخرى ، فإن مستوى نجاحنا سيكون أعلى. والعكس صحيح أيضًا: يجب على محركات البحث الأخرى أيضًا اختبار وتنفيذ الأشياء التي طبقتها Bing.
من خلال الخبرة ، تعلمنا عدم الثقة في النتائج التي تبدو جيدة للغاية بحيث لا يمكن تصديقها. يتفاعل الناس بشكل مختلف مع المواقف المختلفة. يشتبهون في وجود خطأ ما ويدرسون النتائج السلبية للتجارب مع ميزاتهم الجديدة الرائعة ، ويطرحون أسئلة ويغرقون في البحث عن أسباب هذه النتيجة. ولكن إذا كانت النتيجة إيجابية ببساطة ، فعندئذ يتراجع الشك ويبدأ الناس في الاحتفال ، ولا يدرسون بعمق ولا يبحثون عن الشذوذ.
عندما تكون النتائج رائعة بشكل استثنائي ، فإننا معتادون على اتباع قانون Twyman [27]: كل شيء يبدو مثيرًا أو مختلفًا عادة ما يكون كاذبًا.
يمكن تفسير قانون Twyman باستنتاج بايزي. في تجربتنا ، كنا نعلم أن الاختراق أمر نادر الحدوث. على سبيل المثال ، أدت العديد من التجارب إلى تحسين مقياسنا التوجيهي بشكل كبير ، وهو عدد الجلسات لكل مستخدم. تخيل أن التوزيع الذي نواجهه في التجارب طبيعي ، ويتمركز عند النقطة 0 وانحراف معياري بنسبة 0.25٪. إذا أظهرت التجربة + 2٪ من قيمة المقياس الرئيسي ، فإننا نسمي قانون Twyman ونقول أن هذه نتيجة مثيرة للاهتمام للغاية ، والتي تقع على مسافة 8 انحرافات معيارية عن المتوسط ولديها احتمال
10-15 ، باستثناء عوامل أخرى. حتى مع الأهمية الإحصائية ، فإن التوقعات الأولية قوية جدًا لدرجة أننا سنؤجل الاحتفال بالنجاح ونتعمق في البحث عن سبب الخطأ الإيجابي الكاذب من النوع الثاني. غالبًا ما يتم تطبيق قانون Twyman لإثبات أن
=NP . اليوم ، لن يسعد أي محرر موقع إذا تلقى مثل هذه الأدلة. على الأرجح ، سيجيب على الفور بإجابة نموذجية: "في إثباتك أن P = NP ، تم ارتكاب خطأ في الصفحة X."
مثال: قياس مكتب بديل عبر الإنترنت
تحدث كوك وفريقه [17] عن تجربة مثيرة أجراها مع Microsoft Office Online. اختبر الفريق تصميمًا جديدًا للصفحة برز فيه زر بقوة ، ودعا إلى الدفع مقابل المنتج. المقياس الرئيسي الذي أراد الفريق قياسه: عدد عمليات الشراء لكل مستخدم. لكن تتبع المشتريات الحقيقية يتطلب تعديل نظام الفوترة ، وفي ذلك الوقت كان من الصعب القيام بذلك. ثم قرر الفريق استخدام المقياس "النقرات المؤدية إلى الشراء" وتطبيق الصيغة
( ) * = ، حيث يتم التحويل من النقرات إلى الشراء.
ولدهشتهم ، في التجربة ، انخفض عدد النقرات بنسبة 64٪. أجبرت هذه النتائج الصادمة على تحليل أعمق للبيانات ، وتبين أن افتراض تحويل مستقر من نقرة إلى شراء خطأ. اجتذبت الصفحة التجريبية ، التي أظهرت تكلفة المنتج ، نقرات أقل ، ولكن هؤلاء المستخدمين الذين نقروا عليها كانوا مؤهلين بشكل أفضل وكان لديهم تحويل أكبر بكثير من النقر إلى الشراء.
مثال: نقرات أكثر من صفحة بطيئة
تمت إضافة جافا سكريبت إلى صفحة نتائج بحث Bing. عادةً ما يؤدي هذا النص البرمجي إلى إبطاء الصفحة ، لذا توقع الجميع رؤية تأثير سلبي طفيف على مقاييس التفاعل الرئيسية ، مثل عدد النقرات على المستخدم. لكن النتائج أظهرت العكس ، كان هناك نقرات أكثر! [18] على الرغم من الديناميكيات الإيجابية ، اتبعنا قانون Twyman وحل اللغز. تعتمد أدوات تتبع النقرات على إشارات الويب ، ولم تقم بعض المتصفحات بإجراء مكالمة إذا غادر المستخدم الصفحة. [28] وهكذا ، أثرت جافا سكريبت على دقة عدد النقرات.
مثال: Bing Edge
لعدة أشهر في عام 2013 ، غيرت Bing شبكة توصيل المحتوى الخاصة بها من Akamai إلى Bing Edge الخاصة بها. تم دمج تبديل حركة المرور إلى Bing Edge مع العديد من التحسينات الأخرى. ذكرت عدة فرق أنها حسنت المقاييس الرئيسية: زادت نسبة النقر إلى الظهور لصفحة Bing الرئيسية ، وبدأ استخدام الميزات في كثير من الأحيان ، وبدأ التدفق في الانخفاض. وهكذا اتضح أن كل هذه التحسينات كانت مرتبطة بعدد النقرات النظيفة: لم تحسن Bing Edge سرعة الصفحة فحسب ، بل أيضًا إمكانية توصيل النقرات. لتقييم التأثير ، أطلقنا تجربة تم فيها استبدال منهج المنارة لتتبع النقرات بنهج مع إعادة تحميل الصفحة. تُستخدم هذه التقنية في الإعلانات وتؤدي إلى فقدان بسيط للنقرات ، مما يؤدي إلى إبطاء تأثير كل نقرة. أظهرت النتائج أن نسبة النقرات المفقودة انخفضت بأكثر من 60٪! ومعظم الإنجازات التي تم الإعلان عنها خلال تلك الفترة كانت نتيجة تحسين توصيل النقرات.
مثال: بحث MSN Bing
الإكمال التلقائي هو قائمة منسدلة توفر خيارات لإكمال الطلب أثناء قيام شخص ما بكتابته. خططت MSN لتحسين هذه الميزة باستخدام خوارزمية جديدة ومحسنة (تكون فرق تطوير الميزات جاهزة دائمًا لتوضيح سبب كون الخوارزمية الجديدة أفضل من القديمة ، ولكن غالبًا ما يصابون بالإحباط عندما يرون نتائج التجارب). حققت التجربة نجاحًا كبيرًا ؛ فقد زاد عدد عمليات البحث التي جاءت إلى Bing مع MSN بشكل ملحوظ. وفقًا لقواعدنا ، بدأنا نفهم واكتشفنا أنه عندما نقر المستخدم على المطالبة ، أجرت الشفرة الجديدة استفساري بحث (تم إغلاق أحدهما على الفور من قبل المتصفح بمجرد ظهور نتائج البحث).
لذلك قد لا يكون تفسير العديد من النتائج الإيجابية مثيرًا. ومهمتنا هي إيجاد تأثير حقيقي على المستخدم ، وقد ساعدت قاعدة Twyman حقًا في ذلك وفي فهم العديد من النتائج التجريبية.
القاعدة رقم 3. ستختلف مصلحتك.
هناك العديد من الأمثلة الموثقة لتجارب التحكم الناجحة. على سبيل المثال ، "
أي اختبار فاز؟ " يحتوي على مئات الأمثلة على اختبارات أ / ب ، ويتم تحديث القائمة كل أسبوع.
على الرغم من أن هذا هو مولد رائع للأفكار ، إلا أن هذه الأمثلة لها العديد من المشاكل:
- تختلف الجودة. في هذه الدراسات ، يتحدث شخص من شركة عن نتيجة اختبار أ / ب. هل كان هناك تقييم خبير؟ هل تم تنفيذه بشكل صحيح؟ هل كانت هناك انبعاثات؟ هل كانت قيمة p صغيرة بما يكفي (رأينا اختبارات أ / ب المنشورة بقيمة p أكبر من 0.05 ، والتي عادة ما تعتبر غير ذات دلالة إحصائية)؟ هل كانت هناك مطبات تحدثنا عنها سابقًا ، والتي لم يراجعها مؤلفو الاختبار بشكل صحيح؟
- ما يعمل في مجال واحد قد لا يعمل في مجال آخر. على سبيل المثال ، يوصي Neil Patel [29] باستخدام كلمة "مجانًا" في الإعلانات التي تقدم إصدارًا تجريبيًا لمدة 30 يومًا بدلاً من "ضمان استعادة الأموال لمدة 30 يومًا". قد يعمل هذا مع منتج واحد وجمهور واحد ، لكننا نشك في أن النتيجة ستعتمد بشكل كبير على المنتج والجمهور. يذكر جوشوا بورتر [30] أن "الأحمر أفضل من اللون الأخضر" للأزرار التي تدعو للانضمام إلى "ابدأ الآن". ولكن نظرًا لأننا لم نر العديد من المواقع باستخدام زر أحمر للحث على اتخاذ إجراء ، فمن الواضح أنه لم يتم إعادة إنتاج هذه النتيجة بشكل جيد.
- تأثير الحداثة والمرة الأولى. نحقق الاستقرار في تجاربنا ، والعديد من التجارب في العديد من الأمثلة لم تجر لفترة كافية للتحقق من هذه التأثيرات.
- تفسير غير صحيح للنتائج. قد لا يتم التعرف على سبب خفي أو عامل محدد أو يساء فهمه. نقدم مثالين. واحد منهم هو أول تجربة تحكم موثقة.
مثال 1 داء الاسقربوط هو مرض يسببه نقص فيتامين سي. وقد قتل أكثر من 100.000 شخص في القرنين السادس عشر والثامن عشر ، ومعظمهم من البحارة الذين ذهبوا في رحلات طويلة وبقوا في البحر لفترة أطول من عمر الفواكه والخضروات. في عام 1747 ، لاحظ الدكتور جيمس ليند أن الإسقربوط أقل تأثراً على السفن في البحر الأبيض المتوسط. بدأ بإعطاء الليمون والبرتقال لبعض البحارة ، تاركًا الآخرين لنظامهم الغذائي المعتاد. كانت التجربة ناجحة للغاية ، لكن الطبيب لم يفهم السبب. في المستشفى الملكي البحري في المملكة المتحدة ، عالج مرضى الاسقربوط بعصير الليمون المركز ، والذي وصفه بالسرقة. ركزها الطبيب بالتسخين ، مما أدى إلى تدمير فيتامين سي ليند فقد الإيمان وكثيراً ما لجأ إلى إراقة الدماء. في عام 1793 ، أجريت اختبارات حقيقية. وعصير الليمون أصبح جزءًا من النظام الغذائي اليومي للبحارة. اختفى Scurvy بسرعة ، ولا يزال البحارة البريطانيون يطلقون على عشبة الليمون.
مثال 2 تحدثت ماريسا ماير عن تجربة زادت فيها Google عدد النتائج على صفحة البحث من 10 إلى 30. وانخفض عدد الزيارات والأرباح من المستخدمين الذين بحثوا على Google بنسبة 20٪. وكيف شرحت هذا؟ مثل ، تطلبت الصفحة إنشاء نصف ثانية أخرى. بالطبع ، تعد الإنتاجية عاملاً مهمًا ، لكننا نشك في أن هذا لم يؤثر إلا على جزء صغير من الخسائر. هنا رؤيتنا للأسباب:
- أجرى Bing تجارب بطيئة معزولة [11] ، تغير خلالها الأداء فقط. أثر تأخير استجابة الخادم بمقدار 250 مللي ثانية على الإيرادات بنسبة 1.5٪ تقريبًا ونسبة النقر إلى الظهور بنسبة 0.25٪. هذا تأثير كبير ، ويمكن افتراض أن 500 مللي ثانية ستؤثر على الإيرادات ونسبة النقر إلى الظهور بنسبة 3٪ و 0.5٪ على التوالي ، ولكن ليس بنسبة 20٪ (لنفترض أن التقريب الخطي قابل للتطبيق هنا). أظهرت الاختبارات القديمة في Bing [32] تأثيرًا مشابهًا على النقرات وأثرًا أقل على الأرباح بتأخير ثانيتين.
- كتب Jake Brutlag من Google في مشاركة مدونة حول تجربة [12] يوضح أن إبطاء نتائج البحث من 100 مللي ثانية إلى 400 له تأثير كبير على عدد محدد من عمليات البحث ويتراوح بين 0.2٪ و 0.6٪ ، وهو ما يعمل جيدًا بتجاربنا ، ولكن بعيدًا جدًا عن نتائج ماريسا ماير.
- أجرت BIng تجربة عرض 20 نتيجة بحث بدلاً من 10. أدى فقدان الربح إلى القضاء تمامًا على إضافة إعلانات إضافية (مما جعل الصفحة أبطأ قليلاً). نعتقد أن نسبة الإعلان إلى خوارزميات البحث أكثر أهمية من الأداء.
نحن متشككون في العديد من النتائج الرائعة لاختبارات A / B المنشورة في مصادر مختلفة. عند التحقق من نتائج التجارب ، اسأل نفسك ما هو مستوى الثقة الذي لديك فيه؟ وتذكر أنه حتى لو نجحت الفكرة في أحد المواقع ، فليس من الضروري أن تعمل على موقع آخر. أفضل شيء يمكننا القيام به هو الحديث عن استنساخ التجارب ونجاحها أو فشلها. سيكون أكثر فائدة للعلم.
القاعدة رقم 4: السرعة تعني الكثير
أدرك مطورو الويب الذين يختبرون ميزاتهم باستخدام تجارب التحكم بسرعة أن أداء الموقع أو سرعته يمثلان معلمات مهمة [13 ؛ 14 ؛ 33]. حتى التأخير البسيط في تشغيل الموقع يمكن أن يؤثر على المقاييس الرئيسية لمجموعة الاختبار.
أفضل طريقة لتقييم آثار الأداء هي إجراء تجربة تباطؤ معزولة ، أي فقط مع تأخير إضافي. يوضح الشكل 3 رسمًا بيانيًا قياسيًا للعلاقة بين الأداء والمقياس الذي يتم اختباره (نسبة النقر إلى الظهور ومعدل نجاح الوحدة والإيراد). عادةً ما يكون الموقع أسرع ، كلما كان ذلك أفضل (أعلى في هذا الرسم البياني). من خلال إبطاء عمل مجموعة الاختبار فيما يتعلق بالمجموعة الضابطة ، يمكنك قياس تأثير الأداء على المقياس الذي تهتم به. من المهم ملاحظة:
- يتم قياس تأثير التباطؤ على مجموعة الاختبار هنا والآن (خط متقطع على الرسم البياني) ويعتمد على الموقع والجمهور. إذا تغير الموقع أو الجمهور ، فقد يؤثر تدهور الأداء على المقاييس الرئيسية بشكل مختلف.
- تُظهر التجربة تأثير التباطؤ على المقاييس الرئيسية. يمكن أن يكون هذا مفيدًا جدًا عندما تحاول قياس تأثير ميزة جديدة لا يكون تنفيذها الأول فعالاً. افترض أنه يحسن مقياس M بنسبة X٪ ، وفي الوقت نفسه يبطئ الموقع بنسبة T٪. باستخدام تجربة التباطؤ ، يمكننا تقييم تأثير التباطؤ على المقياس M وتصحيح تأثير الميزة والحصول على التأثير المتوقع X '٪ (من المنطقي افتراض أن هذه التأثيرات لها خاصية الإضافة). وبالتالي يمكننا الإجابة على السؤال التالي: "كيف ستؤثر على المقياس الرئيسي إذا تم تنفيذه بفاعلية؟".
- يمكننا أن نفترض كيف ستؤثر حقيقة أن الموقع سيبدأ العمل بشكل أسرع والمساعدة في حساب عائد الاستثمار لجهود التحسين على المقياس الرئيسي. باستخدام تقريب خطي (المصطلح الأول من سلسلة تايلور) ، يمكننا أن نفترض أن التأثير على المقياس هو نفسه في كلا الاتجاهين. نفترض أن الدلتا العمودي هو نفسه في كلا الاتجاهين ومختلف تمامًا في الإشارة. لذلك ، عند تجربة التباطؤ في القيم المختلفة ، يمكننا أن نتخيل تقريبًا كيف سيؤثر التسارع على هذه القيم نفسها. لقد أجرينا مثل هذه الاختبارات في Bing وتم تأكيد نظريتنا بالكامل.
ما مدى أهمية الأداء؟ مهم للغاية. في أمازون ، يؤدي تباطؤ 100 مللي ثانية إلى انخفاض المبيعات بنسبة 1٪ ، كما قال جريج لينديد [34 صفحة 10]. ويظهر المتحدثون من Bing و Google [32] تأثيرًا كبيرًا للأداء على المقاييس الرئيسية.
مثال: تجربة تباطؤ الخادم
أجرينا تجربة لمدة أسبوعين في Bing لإبطاء الخدمة بمقدار 100 مللي ثانية لـ 10٪ من المستخدمين ، بمقدار 250 مللي ثانية لـ 10٪ أخرى من المستخدمين. اتضح أن كل 100 مللي ثانية من تسريع الخدمة زادت الإيرادات بنسبة 0.6٪. من هنا ظهرت حتى عبارة تعكس بشكل جيد جوهر مؤسستنا:
مهندس سيحسن أداء الخادم بمقدار 10 مللي ثانية (1/30 من سرعة وميض أعيننا) سيكسب شركته أكثر من أرباح العام. كل مللي ثانية مهمة.
في التجربة الموصوفة ، قمنا بإبطاء وقت استجابة الخادم ، ثم قمنا بإبطاء وقت تشغيل جميع العناصر الموجودة في الصفحة. لكن الصفحة تحتوي على أجزاء أكثر أهمية ، وهناك أجزاء أقل أهمية. على سبيل المثال ، قد لا يعرف المستخدمون أن العناصر خارج نطاق الشاشة لم يتم تحميلها بعد. ولكن هل هناك أي عناصر معروضة على الفور يمكن إبطائها دون الإضرار بالمستخدم؟ كما سترى أدناه ، هناك مثل هذه العناصر.
مثال: أداء اللوحة اليمنى ليس بالغ الأهمية
في Bing ، توجد بعض العناصر التي تسمى اللقطات في اللوحة اليمنى ويتم تحميلها في وقت متأخر (بعد حدث window.onload). لقد أجرينا مؤخرًا تجربة: تباطأت عناصر اللوحة اليمنى بمقدار 250 مللي ثانية. إذا أثر هذا على المقاييس الرئيسية ، فمن غير المهم أن لا نلاحظ أي شيء. وشملت التجربة ما يقرب من 20 مليون مستخدم.
غالبًا ما يتم حساب وقت تحميل الصفحة (PLT) باستخدام حدث window.onload ، كعلامة على اكتمال نشاط المتصفح المفيد. ولكن هذا المقياس اليوم لديه عيب خطير عند العمل مع المتصفحات الحديثة. كما أظهر Steve Souders [32] ، يظهر الجزء العلوي من صفحة أمازون في ثانيتين ، بينما تنطلق windows.onload في 5.2 ثانية. ذكر شورمان [32] أنهم كانوا قادرين على عرض الصفحة ديناميكيًا ، لذا كان من المهم بالنسبة لهم إظهار الرأس بسرعة كبيرة. والعكس صحيح أيضًا: في Gmail ، يتم تشغيل windows.onload بعد 3.3 ثانية ، بينما في تلك اللحظة فقط يظهر شريط التنزيل على الشاشة ، وسيتم عرض كل المحتوى في 4.8 ثانية.
هناك مقاييس تتعلق بالوقت ، على سبيل المثال: الوقت للنتيجة الأولى (على سبيل المثال ، الوقت حتى أول تغريدة على Twitter ، أول نتيجة بحث على صفحة النتائج). ولكن مصطلح "الأداء المحسوس" يُستخدم دائمًا لوصف سرعة الصفحة هذه حتى يدرك المستخدم أنها مليئة بما فيه الكفاية. من الأسهل وصف مفهوم "الأداء المدرك" بشكل حدسي بدلاً من صياغته بدقة ، وبالتالي ، ليس لدى أي من المتصفحات خططًا لتنفيذ حدث
perception.ready() . لحل هذه المشكلة ، يتم استخدام العديد من الافتراضات والافتراضات ، على سبيل المثال:
- وقت أعلى الصفحة (AFT) [37]. يتم قياسها على أنها اللحظة التي يتم فيها عرض جميع وحدات البكسل العلوية للصفحة. يعتمد التنفيذ على الأساليب البحثية المعقدة بشكل خاص عند التعامل مع مقاطع الفيديو والصور المتحركة ومعارض التمرير والمحتويات الديناميكية الأخرى التي تغير الجزء العلوي من الصفحة. يمكن تعيين العتبات على "النسبة المئوية لوحدات البكسل المرسومة" لتجنب تأثير العناصر الصغيرة وغير المهمة التي يمكن أن تزيد من القياس المقاس.
- مؤشر السرعة [38] هو بعض التعميم AFT الذي يحسب متوسط الوقت الذي تظهر فيه عناصر الصفحة المرئية على الشاشة. لا تعاني السرعة من العناصر الصغيرة التي تظهر في وقت متأخر ، ولكنها لا تزال تتأثر بالمحتوى الديناميكي الذي يغير الجزء العلوي من الصفحة.
- وقت مرحلة الصفحة ووقت توفر المستخدم [39]. وقت مرحلة الصفحة - الوقت المطلوب لكل مرحلة في عرض الصفحة الفردية. , . — , .
W3C- , HTML, , , . , , , .
Bing , « » (TTS) [24] . — . , 30 . — «Perceived performance». , ; , , . , , , . , . , , , , — .
№5: — , —
, Bing — , , . , — , , . , , . , , .
:
Bing . , «data mining», Bing «Examples of data mining», «Advantages of Data Mining», «definition of data mining», «Data mining companies»,«data mining software» .. . 10 . , (p-value 0,64).
:
Bing , , , , . . 17 %, (p-value 0,71).
:
Bing , 10 . , :
- , , «ebay», CTR 75 %. 10 . : 8 , , 4 . (p-value 0,92), production.
- , «» , Bing (14 ). , 3 «» , : 1,8 % , 30 , 18 % ( ), (p-value 0,93). .
:
. 10 , 12 % ( $150 , ). , (p-value 0,83)
, , . , , .
, ( Microsoft, Amazon .), CTR. , , . , . , . «» . : — , — .
№6: ,
. .. [40]: « , , . , — ». , online-, , [17;41], , , . , . LinkedIn.
: LinkedIn
LinkedIn . 2013 , , , , — LinkedIn, . , : , . , , , . . : . , , , . , , - , , - . .
: LinkedIn
LinkedIn . , . , . , . , , . , . , , , . , , , . , , . , . , .
offline- , , online, , , [4;11]. (Mullty-Variable) , MV-. ( /B/C/D) .
— Agile, MVP [15]: MVT, , . , . , , .. MV- - .
: 1 % , . Agile- Knight Capital, 2012 440 Knights 75 %.
№7:
. , , . , , . , . , [42] , , n > 30, . , . — , Neil Patel , .
, ( ) [16], , . , , .
,
355 * s^2 , , .
s — , :
$$s = \frac{E (XE (X))^3}{\Var (X)^{3/2}}$$, 1. , , Bing:
|
|
|
|
Revenue/User
| 17,9
| 114 .
| 4,4 %
|
Revenue/User (capped)
| 5,2
| 9,7 .
| 10,5 %
|
Sessions/User
| 3,6
| 4,7 .
| 5,4 %
|
Time To Success
| 2,1
| 1,55 .
| 12,3 %
|
, « » 10, « » — 30. 95 % , , 0,025, 0,3 0,2. Boos Hughes-Oliver [43]. , . , 18,2, 114 . . 4 , 100 1000 , QQ. 95- , , 5 %. 100 000 , -2 2.

, - , . , « » , , 18 5, . , 30 % , .
, , . , , , , 0. , 1.
, [16]. bootstrap [44].
الخلاصة
7 , , . , , , , . , Twyman' , , . , , , , . — — . , , , , — . , , (, ). , , . — , , , . , : , . , , . , . Agile. — , . , , . , — . , , , .
, , . Mujtaba Khambatti, John Psaroudakis, Sreenivas Addagatke, . Juan Lavista Ferres, Urszula Chajewska, Greben Langendijk, Lukas Vermeer, Jonas Alves. Eytan Bakshy, Brooks Bell Colin McFarland.
الأدب- Kohavi, Ron and Round, Matt. Front Line Internet Analytics at Amazon.com. [ed.] Jim Sterne. Santa Barbara, CA: sn, 2004. ai.stanford.edu/~ronnyk/emetricsAmazon.pdf .
- McKinley, Dan. Design for Continuous Experimentation: Talk and Slides. [Online] Dec 22, 2012. mcfunley.com/designfor-continuous-experimentation .
- Bakshy, Eytan and Eckles, Dean. Uncertainty in Online Experiments with Dependent Data: An Evaluation of Bootstrap Methods. KDD 2013: Proceedings of the 19th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. 2013.
- Tang, Diane, et al. Overlapping Experiment Infrastructure: More, Better, Faster Experimentation. Proceedings 16th Conference on Knowledge Discovery and Data Mining. 2010.
- Moran, Mike. Multivariate Testing in Action: Quicken Loan's Regis Hadiaris on multivariate testing. Biznology Blog by Mike Moran. [Online] December 2008. www.biznology.com/2008/12/multivariate_testing_in_action .
- Posse, Christian. Key Lessons Learned Building LinkedIn Online Experimentation Platform. Slideshare. [Online] March 20, 2013. www.slideshare.net/HiveData/googlecontrolledexperimentationpanelthe-hive .
- Kohavi, Ron, Crook, Thomas and Longbotham, Roger. Online Experimentation at Microsoft. Third Workshop on Data Mining Case Studies and Practice Prize. 2009. http://expplatform.com/expMicrosoft.aspx .
- Amatriain, Xavier and Basilico, Justin. Netflix Recommendations: Beyond the 5 stars. [Online] April 2012. techblog.netflix.com/2012/04/netflix-recommendationsbeyond-5-stars.html .
- McFarland, Colin. Experiment!: Website conversion rate optimization with A/B and multivariate testing. sl: New Riders, 2012. 978-0321834607.
- Smietana, Brandon. Zynga: What is Zynga's core competency? Quora. [Online] Sept 2010. www.quora.com/Zynga/What-is-Zyngas-corecompetency/answer/Brandon-Smietana .
- Kohavi, Ron, et al. Online Controlled Experiments at Large Scale. KDD 2013: Proceedings of the 19th ACM SIGKDD international conference on Knowledge discovery and data mining. 2013. bit.ly/ExPScale .
- Brutlag, Jake. Speed Matters. Google Research blog. [Online] June 23, 2009. googleresearch.blogspot.com/2009/06/speed-matters.html .
- Sullivan, Nicole. Design Fast Websites. Slideshare. [Online] Oct 14, 2008. www.slideshare.net/stubbornella/designingfast-websites-presentation .
- Kohavi, Ron, Henne, Randal M and Sommerfield, Dan. Practical Guide to Controlled Experiments on the Web: Listen to Your Customers not to the HiPPO. The Thirteenth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD 2007). August 2007, pp. 959-967. www.expplatform.com/Documents/GuideControlledExperiments.pdf .
- Ries, Eric. The Lean Startup: How Today's Entrepreneurs Use Continuous Innovation to Create Radically Successful Businesses. sl: Crown Business, 2011. 978-0307887894.
- Kohavi, Ron, et al. Controlled experiments on the web: survey and practical guide. Data Mining and Knowledge Discovery. February 2009, Vol. 18, 1, pp. 140-181. www.exp-platform.com/Pages/hippo_long.aspx .
- Crook, Thomas, et al. Seven Pitfalls to Avoid when Running Controlled Experiments on the Web. [ed.] Peter Flach and Mohammed Zaki. KDD '09: Proceedings of the 15th ACM SIGKDD international conference on Knowledge discovery and data mining. 2009, pp. 1105-1114. www.expplatform.com/Pages/ExPpitfalls.aspx .
- Kohavi, Ron, et al. Trustworthy online controlled experiments: Five puzzling outcomes explained. Proceedings of the 18th Conference on Knowledge Discovery and Data Mining. 2012, www.expplatform.com/Pages/PuzzingOutcomesExplained.aspx .
- Wikipedia contributors. Fisher's method. Wikipedia. [Online] Jan 2014. http://en.wikipedia.org/wiki/Fisher %27s_method .
- Eisenberg, Bryan. How to Increase Conversion Rate 1,000 Percent. ClickZ. [Online] Feb 28, 2003. www.clickz.com/showPage.html?page=1756031 .
- Spool, Jared. The $300 Million Button. USer Interface Engineering. [Online] 2009. www.uie.com/articles/three_hund_million_button .
- Goldstein, Noah J, Martin, Steve J and Cialdini, Robert B. Yes!: 50 Scientifically Proven Ways to Be Persuasive. sl: Free Press, 2008. 1416570969.
- Collins, Jim and Porras, Jerry I. Built to Last: Successful Habits of Visionary Companies. sl: HarperBusiness, 2004. 978- 0060566104.
- Badam, Kiran. Looking Beyond Page Load Times – How a relentless focus on Task Completion Times can benefit your users. Velocity: Web Performance and Operations. 2013. velocityconf.com/velocityny2013/public/schedule/detail/32 820.
- Why Most Published Research Findings Are False. Ioannidis, John P. 8, 2005, PLoS Medicine, Vol. 2, p. e124. www.plosmedicine.org/article/info :doi/10.1371/journal.pme d.0020124.
- Wacholder, Sholom, et al. Assessing the Probability That a Positive Report is False: An Approach for Molecular Epidemiology Studies. Journal of the National Cancer Institute. 2004, Vol. 96, 6. jnci.oxfordjournals.org/content/96/6/434.long .
- Ehrenberg, ASC The Teaching of Statistics: Corrections and Comments. Journal of the Royal Statistical Society. Series A, 1974, Vol. 138, 4.
- Ron Kohavi, David Messner,Seth Eliot, Juan Lavista Ferres, Randy Henne, Vignesh Kannappan,Justin Wang. Tracking Users' Clicks and Submits: Tradeoffs between User Experience and Data Loss. Redmond: sn, 2010.
- Patel, Neil. 11 Obvious A/B Tests You Should Try. QuickSprout. [Online] Jan 14, 2013. http://www.quicksprout.com/2013/01/14/11-obvious-ab-tests-youshould-try/ .
- Porter, Joshua. The Button Color A/B Test: Red Beats Green. Hutspot. [Online] Aug 2, 2011. blog.hubspot.com/blog/tabid/6307/bid/20566/The-ButtonColor-AB-Test-Red-Beats-Green.aspx .
- Linden, Greg. Marissa Mayer at Web 2.0. Geeking with Greg. [Online] Nov 9, 2006. glinden.blogspot.com/2006/11/marissa-mayer-at-web20.html .
- Performance Related Changes and their User Impact. Schurman, Eric and Brutlag, Jake. sl: Velocity 09: Velocity Web Performance and Operations Conference, 2009.
- Souders, Steve. High Performance Web Sites: Essential Knowledge for Front-End Engineers. sl: O'Reilly Media, 2007. 978-0596529307.
- Linden, Greg. Make Data Useful. [Online] Dec 2006. sites.google.com/site/glinden/Home/StanfordDataMining.20 06-11-28.ppt.
- Wikipedia contributors. Above the fold. Wikipedia, The Free Encyclopedia. [Online] Jan 2014. en.wikipedia.org/wiki/Above_the_fold .
- Souders, Steve. Moving beyond window.onload (). High Performance Web Sites Blog. [Online] May 13, 2013. www.stevesouders.com/blog/2013/05/13/moving-beyondwindow-onload .
- Brutlag, Jake, Abrams, Zoe and Meenan, Pat. Above the Fold Time: Measuring Web Page Performance Visually. Velocity: Web Performance and Operations Conference. 2011. en.oreilly.com/velocitymar2011/public/schedule/detail/18692 .
- Meenan, Patrick. Speed Index. WebPagetest. [Online] April 2012. sites.google.com/a/webpagetest.org/docs/usingwebpagetest/metrics/speed-index .
- Meenan, Patrick, Feng, Chao (Ray) and Petrovich, Mike. Going Beyond onload — How Fast Does It Feel? Velocity: Web Performance and Operations. 2013. velocityconf.com/velocityny2013/public/schedule/detail/31 344.
- Fisher, Ronald A. Presidential Address. Sankhyā: The Indian Journal of Statistics. 1938, Vol. 4, 1. www.jstor.org/stable/40383882 .
- Kohavi, Ron and Longbotham, Roger. Unexpected Results in Online Controlled Experiments. SIGKDD Explorations. 2010, Vol. 12, 2. www.exp-platform.com/Documents/2010- 12 %20ExPUnexpectedSIGKDD.pdf.
- Montgomery, Douglas C. Applied Statistics and Probability for Engineers. 5th. sl: John Wiley & Sons, Inc, 2010. 978- 0470053041.
- Boos, Dennis D and Hughes-Oliver, Jacqueline M. How Large Does n Have to be for Z and t Intervals? The American Statistician. 2000, Vol. 54, 2, pp. 121-128.
- Efron, Bradley and Robert J. Tibshirani. An Introduction to the Bootstrap. New York: Chapman & Hall, 1993. 0-412-04231- 2.