
يعد تطوير نظام DBMS مستقبلًا يتقدم باستمرار. DBMSs تتحسن وتتوسع بشكل أفضل على منصات الأجهزة ، في حين أن منصات الأجهزة نفسها تزيد من الإنتاجية ، وعدد النوى ، والذاكرة - أخيل اللحاق بالسلحفاة ، ولكن لا يزال لا. مشكلة تحجيم DBMS على قدم وساق.
واجه Postgres Professional مشكلة في التوسع ليس فقط نظريًا ، ولكن أيضًا عمليًا: مع عملائه. وأكثر من مرة. ستتم مناقشة إحدى هذه الحالات في هذه المقالة.
يتم قياس PostgreSQL بشكل جيد على أنظمة NUMA إذا كانت لوحة أم واحدة مع معالجات متعددة وناقلات بيانات متعددة. يمكن قراءة بعض التحسينات
هنا وهنا . ومع ذلك ، هناك فئة أخرى من الأنظمة ، ولديها العديد من اللوحات الأم ، ويتم تبادل البيانات بينها باستخدام الاتصال البيني ، بينما يعمل مثيل واحد من نظام التشغيل عليها ، وبالنسبة للمستخدم ، يبدو هذا التصميم وكأنه جهاز واحد. وعلى الرغم من أنه يمكن أن تعزى هذه الأنظمة رسميًا أيضًا إلى NUMA ، ولكنها في جوهرها أقرب إلى أجهزة الكمبيوتر العملاقة ، الوصول إلى الذاكرة المحلية للعقدة والوصول إلى ذاكرة العقدة المجاورة تختلف اختلافا جذريا. يعتقد مجتمع PostgreSQL أن مثيل Postgres الوحيد الذي يعمل على مثل هذه البنى هو مصدر المشاكل ، ولا يوجد نهج منظم لحلها بعد.
وذلك لأن بنية البرامج التي تستخدم الذاكرة المشتركة مصممة بشكل أساسي لحقيقة أن وقت الوصول لعمليات مختلفة إلى ذاكرتها الخاصة والذاكرة البعيدة يمكن مقارنته إلى حد ما. في حالة العمل مع العديد من العقد ، يتوقف الرهان على الذاكرة المشتركة كقناة اتصال سريعة لتبرير نفسها ، لأنه نظرًا لوقت الاستجابة ، يكون إرسال طلب لتنفيذ إجراء معين إلى العقدة (العقدة) أرخص بكثير بيانات مثيرة للاهتمام من إرسال هذه البيانات في الحافلة. لذلك ، بالنسبة للحواسيب العملاقة ، وبشكل عام ، الأنظمة التي تحتوي على العديد من العقد ، فإن حلول الكتلة ذات صلة.
هذا لا يعني أن الجمع بين الأنظمة متعددة العقد وبنية الذاكرة المشتركة Postgres النموذجية يحتاج إلى وضع حد له. بعد كل شيء ، إذا كانت عمليات postgres تقضي معظم وقتها في إجراء العمليات الحسابية المعقدة محليًا ، فستكون هذه البنية حتى فعالة للغاية. في حالتنا ، اشترى العميل بالفعل خادمًا قويًا متعدد العقدة ، وكان علينا حل مشكلات PostgreSQL عليه.
لكن المشاكل كانت خطيرة: تم تنفيذ أبسط طلبات الكتابة (تغيير العديد من قيم الحقول في سجل واحد) في فترة من عدة دقائق إلى ساعة. كما تم تأكيده لاحقًا ، فإن هذه المشاكل تتجلى في كل مجدها على وجه التحديد بسبب العدد الكبير من النوى ، وبالتالي ، التوازي الجذري في تنفيذ الطلبات مع تبادل بطيء نسبيًا بين العقد.
لذلك ، ستظهر المقالة كما لو كانت ذات استخدام مزدوج:
- مشاركة الخبرة: ماذا تفعل إذا تباطأت قاعدة البيانات بشكل جدي في نظام متعدد العقد. من أين نبدأ ، وكيفية تشخيص مكان الانتقال.
- صف كيف يمكن حل مشكلات PostgreSQL DBMS نفسها بمستوى عالٍ من التوافق. بما في ذلك كيف يؤثر التغيير في خوارزمية أخذ الأقفال على أداء PostgreSQL.
الخادم و DB
يتألف النظام من 8 شفرات مع 2 مقابس في كل منهما. في المجموع ، أكثر من 300 النوى (باستثناء hypertreading). إطار سريع (تقنية الشركة المصنعة) يربط الشفرات. لا يعني ذلك أنه جهاز كمبيوتر فائق ، ولكن بالنسبة لمثيل واحد من DBMS ، فإن التكوين مثير للإعجاب.
الحمل كبير أيضًا. أكثر من 1 تيرابايت من البيانات. حوالي 3000 معاملة في الثانية. أكثر من 1000 اتصالاً بـ postgres.
بعد أن بدأنا في التعامل مع توقعات تسجيل الساعة ، كان أول شيء فعلناه هو الكتابة إلى القرص كسبب للتأخير. بمجرد أن بدأت التأخيرات غير المفهومة ، بدأ إجراء الاختبارات حصريًا على
tmpfs . لم تتغير الصورة. القرص لا علاقة له به.
الشروع في التشخيص: طرق العرض
نظرًا لأن المشاكل ظهرت على الأرجح بسبب المنافسة العالية للعمليات التي "تدق" على نفس الأشياء ، فإن أول شيء يجب التحقق منه هو الأقفال. في PostgreSQL ، هناك طريقة عرض
pg.catalog.pg_locks و
pg_stat_activity لمثل هذا الاختيار. والثاني ، بالفعل في الإصدار 9.6 ، أضاف معلومات حول ما تنتظره العملية (
أميت كابيلا ، Ildus Kurbangaliev ) -
wait_event_type . القيم الممكنة لهذا المجال موصوفة
هنا .
لكن أولاً ، احسب فقط:
postgres=
هذه أرقام حقيقية. وصلت إلى 200،000 قفل.
في نفس الوقت ، تم تعليق هذه الأقفال على الطلب المشؤوم:
SELECT COUNT(mode), mode FROM pg_locks WHERE pid =580707 GROUP BY mode; count | mode —
عند قراءة المخزن المؤقت ، يستخدم DBMS قفل
share ، أثناء الكتابة -
exclusive . بمعنى ، شكلت أقفال الكتابة أقل من 1 ٪ من جميع الطلبات.
في طريقة العرض
pg_locks ، لا تبدو أنواع التأمين دائمًا كما هو موضح
في وثائق المستخدم.
هنا لوحة المباراة:
AccessShareLock = LockTupleKeyShare RowShareLock = LockTupleShare ExclusiveLock = LockTupleNoKeyExclusive AccessExclusiveLock = LockTupleExclusive
أظهر استعلام SELECT وضع FROM pg_locks أن CREATE INDEX (بدون CONCURRENTLY) ستنتظر 234 INSERTs و 390 INSERTs
buffer content lock . الحل المحتمل هو "تعليم" INSERTs من جلسات مختلفة للتقاطع أقل في المخازن المؤقتة.
حان الوقت لاستخدام الكمال
تجمع الأداة المساعدة
perf الكثير من المعلومات التشخيصية. في وضع التسجيل ... يكتب إحصائيات لأحداث النظام إلى الملفات (بشكل افتراضي في
./perf_data ) ، وفي وضع
report يقوم بتحليل البيانات التي تم جمعها ، على سبيل المثال ، يمكنك تصفية الأحداث التي تتعلق فقط بـ
postgres أو
pid معين:
$ perf record -u postgres $ perf record -p 76876 , $ perf report > ./my_results
نتيجة لذلك ، سنرى شيئا مثل
يتم وصف كيفية استخدام
perf لتشخيص PostgreSQL ، على سبيل المثال ،
هنا ، وكذلك في
الويكي pg .
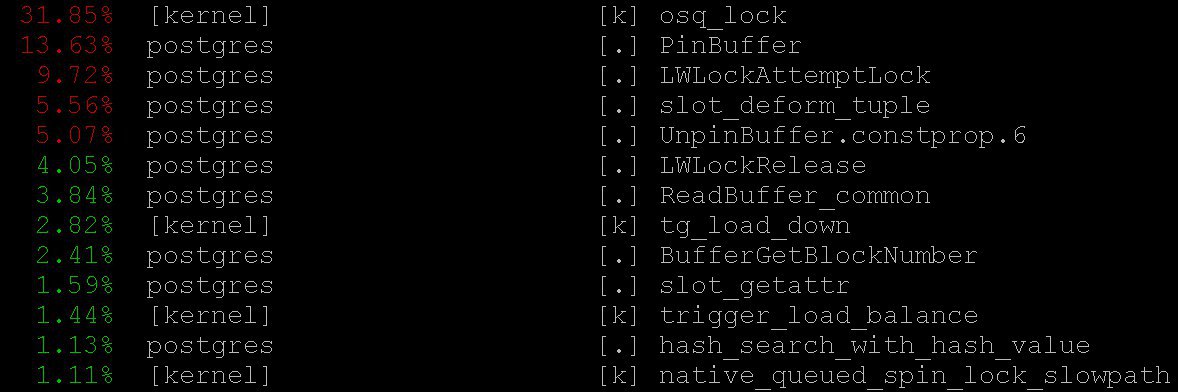
في حالتنا ، حتى الوضع الأبسط أعطى معلومات مهمة
perf top -
perf top ، والذي يعمل ، بالطبع ، بروح نظام التشغيل
top . لقد رأينا أنه مع
perf top يقضي المعالج معظم الوقت في
PinBuffer() الأساسية ، وكذلك في
PinBuffer() و
LWLockAttemptLock(). .
PinBuffer() هي وظيفة تزيد من عداد الإشارات إلى المخزن المؤقت (تعيين صفحة بيانات إلى ذاكرة الوصول العشوائي) ، بفضل عمليات postgres تعرف أي المخازن المؤقتة التي يمكن
PinBuffer() لا يمكن.
LWLockAttemptLock() - وظيفة التقاط
LWLock .
LWLock هو نوع من القفل مع مستويين
shared LWLock ، دون تحديد حالات
deadlock ، يتم تخصيص الأقفال مسبقًا
shared memory ، عمليات الانتظار تنتظر في طابور.
لقد تم بالفعل تحسين هذه الوظائف على محمل الجد في PostgreSQL 9.5 و 9.6. تم استبدال spinlocks داخلها بالاستخدام المباشر للعمليات الذرية.
الرسوم البيانية اللهب
إنه مستحيل بدونهم: حتى لو كانوا عديمي الفائدة ، لا يزال من الجدير أن نقول عنهم - فهي جميلة بشكل غير عادي. لكنها مفيدة. هنا توضيح من
github ، وليس من قضيتنا (لا نحن ولا العميل جاهزون للكشف عن التفاصيل حتى الآن).

تُظهر هذه الصور الجميلة بوضوح ما تتطلبه دورات المعالج. يمكن
perf نفسه جمع البيانات ، ولكن
flame graph يتصور البيانات بذكاء ، ويبني الأشجار بناءً على مكدسات المكالمات المجمعة. يمكنك قراءة المزيد حول التنميط باستخدام الرسوم البيانية لهب ، على سبيل المثال ،
هنا ، وتنزيل كل ما تحتاجه
هنا .
في حالتنا ، كانت كمية كبيرة من
nestloop مرئية على الرسوم البيانية اللهب. على ما يبدو ، تسببت JOINs لعدد كبير من الجداول في العديد من طلبات القراءة المتزامنة في عدد كبير من عمليات تأمين
access share .
تظهر الإحصائيات التي تم جمعها بواسطة
perf أين تذهب دورات المعالج. وعلى الرغم من أننا رأينا أن معظم وقت المعالج يمر على الأقفال ، إلا أننا لم نر ما يؤدي بالضبط إلى مثل هذه التوقعات الطويلة للأقفال ، حيث أننا لا نرى بالضبط أين تحدث توقعات القفل ، لأن وقت وحدة المعالجة المركزية لا يضيع الانتظار.
لمشاهدة التوقعات بأنفسهم ، يمكنك إنشاء طلب لعرض النظام
pg_stat_activity .
SELECT wait_event_type, wait_event, COUNT(*) FROM pg_stat_activity GROUP BY wait_event_type, wait_event;
كشفت أن:
LWLockTranche | buffer_content | UPDATE ************* LWLockTranche | buffer_content | INSERT INTO ******** LWLockTranche | buffer_content | \r | | insert into B4_MUTEX | | values (nextval('hib | | returning ID Lock | relation | INSERT INTO B4_***** LWLockTranche | buffer_content | UPDATE ************* Lock | relation | INSERT INTO ******** LWLockTranche | buffer_mapping | INSERT INTO ******** LWLockTranche | buffer_content | \r
(العلامات النجمية هنا تستبدل ببساطة تفاصيل الطلب التي لم نكشف عنها).
يمكنك رؤية قيم
buffer_content (حظر محتويات المخازن المؤقتة) و
buffer_mapping (حظر مكونات لوحة التجزئة
shared_buffers ).
لمساعدة gdb
ولكن لماذا يوجد الكثير من التوقعات لهذه الأنواع من الأقفال؟ للحصول على معلومات أكثر تفصيلاً حول التوقعات ، كان علي استخدام مصحح
GDB . مع
GDB يمكننا الحصول على مكدس مكالمات لعمليات محددة. من خلال تطبيق أخذ العينات ، أي بعد جمع عدد معين من مكدسات المكالمات العشوائية ، يمكنك الحصول على فكرة عن المكدسات التي لها أطول التوقعات.
النظر في عملية تجميع الإحصاءات. سننظر في مجموعة "الدليل" للإحصاءات ، على الرغم من استخدام نصوص خاصة في الحياة الواقعية تقوم بذلك تلقائيًا.
أولاً ، يجب إرفاق gdb بعملية PostgreSQL. للقيام بذلك ، ابحث عن
pid عملية الخادم ، على سبيل المثال من
$ ps aux | grep postgres
لنفترض أننا وجدنا:
postgres 2025 0.0 0.1 172428 1240 pts/17 S 23 0:00 /usr/local/pgsql/bin/postgres -D /usr/local/pgsql/data
والآن أدخل
pid في المصحح:
igor_le:~$gdb -p 2025
مرة واحدة داخل المصحح ، نكتب
bt [أي
backtrace ] أو
where . ونحصل على الكثير من المعلومات حول هذا النوع:
(gdb) bt #0 0x00007fbb65d01cd0 in __write_nocancel () from /lib64/libc.so.6 #1 0x00000000007c92f4 in write_pipe_chunks ( data=0x110e6e8 "2018‐06‐01 15:35:38 MSK [524647]: [392‐1] db=bp,user=bp,app=[unknown],client=192.168.70.163 (http://192.168.70.163) LOG: relation 23554 new block 493: 248.389503\n2018‐06‐01 15:35:38 MSK [524647]: [393‐1] db=bp,user=bp,app=["..., len=409, dest=dest@entry=1) at elog.c:3123 #2 0x00000000007cc07b in send_message_to_server_log (edata=0xc6ee60 <errordata>) at elog.c:3024 #3 EmitErrorReport () at elog.c:1479
بعد جمع الإحصائيات ، بما في ذلك مكدسات المكالمات من جميع عمليات postgres ، التي تم جمعها بشكل متكرر في نقاط زمنية مختلفة ، رأينا أن
buffer partition lock داخل
relation extension lock استمر 3706 ثانية (حوالي ساعة) ، أي أقفال على قطعة من جدول تجزئة المخزن المؤقت المدير ، الذي كان ضروريًا لتحل محل المخزن المؤقت القديم ، من أجل استبداله لاحقًا بواحد جديد يتوافق مع الجزء الممتد من الجدول. كما تم ملاحظة عدد معين من أقفال
buffer content lock ، وهو ما يتوافق مع توقع قفل صفحات فهرس
B-tree للإدخال.

في البداية ، جاء تفسيران لوقت انتظار هائل:
- شخص آخر أخذ هذا
LWLock وتمسك به. لكن هذا غير مرجح. لأنه لا يوجد شيء معقد يحدث داخل قفل قسم المخزن المؤقت. - واجهنا بعض السلوك المرضي لـ
LWLock . هذا ، على الرغم من حقيقة أن أحداً لم يمسك القفل لفترة طويلة ، فقد ظل توقعه طويلاً بشكل غير معقول.
بقع التشخيص وعلاج الأشجار
من خلال تقليل عدد الاتصالات المتزامنة ، فإننا ربما نفقد تدفق الطلبات إلى الأقفال. لكن ذلك سيكون مثل الاستسلام. بدلاً من ذلك ،
اقترح ألكسندر كوروتكوف ، كبير المهندسين في Postgres Professional (بالطبع ، ساعد في إعداد هذه المقالة) ، سلسلة من التصحيحات.
بادئ ذي بدء ، كان من الضروري الحصول على صورة أكثر تفصيلا عن الكارثة. بغض النظر عن مدى جودة الأدوات النهائية ، ستكون البقع التشخيصية لتصنيعها مفيدة أيضًا.
تمت كتابة تصحيح يضيف تسجيلًا تفصيليًا للوقت الذي يقضيه في
relation extension ، ما الذي يحدث داخل دالة
RelationAddExtraBlocks() . لذا ، اكتشفنا الوقت الذي يقضيه داخل
RelationAddExtraBlocks().ودعما له ، تم كتابة تقرير رقعة آخر في تقرير
pg_stat_activity حول ما نقوم به الآن
relation extension . تم ذلك على هذا النحو: عندما تتوسع
relation ، يصبح
application_name RelationAddExtraBlocks . يتم الآن تحليل هذه العملية بشكل ملائم مع أقصى قدر من التفاصيل باستخدام
gdb bt و
perf .
في الواقع تم كتابة بقع طبية (وليس تشخيصية) اثنين. غيّر التصحيح الأول سلوك أقفال أوراق
B‐tree : في وقت سابق ، عندما طُلب إدخاله ، تم حظر الورقة
share ، وبعد ذلك أصبحت
exclusive . الآن يحصل على الفور
exclusive . الآن
تم بالفعل تثبيت هذا التصحيح لـ
PostgreSQL 12 . لحسن الحظ ، حصل
ألكسندر كوروتكوف هذا العام على
صفة المسافر - ثاني PostgreSQL في روسيا والثاني في الشركة.
تم أيضًا زيادة قيمة
NUM_BUFFER_PARTITIONS من 128 إلى 512 لتقليل الحمل على أقفال التعيين: تم تقسيم جدول تجزئة مدير المخزن المؤقت إلى قطع أصغر ، على أمل أن يتم تقليل الحمل على كل قطعة محددة.
بعد تطبيق هذا التصحيح ، اختفت الأقفال الموجودة على محتويات المخازن المؤقتة ، ولكن على الرغم من الزيادة في
NUM_BUFFER_PARTITIONS ، بقيت
buffer_mapping ، أي أننا نذكرك بحظر قطع جدول تجزئة مدير المخزن المؤقت:
locks_count | active_session | buffer_content | buffer_mapping ----‐‐‐--‐‐‐+‐------‐‐‐‐‐‐‐‐‐+‐‐‐------‐‐‐‐‐‐‐+‐‐------‐‐‐ 12549 | 1218 | 0 | 15
وحتى هذا ليس بالكثير. ب- لم تعد الشجرة عنق الزجاجة. جاء امتداد
heap- إلى المقدمة.
علاج الضمير
بعد ذلك ، طرح ألكسندر الفرضية والحل التالي:
ننتظر الكثير من الوقت على
buffer parittion lock عند
buffer parittion lock المخزن المؤقت. ربما على نفس
buffer parittion lock هناك بعض الصفحات المطلوبة للغاية ، على سبيل المثال ، جذر بعض
B‐tree عند هذه النقطة ، هناك تدفق مستمر لطلبات
shared lock من طلبات القراءة.
خط الانتظار في
LWLock "ليس عادلاً". نظرًا لأن
shared lock يمكن أخذها حسب الحاجة في وقت واحد ، ثم إذا تم أخذ
shared lock بالفعل ، فإن
shared lock اللاحقة تمر دون انتظار. وبالتالي ، إذا كان تدفق الأقفال المشتركة بكثافة كافية بحيث لا توجد "نوافذ" بينهما ، فإن انتظار
exclusive lock يذهب إلى ما لا نهاية.
لإصلاح ذلك ، يمكنك محاولة تقديم - رقعة من سلوك الأقفال "المحترم". يوقظ ضمير
shared locker طابور بصدق عندما يكون لديهم بالفعل
exclusive lock (من المثير للاهتمام أن الأقفال الثقيلة -
hwlock - ليس لديهم مشاكل في الضمير: هم دائمًا يصطفون بصدق)
locks_count | active_session | buffer_content | buffer_mapping | reladdextra | inserts>30sec ‐‐‐‐‐‐-‐‐‐‐‐+‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐+‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐+‐‐‐‐‐‐‐‐‐‐‐--‐-‐+‐‐‐‐‐‐-‐‐‐‐‐‐+‐‐‐‐------ 173985 | 1802 | 0 | 569 | 0 | 0
كل شيء على ما يرام! لا توجد
insert طويلة. على الرغم من بقاء الأقفال على قطع لوحات التجزئة. ولكن ما يجب القيام به ، هذه هي خصائص إطارات حاسوبنا الصغير الصغير.
تم
تقديم هذا التصحيح أيضًا
للمجتمع . ولكن بغض النظر عن كيفية تطور مصير هذه التصحيحات في المجتمع ، فلا شيء يمنعهم من الدخول إلى الإصدارات التالية من
Postgres Pro Enterprise ، والتي تم تصميمها خصيصًا للعملاء الذين لديهم أنظمة محملة بكثافة.
معنوي
أقفال خفيفة الوزن ذات أخلاق عالية -
exclusive - كتل تخطي الطابور - حلت مشكلة التأخير في الساعة في نظام متعدد العقد. لم تعمل علامة تجزئة
buffer manager بسبب
share lock تدفق
share lock ، مما لم يترك أي فرصة للأقفال اللازمة لتحل محل المخازن المؤقتة القديمة وتحميل مخازن جديدة. كانت مشاكل تمديد المخزن المؤقت لجداول قاعدة البيانات نتيجة لذلك فقط. قبل ذلك ، كان من الممكن توسيع عنق الزجاجة مع الوصول إلى جذر
B-treeلم يتم تصميم PostgreSQL لمعماريات NUMA وأجهزة الكمبيوتر العملاقة. يعد التكيف مع هياكل Postgres هذه مهمة ضخمة تتطلب (وربما تتطلب) جهودًا منسقة للعديد من الأشخاص وحتى الشركات. ولكن يمكن تخفيف العواقب غير السارة لهذه المشاكل المعمارية. وعلينا أن: أنواع الحمل التي أدت إلى تأخيرات مماثلة لتلك الموصوفة هي نموذجية تمامًا ، ولا تزال إشارات استغاثة مماثلة من أماكن أخرى تأتي إلينا. ظهرت مشاكل مماثلة في وقت سابق - على الأنظمة ذات النوى الأقل ، لم تكن العواقب وخيمة للغاية ، وتم علاج الأعراض بطرق أخرى وبقع أخرى. الآن ظهر دواء آخر - ليس شاملاً ، ولكنه مفيد بشكل واضح.
لذلك ، عندما تعمل PostgreSQL مع ذاكرة النظام بأكمله كذاكرة محلية ، لا يمكن مقارنة ناقل عالي السرعة بين العقد بوقت الوصول إلى الذاكرة المحلية. تنشأ المهام بسبب هذا الأمر الصعب ، العاجل غالبًا ، ولكنه مثير للاهتمام. وتجربة حلها مفيدة ليس فقط للحسم ، ولكن أيضًا للمجتمع بأكمله.
