
قبل أكثر من عام بقليل ،
استعرضنا تطبيق
Splunk Machine Learning Toolkit ، والذي يمكنك من خلاله تحليل بيانات الجهاز على النظام الأساسي Splunk باستخدام خوارزميات التعلم الآلي المختلفة.
نريد اليوم أن نتحدث عن تلك التحديثات التي ظهرت خلال العام الماضي. تم إصدار العديد من الإصدارات الجديدة ، تمت إضافة العديد من الخوارزميات والمرئيات التي ستسمح بنقل تحليل البيانات في Splunk إلى مستوى جديد.
خوارزميات جديدة
قبل الحديث عن الخوارزميات ، تجدر الإشارة إلى أن هناك
واجهة برمجة تطبيقات ML-SPL يمكنك من خلالها تحميل أي خوارزمية مفتوحة المصدر لأكثر من 300 خوارزمية Python. ومع ذلك ، تحتاج إلى أن تكون قادرًا على البرمجة إلى حد ما في Python.
لذلك ، سوف ننتبه إلى الخوارزميات التي كانت متوفرة سابقًا فقط بعد معالجة بايثون ، ولكنها الآن مضمنة في التطبيق ويمكن استخدامها بسهولة من قبل الجميع.
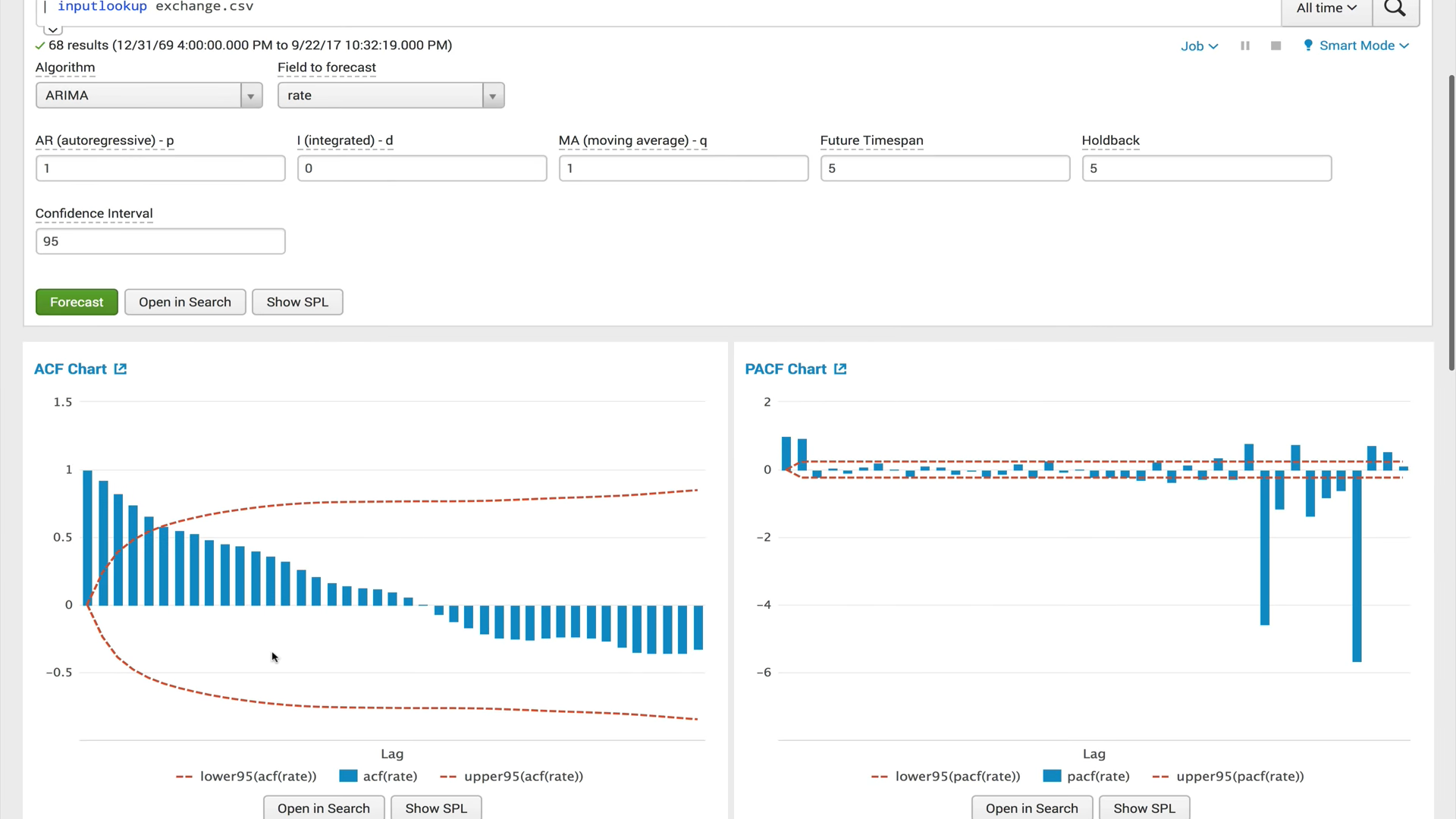
 ACF (وظيفة الارتباط الذاتي)
ACF (وظيفة الارتباط الذاتي)تُظهر وظيفة الارتباط الذاتي العلاقة بين الوظيفة ونسختها المحولة بمقدار مقدار الوقت. يساعدك ACF في العثور على أقسام مكررة أو تحديد تردد الإشارة ، مخفيًا بسبب تداخل الضوضاء والاهتزازات في الترددات الأخرى.
PACF (وظيفة الارتباط الذاتي الجزئي)تُظهر وظيفة الارتباط الذاتي الخاص الارتباط بين المتغيرين ، مطروحًا منه تأثير جميع قيم الارتباط الذاتي الداخلي. يشبه الارتباط الذاتي الخاص في تأخر معين الارتباط الذاتي العادي ، ولكن حسابه يستبعد تأثير الارتباط الذاتي مع التباطؤ الأصغر. من الناحية العملية ، يوفر الارتباط الذاتي الخاص صورة "أكثر نظافة" للتبعيات الدورية.
ARIMA (عملية متكاملة للانحدار الذاتي والمتوسط المتحرك)يعد نموذج ARIMA أحد أكثر النماذج شيوعًا لبناء تنبؤات قصيرة المدى. تعبر قيم الانحدار الذاتي عن اعتماد القيمة الحالية للسلسلة الزمنية على السابقة ، ويحدد المتوسط المتحرك للنموذج تأثير أخطاء التوقعات السابقة (تسمى أيضًا الضوضاء البيضاء) على القيمة الحالية.
 مصنف تعزيز التدرج وعاكس التدرج
مصنف تعزيز التدرج وعاكس التدرجتعزيز التدرج هو طريقة التعلم الآلي المستخدمة في مشاكل الانحدار والتصنيف التي تخلق نموذج التنبؤ في شكل مجموعة من النماذج الضعيفة ، وعادة ما تكون أشجار القرار. يقوم ببناء النموذج على مراحل ، عندما تسعى كل خوارزمية لاحقة لتعويض أوجه القصور في تكوين جميع الخوارزميات السابقة. في البداية ، نشأ مفهوم التعزيز في الأعمال فيما يتعلق بمسألة ما إذا كان من الممكن ، وجود العديد من خوارزميات التعلم السيئة (تختلف قليلاً عن التعريف العشوائي) ، للحصول على واحدة جيدة. على مدى السنوات العشر الماضية ، ظل التعزيز أحد أكثر طرق التعلم الآلي شيوعًا ، جنبًا إلى جنب مع الشبكات العصبية. الأسباب الرئيسية هي البساطة والتنوع والمرونة (القدرة على بناء تعديلات مختلفة) ، والأهم من ذلك ، قدرة التعميم العالية.
س يعنيتعد خوارزمية التجميع X-يعني خوارزمية k-يعني متقدمة تحدد تلقائيًا عدد المجموعات بناءً على معيار معلومات بايزي (BIC). هذه الخوارزمية ملائمة للاستخدام عندما لا تكون هناك معلومات أولية حول عدد المجموعات التي يمكن تقسيم هذه البيانات إليها.
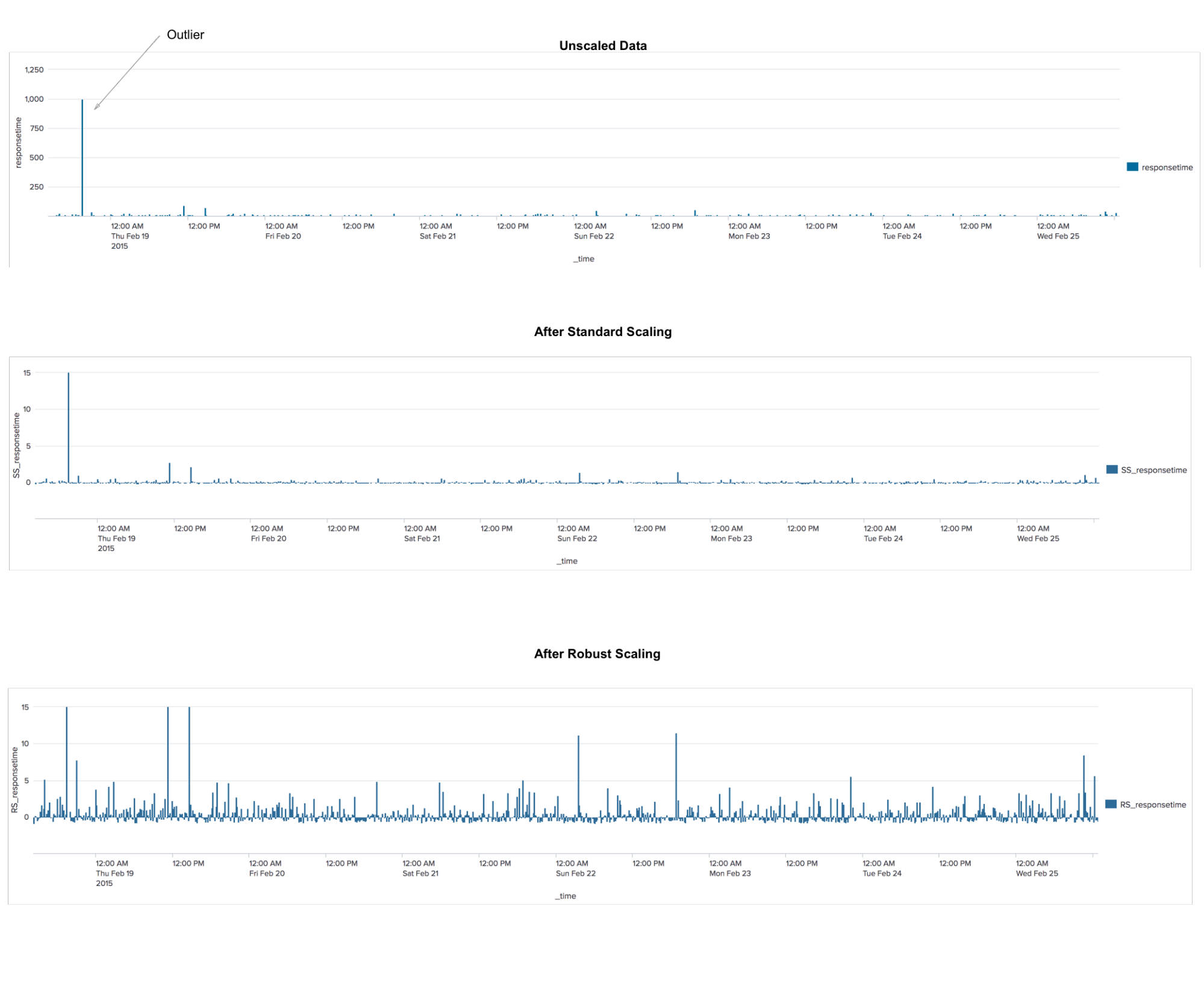
Robustscalerهذه خوارزمية معالجة البيانات. التطبيق مشابه لخوارزمية StandardScaler ، التي تحول البيانات بحيث يكون المتوسط لكل ميزة 0 ويكون التباين 1 ، مما يؤدي إلى أن جميع الميزات لها نفس المقياس. ومع ذلك ، فإن هذا التحجيم لا يضمن تلقي أي قيم دنيا وحد أقصى للسمات. يشبه RobustScaler معيار StandardScaler في أنه نتيجة لتطبيقه ، سيكون للميزات نفس المقياس. ومع ذلك ، يستخدم RobustScaler الوسيط والأرباع بدلاً من المتوسط والتباين. يسمح هذا لـ RobustScaler بتجاهل القيم المتطرفة أو أخطاء القياس ، والتي يمكن أن تكون مشكلة لطرق القياس الأخرى.
 TFIDF
TFIDFمقياس إحصائي يستخدم لتقييم أهمية الكلمة في سياق مستند يشكل جزءًا من مجموعة من المستندات. المبدأ هو هذا: إذا تم العثور على كلمة في كثير من الأحيان في وثيقة ، ونادرا ما وجدت في جميع الوثائق الأخرى ، وبالتالي فإن هذه الكلمة ذات أهمية كبيرة للوثيقة نفسها.
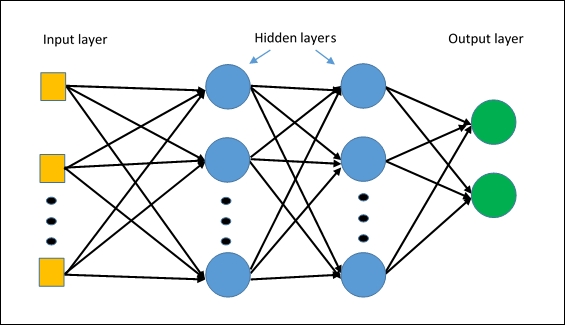
MLPClassifierأول خوارزمية الشبكة العصبية في Splunk. تم بناء الخوارزمية على أساس منظور
متعدد الطبقات ، والذي سوف يلتقط العلاقات غير الخطية في البيانات.
الإدارة
في الإصدارات الجديدة ، تغيرت إدارة التطبيق بشكل كبير.
أولاً ، تمت إضافة
نموذج يحتذى به للوصول إلى النماذج والتجارب المختلفة.
ثانيًا ، تم إدخال واجهة جديدة
لإدارة النماذج . الآن يمكنك بسهولة معرفة أنواع النماذج التي لديك ، والتحقق من إعدادات كل نموذج (على سبيل المثال ، المتغيرات التي تم استخدامها لتدريبه) وعرض أو تحديث إعدادات المشاركة لكل نموذج.
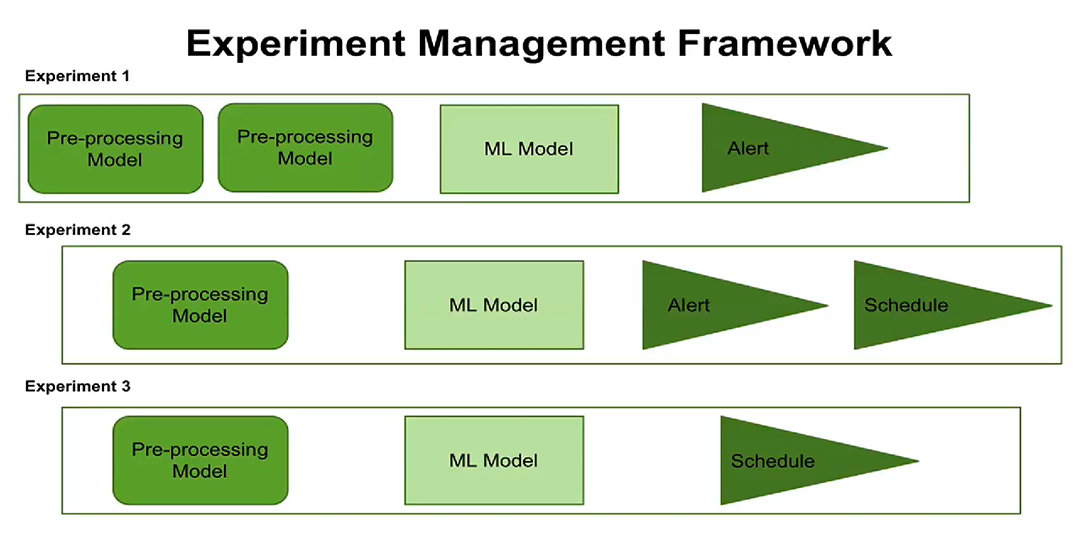
ثالثاً ، ظهور مفهوم إدارة التجارب. الآن يمكنك
تكوين تنفيذ التجارب وفقًا لجدول زمني ، تكوين التنبيهات. يمكن للمستخدمين معرفة متى تتم جدولة كل تجربة ، وما هي خطوات المعالجة والمعلمات التي تم تكوينها لكل تجربة.
يمنحك المفهوم الجديد لإدارة التجارب الآن الفرصة لإنشاء العديد من التجارب وإدارتها في وقت واحد ، لتسجيل متى تم تنفيذ هذه التجارب والنتائج التي تم الحصول عليها.
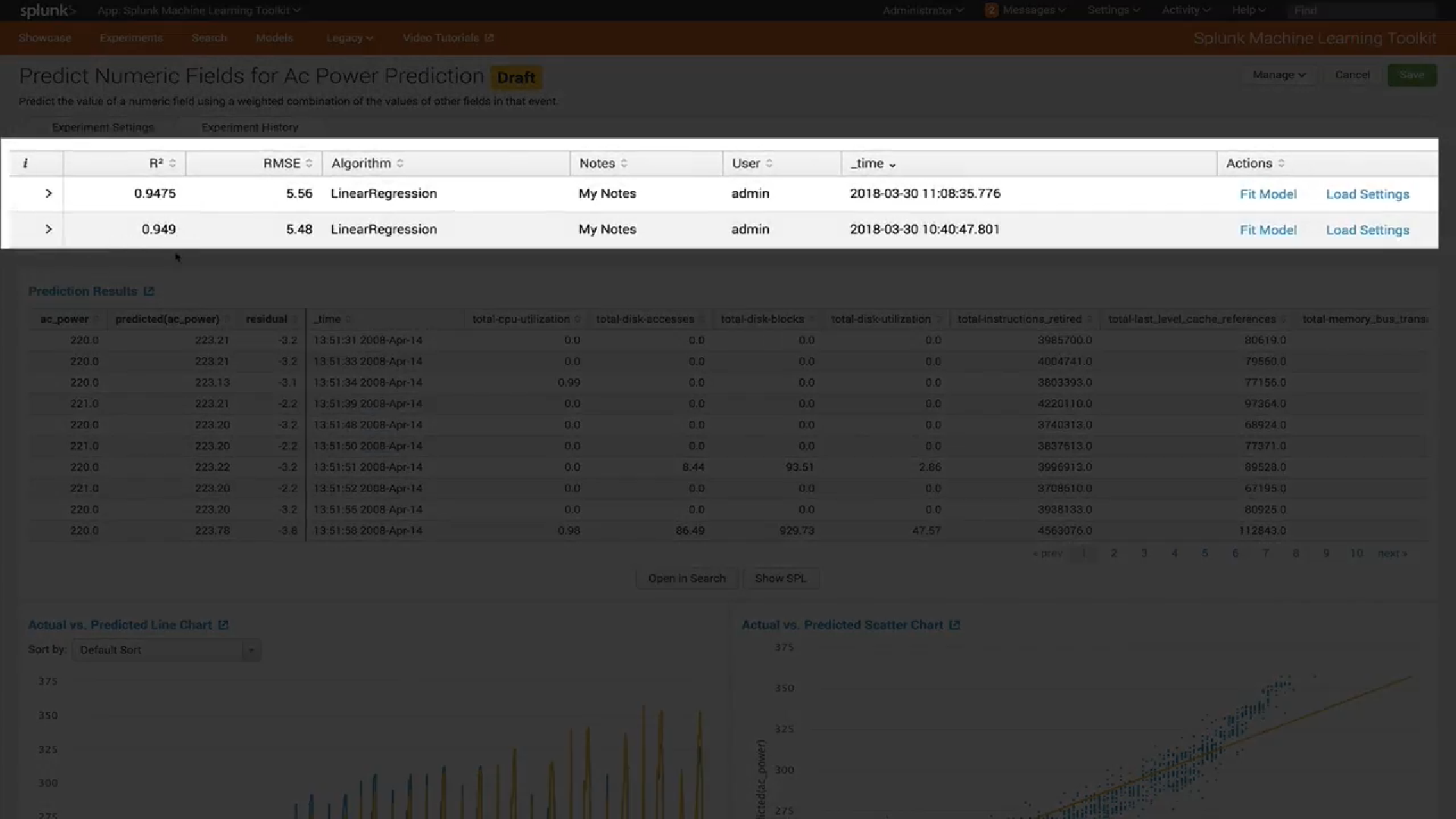
التصور
في الإصدار الأحدث من MLTK 3.4 ، تمت إضافة نوع جديد من التصور.
مؤامرة Box Box الشهيرة أو ، كما نسميها أيضًا ، "Boxes with moustache".
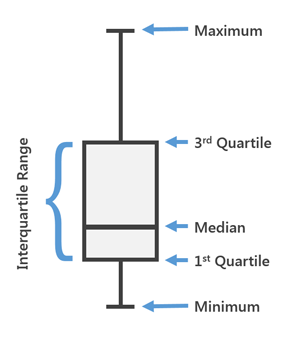
يتم استخدام Box Plot في الإحصائيات الوصفية ، باستخدامه يمكنك أن ترى الوسيط بسهولة (أو ، إذا لزم الأمر ، المتوسط) ، والأربعة الدنيا والعليا ، والقيم الدنيا والقصوى للعينة والقيم المتطرفة. يمكن رسم العديد من هذه الصناديق جنبًا إلى جنب لمقارنة توزيع واحد مع توزيع آخر بشكل مرئي. تسمح لك المسافات بين الأجزاء المختلفة من الصندوق بتحديد درجة التشتت (التشتت) وعدم تناسق البيانات وتحديد القيم المتطرفة.
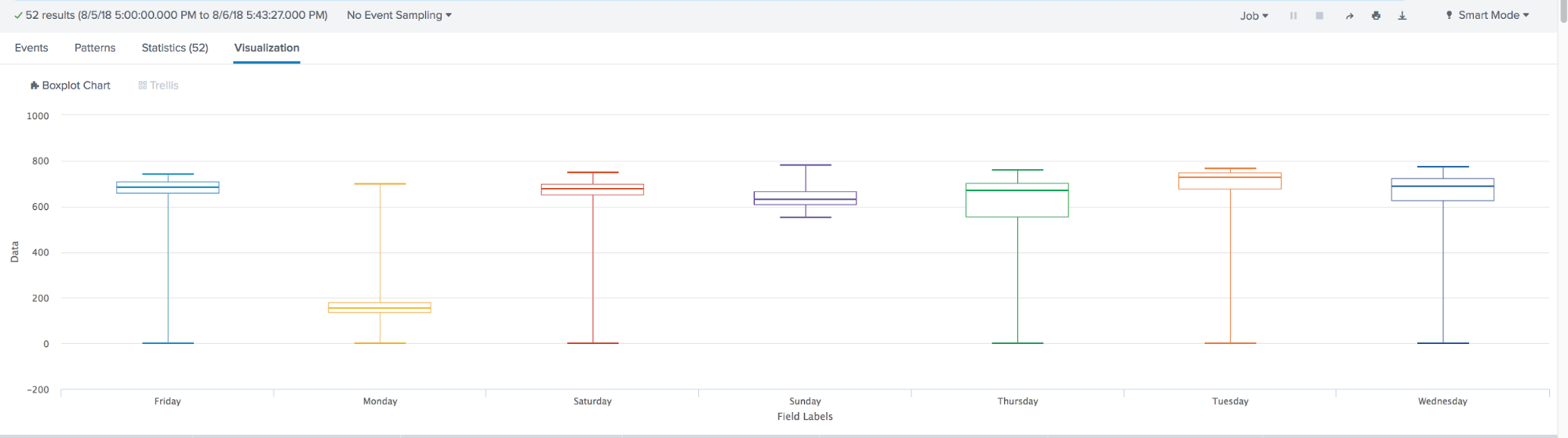
تلخيصًا ، على مدار العام ، خطى التعلم الآلي في Splunk خطوة كبيرة إلى الأمام. ظهر:
- العديد من الخوارزميات المدمجة الجديدة ، مثل: ACF و PACF و ARIMA و Gradient BoostingClassifier و Gradient Boosting Regressor و X-يعني و RobustScaler و TFIDF و MLPClassifier ؛
- نموذج الوصول القائم على الأدوار والقدرة على إدارة النماذج والتجارب ؛
- مؤامرة مربع التصور
