هذا التقرير الذي أعده أليكسي ميلوفيدوف ، رئيس فريق تطوير ClickHouse ، هو لمحة عامة عن أنظمة قواعد البيانات القليلة المعروفة. بعضهم عفا عليه الزمن ، والبعض الآخر أوقف تطورهم وهجرهم. يلفت أليكسي الانتباه إلى الحلول المعمارية المثيرة للاهتمام في الأمثلة المدرجة ، ويفهم مصيرهم ويشرح المتطلبات التي يجب أن يستوفيها مشروعك مفتوح المصدر.
- سيكون تقريري حول قواعد البيانات. دعني أسألك على الفور ، أي خريطة مترو تظهر على هذه الشريحة؟ كل الخطوط تسير في اتجاه واحد.
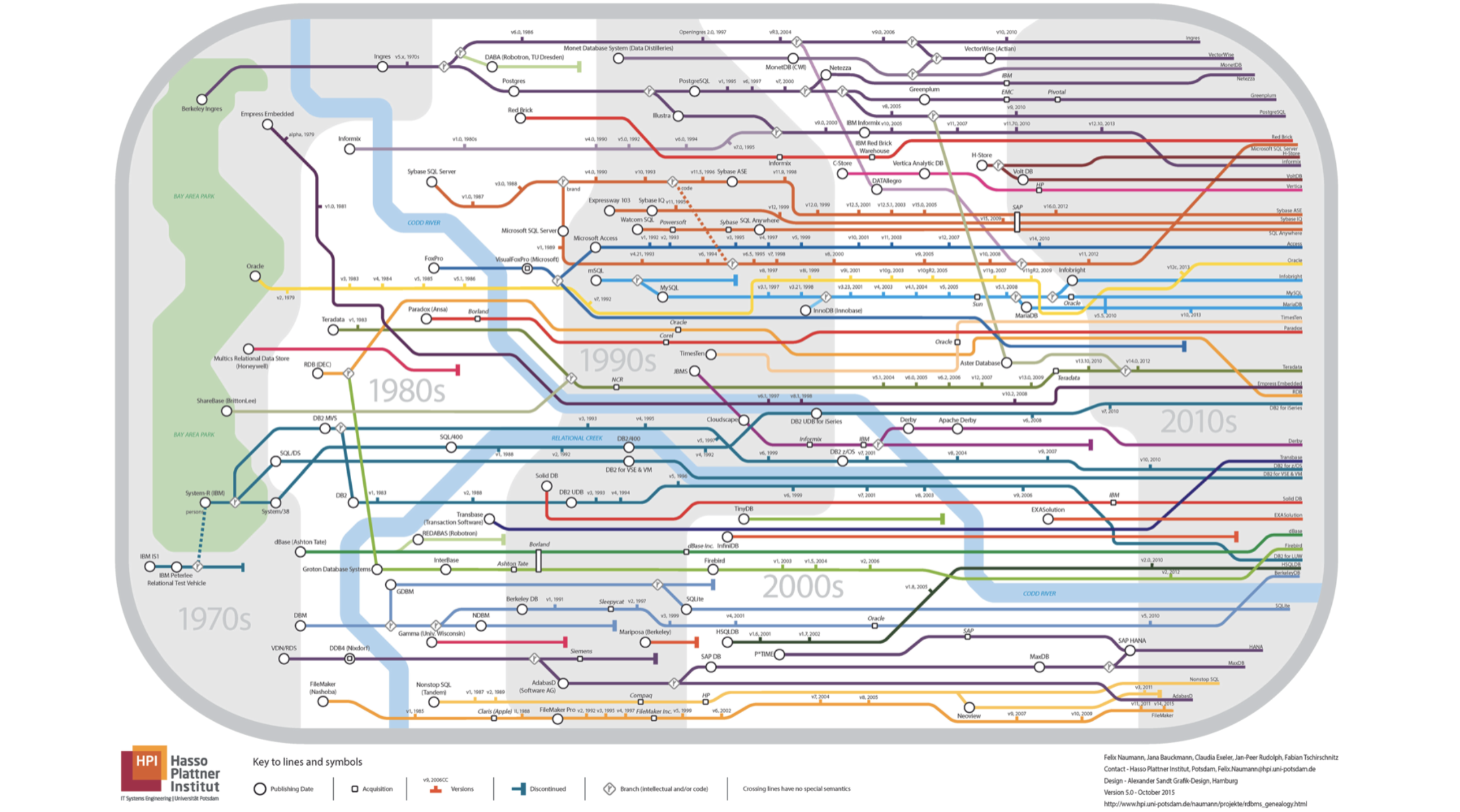
كل شيء خاطئ ، إنه ليس تحت الأرض على الإطلاق ، إنه أصل قواعد البيانات العلائقية. إذا نظرت عن كثب ، سترى أن النهر هو نهر
كودا .
لن أتحدث عنها. ما الذي يمكن أن يكون مملًا أكثر من الحديث عن MySQL أو PostgreSQL أو شيء من هذا القبيل؟ بدلاً من ذلك ، سأتحدث عن صياغة قواعد البيانات.

تجميع يدوي. أنظمة غير معروفة لأي شخص تقريبًا. إما أنها مصممة من قبل شخص واحد أو مهجورة منذ فترة طويلة.

المثال الأول هو EventQL. يرجى رفع يدك إذا سمعت عن هذا النظام. لا يوجد شخص واحد ، باستثناء أولئك الذين يعملون في Yandex والذين استمعوا بالفعل إلى تقريري. لذلك ، لم يكن من دون جدوى أن أدرجت هذا النظام في مراجعتي.

هذا هو محرك قاعدة بيانات الأعمدة الموزعة المصممة لمعالجة الأحداث والتحليلات. ينفذ استعلامات SQL سريعة جدًا ، مفتوحة المصدر منذ 26 يوليو 2016 ، مكتوبة بلغة C ++ ، يتم استخدام ZooKeeper للتنسيق ، ولا توجد تبعيات بجانبها. يذكرني بشيء. نظامنا الرائع ، الجميع يعرف الاسم بالفعل. EventQL هو شيء مثل ClickHouse ، ولكنه أفضل. موازين موزعة ومتوازية بشكل كبير وموجهة نحو العمود إلى بيتابايت وطلبات النطاق السريع - كل شيء واضح ، لدينا كل شيء. دعم كامل تقريبًا لـ SQL 2009 ، وإدراج وتحديثات في الوقت الفعلي ، وتوزيع تلقائي للبيانات عبر المجموعة ، وحتى لغة ChartSQL لوصف الرسوم البيانية. كم هذا رائع! هذا ما نعد به الجميع وما ليس لدينا.
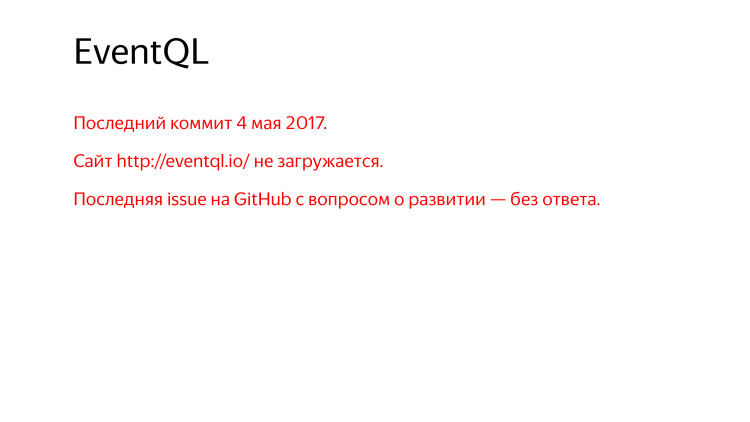
ومع ذلك ، فإن آخر التزام قبل عام تقريبًا ، هناك موقع لا يتم تحميله ، يجب عليك مشاهدته من خلال web.archive.org.
اسأل على GitHub - ما هي خططك التطويرية ، وماذا سيحدث بعد ذلك؟ لم يجب أحد.
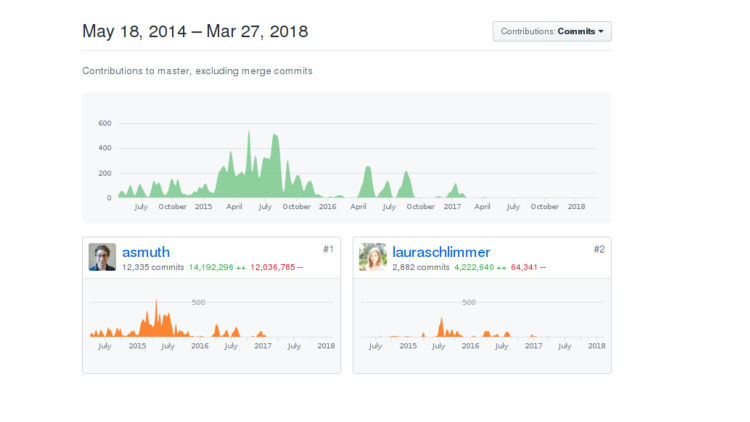
يحتوي النظام على مطورين. واحد هو مطور الواجهة الخلفية ، والثاني هو الواجهة الأمامية. لن أظهر أيهم ربما سيخمن لنفسك. من صنع DeepCortex. يبدو الاسم مألوفًا ، ولكن هناك العديد من الشركات التي تحتوي على كلمة Deep وكلمة Cortex. DeepCortex هي شركة غير معروفة من برلين. تم تطوير النظام منذ عام 2014 ، وتم تطويره داخليًا لفترة طويلة ، ثم تم إطلاقه إلى مصدر مفتوح وتم التخلي عنه بعد عام.

يبدو شيء من هذا القبيل: لقد ألقوا بها في الهواء وفكروا ، فجأة لاحظها شخص ما أو أنها ستطير بعيدًا في مكان ما. لسوء الحظ لا.
عيب آخر هو ترخيص AGPL ، وهو أمر غير مريح نسبيًا. حتى إذا لم تفرض قيودًا شديدة على شركتك لاستخدامها ، فلا يزال هناك مخاوف في كثير من الأحيان ، فقد يكون لدى القسم القانوني بعض النقاط ضدها.
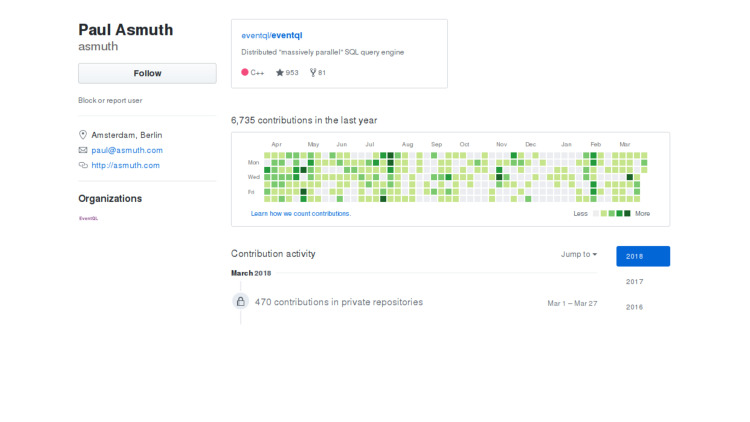
بدأت في البحث عما حدث ، ولماذا لم يتم تطويره. نظرت إلى حساب المطور ، من حيث المبدأ كل شيء على ما يرام ، يعيش الشخص ، يستمر في الالتزام ، ومع ذلك ، كل الالتزامات إلى المستودع الخاص. ليس من الواضح ما حدث.

انتقل إما إلى شركة أخرى وفقد الاهتمام بالدعم ، أو تغيرت أولويات الشركة ، أو بعض ظروف الحياة. ربما لم تشعر الشركة نفسها بالسوء الشديد ، وتم صنع المصدر المفتوح فقط في حالة. أو متعب فقط. لا أعرف الجواب الدقيق. إذا كان أي شخص يعرف ، من فضلك قل لي.

ولكن كل هذا لم يتم عبثا. بادئ ذي بدء ، ChartSQL لوصف الرسوم البيانية. الآن يتم استخدام شيء مشابه في نظام تصور البيانات Tabix لـ ClickHouse. يحتوي EventQL على مدونة ، ومع ذلك ، فهو غير متوفر حاليًا ، عليك أن تبحث عبر web.archive.org ، وهناك ملفات .txt. يتم تنفيذ النظام بكفاءة عالية ، وإذا كنت مهتمًا ، يمكنك قراءة الرمز ورؤية الحلول المعمارية المثيرة للاهتمام.
هذا كل شيء عنها الآن. والنظام التالي يفوز بالجميع ، والذي سأفكر فيه ، لأنه يحمل الاسم الأفضل واللذيذ. نظام Alenka.
كنت أرغب في إضافة صورة لتغليف الشوكولاتة ، لكن أخشى أنه ستكون هناك مشكلات في حقوق الطبع والنشر. ما هو الانكا؟

هذا هو DBMS التحليلي الذي ينفذ الاستعلامات على مسرعات الرسومات. افتتاحية ، رخصة أباتشي 2 ، 1103 نجوم ، مكتوبة بـ CUDA ، القليل من C ++ ، مطور واحد من مينسك. حتى أن هناك سائق JDBC. افتتاحية منذ 2012. ومع ذلك ، منذ عام 2016 ، لم يعد النظام يتطور لسبب ما.

هذا مشروع شخصي ، ليس ملكًا للشركة ، ولكنه حقًا مشروع لشخص واحد. هذا هو نموذج أولي للبحث لاستكشاف إمكانيات معالجة البيانات بسرعة على GPU. هناك اختبارات مثيرة للاهتمام من مارك ليتفينتشيك ، إذا كنت مهتمًا ، يمكنك إلقاء نظرة على المدونة. ربما ، رأى الكثيرون بالفعل اختباراته هناك أن ClickHouse هو الأسرع.

ليس لدي إجابة لماذا تم التخلي عن النظام ، مجرد تخمينات. الآن يعمل الشخص في nVidia ، ربما هذه مجرد مصادفة.

هذا مثال رائع ، لأنه يزيد من الاهتمام والآفاق ، يمكنك أن ترى وتفهم كيف يمكنك القيام بذلك ، وكيف يمكن للنظام العمل على GPU.
ولكن إذا كنت مهتمًا بهذا الموضوع ، فهناك مجموعة من الخيارات الأخرى. على سبيل المثال ، نظام MapD.
من سمع عن MapD؟ الإساءة. هذه شركة جريئة ، تقوم أيضًا بتطوير قاعدة بيانات GPU. تم إصداره مؤخرًا في مصدر مفتوح بموجب ترخيص Apache 2. لا أعرف الغرض منه ، جيد أو العكس. هذه الشركة الناشئة ناجحة للغاية بحيث يتم وضعها في مصدر مفتوح أو العكس بالعكس ، سيتم إغلاقها قريبًا.
هناك PGStorm. إذا كنت على دراية كاملة بـ PostgreSQL ، فيجب أن تسمع عن PGStorm. أيضا مفتوح المصدر ، طوره شخص واحد. من الأنظمة المغلقة ، هناك BrytlytDB ، Kinetica ، والشركة الروسية Polymatic ، التي تصنع نظام ذكاء الأعمال. التحليلات والتصور وكل ذلك. ومعالجة البيانات ، يمكنها أيضًا استخدام مسرعات الرسومات ، قد يكون من المثير للاهتمام رؤيتها.

هل من الممكن القيام بشيء أكثر برودة من GPU؟ على سبيل المثال ، كان هناك نظام يعالج البيانات على FPGA. هذا Kickfire. سلمت حلها في شكل حديد مع البرنامج على الفور. صحيح ، تم إغلاق الشركة منذ فترة طويلة ، كان هذا الحل مكلفًا للغاية ولم يكن بإمكانه التنافس مع خزائن أخرى من هذا القبيل عندما يحضر بعض البائعين هذه الخزانة إليك ، ويعمل كل شيء بطريقة سحرية.
علاوة على ذلك ، هناك معالجات تحتوي على تعليمات لتسريع SQL - SQL في السيليكون في نماذج معالج SPARC الجديدة. ولكن لا داعي لأن تعتقد أنك تكتب الانضمام إلى Assembler ، فهذا ليس موجودًا. هناك تعليمات بسيطة إما أن تقوم بإزالة الضغط باستخدام بعض الخوارزميات البسيطة وقليل من التصفية. من حيث المبدأ ، لا يمكنها فقط تسريع SQL. على سبيل المثال ، تحتوي معالجات Intel على مجموعة من تعليمات SSE 4.2 لمعالجة السلاسل. عندما ظهر في وقت ما من عام 2008 ، كان موقع Intel يحتوي على مقالة بعنوان "استخدام تعليمات معالج Intel الجديدة لتسريع معالجة XML". إنه نفس الشيء هنا. يمكن استخدام تعليمات مفيدة لتسريع قاعدة البيانات.
خيار آخر مثير للاهتمام للغاية هو نقل مهمة تصفية البيانات جزئيًا إلى SSD. الآن أصبحت محركات الأقراص ذات الحالة الصلبة قوية جدًا ، وهذا جهاز كمبيوتر صغير مزود بوحدة تحكم ، ويمكنك تحميل التعليمات البرمجية الخاصة بك إليه إذا حاولت حقًا. سيتم قراءة بياناتك من SSD ، ولكن سيتم تصفيتها على الفور ونقل البيانات الضرورية فقط إلى برنامجك. رائع جدًا ، ولكن كل هذا لا يزال في مرحلة البحث. هنا مقال عن VLDB ، اقرأ.
علاوة على ذلك ، بعض ViyaDB.

تم افتتاحه قبل شهر فقط. "قاعدة بيانات تحليلية للبيانات غير المصنفة." لماذا يتم وضع "غير مفرز" في الاسم ، من غير الواضح لماذا يجب التركيز على هذا. ماذا ، في قواعد البيانات الأخرى فقط مع تلك التي تم فرزها يمكنك العمل؟
كل شيء على ما يرام ، كود المصدر على GitHub ، ترخيص Apache 2.0 ، المكتوب بأحدث C ++ ، كل شيء على ما يرام. مطور واحد ، ولكن لا شيء.

أكثر ما أعجبني ، حيث يمكنك أخذ مثال ، هو التحضير الممتاز للإطلاق. لذلك ، أنا مندهش من أنه لم يسمع أحد. يوجد موقع رائع ، يوجد توثيق ، هناك مقال عن حبري ، هناك مقال عن Medium ، LinkedIn ، Hacker News. اذن ماذا؟ هل كل هذا هباء؟ لم تنظر في أي من هذا. هنا يقولون ، هبر ليس كعكة. حسنا ، ربما ، ولكن هذا شيء عظيم.
كيف يبدو هذا النظام؟

البيانات في ذاكرة الوصول العشوائي ، يعمل النظام مع البيانات المجمعة. التجميع المسبق مستمر. نظام للاستفسارات التحليلية. هناك بعض دعم SQL الأولي ، ولكنه بدأ للتو في التطور ، في البداية كان يجب كتابة الاستعلامات في نوع ما من JSON. من الميزات المثيرة للاهتمام ، التي تعطيها طلبًا ، وتكتب رمزًا لـ C ++ لطلبك نفسه ، يتم إنشاء هذا الرمز وتجميعه وتحميله ديناميكيًا ومعالجة بياناتك. كيف ستتم معالجة طلبك على النحو الأمثل قدر الإمكان. رمز C ++ متخصص بشكل مثالي مكتوب لطلبك. هناك تحجيم ، ويستخدم القنصل للتنسيق. هذا أيضًا زائد ، كما تعلمون ، إنه أكثر برودة من ZooKeeper. أم لا. لست متأكدا ، ولكن يبدو أن نعم.
بعض المباني التي ينطلق منها هذا النظام متناقضة إلى حد ما. أنا من أشد المتحمسين للتقنيات المختلفة ، ولا أريد توبيخ أي شخص. هذا مجرد رأيي ، ربما أكون مخطئا.
الفرضية هي أنه من أجل تسجيل البيانات الجديدة باستمرار في النظام ، بما في ذلك بأثر رجعي ، قبل ساعة ، قبل يوم ، حدث قبل أسبوع. وفي نفس الوقت تشغيل الاستعلامات التحليلية على هذه البيانات على الفور.

يدعي المؤلف أنه لهذا يجب أن يكون النظام بالضرورة في الذاكرة. الأمر ليس كذلك. إذا كنت مهتمًا بالسبب ، يمكنك قراءة المقالة "تطور هياكل البيانات في Yandex.Metrica". شخص واحد في الغرفة كان يقرأ.
ليس من الضروري تخزين البيانات في ذاكرة الوصول العشوائي. لن أقول ما يجب القيام به وما النظام المطلوب تثبيته إذا كنت مهتمًا بحل هذه المشكلة.

ما الخير الذي يمكنك تعلمه؟ الحل المعماري المثير للاهتمام هو إنشاء التعليمات البرمجية في C ++. إذا كنت مهتمًا بهذا الموضوع ، فيمكنك الانتباه إلى مثل هذا المشروع البحثي DBToaster. معهد EPFL للأبحاث ، متوفر على GitHub ، Apache 2.0. كود سكالا ، تعطي استعلام SQL هناك ، يولد هذا الرمز مصادر C ++ لك ، والتي ستقرأ البيانات وتعالجها من مكان ما بالطريقة المثلى. ربما ، ولكن لست متأكدا.

هذا هو نهج واحد فقط لإنشاء التعليمات البرمجية لمعالجة الاستعلام. هناك نهج أكثر شعبية - توليد كود LLVM. خلاصة القول هي أن برنامجك ، كما كان ، يكتب ديناميكيًا في Assembler. حسنا ، ليس حقا ، على LLVM. هناك MemSQL كمثال. هذه في الأصل قاعدة بيانات OLTP ، ولكنها مناسبة أيضًا للتحليلات. تم استخدام C ++ المغلقة والمملوكة في الأصل هناك لإنشاء التعليمات البرمجية. ثم تحولوا إلى LLVM. لماذا؟ لقد كتبت كود C ++ ، عليك تجميعه ، ويستغرق الأمر خمس ثوانٍ للقيام بذلك. حسنًا ، إذا كانت طلباتك متشابهة إلى حد ما ، فيمكنك إنشاء الرمز مرة واحدة. ولكن عندما يتعلق الأمر بالتحليلات ، فلديك طلبات مخصصة هناك ، ومن المحتمل جدًا أنه في كل مرة لا تكون فيها مختلفة فقط ، بل لها بنية مختلفة أيضًا. إذا كان إنشاء الشفرة على LLVM ، فإنه يستغرق ملي ثانية أو عشرات المللي ثانية ، بشكل مختلف ، وأحيانًا أكثر.
مثال آخر هو إمبالا. يستخدم أيضًا LLVM. ولكن إذا تحدثنا عن ClickHouse ، فهناك أيضًا إنشاء رمز ، ولكن يعتمد ClickHouse بشكل أساسي على معالجة الطلبات الموجهة. مترجم ، ولكنه يعمل على المصفوفات ، لذلك فهو يعمل بسرعة كبيرة ، مثل أنظمة مثل kdb +.
مثال آخر مثير للاهتمام. أفضل شعار في تقييمي.

نظام إدارة قاعدة البيانات العلائقية مفتوح المصدر الأول والوحيد المصمم خصيصًا لتخزين البيانات وذكاء الأعمال. متوفر على GitHub ، ترخيص Apache 2. كان يوجد GPL ، ولكن تم تغييره وإتمامه بشكل صحيح. هو مكتوب بلغة جافا. آخر التزام قبل ست سنوات. في البداية ، تم تطوير النظام من قبل المنظمة غير الربحية Eigenbase ، وكان هدف المنظمة هو تطوير إطار عمل ، وقاعدة رمز قابلة للتوسيع إلى أقصى حد لقواعد البيانات ، والتي ليست فقط OLTP ، ولكن على سبيل المثال ، واحد للتحليلات ، LucidDB نفسها ، وغيرها من StreamBase لمعالجة تدفق البيانات.

ماذا حدث منذ ست سنوات؟ بنية جيدة ، وقاعدة تعليمات برمجية قابلة للتوسيع ، وأكثر من مطور واحد. وثائق رائعة. لا شيء يتم تحميله الآن ، ولكن يمكنك رؤيته من خلال WebArchive. دعم SQL كبير.

لكن هناك خطأ ما. الفكرة جيدة ، ولكن تم القيام بذلك من قبل منظمة غير ربحية لبعض التبرعات ، وكان هناك عدد من الشركات الناشئة في مكان قريب. لسبب ما ، كان كل شيء منحنيًا. لم يتمكنوا من العثور على التمويل ، ولم يكن هناك متحمسون ، وقد أغلقت جميع هذه الشركات الناشئة منذ وقت طويل.
ولكن ليس بهذه البساطة. كل هذا لم يذهب سدى.

هناك مثل هذا الإطار - أباتشي كالسيت. إنه نوع من الواجهة الأمامية لقواعد بيانات SQL. يمكنه تحليل الاستعلامات ، والتحليل ، وتنفيذ جميع أنواع تحويلات التحسين ، ووضع خطة لتنفيذ الاستعلام ، وتوفير مشغل JDBC جاهز.
تخيل أنك استيقظت فجأة ، وكنت في مزاج جيد ، وقررت تطوير DBMS العلائقية. أنت لا تعرف ، يحدث ذلك. الآن يمكنك أن تأخذ Apache Calcite ، عليك فقط إضافة تخزين البيانات ، وقراءة البيانات ، ومعالجة الطلبات ، والنسخ المتماثل ، والتسامح مع الأخطاء ، والتقسيم ، كل شيء بسيط. يعتمد Apache Calcite على قاعدة Codid LucidDB ، والتي كانت نظامًا متقدمًا حيث أخذوا الواجهة الأمامية بالكامل من هناك ، والتي يتم استخدامها الآن في بعض الأشكال المعدلة في جميع منتجات Apache و Hive و Drill و Samza و Storm وحتى MapD ، على الرغم من حقيقة أن هو مكتوب في C ++ ، ربط هذا الرمز بطريقة أو بأخرى في جافا.

تستخدم جميع هذه الأنظمة المثيرة للاهتمام Apache Calcite.
النظام التالي هو InfiniDB. من هذه الأسماء بالدوار.

كان هناك Calpont ، الذي كان في الأصل InfiniDB نظامًا مملوكًا ، وكان الأمر هو أن مديري المبيعات اتصلوا بشركتنا وباعوا لنا هذا النظام. كان من المثير للاهتمام المشاركة في هذا. يقولون أن DBMS التحليلي ، رائع ، أسرع من Hadoop ، موجه للأعمدة ، بطبيعة الحال ، ستعمل جميع الاستعلامات بسرعة. ولكن بعد ذلك لم يكن لديهم كتلة ، ولم يتوسع النظام. أقول أنه لا يوجد عنقود - لا يمكننا الشراء. أتطلع ، بعد نصف عام من إصدار إصدار InfiniDB 4.0 ، أضفنا التكامل مع Hadoop ، والتحجيم ، كل شيء على ما يرام.
لقد مرت ستة أشهر ، ويتوفر رمز المصدر في مصدر مفتوح. ثم فكرت ما كنت جالسًا فيه ، وأطور شيئًا ، يجب أن نأخذه ، هناك شيء جاهز.
بدأوا في النظر في كيفية التكيف والاستخدام. بعد عام ، أفلست الشركة. لكن شفرة المصدر متاحة.
وهذا ما يسمى المصدر المفتوح بعد الوفاة. وهذا أمر جيد. إذا لم تشعر بعض الشركات بشكل جيد للغاية ، فمن الضروري أن يبقى بعض التراث على الأقل ، حتى يتمكن الآخرون من استخدامه.

كل ذلك كان هباء. استنادًا إلى مصدر InfiniDB ، لدى MariaDB محرك جدول يسمى ColumnStore. في الواقع ، هذا هو InfiniDB. الشركة لم تعد موجودة ، يعمل الناس الآن في أماكن أخرى ، لكن الإرث لا يزال قائماً ، وهذا رائع. الجميع يعرف عن MariaDB. إذا كنت تستخدمه ، وتحتاج إلى ربط المحرك التحليلي الموجه للأعمدة بسرعة ، فيمكنك أخذ ColumnStore. في الخفاء ، سأقول أن هذا ليس الحل الأفضل. إذا كنت بحاجة إلى أفضل حل ، فأنت تعرف إلى من تذهب وماذا تستخدم.
نظام آخر مع كلمة Infini في الاسم. لديهم شعار غريب ، يبدو أن هذا الخط ينحني. وخط آخر غير مفهوم ، لسبب ما لا يوجد تحيز ، كما لو تم رسمه في الرسام. وجميع الحروف كبيرة ، ربما لترهيب المنافسين.

أنا متحمس لجميع أنواع التقنيات ، محترم للغاية لجميع أنواع الحلول المثيرة للاهتمام. أنا لا أمزح ، لا حاجة للتفكير.
كيف كان هذا النظام؟ لم يعد هذا نظامًا تحليليًا ، بل هو OLTP. نظام لمعالجة المعاملات على المقاييس القصوى. يوجد موقع ، ومزايا هذا النظام هو أن الموقع يتم تحميله. لأنني عندما أنظر إلى جميع الآخرين ، اعتدت على حقيقة أنه سيكون هناك موقف للسيارات أو شيء آخر. المصادر متوفرة. الآن GPL. كان من المعتاد أن يكون AGPL ، لكن لحسن الحظ ، قام المؤلف بتغييره بسرعة. مكتوب بلغة C ++ ، أكثر من مطور واحد ، تم نشره لمصدر مفتوح في نوفمبر 2013 ، وتم التخلي عنه بالفعل في يناير 2014. شهر ونصف. لماذا؟ ما هي النقطة؟ لماذا تفعل ذلك؟

قاعدة بيانات OLTP مع دعم SQL الأولي ، مشروع شخصي ، لا توجد شركة وراءه. يقول المؤلف نفسه في Hackers News أنه نشر في مصدر مفتوح على أمل جذب المتحمسين الذين سيعملون على هذا المنتج.

هذا الأمل محكوم عليه دائما بالفشل. لديك فكرة ، أنت رائع ، أنت متحمس. لذا عليك أن تفعل هذه الفكرة. من غير المحتمل أن يستلهم ذلك أي شخص آخر. أو سيكون عليك العمل بجد لإلهام شخص ما. لذلك من الصعب أن نأمل أنه من أي مكان على الجانب الآخر من العالم ، سيظهر شخص يبدأ في إضافة رمز شخص آخر على GitHub.
ثانيا ، ربما مجرد التقليل من التعقيد. تطوير DBMS ليس مغامرة لمدة 20 دقيقة. إنه صعب وطويل ومكلف.
هذه حالة مثيرة للاهتمام للغاية ، لقد سمع الكثيرون RethinkDB. هذا المثال ليس أساسًا تحليليًا ، وليس OLTP ، ولكنه أساس موجه نحو المستندات.

لقد غير هذا النظام مفهومه عدة مرات. إعادة التفكير. على سبيل المثال ، في عام 2011 ، كتب أن هذا محرك لـ MySQL ، وهو أسرع مائة مرة على SSD ، كما هو مكتوب على الموقع الرسمي. ثم قيل أن هذا نظام ببروتوكول memcached ، تم تحسينه أيضًا لـ SSD. وبعد فترة ، إنها قاعدة بيانات لتطبيقات الوقت الفعلي. أي من أجل الاشتراك في البيانات وتلقي التحديثات مباشرة في الوقت الحقيقي. لنفترض جميع أنواع الدردشات التفاعلية والألعاب عبر الإنترنت. محاولة لإيجاد مكانة. -, JSON. MongoDB. . MongoDB , ? MongoDB . , , «PostgreSQL ».
? — . . , .
RethinkDB? , RAFT. , , , . JSON, - LINQ . ReQL, ++, , ++.

. . , , , , . , , . 20938 GitHub. - .

, , , , , . لماذا؟ ما الخطب؟

, 2009 , , , . , , 2016 . , , , . , , RethinkDB, , , The Linux Foundation. AGPL Apache 2, . , — .

, , , , , , . , .
, , . , - , , , , .
. , , . , XML 15 .
- , 2000-, . , XML . - - , . , .

, Sedna. XML , . , . , . , Sedna, , , , . , .
2013, , . XML , , .
— .
— , , . garret.ru, , . , . , , , . .

. 2014 — IMCS, PostgreSQL, . PostgreSQL, SQL, , . select, . -, . , , , . , . , , , - . , .
, - ? .

, , ? , — . : , - , . , . .
— . , , . , , .
— . , -. - , — , , , -.
, , , .
— , ? , - .
, , . . , , , .
— - - . -, KPHP.
— . , , , .

, , : , , , ? — . , . , . ? : , .
. , , . , .
. , - , , multimodel DB, , , OLTP, , , , . , ? , , - . - -, , , , . , .
دعم موثوق للشركة الأم. لا توجد تعليقات. ليس ترخيصًا مقيدًا ، حتى لا تخيف الشركات الأخرى القسم القانوني ، فإن هؤلاء الناس يخافون من كل شيء. يجب أن تأتي فوائد نظامك من الأسباب الأساسية. لنفترض ، إذا كانت لديك قاعدة بيانات لمعالجة XML ، فهذا ليس جيدًا إلى حد ما. ربما لا يحتاج أي شخص آخر إلى تخزين البيانات في XML. وإذا كانت لديك قاعدة بيانات موجهة نحو المستندات ، فهذه قاعدة أخرى. يحتاج الجميع إلى الاحتفاظ بالوثائق ، وبغض النظر عن ما هو بالضبط. بالإضافة إلى ذلك ، فإن دعم تنمية المجتمع مهم جدًا لمصدر مفتوح جيد. هذا لا يعني أنك تحتاج فقط إلى تعليق طلبات السحب. هذا يعني - تحتاج إلى أن يشعر الناس بأنك موجود ، فأنت تجيب على الأسئلة ، وأن المنتج في طور النمو. هذا ما سيجعل مصدر مفتوح جيد وحي. هذا كل شيء ، شكرا.