قبل أشهر قليلة ، قررنا في أحد الأحداث السابقة محاولة القراءة معًا.
تنسيقنا:
- اختر كتابًا.
- نحدد الجزء الذي يجب قراءته في غضون أسبوع. اختر حجمًا صغيرًا.
- نناقش يوم الجمعة ما نقرأه.
- نقرأ خلال ساعات العمل ، نناقش خلال ساعات العمل.
- بعد الانتهاء من الكتاب ، نختار معا ما يلي.
ما يعطي:
- الدافع للقراءة والقراءة.
- تنمية المهارات (بما في ذلك للمستقبل).
- محاذاة العقلية والمصطلحات في فريق.
- نمو الثقة.
- سبب آخر للحديث.
أحد أحدث الكتب التي قرأناها هو
تصميم تطبيقات مكثفة للبيانات . نعم ، هذا الكتاب نفسه مع خنزير. وقد أحب الجميع هذا الكتاب كثيرًا لدرجة أنني قررت مراجعته هنا حتى يقرأه المزيد من الأشخاص.
 خريطة بالجودة الأصلية
خريطة بالجودة الأصليةتوجد ترجمة لهذا الكتاب إلى الروسية من الناشر بيتر. لكننا قرأنا في النص الأصلي ، لذلك لا أعدكم بأن ترجمة المصطلحات ستطابق. علاوة على ذلك ، لم نترجم عمدا جزء من المصطلحات.
الجزء الأول من الكتاب مخصص لأساسيات أنظمة معالجة البيانات.
يشير
الفصل الأول إلى أن الخصائص المهمة لهذه الأنظمة هي الموثوقية وقابلية التوسع وسهولة الصيانة.
يصف
الفصل الثاني نماذج البيانات المختلفة. يتم وصف قواعد بيانات DBMS الاعتيادية والموجهة إلى المستندات ، بالإضافة إلى قواعد بيانات الأعمدة والرسم البياني الأقل شهرة.
الفصول الأولى محدثة ، تحدد نطاق الكتاب. في العديد من الأماكن أدناه ، يشير المؤلف إلى الفصول الأولى. في الإنصاف ، يمكننا القول أن الكتاب مليء بالمراجع التبادلية.
ما يثير الدهشة من الفصول الأولى هو عدد المصادر (هناك ببليوغرافيا بعد كل فصل). يتم ترتيب روابط عشرات المقالات (المدونات والعلمية) والكتب بدقة في جميع الفصول. يتجاوز عدد المصادر لبعض الفصول مائة.
يبدأ
الفصل الثالث برمز المصدر لأبسط مخزن لقيمة المفتاح:
ستعمل حتى بشكل جيد جدًا في الكتابة ، ولكن بالطبع لا تخلو من مشاكل القراءة.
وعلى الفور ، يتم تقديم خيارات لتحسين الأداء. يصف فهارس التجزئة و SSTable و b-tree و LSM-tree. يتم شرح كل هذا على الأصابع ، ولكن يتم توضيح كيفية استخدام هذا الهيكل أو ذاك في قواعد البيانات المألوفة.
التركيز على الممارسة هو سمة مميزة أخرى للكتاب. معظم الأمثلة والوصفات عملية لدرجة أنني صادفت كل شيء ذي صلة تقريبًا.
يصف
الفصل الرابع الترميز: من JSON العادي و XML إلى Protobuf و AVRO. نحن لا نختار التنسيق دائمًا بوعي ، وعادةً ما يتم فرضه بواسطة تقنية أو أخرى ككل. ولكن من الرائع أن نفهم كيف يعمل في الداخل ، ما هي نقاط القوة والضعف في التنسيق.
لم يستخدم المؤلف على وجه التحديد مصطلح التسلسل ، حيث أن هذا المصطلح له معنى آخر في قواعد البيانات.
محتوى الفصول أكثر ثراء بكثير من العرض التقديمي الموجز. يصف الجزء الأول أيضًا الاختلافات بين OLTP و OLAP ، وكيفية ترتيب البحث عن نص كامل والبحث في قواعد بيانات الأعمدة ، و REST ، ووسطاء الرسائل.
الجزء الثاني من الكتاب يتحدث عن أنظمة معالجة البيانات الموزعة. تحتوي جميع الأنظمة الحديثة تقريبًا التي يتم تحميلها بشكل أو بآخر على عدة نسخ متماثلة أو أنظمة فرعية (خدمات مصغرة).
عندما بدأنا في ممارسة القراءة معًا ، ناقشنا ببساطة ملاحظاتنا والأماكن المثيرة للاهتمام والأفكار. في مرحلة ما ، أدركنا أننا ببساطة لم يكن لدينا ما يكفي من المحادثات ، بعد المناقشة يتم نسيان كل شيء بسرعة. ثم قررنا تعزيز ممارستنا وإضافة ملء الخريطة الذهنية. كان الابتكار فقط هذا الكتاب. بدءًا من الجزء الثاني ، بدأنا في الحفاظ على خريطة ذهنية لكل فصل. لذلك ، سيكون كل فصل مع الخريطة الذهنية. استخدمنا coggle.it
يصف
الفصل الخامس النسخ المتماثل.
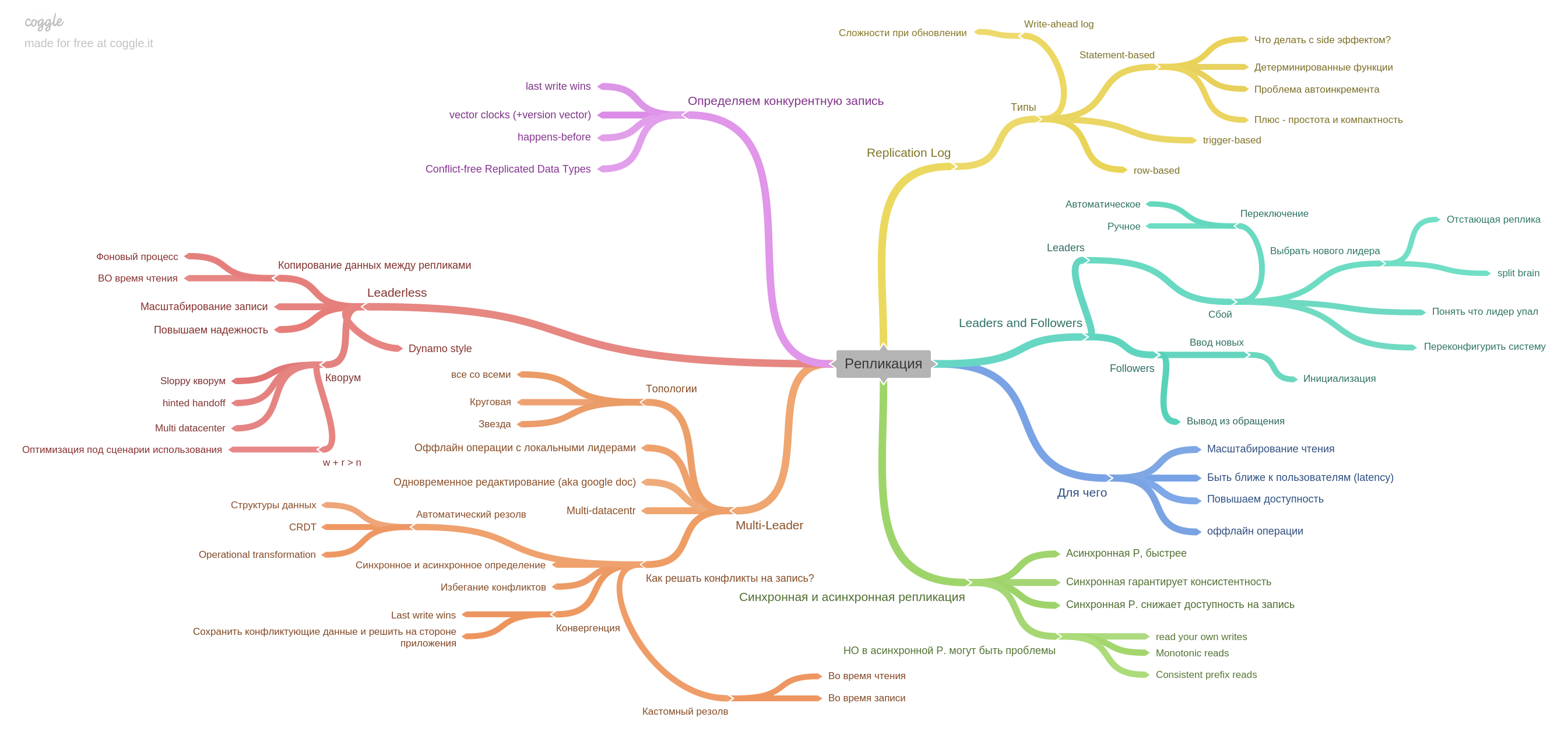
هنا يتم جمع جميع المعلومات الأساسية حول النسخ المتماثلة: سيد واحد ، متعدد الوسائط ، سجل النسخ المتماثل وكيفية العيش مع سجل تنافسي في أنظمة بدون قائد.
يصف
الفصل السادس التقسيم (ويعرف أيضًا بالتقاسم ومجموعة من المصطلحات الأخرى).
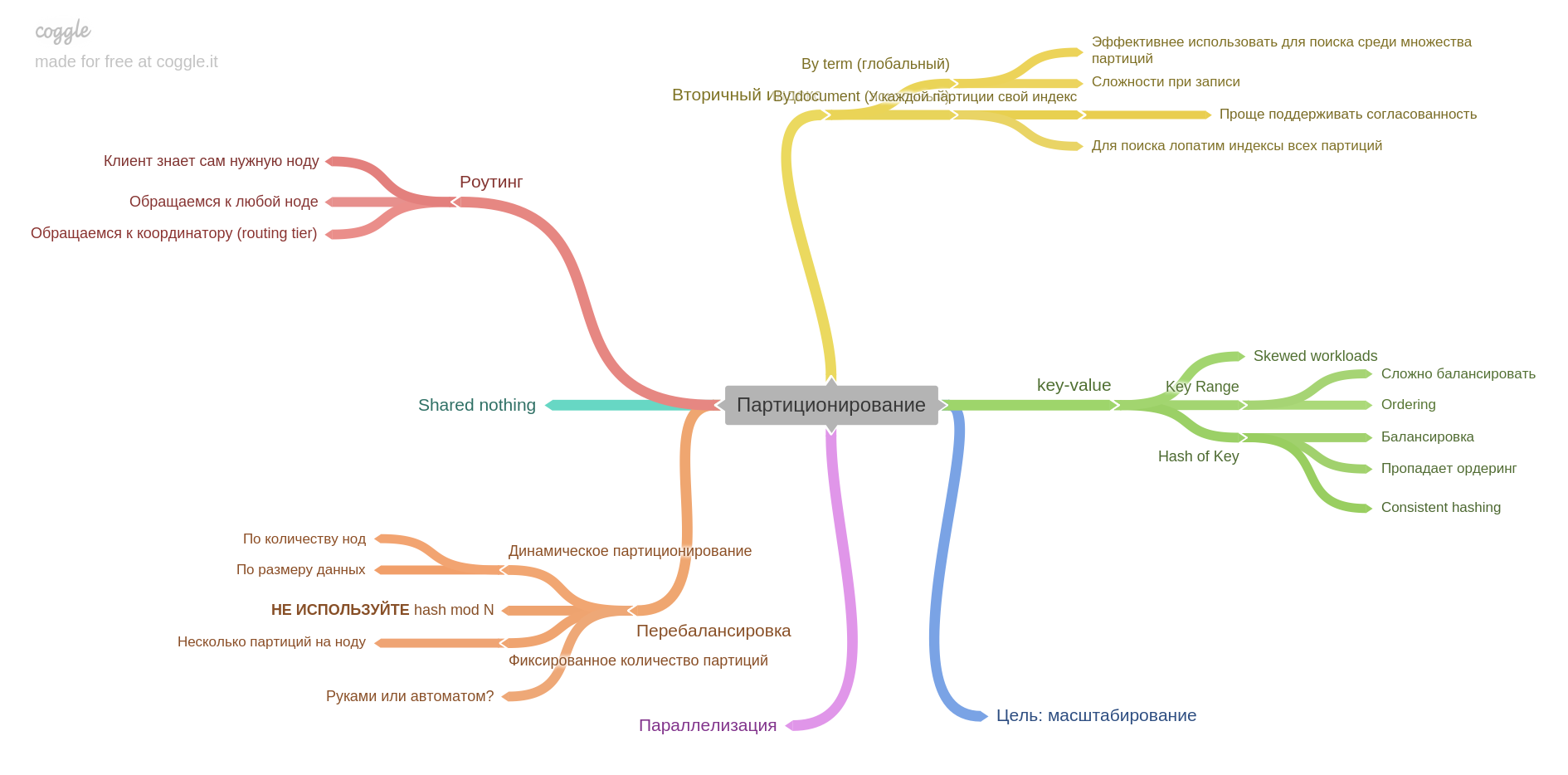
سوف تتعلم كيفية تقسيم البيانات إلى أجزاء ، وما هي المشاكل التي يمكن حلها وأيها يمكن الحصول عليه ، وكيفية بناء الفهارس وموازنة البيانات.
الفصل السابع : المعاملات.
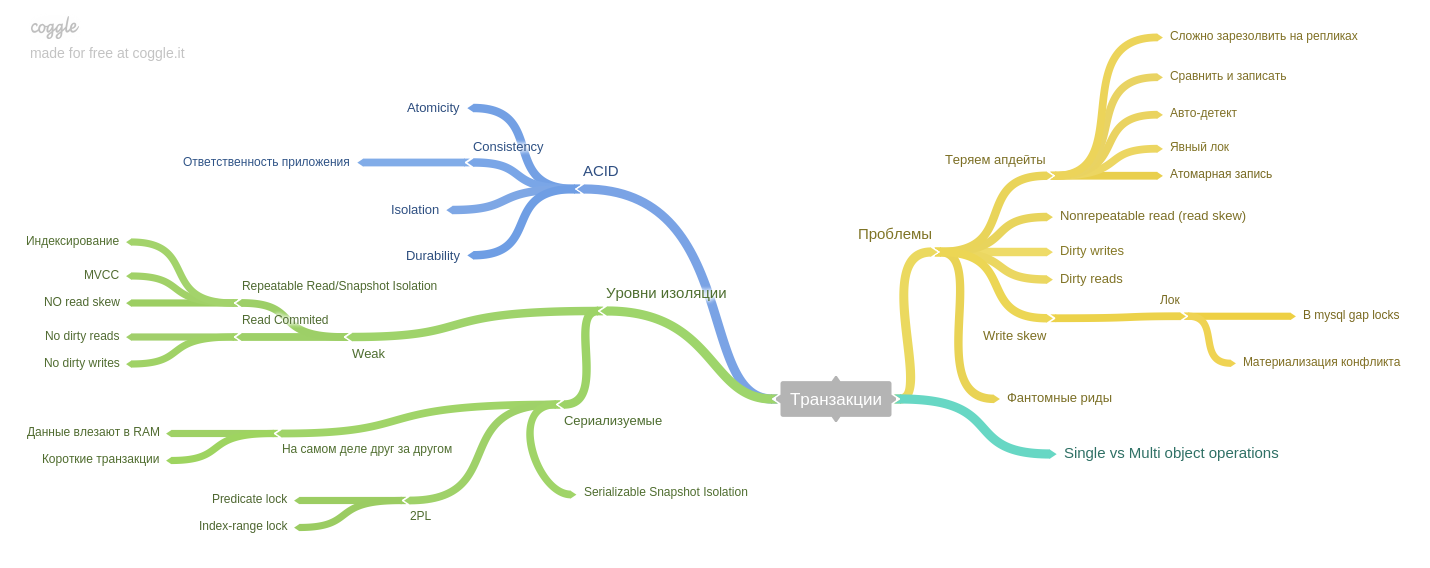
يتم وصف الظواهر (قراءة الانحراف ، كتابة الانحراف ، القراءة الوهمية ، إلخ) وكيف تساعد مستويات العزلة لقواعد بيانات نمط ACID على تجنب المشاكل.
الفصل الثامن: عن المشاكل الخاصة بالأنظمة الموزعة.
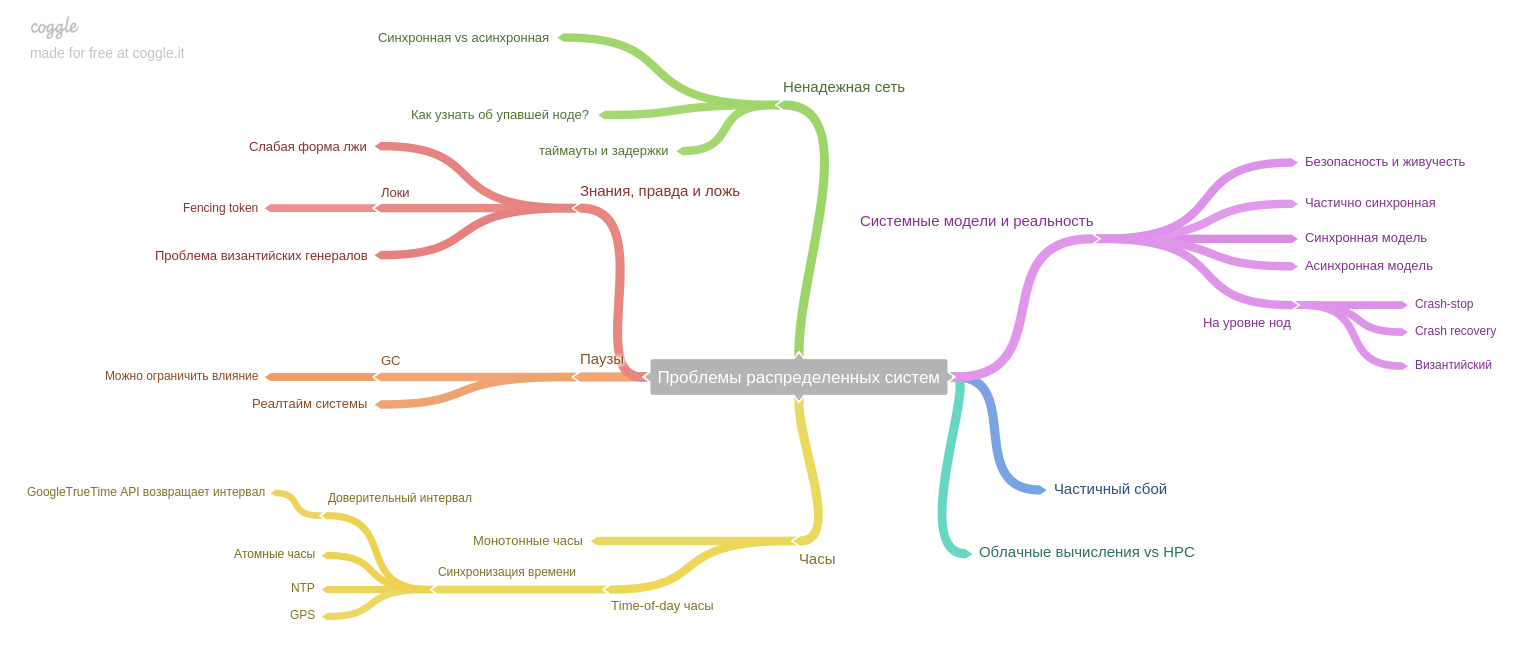
يؤكد المؤلف على فكرة مهمة: إذا عمل النظام في وقت سابق على جهاز واحد ، وفي حالة الفشل توقف النظام بأكمله عن العمل (وقبول أي بيانات جديدة). وهكذا ، ظلت البيانات بعد الفشل في حالة ثابتة ، ولكن اليوم ، في عصر النسخ المتماثلة والخدمات الصغيرة ، يتم إغلاق جزء فقط من النظام. وبالتالي ، فإننا نواجه مشكلة جديدة: ضمان تناسق البيانات في حالات الفشل الجزئي ، والمشاكل المستمرة مع شبكة غير موثوقة ، وما إلى ذلك.
يصف
الفصل التاسع التماسك والإجماع ويقدم مفهومًا مهمًا: قابلية الخطية. أتذكر أن الرأس جاء بقوة وتناسب رأسي)
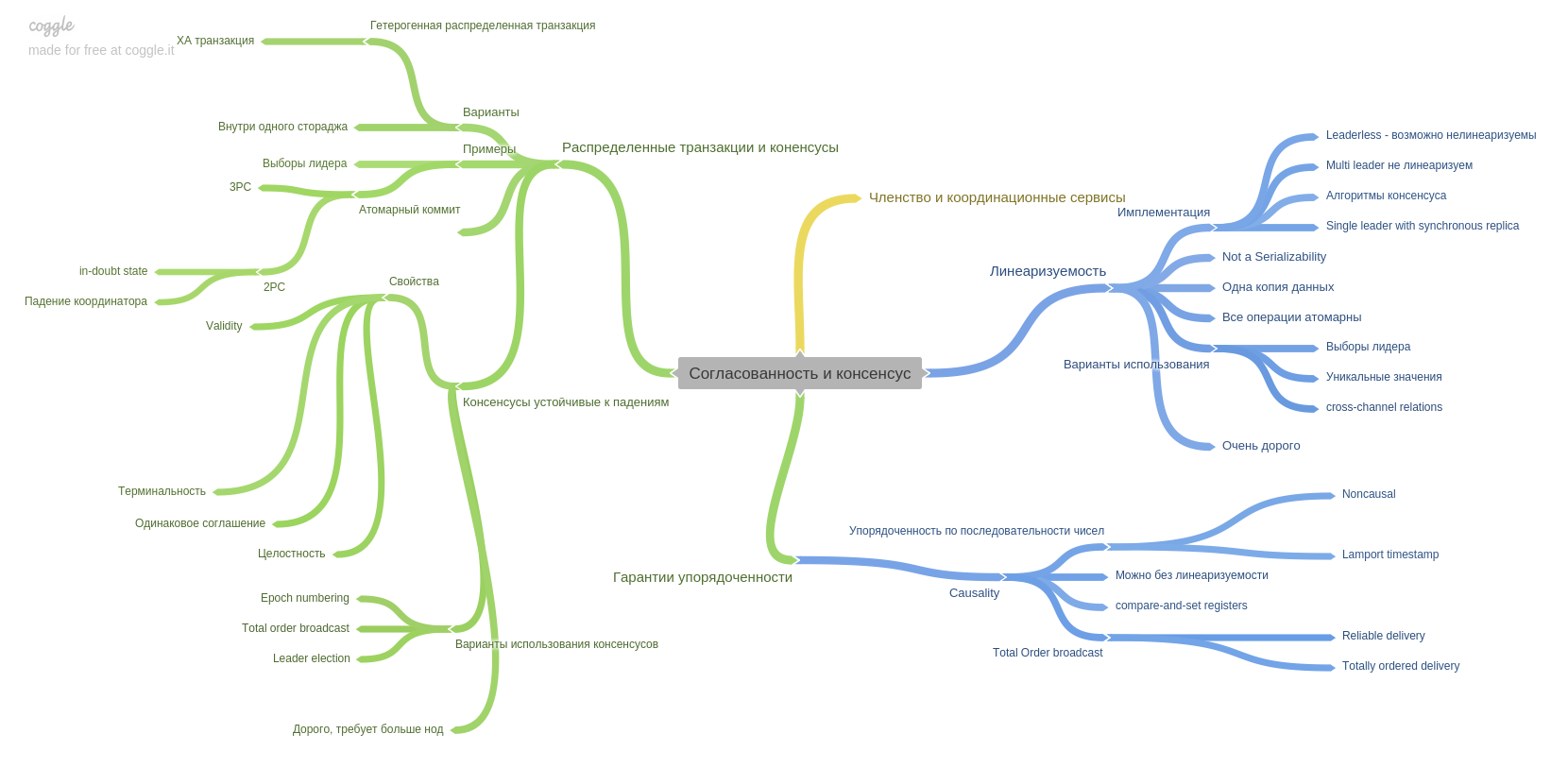
يصف هذا الفصل أيضًا أسلوب الالتزام على مرحلتين ونقاط ضعفه. أيضا في هذا الفصل سوف تقرأ عن ضمانات النظام. كيف وماذا يمكن أن توفر لك الأنظمة الحديثة.
الجزء الثالث من الكتاب مخصص للبيانات المشتقة (لا توجد ترجمة ثابتة). ونتيجة لذلك ، يعبر المؤلف عن فكرة أن جميع الفهارس والجداول والعروض المادية ليست سوى ذاكرة تخزين مؤقت فوق السجل. يحتوي السجل فقط على البيانات الأكثر صلة ، وكل شيء آخر متأخر ويتم استخدامه للراحة.
الفصل العاشر.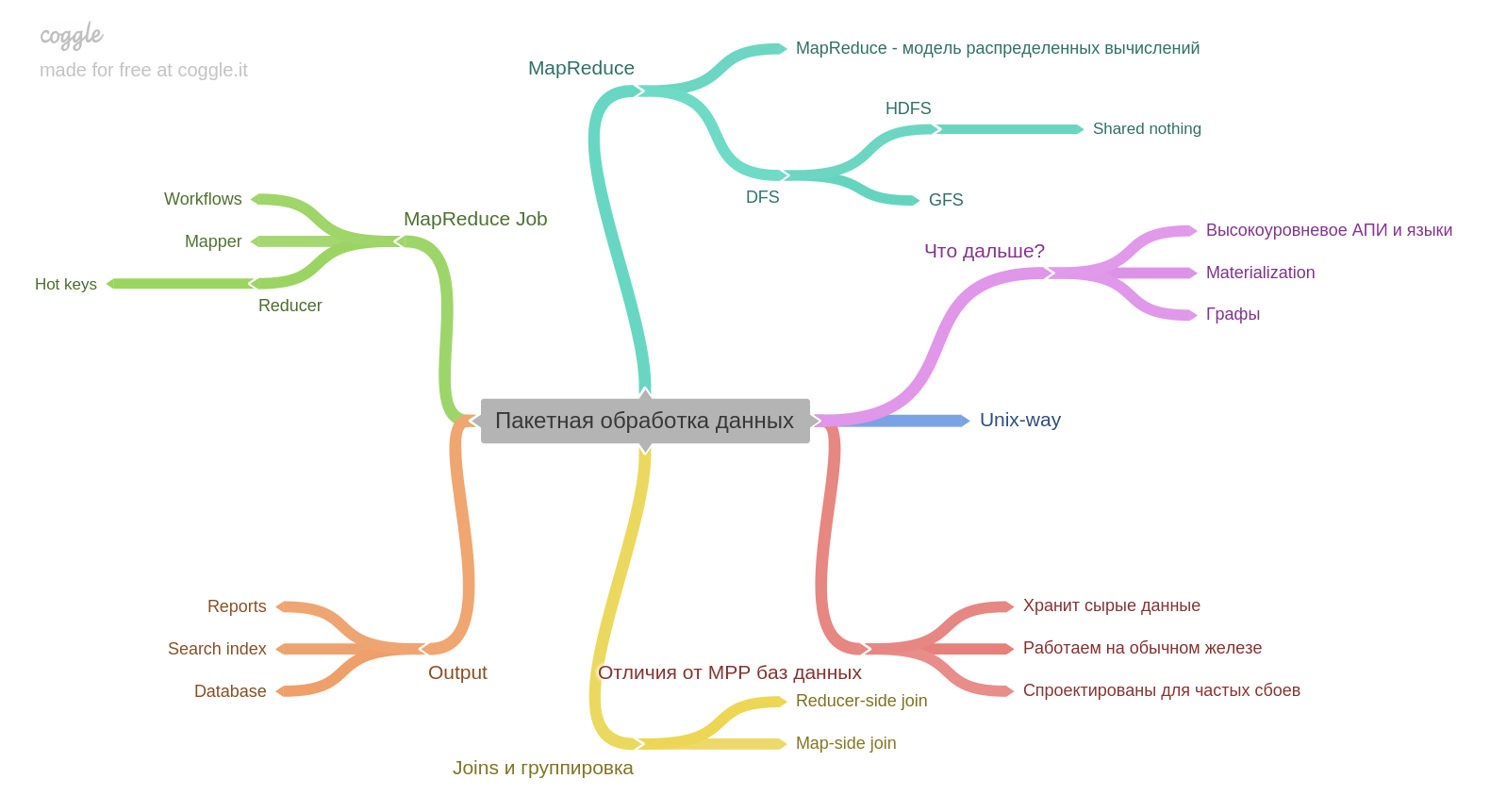
إذا كانت لديك خبرة مع Hadoop أو MapReduce ، ربما ستتعلم القليل الجديد. لكني لم أعمل وكان ذلك مثيرا للاهتمام. نقطة مهمة بالنسبة لي - نتيجة المعالجة المجمعة في حد ذاتها يمكن أن تصبح الأساس لقاعدة بيانات أخرى.
الفصل 11. تدفق معالجة البيانات.
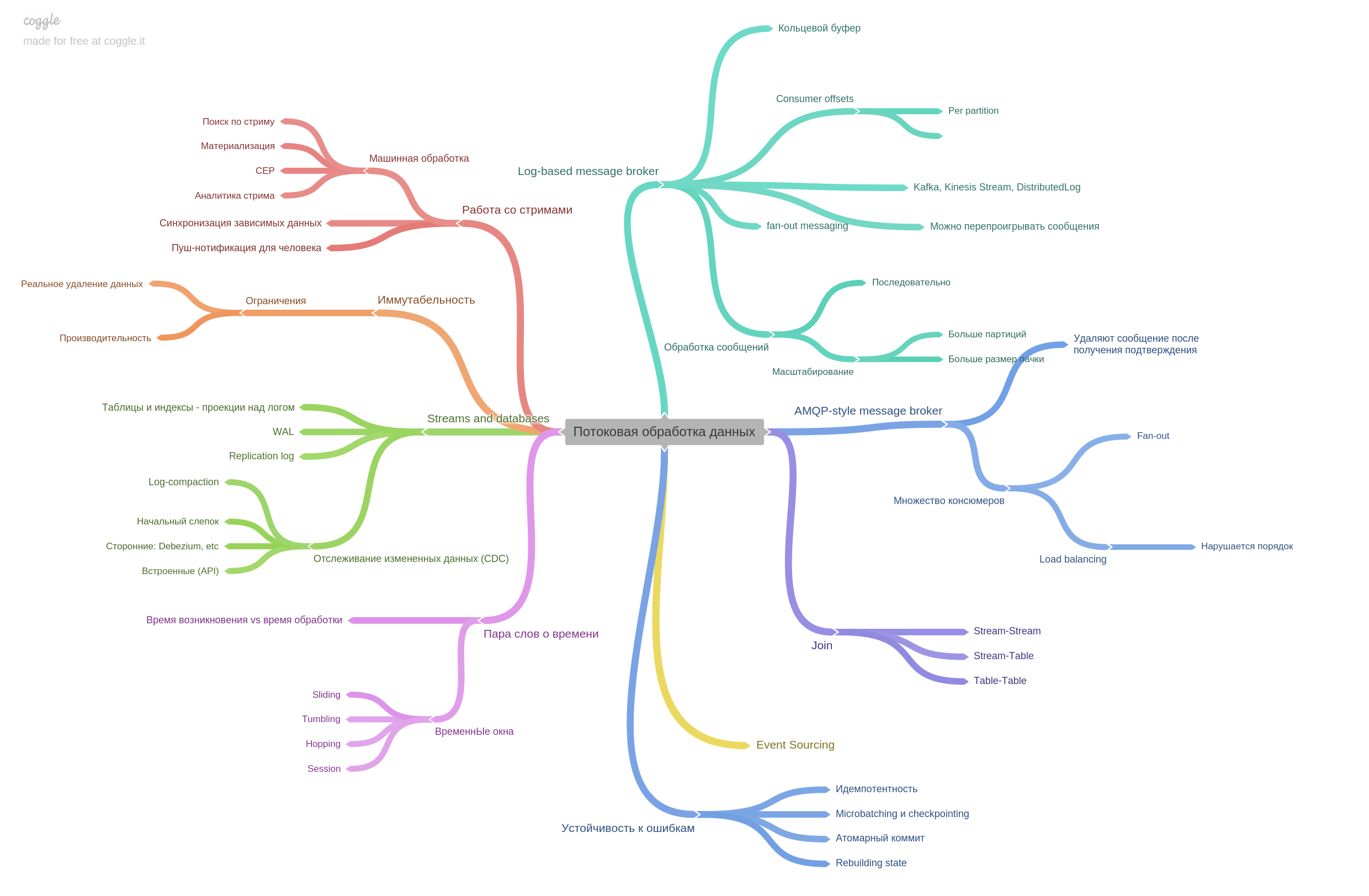
يتم وصف وسطاء الرسائل وكيف يختلف نمط AMPQ عن القائم على السجل. في الواقع ، يحتوي الفصل على الكثير من المعلومات الأخرى. كان من الممتع جدا القراءة.
الفصل الأخير عن المستقبل. ما يمكن توقعه ، وما هي أفكار الباحثين والمهندسين المشغولين بالفعل.
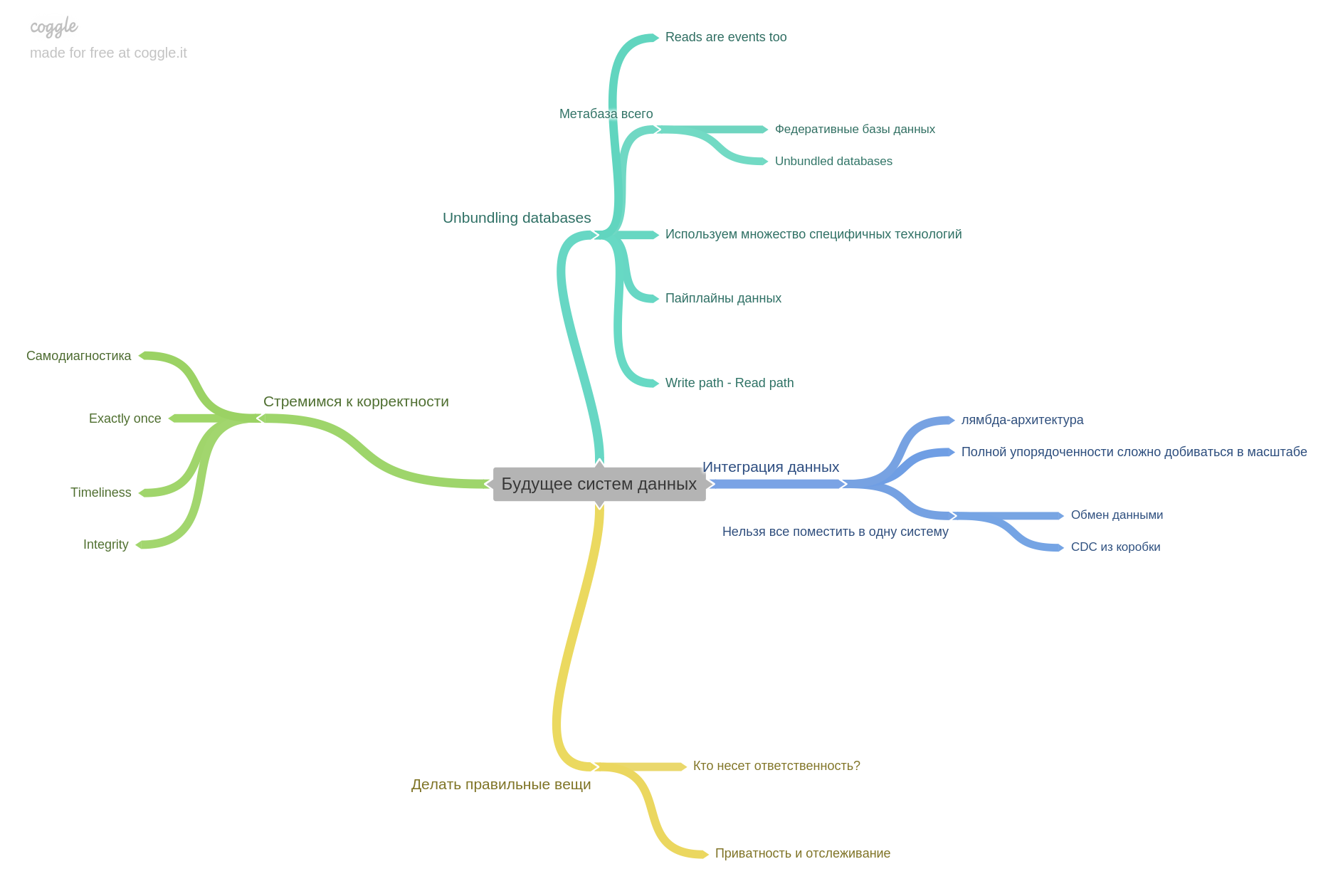
بهذا نختتم مراجعتي. من المهم أن نفهم أنني قمت بعمل جزء فقط من الأطروحات لكل فصل. يحتوي الكتاب على محتوى كثيف لدرجة أنه لا يمكن اختصاره لفترة وجيزة ، ولكن إعادة سرده بالكامل.
أنا شخصياً أعتقد أن هذا الكتاب هو أفضل تقنية في السنوات القليلة الماضية. أوصي بشدة بقراءته. وليس مجرد قراءة ، ولكن العمل بجد. اتبع الروابط من قائمة المراجع ، العب مع DBMSs حقيقية.
بعد قراءة هذا الكتاب ، يمكنك بسهولة الإجابة على العديد من الأسئلة في مقابلة لقاعدة البيانات الفنية. لكن هذه ليست النقطة. ستصبح أكثر برودة كمطور ، وستعرف الهيكل الداخلي ونقاط القوة والضعف لقواعد البيانات المختلفة وتفكر في مشاكل الأنظمة الموزعة.
أنا مستعد لمناقشة كل من الكتاب نفسه وممارستنا للقراءة معا.
اقرأ الكتب!