مرحبا بالجميع!
اليوم سأخبرك كيف ننظر في
hh.ru في الإحصائيات اليدوية للتجارب. سنرى من أين تأتي البيانات ، وكيف نعالجها ، والمزالق التي نواجهها. في هذه المقالة سوف أشارك في بنية ونهج مشتركين ، سيكون هناك حد أدنى من النصوص البرمجية الحقيقية والتعليمات البرمجية. الجمهور الرئيسي هو محللون مبتدئون مهتمون ببنية البنية التحتية لتحليل البيانات في hh.ru. إذا كان هذا الموضوع مثيرًا للاهتمام - اكتب في التعليقات ، فيمكننا الخوض في الكود في المقالات التالية.
يمكنك أن تقرأ عن كيفية مراعاة المقاييس التلقائية لتجارب A / B في مقالتنا
الأخرى .

ما البيانات التي نحللها ومن أين أتوا
نقوم بتحليل سجلات الوصول وأي سجلات مخصصة نكتبها بأنفسنا.
95.108.213.12 - - [13 / أغسطس / 2018: 04: 00: 02 +0300] 200 "GET / صاحب العمل / 2574971 HTTP / 1.1" 12012 "-" "Mozilla / 5.0 (متوافق ؛ YandexBot / 3.0 ؛ + http: / /yandex.com/bots) "" - "" gardabani.headhunter.ge "" 0.063 "-" "1534122002.858" - "" 192.168.2.38:1500 "" [0.064] "{15341220027959c8c01c51a6e01b682f} 200 https 1 -" - "- - [35827] [0.000 0]
178.23.230.16 - - [13 / أغسطس / 2018: 04: 00: 02 +0300] 200 "GET / vacancy / 24266672 HTTP / 1.1" 24229 " hh.ru/vacancy/24007186؟query=bmw " "Mozilla / 5.0 ( Macintosh ؛ Intel Mac OS X 10_10_5) AppleWebKit / 603.3.8 (KHTML ، مثل Gecko) الإصدار / 10.1.2 Safari / 603.3.8 "-" "hh.ru" "0.210" "last_visit = 1534111115966 :: 1534121915966 ؛ hhrole = مجهول ؛ المناطق = 1 ؛ tmr_detect = 0٪ 7C1534121918520 ؛ total_searches = 3 ؛ unique_banner_user = 1534121429.273825242076558 "" 1534122002.859 "" - "" 192.168.2.239:1500 "" [0.208] "{1534122002649b7eef2e901d8c9c0469} 200 https 1 -" - "- - [35927] [0.001 0]
في هندستنا ، تقوم كل خدمة بكتابة السجلات محليًا ، ومن ثم من خلال سجلات خادم العميل المكتوبة ذاتيًا (بما في ذلك سجلات الوصول nginx) التي يتم جمعها في مستودع مركزي (فيما يلي تسجيل الدخول). يستطيع المطورون الوصول إلى هذا الجهاز ويمكنهم تسجيل السجلات يدويًا إذا لزم الأمر. ولكن كيف يمكن ، في وقت معقول ، أن تلتهم عدة مئات من الجيجابايت من السجلات؟ بالطبع ، صبهم في hadoop!
من أين تأتي البيانات في hadoop؟
لا يقوم Hadoop بتخزين سجلات الخدمة فحسب ، بل يقوم أيضًا بتحميل قاعدة بيانات المنتجات. كل يوم في hadoop نقوم بتحميل بعض الجداول المطلوبة للتحليلات.
تدخل سجلات الخدمة في hadoop بثلاث طرق.
- الطريق إلى الجبين - يتم إطلاق cron من تخزين السجل في الليل ، ويقوم rsync بتحميل السجلات الأولية إلى hdfs.
- الطريقة عصرية - يتم سكب السجلات من الخدمات ليس فقط في التخزين المشترك ، ولكن أيضًا في الكافكا ، حيث يقرأها التدفق ، ويقوم بمعالجة مسبقة ويحفظها في محركات الأقراص الثابتة.
- المسار قديم - في الأيام التي سبقت كافكا ، كتبنا خدمتنا الخاصة ، التي تقرأ السجلات الأولية من التخزين ، وتحولها من المعالجة المسبقة ، وتحملها على الأقراص الصلبة.
دعونا ننظر في كل نهج بمزيد من التفصيل.
مسار الجبين
يدير Cron نص باش عادي.
كما نتذكر ، في مستودع السجلات ، جميع السجلات في شكل ملفات عادية ، هيكل المجلد هو تقريبا ما يلي: /logging/java/2018/08/10/{service_nameasure/*.log
تقوم Hadoop بتخزين ملفاتها في نفس بنية المجلد تقريبًا hdfs-raw / banner-الإصدارات / السنة = 2018 / الشهر = 08 / اليوم = 10
سنة ، شهر ، يوم نستخدمه كأقسام.
وبالتالي ، نحتاج فقط إلى تشكيل المسارات الصحيحة (السطور 3-4) ، ثم تحديد جميع السجلات اللازمة (السطر 6) واستخدام rsync لملئها في hadoop (السطر 8).
مزايا هذا النهج:- التطور السريع
- كل شيء شفاف وواضح.
السلبيات:طريقة عصرية
نظرًا لأننا نقوم بتحميل السجلات إلى المستودع باستخدام نص مكتوب ذاتيًا ، فقد كان من المنطقي أن نفشل في القدرة على تحميلها ليس فقط إلى الخادم ، ولكن أيضًا إلى kafka.
الايجابيات- السجلات على الإنترنت (تظهر سجلات hadoop عند ملء كافكا)
- يمكنك القيام بمعالجة مسبقة
- إنه يحمل الحمل جيدًا ويمكنك تحميل سجلات كبيرة
سلبيات- إعداد أكثر صعوبة
- علي أن أكتب الرمز
- المزيد من أجزاء عملية الصب
- رصد وتحليل الحوادث أكثر تعقيدا
الطريقة القديمة
وهي تختلف عن الموضة فقط في حالة عدم وجود كافكا. لذلك ، فإنه يرث كل العيوب وبعض مزايا النهج السابق فقط. تقوم خدمة منفصلة (ustats-uploader) في جافا بقراءة الملفات الضرورية بشكل دوري ، ومعالجتها مسبقًا وتحميلها إلى hadoop.
الايجابيات- يمكنك القيام بمعالجة مسبقة
سلبيات- إعداد أكثر صعوبة
- علي أن أكتب الرمز
وهكذا دخلت البيانات في hadoop وجاهزة للتحليل. دعونا نتوقف قليلاً ونتذكر ما هو hadoop ولماذا يمكن استهلاك مئات الجيجابايت عليه أسرع بكثير من grep العادي.
Hadoop
Hadoop هو مستودع بيانات موزع. لا تقع البيانات على أي خادم منفصل ، ولكن يتم توزيعها بين عدة أجهزة ، ويتم تخزينها أيضًا ليس في حالة واحدة ، ولكن في عدة حالات - تم ذلك لضمان الموثوقية. يكمن أساس سرعة معالجة البيانات في تغيير النهج مقارنة بقواعد البيانات التقليدية.
في حالة وجود قاعدة بيانات منتظمة ، نقوم باستخراج البيانات منها وإرسالها إلى العميل ، الذي يقوم بنوع من التحليل ويعيد النتيجة إلى المحلل. وبالتالي ، من أجل الحساب بشكل أسرع ، نحتاج إلى العديد من العملاء وموازنة الطلبات (على سبيل المثال ، لتقسيم البيانات حسب الأشهر - ويمكن لكل عميل قراءة البيانات لشهره).
في hadoop ، العكس هو الصحيح. نرسل الرمز (بالضبط ما نريد حسابه) إلى البيانات ، ويتم تنفيذ هذا الرمز على الكتلة. كما نعلم ، تقع البيانات على العديد من الأجهزة ، لذلك ينفذ كل جهاز فقط التعليمات البرمجية على بياناته ويعيد النتيجة إلى العميل.
ربما سمع الكثير عن
تقليل الخريطة ، ولكن كتابة التعليمات البرمجية للتحليلات ليست مريحة وسريعة للغاية ، بينما الكتابة في SQL أبسط بكثير. لذلك ، ظهرت خدمات يمكنها تحويل SQL إلى تقليص الخريطة بشفافية للمستخدم ، وقد لا يشك المحلل في كيفية النظر في طلبه بالفعل.
في hh.ru نستخدم الخلية والمعزوفة لهذا الغرض. كان Hive هو الأول ، لكننا نتحرك تدريجيًا إلى المعزوفة ، لأنها أسرع بكثير لطلباتنا. كواجهة مستخدم رسومية ، نستخدم هوى وزيبلين.
إنه أكثر ملاءمة بالنسبة لي للنظر في التحليلات في python في jupyter ، وهذا يسمح لنا بقراءتها بنقرة واحدة والحصول على جداول excel المنسقة بشكل صحيح عند الإخراج ، مما يوفر الكثير من الوقت. اكتب في التعليقات ، هذا الموضوع يرسم إلى مقال منفصل.
دعونا نعود إلى التحليلات نفسها.
كيف نفهم ما نريد أن نفكر فيه؟
جاء مدير المنتج بمهمة حساب نتائج التجربة
نرسل رسالة إخبارية بالبريد الإلكتروني نرسل فيها الوظائف الشاغرة المناسبة لمقدم الطلب (هل يحب الجميع مثل هذه المراسلات؟). قررنا تغيير تصميم الرسالة قليلاً ونريد أن نفهم ما إذا كانت أفضل. لهذا سننظر في:
- عدد التحولات إلى الشواغر من الرسالة ؛
- ملاحظات بعد الانتقال
اسمحوا لي أن أذكرك بأن كل ما لدينا هو سجل الوصول وقاعدة البيانات. نحن بحاجة إلى صياغة مقاييسنا من حيث نقرات الارتباط.
عدد التحولات إلى شاغر من حرف
الانتقال هو طلب GET إلى
hh.ru/vacancy/26646861 . لفهم مصدر الانتقال ، نضيف علامات utm من النموذج؟ Utm_source = email_campaign_123. بالنسبة لطلبات GET في سجل الوصول ، ستكون هناك معلومات حول المعلمات ، ويمكننا تصفية الانتقالات فقط من قائمتنا البريدية.
عدد الاستجابات بعد النقل
هنا يمكننا ببساطة حساب عدد الردود على الوظائف الشاغرة من النشرة الإخبارية ، ولكن بعد ذلك ستكون الإحصاءات غير صحيحة ، لأن الإجابات قد تتأثر بشيء آخر ، باستثناء رسالتنا ، على سبيل المثال ، تم شراء إعلان في ClickMe لشغل وظيفة شاغرة ، وبالتالي عدد الردود نمت بشكل كبير.
لدينا خياران لكيفية صياغة عدد الردود:
- الاستجابة هي POST على hh.ru/applicant/vacancy_response/popup؟vacancy_id=26646861 ، والتي تحتوي على hh.ru/vacancy/26646861؟utm_source=email_campaign_123 .
- إن الفروق الدقيقة في هذا النهج هي أنه إذا تحول المستخدم إلى شاغر ، ثم تجول في الموقع قليلاً ثم استجاب لشغور ، فلن نحسبه.
- يمكننا أن نتذكر هوية المستخدم الذي انتقل إلى hh.ru/vacancy/26646861 ، وحساب عدد المراجعات للشغور خلال اليوم بناءً على قاعدة البيانات.
يتم تحديد اختيار النهج وفقًا لمتطلبات العمل ، وعادة ما يكون الخيار الأول كافياً ، ولكن كل هذا يتوقف على ما ينتظره مدير المنتج.
المخاطر التي قد تحدث
- ليست كل البيانات في hadoop ، تحتاج إلى إضافة بيانات من قاعدة بيانات المنتج. على سبيل المثال ، في السجلات عادة ما يكون معرف فقط ، وإذا كنت بحاجة إلى اسم - فهو موجود في قاعدة البيانات. في بعض الأحيان تحتاج إلى البحث عن مستخدم عن طريق استئناف_السعر ، ويتم تخزين هذا أيضًا في قاعدة البيانات. للقيام بذلك ، نقوم بإلغاء تحميل جزء من قاعدة البيانات في hadoop بحيث يكون الانضمام أبسط.
- قد تكون البيانات منحنيات. هذه عمومًا كارثة على hadoop وطريقة تحميل البيانات فيه. بناءً على البيانات ، يمكن أن تكون القيمة الفارغة فارغة ، لا شيء ، لا شيء ، سلسلة فارغة ، إلخ. يجب أن تكون حذرًا في كل حالة ، لأن البيانات مختلفة حقًا ، ويتم تحميلها بطرق مختلفة ولأغراض مختلفة.
- عد طويل لكامل الفترة. على سبيل المثال ، نحتاج إلى حساب انتقالاتنا واستجاباتنا للشهر. هذا هو ما يقرب من 3 تيرابايت من السجلات. حتى hadoop سيستغرق هذا بعض الوقت. عادة ما تكون كتابة طلب عمل 100 ٪ في المرة الأولى صعبة للغاية ، لذلك نكتبه عن طريق التجربة والخطأ. كل وقت للانتظار 20 دقيقة هو وقت طويل جداً. طرق الحل:
- تصحيح الطلب على السجلات في يوم واحد. نظرًا لأننا قسمنا البيانات في hadoop ، فمن السهل جدًا حساب شيء ما لمدة يوم واحد من السجلات.
- قم بتحميل السجلات الضرورية إلى الجدول المؤقت. كقاعدة ، نتفهم عناوين URL التي نهتم بها ، ويمكننا إنشاء جدول مؤقت للسجلات من عناوين URL هذه.
أنا شخصياً ، الخيار الأول أكثر ملاءمة بالنسبة لي ، لكن في بعض الأحيان ، أحتاج إلى إنشاء جدول مؤقت ، يعتمد على الموقف. - التشوهات في المقاييس النهائية
- من الأفضل تصفية السجلات. تحتاج إلى الانتباه ، على سبيل المثال ، إلى رمز الاستجابة ، وإعادة التوجيه ، وما إلى ذلك. بيانات أقل وأفضل ، ولكن أكثر دقة ، مما أنت متأكد منه.
- أقل عدد ممكن من الخطوات الوسيطة في المقياس. على سبيل المثال ، التحول إلى وظيفة شاغرة هو خطوة واحدة (طلب GET لـ / وظيفة شاغرة / 123). الجواب اثنان (الانتقال إلى الوظيفة الشاغرة + الوظيفة). كلما كانت السلسلة أقصر ، كانت الأخطاء أقل وأكثر دقة المقياس. يحدث في بعض الأحيان أن يتم فقدان البيانات بين التحولات ويستحيل حساب شيء ما بشكل عام. لحل هذه المشكلة ، نحتاج إلى التفكير في ما سنفكر فيه وكيف قبل تطوير التجربة. إن سجلك المنفصل للأحداث الضرورية يساعدك كثيرًا. يمكننا تصوير الأحداث الضرورية ، وبالتالي ستكون سلسلة الأحداث أكثر دقة ، والعد أسهل.
- يمكن أن تولد البوتات مجموعة من التحولات. يجب أن تفهم إلى أين يمكن أن تصل برامج التتبُّع (على سبيل المثال ، في الصفحات التي تتطلب التفويض ، لا يجب أن تكون) ، وتصفية هذه البيانات.
- المطبات الكبيرة - على سبيل المثال ، في إحدى المجموعات ، يمكن أن يكون هناك مقدم طلب واحد ، والذي يولد 50 ٪ من جميع الردود. سيكون هناك عدد كبير من الإحصاءات ، كما يجب تصفية هذه البيانات.
- من الصعب صياغة ما يجب مراعاته من حيث سجل الوصول. وهذا يساعد على معرفة قاعدة الكود والخبرة وأدوات تطوير Chrome. نقرأ وصف المقياس من المنتج ونكرره بأيدينا على الموقع ونرى ما هي التحولات التي يتم إنشاؤها.
أخيرًا ، دعنا نتحدث عن كيف يجب أن تبدو نتيجة الحسابات.
نتيجة الحساب
في مثالنا ، هناك مجموعتان ومقاييس تشكلان قمعًا.
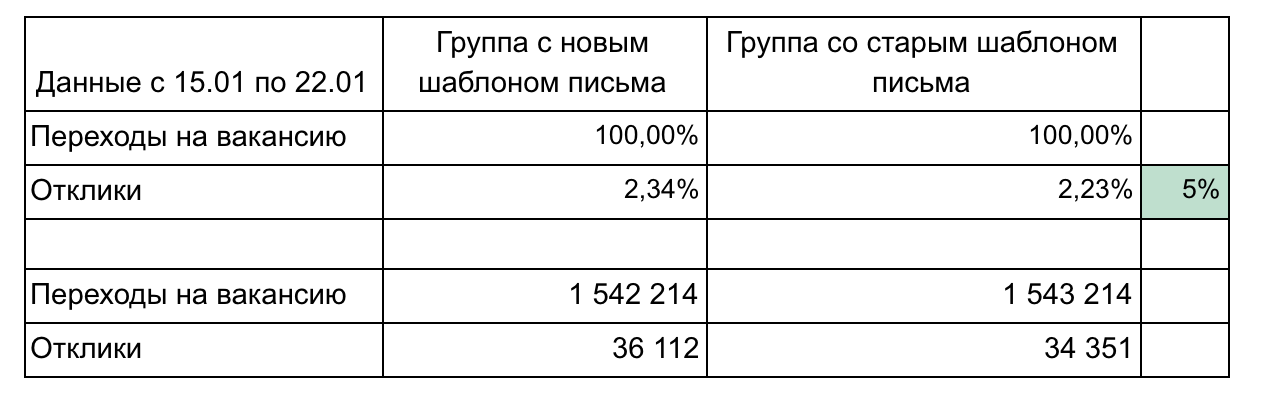
توصيات للإبلاغ عن النتائج:
- لا تفرط في تحميل الأجزاء إلا إذا لزم الأمر. البساطة والأصغر أفضل (على سبيل المثال ، يمكننا هنا عرض كل وظيفة شاغرة بشكل منفصل أو النقرات حسب اليوم). ركز على شيء واحد.
- قد تكون التفاصيل مطلوبة أثناء نتائج العرض التوضيحي ، لذا فكر في الأسئلة التي قد تطرحها وأعد التفاصيل. (في مثالنا ، يمكن أن تكون التفاصيل وفقًا لسرعة الانتقال بعد إرسال البريد الإلكتروني - يوم واحد ، 3 أيام ، أسبوع ، تجميع الشواغر حسب المجال المهني)
- تذكر الأهمية الإحصائية. على سبيل المثال ، التغيير بنسبة 1٪ مع 100 نقرة و 15 نقرة غير مهم ويمكن أن يكون عشوائيًا. استخدم الآلات الحاسبة
- أتمتة قدر الإمكان ، لأنه سيكون عليك العد عدة مرات. عادة في منتصف التجربة ، يريد المرء بالفعل أن يفهم كيف تسير الأمور. بعد التجربة ، قد تطرح أسئلة وسيكون عليك توضيح شيء ما. وبالتالي ، سيكون من الضروري العد 3-4 مرات ، وإذا كانت كل عملية حسابية عبارة عن سلسلة من 10 استعلامات ثم النسخ اليدوي إلى التفوق ، فسيؤذي ويقضي الكثير من الوقت. تعلم الثعبان ، سيوفر الكثير من الوقت.
- استخدم تمثيل رسومي للنتائج عند الضرورة. تسمح لك أدوات الخلية والخلية المدمجة ببناء رسوم بيانية بسيطة خارج الصندوق.
من الضروري مراعاة المقاييس المختلفة في كثير من الأحيان ، لأننا نصدر كل مهمة تقريبًا كجزء من تجربة A / B. لا يوجد شيء معقد في الحسابات ، بعد 2-3 تجارب يأتي الفهم لكيفية القيام بذلك. تذكر أن سجلات الوصول تخزن الكثير من المعلومات المفيدة التي يمكن أن توفر أموال الشركات ، وتساعدك على الترويج لفكرتك وإثبات أي من خيارات التغيير أفضل. الشيء الرئيسي هو أن تكون قادرًا على الحصول على هذه المعلومات.