بدأنا
في دراسة مجموعات التحكم (Cgroups) في Red Hat Enterprise Linux 7 - وهي آلية على مستوى النواة تسمح لك بالتحكم في استخدام موارد النظام ، وفحصت باختصار الأسس النظرية وانتقل الآن إلى ممارسة إدارة وحدة المعالجة المركزية ، والذاكرة ، وموارد الإدخال / الإخراج.
ومع ذلك ، قبل تغيير أي شيء ، من المفيد دائمًا معرفة كيفية ترتيب كل شيء الآن.
هناك أداتان يمكنك من خلالهما رؤية حالة المجموعات النشطة في النظام. أولاً ، هذا هو systemd-cgls - وهو أمر يعرض قائمة تشبه مجموعات المجموعات والعمليات الجارية. يبدو ناتجها كالتالي:
هنا نرى مجموعات المستوى الأعلى: user.slice و system.slice. ليس لدينا أجهزة افتراضية ، وبالتالي ، تحت التحميل ، تتلقى هذه المجموعات ذات المستوى الأعلى 50٪ من موارد وحدة المعالجة المركزية (لأن شريحة الجهاز غير نشطة). هناك شريحتين فرعيتين في user.slice: user-1000.slice و user-0.llice. يتم تحديد شرائح المستخدم بواسطة User ID (UID) ، لذلك قد يكون من الصعب تحديد المالك ، باستثناء العمليات الجارية. في حالتنا ، تُظهر جلسات ssh أن المستخدم 1000 أكثر ثراءً ، والمستخدم 0 هو الجذر ، على التوالي.
الأمر الثاني الذي سنستخدمه هو systemd-cgtop. يظهر صورة لاستخدام الموارد في الوقت الحقيقي (يتم أيضًا إخراج ناتج systemd-cgls ، بالمناسبة ، في الوقت الحقيقي). على الشاشة ، يبدو شيء من هذا القبيل:
توجد مشكلة واحدة في systemd-cgtop - فهي تعرض إحصاءات فقط لتلك الخدمات والشرائح التي تم تمكين محاسبة استخدام الموارد لها. يتم تمكين المحاسبة عن طريق إنشاء ملفات conf في ملف الدلائل الفرعية المناسبة في / etc / systemd / system. على سبيل المثال ، تتيح القائمة المنسدلة في لقطة الشاشة أدناه استخدام وحدة المعالجة المركزية والذاكرة لخدمة sshd. للقيام بذلك بنفسك ، ما عليك سوى إنشاء نفس القائمة المنسدلة في محرر نصوص. بالإضافة إلى ذلك ، يمكن أيضًا تمكين المحاسبة باستخدام sshd.service CPUAccounting = true الأمر MemoryAccounting = true.
بعد إنشاء القائمة المنسدلة ، يجب عليك إدخال الأمر systemctl daemon-reload ، بالإضافة إلى الأمر systemctl إعادة التشغيل <service_name> للخدمة المقابلة. ونتيجة لذلك ، سترى إحصاءات حول استخدام الموارد ، ولكن هذا سيخلق عبئًا إضافيًا ، حيث سيتم إنفاق الموارد أيضًا على المحاسبة. لذلك ، يجب تضمين المحاسبة بعناية وفقط لتلك الخدمات والمجموعات التي يجب مراقبتها بهذه الطريقة. ومع ذلك ، غالبًا بدلاً من systemd-cgtop ، يمكنك القيام بالأوامر العلوية أو أوامر iotop.
تغيير الكرات CPU للمتعة ومفيدة
لنرى الآن كيف يؤثر التغيير في كرة المعالج (مشاركات وحدة المعالجة المركزية) على الأداء. على سبيل المثال ، سيكون لدينا مستخدمان غير مميزين وخدمة نظام واحدة. المستخدم الذي لديه تسجيل دخول mrichter لديه UID من 1000 ، والتي يمكن التحقق منها باستخدام ملف / etc / passwd.
هذا أمر مهم لأن شرائح المستخدم يتم تسميتها بواسطة UID وليس باسم الحساب.
الآن ، دعنا نذهب إلى الدليل المنسدل ونرى ما إذا كان هناك أي شيء بالفعل لشريحته.
لا ، لا يوجد شيء. على الرغم من وجود شيء آخر - ألق نظرة على الأشياء المتعلقة بخدمة foo.service:
إذا كنت معتادًا على ملفات وحدة systemd ، فسترى هنا ملف وحدة عاديًا تمامًا يقوم بتشغيل الأمر / usr / bin / sha1sum / dev / zero كخدمة (بمعنى آخر ، برنامج خفي). بالنسبة لنا ، ما يهم هو أن foo سيستغرق حرفيا جميع موارد المعالج التي سيسمح له النظام باستخدامها. بالإضافة إلى ذلك ، لدينا هنا قائمة منسدلة لضبط قيمة foo لخدمة foo على 2048. بشكل افتراضي ، كما تتذكر ، يتم استخدامها مع القيمة 1024 ، لذا تحت التحميل foo سيحصل على حصة مزدوجة من موارد وحدة المعالجة المركزية داخل system.slice ، شريحة الأصل الرئيسية (بما أن foo هي خدمة).
الآن قم بتشغيل foo من خلال systemctl ونرى ما يظهر لنا الأمر العلوي:
نظرًا لعدم وجود أي أشياء عمل في النظام عمليًا ، تستهلك خدمة foo (pid 2848) تقريبًا كل وقت المعالج لوحدة معالجة مركزية واحدة.
الآن دعونا نقدم mrichter في معادلة المستخدم. أولاً ، قطعناه كرة CPU تصل إلى 256 ، ثم قام بتسجيل الدخول وبدء foo.exe ، وبعبارة أخرى ، نفس البرنامج ، ولكن كعملية مستخدم.
لذلك أطلق mrichter فو. وإليك ما يظهره الأمر العلوي الآن:
غريب ، هاه؟ يبدو أن المستخدم المستخدم يحصل على حوالي 10 في المائة من وقت المعالج ، نظرًا لأنه لديه = 256 كرة ، و foo.service لديه ما يصل إلى 2048 ، أليس كذلك؟
الآن نقدم دورف في المعادلة. هذا هو مستخدم عادي آخر مع كرة CPU قياسية تساوي 1024. سيعمل أيضًا foo ، ومرة أخرى سنرى كيف سيتغير توزيع وقت المعالج.
dorf هو مستخدم في المدرسة القديمة ، يبدأ العملية فقط ، دون أي نصوص ذكية أو أي شيء آخر. ومرة أخرى ننظر إلى ناتج القمة:
لذا ... دعونا نلقي نظرة على شجرة المجموعات ومحاولة معرفة ما هو:
إذا كنت تتذكر ، فعادة ما يوجد في النظام ثلاث مجموعات cgroup ذات المستوى الأعلى: النظام والمستخدم والجهاز. نظرًا لعدم وجود أجهزة افتراضية في مثالنا ، تبقى شرائح النظام والمستخدم فقط. كل واحد منهم يحتوي على كرة CPU تبلغ 1024 ، وبالتالي تحت التحميل فإنه يتلقى نصف وقت المعالج. نظرًا لأن foo.service تعيش في النظام ، ولا يوجد أي مرشحين آخرين لوقت وحدة المعالجة المركزية في هذه الشريحة ، فإن foo.service تتلقى 50٪ من موارد وحدة المعالجة المركزية.
علاوة على ذلك ، يعيش المستخدمون في شريحة المستخدم. الكرة الأولى هي 1024 ، والثانية - 256. وبالتالي ، فإن dorf يحصل على وقت معالج أربع مرات أكثر من mrichter. الآن دعونا نرى ما يظهر أعلى: foo.service - 50٪ ، dorf - 40٪ ، mrichter - 10٪.
عند ترجمة ذلك إلى لغة حالة استخدام ، يمكننا القول أن dorf له أولوية أعلى. وفقًا لذلك ، يتم تكوين مجموعات cgroups بحيث يقوم المستخدم باختصار الموارد للوقت الذي يحتاج فيه إلى dorf'u. في الواقع ، بعد كل شيء ، بينما كان mrichter في النظام وحده ، حصل على 50 ٪ من وقت المعالج ، لأنه في شريحة المستخدم لم يتنافس أي شخص آخر على موارد وحدة المعالجة المركزية.
في الواقع ، كرات CPU هي طريقة لتوفير "حد أدنى مضمون" معين من وقت المعالج ، حتى بالنسبة للمستخدمين والخدمات ذات الأولوية الأقل.
بالإضافة إلى ذلك ، لدينا طريقة لتعيين حصة ثابتة لموارد وحدة المعالجة المركزية ، وهو حد معين للأرقام المطلقة. سنفعل ذلك من أجل المستخدم ونرى كيف يتغير توزيع الموارد.
الآن دعنا نقتل مهام المستخدم dorf ، وإليك ما يحدث:
بالنسبة لـ mrichter ، فإن الحد الأقصى لوحدة المعالجة المركزية هو 5٪ ، لذا فإن foo.service تحصل على بقية وقت المعالج.
استمر في التسلط ووقف foo.service:
ما نراه هنا: يمتلك mrichter 5٪ من وقت المعالج ، والباقي 95٪ من النظام خاملاً. السخرية الرسمية ، نعم.
في الواقع ، يسمح لك هذا النهج بتهدئة الخدمات أو التطبيقات التي ترغب في التأرجح فجأة وسحب جميع موارد المعالج لأنفسهم على حساب العمليات الأخرى.
لذا ، تعلمنا كيفية التحكم في الوضع الحالي باستخدام مجموعات cgroups. الآن نحفر أعمق قليلاً ونرى كيف يتم تنفيذ cgroup على مستوى نظام الملفات الظاهري.
يقع الدليل الجذر لجميع مجموعات cgroups قيد التشغيل في / sys / fs / cgroup. عندما يقوم النظام بالتمهيد ، يتم ملؤه عند بدء تشغيل الخدمات والمهام الأخرى. عند بدء الخدمات وإيقافها ، تظهر الأدلة الفرعية وتختفي.
في لقطة الشاشة أدناه ، انتقلنا إلى دليل فرعي لوحدة تحكم وحدة المعالجة المركزية ، وبالتحديد في شريحة النظام. كما ترون ، فإن الدليل الفرعي لـ foo ليس هنا بعد. قم بتشغيل foo وتحقق من شيئين ، وهما PID وكرة CPU الحالية:
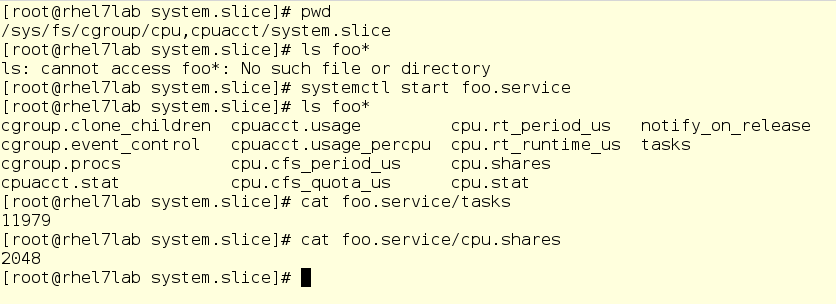
تحذير هام: هنا يمكنك تغيير القيم على الطاير. نعم ، من الناحية النظرية تبدو رائعة (وفي الواقع أيضًا) ، لكنها يمكن أن تتحول إلى فوضى كبيرة. لذلك ، قبل تغيير أي شيء ، قم بوزن كل شيء بعناية ولا تلعب أبدًا على خوادم المعارك. ولكن على أي حال ، يعد نظام الملفات الظاهري شيئًا يتم التعمق فيه عندما تتعلم كيفية عمل المجموعات.