تم تقديم الإصدار الأول من CTP لـ SQL Server 2019 في 24 سبتمبر ، واسمحوا لي أن أقول أنه مليء بجميع أنواع التحسينات والميزات الجديدة (يمكن العثور على العديد منها في نموذج المعاينة في قاعدة بيانات Azure SQL). لقد أتيحت لي فرصة استثنائية للتعرف على هذا قبل ذلك بقليل ، مما سمح لي بتوسيع فهمي للتغييرات ، حتى بشكل سطحي. يمكنك أيضًا قراءة
أحدث المنشورات من فريق SQL Server والوثائق المحدثة .
دون الخوض في التفاصيل ، سأناقش ميزات النواة الجديدة التالية: الأداء واستكشاف الأخطاء وإصلاحها والأمان والتوافر والتطوير. في الوقت الحالي ، لدي تفاصيل أكثر بقليل من غيرها ، وبعضها مستعد بالفعل للنشر. سأعود إلى هذا القسم ، وكذلك إلى العديد من المقالات والوثائق الأخرى ، ونشرها. أسارع بإبلاغك أن هذه ليست مراجعة شاملة ، ولكنها جزء فقط من الوظيفة التي تمكنت من "لمسها" ، حتى CTP 2.0. لا يزال هناك الكثير للحديث عنه.
الأداء
متغيرات الجدول: مبنى الخطة المؤجلة
لم يتم تعيين سمعة جيدة جدًا لمتغيرات الجدول ، ومعظمها في مجال تقدير التكلفة. بشكل افتراضي ، يفترض SQL Server أن متغير الجدول يمكن أن يحتوي على صف واحد فقط ، مما يؤدي في بعض الأحيان إلى اختيار غير ملائم للخطة عندما يحتوي المتغير على صفوف أكثر من مرة. عادةً ما يتم استخدام الخيار (RECOMPILE) كحل بديل ، ولكن هذا يتطلب تغييرات في الكود وهو أمر مهدر ، فيما يتعلق بالموارد ، لإجراء إعادة البناء في كل مرة ، في حين أن عدد الأسطر غالبًا ما يكون هو نفسه. لمحاكاة إعادة البناء ، تم تقديم إشارة
التتبع 2453 ، ولكنها تتطلب أيضًا إطلاقًا مع العلم ، وتعمل فقط عند حدوث تغيير كبير في السطور.
عند مستوى التوافق 150 ، يتم تنفيذ البناء المؤجل إذا كانت متغيرات الجدول موجودة ولم يتم بناء خطة الاستعلام حتى يتم تعبئة متغير الجدول مرة واحدة. سيتم تقدير التكلفة بناءً على نتائج الاستخدام الأول لمتغير الجدول ، دون مزيد من التغييرات. هذا هو حل وسط بين إعادة البناء المستمر للحصول على التكلفة الدقيقة ، والغياب التام لإعادة البناء بتكلفة ثابتة 1. إذا ظل عدد الصفوف ثابتًا نسبيًا ، فهذا مؤشر جيد (وحتى أفضل إذا تجاوز العدد 1) ، ولكن قد يكون أقل ربحية إذا هناك اختلاف كبير في عدد الصفوف.
لقد قدمت تحليلاً أعمق في مقالة حديثة
جدولة المتغيرات: تأخر البناء في SQL Server ، وتحدث برنت أوزار أيضًا عن هذا في المقالة
Fast Tabular Variables (ومشاكل تحليل المعلمات الجديدة) .
ملاحظات تخصيص الذاكرة في وضع السلسلة
يحتوي SQL Server 2017 على ملاحظات حول تخصيص الدُفعات ، موصوفة بالتفصيل
هنا . بشكل أساسي ، بالنسبة لأي تخصيص للذاكرة مرتبط بخطة استعلام تتضمن عبارات وضع الدفعة ، سيقوم SQL Server بتقييم الذاكرة المستخدمة بواسطة الاستعلام ومقارنتها بالذاكرة المطلوبة. إذا كانت الذاكرة المطلوبة صغيرة جدًا أو كبيرة جدًا ، مما سيؤدي إلى استنزاف في tempdb أو إهدار للذاكرة ، فسيتم تعديل الذاكرة المخصصة لخطة الاستعلام المقابلة في البداية التالية. سيؤدي هذا السلوك إلى تقليل الحجم المخصص وتوسيع التوافق أو زيادته لتحسين الأداء.
الآن نحصل على نفس السلوك للاستعلامات في وضع السلسلة ، تحت مستوى التوافق 150. إذا تم فرض الاستعلام لدمج البيانات إلى القرص ، فسيتم زيادة الذاكرة المخصصة لعمليات الإطلاق اللاحقة. إذا كان نصف الطلب مطلوبًا عند اكتمال الطلب مما تم تخصيصه ، فسيتم تعديله للأسفل في الطلبات اللاحقة. يصف بريتن أوزار هذا بمزيد من التفصيل في مقالته
تخصيص الذاكرة المشروطة .
وضع الدفعة للتخزين سطرًا تلو الآخر
بدءًا من SQL Server 2012 ، استفاد الاستعلام عن الجداول باستخدام فهارس الأعمدة من تحسين أداء وضع الدُفعة. ترجع تحسينات الأداء إلى معالج استعلام يقوم بإجراء الدفعات بدلاً من معالجة الصفوف. تتم معالجة الخطوط أيضًا بواسطة قلب التخزين في الحزم ، والتي تتجنب عبارات تبادل التزامن. ذكرني بول وايت (
SQL_Kiwi ) أنه إذا كنت تستخدم جدولًا فارغًا مع تخزين العمود لجعل عمليات الدفعة ممكنة ، فسيتم جمع الصفوف المجهزة في حزم بواسطة بيان غير مرئي. ومع ذلك ، يمكن لهذا العكاز أن يلغي أي تحسينات تم تلقيها من المعالجة المجمعة. توجد بعض المعلومات حول هذا في
إجابة Stack Exchange .
عند مستوى التوافق 150 ، سيحدد SQL Server 2019 تلقائيًا وضع الدُفعة كأرض وسط في حالات معينة ، حتى في حالة عدم وجود فهارس أعمدة. قد تعتقد أنه لم لا تقوم فقط بإنشاء فهرس عمود وقبعة؟ أو الاستمرار في استخدام العكاز المذكور أعلاه؟ تم توسيع هذا النهج أيضًا إلى الكائنات التقليدية مع تخزين الصفوف ، لأن فهارس الأعمدة ، لعدة أسباب ، ليست ممكنة دائمًا ، بما في ذلك القيود الوظيفية (على سبيل المثال ، المشغلات) ، والنفقات العامة أثناء عمليات التحديث أو الحذف المحملة بشدة ، ونقص الدعم من الشركات المصنعة الخارجية. ولا يمكن توقع أي شيء جيد من هذا العكاز.
لقد أنشأت جدولًا بسيطًا للغاية يحتوي على 10 ملايين صف وفهرس مجمع في عمود صحيح وأجري هذا الاستعلام:
SELECT sa5, sa2, SUM(i1), SUM(i2), COUNT(*) FROM dbo.FactTable WHERE i1 > 100000 GROUP BY sa5, sa2 ORDER BY sa5, sa2;
تُظهر الخطة بوضوح عمليات البحث عن الفهرس
المجمعة والتوافق ، ولكن ليس كلمة واحدة حول فهرس العمود (كما يظهر
SentryOne Plan Explorer ):
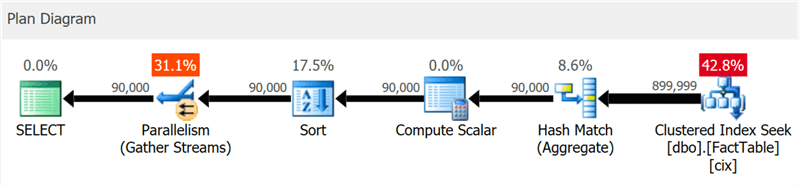
ولكن إذا قمت بالتعمق أكثر قليلاً ، يمكنك أن ترى أنه تم تنفيذ جميع العوامل تقريبًا في وضع الدفعة ، حتى الفرز والحسابات العددية:

يمكنك تعطيل هذه الميزة من خلال البقاء على مستوى توافق أقل عن طريق تغيير تكوين قاعدة البيانات أو باستخدام موجه DISALLOW_BATCH_MODE في الاستعلام:
SELECT … OPTION (USE HINT ('DISALLOW_BATCH_MODE'));
في هذه الحالة ، يظهر عامل تبادل إضافي ، ويتم تنفيذ جميع العوامل في وضع سطر بسطر ، ويزداد وقت تنفيذ الاستعلام ثلاث مرات تقريبًا.

إلى مستوى معين ، يمكنك رؤية هذا في الرسم التخطيطي ، ولكن في شجرة التفاصيل الخاصة بالخطة يمكنك أيضًا رؤية تأثير شرط التحديد غير قادر على استبعاد الصفوف حتى يحدث التصنيف:

لا يعد اختيار وضع الدُفعة دائمًا خطوة جيدة - حيث يأخذ الاستدلال المضمّن في خوارزمية اتخاذ القرار في الاعتبار عدد الخطوط وأنواع المشغلين المقترحين والفوائد المتوقعة من وضع الدُفعة.
APPROX_COUNT_DISTINCT
هذه الوظيفة التجميعية الجديدة مخصصة لسيناريوهات تخزين البيانات وهي تعادل COUNT (DISTINCT ()). ومع ذلك ، بدلاً من إجراء عمليات فرز مكلفة لتحديد الكمية الفعلية ، تعتمد الوظيفة الجديدة على الإحصائيات للحصول على بيانات دقيقة نسبيًا. عليك أن تفهم أن الخطأ يقع في حدود 2٪ من المبلغ المحدد ، وفي 97٪ من الحالات التي تعد المعيار للتحليلات عالية المستوى ، هذه هي القيم المعروضة على المؤشرات أو تُستخدم لإجراء تقييمات سريعة.
في نظامي ، أنشأت جدولًا يحتوي على أعمدة صحيحة تتضمن قيمًا فريدة في النطاق من 100 إلى 1،000،000 ، وأعمدة الصف ، مع قيم فريدة في النطاق من 100 إلى 100000. لم يكن بها فهارس باستثناء المفتاح الأساسي المتجمع في الأول عمود صحيح. في ما يلي نتائج تشغيل COUNT (DISTINCT ()) و APPROX_COUNT_DISTINCT () على هذه الأعمدة ، والتي يمكنك من خلالها رؤية اختلافات طفيفة (ولكن دائمًا في حدود 2٪):
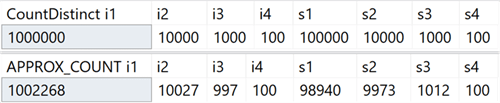
المكسب كبير إذا كانت هناك قيود على الذاكرة ، والتي تنطبق على معظمنا. إذا نظرت إلى خطط الاستعلام ، في هذه الحالة بالذات ، يمكنك أن ترى اختلافًا كبيرًا في استهلاك الذاكرة بواسطة عامل مطابقة التجزئة:

لاحظ أنك ستلاحظ عادةً تحسينات كبيرة في الأداء فقط إذا كنت مقيّدًا بالفعل بالذاكرة. على نظامي ، استمر التنفيذ لفترة أطول قليلاً بسبب ارتفاع استخدام وحدة المعالجة المركزية للميزة الجديدة:

ربما يكون الفرق أكثر أهمية إذا كان لدي جداول أكبر ، أو ذاكرة أقل متاحة لـ SQL Server ، أو التزامن العالي ، أو مزيج من ما سبق.
نصائح لاستخدام مستوى التوافق داخل الاستعلام
هل لديك استعلام خاص يعمل بشكل أفضل تحت مستوى توافق معين مختلف عن قاعدة البيانات الحالية؟ هذا ممكن الآن بفضل تلميحات الاستعلام الجديدة التي تدعم ستة مستويات مختلفة من التوافق وخمسة نماذج مختلفة لتقدير عدد العناصر. فيما يلي مستويات التوافق المتاحة ، وصيغة المثال ، ونموذج مستوى التوافق المستخدم في كل حالة. انظر كيف يؤثر ذلك على التصنيفات ، حتى بالنسبة لعروض النظام:

باختصار: لم تعد هناك حاجة لتذكر علامات التتبع ، أو تتساءل عما إذا كنت بحاجة إلى القلق بشأن ما إذا كان التصحيح TF 4199 لمُحسِّن الاستعلام موزعًا أم أنه تم إلغاؤه بواسطة حزمة خدمة أخرى. لاحظ أن هذه النصائح الإضافية تمت إضافتها مؤخرًا أيضًا لـ SQL Server 2017 في التحديث التراكمي رقم 10 (انظر
مدونة Pedro Lopez للحصول على التفاصيل). يمكنك رؤية جميع التلميحات المتاحة بالأمر التالي:
SELECT name FROM sys.dm_exec_valid_use_hints;
ولكن لا تنس أن التلميحات هي إجراء استثنائي ، فهي غالبًا ما تكون مناسبة للخروج من موقف صعب ، ولكن لا ينبغي التخطيط لاستخدامها على المدى الطويل ، حيث قد يتغير سلوكهم مع التحديثات اللاحقة.
استكشاف الأخطاء وإصلاحها
التنميط الافتراضي المبسط
يتطلب فهم هذا التحسين بضع نقاط للتذكر. قدم SQL Server 2014 عرض DMV sys.dm_exec_query_profiles ، والذي يسمح للمستخدم الذي يقوم بتنفيذ الاستعلام بجمع معلومات تشخيصية حول جميع العبارات في جميع أجزاء الاستعلام. تصبح المعلومات التي تم جمعها متاحة بعد الانتهاء من الاستعلام وتسمح لك بتحديد المشغلين الذين أنفقوا بالفعل الموارد الرئيسية ولماذا. يمكن لأي مستخدم لم يستوف طلبًا محددًا أن يتلقى هذه البيانات لأي جلسة تم تضمينها في إحصائيات ملف تعريف XML أو إحصائيات ملف التعريف ، أو لجميع الجلسات ، باستخدام حدث query_post_execution_showplan الموسع ، على الرغم من أن هذا الحدث ، على وجه الخصوص ، يمكن أن يؤثر على الأداء العام.
في Management Studio 2016 ، تمت إضافة الوظائف التي تسمح لك بعرض تدفقات البيانات التي تمر عبر خطة الاستعلام في الوقت الحقيقي بناءً على المعلومات التي تم جمعها من DMV ، مما يجعلها أكثر قوة لاستكشاف الأخطاء وإصلاحها. يوفر Plan Explorer أيضًا القدرة على تصور البيانات التي تمر عبر الاستعلام ، في الوقت الحقيقي وفي وضع التشغيل.
بدءًا من SQL Server 2016 Service Pack 1 (SP1) ، يمكنك أيضًا تمكين إصدار خفيف من جمع هذه البيانات لجميع الجلسات باستخدام علامة التتبع 7412 أو خاصية query_thread_profile المتقدمة ، والتي تسمح لك بالحصول على الفور على أحدث المعلومات حول أي جلسة ، دون الحاجة إلى أي شيء تضمينه بشكل صريح (على وجه الخصوص ، الأشياء التي تؤثر سلبًا على الأداء). يتم وصف هذا بمزيد من التفصيل في
مدونة بيدرو لوبيز .
في SQL Server 2019 ، يتم تمكين هذه الميزة افتراضيًا ، لذلك لا تحتاج إلى تشغيل أي جلسات ذات أحداث موسعة أو استخدام أي علامات تتبع وعبارات إحصائية في أي استعلام. ما عليك سوى إلقاء نظرة على البيانات من DMV في أي وقت لجميع الجلسات المتزامنة. ولكن من الممكن تعطيل هذا الوضع باستخدام LIGHTWEIGHT_QUERY_PROFILING ، ومع ذلك ، لا يعمل بناء الجملة هذا في CTP 2.0 وسيتم إصلاحه في الإصدارات المستقبلية.
إحصائيات فهرس العمود المجمعة متاحة الآن في قواعد البيانات المستنسخة
في الإصدارات الحالية من SQL Server ، عند نسخ قاعدة بيانات ، يتم استخدام الإحصائيات الأصلية للكائن فقط من فهارس الأعمدة المجمعة ، باستثناء التحديثات التي يتم إجراؤها على الجدول بعد إنشائها. إذا كنت تستخدم استنساخًا لتكوين الاستعلامات واختبارات الأداء الأخرى ، والتي تستند إلى تصنيفات الطاقة ، فقد لا تعمل هذه الأمثلة. وصف Parikshit Savyani القيود
في هذا المنشور وقدم حلاً مؤقتًا - قبل إنشاء الاستنساخ ، تحتاج إلى إنشاء برنامج نصي ينفذ SHOW_STATISTICS DBCC ... مع STATS_STREAM لكل كائن. إنها باهظة الثمن ، وبطبيعة الحال ، من السهل نسيانها.
في SQL Server 2019 ، ستتوفر هذه الإحصائيات المحدثة تلقائيًا في النسخ ، بحيث يمكنك اختبار سيناريوهات الاستعلام المختلفة والحصول على خطط موضوعية تستند إلى إحصائيات حقيقية ، بدون تشغيل STATS_STREAM يدويًا لجميع الجداول.
توقعات الضغط لتخزين العمود
في الإصدارات الحالية ، يكون لإجراء sys.sp_estimate_data_compression_savings الاختيار التالي:
if (@data_compression not in ('NONE', 'ROW', 'PAGE'))
هذا يعني أنه يسمح لك بالتحقق من ضغط الخط أو الصفحة (أو رؤية نتيجة حذف الضغط الحالي). في SQL Server 2019 ، يبدو هذا الاختيار الآن كما يلي:
if (@data_compression not in ('NONE', 'ROW', 'PAGE', 'COLUMNSTORE', 'COLUMNSTORE_ARCHIVE'))
هذه أخبار رائعة لأنها تسمح لك بالتنبؤ تقريبًا بتأثير إضافة فهرس عمود إلى جدول لا يحتوي عليه ، أو تحويل الجداول أو الأقسام إلى تنسيق تخزين أعمدة مضغوط أكثر ، دون الحاجة إلى استعادة الجدول إلى نظام آخر. كان لدي جدول يحتوي على 10 ملايين سطر ، قمت من أجله بإجراء تخزين مع كل من المعلمات الخمس:
EXEC sys.sp_estimate_data_compression_savings @schema_name = N'dbo', @object_name = N'FactTable', @index_id = NULL, @partition_number = NULL, @data_compression = N'NONE';
النتائج:

كما هو الحال مع أنواع الضغط الأخرى ، تعتمد الدقة بشكل كامل على الصفوف المتاحة وتمثيل بقية البيانات. ومع ذلك ، فهذه طريقة قوية جدًا للحصول على نتائج يمكن التنبؤ بها دون صعوبة كبيرة.
ميزة جديدة للحصول على معلومات الصفحة
لفترة طويلة ، تم استخدام DBCC PAGE و DBCC IND لجمع معلومات حول الصفحات التي تحتوي على قسم أو فهرس أو جدول. لكنها غير موثقة وغير مدعومة ، وقد يكون من الصعب أن أتمتة حل المهام المرتبطة بفهارس أو صفحات متعددة.
في وقت لاحق ، ظهرت وظيفة إدارية ديناميكية (DMF) sys.dm_db_database_page_allocations ، والتي ترجع مجموعة تمثل جميع الصفحات في الكائن المحدد. لا تزال غير موثقة ولديها عيوب يمكن أن تصبح مشكلة حقيقية على طاولات كبيرة: حتى للحصول على معلومات حول صفحة واحدة ، يجب أن تقرأ البنية بأكملها ، والتي يمكن أن تكون مكلفة للغاية.
في SQL Server 2019 ، ظهر DMF آخر - sys.dm_db_page_info. تقوم بإرجاع كافة معلومات الصفحة بشكل أساسي ، بدون النفقات العامة لتوزيع DMF. ومع ذلك ، لاستخدام الوظيفة في الإصدارات الحالية ، تحتاج إلى معرفة رقم الصفحة التي تبحث عنها مقدمًا. ربما تم اتخاذ هذه الخطوة عمدا ، لأنه هذه هي الطريقة الوحيدة لضمان الأداء. لذلك إذا كنت تحاول تحديد جميع الصفحات في فهرس أو جدول ، فلا تزال بحاجة إلى استخدام توزيع DMF. في المقالة التالية سوف أصف هذا السؤال بمزيد من التفصيل.
الأمان
تشفير دائم باستخدام بيئة آمنة (جيب)
في الوقت الحالي ، يحمي التشفير الدائم البيانات الحساسة أثناء الإرسال وفي الذاكرة عن طريق التشفير / فك التشفير في كل نهاية من العملية. لسوء الحظ ، غالبًا ما يؤدي هذا إلى قيود خطيرة عند العمل مع البيانات ، مثل عدم القدرة على إجراء العمليات الحسابية والتصفية ، لذلك يجب عليك نقل مجموعة البيانات بالكامل إلى جانب العميل لإجراء بحث عن النطاق.
البيئة الآمنة (الجيب) هي منطقة محمية من الذاكرة حيث يمكن تفويض مثل هذه العمليات الحسابية والتصفية (يستخدم Windows
الأمان المستند إلى الظاهرية ) - تظل البيانات مشفرة في النواة ، ولكن يمكن فك تشفيرها أو تشفيرها بأمان في بيئة آمنة. تحتاج فقط إلى إضافة معلمة ENCLAVE_COMPUTATIONS إلى المفتاح الأساسي باستخدام SSMS ، على سبيل المثال ، عن طريق تحديد المربع "السماح بالحسابات في بيئة آمنة":
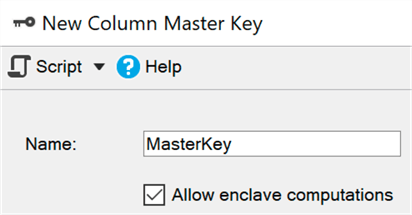
يمكنك الآن تشفير البيانات على الفور تقريبًا ، مقارنةً بالطريقة القديمة (حيث سيتعين على المعالج ، Set-SqlColumnEncyption cmdlet أو تطبيقك ، الحصول على المجموعة بالكامل من قاعدة البيانات ، وتشفيرها ، وإرسالها مرة أخرى):
ALTER TABLE dbo.Patients ALTER COLUMN SSN char(9)
أعتقد أنه بالنسبة للعديد من المؤسسات ، سيكون هذا التحسين هو الأخبار الرئيسية ، ولكن في برنامج التحويلات النقدية الحالي ، لا تزال بعض هذه الأنظمة الفرعية قيد التحسين ، وبالتالي يتم إيقاف تشغيلها افتراضيًا ، ولكن
هنا يمكنك معرفة كيفية تشغيلها.
إدارة الشهادة في مدير التهيئة
لطالما كانت إدارة شهادات SSL و TLS مؤلمة ، واضطر العديد من الأشخاص إلى القيام بالعمل الشاق لإنشاء نصوصهم الخاصة لنشر شهادات المؤسسة الخاصة بهم والحفاظ عليها. يساعدك مدير التهيئة المحدّث لـ SQL Server 2019 في عرض الشهادات والتحقق منها بسرعة من أي مثيل ، والعثور على الشهادات التي على وشك أن تنتهي صلاحيتها في المستقبل القريب ، ومزامنة عمليات نشر الشهادات عبر جميع النسخ المكررة في مجموعة توفر أو جميع العقد في مثيل نظام مجموعة تجاوز الفشل.
لم أجرب كل هذه العمليات ، ولكن يجب أن تعمل مع الإصدارات السابقة من SQL Server إذا كانت الإدارة تأتي من SQL Server 2019 Configuration Manager.
تصنيف وتدقيق البيانات المضمنة
أضاف فريق تطوير SQL Server القدرة على تصنيف البيانات في SSMS 17.5 ، مما يسمح لك بتحديد أي أعمدة قد تحتوي على معلومات حساسة أو تتعارض مع معايير مختلفة (HIPAA ، SOX ، PCI ، و GDPR ، بالطبع). يستخدم المعالج خوارزمية تقدم أعمدة من المفترض أن تسبب مشاكل ، ولكن يمكنك إما تعديل الجملة من خلال إزالة هذه الأعمدة من القائمة ، أو إضافة عمودك الخاص. لتخزين التصنيف ، يتم استخدام الخصائص المتقدمة ؛ يستخدم تقرير SSMS المضمن نفس المعلومات لعرض بياناته. خارج التقرير ، هذه الخصائص ليست واضحة للغاية.
قدم SQL Server 2019 عبارة جديدة لهذه البيانات الوصفية ، وهي متاحة بالفعل في قاعدة بيانات Azure SQL ، تسمى ADD SENSITIVITY CLASSIFICATION. يسمح لك بفعل نفس المعالج في SSMS ، ولكن لم تعد المعلومات مخزنة في الخاصية الموسعة ، ويتم عرض أي وصول إلى هذه البيانات تلقائيًا في التدقيق كعمود XML جديد data_sensitivity_information. يحتوي على جميع أنواع المعلومات التي تأثرت أثناء المراجعة.
كمثال سريع ، لنفترض أن لدي جدولًا للمقاولين الخارجيين:
CREATE TABLE dbo.Contractors ( FirstName sysname, LastName sysname, SSN char(9), HourlyRate decimal(6,2) );
بالنظر إلى مثل هذا الهيكل ، يصبح من الواضح أن الأعمدة الأربعة إما تكون عرضة للتسرب ، أو يجب أن تكون متاحة فقط لدائرة محدودة من الناس. هنا يمكنك الحصول على أذونات ، ولكن على الأقل تحتاج إلى التركيز عليها. وبالتالي ، يمكننا تصنيف هذه الأعمدة بطرق مختلفة:
ADD SENSITIVITY CLASSIFICATION TO dbo.Contractors.FirstName, dbo.Contractors.LastName WITH (LABEL = 'Confidential – GDPR', INFORMATION_TYPE = 'Personal Info'); ADD SENSITIVITY CLASSIFICATION TO dbo.Contractors.SSN WITH (LABEL = 'Highly Confidential', INFORMATION_TYPE = 'National ID'); ADD SENSITIVITY CLASSIFICATION TO dbo.Contractors.HourlyRate WITH (LABEL = 'Highly Confidential', INFORMATION_TYPE = 'Financial');
الآن ، بدلاً من النظر إلى sys.extended_properties ، يمكنك رؤيتها في sys.sensitivity_classifications:

وإذا أجرينا عينات تدقيق (أو DML) لهذا الجدول ، فلن نحتاج إلى تغيير أي شيء على وجه التحديد ؛ بعد إنشاء التصنيف ، يقوم
SELECT * بتسجيل سجل لهذا النوع من المعلومات في عمود التدقيق في عمود جديد data_sensitivity_information:
<sensitivity_attributes> <sensitivity_attribute label="Confidential - GDPR" information_type="Personal Info" /> <sensitivity_attribute label="Highly Confidential" information_type="National ID" /> <sensitivity_attribute label="Highly Confidential" information_type="Financial" /> </sensitivity_attributes>
بالطبع ، هذا لا يحل جميع قضايا الامتثال للمعايير ، ولكن يمكن أن يعطي ميزة حقيقية. يمكن أن يؤدي استخدام المعالج لتحديد الأعمدة تلقائيًا وترجمة مكالمات sp_addextendedproperty إلى أوامر إضافة تصنيف الحساسية إلى تبسيط مهمة الامتثال للمعايير بشكل كبير. في وقت لاحق ، سأكتب مقالة منفصلة حول هذا الموضوع.
يمكنك أيضًا أتمتة إنشاء (أو تحديث) الأذونات استنادًا إلى التسمية في البيانات الوصفية - إنشاء نص برمجي SQL ديناميكي يمنع الوصول إلى جميع أعمدة (GDPR) السرية ، والتي ستسمح لك بإدارة المستخدمين أو المجموعات أو الأدوار ب. سأعمل على هذه المسألة في المستقبل.
التوفر
إنشاء فهرس متجدد في الوقت الحقيقي
في SQL Server 2017 ، أصبح من الممكن تعليق إعادة بناء الفهرس واستئنافه في الوقت الفعلي ، والذي يمكن أن يكون مفيدًا جدًا إذا كنت بحاجة إلى تغيير عدد المعالجات المستخدمة ، أو المتابعة من لحظة التعليق بعد الفشل ، أو ببساطة سد الفجوة بين نوافذ الخدمة. لقد تحدثت عن هذه الميزة في
مقال سابق .
في SQL Server 2019 ، يمكنك استخدام نفس البنية لإنشاء فهارس في الوقت الفعلي ، وإيقاف مؤقت ومتابعة ، وكذلك للحد من وقت التنفيذ (تحديد وقت الإيقاف المؤقت):
CREATE INDEX foo ON dbo.bar(blat) WITH (ONLINE = ON, RESUMABLE = ON, MAX_DURATION = 10 MINUTES);
إذا كان هذا الاستعلام يعمل لفترة طويلة جدًا ، فعندئذ توقف مؤقتًا ، يمكنك تشغيل ALTER INDEX في جلسة أخرى (حتى لو لم يكن الفهرس موجودًا فعليًا بعد):
ALTER INDEX foo ON dbo.bar PAUSE;
في البنيات الحالية ، لا يمكن تقليل درجة التوازي أثناء التجديد ، كما هو الحال مع إعادة البناء. عند محاولة تقليل DOP:
ALTER INDEX foo ON dbo.bar RESUME WITH (MAXDOP = 2);
نحصل على ما يلي:
Msg 10666, Level 16, State 1, Line 3 Cannot resume index build as required DOP 4 (DOP operation was started with) is not available. Please ensure sufficient DOP is available or abort existing index operation and try again. The statement has been terminated.
في الواقع ، إذا حاولت القيام بذلك ، ثم قمت بتنفيذ الأمر بدون معلمات إضافية ، فسوف تحصل على نفس الخطأ ، على الأقل في البنيات الحالية. أعتقد أن محاولة التجديد تم تسجيلها في مكان ما وأراد النظام استخدامها مرة أخرى. للمتابعة ، يجب عليك تحديد قيمة DOP الصحيحة (أو أعلى):
ALTER INDEX foo ON dbo.bar RESUME WITH (MAXDOP = 4);
لتوضيح الأمر: يمكنك زيادة DOP عند استئناف إنشاء فهرس متوقف مؤقتًا ، ولكن ليس خفضه.
فائدة إضافية لكل هذا أنه يمكنك تكوين إنشاء و / أو تجديد الفهارس في الوقت الحقيقي كوضع افتراضي باستخدام جمل ELEVATE_ONLINE و ELEVATE_RESUMABLE لقاعدة البيانات الجديدة.
إنشاء / إعادة بناء فهارس الأعمدة المجمعة في الوقت الفعلي
بالإضافة إلى إنشاء الفهرس القابل للتجديد ، نحصل أيضًا على فرصة لإنشاء أو إعادة بناء فهارس الأعمدة المجمعة في الوقت الفعلي. يعد هذا تغييرًا كبيرًا ، والذي يسمح لك بعدم قضاء وقت نوافذ الخدمة على صيانة هذه المؤشرات أو (لمزيد من اليقين) لتحويل المؤشرات من الصفوف إلى الأعمدة:
CREATE TABLE dbo.splunge ( id int NOT NULL ); GO CREATE UNIQUE CLUSTERED INDEX PK_Splunge ON dbo.splunge(id); GO CREATE CLUSTERED COLUMNSTORE INDEX PK_Splunge ON dbo.splunge WITH (DROP_EXISTING = ON, ONLINE = ON);
تحذير واحد: إذا تم إنشاء فهرس مجمع تقليدي موجود في الوقت الفعلي ، فإن تحويله إلى فهرس عمود مجمع ممكن أيضًا في هذا الوضع فقط. إذا كان جزءًا من المفتاح الأساسي ، مدمجًا أم لا ... CREATE TABLE dbo.splunge ( id int NOT NULL CONSTRAINT PK_Splunge PRIMARY KEY CLUSTERED (id) ); GO
نحصل على الخطأ التالي: Msg 1907, Level 16 Cannot recreate index 'PK_Splunge'. The new index definition does not match the constraint being enforced by the existing index.
يجب عليك أولاً إزالة القيد من أجل تحويله إلى فهرس عمود مجمع ، ولكن يمكن تنفيذ كلتا العمليتين في الوقت الفعلي: ALTER TABLE dbo.splunge DROP CONSTRAINT PK_Splunge WITH (ONLINE = ON); GO CREATE CLUSTERED COLUMNSTORE INDEX PK_Splunge ON dbo.splunge WITH (ONLINE = ON);
يعمل هذا ، ولكن من المحتمل أن تستغرق الجداول الكبيرة وقتًا أطول مما لو تم تنفيذ المفتاح الأساسي كمؤشر فريد مجمع. لا يمكنني الجزم إذا كان هذا تقييدًا مقصودًا أو مجرد تقييد لبرنامج التحويلات النقدية الحالي.إعادة توجيه اتصال النسخ المتماثل من خادم ثانوي إلى خادم أساسي
تسمح لك هذه الوظيفة بتكوين إعادة التوجيه دون الاستماع ، بحيث يمكنك تبديل الاتصال بالخادم الأساسي ، حتى إذا تم تحديد الثانوي بشكل مباشر في سلسلة الاتصال. يمكن استخدام هذه الوظيفة عندما لا تدعم تقنية التجميع الاستماع ، عند استخدام AGs بدون كتلة ، أو عندما يكون هناك مخطط إعادة توجيه معقد في سيناريو به شبكات فرعية متعددة. سيمنع هذا الاتصال ، على سبيل المثال ، من محاولة كتابة عمليات للنسخ المتماثل في وضع القراءة فقط (والفشل على التوالي).التنمية
ميزات إضافية للرسم البياني
تدعم علاقات الرسم البياني الآن عبارة MERGE للعقدة أو جداول الحدود باستخدام مسندات MERGE ؛ الآن يمكن لمشغل واحد تحديث حافة موجودة أو إدراج حافة جديدة. يسمح لك تقييد الحافة الجديد بتحديد العقد التي يمكن للحافة الاتصال بها.Utf-8
أضاف SQL Server 2012 دعمًا لـ UTF-16 وأحرفًا إضافية عن طريق تعيين الفرز عن طريق تحديد اسم مع اللاحقة _SC ، مثل Latin1_General_100_CI_AI_SC ، لاستخدام أعمدة Unicode (nchar / nvarchar). في SQL Server 2017 ، يمكنك استيراد وتصدير بيانات UTF-8 من هذه الأعمدة وإليها باستخدام أدوات مثل BCP و BULK INSERT .في SQL Server 2019 ، هناك خيارات ترتيب جديدة لدعم الاحتفاظ القسري ببيانات UTF-8 في شكلها الأصلي. لذلك يمكنك بسهولة إنشاء أعمدة char أو varchar وتخزين بيانات UTF-8 بشكل صحيح باستخدام الترتيب الجديد مع اللاحقة _SC_UTF8 ، مثل Latin1_General_100_CI_AI_SC_UTF8. يمكن أن يساعد هذا في تحسين التوافق مع التطبيقات الخارجية و DBMS ، دون تكلفة معالجة وتخزين nvarchar.وجدت بيضة عيد الفصح
بقدر ما أتذكر ، يشكو مستخدمو SQL Server من رسالة الخطأ الغامضة هذه: Msg 8152 String or binary data would be truncated.
في إصدارات CTP التي جربتها ، لوحظت رسالة خطأ مثيرة للاهتمام لم تكن موجودة من قبل: Msg 2628 String or binary data would be truncated in table '%.*ls', column '%.*ls'. Truncated value: '%.*ls'
لا أعتقد أن هناك حاجة إلى أي شيء آخر هنا ؛ هذا تحسن كبير (وإن كان متأخرًا جدًا) ، ويعد بإسعاد الكثيرين. ومع ذلك ، لن تتوفر هذه الوظيفة في CTP 2.0 ؛ أنا فقط أعطيك الفرصة للنظر قليلاً إلى الأمام. أدرج برنت أوزار جميع الرسائل الجديدة التي وجدها في برنامج التحويلات النقدية الحالي وقام بتتبيلها ببعض التعليقات المفيدة في مقاله sys.messages: اكتشاف ميزات إضافية .الخلاصة
يوفر SQL Server 2019 ميزات إضافية جيدة ستساعد في تحسين العمل مع منصة قاعدة البيانات العلائقية المفضلة لديك ، وهناك عدد من التغييرات التي لم أتحدث عنها. ذاكرة موفرة للطاقة ، وتجميع لخدمات التعلم الآلي ، والنسخ المتماثل والمعاملات الموزعة على Linux ، و Kubernetes ، وموصلات Oracle / Teradata / MongoDB ، وارتفعت تكرارات AG المتزامنة لدعم Java (تنفيذ مشابه لـ Python / R) ، وبنفس القدر من الأهمية ، قفزة جديدة ، بعنوان مجموعة البيانات الكبيرة. لاستخدام بعض هذه الميزات ، يجب عليك التسجيل باستخدام نموذج EAP هذا .كتاب بوب وارد القادم ، Pro SQL Server على Linux - بما في ذلك النشر القائم على الحاويات مع Docker و Kubernetes , , .
.
CTP - , !