الأصدقاء ، مساء الخير.
هناك فهم واضح أن غالبية مشاريع ICO هي في الأساس أصل غير ملموس. مشروع ICO ليس سيارة مرسيدس-بنز - إنه يقود بغض النظر عمن يحب ذلك أم لا. والتأثير الرئيسي على الطرح الأولي للعملات يتم من خلال الحالة المزاجية للناس - كل من الموقف تجاه مؤسس / مؤسس الطرح الأولي للعمل والمشروع نفسه.
سيكون من اللطيف قياس موقف الناس بطريقة ما تجاه مؤسس ICO و / أو مشروع ICO. الذي تم القيام به. التقرير أدناه.
وكانت النتيجة أداة لجمع أمزجة إيجابية / سلبية من الإنترنت ، وخاصة من تويتر.
بيئتي هي Windows 10 x64 ، استخدمت لغة Python 3 في محرر Spyder في Anaconda 5.1.0 ، وهو اتصال شبكة سلكية.
جمع البيانات
سأحصل على الحالة المزاجية من مشاركات Twitter. أولاً ، سأكتشف ما يفعله مؤسس ICO الآن وكيف يستجيبون بشكل إيجابي لهذا الأمر مع مثال لشخصيات مشهورة.
سأستخدم مكتبة ثعبان بيثون. للعمل مع تويتر ، تحتاج إلى التسجيل كمطور فيه ، راجع twitter / . احصل على معايير الوصول إلى Twitter.
الرمز كما يلي:
import tweepy API_KEY = "vvvvEXQWhuF1fhAqAtoXRrrrr" API_SECRET = "vvvv30kspvqiezyPc26JafhRjRiZH3K12SGNgT0Ndsqu17rrrr" ACCESS_TOKEN = "vvvv712098-WBn6rZR4lXsnZCwcuU0aOsRkENSGpw2lppArrrr" ACCESS_TOKEN_SECRET = "vvvvlG7APRc5yGiWY5xFKfIGpqkHnXAvuwwVzMwyyrrrr" auth = tweepy.OAuthHandler(API_KEY, API_SECRET) auth.set_access_token(ACCESS_TOKEN, ACCESS_TOKEN_SECRET) api = tweepy.API(auth)
الآن يمكننا أن ننتقل إلى Twitter API ونحصل على شيء منه ، أو العكس بالعكس. الشيء الذي تم القيام به في أوائل أغسطس. تحتاج إلى الحصول على بعض التغريدات للعثور على المشروع الحالي للمؤسس. بحثت على هذا النحو:
import pandas as pd searchstring = searchinfo+' -filter:retweets' results = pd.DataFrame() coursor = tweepy.Cursor(api.search, q=searchstring, since="2018-07-07", lang="en", count = 500) for tweet in coursor.items(): my_series = pd.Series([str(tweet.id), tweet.created_at, tweet.text, tweet.retweeted], index=['id', 'title', 'text', 'retweeted']) result = pd.DataFrame(my_series).transpose() results = results.append(result, ignore_index = True) results.to_excel('results.xlsx')
في searchinfo ، نستبدل الاسم الضروري وإعادة التوجيه. تم حفظ النتيجة في results.xlsx excel.
مبدع
ثم قررت أن أصنع إبداعًا. نحتاج أن نجد مشاريع المؤسس. أسماء المشاريع هي أسماء مناسبة ويتم تكبيرها. لنفترض أن هذا يبدو صحيحًا أيضًا أنه مع كتابة حرف كبير في كل تغريدة: 1) اسم المؤسس ، 2) اسم مشروعه ، 3) الكلمة الأولى للتغريدة و 4) الكلمات الدخيلة. سيتم العثور على الكلمات 1 و 2 بشكل متكرر على التغريدات ، و 3 و 4 نادرة ، في تكرار نحن 3 و 4 ونزيلها. نعم ، اتضح أيضًا أن الروابط غالبًا ما تظهر عبر التغريدات ، 5) سنزيلها أيضًا.
اتضح مثل هذا:
import re import nltk nltk.download('stopwords') from nltk.corpus import stopwords from nltk.stem.porter import PorterStemmer corpus = [] for i in range(0, len(results.index)): review1 = [] mystr = results['text'][i]
تحليل البيانات الإبداعية
في متغير الأسماء لدينا الكلمات ، وفي المتغير X - الأماكن التي تم ذكرها فيها. الجدول "إيقاف" X - الحصول على عدد المراجع. نحذف الكلمات التي نادرا ما تذكر. حفظ في Excel. وفي إكسيل نقوم بعمل مخطط شريطي جميل يحتوي على معلومات حول عدد المرات التي يتم ذكر الكلمات فيها في أي استعلام.
نجومنا الأوليون في ICO هم Le Minh Tam و Mike Novogratz. الرسوم البيانية:
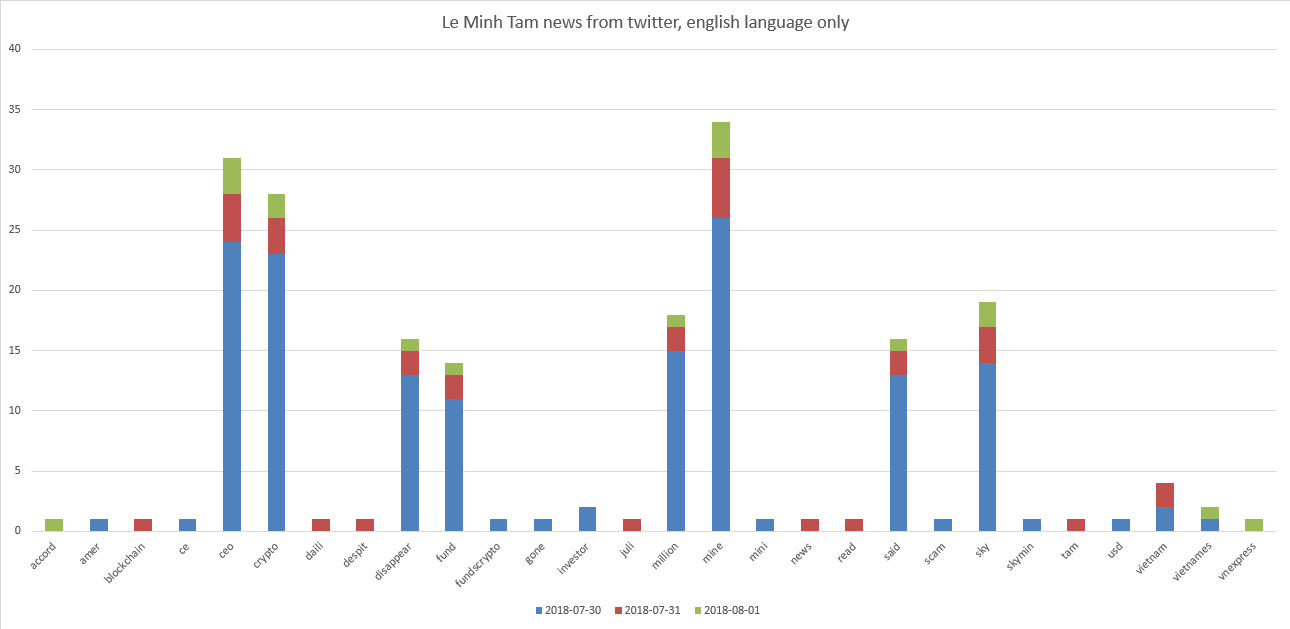
يمكن ملاحظة أن Le Minh Tam مرتبط بـ "ceo ، crypto ، الألغام ، sky". وقليلا ل "تختفي ، وتمول ، مليون".
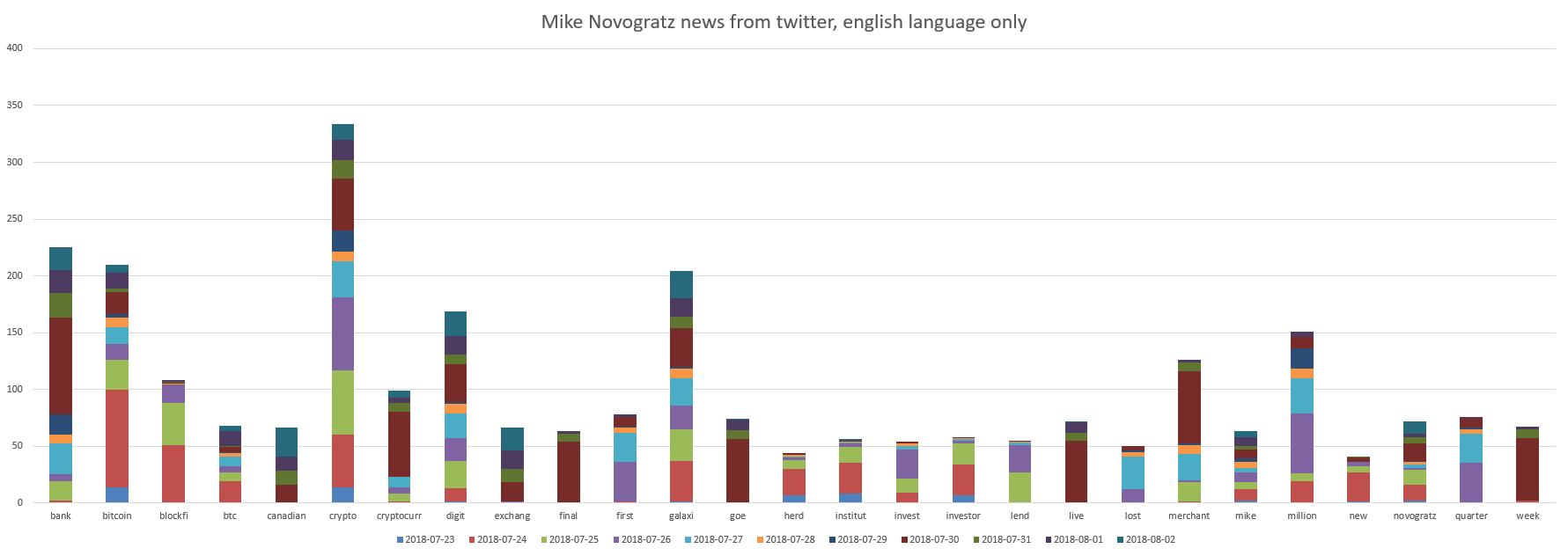
يمكن ملاحظة أن مايك نوفوغراتز مرتبط بـ "بنك ، بيتكوين ، تشفير ، رقم ، مجرة".
يمكن صب البيانات من X في شبكة عصبية ويمكن أن تتعلم تحديد أي شيء ، ولكن يمكنك:
تحليل البيانات
ثم نتوقف خداع كن مبدعًا وابدأ في استخدام مكتبة python TextBlob . المكتبة هي معجزة كيف جيدة.
يقول الأذكياء أنها تستطيع:
- إبراز العبارات
- قم بوضع علامات جزئية
- تحليل المزاج (هذا مفيد لنا أدناه) ،
- القيام بالتصنيف (خليج ساذج ، شجرة القرار) ،
- ترجمة وتعريف اللغة باستخدام الترجمة من Google ،
- القيام بالرمز (تقسيم النص إلى كلمات وجمل) ،
- تحديد ترددات الكلمات والعبارات ،
- القيام بالتحليل
- كشف ن غرام
- لا تكشف عن انحراف \ انحراف \ اقتران الكلمات (التعددية و التفرد) و اللم ،
- الإملاء الصحيح.
تسمح لك المكتبة بإضافة نماذج أو لغات جديدة من خلال الإضافات ولديها تكامل WordNet. في كلمة واحدة ، NLP هو معجزة طفل .
تم حفظ نتائج البحث في ملف results.xlsx أعلاه. قم بتنزيله وتصفحه مع مكتبة TextBlob لأغراض تقييم الحالة المزاجية:
from textblob import TextBlob results = pd.read_excel('results.xlsx') polarity = 0 for i in range(0, len(results.index)): polarity += TextBlob(results['text'][i]).sentiment.polarity print(polarity/i)
عظيم! سطران من التعليمات البرمجية ونتيجة الانفجار.
نظرة عامة على النتائج
اتضح أنه في بداية أغسطس 2018 ، تظهر التغريدات الموجودة على استعلام "Le Minh Tam" شيئًا انعكس سلبًا في التغريدات بمتوسط تقييم لكل التغريدات ناقص 0.13 . إذا شاهدنا التغريدات بنفسها ، فسوف نرى على سبيل المثال "قال الرئيس التنفيذي لشركة Crypto Mining اختفى مع 35 مليون دولار في الأموال ، وقد حصل الرئيس التنفيذي لشركة Min Min's الرئيس التنفيذي لشركة Sky Mining Le Minh Tam على ...".
وقام صديق مايك نوفوغراتز بشيء كان له تأثير إيجابي على التغريدات بمتوسط تقييم لجميع التغريدات بالإضافة إلى 0.03 . يمكنك تفسيره بحيث يتحرك كل شيء بهدوء.
خطة الهجوم
لأغراض تقييم ICO ، يجدر رصد المعلومات حول مؤسسي ICO و ICO نفسها من عدة مصادر. على سبيل المثال:
خطة لرصد ICO واحد:
- إنشاء قائمة بأسماء مؤسسي ICO و ICO نفسها ،
- ننشئ قائمة بموارد المراقبة ،
- نصنع روبوتًا يجمع البيانات لكل صف من 1 - لكل مورد من 2 ، المثال أعلاه ،
- نصنع روبوتًا يقوم بتقييم كل 3 ، المثال أعلاه ،
- حفظ النتائج 4 (و 3) ،
- كرر الخطوات من 3 إلى 5 ساعات ، بطريقة تلقائية ، يمكن نشر / إرسال / حفظ نتائج التقييم في مكان ما ،
- نقوم تلقائيًا بمراقبة القفزات في التقييم في الفقرة 6. إذا كانت هناك قفزات في التقييم في الفقرة 6 ، فهذه مناسبة لإجراء دراسة إضافية لما يحدث بخبرة. وإثارة الذعر ، أو العكس نفرح.
حسنا ، شيء من هذا القبيل.
PS حسنا ، أو شراء هذه المعلومات ، على سبيل المثال هنا thomsonreuters