مرحبًا يا هابر ، سأتحدث في هذه المقالة عن مكتبة الإشعال ، التي يمكنك من خلالها تدريب الشبكات العصبية واختبارها بسهولة باستخدام إطار عمل PyTorch.
من خلال الإشعال ، يمكنك كتابة دورات لتدريب الشبكة في بضعة أسطر فقط ، وإضافة حساب المقاييس القياسية من الصندوق ، وحفظ النموذج ، وما إلى ذلك. حسنًا ، بالنسبة لأولئك الذين انتقلوا من TF إلى PyTorch ، يمكننا القول أن مكتبة الإشعال هي Keras for PyTorch.
ستفحص المقالة بالتفصيل مثالًا لتدريب شبكة عصبية لمهمة تصنيف باستخدام إشعال.

أضف المزيد من النار إلى PyTorch
لن أضيع الوقت في الحديث عن مدى روعة إطار عمل PyTorch. أي شخص استخدمها بالفعل يفهم ما أكتب عنه. ولكن ، بكل مزاياها ، لا تزال منخفضة المستوى من حيث دورات الكتابة للتدريب والاختبار واختبار الشبكات العصبية.
إذا نظرنا إلى أمثلة رسمية لاستخدام إطار عمل PyTorch ، فسوف نرى دورتين على الأقل من التكرارات حسب الحقبة وبدفعات مجموعة التدريب في رمز تدريب الشبكة:
for epoch in range(1, epochs + 1): for batch_idx, (data, target) in enumerate(train_loader):
تتمثل الفكرة الرئيسية لمكتبة الإشعال في دمج هذه الحلقات في فئة واحدة ، مع السماح للمستخدم بالتفاعل مع هذه الحلقات باستخدام معالجات الأحداث.
ونتيجة لذلك ، في حالة مهام التعلم العميق القياسية ، يمكننا توفير الكثير على عدد أسطر التعليمات البرمجية. أسطر أقل - أخطاء أقل!
على سبيل المثال ، للمقارنة ، على اليسار يوجد رمز للتدريب والتحقق من صحة النموذج باستخدام الإشعال ، وعلى اليمين هو PyTorch النقي:
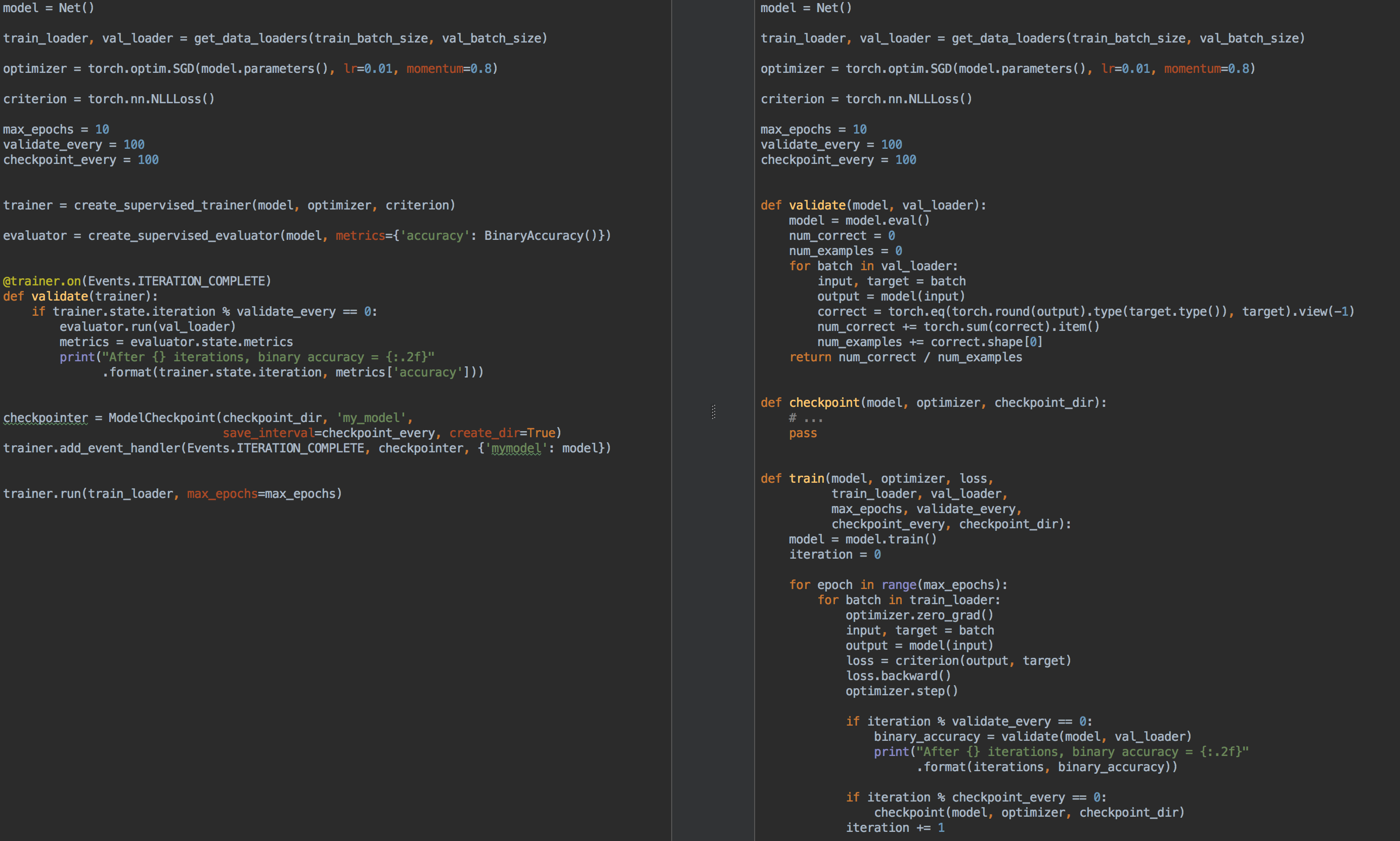
مرة أخرى ، ما هو الشيء الذي تشتعل ؟
- لم تعد بحاجة إلى الكتابة لكل حلقات المهام
for epoch in range(n_epochs) for batch in data_loader . - يسمح لك بتحليل الكود بشكل أفضل
- يسمح لك بحساب المقاييس الأساسية خارج الصندوق
- يوفر "الكعك" من النوع
- حفظ أحدث وأفضل النماذج (أيضًا مُحسِّن ومُجدوَل معدل التعلم) أثناء التدريب ،
- توقف عن التعلم المبكر
- الخ.
- يدمج بسهولة مع أدوات التصور: tensorboardX ، visdom ، ...
بشكل ما ، كما ذكرنا من قبل ، يمكن مقارنة مكتبة الإشعال مع جميع Keras الشهيرة و API الخاصة بها لشبكات التدريب والاختبار. أيضا ، مكتبة الإشعال للوهلة الأولى تشبه إلى حد كبير مكتبة tnt ، حيث كان لدى كلتا المكتبتين في البداية أهداف مشتركة ولديهما أفكار مماثلة لتنفيذها.
لذا ، قم بإضاءة:
pip install pytorch-ignite
أو
conda install ignite -c pytorch
بعد ذلك ، بمثال ملموس ، سنتعرف على واجهة برمجة تطبيقات الإشعال .
مهمة التصنيف مع إشعال
في هذا الجزء من المقالة ، سننظر في مثال مدرسي لتدريب شبكة عصبية لمشكلة التصنيف باستخدام مكتبة الإشعال .
لذا ، لنأخذ مجموعة بيانات بسيطة مع صور فواكه مع kaggle . وتتمثل المهمة في ربط فئة مقابلة بكل صورة فاكهة.
قبل استخدام الإشعال ، دعنا نحدد المكونات الرئيسية:
دفق البيانات
- محمل نموذج تدريب التدريب
- دفعة دفعة تنزيل
نموذج:
- خذ شبكة الضغط الصغيرة من
torchvision
خوارزمية التحسين:
وظيفة الخسارة:
كود from pathlib import Path import numpy as np import torch from torch.utils.data import Dataset, DataLoader from torch.utils.data.dataset import Subset from torchvision.datasets import ImageFolder from torchvision.transforms import Compose, RandomResizedCrop, RandomVerticalFlip, RandomHorizontalFlip from torchvision.transforms import ColorJitter, ToTensor, Normalize FRUIT360_PATH = Path(".").resolve().parent / "input" / "fruits-360_dataset" / "fruits-360" device = "cuda" train_transform = Compose([ RandomHorizontalFlip(), RandomResizedCrop(size=32), ColorJitter(brightness=0.12), ToTensor(), Normalize(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5]) ]) val_transform = Compose([ RandomResizedCrop(size=32), ToTensor(), Normalize(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5]) ]) batch_size = 128 num_workers = 8 train_dataset = ImageFolder((FRUIT360_PATH /"Training").as_posix(), transform=train_transform, target_transform=None) val_dataset = ImageFolder((FRUIT360_PATH /"Test").as_posix(), transform=val_transform, target_transform=None) train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True, num_workers=num_workers, drop_last=True, pin_memory="cuda" in device) val_loader = DataLoader(val_dataset, batch_size=batch_size, shuffle=True, num_workers=num_workers, drop_last=False, pin_memory="cuda" in device)
import torch.nn as nn from torchvision.models.squeezenet import squeezenet1_1 model = squeezenet1_1(pretrained=False, num_classes=81) model.classifier[-1] = nn.AdaptiveAvgPool2d(1) model = model.to(device)
import torch.nn as nn from torch.optim import SGD optimizer = SGD(model.parameters(), lr=0.01, momentum=0.5) criterion = nn.CrossEntropyLoss()
لذا حان الوقت لتشغيل الإشعال :
from ignite.engine import Engine, _prepare_batch def process_function(engine, batch): model.train() optimizer.zero_grad() x, y = _prepare_batch(batch, device=device) y_pred = model(x) loss = criterion(y_pred, y) loss.backward() optimizer.step() return loss.item() trainer = Engine(process_function)
دعونا نرى ما يعنيه هذا الرمز.
محرك Engine
فئة ignite.engine.Engine هي إطار المكتبة ، والهدف من هذه الفئة هو trainer :
trainer = Engine(process_function)
يتم تعريفه بوظيفة process_function لدالة الإدخال لمعالجة دفعة واحدة ويعمل على تنفيذ التمريرات لعينة التدريب. داخل فئة ignite.engine.Engine ، يحدث ما يلي:
while epoch < max_epochs:
العودة إلى وظيفة process_function :
def process_function(engine, batch): model.train() optimizer.zero_grad() x, y = _prepare_batch(batch, device=device) y_pred = model(x) loss = criterion(y_pred, y) loss.backward() optimizer.step() return loss.item()
نرى أنه داخل الوظيفة نقوم ، كالعادة في حالة تدريب النموذج ، بحساب التوقعات y_pred ، وحساب دالة loss ، loss والتدرجات. يسمح لك هذا الأخير بتحديث وزن النموذج: optimizer.step() .
بشكل عام ، لا توجد قيود على كود وظيفة process_function . نلاحظ فقط أنها تأخذ وسيطتين كمدخل: كائن Engine (في حالتنا ، trainer ) والدفعة من محمل البيانات. لذلك ، على سبيل المثال ، لاختبار شبكة عصبية ، يمكننا تحديد كائن آخر من فئة ignite.engine.Engine ، ignite.engine.Engine ، حيث تقوم وظيفة الإدخال ببساطة بحساب التوقعات ، وتنفيذ تمرير اختبار اختباري مرة واحدة. اقرأ عنها لاحقًا.
لذا ، فإن الرمز أعلاه يحدد فقط الأشياء الضرورية دون بدء التدريب. في الأساس ، في الحد الأدنى من المثال ، يمكنك استدعاء الطريقة:
trainer.run(train_loader, max_epochs=10)
وهذا الكود يكفي لتدريب النموذج "بهدوء" (بدون أي اشتقاق للنتائج الوسيطة).
ملاحظةلاحظ أيضًا أنه بالنسبة للمهام من هذا النوع ، تحتوي المكتبة على طريقة مناسبة لإنشاء كائن trainer :
from ignite.engine import create_supervised_trainer trainer = create_supervised_trainer(model, optimizer, criterion, device)
بالطبع ، في الممارسة العملية ، المثال أعلاه ليس له فائدة تذكر ، لذا دعنا نضيف الخيارات التالية لـ "المدرب":
- عرض قيمة دالة الخسارة كل 50 تكرار
- بدء حساب المقاييس في مجموعة التدريب بنموذج ثابت
- بدء حساب المقاييس في عينة الاختبار بعد كل عصر
- حفظ معلمات النموذج بعد كل عصر
- الحفاظ على أفضل ثلاثة نماذج
- تغير في سرعة التعلم حسب العصر (جدولة معدل التعلم)
- التدريب على التوقف المبكر (التوقف المبكر)
الأحداث ومعالجات الأحداث
لإضافة الخيارات أعلاه لـ "المدرب" ، توفر مكتبة الإشعال نظام حدث وإطلاق معالجات الأحداث المخصصة. وبالتالي ، يمكن للمستخدم التحكم في كائن من فئة Engine في كل مرحلة:
- بدء تشغيل المحرك / اكتماله
- بدأ العصر / انتهى
- بدأ / انتهى تكرار الدفعة
وتشغيل التعليمات البرمجية الخاصة بك في كل حدث.
يعرض قيم دالة الخسارة
للقيام بذلك ، ما عليك سوى تحديد الوظيفة التي سيتم عرض الإخراج على الشاشة ، وإضافتها إلى "المدرب":
from ignite.engine import Events log_interval = 50 @trainer.on(Events.ITERATION_COMPLETED) def log_training_loss(engine): iteration = (engine.state.iteration - 1) % len(train_loader) + 1 if iteration % log_interval == 0: print("Epoch[{}] Iteration[{}/{}] Loss: {:.4f}" .format(engine.state.epoch, iteration, len(train_loader), engine.state.output))
في الواقع ، هناك طريقتان لإضافة معالج حدث: من خلال add_event_handler ، أو من خلال الديكور. يمكن القيام بنفس الشيء أعلاه كما يلي:
from ignite.engine import Events log_interval = 50 def log_training_loss(engine):
لاحظ أنه يمكن تمرير أي وسيطات إلى وظيفة معالجة الحدث. بشكل عام ، ستبدو هذه الوظيفة كما يلي:
def custom_handler(engine, *args, **kwargs): pass trainer.add_event_handler(Events.ITERATION_COMPLETED, custom_handler, *args, **kwargs)
لذا ، فلنبدأ التدريب في عصر واحد ونرى ما سيحدث:
output = trainer.run(train_loader, max_epochs=1)
Epoch[1] Iteration[50/322] Loss: 4.3459 Epoch[1] Iteration[100/322] Loss: 4.2801 Epoch[1] Iteration[150/322] Loss: 4.2294 Epoch[1] Iteration[200/322] Loss: 4.1467 Epoch[1] Iteration[250/322] Loss: 3.8607 Epoch[1] Iteration[300/322] Loss: 3.6688
ليس سيئا! دعنا نذهب أبعد من ذلك.
بدء حساب المقاييس على عينات التدريب والاختبار
دعونا نحسب المقاييس التالية: متوسط الدقة ومتوسط الاكتمال بعد كل فترة من فترة التدريب وعينة الاختبار بأكملها. لاحظ أننا سنحسب المقاييس من جانب عينة التدريب بعد كل فترة تدريب ، وليس أثناء التدريب. وبالتالي ، سيكون قياس الكفاءة أكثر دقة ، لأن النموذج لا يتغير أثناء الحساب.
لذا ، نحدد المقاييس:
from ignite.metrics import Loss, CategoricalAccuracy, Precision, Recall metrics = { 'avg_loss': Loss(criterion), 'avg_accuracy': CategoricalAccuracy(), 'avg_precision': Precision(average=True), 'avg_recall': Recall(average=True) }
بعد ذلك ، سنقوم بإنشاء محركين لتقييم النموذج باستخدام ignite.engine.create_supervised_evaluator :
from ignite.engine import create_supervised_evaluator
نقوم بإنشاء محركين من أجل إرفاق المزيد من معالجات الأحداث الإضافية val_evaluator ( val_evaluator ) لحفظ النموذج والتوقف عن التعلم مبكرًا (حول كل هذا أدناه).
دعونا نلقي نظرة فاحصة أيضًا على كيفية تعريف محرك تقييم النموذج ، أي كيفية تعريف وظيفة الإدخال process_function لمعالجة دفعة واحدة:
def create_supervised_evaluator(model, metrics={}, device=None): if device: model.to(device) def _inference(engine, batch): model.eval() with torch.no_grad(): x, y = _prepare_batch(batch, device=device) y_pred = model(x) return y_pred, y engine = Engine(_inference) for name, metric in metrics.items(): metric.attach(engine, name) return engine
نواصل كذلك. دعنا نختار بشكل عشوائي الجزء من عينة التدريب الذي سنحسب عليه المقاييس:
import numpy as np from torch.utils.data.dataset import Subset indices = np.arange(len(train_dataset)) random_indices = np.random.permutation(indices)[:len(val_dataset)] train_subset = Subset(train_dataset, indices=random_indices) train_eval_loader = DataLoader(train_subset, batch_size=batch_size, shuffle=True, num_workers=num_workers, drop_last=True, pin_memory="cuda" in device)
بعد ذلك ، دعنا نحدد في أي نقطة في التدريب سنبدأ حساب المقاييس وسنخرج إلى الشاشة:
@trainer.on(Events.EPOCH_COMPLETED) def compute_and_display_offline_train_metrics(engine): epoch = engine.state.epoch print("Compute train metrics...") metrics = train_evaluator.run(train_eval_loader).metrics print("Training Results - Epoch: {} Average Loss: {:.4f} | Accuracy: {:.4f} | Precision: {:.4f} | Recall: {:.4f}" .format(engine.state.epoch, metrics['avg_loss'], metrics['avg_accuracy'], metrics['avg_precision'], metrics['avg_recall'])) @trainer.on(Events.EPOCH_COMPLETED) def compute_and_display_val_metrics(engine): epoch = engine.state.epoch print("Compute validation metrics...") metrics = val_evaluator.run(val_loader).metrics print("Validation Results - Epoch: {} Average Loss: {:.4f} | Accuracy: {:.4f} | Precision: {:.4f} | Recall: {:.4f}" .format(engine.state.epoch, metrics['avg_loss'], metrics['avg_accuracy'], metrics['avg_precision'], metrics['avg_recall']))
يمكنك الركض!
output = trainer.run(train_loader, max_epochs=1)
نظهر على الشاشة
Epoch[1] Iteration[50/322] Loss: 3.5112 Epoch[1] Iteration[100/322] Loss: 2.9840 Epoch[1] Iteration[150/322] Loss: 2.8807 Epoch[1] Iteration[200/322] Loss: 2.9285 Epoch[1] Iteration[250/322] Loss: 2.5026 Epoch[1] Iteration[300/322] Loss: 2.1944 Compute train metrics... Training Results - Epoch: 1 Average Loss: 2.1018 | Accuracy: 0.3699 | Precision: 0.3981 | Recall: 0.3686 Compute validation metrics... Validation Results - Epoch: 1 Average Loss: 2.0519 | Accuracy: 0.3850 | Precision: 0.3578 | Recall: 0.3845
أفضل بالفعل!
بعض التفاصيل
دعنا ننظر إلى الرمز السابق قليلاً. ربما لاحظ القارئ سطر التعليمات البرمجية التالي:
metrics = train_evaluator.run(train_eval_loader).metrics
وربما كان هناك سؤال حول نوع الكائن الذي تم الحصول عليه من train_evaluator.run(train_eval_loader) ، الذي يحتوي على سمة metrics .
في الواقع ، تحتوي فئة Engine على بنية تسمى state (نوع State ) لتتمكن من نقل البيانات بين معالجات الأحداث. تحتوي سمة state هذه على معلومات أساسية عن العصر الحالي والتكرار وعدد العصور وما إلى ذلك. يمكن استخدامه أيضًا لنقل أي بيانات للمستخدم ، بما في ذلك نتائج حساب المقاييس.
state = train_evaluator.run(train_eval_loader) metrics = state.metrics
حساب المقاييس أثناء التدريب
إذا كانت المهمة تحتوي على عينة تدريب ضخمة وحساب المقاييس بعد كل فترة تدريب مكلفة ، ولكنك لا تزال ترغب في رؤية بعض المقاييس تتغير أثناء التدريب ، يمكنك استخدام معالج الأحداث RunningAverage التالي من الصندوق. على سبيل المثال ، نريد حساب دقة المصنف وعرضها:
acc_metric = RunningAverage(CategoryAccuracy(...), alpha=0.98) acc_metric.attach(trainer, 'running_avg_accuracy') @trainer.on(Events.ITERATION_COMPLETED) def log_running_avg_metrics(engine): print("running avg accuracy:", engine.state.metrics['running_avg_accuracy'])
لاستخدام وظيفة RunningAverage ، تحتاج إلى تثبيت الإشعال من المصادر:
pip install git+https:
جدولة معدل التعلم
هناك عدة طرق لتغيير سرعة التعلم باستخدام الإشعال . بعد ذلك ، ضع في الاعتبار أبسط طريقة عن طريق استدعاء الدالة lr_scheduler.step() في بداية كل عصر.
from torch.optim.lr_scheduler import ExponentialLR lr_scheduler = ExponentialLR(optimizer, gamma=0.8) @trainer.on(Events.EPOCH_STARTED) def update_lr_scheduler(engine): lr_scheduler.step()
حفظ أفضل النماذج والمعلمات الأخرى أثناء التدريب
أثناء التدريب ، سيكون من الرائع تسجيل أوزان أفضل نموذج على القرص ، بالإضافة إلى حفظ أوزان النموذج ومعلمات المُحسّن والمعلمات لتغيير سرعة التعلم بشكل دوري. قد يكون هذا الأخير مفيدًا لاستئناف التعلم من آخر حالة تم حفظها.
يحتوي Ignite على فئة ModelCheckpoint خاصة لهذا الغرض. لذا ، دعنا ModelCheckpoint حدث ModelCheckpoint أفضل نموذج من حيث الدقة في مجموعة الاختبار. في هذه الحالة ، نحدد دالة function_function تعطي قيمة الدقة لمعالج الأحداث وتقرر ما إذا كان سيتم حفظ النموذج أم لا:
from ignite.handlers import ModelCheckpoint def score_function(engine): val_avg_accuracy = engine.state.metrics['avg_accuracy'] return val_avg_accuracy best_model_saver = ModelCheckpoint("best_models", filename_prefix="model", score_name="val_accuracy", score_function=score_function, n_saved=3, save_as_state_dict=True, create_dir=True)
الآن قم بإنشاء ModelCheckpoint حدث ModelCheckpoint آخر للحفاظ على حالة التعلم كل 1000 تكرار:
training_saver = ModelCheckpoint("checkpoint", filename_prefix="checkpoint", save_interval=1000, n_saved=1, save_as_state_dict=True, create_dir=True) to_save = {"model": model, "optimizer": optimizer, "lr_scheduler": lr_scheduler} trainer.add_event_handler(Events.ITERATION_COMPLETED, training_saver, to_save)
لذا ، كل شيء جاهز تقريبًا ، أضف العنصر الأخير:
التدريب على التوقف المبكر (التوقف المبكر)
دعنا نضيف معالج حدث آخر سيتوقف عن التعلم إذا لم يكن هناك تحسن في جودة النموذج على مدى 10 عصور. سنقوم بتقييم جودة النموذج مرة أخرى باستخدام score_function Score_function.
from ignite.handlers import EarlyStopping early_stopping = EarlyStopping(patience=10, score_function=score_function, trainer=trainer) val_evaluator.add_event_handler(Events.EPOCH_COMPLETED, early_stopping)
ابدأ التدريب
لبدء التدريب ، يكفي أن ندعو طريقة run() . سنقوم بتدريب النموذج لمدة 10 عصور:
max_epochs = 10 output = trainer.run(train_loader, max_epochs=max_epochs)
إخراج الشاشة Learning rate: 0.01 Epoch[1] Iteration[50/322] Loss: 2.7984 Epoch[1] Iteration[100/322] Loss: 1.9736 Epoch[1] Iteration[150/322] Loss: 4.3419 Epoch[1] Iteration[200/322] Loss: 2.0261 Epoch[1] Iteration[250/322] Loss: 2.1724 Epoch[1] Iteration[300/322] Loss: 2.1599 Compute train metrics... Training Results - Epoch: 1 Average Loss: 1.5363 | Accuracy: 0.5177 | Precision: 0.5477 | Recall: 0.5178 Compute validation metrics... Validation Results - Epoch: 1 Average Loss: 1.5116 | Accuracy: 0.5139 | Precision: 0.5400 | Recall: 0.5140 Learning rate: 0.008 Epoch[2] Iteration[50/322] Loss: 1.4076 Epoch[2] Iteration[100/322] Loss: 1.4892 Epoch[2] Iteration[150/322] Loss: 1.2485 Epoch[2] Iteration[200/322] Loss: 1.6511 Epoch[2] Iteration[250/322] Loss: 3.3376 Epoch[2] Iteration[300/322] Loss: 1.3299 Compute train metrics... Training Results - Epoch: 2 Average Loss: 3.2686 | Accuracy: 0.1977 | Precision: 0.1792 | Recall: 0.1942 Compute validation metrics... Validation Results - Epoch: 2 Average Loss: 3.2772 | Accuracy: 0.1962 | Precision: 0.1628 | Recall: 0.1918 Learning rate: 0.006400000000000001 Epoch[3] Iteration[50/322] Loss: 0.9016 Epoch[3] Iteration[100/322] Loss: 1.2006 Epoch[3] Iteration[150/322] Loss: 0.8892 Epoch[3] Iteration[200/322] Loss: 0.8141 Epoch[3] Iteration[250/322] Loss: 1.4005 Epoch[3] Iteration[300/322] Loss: 0.8888 Compute train metrics... Training Results - Epoch: 3 Average Loss: 0.7368 | Accuracy: 0.7554 | Precision: 0.7818 | Recall: 0.7554 Compute validation metrics... Validation Results - Epoch: 3 Average Loss: 0.7177 | Accuracy: 0.7623 | Precision: 0.7863 | Recall: 0.7611 Learning rate: 0.005120000000000001 Epoch[4] Iteration[50/322] Loss: 0.8490 Epoch[4] Iteration[100/322] Loss: 0.8493 Epoch[4] Iteration[150/322] Loss: 0.8100 Epoch[4] Iteration[200/322] Loss: 0.9165 Epoch[4] Iteration[250/322] Loss: 0.9370 Epoch[4] Iteration[300/322] Loss: 0.6548 Compute train metrics... Training Results - Epoch: 4 Average Loss: 0.7047 | Accuracy: 0.7713 | Precision: 0.8040 | Recall: 0.7728 Compute validation metrics... Validation Results - Epoch: 4 Average Loss: 0.6737 | Accuracy: 0.7778 | Precision: 0.7955 | Recall: 0.7806 Learning rate: 0.004096000000000001 Epoch[5] Iteration[50/322] Loss: 0.6965 Epoch[5] Iteration[100/322] Loss: 0.6196 Epoch[5] Iteration[150/322] Loss: 0.6194 Epoch[5] Iteration[200/322] Loss: 0.3986 Epoch[5] Iteration[250/322] Loss: 0.6032 Epoch[5] Iteration[300/322] Loss: 0.7152 Compute train metrics... Training Results - Epoch: 5 Average Loss: 0.5049 | Accuracy: 0.8282 | Precision: 0.8393 | Recall: 0.8314 Compute validation metrics... Validation Results - Epoch: 5 Average Loss: 0.5084 | Accuracy: 0.8304 | Precision: 0.8386 | Recall: 0.8328 Learning rate: 0.0032768000000000007 Epoch[6] Iteration[50/322] Loss: 0.4433 Epoch[6] Iteration[100/322] Loss: 0.4764 Epoch[6] Iteration[150/322] Loss: 0.5578 Epoch[6] Iteration[200/322] Loss: 0.3684 Epoch[6] Iteration[250/322] Loss: 0.4847 Epoch[6] Iteration[300/322] Loss: 0.3811 Compute train metrics... Training Results - Epoch: 6 Average Loss: 0.4383 | Accuracy: 0.8474 | Precision: 0.8618 | Recall: 0.8495 Compute validation metrics... Validation Results - Epoch: 6 Average Loss: 0.4419 | Accuracy: 0.8446 | Precision: 0.8532 | Recall: 0.8442 Learning rate: 0.002621440000000001 Epoch[7] Iteration[50/322] Loss: 0.4447 Epoch[7] Iteration[100/322] Loss: 0.4602 Epoch[7] Iteration[150/322] Loss: 0.5345 Epoch[7] Iteration[200/322] Loss: 0.3973 Epoch[7] Iteration[250/322] Loss: 0.5023 Epoch[7] Iteration[300/322] Loss: 0.5303 Compute train metrics... Training Results - Epoch: 7 Average Loss: 0.4305 | Accuracy: 0.8579 | Precision: 0.8691 | Recall: 0.8596 Compute validation metrics... Validation Results - Epoch: 7 Average Loss: 0.4262 | Accuracy: 0.8590 | Precision: 0.8685 | Recall: 0.8606 Learning rate: 0.002097152000000001 Epoch[8] Iteration[50/322] Loss: 0.4867 Epoch[8] Iteration[100/322] Loss: 0.3090 Epoch[8] Iteration[150/322] Loss: 0.3721 Epoch[8] Iteration[200/322] Loss: 0.4559 Epoch[8] Iteration[250/322] Loss: 0.3958 Epoch[8] Iteration[300/322] Loss: 0.4222 Compute train metrics... Training Results - Epoch: 8 Average Loss: 0.3432 | Accuracy: 0.8818 | Precision: 0.8895 | Recall: 0.8817 Compute validation metrics... Validation Results - Epoch: 8 Average Loss: 0.3644 | Accuracy: 0.8713 | Precision: 0.8784 | Recall: 0.8707 Learning rate: 0.001677721600000001 Epoch[9] Iteration[50/322] Loss: 0.3557 Epoch[9] Iteration[100/322] Loss: 0.3692 Epoch[9] Iteration[150/322] Loss: 0.3510 Epoch[9] Iteration[200/322] Loss: 0.3446 Epoch[9] Iteration[250/322] Loss: 0.3966 Epoch[9] Iteration[300/322] Loss: 0.3451 Compute train metrics... Training Results - Epoch: 9 Average Loss: 0.3315 | Accuracy: 0.8954 | Precision: 0.9001 | Recall: 0.8982 Compute validation metrics... Validation Results - Epoch: 9 Average Loss: 0.3559 | Accuracy: 0.8818 | Precision: 0.8876 | Recall: 0.8847 Learning rate: 0.0013421772800000006 Epoch[10] Iteration[50/322] Loss: 0.3340 Epoch[10] Iteration[100/322] Loss: 0.3370 Epoch[10] Iteration[150/322] Loss: 0.3694 Epoch[10] Iteration[200/322] Loss: 0.3409 Epoch[10] Iteration[250/322] Loss: 0.4420 Epoch[10] Iteration[300/322] Loss: 0.2770 Compute train metrics... Training Results - Epoch: 10 Average Loss: 0.3246 | Accuracy: 0.8921 | Precision: 0.8988 | Recall: 0.8925 Compute validation metrics... Validation Results - Epoch: 10 Average Loss: 0.3536 | Accuracy: 0.8731 | Precision: 0.8785 | Recall: 0.8722
تحقق الآن من النماذج والمعلمات المحفوظة على القرص:
ls best_models/ model_best_model_10_val_accuracy=0.8730994.pth model_best_model_8_val_accuracy=0.8712978.pth model_best_model_9_val_accuracy=0.8818188.pth
و
ls checkpoint/ checkpoint_lr_scheduler_3000.pth checkpoint_optimizer_3000.pth checkpoint_model_3000.pth
التنبؤات من قبل نموذج مدرب
أولاً ، قم بإنشاء محمّل بيانات اختبار (على سبيل المثال ، خذ عينة للتحقق) بحيث تتكون مجموعة البيانات من الصور ومؤشراتها:
class TestDataset(Dataset): def __init__(self, ds): self.ds = ds def __len__(self): return len(self.ds) def __getitem__(self, index): return self.ds[index][0], index test_dataset = TestDataset(val_dataset) test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False, num_workers=num_workers, drop_last=False, pin_memory="cuda" in device)
باستخدام الإشعال ، سننشئ محرك تنبؤ جديد لبيانات الاختبار. للقيام بذلك ، نقوم بتعريف الوظيفة inference_update ، والتي تُرجع نتيجة التنبؤ وفهرسة الصورة. لزيادة الدقة ، سنستخدم أيضًا الحيلة المعروفة "زيادة وقت الاختبار" (TTA).
import torch.nn.functional as F from ignite._utils import convert_tensor def _prepare_batch(batch): x, index = batch x = convert_tensor(x, device=device) return x, index def inference_update(engine, batch): x, indices = _prepare_batch(batch) y_pred = model(x) y_pred = F.softmax(y_pred, dim=1) return {"y_pred": convert_tensor(y_pred, device='cpu'), "indices": indices} model.eval() inferencer = Engine(inference_update)
بعد ذلك ، قم بإنشاء معالجات الأحداث التي ستقوم بإعلامك عن مرحلة التنبؤات وحفظ التوقعات في صفيف مخصص:
@inferencer.on(Events.EPOCH_COMPLETED) def log_tta(engine): print("TTA {} / {}".format(engine.state.epoch, n_tta)) n_tta = 3 num_classes = 81 n_samples = len(val_dataset) # y_probas_tta = np.zeros((n_samples, num_classes, n_tta), dtype=np.float32) @inferencer.on(Events.ITERATION_COMPLETED) def save_results(engine): output = engine.state.output tta_index = engine.state.epoch - 1 start_index = ((engine.state.iteration - 1) % len(test_loader)) * batch_size end_index = min(start_index + batch_size, n_samples) batch_y_probas = output['y_pred'].detach().numpy() y_probas_tta[start_index:end_index, :, tta_index] = batch_y_probas
قبل بدء العملية ، لنقم بتنزيل أفضل نموذج:
model = squeezenet1_1(pretrained=False, num_classes=64) model.classifier[-1] = nn.AdaptiveAvgPool2d(1) model = model.to(device) model_state_dict = torch.load("best_models/model_best_model_10_val_accuracy=0.8730994.pth") model.load_state_dict(model_state_dict)
أطلقنا:
inferencer.run(test_loader, max_epochs=n_tta) > TTA 1 / 3 > TTA 2 / 3 > TTA 3 / 3
بعد ذلك ، بطريقة قياسية ، نأخذ متوسط تنبؤات TTA ونحسب مؤشر الفئة بأعلى احتمال:
y_probas = np.mean(y_probas_tta, axis=-1) y_preds = np.argmax(y_probas, axis=-1)
والآن يمكننا مرة أخرى حساب دقة النموذج وفقًا للتنبؤات:
from sklearn.metrics import accuracy_score y_test_true = [y for _, y in val_dataset] accuracy_score(y_test_true, y_preds) > 0.9310369676443035
, , . , , , ignite .
.
github
- fast neural transfer
- reinforcement learning
- dcgan
الخلاصة
, ignite Facebook (. ). 0.1.0, API (Engine, State, Events, Metric, ...) . , , , pull request- github .
شكرا لكم على اهتمامكم!