شركة Enron هي واحدة من أشهر الشخصيات في الأعمال الأمريكية في العقد الأول من القرن الحادي والعشرين. لم يتم تسهيل ذلك من خلال مجال نشاطهم (الكهرباء وعقود توريده) ، ولكن بسبب الرنين بسبب الاحتيال فيه. لمدة 15 عامًا ، نما دخل الشركات بسرعة ، ووعد العمل فيه براتب جيد. لكن كل هذا انتهى بنفس السرعة: في الفترة 2000-2001. انخفض سعر السهم من 90 دولارًا للوحدة إلى صفر تقريبًا بسبب كشف الاحتيال مع الدخل المعلن. منذ ذلك الحين ، أصبحت كلمة "Enron" كلمة منزلية وتعمل كعلامة للشركات التي تعمل في نمط مماثل.
خلال المحاكمة ، أدين 18 شخصًا (بما في ذلك أكبر المدعى عليهم في هذه القضية: أندرو فاستوف ، جيف سكيلينج وكينيث لاي).
![صورة! [صورة] (http: // https: //habrastorage.org/webt/te/rh/1l/terh1lsenbtg26n8nhjbhv3opfi.jpeg)](https://habrastorage.org/webt/te/rh/1l/terh1lsenbtg26n8nhjbhv3opfi.jpeg)
في الوقت نفسه ، تم نشر أرشيف للمراسلات الإلكترونية بين موظفي الشركة ، والمعروف باسم Enron Email Dataset ، والمعلومات الداخلية حول دخل موظفي هذه الشركة.
ستفحص المقالة مصادر هذه البيانات وتبني نموذجًا يعتمد عليها لتحديد ما إذا كان الشخص مشتبهًا في الاحتيال. تبدو مثيرة للاهتمام؟ ثم ، مرحباً بك في حبركت.
وصف مجموعة البيانات
مجموعة بيانات Enron (مجموعة البيانات) هي مجموعة مركبة من البيانات المفتوحة التي تحتوي على سجلات الأشخاص الذين يعملون في شركة لا تنسى بالاسم المقابل.
يمكن أن يميز 3 أجزاء:
- payments_features - مجموعة تميز الحركات المالية ؛
- stock_features - مجموعة تعكس العلامات المرتبطة بالأسهم ؛
- email_features - مجموعة تعكس معلومات حول رسائل البريد الإلكتروني لشخص معين في شكل مجمع.
بالطبع ، هناك أيضًا متغير هدف يشير إلى ما إذا كان الشخص مشتبهًا في الاحتيال (علامة "poi" ).
قم بتنزيل بياناتنا وابدأ العمل معهم:
import pickle with open("final_project/enron_dataset.pkl", "rb") as data_file: data_dict = pickle.load(data_file)
بعد ذلك ، نقوم بتحويل مجموعة data_dict إلى Pandas dataframe لمزيد من العمل المريح مع البيانات:
import pandas as pd import warnings warnings.filterwarnings('ignore') source_df = pd.DataFrame.from_dict(data_dict, orient = 'index') source_df.drop('TOTAL',inplace=True)
نقوم بتجميع العلامات وفقًا للأنواع المشار إليها سابقًا. سيؤدي ذلك إلى تسهيل العمل بالبيانات بعد ذلك:
payments_features = ['salary', 'bonus', 'long_term_incentive', 'deferred_income', 'deferral_payments', 'loan_advances', 'other', 'expenses', 'director_fees', 'total_payments'] stock_features = ['exercised_stock_options', 'restricted_stock', 'restricted_stock_deferred','total_stock_value'] email_features = ['to_messages', 'from_poi_to_this_person', 'from_messages', 'from_this_person_to_poi', 'shared_receipt_with_poi'] target_field = 'poi'
البيانات المالية
في مجموعة البيانات هذه يوجد NaN معروف للكثيرين ، ويعبر عن الفجوة المعتادة في البيانات. بمعنى آخر ، لم يتمكن مؤلف مجموعة البيانات من العثور على أي معلومات حول سمة معينة مرتبطة بسطر معين في إطار البيانات. نتيجة لذلك ، يمكننا أن نفترض أن NaN يساوي 0 ، لأنه لا توجد معلومات حول سمة معينة.
payments = source_df[payments_features] payments = payments.replace('NaN', 0)
التحقق من البيانات
عند المقارنة مع ملف PDF الأصلي الكامن وراء مجموعة البيانات ، اتضح أن البيانات مشوهة قليلاً ، لأنه ليس لجميع البنود في إطار بيانات المدفوعات ، فإن حقل total_payments هو مجموع جميع المعاملات المالية لهذا الشخص. يمكنك التحقق من ذلك على النحو التالي:
errors = payments[payments[payments_features[:-1]].sum(axis='columns') != payments['total_payments']] errors.head()

نرى أن BELFER ROBERT و BHATNAGAR SANJAY لديهما مبالغ دفع غير صحيحة.
يمكنك إصلاح هذا الخطأ عن طريق نقل البيانات في سطور الخطأ إلى اليسار أو اليمين واحتساب مجموع جميع المدفوعات مرة أخرى:
import numpy as np shifted_values = payments.loc['BELFER ROBERT', payments_features[1:]].values expected_payments = shifted_values.sum() shifted_values = np.append(shifted_values, expected_payments) payments.loc['BELFER ROBERT', payments_features] = shifted_values shifted_values = payments.loc['BHATNAGAR SANJAY', payments_features[:-1]].values payments.loc['BHATNAGAR SANJAY', payments_features] = np.insert(shifted_values, 0, 0)
بيانات المخزون
stocks = source_df[stock_features] stocks = stocks.replace('NaN', 0)
قم بإجراء التحقق من الصحة في هذه الحالة أيضًا:
errors = stocks[stocks[stock_features[:-1]].sum(axis='columns') != stocks['total_stock_value']] errors.head()

وبالمثل ، سوف نقوم بإصلاح الخطأ في الأسهم:
shifted_values = stocks.loc['BELFER ROBERT', stock_features[1:]].values expected_payments = shifted_values.sum() shifted_values = np.append(shifted_values, expected_payments) stocks.loc['BELFER ROBERT', stock_features] = shifted_values shifted_values = stocks.loc['BHATNAGAR SANJAY', stock_features[:-1]].values stocks.loc['BHATNAGAR SANJAY', stock_features] = np.insert(shifted_values, 0, shifted_values[-1])
مراسلات البريد الإلكتروني
إذا كانت NaN لهذه الأموال أو الأسهم تعادل 0 ، وهذا يتناسب مع النتيجة النهائية لكل من هذه المجموعات ، في حالة البريد الإلكتروني ، يكون NaN أكثر منطقية للاستبدال ببعض القيمة الافتراضية. للقيام بذلك ، يمكنك استخدام Imputer:
from sklearn.impute import SimpleImputer imp = SimpleImputer()
في الوقت نفسه ، سنأخذ في الاعتبار القيمة الافتراضية لكل فئة (سواء اشتبهنا في وجود شخص محتال) بشكل منفصل:
target = source_df[target_field] email_data = source_df[email_features] email_data = pd.concat([email_data, target], axis=1) email_data_poi = email_data[email_data[target_field]][email_features] email_data_nonpoi = email_data[email_data[target_field] == False][email_features] email_data_poi[email_features] = imp.fit_transform(email_data_poi) email_data_nonpoi[email_features] = imp.fit_transform(email_data_nonpoi) email_data = email_data_poi.append(email_data_nonpoi)
مجموعة البيانات النهائية بعد التصحيح:
df = payments.join(stocks) df = df.join(email_data) df = df.astype(float)
الانبعاثات
في الخطوة الأخيرة من هذه المرحلة ، سنقوم بإزالة جميع القيم المتطرفة ، والتي يمكن أن تشوه التدريب. في الوقت نفسه ، يطرح السؤال دائمًا: ما مقدار البيانات التي يمكننا إزالتها من العينة وما زلت لا نفقد كنموذج مدرب؟ اتبعت نصيحة أحد المحاضرين في دورة ML (تعلم الآلة) حول Udacity - "قم بإزالة 10 وتحقق من الانبعاثات مرة أخرى".
first_quartile = df.quantile(q=0.25) third_quartile = df.quantile(q=0.75) IQR = third_quartile - first_quartile outliers = df[(df > (third_quartile + 1.5 * IQR)) | (df < (first_quartile - 1.5 * IQR))].count(axis=1) outliers.sort_values(axis=0, ascending=False, inplace=True) outliers = outliers.head(10) outliers
في الوقت نفسه ، لن نقوم بحذف السجلات المتطرفة والتي يشتبه في أنها احتيالية. والسبب هو أنه لا يوجد سوى 18 صفًا بهذه البيانات ، ولا يمكننا التضحية بها ، لأن هذا يمكن أن يؤدي إلى نقص الأمثلة التدريبية. ونتيجة لذلك ، فإننا نزيل فقط أولئك الذين لا يشتبه في أنهم احتيال ، ولكن في نفس الوقت لديهم عدد كبير من العلامات التي يتم من خلالها ملاحظة الانبعاثات:
target_for_outliers = target.loc[outliers.index] outliers = pd.concat([outliers, target_for_outliers], axis=1) non_poi_outliers = outliers[np.logical_not(outliers.poi)] df.drop(non_poi_outliers.index, inplace=True)
إنهاء
نقوم بتطبيع بياناتنا:
from sklearn.preprocessing import scale df[df.columns] = scale(df)
يتيح استهداف المتغير الهدف إلى طريقة عرض متوافقة:
target.drop(non_poi_outliers.index, inplace=True) target = target.map({True: 1, False: 0}) target.value_counts()

ونتيجة لذلك ، كان 18 مشتبهاً بهم و 121 ممن لم يلقوا شبهات.
اختيار الميزة
ربما تكون إحدى أهم النقاط قبل تعلم أي نموذج هي اختيار أهم الميزات.
اختبار التعددية الخطية
import matplotlib.pyplot as plt import seaborn as sns %matplotlib inline sns.set(style="whitegrid") corr = df.corr() * 100 # Select upper triangle of correlation matrix mask = np.zeros_like(corr, dtype=np.bool) mask[np.triu_indices_from(mask)] = True # Set up the matplotlib figure f, ax = plt.subplots(figsize=(15, 11)) # Generate a custom diverging colormap cmap = sns.diverging_palette(220, 10) # Draw the heatmap with the mask and correct aspect ratio sns.heatmap(corr, mask=mask, cmap=cmap, center=0, linewidths=1, cbar_kws={"shrink": .7}, annot=True, fmt=".2f")
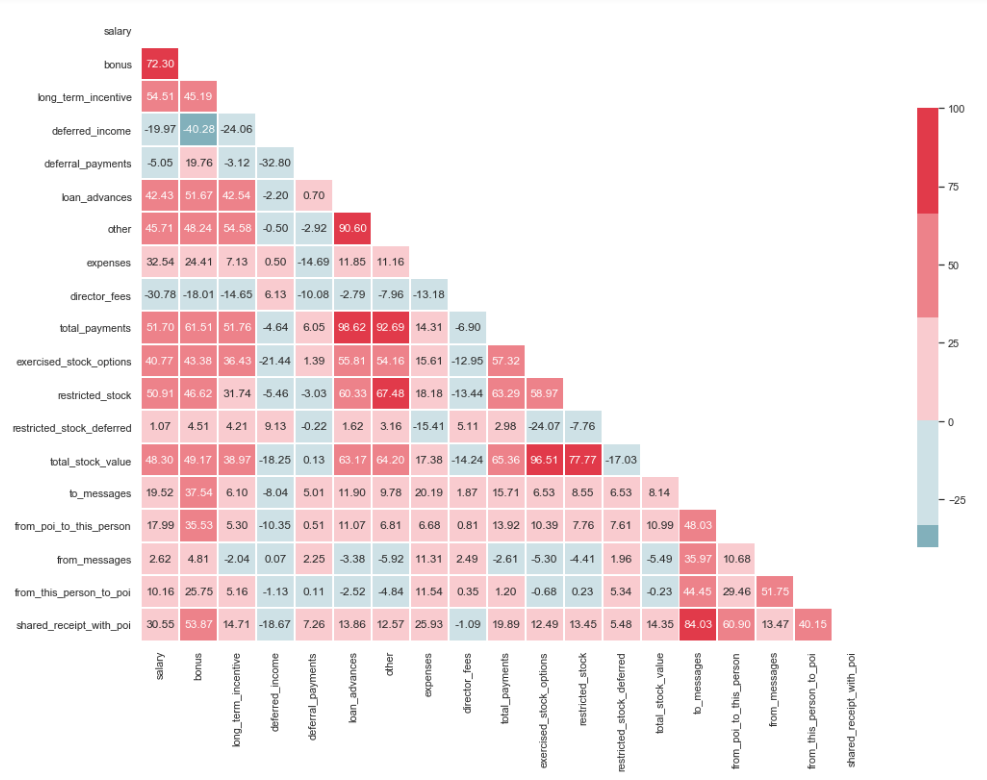
كما ترون من الصورة ، لدينا علاقة واضحة بين "loan_advanced" و "total_payments" ، وكذلك بين "total_stock_value" و "limited_stock". كما ذكرنا سابقًا ، فإن "total_payments" و "total_stock_value" ما هي إلا نتيجة لإضافة جميع المؤشرات في مجموعة معينة. لذلك ، يمكن حذفها:
df.drop(columns=['total_payments', 'total_stock_value'], inplace=True)
خلق خصائص جديدة
هناك أيضا افتراض أن المشتبه بهم كتبوا للشركاء أكثر من الموظفين الذين لم يشاركوا في ذلك. ونتيجة لذلك ، يجب أن تكون نسبة هذه الرسائل أكبر من نسبة الرسائل إلى الموظفين العاديين. استنادًا إلى هذا البيان ، يمكنك إنشاء علامات جديدة تعكس النسبة المئوية الواردة / الصادرة المتعلقة بالمشتبه بهم:
df['ratio_of_poi_mail'] = df['from_poi_to_this_person']/df['to_messages'] df['ratio_of_mail_to_poi'] = df['from_this_person_to_poi']/df['from_messages']
فحص العلامات غير الضرورية
في مجموعة أدوات الأشخاص المرتبطين بـ ML ، هناك العديد من الأدوات الممتازة لاختيار أهم الميزات (SelectKBest و SelectPercentile و VarianceThreshold وما إلى ذلك). في هذه الحالة ، سيتم استخدام RFECV ، لأنه يتضمن التحقق المتبادل ، والذي يسمح لك بحساب أهم الميزات والتحقق منها على جميع المجموعات الفرعية للعينة:
from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(df, target, test_size=0.2, random_state=42)
from sklearn.feature_selection import RFECV from sklearn.ensemble import RandomForestClassifier forest = RandomForestClassifier(random_state=42) rfecv = RFECV(estimator=forest, cv=5, scoring='accuracy') rfecv = rfecv.fit(X_train, y_train) plt.figure() plt.xlabel("Number of features selected") plt.ylabel("Cross validation score of number of selected features") plt.plot(range(1, len(rfecv.grid_scores_) + 1), rfecv.grid_scores_, '--o') indices = rfecv.get_support() columns = X_train.columns[indices] print('The most important columns are {}'.format(','.join(columns)))
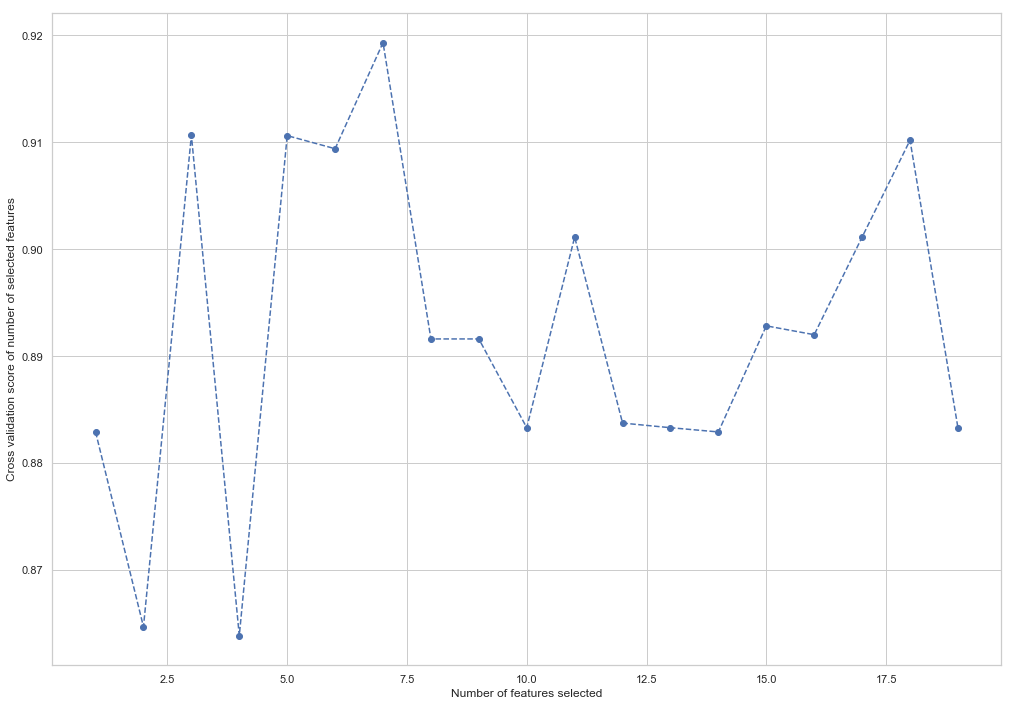
كما ترى ، حسبت RandomForestClassifier أن 7 سمات فقط من 18 سمة مهمة. يؤدي استخدام الباقي إلى انخفاض في دقة النموذج.
The most important columns are bonus, deferred_income, other, exercised_stock_options, shared_receipt_with_poi, ratio_of_poi_mail, ratio_of_mail_to_poi
سيتم استخدام هذه الميزات السبع في المستقبل من أجل تبسيط النموذج وتقليل مخاطر إعادة التدريب:
- مكافأة
- دخل مؤجل
- أخرى
- ممارسة_المخزون_اختيارات
- Shared_receipt_with_poi
- نسبة_بوي_بوي
- نسبة_البريد_البريد
تغيير هيكل التدريب وعينات الاختبار للتدريب النموذجي في المستقبل:
X_train = X_train[columns] X_test = X_test[columns]
هذا هو نهاية الجزء الأول الذي يصف استخدام مجموعة بيانات Enron كمثال لمهمة التصنيف في اللغة الإنجليزية. استنادًا إلى المواد من دورة مقدمة في تعلُم الآلة على Udacity. هناك أيضًا دفتر ملاحظات بيثون يعكس التسلسل الكامل للأفعال.
الجزء الثاني هنا