الجوهر
اتضح أنه لهذا يكفي تشغيل مثل هذه المجموعة من الأوامر:
git clone https://github.com/attardi/wikiextractor.git cd wikiextractor wget http://dumps.wikimedia.org/ruwiki/latest/ruwiki-latest-pages-articles.xml.bz2 python3 WikiExtractor.py -o ../data/wiki/ --no-templates --processes 8 ../data/ruwiki-latest-pages-articles.xml.bz2
ثم صقل قليلاً باستخدام برنامج نصي للمعالجة اللاحقة
python3 process_wikipedia.py
والنتيجة هي ملف .csv منتهي .csv .
من الواضح أن:
- يمكن تغيير
http://dumps.wikimedia.org/ruwiki/latest/ruwiki-latest-pages-articles.xml.bz2 إلى اللغة التي تحتاج إليها ، مزيد من التفاصيل هنا [4] ؛ - يمكن العثور على جميع المعلومات حول معلمات
wikiextractor في الدليل (يبدو أنه لم يتم تحديث الرصيف الرسمي ، على عكس mana) ؛
يعمل النص البرمجي لما بعد المعالجة على تحويل ملفات wiki إلى جدول مثل هذا:
| idx | article_uuid | الجملة | جملة نظيفة | تنظيف طول الجملة |
|---|
| 0 | 74fb822b-54bb-4bfb-95ef-4eac9465c7d7 | Jean I de Chatillon (Count de Pentevre) جان الأول دي ... | jean i de châtillon count de pentevre jean i de cha ... | 38 |
| 1 | 74fb822b-54bb-4bfb-95ef-4eac9465c7d7 | كان تحت حماية روبرت دي فيرا ، الكونت يا ... | كان يحرسه روبرت دي فيرا الرسم البياني أكسفورد ... | 18 |
| 2 | 74fb822b-54bb-4bfb-95ef-4eac9465c7d7 | ومع ذلك ، هنري دي Gromont ، غرام ... | ومع ذلك ، عارض هنري دي جرومون هذا ... | 14 |
| 3 | 74fb822b-54bb-4bfb-95ef-4eac9465c7d7 | قدم له الملك ميزة مهمة أخرى كزوجة ... | قدم الملك لزوجته شخصًا آخر مهمًا من فلي ... | 48 |
| 4 | 74fb822b-54bb-4bfb-95ef-4eac9465c7d7 | تم الإفراج عن جان وعاد إلى فرنسا عام 138 ... | جان حررت فرنسا العام الزفاف م ... | 52 |
article_uuid - مفتاح فريد زائف ، يجب الحفاظ على ترتيب الفكرة بعد المعالجة المسبقة.
لماذا
ربما ، في الوقت الحالي ، وصل تطوير أدوات ML إلى هذا المستوى [8] الذي يكفي حرفيا يومين لبناء نموذج / خط أنابيب NLP عامل. تنشأ المشاكل فقط في حالة عدم وجود مجموعات بيانات موثوقة / تضمين جاهز / نماذج لغة جاهزة. الغرض من هذه المقالة هو تخفيف ألمك قليلاً من خلال إظهار أن ساعتين تكفي لمعالجة ويكيبيديا بأكملها (من الناحية النظرية هي المجموعة الأكثر شيوعًا لتدريب تضمين الكلمات في البرمجة اللغوية العصبية). بعد كل شيء ، إذا كان بضعة أيام كافية لبناء نموذج بسيط ، فلماذا تقضي وقتًا أطول في الحصول على بيانات لهذا النموذج؟
مبدأ النص
يحفظ wikiExtractor مقالات Wiki كنص مفصولة بواسطة كتل <doc> . في الواقع ، يعتمد البرنامج النصي على المنطق التالي:
- خذ قائمة بجميع الملفات في الإخراج ؛
- نقسم الملفات إلى مقالات.
- إزالة كافة علامات HTML المتبقية والأحرف الخاصة ؛
- باستخدام
nltk.sent_tokenize نقسم إلى جمل. - بحيث لا تنمو التعليمات البرمجية إلى حجم كبير وتبقى قابلة للقراءة ، يتم تعيين uuid كل مقالة خاصة بها ؛
كمعالجة نصية ، إنها بسيطة (يمكنك قصها بنفسك بسهولة):
- حذف الأحرف غير الحروفية ؛
- حذف كلمات التوقف ؛
مجموعة البيانات ، ماذا الآن؟
التطبيق الرئيسي
في معظم الأحيان ، في الممارسة العملية ، في NLP عليك التعامل مع مهمة بناء التضمين.
لحلها ، عادة ما تستخدم إحدى الأدوات التالية:
- المتجهات الجاهزة / تضمين الكلمات [6] ؛
- تم تدريب الحالات الداخلية لشبكة CNN على مهام مثل تحديد الجمل / نماذج اللغة / التصنيف الزائف [7] ؛
- مزيج من الأساليب المذكورة أعلاه ؛
بالإضافة إلى ذلك ، فقد ثبت عدة مرات [9] أنه كخط أساس جيد لتضمين الجمل ، يمكنك ببساطة أن تأخذ متوسّط الكلمات (المتوسط مع بعض التفاصيل الصغيرة ، التي سنحذفها الآن).
حالات استخدام أخرى
- نستخدم جمل عشوائية من ويكي كمثال سلبي لفقدان ثلاثية ؛
- نقوم بتدريب برامج التشفير على الجمل باستخدام تعريف العبارات المزيفة [10] ؛
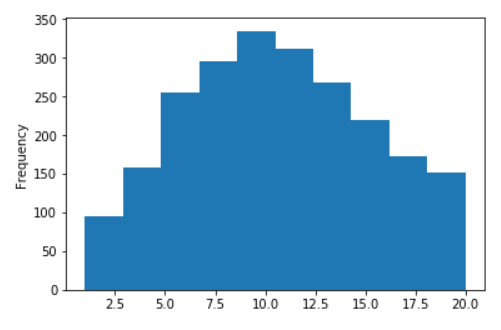
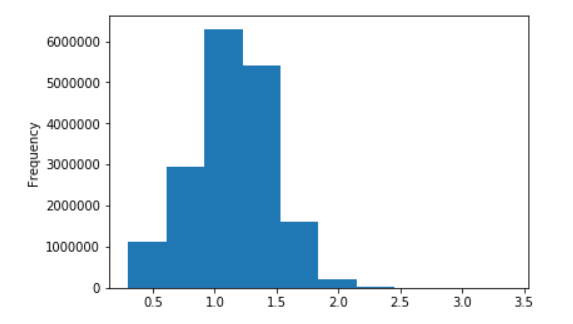
بعض الرسوم البيانية للويكي الروسي
توزيع طول جمل ويكيبيديا الروسية
لا لوغاريتمات (على المحور X ، تقتصر القيم على 20)
في اللوغاريتمات العشرية
المراجع
- تم تدريب ناقلات كلمة النص السريع على ويكي ؛
- نماذج النص السريع و Word2Vec للغة الروسية ؛
- مكتبة مستخرجة ويكي رهيبة لثعبان ؛
- الصفحة الرسمية مع روابط ويكي ؛
- برنامجنا النصي لما بعد المعالجة ؛
- المقالات الرئيسية حول تضمين الكلمات: Word2Vec ، Fast-Text ، tuning ؛
- العديد من مناهج SOTA الحالية:
- الاستدلال ؛
- CNN التكوين المسبق التدريب ؛
- ULMFiT ؛
- النهج السياقية لتمثيل الكلمات (Elmo) ؛
- لحظة Imagenet في البرمجة اللغوية العصبية ؟
- خطوط الأساس لتضمين المقترحات 1 و 2 و 3 و 4 ؛
- تعريف العبارات المزيفة لبرنامج التشفير ؛