أقدم لك الجزء الثاني من المقالة حول البحث عن الاحتيال المشتبه به بناءً على بيانات من Enron Dataset. إذا لم تكن قد قرأت الجزء الأول ، فيمكنك التعرف عليه هنا .
الآن سنتحدث عن عملية بناء وتحسين واختيار نموذج يعطي الإجابة: هل يستحق الشك في شخص احتيالي؟
في وقت سابق ، قمنا بتحليل إحدى مجموعات البيانات المفتوحة التي توفر معلومات حول المشتبه بهم في قضية إنرون والاحتيال فيها. أيضا ، تم تصحيح التحيز في البيانات الأولية ، وسد الثغرات (NaN) ، وبعد ذلك تم تطبيع البيانات واكتمل اختيار السمات.
كانت النتيجة مألوفة للكثيرين:
- X_train و y_train - العينة المستخدمة للتدريب (111 سجل) ؛
- X_test و y_test - عينة يتم فيها التحقق من صحة تنبؤات نماذجنا (28 إدخالاً).
الحديث عن النماذج ... من أجل التنبؤ بشكل صحيح بما إذا كان الأمر يستحق الشك في شخص ما ، بناءً على بعض العلامات التي تميز أنشطته ، سنستخدم التصنيف. يمكن أخذ الأنواع الرئيسية من النماذج المستخدمة لحل المشكلات في هذا الجزء من Sklearn:
- ساذجة بايز (مصنف ساذج بايز) ؛
- SVM (جهاز ناقل مرجعي) ؛
- أقرب الجيران K (طريقة للعثور على أقرب الجيران) ؛
- غابة عشوائية (غابة عشوائية) ؛
- الشبكة العصبية.
هناك أيضًا صورة توضح قابليتها للتطبيق بشكل جيد:
من بينها هناك شجرة القرار (شجرة القرار) ، مألوفة للكثيرين ، ولكن ، ربما ، ليس من المنطقي في مهمة واحدة استخدام هذه الطريقة مع Random Forest ، وهي مجموعة من أشجار القرار. لذلك ، استبدلها بالانحدار اللوجستي ، الذي يمكن أن يعمل كمصنف وينتج أحد الخيارات المتوقعة (0 أو 1).
ابدأ
نقوم بتهيئة جميع المصنفات المذكورة بقيم افتراضية:
from sklearn.naive_bayes import GaussianNB from sklearn.linear_model import LogisticRegression from sklearn.neighbors import KNeighborsClassifier from sklearn.svm import SVC from sklearn.neural_network import MLPClassifier from sklearn.ensemble import RandomForestClassifier random_state = 42 gnb = GaussianNB() svc = SVC() knn = KNeighborsClassifier() log = LogisticRegression(random_state=random_state) rfc = RandomForestClassifier(random_state=random_state) mlp = MLPClassifier(random_state=random_state)
سنقوم أيضًا بتجميعها بحيث يكون من الأسهل العمل معها كمجموع ، بدلاً من كتابة التعليمات البرمجية لكل فرد. على سبيل المثال ، يمكننا تدريبهم جميعًا مرة واحدة:
classifiers = [gnb, svc, knn, log, rfc, mlp] for clf in classifiers: clf.fit(X_train, y_train)
بعد تدريب النماذج ، حان الوقت لإجراء أول اختبار لجودة التنبؤ بها. بالإضافة إلى ذلك ، نتصور نتائجنا باستخدام Seaborn:
from sklearn.metrics import accuracy_score def calculate_accuracy(X, y): result = pd.DataFrame(columns=['classifier', 'accuracy']) for clf in classifiers: predicted = clf.predict(X_test) accuracy = round(100.0 * accuracy_score(y_test, predicted), 2) classifier = clf.__class__.__name__ classifier = classifier.replace('Classifier', '') result = result.append({'classifier': classifier, 'accuracy': accuracy}, ignore_index=True) print('Accuracy is {accuracy}% for {classifier_name}'.format(accuracy=accuracy, classifier_name=classifier)) result = result.sort_values(['classifier'], ascending=True) plt.subplots(figsize=(10, 7)) sns.barplot(x="classifier", y='accuracy', palette=cmap, data=result)
دعونا نلقي نظرة على الفكرة العامة لدقة المصنفات:
calculate_accuracy(X_train, y_train)
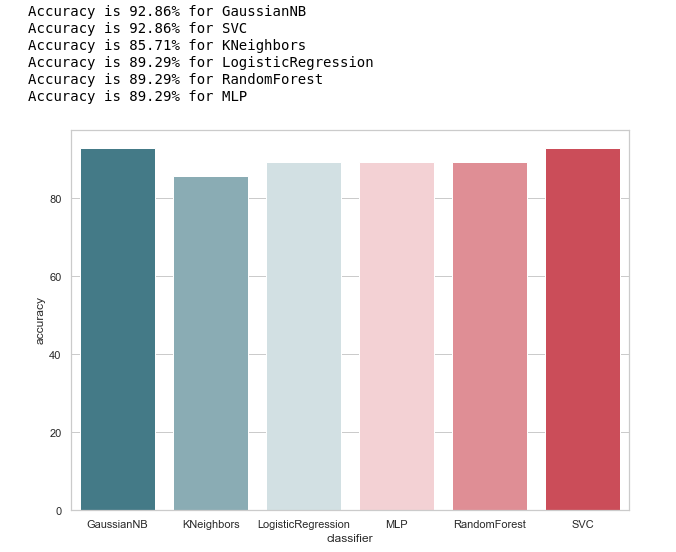
للوهلة الأولى ، تبدو جيدة جدًا ، وتتقلب دقة التنبؤات على عينة الاختبار بنسبة 90٪ تقريبًا. يبدو أن المهمة رائعة!
في الواقع ، ليس كل شيء وردية للغاية.الدقة العالية ليست ضمانًا للتنبؤات الصحيحة. تحتوي عينة الاختبار الخاصة بنا على 28 سجلًا ، 4 منها تتعلق بالمشتبه بهم ، و 24 سجلًا لمن هم خارج الشك. تخيل أننا أنشأنا نوعًا من خوارزمية الشكل:
def QuaziAlgo(features): return 0
ثم أعطوه عينة الاختبار عند المدخل ، واستلموا أن جميع الأشخاص الـ 28 كانوا أبرياء. ماذا ستكون دقة الخوارزمية في هذه الحالة؟

ومن المثير للاهتمام أن KNeighbours لديها دقة التنبؤ نفسها ...
ولكن مع ذلك ، قبل أن نمدح أنفسنا ، دعونا نبني مصفوفة ارتباك لنتائج التنبؤ:
from sklearn.metrics import confusion_matrix def make_confussion_matrices(X, y): matrices = {} result = pd.DataFrame(columns=['classifier', 'recall']) for clf in classifiers: classifier = clf.__class__.__name__ classifier = classifier.replace('Classifier', '') predicted = clf.predict(X_test) print(f'{predicted}-{classifier}') matrix = confusion_matrix(y_test,predicted,labels=[1,0]) matrices[classifier] = matrix.T return matrices
نحسب مصفوفات الخطأ لكل مصنف ، ونرى مع ذلك ما توقعوه:
matrices = make_confussion_matrices(X_train,y_train)

حتى التمثيل النصي لنتيجة عمل المصنفات يكفي لفهم أن هناك خطأ ما واضح.
لم تكشف أقرب طريقة من الجيران عن مشتبه به واحد في عينة الاختبار على الإطلاق. ينشأ سؤالان:
- ما سبب هذا السلوك لمصنف KNeighbours؟
- لماذا قمنا ببناء مصفوفات الخطأ إذا لم نستخدمها ، ولكن فقط انظر إلى نتائج التنبؤ؟
نلقي نظرة أعمق
لنبدأ بالسؤال الثاني. دعونا نحاول تصور مصفوفات الأخطاء الخاصة بنا وتقديم البيانات في شكل رسوم بيانية لفهم مكان حدوث خطأ التصنيف:
import itertools from collections import Iterable def draw_confussion_matrices(row,col,matrices,figsize = (16,12)): fig, (axes) = plt.subplots(row,col, sharex='col', sharey='row',figsize=figsize ) if any(isinstance(i, Iterable) for i in axes): axes = list(itertools.chain.from_iterable(axes)) idx = 0 for name,matrix in matrices.items(): df_cm = pd.DataFrame( matrix, index=['True','False'], columns=['True','False'], ) ax = axes[idx] fig.subplots_adjust(wspace=0.1) sns.heatmap(df_cm, annot=True,cmap=cmap,cbar=False ,fmt="d",ax=ax,linewidths=1) ax.set_title(name) idx += 1
نعرضها في صفين و 3 أعمدة:
draw_confussion_matrices(2,3,matrices)
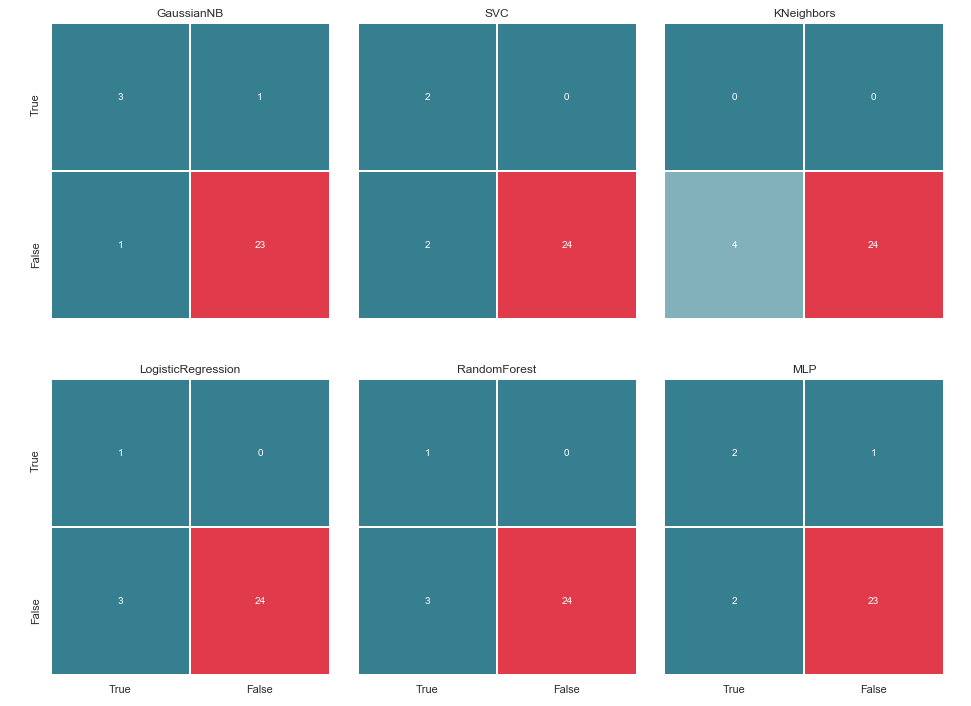
قبل المتابعة ، يجدر إعطاء بعض التوضيح. التعيين True ، الذي يقع على يسار مصفوفة الخطأ لمصنف معين ، يعني أن المصنف اعتبر الشخص مشتبهًا به ، والقيمة False تعني أن هذا الشخص خارج الشك. وبالمثل ، فإن True و False في أسفل الصورة يعطينا حالة حقيقية ، والتي قد لا تتزامن مع قرار المصنف.
على سبيل المثال ، نرى أن قرارات KNebors بدقة دقة 85.71٪ تزامنت مع الوضع الحقيقي عندما تم تضمين 24 شخصًا ، كانوا خارج الشك ، في قائمة مماثلة من قبل المصنف. ولكن تم تضمين 4 أشخاص من قائمة المشتبه بهم في هذه القائمة. إذا اتخذ هذا المصنف قرارات ، فربما كان بإمكان شخص ما تجنب المحكمة.
وبالتالي ، تعد مصفوفات الخطأ أداة جيدة جدًا لفهم الأخطاء التي حدثت في مشكلات التصنيف. ميزتها الرئيسية هي الرؤية ، وبالتالي نناشدهم.
المقاييس
بشكل عام ، يمكن توضيح ذلك بالصورة التالية:

وما هو TP و TN و FP ونوع من FN في هذه الحالة؟
وبعبارة أخرى ، نحن نسعى جاهدين لضمان تطابق إجابات المصنف والوضع الحقيقي. أي لضمان توزيع جميع الأرقام بين الخلايا TP و TN (حلول حقيقية) ولا تقع في FN و FP (حلول خاطئة).
ليس كل شيء دائمًا مثيرًا للغاية ولا لبس فيهعلى سبيل المثال ، في الحالة القانونية لتشخيص السرطان ، يفضل FP على FN ، لأنه في حالة الحكم الكاذب على السرطان ، سيتم وصف المريض للأدوية وسيتم علاجه. نعم ، سيؤثر ذلك على صحته ومحفظته ، ولكن لا يزال يعتبر أقل خطورة من FN والفترة الضائعة التي يمكن فيها هزيمة السرطان بوسائل صغيرة.
ماذا عن المشتبه بهم في قضيتنا؟ FN ربما ليست سيئة مثل FP. ولكن المزيد عن ذلك لاحقًا ...
وبما أننا نتحدث عن الاختصارات ، فقد حان الوقت لاستعادة مقاييس الدقة (الدقة) والاكتمال (الاستدعاء).
إذا خرجت عن السجل الرسمي ، فيمكن التعبير عن الدقة على النحو التالي:
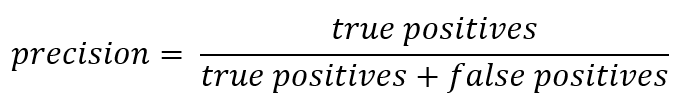
وبعبارة أخرى ، يتم الاحتفاظ بحساب عدد الردود الإيجابية التي تم تلقيها من المصنف صحيحة. كلما زادت الدقة ، قل عدد النتائج الزائفة (الدقة هي 1 إذا لم يكن هناك FPs).
يتم تقديم الاستدعاء بشكل عام على النحو التالي:
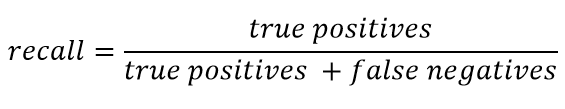
يصف الاستدعاء قدرة المصنف على "تخمين" أكبر عدد ممكن من الإجابات الإيجابية. كلما زاد الاكتمال ، انخفض FN.
عادة ما يحاولون الموازنة بين الاثنين ، ولكن في هذه الحالة سيتم إعطاء الأولوية تمامًا لـ Precision. السبب: نهج أكثر إنسانية ، والرغبة في تقليل عدد الإيجابيات الكاذبة ، ونتيجة لذلك ، لتجنب الوقوع في الشك على الأبرياء.
نحسب الدقة لمصنفاتنا:
from sklearn.metrics import precision_score def calculate_precision(X, y): result = pd.DataFrame(columns=['classifier', 'precision']) for clf in classifiers: predicted = clf.predict(X_test) precision = precision_score(y_test, predicted, average='macro') classifier = clf.__class__.__name__ classifier = classifier.replace('Classifier', '') result = result.append({'classifier': classifier, 'precision': precision}, ignore_index=True) print('Precision is {precision} for {classifier_name}'.format(precision=round(precision,2), classifier_name=classifier)) result = result.sort_values(['classifier'], ascending=True) plt.subplots(figsize=(10, 7)) sns.barplot(x="classifier", y='precision', palette=cmap, data=result) calculate_precision(X_train, y_train)
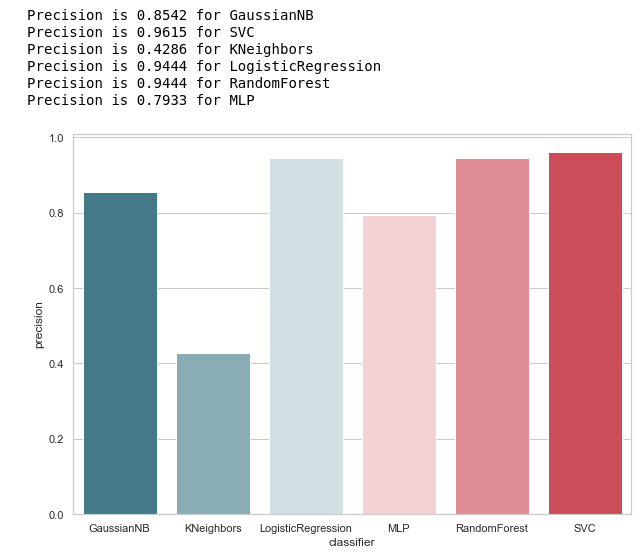
على النحو التالي من الشكل ، تم إصداره كما هو متوقع: تبين أن دقة KNeighbours هي الأدنى ، لأن قيمة TP هي الأدنى.
في الوقت نفسه ، هناك مقال جيد عن المقاييس في حبري ، وأولئك الذين يريدون التعمق في هذا الموضوع يجب أن يتعرفوا عليه.
تحديد معلمة فرط
بعد العثور على المقياس الأنسب للظروف المحددة (نقوم بتقليل عدد FPs) ، يمكننا العودة إلى السؤال الأول: ما سبب هذا السلوك لمصنف KNeighbours؟
السبب يكمن في الإعدادات الافتراضية التي تم إنشاء هذا النموذج بها. وعلى الأرجح ، يمكن أن يصرخ كثيرون في هذه المرحلة: لماذا التدريب على المعلمات الافتراضية؟ هناك أدوات تحديد خاصة ، على سبيل المثال ، GridSearchCV الذي يستخدم غالبًا.
نعم ، لقد حان الوقت للجوء إليه ،
ولكن قبل ذلك ، قمنا بإزالة المصنف Bayesian من قائمتنا. تسمح FP واحد ، وفي نفس الوقت ، لا تقبل هذه الخوارزمية أي معلمات متغيرة ، ونتيجة لذلك لن تتغير النتيجة.
classifiers.remove(gnb)
ضبط دقيق
نحدد شبكة من المعلمات لكل مصنف:
parameters = {'SVC':{'kernel':('linear', 'rbf','poly'), 'C':[i for i in range(1,11)],'random_state': (random_state,)}, 'KNeighbors':{'algorithm':('ball_tree', 'kd_tree'), 'n_neighbors':[i for i in range(2,20)]}, 'LogisticRegression':{'penalty':('l1', 'l2'), 'C':[i for i in range(1,11)],'random_state': (random_state,)}, 'RandomForest':{'n_estimators':[i for i in range(10,101,10)],'random_state': (random_state,)}, 'MLP':{'activation':('relu','logistic'),'solver':('sgd','lbfgs'),'max_iter':(500,1000), 'hidden_layer_sizes':[(7,),(7,7)],'random_state': (random_state,)}}
بالإضافة إلى ذلك ، أردت الانتباه إلى عدد الطبقات / الخلايا العصبية في MLP.
تقرر عدم وضعها من خلال البحث الشامل لجميع القيم الممكنة ، ولكن لا تزال قائمة على الصيغة :
أريد أن أقول على الفور ، سيتم التدريب والتحقق المتبادل فقط على عينة التدريب. أفترض أن هناك رأيًا يمكنك القيام بذلك على جميع البيانات ، كما هو الحال في المثال مع Iris Dataset. ولكن ، في رأيي ، هذا النهج ليس له ما يبرره تمامًا ، لأنه لن يكون من الممكن الوثوق في نتائج التحقق على عينة اختبار.
سننفذ التحسين ونستبدل مصنفاتنا بنسختها المحسنة:
from sklearn.model_selection import GridSearchCV warnings.filterwarnings('ignore') for idx,clf in enumerate(classifiers): classifier = clf.__class__.__name__ classifier = classifier.replace('Classifier', '') params = parameters.get(classifier) if not params: continue new_clf = clf.__class__() gs = GridSearchCV(new_clf, params, cv=5) result =gs.fit(X_train, y_train) print(f'The best params for {classifier} are {result.best_params_}') classifiers[idx] = result.best_estimator_

بعد اختيار مقياس للتقييم وأداء GridSearchCV ، نكون مستعدين لرسم الخط النهائي.
لتلخيص
مصفوفة الخطأ v.2
matrices = make_confussion_matrices(X_train,y_train) draw_confussion_matrices(1,2,first_row,figsize = (10.5,6)) draw_confussion_matrices(1,3,second_row,figsize = (16,6))

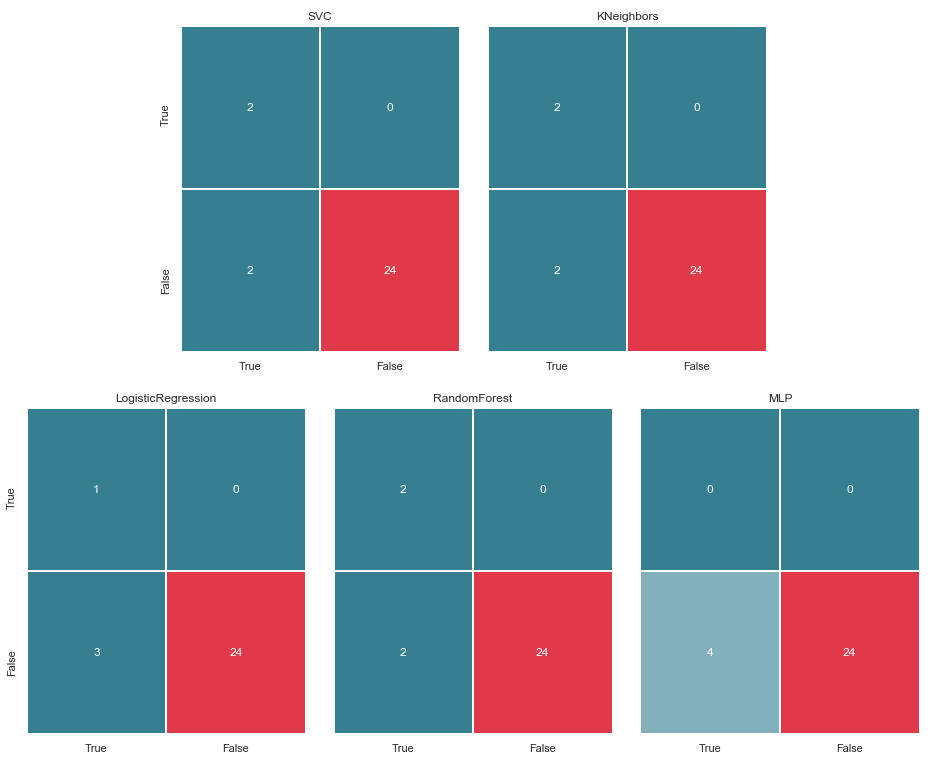
كما يتبين من المصفوفة ، أظهر MLP التحلل واعتبر أنه لا يوجد مشتبه بهم في عينة الاختبار. اكتسبت غابة عشوائية الدقة وصححت المعلمات السلبية الكاذبة والإيجابية الحقيقية. وأظهر KNeighbours تحسنا في التنبؤ. توقعات الآخرين لم تتغير.
الدقة v.2
الآن ، لا يوجد أي من المصنفات الحالية لدينا أخطاء مع خطأ إيجابي ، وهي أخبار جيدة. ولكن إذا عبرنا عن كل شيء بلغة الأرقام ، نحصل على الصورة التالية:
calculate_precision(X_train, y_train)
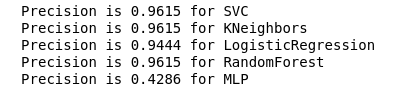
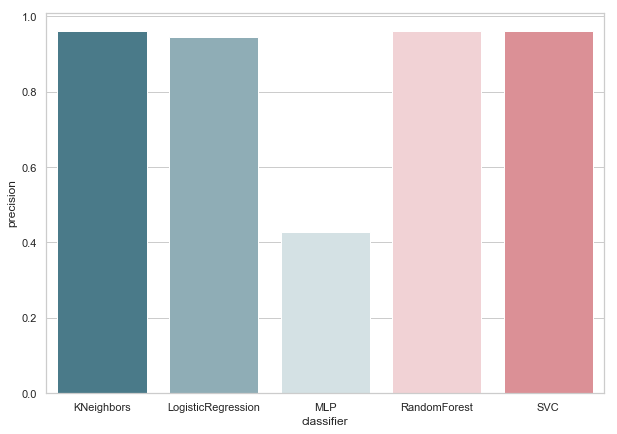
تم تحديد 3 المصنفات مع أعلى درجات الدقة. ولها نفس القيم ، بناءً على مصفوفة الخطأ. أي مصنف تختار؟
من هو الأفضل؟
يبدو لي أن هذا سؤال صعب إلى حد ما ولا توجد له إجابة عالمية. ومع ذلك ، فإن وجهة نظري في هذه الحالة قد تبدو مثل هذا:
1. يجب أن يكون المصنف بسيطا في تنفيذه الفني قدر الإمكان. ثم سيكون لديه خطر أقل لإعادة التدريب (ربما حدث هذا مع MLP). لذلك ، هذه ليست غابة عشوائية ، لأن هذه الخوارزمية عبارة عن مجموعة من 30 شجرة ، ونتيجة لذلك ، تعتمد عليها. متوافق مع إحدى أفكار Python Zen: البساطة أفضل من التعقيد.
2. ليس سيئًا عندما كانت الخوارزمية بديهية. أي أن KNeighbours يُنظر إليه ببساطة أكثر من SVM مع مساحة محتملة متعددة الأبعاد.
وهذا بدوره يشبه عبارة أخرى: الصريح أفضل من الضمني.
لذلك ، فإن الجيران مع 3 جيران ، في رأيي ، هو أفضل مرشح.
هذا هو نهاية الجزء الثاني ، ويصف استخدام مجموعة بيانات Enron كمثال لمهمة التصنيف في التعلم الآلي. استنادًا إلى المواد من دورة مقدمة في تعلُم الآلة على Udacity. هناك أيضًا دفتر ملاحظات python يعكس التسلسل الموضح بالكامل للإجراءات.